1.本技术涉及智能机器人技术领域,更具体地说,涉及一种催收机器人交互方法、装置、催收机器人及存储介质。
背景技术:
2.随着人工智能的快速发展,智能催收机器人也应运而生,成为众多金融企业改善催收现状的新的选择对象。
3.目前,现有的大多催收机器人大都是基于模板的催收流程,具体是事先准备好一个对话模板库,对客户输入的句子,找到匹配的问句模板,然后,按照对应的应答模板生成应答,这种实现方式对于客户的简单回答能够进行识别并进行回复,但是,对于客户在口语中出现的结巴话语、说话顺序不对或者句子长度很长等情况时,则会导致客户的句子不在模板匹配范围内,此时,催收机器人则会无法回复或者会出现回复不正确。
4.综上所述,如何使催收机器人准确地进行回复,是目前本领域技术人员亟待解决的技术问题。
技术实现要素:
5.有鉴于此,本技术的目的是提供一种催收机器人交互方法、装置、催收机器人及存储介质,用于使催收机器人准确地进行回复。
6.为了实现上述目的,本技术提供如下技术方案:
7.一种催收机器人交互方法,包括:
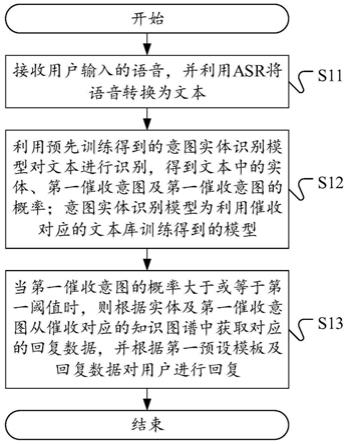
8.接收用户输入的语音,并利用asr将所述语音转换为文本;
9.利用预先训练得到的意图实体识别模型对所述文本进行识别,得到所述文本中的实体、第一催收意图及所述第一催收意图的概率;所述意图实体识别模型为利用催收对应的文本库训练得到的模型;
10.当所述第一催收意图的概率大于或等于第一阈值时,则根据所述实体及所述第一催收意图从催收对应的知识图谱中获取对应的回复数据,并根据第一预设模板及所述回复数据对所述用户进行回复。
11.优选的,所述意图实体识别模型包括:
12.第一输入层,用于输入所述文本;
13.第一embedding层,用于将所述文本进行向量化表示,以得到第一多维矩阵;
14.intent label attention层,用于从所述第一多维矩阵中提取不同类型的第一催收意图;
15.slot label attention层,用于从所述第一多维矩阵中提取实体特征;
16.第一ln层,用于对所述intent label attention层提取的各类型的第一催收意图进行标准化;
17.第二ln层,用于对所述slot label attention层提取的实体特征进行标准化;
18.所述拼接层,用于对所述第一ln层和所述第二ln层输出的结果向量进行拼接;
19.crf层,用于从拼接结果中查找实体;
20.第一softmax层,用于根据所述拼接结果计算各类型的第一催收意图的概率;
21.第一输出层,用于输出实体、概率最大对应的第一催收意图及其概率。
22.优选的,在利用预先训练得到的意图实体识别模型对所述文本进行识别之前,还包括:
23.利用预先训练得到的意图识别模型对所述文本进行识别,得到所述文本的第二催收意图及所述第二催收意图的概率;所述意图识别模型为利用所述文本库训练得到的模型;
24.判断所述第二催收意图的概率是否大于或等于第二阈值;
25.若是,则执行所述利用预先训练得到的意图实体识别模型对所述文本进行识别的步骤。
26.优选的,若所述第二催收意图的概率未大于或等于所述第二阈值,则还包括:
27.判断所述第二催收意图的概率是否大于或等于第三阈值;所述第三阈值小于所述第二阈值;
28.若是,则对所述文本进行分词,从分词结果中提取所述文本中的实体,并根据所述文本中的实体进行回复,以向所述用户进行确认;
29.若否,则确认所述第二催收意图为闲聊意图,并进入闲聊模式。
30.优选的,所述意图识别模型包括:
31.第二输入层,用于输入所述文本;
32.第二embedding层,用于将所述文本进行向量化表示,以得到第二多维矩阵;
33.bi-gru层,用于从所述第二多维矩阵中进行文本特征提取,得到一次文本特征提取结果;
34.attention层,用于从所述一次文本特征提取结果中进行文本特征提取,得到二次文本特征提取结果;
35.第二softmax层,用于根据所述二次文本特征提取结果计算各类型的第二催收意图的概率;
36.第二输出层,用于输出概率最大对应的第二催收意图及其概率。
37.优选的,若所述第一催收意图的概率未大于或等于所述第一阈值,则还包括:
38.根据所述意图实体识别模型得到的实体,按照第二预设模板进行回复,以向所述用户进行确认。
