1.本技术涉及数据处理技术领域,尤其涉及一种文本分类模型的训练方法、文本分类方法、装置和设备。
背景技术:
2.随着信息化、数字化的不断深入,运维过程的智能化程度不断提升。日志数据作为互联网技术(internet technology,it)的重要输出,在监测、分析系统运行情况方面发挥着重要的作用。
3.现有技术中针对运维日志的分析主要是针对机器人的运行日志进行分析,缺少针对浏览器弹窗日志分析方法。浏览器弹窗日志为用户通过浏览器访问系统时,浏览器上弹出的弹窗内的文本信息。
4.为了更好的监测和分析系统,急需一种文本分类方法,能够对浏览器弹窗日志进行分类。
技术实现要素:
5.本技术提供一种文本分类模型的训练方法、文本分类方法、装置和设备,能够解决现有技术中无法对浏览器弹窗日志进行分析的问题,基于训练得到的文本分类模型对系统进行监测和分析,能够提高系统运维效率。
6.第一方面,本技术提供一种文本分类模型的训练方法,包括:获取多条浏览器的历史弹窗内的文本信息;对每个文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量;对第一特征向量进行聚类,得到至少一个文本信息组;从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板;根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型。
7.可选地,对每个文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量,包括:对每个文本信息进行分词处理,生成第一词袋;确定第一词袋中,任一第一词汇对应的第二特征向量;根据第二特征向量,确定每个文本信息对应的第一特征向量。
8.可选地,根据第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量,包括:获取第一词袋中的第一词汇的总数量;获取第一词袋中的每个第一词汇在多个文本信息中的出现频次,以及包含每个第一词汇的文本信息数量;根据第一词袋中的第一词汇的总数量、每个第一词汇在多个历史弹窗内的文本信息中的出现频次,以及包含每个第一词汇的文本信息数量,确定每个第一词汇分别对应的权重;根据第一词袋中的每个第一词汇分别对应的权重,以及每个第一词汇对应的第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量。
9.可选地,根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分
类模型,包括:对每个文本信息模板进行分词处理,生成第二词袋;确定第二词袋中,任一第二词汇对应的第三特征向量;根据文本相似度算法和第三特征向量,对初始文本分类模型进行训练,得到文本分类模型。
10.可选地,确定第一词袋中,任一第一词汇对应的第二特征向量之后,还包括:对第二特征向量进行降维处理,得到降维后的第二特征向量;相应的,根据第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量,包括:根据降维后的第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量。
11.可选地,对每个历史弹窗内的文本信息进行分词处理,包括:对每个历史弹窗内的文本信息进行预处理,得到预处理后的历史弹窗内的文本信息,以去除历史弹窗内的文本信息中包括的目标数据,目标数据包括如下类型的数据中的至少一种:数字、外语和符号;对预处理后的历史弹窗内的文本信息进行分词处理。
12.第二方面,本技术提供一种文本分类方法,包括:获取待分类文本信息,文本信息为浏览器的弹窗内的信息;对待分类文本信息进行分词处理,生成第三词袋;将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息的类型,文本分类模型为通过多条浏览器的历史弹窗内的文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量,并对第一特征向量进行聚类,得到至少一个文本信息组,并从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板,并根据至少一个文本信息模板,对初始文本分类模型进行训练后得到。
13.可选地,将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息的类型,包括:将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息与每个文本信息模板之间的相似度值;若待分类文本信息与第一文本信息模板之间的相似度值小于或者等于第一预设阈值,且相似度值大于待分类文本信息与第二文本信息模板之间的相似度值,则将第一文本信息模板对应的类型确定待分类文本信息的类型。
14.可选地,还包括:统计预设时长内,确定出的任一类型的文本信息的数量;若数量大于第二预设阈值,则发送告警信息。
15.第三方面,本技术提供一种文本分类模型的训练装置,该装置包括:
16.获取模块,用于获取多条浏览器的历史弹窗内的文本信息。
17.处理模块,用于对每个文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量,对第一特征向量进行聚类,得到至少一个文本信息组;从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板;根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型。
