用于概念聚类的设备和计算机实现的方法
背景技术:
1.本发明涉及概念聚类。
2.例如在r. e. stepp和r. s. michalski.的“conceptual clustering of structured objects: a goal-oriented approach”(人工智能,28(1):43
–
69(1986))中描述了概念聚类在关系数据上的任务。
技术实现要素:
3.本发明提供了一种用于解决关系数据上的概念聚类问题的计算机实现的方法、对应的设备和对应的计算机程序。
4.该计算机实现的方法包括:确定第一实体的嵌入,特别是知识图的嵌入,在特别是加权的、特别是无向图中插入用于嵌入的第一顶点,在图中确定包括第一顶点的顶点的第一聚类,为第一聚类确定第二实体,特别是在知识图中,确定第一实体与第二实体之间的语义相似度,特别是在知识图中,取决于第一实体与第二实体之间的语义相似度来确定第一聚类的规则。这样,概念聚类任务在知识图kg的实体上执行,其中给定目标实体的集合和kg,目标是基于在kg上为这些组计算的描述的质量,将这些实体聚类到特别是未知数量的不同组中。该规则为计算的聚类提供了对于人类和机器一样可理解的描述。该方法具有计算高质量聚类连同其描述的能力,而无需先验知道它们的数量。此外,与不需要聚类的数量作为输入的其他现有聚类方法(例如,dbscan)形成对比,该方法由于要调谐的超参数的数量小而尤其吸引人。
5.在图中插入第一顶点可以包括利用标签来标记将图的第一顶点链接到第二顶点的图的边。依赖于目标实体,构造了特别是无向完全加权图,其中每对实体之间的边被标记。
6.对边进行标记可以包括取决于第一顶点的第一向量与第二顶点的第二向量之间的距离来确定权重,并且利用函数将权重映射到标签。使用例如嵌入空间中相应实体之间的余弦相似度来标记每对实体之间的边。
7.确定第一聚类可以包括确定包括第一顶点的第一聚类的图的边的子集,使得图中没有循环与该子集相交一次。多切割(multicut)问题基于该图被制定并且得到了有效解决。
8.确定嵌入可以包括利用模型将第一实体映射到向量空间中的第一向量。该模型可以是嵌入模型,其将kg的实体和关系转换成向量空间中的向量,特别是低维向量空间中的向量。
9.确定规则可以包括取决于与第二实体的语义相似度来确定多个规则,并且从多个规则选择规则。
10.选择规则可以包括确定规则所覆盖的属于第一聚类的实体的数量,确定规则所覆盖的属于第二聚类的实体的数量,取决于规则所覆盖的属于第一聚类的实体的数量并且取决于属于第二聚类的实体的数量来确定规则的度量,以及如果度量满足条件则选择该规
则,或否则不选择该规则。
11.确定度量可以包括确定规则所覆盖的属于第一聚类的实体的数量与第一聚类的基数的比率。
12.确定度量可以包括确定规则所覆盖的属于第二聚类的实体的数量与第二聚类的基数的比率。
13.该方法可以包括取决于规则来确定输出,检测规则的输入,以及取决于输入来确定规则的标签。该规则描述了kg中发现的概念。可以向专家提供这样的描述,并且为其建议名称。这样的概念可以然后以建议的名称被添加到kg。
14.该方法可以包括接收输入,特别是查询或消息,取决于输入来选择规则,取决于规则来确定至少一个实体,取决于至少一个实体来输出响应。
15.输出响应可以包括取决于至少一个实体来指示机器的状态、数字图像中对象的属性或问题的答案。
16.该设备适于执行该方法。该计算机程序包括计算机可读指令,所述计算机可读指令当在计算机上执行时,使得计算机执行该方法中的步骤。
附图说明
17.另外有利的实施例从以下描述和附图可导出。在附图中:图1示意性地描绘了用于解决关系数据上的概念聚类问题的设备的各方面,图2示意性地描绘了用于解决关系数据上的概念聚类问题的方法中的步骤,图3示意性地描绘了应用的方面。
具体实施方式
18.知识图kg表示事实信息的相互关联的集合,并且它们经常被编码为《主谓宾》三元组的集合,例如,《约翰工作在a公司》。这样的三元组的主语或宾语被称为实体。谓词被称为关系。kg三元组的集合可以被自然地表示为有向图,其顶点和边都被标记。