39.优选的,根据所述实体及所述第一催收意图从催收对应的知识图谱中获取对应的回复数据,包括:
40.将所述实体、所述第一催收意图、历史实体及历史催收意图进行特征化,以得到最终特征,并根据所述最终特征从催收对应的知识图谱中获取对应的回复数据。
41.一种催收机器人交互装置,包括:
42.接收模块,用于接收用户输入的语音,并利用asr将所述语音转换为文本;
43.第一识别模块,用于利用预先训练得到的意图实体识别模型对所述文本进行识别,得到所述文本中的实体、第一催收意图及所述第一催收意图的概率;所述意图实体识别
模型为利用催收对应的文本库训练得到的模型;
44.回复模块,用于当所述第一催收意图的概率大于或等于第一阈值时,则根据所述实体及所述第一催收意图从催收对应的知识图谱中获取对应的回复数据,并根据第一预设模板及所述回复数据对所述用户进行回复。
45.一种催收机器人,包括:
46.存储器,用于存储计算机程序;
47.处理器,用于执行所述计算机程序时实现如上述任一项所述的催收机器人交互方法的步骤。
48.一种可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上述任一项所述的催收机器人交互方法的步骤。
49.本技术提供了一种催收机器人交互方法、装置、催收机器人及存储介质,其中,该方法包括:接收用户输入的语音,并利用asr将语音转换为文本;利用预先训练得到的意图实体识别模型对文本进行识别,得到文本中的实体、第一催收意图及第一催收意图的概率;意图实体识别模型为利用催收对应的文本库训练得到的模型;当第一催收意图的概率大于或等于第一阈值时,则根据实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据,并根据第一预设模板及回复数据对用户进行回复。
50.本技术公开的上述技术方案,利用asr将用户输入的语音转换为文本,并利用预先训练得到意图识别模型识别文件中的实体、文本的第一催收意图以及第一催收意图的概率,当第一催收意图的概率大于或等于第一阈值时,则表明确实属于催收意图,此时,则根据利用意图识别模型识别得到的实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据,并基于所获取的回复数据集采用第一预设模板来对用户进行回复,通过上述过程可知,本技术基于rasa框架及知识图谱实现催收机器人与用户的交互,并基于深度学习的方法来从语音转换得到的文本中识别得到实体和用户的催收意图且基于识别得到的实体和意图进行催收回复,从而实现准确地进行催收回复,并提高对话能力。
附图说明
51.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
52.图1为本技术实施例提供的一种催收机器人交互方法的流程图;
53.图2为本技术实施例提供的意图实体识别模型的结构示意图;
54.图3为本技术实施例提供的另一种催收机器人交互方法的流程图;
55.图4为本技术实施例提供的意图识别模型的结构示意图;
56.图5为本技术实施例提供的gru的结构图;
57.图6为本技术实施例提供的attention层的结构示意图;
58.图7为rasa的框架图;
59.图8为本技术实施例提供的一种催收机器人交互装置的结构示意图;
60.图9为本技术实施例提供的一种催收机器人的结构示意图。
具体实施方式
61.目前,现有催收机器人大都是基于模板的催收流程,具体是实现准备好一个对话模板库,对于客户输入的句子,催收机器人从对话模板库中找到与客户输入的句子匹配的问句模板,并按照对应的应答模板生成应答,这种实现方式对于客户的简单回答能够进行简单识别并进行回复,但是,对于客户在口语中出现的结巴话语、说话顺序不对、句子长度很长,或者asr(automatic speech recognition,自动语音识别技术)未能正确识别文字等情况时,则会导致客户的句子不在模板匹配范围内,此时,催收机器人则无法进行回复或会出现回复不正确。
62.为此,本技术提供一种催收机器人交互方法、装置、催收机器人及存储介质,用于使催收机器人准确地进行回复。
63.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
