1.本发明涉及一种基于特征衰减筛选的神经机器翻译方法,属于自然语言处理中的机器翻译技术领域。
背景技术:
2.自从计算机诞生以来,人们一直希望找到某种方式,使计算机可以理解人类语言。自然语言处理(natural language processing,nlp)技术的发展将这一想法成为可能。机器翻译(machine translation,mt)作为自然语言处理领域的一个重要分支,其目的在于将一种语言经过某种变换,转化为另一种语言,并保持语义信息不变。
3.机器翻译系统大多基于神经网络,借助大规模平行数据和深度学习技术,神经机器翻译在一些翻译任务上取得了媲美人工翻译的成绩。但是,对于世界上大部分语言来说,大规模平行数据集的构建困难重重。目前,采用数据增强方法是解决数据量不足的一种有效途径,其中,反向翻译(back translation,bt)因较为有效,目前已广泛应用在各种低资源神经机器翻译方法中。
4.但是,受限于反向翻译模型的质量,其生成的伪数据质量良莠不齐,而由于伪数据数量可观,直接关系到最终翻译模型的效果,因此,迫切需要一种有效的方法来去除伪数据中质量较差的部分,提升伪数据质量,增强翻译模型的翻译效果。
技术实现要素:
5.本发明的目的是为了解决神经机器翻译方法反向翻译模型伪数据质量差导致的翻译效果不佳的技术问题,提出了一种基于特征衰减筛选的神经机器翻译方法。本方法的创新点在于:通过应用一种特征衰减算法,有效筛选去除反向翻译过程中质量较差的数据,增强了最终模型的翻译效果。
6.首先,对有关概念进行说明:
7.1.源语言和目标语言
8.源语言表示机器翻译任务的输入语言,目标语言表示机器翻译任务的输出语言。
9.2.平行数据集d
10.表示包含源语言文本和对应的目标语言文本的数据集,其形式为:d={(x1,y1),(x2,y2),
…
,(xi,yi),
…
,(xm,ym)},其中,下标m表示数据集共有m条数据,(xi,yi)表示一条数据,由源语言文本xi和对应的目标语言文本yi组成。
11.3.目标语言单语数据集dy12.表示仅由目标语言文本构成的数据集,形式为:dy={y1,y2,
…
,y
l
},下标l表示数据集中共有l条数据。
13.4.bpe(byte pair encoding),字节对编码技术
14.该技术通过不断组合出现频率最高的相邻字符的方式进行数据压缩,从而减少翻译字典条目。
15.5.句子特征
16.即n元模型(n-gram)。n元模型按照单词数量对文本进行划分,n取任意正整数。例如,句子“我喜欢吃苹果”中,“苹果”为一个2-gram,“吃苹果”为一个3-gram,使用2-gram和3-gram作为句子特征。
17.6.transformer翻译模型
18.为本方法构建翻译系统的基准模型。
19.一种基于特征衰减筛选的神经机器翻译方法,包括以下步骤:
20.步骤1:对平行数据集d和目标语言单语数据集dy进行数据预处理,包括数据清洗、分词和bpe处理。
21.具体地,可以采用以下方式:
22.步骤1.1:使用moses脚本清洗数据,包括去除源语言文本与目标语言文本长度差异过大的数据(比如,源语言文本与目标语言文本长度差异超过10的数据)、将文本字母小写化、对数据进行标点符号规范化(将标点符号统一替换为英文标点),其中,moses为机器翻译开源预处理工具。
23.步骤1.2:使用外部开源分词工具,对数据进行分词处理;
24.步骤1.3:使用外部开源bpe工具,对数据进行bpe处理。
25.步骤2:将平行数据集d输入到transformer模型中,训练得到从目标语言到源语言的反向翻译模型model
yx
。
26.步骤3:使用反向翻译模型model
yx
,将目标语言单语数据集dy翻译为源语言形式数据集d
x
,其形式为{x1,x2,
…
,x
l
}。
27.步骤4:将d
x
与dy对应数据拼接,构建伪平行数据集d
syn
,形式为:d
syn
={(x1,y1),(x1,y1),
…
,(x
l
,y
l
)}。
28.步骤5:应用特征衰减算法,对步骤4中所得伪平行数据集d
syn
进行筛选。
29.具体地,包括以下步骤:
30.步骤5.1:对平行数据集d中的源语言文本进行句子特征统计,并按照数量从大到小的顺序进行排序,取前k个句子特征,构建特征集合fs;
31.步骤5.2:为特征集合fs中的每个句子特征,赋初始分数init(f);
32.步骤5.3:遍历伪平行数据集d
syn
,对每条数据的源语言文本进行打分,如下:
[0033][0034]
其中,s表示源语言句子,score(s)表示该条句子的得分,word_counts表示s中的单词数量,value(f)表示当前迭代轮数句子特征f的分数,第一次迭代时value(f)=init(f)。
