1.本发明涉及计算机视觉技术领域,尤其涉及基于歧义指导互标签更新的鲁棒知识蒸馏方法。
背景技术:
2.近些年,许多模型压缩方法被提出用于减少卷积神经网络的参数量从而实现模型加速的目的。在这些方法当中,知识蒸馏扮演了一个重要的角色。知识蒸馏通常包含一个教师网络和一个学生网络,学生网络通过学习教师网络的输出中蕴含的“暗知识“,泛化能力得到了明显增强。但是在实际情况中,训练数据集中往往含有大量的标签噪声,对这些标签噪声的过拟合会显著影响知识蒸馏的性能。
技术实现要素:
3.有鉴于此,本发明的目的在于提出一种基于歧义指导互标签更新的鲁棒知识蒸馏方法,该方案基于标签更新策略,在知识蒸馏的过程中动态地更新标签,从而大大降低了噪声标签对知识蒸馏的影响,提升了模型的鲁棒性。
4.为了实现上述的技术目的,本发明所采用的技术方案为:
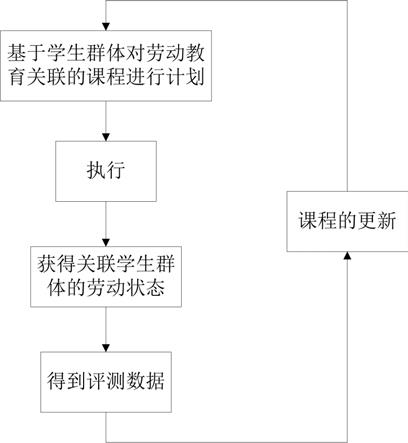
5.一种基于歧义指导互标签更新的鲁棒知识蒸馏方法,其包括:
6.a、构建训练数据集,并按预设条件对其进行预处理;
7.b、构建教师网络和学生网络;
8.c、通过鲁棒学习方法将训练数据集导入教师网络中进行训练,获得预设性能的教师模型;
9.d、将训练数据集导入学生网络中,然后对训练数据集中的每个样本进行歧义感知权重估计和权重分配;
10.e、学生网络按预设条件根据小损失标准对训练数据集中的样本进行标签重新标注,再结合教师网络特征的标签传播算法更新标签,然后计算损失,更新网络参数;
11.f、在学生网络和教师网络之间进行互标签传播算法,并更新样本标签,然后计算损失,更新网络参数;
12.g、将测试图像数据导入学生网络,由学生网络的学生模型前向传播得到预测结果且将其用于图像分类。
13.作为一种可能的实施方式,进一步,步骤a中,所述训练数据集包括具有噪声标签数据的噪声数据集和/或无噪声标签数据的无噪声数据集;其中,无噪声标签数据的无噪声数据集经注入噪声处理后,生成合成噪声数据集。
14.作为其中一种较优的无噪声数据集处理方法,优选的,所述无噪声数据集被等分为两份,其中一份经注入噪声处理后,用于学生网络训练,另一份不作处理,用于教师网络训练,,该噪声被设为c-n噪声,所述教师模型使用标准交叉熵损失训练。
15.作为另一种较优的无噪声数据集处理方法,优选的,所述注入噪声处理的方法为
在无噪声数据集中加入对称和/或非对称噪声。
16.作为一种较优的选择实施方式,优选的,所述噪声数据集包括animal-10n数据集、clothing1m数据集中的一种以上,所述无噪声数据集包括cifar-100数据集。
17.作为一种较优的选择实施方式,优选的,步骤b中,所述教师网络、学生网络为如下之一:
18.(1)所述教师网络为层数为40,宽度系数为2的宽残差网络,所述学生网络为层数为16,宽度系数为2的宽残差网络;
19.(2)所述教师网络为层数为40,宽度系数为2的宽残差网络,所述学生网络为层数为40,宽度系数为1的宽残差网络;
20.(3)所述教师网络为层数为56的残差网络,所述学生网络为层数为20的残差网络。
21.作为一种较优的选择实施方式,优选的,步骤d中,通过歧义感知权重估计模块对训练数据集中的每个样本进行歧义感知权重估计和权重分配,该歧义感知权重估计模块包括两个全连接层,且两个全连接层之间还设有prelu层,步骤d具体包括:
22.将训练数据集中的所有样本导入学生网络,得到它们的特征,然后计算每个类别的原型特征,其公式如下:
[0023][0024]
其中,为训练数据的数量,nc表示类别为c的样本数量;
[0025]
按如下公式计算每个样本的特征分布得分:
[0026][0027]
将在第t轮的标签和特征分布得分拼接起来得到歧义特征向量,其公式如下:
[0028][0029]
其中,作为歧义特征向量送入一个双层感知机网络得到最终的样本权重,其公式如下:
[0030][0031]
其中为两个全连接层,σ表示prelu操作;
[0032]
将权重写为矩阵形式,其公式如下:
[0033][0034]
作为一种较优的选择实施方式,优选的,步骤e具体包括:
[0035]
使用教师网络的特征构建k-nn图g=<v,e>,其中v和e分别表示顶点集合和边集合,顶点之间的相似度矩阵被描述如下:
[0036]
[0037]
其中代表样本xi在教师网络下的特征,nnk(xi)表示样本xi的k近邻,然后,可得到一个对称邻接矩阵继而进行归一化w
t
得到其中,d为对角度矩阵;同时,根据小损失标准,训练数据集原始的标注将被根据学生网络小损失标准重新标注,其公式如下:
[0038][0039]
其中,表示学生网络对样本xi的预测,为样本的原始标签,为指示函数,表示被学生网络选择的干净样本集合;
[0040]
联合k-nn图g,将更新后的标签矩阵z和样本权重矩阵进行标签传播,其公式如下
[0041][0042]
其中,lp可被定义为其中,lp可被定义为式中,