64.参见图1,其示出了本技术实施例提供的一种催收机器人交互方法的流程图,本技术实施例提供的一种催收机器人交互方法,可以包括:
65.s11:接收用户输入的语音,并利用asr将语音转换为文本。
66.需要说明的是,本技术所提供的催收机器人交互方法可以应用于催收机器人,也即催收机器人交互方法的执行主体可以为催收机器人。
67.在催收机器人交互过程中,催收机器人可以接收用户所输出的语音,并利用asr将所接收到的用户输入的语音转换为文本。
68.s12:利用预先训练得到的意图实体识别模型对文本进行识别,得到文本中的实体、第一催收意图及第一催收意图的概率;意图实体识别模型为利用催收对应的文本库训练得到的模型。
69.在步骤s11的基础上,催收机器人可以利用预先训练得到的意图实体识别模型来对用户所输入的语音进行转换得到的文本进行识别,以得到文本中的实体、第一催收意图以及第一催收意图的概率。其中,这里提及的实体指的是现实世界中的事物,比如人、地名、概念、公司等,这里提及的第一催收意图具体可以包括承诺还款、协商还款等。得到第一催收意图的概率是为了便于基于所得概率确定利用意图实体识别模型所识别得到的文本的第一催收意图是催收的意图、而非是闲聊意图等非催收的意图的可能性,概率越大,则表明第一催收意图是催收的意图的可能性越大。
70.其中,意图实体识别模型是利用催收对应的文本库对第一初始模型进行训练得到的模型,其中,催收对应的文本库中具体可以包括催收对应的用户语音通过利用asr转换得到的文本数据、文本数据中的实体、各类型的第一催收意图等,以利用催收对应的文本库中的文本数据、文本数据中的实体、各类型的第一催收意图对第一初始模型进行训练而得到意图实体识别模型。
71.通过预先训练得到意图实体识别模型及利用该意图实体识别模型来对用户输入的语音转换得到的文本进行识别的方式可以实现利用深度学习的方式来对语音转换得到的文本进行识别,以提高识别的准确性和可靠性,且通过深度学习来对语音转换得到的文
本进行识别得到文本中的实体、第一催收意图及第一催收意图的概率的方式可以便于基于实体、第一催收意图来进行语音回复,以提高催收机器人进行催收回复的准确性。
72.s13:当第一催收意图的概率大于或等于第一阈值时,则根据实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据,并根据第一预设模板及回复数据对用户进行回复。
73.在步骤s12的基础上,将所得到的第一催收意图的概率与第一阈值进行比较,其中,第一阈值具体可以为0.8,当然,也可以根据实际需要而对其进行调整。若第一催收意图的概率大于或等于第一阈值,则表明对用户所输入的语音进行转换得到的文本极有可能是催收的意图,也即若第一催收意图的概率大于或等于第一阈值,则催收机器人即会将用户输入的语音转换得到的文本判断为催收的意图,此时,催收机器人才会根据文本中的实体及文本的第一催收意图采取相应的回复策略,并根据文本中的实体及文本的第一催收意图从催收对应的知识图谱中获取与实体及语音的第一催收意图对应的回复数据(即进入意图与实体匹配流程),从而基于实体、概率大于或等于第一阈值的第一催收意图、催收对应的知识图谱来提高回复数据获取的准确性。催收机器人在获取对应的回复数据之后,可以按照所采取的回复策略,利用第一预设模板并基于回复数据来对用户进行回复,以便于用户基于催收机器人的回复进行语音输入等操作,从而实现对用户的催收。需要说明的是,若第一催收意图的概率大于或等于第一阈值,则催收机器人会将此轮文本中的实体及文本的第一催收意图保存在rasa框架的追踪器中,以便于后续进行使用。通过上述过程可知,本技术通过rasa框架及知识图谱相结合的方式来实现催收机器人交互,以便于提高催收交互效果,并便于显著增加催收机器人的聊天水平。
74.其中,知识图谱是谷歌及其服务使用的知识库,通过各种来源收集的信息来增强其搜索引擎的结果,知识图谱本质是语义网络的知识库。催收对应的知识图谱中存储有实体、催收意图对应的催收回复数据等,以便于催收机器人基于催收对应的知识图谱来对用户进行智能催收。需要说明的是,在本技术中,催收对应的知识图谱具体可以以neo4j数据库的形式进行存在,其是一个高性能的nosql(泛指非关系型的数据库)图形数据库,它将结构化数据存储在网络中而并不是表中。而且neo4j是用于构造知识谱图的工具,工作内容主要是在数据收集阶段和图谱设计阶段,数据收集阶段主要是从非结构化数据中提取出结构化的信息,比如从网页文本中提取实体信息和实体间的关系,图谱设计阶段。本技术考虑使用neo4j数据库,通过三元组的形式来进行存储,以人物为节点,金额、时间等作为节点属性进行连接。