18.可选地,处理模块,具体用于对每个文本信息进行分词处理,生成第一词袋;确定第一词袋中,任一第一词汇对应的第二特征向量;根据第二特征向量,确定每个文本信息对应的第一特征向量。
19.可选地,处理模块,具体用于获取第一词袋中的第一词汇的总数量;获取第一词袋中的每个第一词汇在多个文本信息中的出现频次,以及包含每个第一词汇的文本信息数量;根据第一词袋中的第一词汇的总数量、每个第一词汇在多个历史弹窗内的文本信息中的出现频次,以及包含每个第一词汇的文本信息数量,确定每个第一词汇分别对应的权重;
根据第一词袋中的每个第一词汇分别对应的权重,以及每个第一词汇对应的第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量。
20.可选地,处理模块,具体用于对每个文本信息模板进行分词处理,生成第二词袋;确定第二词袋中,任一第二词汇对应的第三特征向量;根据文本相似度算法和第三特征向量,对初始文本分类模型进行训练,得到文本分类模型。
21.可选地,处理模块,还用于对第二特征向量进行降维处理,得到降维后的第二特征向量。
22.相应的,处理模块,具体用于根据降维后的第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量。
23.可选地,处理模块,具体用于对每个历史弹窗内的文本信息进行预处理,得到预处理后的历史弹窗内的文本信息,以去除历史弹窗内的文本信息中包括的目标数据,目标数据包括如下类型的数据中的至少一种:数字、外语和符号;对预处理后的历史弹窗内的文本信息进行分词处理。
24.第四方面,本技术提供一种文本分类装置,包括:
25.获取模块,用于获取待分类文本信息,文本信息为浏览器的弹窗内的信息。
26.处理模块,用于对待分类文本信息进行分词处理,生成第三词袋。
27.处理模块,还用于将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息的类型,文本分类模型为通过多条浏览器的历史弹窗内的文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量,并对第一特征向量进行聚类,得到至少一个文本信息组,并从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板,并根据至少一个文本信息模板,对初始文本分类模型进行训练后得到。
28.可选地,处理模块,具体用于将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息与每个文本信息模板之间的相似度值;若待分类文本信息与第一文本信息模板之间的相似度值小于或者等于第一预设阈值,且相似度值大于待分类文本信息与第二文本信息模板之间的相似度值,则将第一文本信息模板对应的类型确定待分类文本信息的类型。
29.可选地,处理模块,还用于统计预设时长内,确定出的任一类型的文本信息的数量;若数量大于第二预设阈值,则发送告警信息。
30.第五方面,本技术提供一种电子设备,包括:至少一个处理器;以及与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器执行的指令,指令被至少一个处理器执行,以使至少一个处理器能够执行如第一方面或第一方面的可选方式的方法,或者,如第二方面或第二方面的可选方式的方法。
31.第六方面,本技术提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机执行指令,计算机执行指令被处理器执行时用于实现如第一方面或第一方面的可选方式的方法,或者,如第二方面或第二方面的可选方式的方法。
32.本技术提供的文本分类模型的训练方法、文本分类方法、装置和设备,通过获取多条浏览器的历史弹窗内的文本信息;对每个文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量;对第一特征向量进行聚类,得到至少一个文本信息组;
从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板;根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型,能够解决现有技术中无法对浏览器弹窗日志进行分析的问题,基于训练得到的文本分类模型对系统进行监测和分析,能够提高系统运维效率。
附图说明
33.图1为本技术提供的一种文本分类模型的应用场景的示意图;
34.图2为本技术提供的一种文本分类模型的训练方法的流程示意图;
35.图3为本技术提供的另一种文本分类模型的训练方法的流程示意图;
36.图4为本技术提供的一种文本分类方法的流程示意图;
37.图5为本技术提供的一种文本分类模型的训练装置的结构示意图;
38.图6为本技术提供的一种文本分类装置的结构示意图;
39.图7为本技术提供的一种电子设备的结构示意图。
40.通过上述附图,已示出本公开明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本公开构思的范围,而是通过参考特定实施例为本领域技术人员说明本公开的概念。
具体实施方式
41.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