⊙
表示对应元素间相乘,β为超参数用于平衡损失;计算得到更新后的标签y
(t)
后,按如下公式计算损失:
[0043][0044]
其中,定义为:
[0045][0046]
使用mixup算法得到混合样本数据,所述混合样本数据为虚拟样本,其公式如下:
[0047][0048][0049]
在上述虚拟样本下构建蒸馏损失其公式如下:
[0050][0051]
其中,
[0052]
τ为温度参数;
[0053]
同样的,定义混合样本的分类损失其公式如下:
[0054][0055]
最后,定义了如下损失使学生网络模仿教师网络的样本间的相似度,其公式如下:
[0056]
。
[0057]
作为一种较优的选择实施方式,优选的,步骤f包括:
[0058]
首先,利用步骤d中歧义感知的权重估计模块为每个样本估计权重,得到权重矩阵并按照如下过程更新标签:
[0059][0060][0061]
最后,通过公式(4)计算损失更新网络参数。
[0062]
基于上述方案,本发明还提供一种计算机可读的存储介质,所述的存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述的至少一条指令、至少一段程序、代码集或指令集由处理器加载并执行实现上述所述的基于歧义指导互标签更新的鲁棒知识蒸馏方法。
[0063]
采用上述的技术方案,本发明与现有技术相比,其具有的有益效果为:本方案基于教师-学生网络,提出了一种包括小损失选择的标签传播和互标签传播两个阶段的二阶段标签更新方法,基于该设计的标签更新策略,可以有效地提升知识蒸馏对噪声标签的鲁棒性,从而可以在噪声标签的环境下获取一个高性能的轻量级网络,相比于传统的知识蒸馏方法,本方案考虑到了更为实际的噪声标签问题,使得知识蒸馏算法更能适用于实际情况。
附图说明
[0064]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0065]
图1是本发明方法的简要实施流程示意图。
[0066]
图2是本发明方法的简要原理流程示意图。
具体实施方式
[0067]
下面结合附图和实施例,对本发明作进一步的详细描述。特别指出的是,以下实施例仅用于说明本发明,但不对本发明的范围进行限定。同样的,以下实施例仅为本发明的部分实施例而非全部实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0068]
如图1或图2所示,本方案一种基于歧义指导互标签更新的鲁棒知识蒸馏方法,其包括:
[0069]
a、构建训练数据集,并按预设条件对其进行预处理;
[0070]
本步骤中,使用的训练数据集为常见的三个图像分类数据集,其分别为cifar-100数据集、animal-10n数据集、clothing1m数据集,其中,cifar-100数据集为不含有噪声标签的无噪声数据集,其可以通过添加对称、非对称噪声使其成为合成噪声数据集;除此之外,本方案还提供一种c-n噪声,即将无噪声数据集等分为两份,一份注入噪声(对称、非对称噪声)用于学生网络训练,另一份不做处理用于教师网络训练,该c-n噪声的标准交叉熵损失用于训练教师网络;另外,animal-10n数据集,clothing1m数据集为真实场景下的数据集,其分别含有约8%和38%的噪声标签数据。此外,在训练过程中,还可以采用图像旋转,翻转等方式用于数据增强。为简化描述,下述使用表示训练学生网络所使用的数据集。
[0071]
b、构建教师网络和学生网络;
[0072]
本步骤中,教师网络相比于学生网络一般具有更复杂的模型结构,本方案可以采取如下三对知识蒸馏中常用的网络结构,其分别是:
[0073]
(1)所述教师网络为层数为40,宽度系数为2的宽残差网络,所述学生网络为层数为16,宽度系数为2的宽残差网络,即wrn_40_2-wrn_16_2;
[0074]
(2)所述教师网络为层数为40,宽度系数为2的宽残差网络,所述学生网络为层数为40,宽度系数为1的宽残差网络,即wrn_40_2-wrn_40_1;
[0075]
(3)所述教师网络为层数为56的残差网络,所述学生网络为层数为20的残差网络,即resent56-resnet20。
[0076]
为简化描述,下述分别使用和代表学生模型和教师模型。
[0077]
c、通过鲁棒学习方法将训练数据集导入教师网络中进行训练,获得预设性能的教师模型;
[0078]
本步骤中,所导入的训练数据集为c-n噪声时,该c-n噪声的标准交叉熵损失用于训练教师网络,对于其余的噪声类型(对称、非对称,真实噪声),本方案使用经典鲁棒学习算法dividemix(j.li,r.socher,and s.c.hoi,“dividemix:learning with noisy labels as semi-supervised learning,”in int.conf.learn.represent.,2019.)预训练一个教师模型。