75.本技术公开的上述技术方案,利用asr将用户输入的语音转换为文本,并利用预先训练得到意图识别模型识别文件中的实体、文本的第一催收意图以及第一催收意图的概率,当第一催收意图的概率大于或等于第一阈值时,则表明确实属于催收意图,此时,则根据利用意图识别模型识别得到的实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据,并基于所获取的回复数据集采用第一预设模板来对用户进行回复,通过上述过程可知,本技术基于rasa框架及知识图谱实现催收机器人与用户的交互,并基于深度学习的方法来从语音转换得到的文本中识别得到实体和用户的催收意图且基于识别得到的实体和意图进行催收回复,从而实现准确地对用户的语音进行识别,并准确地进行催收回复。
76.参见图2,其示出了本技术实施例提供的意图实体识别模型的结构示意图。本技术实施例提供的一种催收机器人交互方法,意图实体识别模型可以包括:
77.第一输入层,用于输入文本;
78.第一embedding(嵌入)层,用于将文本进行向量化表示,以得到第一多维矩阵;
79.intent label attention层,用于从第一多维矩阵中提取不同类型的第一催收意图;
80.slot label attention层,用于从第一多维矩阵中提取实体特征;
81.第一ln层(layer normalization,层归一化),用于对intent label attention层提取的各类型的第一催收意图进行标准化;
82.第二ln层,用于对slot label attention层提取的实体特征进行标准化;
83.拼接层,用于对第一ln层和第二ln层输出的结果向量进行拼接;
84.crf(conditional random field,条件随机场)层,用于从拼接结果中查找实体;
85.第一softmax层,用于根据拼接结果计算各类型的第一催收意图的概率;
86.第一输出层,用于输出实体、概率最大对应的第一催收意图及其概率。
87.在本技术中,意图实体识别模型可以包括第一输入层、第一embedding层、intent label attention层、slot label attention层、第一ln层、第二ln层、拼接层、crf层、第一softmax层、第一输出层。其中,转换得到的文本经过第一输入层到达第一embedding层,第一embedding层将文本进行向量化表示,并将第一向量化表示结果从高维稀疏矩阵转换为低维稠密的第一多维矩阵,以方便表示和计算,此时,所得到的第一多维矩阵会分别进入到intent label attention层和slot label attention层这两个不同的attention层中,其中,intent label attention层用于从第一多维矩阵中提取不同类型的第一催收意图(具体即为提取意图类别),slot label attention层用于从第一多维矩阵中提取实体特征。intent label attention层后面接入第一ln层,用于对intent label attention层提取的各类型的第一催收意图进行标准化,slot label attention层后面接入第二ln层,用于对slot label attention层提取的实体特征进行标准化。需要说明的是,在此处不使用batch normalization(bn,批量标准化)的原因时因为后者在计算归一化统计量时计算的样本数太少了,而且bn时取不同样本的同一个特征,而ln取的是同一个样本的不同特征,ln得到的模型更稳定且能起到正则化的作用,其中,ln的计算公式如下:
[0088][0089][0090][0091]
其中,a表示神经网络的节点,h表示隐藏层中节点的数量,l为网络的层数,ε为很小的数,防止分母为零,通过统计量μ和σ得到归一化的值
[0092]
