1.本发明涉及中央空调控制技术领域,特别涉及一种基于多智能体深度强化学习的中央空调控制方法。
背景技术:
2.据统计,在建筑物总能耗中,中央空调系统能耗占比甚至超过50%,其中冷机和冷却水系统的能耗又是中央空调能耗的重要组成部分,因此,冷机和冷却水系统的优化控制对降低整个中央空调系统能耗甚至是建筑总能耗尤为重要。
3.目前,在当前中央空调系统的控制方法中,最优的控制方法主要包含基于规则的控制、基于模型的控制以及无模型的控制等。基于规则的控制往往是静态的,控制规则根据工程师以及设备管理员的经验确定,适用范围和优化程度十分有限。基于模型的方法需要大量的历史数据和传感器信息,以建立精确的中央空调模型,但是该方法通常缺乏较好的鲁棒性,同时并不适用于缺乏历史数据和传感器的旧建筑群。为避免建立准确数学模型,无模型的控制方法已经被采用,传统的无模型控制方法需要对状态和动作进行离散化,导致动作空间较大以及训练时间较长,算法泛化能力下降,无法针对复杂问题进行求解。
4.因此该问题亟待解决。
技术实现要素:
5.为了克服上述现有技术的不足,本发明提供了一种基于多智能体深度强化学习的中央空调控制方法。
6.为达到上述目的,本发明解决其技术问题所采用的技术方案是:一种基于多智能体深度强化学习的中央空调控制方法,根据当前室内需求冷负荷和室外湿球温度对中央空调系统中冷机、冷却水泵和冷却水塔风扇的启停状态和工作参数进行无模型优化控制,包括冷机运行顺序控制,以及冷却水泵和冷却水塔风扇工作频率的智能体优化控制。
7.作为优选,所述中央空调系统中冷机、冷却水泵和冷却水塔依次相连、成组设置,所述冷机顺序控制通过顺序控制器实现,所述冷却水泵和冷却水塔风扇工作频率的智能体优化控制分别通过一个强化学习控制器实现。
8.作为优选,包括步骤如下:
9.a1.由电子温度计记录室外湿球温度;
10.a2.通过能耗软件energyplus模拟仿真求得当前室内需求冷负荷;
11.a3.顺序控制器根据当前室内需求冷负荷确定冷机开启的台数;
12.a4.强化学习控制器接收当前状态信息后,对所接收的数据信息建立环境模型,并根据环境模型提供最优策略。
13.作为优选,所述步骤a2中,用energyplus对当前房间整体建模,输入当前室内干球温度、室外干球温度、室内湿球温度和室外湿球温度,其中cls代表当前室内需求冷负荷,t代表当前室内干球温度、室外干球温度、室内湿球温度和室外湿球温度的集合,model
room
代
表当前房间模型,输出cls={t,model
room
}。
14.作为优选,所述步骤a3中,顺序控制器进行阈值计算和动作执行,其中thresholdn代表阈值,n(0,1,2,3,
…
)代表冷机开启数量,refrigerating capacit代表单个冷机额定制冷量,thresholdn=n
×
refrigerating capacity,顺序控制器实时计算cls落入的thresholdn到threshold
n 1
的范围,始终维持n台冷机处于开启状态,当n=0时,顺序控制器关闭所有冷机,仅靠冷水水泵和冷却水塔风扇工作来带走室内热量。
15.作为优选,所述步骤a4中,两个强化学习控制器分别作为控制冷却水泵和冷却水塔风扇工作频率的智能体,进行多智能体深度强化学习(madrl)并构建神经网络,神经网络包括两个全连接层和回放记忆单元,输入层为当前室内需求冷负荷和室外湿球温度,将中间层与所有可能的动作进行全连接,输出层为当前室内需求冷负荷和室外湿球温度下所有动作的值估计,控制冷却水泵工作频率的智能体输出的动作是冷却水泵所有能达到的频率,控制冷却水塔风扇工作频率的智能体输出的动作是冷却水塔风扇所有能达到的频率,回放记忆单元用于记录所有样本(s
t
,a
t
,r
t
,s
t 1
),其中s
t
表示当前室内需求冷负荷和室外湿球温度,a
t
表示当前室内需求冷负荷和室外湿球温度状态下冷却水泵和冷却水塔风扇的工作频率,s’表示在s
t’状态下执行动作a
t
后迁移到的下一个状态,r
t
表示在当前状态s
t’下执行动作a
t
得到的立即回报。