42.随着信息化、数字化的不断深入,运维过程的智能化程度不断提升。日志数据作为互联网技术的重要输出,在监测、分析系统运行情况方面发挥着重要的作用。
43.现有技术中针对运维日志的分析主要是针对机器人的运行日志进行分析,缺少针对浏览器弹窗日志分析方法。浏览器弹窗日志为用户通过浏览器访问系统时,浏览器上弹出的弹窗内的文本信息。如果一段时间内,某一类型的弹窗日志数量激增或者产生类型不明的弹窗日志,则能够反映出系统可能存在故障。在统计不同类型的弹窗日志的数量之前,首先要解决的问题是如何对弹窗日志进行分类。如果能够训练得到一个分类模型,将采集到的新的弹窗日志输入该模型中,即可确定出该弹窗日志的类型,那么就能解决该问题。
44.本技术提供了一种文本分类模型的训练方法,该方法通过对多条浏览器的历史弹窗内的文本信息进行分析处理后,得到多个不同类型的目标文本信息,并对每个目标文本信息进行打标处理以形成多个训练样本,然后通过所得到的训练样本,对初始文本分类模型进行训练后得到文本分类模型。该模型能够用于对浏览器弹窗日志进行分类,进一步的,可以通过分析目标时间段内的分类情况,基于分析结果产生适宜的告警信息,降低系统运维过程中的人工参与度,减低运维难度,提高运维效率,可以对系统运行情况进行监测和分析,辅助系统故障定位。
45.图1为本技术提供的一种文本分类模型的应用场景的示意图,如图1所示,该应该场景包括至少一个第一电子设备11、第二电子设备12、第三电子设备13。第一电子设备11分
别与第二电子设备12、第三电子设备13连接。
46.其中,每个第一电子设备11均安装有目标应用程序,用户可以通过操作该目标应用程序访问部署在远端第二电子设备12上的系统。在访问远端系统时,若产生弹窗信息,弹窗信息将以浏览器弹窗的形式展示给用户。
47.第三电子设备13用于获取任一第一电子设备11对应的浏览器弹窗中的文本信息,并将其作为待识别文本信息输入到预先训练得到的文本分类模型,得到其对应的类型。
48.具体的,第三电子设备用于获取待分类文本信息,文本信息为浏览器的弹窗内的信息;对待分类文本信息进行分词处理,生成第三词袋;将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息的类型。
49.可选地,还包括第四电子设备14。第三电子设备13与第四电子设备14连接。
50.第三电子设备13还用于统计预设时长内,确定出的任一类型的文本信息的数量;若数量大于第二预设阈值,则向第四电子设备14发送告警信息。
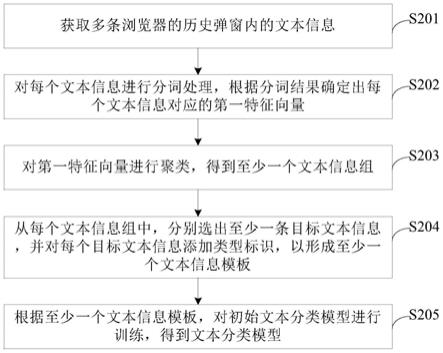
51.图2为本技术提供的一种文本分类模型的训练方法的流程示意图,该方法应用于电子设备,如图2所示,该方法包括:
52.s201、获取多条浏览器的历史弹窗内的文本信息。
53.浏览器的弹窗内的文本信息,即浏览器弹窗日志,是采集到的操作人员通过浏览器访问系统时,浏览器弹出的弹窗中的文本信息。该文本信息具体可以是中文文本。
54.电子设备可以通过物理存储介质和/或网络存储介质中获取浏览器的历史弹窗内的文本信息;也可以通过其交互界面或者其外部接口,接收用户输入的浏览器的历史弹窗内的文本信息。
55.示例性的,操作人员为某个账户信息办理缴费业务时,缴费成功时浏览器界面弹出的“恭喜您,缴费成功!”即为浏览器日志。
56.s202、对每个文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量。
57.电子设备可以采用任意一种适用的分词工具或方法对文本信息进行分词处理。
58.示例性的,电子设备采用结巴(jieba)分词工具对每条浏览器的历史弹窗内的文本信息进行分词处理,得到其对应的词袋。结巴分词工具是基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图;采用了动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的隐马尔可夫模型(hidden markov model,hmm)模型,使用了维特比(viterbi)算法。
59.进一步的,基于得到的分词结果将文本信息向量化表示,得到每条文本信息对应的向量。
60.s203、对第一特征向量进行聚类,得到至少一个文本信息组。
61.对于浏览器弹窗日志而言,适用于无监督的聚类训练,其具体能训练能得到多少个类别是未知的。
62.示例性的,电子设备采用具有噪声的基于密度的聚类方法(density-based spatial clustering of applications with noise,dbscan)。
63.dbscan可以对任意形状的稠密数据集进行聚类,相对的,k-means之类的聚类算法一般只适用于凸数据集;可以在聚类的同时发现异常点,对数据集中的异常点不敏感;其聚
类结果没有偏倚,相对的,k-means之类的聚类算法初始值对聚类结果有很大影响。
64.s204、从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板。
65.示例性的,从每个聚类得到的文本信息组中,随机选出至少一条作为目标文本信息,并添加唯一的类型信息,进而形成类型信息不同的多个训练样本。
66.s205、根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型。
67.示例性的,电子设备通过python中的gensim中的similarities.sparsematrixsimilarity算法训练得到相似度的模型,并基于该相似度模型,将进一步得到文本分类模型。