经过intent label attention层、slot label attention层这两个attention层以及第一ln层、第二ln层这两个ln层之后,输出结果向量会重新在拼接层进行拼接,拼接结果随后进入到crf层中,以用于在序列中查找实体(具体即在序列中查找实体),后接第一softmax层,根据拼接结果计算各类型的第一催收意图的概率,最后第一输出层输出实体、概率最大对应的第一催收意图及其概率。
[0093]
需要说明的是,第一初始模型的结构与意图实体识别模型的结构类似,在此不再赘述。
[0094]
通过上述可知,在意图实体识别模型中除第一输入层和第一输出层之外,之间的各层均是用于从文本中进行特征提取。而且通过双attention层 crf结构的网络模型,可以同时完成意图识别和实体识别任务,以提高任务识别效率,并提高识别的准确性。
[0095]
参见图3,其示出了本技术实施例提供的另一种催收机器人交互方法的流程图。本技术实施例提供的一种催收机器人交互方法,在利用预先训练得到的意图实体识别模型对文本进行识别之前,还可以包括:
[0096]
利用预先训练得到的意图识别模型对文本进行识别,得到文本的第二催收意图及第二催收意图的概率;意图识别模型为利用催收对应的文本库训练得到的模型;
[0097]
判断第二催收意图的概率是否大于或等于第二阈值;
[0098]
若是,则执行利用预先训练得到的意图实体识别模型对文本进行识别的步骤。
[0099]
在本技术中,在利用预先训练得到的意图实体识别模型对文本进行识别之前,可以先利用预先训练得到的意图识别模型对文本进行识别,得到文本的第二催收意图及第二催收意图的概率,其中,第二催收意图具体可以包括承诺还款、协商还款等,得到第二催收意图的概率的目的是为了便于概率确定利用意图识别模型所识别得到的第二催收意图是催收的意图、而非是闲聊意图等非催收的意图的可能性,概率越大,则表明是催收的意图的可能性越大。
[0100]
其中,意图识别模型为利用催收对应的文本库对第二初始模型进行训练得到的模型,且具体是利用文本库中的文本数据、各类型的第二催收意图来对第二初始模型进行训练而得到意图识别模型。
[0101]
在得到第二催收意图的概率之后,可以将第二催收意图的概率与第二阈值进行比较,判断第二催收意图的概率是否大于第二阈值,其中,第二阈值具体可以为0.8,当然,也可以根据实际需要而对其进行调整。若第二催收意图的概率大于或等于第二阈值,则表明用户所输入的语音转换得到文本极有可能是催收的意图,此时,催收机器人判定第二催收意图为催收的意图,并执行利用预先训练得到的意图实体识别模型对文本进行识别的步骤,也即仅在第二催收意图的概率大于或等于第二阈值的情况下才利用意图实体识别模型对文本进行识别。
[0102]
需要说明的是,与意图实体识别模型相比,意图识别模型是一个粗略化的识别模型(换句话说,与意图识别模型相比,意图实体识别模型是一个精细化的模型),也即相比于意图实体识别模型对文本意图进行精细化识别而言,意图识别模型对文本意图进行粗略化的识别,因此,意图识别模型识别速度要比意图实体识别模型快,由此则可利用意图实体识别模型起到初筛的目的,从而便于加快催收机器人回复效率,并通过仅在第二催收意图的概率大于或等于第二阈值时再利用意图识别模型进行识别而提高意图实体识别模型识别
的准确性。
[0103]
本技术实施例提供的一种催收机器人交互方法,若第二催收意图的概率未大于或等于第二阈值,则还可以包括:
[0104]
判断第二催收意图的概率是否大于或等于第三阈值;第三阈值小于第二阈值;
[0105]
若是,则对文本进行分词,从分词结果中提取文本中的实体,并根据文本中的实体进行回复,以向用户进行确认;
[0106]
若否,则确认第二催收意图为闲聊意图,并进入闲聊模式。
[0107]
在本技术中,若确定第二催收意图的概率未大于或等于第二阈值,则判断第二催收意图的概率是否大于或等于第三阈值,其中,第三阈值小于第二阈值,例如:第三阈值具体可以为0.2,当然,也可以根据实际需要而对其进行调整。
[0108]