16.作为优选,所述步骤a4中,两个强化学习控制器将冷却水泵和冷却水塔风扇工作频率的控制问题建模为两个马尔科夫决策过程(mdp)模型,并定义其中的状态、动作以及奖赏函数如下:
17.b1.状态,用s表示,其中c
l
s代表当前室内需求冷负荷,t
wet
代表当前室外湿球温度,两个智能体的当前状态一致,用s来表示,s={cls,t
wet
};
18.b2.动作,用a表示,其中f
pump
代表冷却水泵的频率,f
tower
代表冷却水塔风扇的频率,a
pump
=f
pummp
;a
tower
=f
tower
;
19.b3.奖赏函数,用r表示,其中p
chiller
代表冷机功耗,p
tower
代表冷却水塔风扇功耗,p
pump
代表冷却水泵功耗,
20.作为优选,所述步骤a4中,强化学习控制器建立值函数回报模型,设r(s,a)表示在状态s下采用动作a的回报值,值函数q(s,a)是关于r(s,a)的期望,则q(s,a)=e[r(s,a)]。
[0021]
作为优选,所述步骤a4中,强化学习控制器通过深度q学习(deep q network或dqn)算法求解最优策略,算法训练流程如下:
[0022]
c1.初始化记忆回放单元,容量是n,用于储存训练的样本;
[0023]
c2.初始化当前值网络,随机初始化权重参数ω,初始化目标值网络,结构以及初始化权重与当前值网络相同;
[0024]
c3.将室内需求冷负荷和室外湿球温度通过当前值网络,得到任意状态s下的q(s,a),通过当前值网络计算出值函数后,使用∈greedy策略来选择动作a,每一次状态转移即做出动作记为一个时间步t,将每个时间步得到的数据(s,a,r,s
′
)存入回放记忆单元;
[0025]
c4.定义一个loss function:
[0026]
l(ω)=e[(r γmaxa′
q(s
′
,a
′
;ω-)-q(s,a;ω))2];
[0027]
c5.从回放记忆单元中随机抽取一个(s,a,r,s’),将(s,a,r,s’)分别传给当前值
网络,目标值网络和l(ω),对l(ω)关于ω使用随机梯度下降法进行更新,其更新公式为:
[0028]
作为优选,包括整体算法训练流程如下:
[0029]
d1.在当前时间步t,根据实时冷负荷进行冷机启停控制;
[0030]
d2.观测环境状态s
t
,记录实时冷负荷、室外湿球温度等数据;
[0031]
d3.无模型方法给定控制动作a
t
,使用贪心策略选取当前q值最大的动作a
t
;
[0032]
d4.系统执行控制动作,获得下一个环境状态s
t 1
,计算当前动作下制冷性能系数,并将其作为强化学习算法中的奖赏值r
t
;
[0033]
d5.多智能体深度强化学习算法训练,执行参数更新,将样本(s
t
,a
t
,r
t
,s
t 1
)存储至经验池,并从经验池中随机采样,执行算法训练更新网络参数;
[0034]
d6.结束当前时间步t,开始下一个时间步t 1。
[0035]
由于上述技术方案的运用,本发明与现有技术相比具有下列有益效果:
[0036]
1.本控制方法采用的多智能体深度强化学习,即在传统的强化学习基础上引入多个智能体以及神经网络,解决了强化学习在单个智能体收敛速度较慢的问题和高维状态空间的情况下逐一计算并存储状态-动作值而导致的维度灾难问题,尤其擅长应用在系统内部存在多个协同的控制器方面,根据当前室内需求冷负荷和室外湿球温度将冷却水泵和冷却水塔风扇工作频率的控制问题建模为一个马尔可夫决策过程模型,定义损失函数并对其用梯度下降法进行更新,求解出冷却水泵和冷却水塔风扇工作频率控制的最优策略;
[0037]
2.本控制方法无需在实际部署过程中建立准确的中央空调系统模型,只需使用单个代理即可分别控制冷却水泵和冷却水塔风扇工作频率;
[0038]
3.本控制方法能够依靠少量的历史数据,在短时间内训练出一个高效准确的控制策略,降低不必要的制冷量,减少冷机、冷却水泵和冷却水塔风扇的工作负荷,提高使用寿命并降低故障率,使整个中央空调系统能耗甚至建筑总能耗大大降低。
附图说明
[0039]