68.本技术通过获取多条浏览器的历史弹窗内的文本信息;对每个文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量;对第一特征向量进行聚类,得到至少一个文本信息组;从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板;根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型,能够训练得到用于对浏览器弹窗日志进行分类,解决了现有技术中无法对浏览器日志进行分类的问题。
69.图3为本技术提供的另一种文本分类模型的训练方法的流程示意图,该方法应用于电子设备,如图3所示,该方法包括:
70.s301、获取多条浏览器的历史弹窗内的文本信息。
71.s301与s201具有相同的技术特征,具体描述可参见s201,在此不做赘述。
72.s302、对每个历史弹窗内的文本信息进行预处理,得到预处理后的历史弹窗内的文本信息,以去除历史弹窗内的文本信息中包括的目标数据。
73.目标数据包括如下类型的数据中的至少一种:数字、外语和符号。
74.s303、对预处理后的历史弹窗内的文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量。
75.示例性的,电子设备采用结巴(jieba)分词工具对每条浏览器的历史弹窗内的文本信息进行分词处理,得到其对应的词袋。
76.在一种可能的实现方式中,对每个文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量,包括:对每个文本信息进行分词处理,生成第一词袋;确定第一词袋中,任一第一词汇对应的第二特征向量;根据第二特征向量,确定每个文本信息对应的第一特征向量。
77.通过该方法能够将每个文本信息所对应的词袋中的词汇向量化表示,便于对模型进行训练。
78.可选的,根据第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量,包括:获取第一词袋中的第一词汇的总数量;获取第一词袋中的每个第一词汇在多个文本信息中的出现频次,以及包含每个第一词汇的文本信息数量;根据第一词袋中的第一词汇的总数量、每个第一词汇在多个历史弹窗内的文本信息中的出现频次,以及包含每个第一词汇的文本信息数量,确定每个第一词汇分别对应的权重;根据第一词袋中的每个第一词汇分别对应的权重,以及每个第一词汇对应的第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量。
79.示例性的,通过信息检索与数据挖掘的常用加权技术term frequency
–
inverse document frequency,简称tf-idf基于第二特征向量,确定出每个历史弹窗内的文本信息对应的第一特征向量。其中,tf是词频(term frequency),idf是逆文本频率指数(inverse document frequency)。
80.可选的,在确定第一词袋中,任一第一词汇对应的第二特征向量之后,还包括:对第二特征向量进行降维处理,得到降维后的第二特征向量。
81.相应的,根据第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量,包括:根据降维后的第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量。
82.通过该方法,能够降低数据维度,减少数据量,提高电子设备运行效率,提升模型训练速度。
83.s304、对第一特征向量进行聚类,得到至少一个文本信息组。
84.s305、从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板。
85.s304、s305与s203、s204具有相同的技术特征,具体描述可参见s203、s204,在此不做赘述。
86.s306、根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型。
87.在一种可能的实现方式中,根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型包括:对每个文本信息模板进行分词处理,生成第二词袋;确定第二词袋中,任一第二词汇对应的第三特征向量;根据文本相似度算法和第三特征向量,对初始文本分类模型进行训练,得到文本分类模型。
88.示例性的,电子设备可以采用任意一种适用的分词工具或方法对文本信息模板进行分词处理。
89.示例性的,电子设备采用结巴(jieba)分词工具对每条文本信息模板进行分词处理,得到其对应的词袋。结巴分词工具是基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图;采用了动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的隐马尔可夫模型(hidden markov model,hmm)模型,使用了维特比(viterbi)算法。
90.示例性的,电子设备通过python中的gensim中的similarities.sparsematrixsimilarity算法训练得到相似度的模型,并基于该相似度模型,将进一步得到文本分类模型。