[0035]
步骤5.4:将伪平行数据集d
syn
的所有数据,按照得分从高到低进行排列,选择得分最高的前k条数据构建第一次迭代的数据选择集合s1,并将这k条数据从伪平行数据集d
syn
中去除。
[0036]
步骤5.5:对数据选择集合s1中的句子特征进行统计,对句子特征的分数进行衰减更新,具体如下:
[0037]
value(f)=init(f)0.5
c(f)
ꢀꢀꢀ
(2)
[0038]
其中,c(f)表示句子特征f在选择集合s1中出现的次数。随着句子特征f被选中的次数越多,其分数下降的也越多。
[0039]
步骤5.6:迭代n次上述步骤5.3至步骤5.5,得到n个数据选择集合{s1,s2,
…
,sn},将其进行合并得到筛选后的伪数据集df。
[0040]
步骤6:将步骤5中所得的筛选后数据集df与平行数据集d合并,得到合成平行数据集d
final
。
[0041]
步骤7:将合成平行数据集d
final
输入transformer模型中,训练源语言到目标语言的神经机器翻译模型,利用该模型进行翻译。
[0042]
至此,经过步骤1到步骤7,首先通过反向翻译得到初始的伪数据集,然后通过特征衰减方法对伪数据集进行筛选过滤,随后将过滤后的伪平行数据集加入模型训练,得到的模型相较于未经过滤的方式,翻译质量有进一步的提高。
[0043]
有益效果
[0044]
本发明方法,对比现有技术,具有以下优点:
[0045]
本方法针对常规使用反向翻译方法增强机器翻译效果的方法中存在伪数据质量良莠不齐的问题,通过引入特征衰减筛选的过程,有效剔除了质量不高的伪数据,从而减少噪声数据对模型训练带来的不良影响,提高了模型翻译效果。
附图说明
[0046]
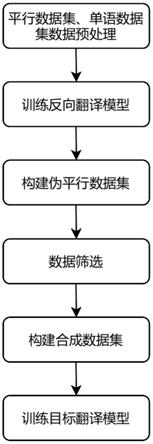
图1为本发明方法的流程图。
具体实施方式
[0047]
下面将结合说明书附图和实施例对本发明方法作进一步详细说明。
[0048]
实施例
[0049]
以iwslt2014数据集中的德英数据集和英语单语数据集为实施例,本实施例将以具体实例对本发明方法进行详细说明。
[0050]
一种基于特征衰减筛选的神经机器翻译方法,如图1所示,包括以下步骤:
[0051]
步骤1:对平行数据集、单语数据集数据进行预处理。
[0052]
对iwslt2014德英数据集和英语单语数据集进行数据清洗和分词,使用工具为moses脚本,随后进行bpe处理。例如,原始数据为(“was ist mit langlebigkeit?”,“what about longevity?”),经过数据清洗、分词和bpe之后的处理结果为:(“was ist mit lang@@le@@big@@keit?”,“what about lon@@ge@@vity?”)。经处理得到德英平行数据集150k,英语单语数据集130k。
[0053]
步骤2:训练反向翻译模型。
[0054]
使用150k德英平行数据集训练英德反向翻译模型,使用模型为transformer-base模型,参数设置使用原始模型推荐参数。
[0055]
步骤3:构建伪平行数据集。
[0056]
使用步骤2中所得的英德翻译模型对英语单语数据集进行反向翻译,得到德英伪平行数据集130k。
[0057]
步骤4:数据筛选.
[0058]
首先对平行数据集中的德语数据进行句子特征统计,构建特征集合。例如,对于句子“was ist mit lang@@le@@big@@keit?”,使用2-gram和3-gram作为句子特征,其句子特征为{“was ist”,“ist mit”,“mit lang@@”,“lang@@le@@”,“le@@big@@”,“big@@keit”,“keit?”,“was ist mit”,“ist mit lang@@”,“mit lang@@le@@”,“lang@@le@@big@@”,“le@@big@@keit”,“big@@keit?”}。对数据集中所有数据均进行句子特征统计后取前5k个句子特征构成特征集合。随后遍历伪平行数据集,按照步骤5所述公式对伪平行数据集中所有句子进行打分,并选择得分最高的前10k条数据加入筛选后的伪平行数据集。迭代此过程6次,得到筛选后的伪平行数据集60k。
[0059]
步骤5:构建合成数据集。
[0060]
将步骤4中所得的筛选后的伪平行数据集与平行数据集合并,构成用于最终目标翻译模型训练的合成数据集,共计210k条数据。
[0061]
步骤6:训练目标翻译模型。
[0062]
使用合成数据集训练源语言到目标语言的翻译模型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。