19.知识图嵌入kge涉及将kg实体和关系嵌入到用户指定维数为n的连续向量空间中。更具体地,kge模型将kg三元组的集合取作输入,并且旨在将实体和关系映射到n维向量空间中,使得保留反映kg结构的一些特征。这些特征由相应嵌入模型的目标函数捕获。从关系数据这样获得数值向量集合。
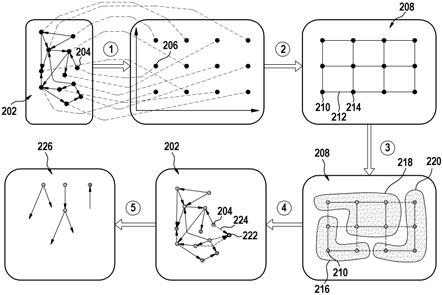
20.概念聚类是将知识图中的实体分组为具有高聚类间相似度和低聚类内相似度的组的集合,以及依据它们的kg属性描述每个聚类内的实体的共性。
21.图的多切割是其边的子集,使得图中没有循环与该子集恰好相交一次。
22.规则归纳(rule induction)是从kg学习规则的任务,即,给定kg,规则学习的目标是构造表单规则的集合,其中h是表单的隐含谓词,其中c是对应于目标聚类的虚拟常数,h是反映x与目标聚类之间的关系的虚拟谓词,并且b是表单谓词的合取,其中每个都可以是变量或者是常数,使得经学习的规则在数据中保持足够频繁。
23.规则的度量是以下函数,其将kg和规则取作输入,并且输出反映给定规则与kg多
么好地匹配的值。
24.合取查询cq是表单的表达,或者有时简单地写做,其中b是类似于为规则定义的cq的主体,并且是所谓的答案变量,即,变量,其位置负责查询的答案。
25.用户以这种查询的形式制定他们的信息需求。例如,对于存储在a公司员工中的kg,可能的合取查询可以要求为a公司的d部门工作的所有人都已婚并且有孩子。形式上,这样的查询可以写作。
26.在上面的示例中,x是给定cq的答案变量。合取查询可以被自然地表示为kg模式。
27.图1描绘了包括至少一个处理器102和用于存储指令和其他数据的至少一个存储装置104的设备100。设备100可以包括输入106和输出108。输入106可以是消息的接收器或用于检测用户查询的用户界面。输出108可以是显示器。
28.设备100适于执行下面参考图2描述的方法。作为关系数据的示例,将针对包括多个实体的知识图kg 202来描述该方法。下面针对多个实体中的第一实体204解释该方法的原理。该方法可以应用于kg 202的任何实体。该方法也可以应用于目标实体,例如,kg 202的一部分。
29.下面描述的用于概念聚类的方法不需要关于聚类数量的信息。
30.该方法将知识图kg、实体t的集合以及包括聚类描述的最大长度m、最小覆盖率和阈值的其他参数取作输入,这些参数用于确定计算出的描述的质量。
31.该方法包括确定kg 202的至少一个实体的嵌入的步骤1。该嵌入可以是向量空间中的向量。该嵌入可以利用模型、特别是嵌入模型来确定。图2示例性地描绘了第一实体204的嵌入206。第一实体204的嵌入206可以是第一向量。
32.对应的算法可以通过使用特定的嵌入模型将实体和关系嵌入到低维向量空间中来开始。可以使用任何嵌入模型。在ren,h.,hu,w.,leskovec,j.的“query2box: reasoning over knowledge graphs in vector space using box embeddings”(in:iclr(2020))中描述了示例性嵌入模型。
33.该方法包括确定图208的步骤2。在该示例中,图208是针对kg 202的实体的嵌入而确定的。步骤2包括在图208中插入用于嵌入206的第一顶点210。当使用目标实体,即,kg 202的实体子集时,图208在存在比实体少的顶点的意义上是不完全的。这意味着,实际上可以避免整个kg 200的图208的构造。
34.示例中的图208是加权无向图。
35.步骤2包括确定图208的边的标签208。在该示例中,在图208中插入第一顶点210包括利用标签来标记将图208的第一顶点210链接到第二顶点214的图的边212。
36.对边212进行标记可以包括取决于第一顶点210的第一向量与第二顶点214的第二向量之间的距离[余弦相似度]来确定权重,并且利用函数将权重映射到标签。
[0037]
在该示例中,图210是可以用作至多切割算法的输入的相似度图。一旦实体和关系被映射到嵌入空间,就可以计算完全无向加权图。在该示例中,,并且e中的每对实体都被连接。然后,该方法使用其向量的余弦相似度来计算每对实体之间的成对距
离。
[0038]