[0079]
d、将训练数据集导入学生网络中,然后对训练数据集中的每个样本进行歧义感知权重估计和权重分配;
[0080]
本步骤中,通过歧义感知权重估计模块对训练数据集中的每个样本进行歧义感知权重估计和权重分配,该歧义感知权重估计模块包括两个全连接层,且两个全连接层之间还设有prelu层,本步骤具体包括:
[0081]
将训练数据集中的所有样本导入学生网络,得到它们的特征,然后计算每个类别的原型(prototype)特征,其公式如下:
[0082]
[0083]
其中,为训练数据的数量,nc表示类别为c的样本数量;
[0084]
接下来,按如下公式计算每个样本的特征分布得分:
[0085][0086]
然后,将在第t轮的标签和特征分布得分拼接起来得到歧义特征向量,其公式如下:
[0087][0088]
其中,作为歧义特征向量送入一个双层感知机网络得到最终的样本权重,其公式如下:
[0089][0090]
其中,为两个全连接层,σ表示prelu操作,该双层感知机网络为前述歧义感知权重估计模块,其包含两层全连接层,输出为一个标量(权重)。具体来说,本方案将标签和相似度得分拼接起来得到歧义特征然后将其送入歧义感知权重估计模块计算该样本的权重;
[0091]
将权重写为矩阵形式,其公式如下:
[0092][0093]
e、学生网络按预设条件根据小损失标准对训练数据集中的样本进行标签重新标注,再结合教师网络特征的标签传播算法更新标签,然后计算损失,
[0094]
更新网络参数;
[0095]
本步骤具体包括:
[0096]
首先,使用教师网络的特征构建k-nn图g=<v,e>,其中,v和e分别表示顶点集合和边集合,顶点之间的相似度矩阵被描述如下:
[0097][0098]
其中代表样本xi在教师网络下的特征,nnk(xi)表示样本xi的k近邻,然后,可得到一个对称邻接矩阵继而进行归一化w
t
得到其中,d为对角度矩阵;同时,根据小损失标准,训练数据集原始的标注将被根据学生网络小损失标准重新标注,其公式如下:
[0099][0100]
其中,表示学生网络对样本xi的预测,为样本的原始标签,为指
示函数,表示被学生网络选择的干净样本集合;
[0101]
联合k-nn图g,将更新后的标签矩阵z和样本权重矩阵进行标签传播,其公式如下:
[0102][0103]
其中,lp可被定义为其中,lp可被定义为式中,
⊙
表示对应元素间相乘,β为超参数用于平衡损失;计算得到更新后的标签y
(t)
后,按如下公式计算损失:
[0104][0105]
其中,定义为:
[0106][0107]
为了进一步提高蒸馏的鲁棒性,使用mixup算法(hongyi zhang,moustapha cisse,yann n dauphin,and david lopez-paz.mixup:beyond empirical risk minimization.in iclr,2018)得到混合样本数据,所述混合样本数据为虚拟样本,其公式如下:
[0108][0109][0110]
在上述虚拟样本下构建蒸馏损失其公式如下:
[0111][0112]
其中,
[0113]
τ为温度参数;
[0114]
同样的,定义混合样本的分类损失其公式如下:
[0115][0116]
最后,为了使得学生网络具有更好的特征表示能力,定义了如下损失使学生网络模仿教师网络的样本间的相似度,其公式如下:
[0117]
。
[0118]
f、在学生网络和教师网络之间进行互标签传播算法,并更新样本标签,然后计算损失,更新网络参数;
[0119]
本步骤具体包括:
[0120]
首先,利用步骤d中歧义感知的权重估计模块为每个样本估计权重,得到权重矩阵并按照如下过程更新标签:
[0121][0122][0123]
最后,通过公式(4)计算损失更新网络参数。
[0124]
g、将测试图像数据导入学生网络,由学生网络的学生模型前向传播得到预测结果且将其用于图像分类。
[0125]
本步骤作为本方案的推理阶段,其只用到训练好的学生网络,将测试图像送入学生网络,学生网络得到输出完成推理。
[0126]
另外,在本发明各个实施方式中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
[0127]
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本发明各个实施方式方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0128]
以上所述仅为本发明的部分实施例,并非因此限制本发明的保护范围,凡是利用本发明说明书及附图内容所作的等效装置或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。