若第二催收意图的概率大于或等于第三阈值,且第二催收意图的概率小于第二阈值,则无法确定第二催收意图是何种意图,也即意图识别模型无法识别用户输入的语音转换得到的文本是何种意图,此时,则会走重复确认流程,具体地,会对语音转换得到的文本进行分词,并从分词结果中提取文本中的实体,并根据文本中的实体进行回复,以向用户进行确认,从而根据用户的回复来增加成功匹配用户意图的准确率。例如:如果从文本中提取的实体为金额,则可以回复“你是想咨询还款金额的问题吗”,即对提取到的文本中的实体向用户进行确认,通过这样的方式来增加成功匹配用户意图的准确率。
[0109]
若第二催收意图的概率不大于第三阈值,则确定为闲聊意图,此时,催收机器人可以进入闲聊模式而在闲聊模式下对用户输入的语音进行回复,从而增加用户体验度。
[0110]
参见图4,其示出了本技术实施例提供的意图识别模型的结构示意图。本技术实施例提供的一种催收机器人交互方法,意图识别模型可以包括:
[0111]
第二输入层,用于输入文本;
[0112]
第二embedding层,用于将文本进行向量化表示,以得到第二多维矩阵;
[0113]
bi-gru层,用于从第二多维矩阵中进行文本特征提取,得到一次文本特征提取结果;
[0114]
attention层,用于从一次文本特征提取结果中进行文本特征提取,得到二次文本特征提取结果;
[0115]
第二softmax层,用于根据二次文本特征提取结果计算各类型的第二催收意图的概率;
[0116]
第二输出层,用于输出概率最大对应的第二催收意图及其概率。
[0117]
在本技术中,意图识别模型可以包括第二输入层、第二embedding层、bi-gru层、attention层、第二softmax层、第二输出层。其中,第二输入层用于接收利用asr对用户输入的语音进行转换而得到的文本,并将文本送入到第二embedding层。第二embedding层的目的是将文本进行向量化表示,并将第二向量化表示结果从高维稀疏矩阵转换为低维稠密的第二多维矩阵,以方便表示和计算,其中,这里提及的第二embedding层与意图实体识别模型中的第一embedding层类似,且第二embedding层可以选择word2vec、glove、bert或者bert的变种形式,实际中可以根据具体需要选择合适的embedding层。经过第二embedding层完成token化(具体即为将单词转换为固定维的向量表示)的第二多维矩阵可以进入到bi-gru(bidirectional gru)层中,以利用bi-gru层从第二多维矩阵中进行一次文本特征
提取,以得到一次文本特征提取结果,具体可以参见图5,其示出了本技术实施例提供的gru的结构图,其中,相对于lstm(长短期记忆网络)来说,gru少了一个门结构,结构相对简单且训练更加容易,gru引入了重置门r
t
和更新门z
t
,其计算公式为:
[0118]rt
=σ(x
twxr
h
t-1whr
br)
[0119]zt
=σ(x
twxz
h
t-1whz
bz)
[0120]
其中,σ为激活函数,t为时间,t-1为上一时刻时间,w为权重矩阵,b为偏置常量,x
t
为t时间的输入。
[0121][0122][0123]
为中间信息,需要遗忘不重要的信息,并记住有用的信息,则h
t
为最后的更新信息。
[0124]
随后,bi-gru层的输出(即第一文本特征)会进入到attention层,以利用attention层对一次文本特征提取结果行二次文本特征提取,以得到二次文本特征提取结果。具体地,可以参见图6,其示出了本技术实施例提供的attention层的结构示意图,attention层大致分为三步骤,输入向量会分为q、k、v三个矩阵,首先是q和k进行相似度计算得到权值,第二步是对上一步的权值进行归一化处理,最后一步是用归一化的权值与v矩阵进行加权求和,其中,attention层的计算公式如下所示:
[0125][0126]
通过上述过程可知,本技术利用bi-gru层实现粗略化地从第二多维矩阵中提取文本特征(即提取得到的是粗略化的文本特征),利用attention层实现对bi-gru层提取的粗略化的文本特征进行更深层次的特征提取工作,以得到精细化的文本特征,从而提高文本特征提取的准确性和精度。
[0127]
经过attention层之后,会进入到第二softmax层,以利用第二softmax层完成最后的归一化,并计算最后的概率值,具体根据二次文本特征提取结果计算各类型的第二催收意图的概率,并根据概率最大的第二催收意图得到用户输入的语音转换得到的文本所表明的意图。之后,经由第二输出层输出概率最大对应的第二催收意图及其概率。