更具体地,让a、b是两个目标实体,并且让是它们在嵌入空间中相应的数值向量。然后如下使用余弦相似度函数来计算a与b之间的距离:。
[0039]
然后构造的完全图g中的每条边都利用以下函数标记。
[0040]
该方法包括在图208中确定至少一个聚类的步骤3。优选地,步骤3包括确定图208中的至少两个聚类。在该示例中,确定包括第一顶点210的顶点的第一聚类216。在该示例中,还确定了第二聚类218和第三聚类220。
[0041]
确定第一聚类216可以包括确定包括第一顶点210的第一聚类216的图208的边的子集,使得图208中没有循环与该子集相交一次。
[0042]
多切割聚类算法可以用于检测嵌入空间中的突出区域。chopra, s., rao, m.的“the partition problem”(math. prog. 59(1
–
3),87
–
115(1993))中公开了多切割聚类方法的各方面。
[0043]
图210的多切割是其边的子集,使得图中没有循环与该子集恰好相交一次。将1分配给多切割中的边,并且将0分配给所有其他边,所有有效多切割的集合可以通过以下线性不等式集合来正式化:。
[0044]
在该示例中,仅考虑无弦循环就足够了。任何有效的多分割唯一地定义了图分解。
[0045]
给定以上定义,最小成本多分割问题如下:。
[0046]
例如,如在keuper,m.,levinkov,e.,bonneel,n.,lavoue,g.,brox,t.,andres,b.的“efficient decomposition of image and mesh graphs by lifted multicuts”(in:iccv(2015))中公开的,该问题使用基于局部搜索策略的有效启发式方法是可解决的。
[0047]
该方法包括为第一聚类216确定第二实体222的步骤4。该步骤4包括确定第一实体204与第二实体222之间的语义相似度224。在知识图202中确定第二实体222和语义相似度224。
[0048]
该方法包括取决于第一实体204与第二实体222之间的语义相似度来确定第一聚类216的规则226的步骤5。
[0049]
确定规则226可以包括取决于与第二实体的语义相似度来确定多个规则,并且从多个规则选择规则226。
[0050]
通过学习horn规则,可以将向量空间中的构造区域(即,聚类)映射到合取查询
(即,描述)。更具体地,对于在步骤3中被聚类成聚类c的每个实体a,该方法可以向kg添加事实,并且学习表单的规则其中m是如上提及的由用户指定的期望描述长度,而是出现在kg中的关系。这意味着实体a被规则覆盖。
[0051]
在galarraga,l.,teflioudi,c.,hose,k.,suchanek,f.m.的“fast rule mining in ontological knowledge bases with amie ”(vldb journal 24(6),707
–
730 (2015))中公开了可以用于学习这样的规则的示例性算法。
[0052]
在其中描述的方法如下所述被修改成能够捕获规则头中的常数。更具体地,在示例性实现方式中,规则被修改成从开始而不是,并且除了“add closing atom operator”操作符之外,通过应用在“fast rule mining in ontological knowledge bases with amie ”中描述的扩展操作符来构造规则的主体。
[0053]
然后可以在各种规则度量上删减经学习的规则,该规则度量诸如是置信度、覆盖率或加权的相对准确度。
[0054]
选择规则226可以包括确定规则226所覆盖的属于第一聚类216的实体的数量,以及确定规则所覆盖的属于第二聚类218的实体的数量。取决于规则226所覆盖的属于第一聚类216的实体的数量并且取决于属于第二聚类218的实体的数量来确定规则226的度量。如果度量满足条件,则选择规则226。否则,不选择规则226。
[0055]
确定度量可以包括确定规则226所覆盖的属于第一聚类216的实体的数量与第一聚类216的基数的比率。
[0056]
确定度量可以包括确定规则所覆盖的属于第二聚类218的实体的数量与第二聚类218的基数的比率。