图1是本发明提出的一种基于多智能体深度强化学习的中央空调控制方法的一种实施例的中央空调系统中冷机、冷却水泵和冷却水塔的布局示意图。
[0040]
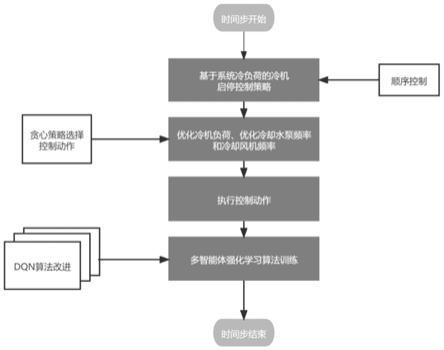
图2是本发明提出的一种基于多智能体深度强化学习的中央空调控制方法的一种实施例的工作流程图。
[0041]
图3是本发明提出的一种基于多智能体深度强化学习的中央空调控制方法的一种实施例中顺序控制器进行阈值计算和动作执行的逻辑流程图。
[0042]
图4是本发明提出的一种基于多智能体深度强化学习的中央空调控制方法的一种实施例中强化学习控制器进行深度q学习算法训练的流程图。
[0043]
图5是本发明提出的一种基于多智能体深度强化学习的中央空调控制方法的一种实施例中整体算法训练的流程图。
具体实施方式
[0044]
下面结合具体实施例,对本发明的内容做进一步的详细说明:
[0045]
结合图1至图5,本实施例是一种基于多智能体深度强化学习的中央空调控制方法,根据当前室内需求冷负荷和室外湿球温度对中央空调系统中冷机、冷却水泵和冷却水塔风扇的启停状态和工作参数进行无模型优化控制,包括冷机运行顺序控制,以及冷却水泵和冷却水塔风扇工作频率的智能体优化控制。
[0046]
如图1所示,中央空调系统中冷机、冷却水泵和冷却水塔依次相连、成组设置,如图2所示,冷机顺序控制通过顺序控制器实现,冷却水泵和冷却水塔风扇工作频率的智能体优化控制分别通过一个强化学习控制器实现。
[0047]
本实施例包括步骤如下:
[0048]
a1.由电子温度计记录室外湿球温度;
[0049]
a2.通过能耗软件energyplus模拟仿真求得当前室内需求冷负荷;
[0050]
a3.顺序控制器根据当前室内需求冷负荷确定冷机开启的台数;
[0051]
a4.强化学习控制器接收当前状态信息后,对所接收的数据信息建立环境模型,并根据环境模型提供最优策略。
[0052]
步骤a2中,用energyplus对当前房间整体建模,输入当前室内干球温度、室外干球温度、室内湿球温度和室外湿球温度,其中cls代表当前室内需求冷负荷,t代表当前室内干球温度、室外干球温度、室内湿球温度和室外湿球温度的集合,model
room
代表当前房间模型,输出cls={t,model
room
}。
[0053]
如图3所示,步骤a3中,顺序控制器进行阈值计算和动作执行,其中thresholdn代表阈值,n(0,1,2,3,
…
)代表冷机开启数量,refrigerating capacit代表单个冷机额定制冷量,thresholdn=n
×
refrigerating capacity,顺序控制器实时计算cls落入的thresholdn到threshold
n 1
的范围,始终维持n台冷机处于开启状态,当n=0时,顺序控制器关闭所有冷机,仅靠冷水水泵和冷却水塔风扇工作来带走室内热量。
[0054]
步骤a4中,两个强化学习控制器分别作为控制冷却水泵和冷却水塔风扇工作频率的智能体,进行多智能体深度强化学习(madrl)并构建神经网络,神经网络包括两个全连接层和回放记忆单元,输入层为当前室内需求冷负荷和室外湿球温度,将中间层与所有可能的动作进行全连接,输出层为当前室内需求冷负荷和室外湿球温度下所有动作的值估计,控制冷却水泵工作频率的智能体输出的动作是冷却水泵所有能达到的频率,控制冷却水塔风扇工作频率的智能体输出的动作是冷却水塔风扇所有能达到的频率,回放记忆单元用于记录所有样本(s
t
,a
t
,r
t
,s
t 1
),其中s
t
表示当前室内需求冷负荷和室外湿球温度,a
t
表示当前室内需求冷负荷和室外湿球温度状态下冷却水泵和冷却水塔风扇的工作频率,s’表示在s
t’状态下执行动作a
t
后迁移到的下一个状态,r
t
表示在当前状态s
t’下执行动作a
t
得到的立即回报。
[0055]
步骤a4中,两个强化学习控制器将冷却水泵和冷却水塔风扇工作频率的控制问题建模为两个马尔科夫决策过程(mdp)模型,并定义其中的状态、动作以及奖赏函数如下:
[0056]
b1.状态,用s表示,其中c