[0128]
通过上述过程可以实现对文本的第二催收意图及其概率的获取,以便于基于此进行意图的确定和后续处理,并提高意图确定的准确性。
[0129]
本技术实施例提供的一种催收机器人交互方法,若第一催收意图的概率未大于或等于第一阈值,则还可以包括:
[0130]
根据意图实体识别模型得到的实体,按照第二预设模板进行回复,以向用户进行确认。
[0131]
在本技术中,若第一催收意图的概率未大于或等于第一阈值,此时,则无法确定第一催收意图具体是何种意图,因此,催收机器人则可以走重复确认流程,具体可以根据利用第一意图识别模型识别得到的实体并结合第二预设模板来进行回复,以向用户进行确认,从而根据用户的回复来增加成功匹配用户意图的准确率。
[0132]
本技术实施例提供的一种催收机器人交互方法,根据实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据,可以包括:
[0133]
将实体、第一催收意图、历史实体及历史催收意图进行特征化,以得到最终特征,并根据最终特征从催收对应的知识图谱中获取对应的回复数据。
[0134]
在本技术中,在根据实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据时,具体可以将此轮用户输入的语音转换得到文本中的实体及文本的第一催收意图、用户此前轮输入的历史语音转换得到的历史文本中的历史实体及历史文本的历史催收意图(具体即为利用意图实体识别模型识别得到且概率大于第一阈值的历史第一催收意图)进行特征化,以得到最终特征,并根据最终特征从催收对应的知识图谱中获取对应的回复数据,从而实现基于历史轮的语音来实现催收回复,即实现用户与催收机器人之间的对轮对话。其中,历史实体及历史语音的历史催收意图可以记录在催收机器人所包含的追踪器中,且根据文本中的实体及文本的第一催收意图所采取的回复策略也可以记录在追踪器中,以用作下次相关回复的参考。
[0135]
通过以上过程可知,本技术中可以基于rasa框架来实现多轮对话,以提高催收机器人催收的智能化。具体如图7所示,其示出了rasa的框架图,消息传入后,会被interpreter(解释器)接收,将消息转换成字典(tokenizer)并转换成特征(features),提取消息中的实体,意图以及对话的特征数据一起传给tracker。tracker是用来追踪对话状态的对象,记录当前的特征、意图、实体和历史状态信息,一起传给policy。policy将当前状态以及历史状态一起特征化,使用预测模型预测下一个动作(action)。action完成实际动作后,将结果通知给tracker,成为历史状态,同时action将结果返回给用户。
[0136]
在本技术中,在得到文本的实体和概率大于或等于第一阈值的第一催收意图之后,rasa会进入到回复策略模块中,根据实体和第一催收意图采取相应的回复策略policy,policy的收入是tracker记录的当前对话状态,输出是一个系统的响应action,policy包含一个featurizer(主要包括三个部分:上轮动作、上轮的意图和实体、本轮的实体和意图),从neo4j数据库中提取用户相关数据后,action会对系统的响应做出回应,按照回复策略回复用户的想要的数据,同时用户输入的语音被解析的同时,tracker追踪器模块也会启动,记录此时的回复策略,用作下次相关后续回复作为参考。
[0137]
其中,在本技术中,获取文本与rasa框架中的message in(消息输入)相对应,模型识别和处理与rasa框架中的interpreter相对应,追踪器与rasa框架中的tracker相对应,回复策略与rasa框架中的policy和action相对应,对用户进行回复与rasa框架中的message out相对应。
[0138]
本技术实施例还提供了一种催收机器人交互装置,参见图8,其示出了本技术实施例提供的一种催收机器人交互装置的结构示意图,可以包括:
[0139]
接收模块81,用于接收用户输入的语音,并利用asr将语音转换为文本;
[0140]