91.本技术在上述实施例的基础上,进一步的,通过对每个历史弹窗内的文本信息进行预处理,得到预处理后的历史弹窗内的文本信息,以去除历史弹窗内的文本信息中包括的目标数据,不仅能够去除掉文本信息中的干扰信息,提高模型训练的效率以及模型的准确性,还能够减少数据量,进一步的,通过对预处理后的历史弹窗内的文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量;对第一特征向量进行聚类,得到至少一个文本信息组;从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板,根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型,能够提高电子设备的运行效率。
92.图4为本技术提供的一种文本分类方法的流程示意图,该方法应用于电子设备,如图4所示,该方法包括:
93.s401、获取待分类文本信息。
94.文本信息为浏览器的弹窗内的信息。
95.电子设备可以通过物理存储介质和/或网络存储介质中获取待分类文本信息;也可以通过其交互界面或者其外部接口,接收用户输入的待分类文本信息。
96.示例性的,通过读取kafka获取待分类文本信息。kafka是一种分布式日志系统。
97.s402、对待分类文本信息进行分词处理,生成第三词袋。
98.电子设备可以采用任意一种适用的分词工具或方法对待分类文本信息进行分词处理。
99.示例性的,电子设备采用jieba分词工具对待分类文本信息进行分词处理,得到其对应的词袋。结巴分词工具是基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图;采用了动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的hmm模型,使用了viterbi算法。
100.可选地,在对待分类文本信息进行分词处理之前,还可以包括对对待分类文本信息进行预处理,得到预处理后的待分类文本信息,以去除待分类文本信息中包括的目标数据。
101.目标数据包括如下类型的数据中的至少一种:数字、外语和符号。
102.s403、将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息的类型。
103.其中,文本分类模型为通过多条浏览器的历史弹窗内的文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量,并对第一特征向量进行聚类,得到至少一个文本信息组,并从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板,并根据至少一个文本信息模板,对初始文本分类模型进行训练后得到。
104.在一种可能的实现方式中,将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息的类型,包括:将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息与每个文本信息模板之间的相似度值;若待分类文本信息与第一文本信息模板之间的相似度值小于或者等于第一预设阈值,且相似度值大于待分类文本信息与第二文本信息模板之间的相似度值,则将第一文本信息模板对应的类型确定待分类文本信息的类型文本信息模板对应的类型确定待分类文本信息的类型。
105.示例性的,将待分类文本信息输入预先训练的文本分类模型中,得到待分类文本信息与各文本信息模板之间的相似度值,若待分类文本信息与第一文本信息模板之间的相似度最高且大于或等于预设阈值δ,则判定该待分类文本信息与该第一文本信息模板的类型一致,则可以进一步的,向待分类文本信息添加与第一文本信息一样的类型标识;若待分类文本信息与第一文本信息模板之间的相似度最高且小于预设阈值δ,则判定该待分类文本信息不属于任一已知类型。
106.其中,预设阈值δ在实际使用过程中,可能根据实际情况进行设置,对此本技术不做限制。
107.可选地,将未识别出类型的待分类文本信息作为新的样本对预先训练得到的文本
分类模型进行补充训练,已更新该文本分类模型。
108.示例性的,存储未识别出类型的待分类文本信息,并实时监测或者周期性获取所存储的未识别出类型的待分类文本信息的数量,若数量达到预设数量,则将存储的未识别出类型的待分类文本信息处理后作为新的样本对预先训练得到的文本分类模型进行补充训练,已更新该文本分类模型。
109.还可以对未识别出类型的待分类文本信息添加特定类型标识,并统计存储的待分类文本信息中,添加该特定类型标识的待分类文本信息的数量,若数量达到预设数量,则将添加该特定类型标识的待分类文本信息处理后作为新的样本对预先训练得到的文本分类模型进行补充训练,已更新该文本分类模型。
110.可选的,该方法还包括:
111.s404、统计预设时长内,确定出的任一类型的文本信息的数量。
112.s405、若数量大于第二预设阈值,则发送告警信息。
113.在一种可能的实现方式中,若数量大于第二预设阈值,则发送告警信息,包括:若数量大于第二预设阈值,则根于预先存储的文本信息的类型与告警信息的对应关系,确定出于该类型文本信息对应的告警信息。
114.本技术通过获取待分类文本信息,文本信息为浏览器的弹窗内的信息;对待分类文本信息进行分词处理,生成第三词袋;将第三词袋输入预先训练的文本分类模型中,能够得到待分类文本信息的类型,进而还能够基于分类情况,通过统计预设时长内,确定出的任一类型的文本信息的数量;若数量大于第二预设阈值,则发送告警信息,能够实现对浏览器弹窗日志进行分类,进一步的,可以通过分析目标时间段内的分类情况,基于分析结果产生适宜的告警信息,降低系统运维过程中的人工参与度,减低运维难度,提高运维效率,可以对系统运行情况进行监测和分析,辅助系统故障定位。