[0057]
第三聚类220可以类似地用于确定度量。
[0058]
在示例中,可以使用排他性覆盖率度量来估计所获得的聚类描述的质量。该度量的主要优点是,在评估给定规则时,它计及了所有计算出的聚类,这与估计单独考虑的规则质量的大多数其他规则度量形成对比。这确保了给定的规则对于手边的聚类是排他性的,这有助于其质量。对于给定的规则r、聚类c、聚类s的集合和kg,排他性覆盖率度量被定义如下:
[0059]
其中是聚类c的规则r的标准覆盖率,并且知识图kg被定义为聚类c内被r所覆盖的实体相对于c的基数的比率。
[0060]
最后,在所有计算出的聚类描述当中,可以选择那些具有最高平均排他性覆盖率的描述。
[0061]
该方法可以包括取决于规则226来确定输出,并且检测规则226的输入,特别是响应于该输出。该方法可以包括取决于输入来确定规则226的标签。
[0062]
规则可以用作基于嵌入所构造的聚类的解释,并且因此可以被视为有助于机器学习模型的可解释性的资产。
[0063]
规则表示概念的人类可解释的标签,所述标签是基于它们的语义相似度进行分组的突出的实体集合。
[0064]
例如,假设给出了从材料科学背景下的科学出版物提取的kg。显然,在这样的提取过程之后,许多概念(例如,sofc的类型)可能丢失,因为它们可能不在文本中被直接提及。
[0065]
在将上述方法应用于这样的kg之后,人们可能获得具有规则226的实体的聚类,该规则226将其描述为“直接通过氧化燃料产生电力的电化学转换设备,其具有从针状形状到大约1.5-2 m长度的尺寸,以用于快速启动时间和大的总功率”的集合。
[0066]
当材料科学家被提供有这样的描述时,他们可以立即意识到该标签描述了“管状sofc”,并且这样的概念可以以建议的名称被添加到kg。
[0067]
该示例中的规则226和输出是“直接通过氧化燃料产生电力的电化学转换设备,其具有从针状形状到大约1.5-2 m长度的尺寸,以用于快速启动时间和大的总功率”或其表示。在该示例中,规则226的标签可以是“管状sofc”。
[0068]
该方法和规则特别有助于半自动本体构造的过程。
[0069]
这使得能够创建新概念,即,新规则。如上所述向kg显式添加新概念可以优化问题回答过程。
[0070]
下面参考图3描述应用的各方面。
[0071]
对应的方法包括接收输入、特别是查询的步骤302。
[0072]
该查询可以是用户用自然语言制定的问题。该问题可以被翻译成正式的表示。
[0073]
该方法包括取决于输入来选择规则226的步骤304。
[0074]
在该示例中,任务是找到问题的答案。当使用对应于概念的规则找到kg中的至少一个实体时,就找到了问题的答案。由于问题是由用户用自然语言制定的,因此它们可能经常包含概念,对于此不存在规则。
[0075]
在这种情况下,该方法包括自动检测如上所述概念的规则226。
[0076]
该方法包括取决于规则226来确定至少一个实体的步骤306。
[0077]
该方法包括取决于至少一个实体来输出响应的步骤308。
[0078]
规则226可以作为在确定规则226时检测到的概念的描述而被呈现给用户。然后,用户可以更好地理解响应。
[0079]
该查询可以涉及机器的状态、数字图像中对象的属性或问题的答案。
[0080]
输出响应可以包括取决于至少一个实体来指示机器的状态、数字图像中对象的属性或问题的答案。
[0081]
在具有适于经由消息进行通信的多个机器的生产线中,输入可以是消息。该消息可以包含有关机器状态的信息。在这种情况下,规则可以涉及针对故障识别的概念。在这种情况下,输出可以是用生产线生产的产品的健全性状态,或者机器或生产线的另一个机器的健康状态。
[0082]
对于数字图像处理,kg可以是在图像的对象识别中被识别的对象的描述。kg中的实体可以表示其对象和/或属性。
[0083]
在街景中,对象可以是汽车、人、房子或基础设施的其他部分。在街景中,属性可以
描述对象和/或对象与另一个对象的关系,特别是在数字图像中。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