l
s代表当前室内需求冷负荷,t
wet
代表当前室外湿球温度,两个智能体的当前状态一致,用s来表示,s={cls,t
wet
};
[0057]
b2.动作,用a表示,其中f
pump
代表冷却水泵的频率,f
tower
代表冷却水塔风扇的频
率,a
pump
=f
pump
;a
tower
=f
tower
;
[0058]
b3.奖赏函数,用r表示,其中p
chiller
代表冷机功耗,p
tower
代表冷却水塔风扇功耗,p
pump
代表冷却水泵功耗,
[0059]
步骤a4中,强化学习控制器建立值函数回报模型,设r(s,a)表示在状态s下采用动作a的回报值,值函数q(s,a)是关于r(s,a)的期望,则q(s,a)=e[r(s,a)]。
[0060]
如图4所示,步骤a4中,强化学习控制器通过深度q学习(deep q network或dqn)算法求解最优策略,算法训练流程如下:
[0061]
c1.初始化记忆回放单元,容量是n,用于储存训练的样本;
[0062]
c2.初始化当前值网络,随机初始化权重参数ω,初始化目标值网络,结构以及初始化权重与当前值网络相同;
[0063]
c3.将室内需求冷负荷和室外湿球温度通过当前值网络,得到任意状态s下的q(s,a’,通过当前值网络计算出值函数后,使用∈-greedy策略来选择动作a,每一次状态转移即做出动作记为一个时间步t,将每个时间步得到的数据(s,a,rs’)存入回放记忆单元;
[0064]
c4.定义一个loss function:
[0065]
l(ω)=e[(r γmaxa,q(s
′
,a
′
;ω-)-q(s,a;ω))2];
[0066]
c5.从回放记忆单元中随机抽取一个(s,a,r,s’),将(s,a,r,s’)分别传给当前值网络,目标值网络和l(ω),对l(ω)关于ω使用随机梯度下降法进行更新,其更新公式为:
[0067]
如图5所示,本实施例包括整体算法训练流程如下:
[0068]
d1.在当前时间步t,根据实时冷负荷进行冷机启停控制;
[0069]
d2.观测环境状态s
t
,记录实时冷负荷、室外湿球温度等数据;
[0070]
d3.无模型方法给定控制动作a
t
,使用贪心策略选取当前q值最大的动作a
t
;
[0071]
d4.系统执行控制动作,获得下一个环境状态s
t 1
,计算当前动作下制冷性能系数,并将其作为强化学习算法中的奖赏值r
t
;
[0072]
d5.多智能体深度强化学习算法训练,执行参数更新,将样本(s
t
,a
t
,r
t
,s
t 1
)存储至经验池,并从经验池中随机采样,执行算法训练更新网络参数;
[0073]
d6.结束当前时间步t,开始下一个时间步t 1。
[0074]
本发明的创新之处如下:
[0075]
1.本控制方法采用的多智能体深度强化学习,即在传统的强化学习基础上引入多个智能体以及神经网络,解决了强化学习在单个智能体收敛速度较慢的问题和高维状态空间的情况下逐一计算并存储状态-动作值而导致的维度灾难问题,尤其擅长应用在系统内部存在多个协同的控制器方面,根据当前室内需求冷负荷和室外湿球温度将冷却水泵和冷却水塔风扇工作频率的控制问题建模为一个马尔可夫决策过程模型,定义损失函数并对其用梯度下降法进行更新,求解出冷却水泵和冷却水塔风扇工作频率控制的最优策略;
[0076]
2.本控制方法无需在实际部署过程中建立准确的中央空调系统模型,只需使用单个代理即可分别控制冷却水泵和冷却水塔风扇工作频率;
[0077]
3.本控制方法能够依靠少量的历史数据,在短时间内训练出一个高效准确的控制策略,降低不必要的制冷量,减少冷机、冷却水泵和冷却水塔风扇的工作负荷,提高使用寿命并降低故障率,使整个中央空调系统能耗甚至建筑总能耗大大降低。
[0078]
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并加以实施,并不能以此限制本发明的保护范围,凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