115.图5为本技术提供的一种文本分类模型的训练装置的结构示意图,如图5所示,该装置包括:
116.获取模块51,用于获取多条浏览器的历史弹窗内的文本信息。
117.处理模块52,用于对每个文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量,对第一特征向量进行聚类,得到至少一个文本信息组;从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板;根据至少一个文本信息模板,对初始文本分类模型进行训练,得到文本分类模型。
118.可选地,处理模块52,具体用于对每个文本信息进行分词处理,生成第一词袋;确定第一词袋中,任一第一词汇对应的第二特征向量;根据第二特征向量,确定每个文本信息对应的第一特征向量。
119.可选地,处理模块52,具体用于获取第一词袋中的第一词汇的总数量;获取第一词袋中的每个第一词汇在多个文本信息中的出现频次,以及包含每个第一词汇的文本信息数量;根据第一词袋中的第一词汇的总数量、每个第一词汇在多个历史弹窗内的文本信息中的出现频次,以及包含每个第一词汇的文本信息数量,确定每个第一词汇分别对应的权重;根据第一词袋中的每个第一词汇分别对应的权重,以及每个第一词汇对应的第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量。
120.可选地,处理模块52,具体用于对每个文本信息模板进行分词处理,生成第二词袋;确定第二词袋中,任一第二词汇对应的第三特征向量;根据文本相似度算法和第三特征向量,对初始文本分类模型进行训练,得到文本分类模型。
121.可选地,处理模块52,还用于对第二特征向量进行降维处理,得到降维后的第二特征向量。
122.相应的,处理模块52,具体用于根据降维后的第二特征向量,确定每个历史弹窗内的文本信息对应的第一特征向量。
123.可选地,处理模块52,具体用于对每个历史弹窗内的文本信息进行预处理,得到预处理后的历史弹窗内的文本信息,以去除历史弹窗内的文本信息中包括的目标数据,目标数据包括如下类型的数据中的至少一种:数字、外语和符号;对预处理后的历史弹窗内的文本信息进行分词处理。
124.该文本分类模型的训练装置可以执行上述图2或图3所示的文本分类模型的训练方法,其内容和效果可参考方法实施例部分,对此不再赘述。
125.图6为本技术提供的一种文本分类装置的结构示意图,如图6所示,该装置包括:
126.获取模块61,用于获取待分类文本信息,文本信息为浏览器的弹窗内的信息。
127.处理模块62,用于对待分类文本信息进行分词处理,生成第三词袋。
128.处理模块62,还用于将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息的类型,文本分类模型为通过多条浏览器的历史弹窗内的文本信息进行分词处理,根据分词结果确定出每个文本信息对应的第一特征向量,并对第一特征向量进行聚类,得到至少一个文本信息组,并从每个文本信息组中,分别选出至少一条目标文本信息,并对每个目标文本信息添加类型标识,以形成至少一个文本信息模板,并根据至少一个文本信息模板,对初始文本分类模型进行训练后得到。
129.可选地,处理模块62,具体用于将第三词袋输入预先训练的文本分类模型中,得到待分类文本信息与每个文本信息模板之间的相似度值;若待分类文本信息与第一文本信息模板之间的相似度值小于或者等于第一预设阈值,且相似度值大于待分类文本信息与第二文本信息模板之间的相似度值,则将第一文本信息模板对应的类型确定待分类文本信息的类型。
130.可选地,处理模块62,还用于统计预设时长内,确定出的任一类型的文本信息的数量;若数量大于第二预设阈值,则发送告警信息。
131.该文本分类装置可以执行上述图4所示的文本分类方法,其内容和效果可参考方法实施例部分,对此不再赘述。
132.图7为本技术提供的一种电子设备的结构示意图,如图7所示,该电子设备包括:处理器71、存储器72;处理器71与存储器72通信连接。存储器72用于存储计算机程序。处理器71用于调用存储器72中存储的计算机程序,以实现上述方法实施例中的方法。
133.可选地,该电子设备还包括:收发器73,用于与其他设备实现通信。
134.该电子设备可以执行上述的文本分类模型的训练方法或文本分类方法,其内容和效果可参考方法实施例部分,对此不再赘述。
135.本技术还提供了一种计算机可读存储介质,计算机可读存储介质中存储有计算机执行指令,计算机执行指令被处理器执行时用于实现上述文本分类模型的训练方法。
136.该计算机可读存储介质所存储的计算机执行指令被处理器执行时能实现上述文本分类模型的训练方法,其内容和效果可参考方法实施例部分,对此不再赘述。
137.本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本技术旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求书指出。应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求书来限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