第一识别模块82,用于利用预先训练得到的意图实体识别模型对文本进行识别,得到文本中的实体、第一催收意图及第一催收意图的概率;意图实体识别模型为利用催收对应的文本库训练得到的模型;
[0141]
回复模块83,用于当第一催收意图的概率大于或等于第一阈值时,则根据实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据,并根据第一预设模板及回复
数据对用户进行回复。
[0142]
本技术实施例提供的一种催收机器人交互装置,意图实体识别模型可以包括:
[0143]
第一输入层,用于输入文本;
[0144]
第一embedding层,用于将文本进行向量化表示,以得到第一多维矩阵;
[0145]
inten label attention层,用于从第一多维矩阵中提取不同类型的第一催收意图;
[0146]
slot label attention层,用于从第一多维矩阵中提取实体特征;
[0147]
第一ln层,用于对intent label attention层提取的各类型的第一催收意图进行标准化;
[0148]
第二ln层,用于对slot label attention层提取的实体特征进行标准化;
[0149]
拼接层,用于对第一ln层和第二ln层输出的结果向量进行拼接;
[0150]
crf层,用于从拼接结果中查找实体;
[0151]
第一softmax层,用于根据拼接结果计算各类型的第一催收意图的概率;
[0152]
第一输出层,用于输出实体、概率最大对应的第一催收意图及其概率。
[0153]
本技术实施例提供的一种催收机器人交互装置,还可以包括:
[0154]
第二识别模块,用于在利用预先训练得到的意图实体识别模型对文本进行识别之前,利用预先训练得到的意图识别模型对文本进行识别,得到文本的第二催收意图及第二催收意图的概率;意图识别模型为利用催收对应的文本库训练得到的模型;
[0155]
第一判断模块,用于判断第二催收意图的概率是否大于或等于第二阈值;
[0156]
执行模块,用于若第二催收意图的概率大于或等于第二阈值,则执行利用预先训练得到的意图实体识别模型对文本进行识别的步骤。
[0157]
本技术实施例提供的一种催收机器人交互装置,还可以包括:
[0158]
第二判断模块,用于若第二催收意图的概率未大于或等于第二阈值,则判断第二催收意图的概率是否大于或等于第三阈值;第三阈值小于第二阈值;
[0159]
分析模块,用于若第二催收意图的概率大于或等于第三阈值,则对文本进行分词,从分词结果中提取文本中的实体,并根据文本中的实体进行回复,以向用户进行确认;
[0160]
第一确认模块,用于若第二催收意图的概率小于第三阈值,则确认第二催收意图为闲聊意图,并进入闲聊模式。
[0161]
本技术实施例提供的一种催收机器人交互装置,意图识别模型可以包括:
[0162]
第二输入层,用于输入文本;
[0163]
第二embedding层,用于将文本进行向量化表示,以得到第二多维矩阵;
[0164]
bi-gru层,用于从第二多维矩阵中进行文本特征提取,得到一次文本特征提取结果;
[0165]
attention层,用于从一次文本特征提取结果中进行文本特征提取,得到二次文本特征提取结果;
[0166]
第二softmax层,用于根据二次文本特征提取结果计算各类型的第二催收意图的概率;
[0167]
第二输出层,用于输出概率最大对应的第二催收意图及其概率。
[0168]
本技术实施例提供的一种催收机器人交互装置,还可以包括:
[0169]
第二确认模块,用于若第一催收意图的概率未大于或等于第一阈值,则根据意图实体识别模型得到的实体,按照第二预设模板进行回复,以向用户进行确认。
[0170]
本技术实施例提供的一种催收机器人交互装置,播放模块83可以包括:
[0171]
获取单元,用于将实体、第一催收意图、历史实体及历史催收意图进行特征化,以得到最终特征,并根据最终特征从催收对应的知识图谱中获取对应的回复数据。
[0172]
本技术实施例还提供了一种催收机器人,参见图9,其示出了本技术实施例提供的一种催收机器人的结构示意图,可以包括:
[0173]
存储器91,用于存储计算机程序;
[0174]
处理器92,用于执行存储器91存储的计算机程序时可实现如下步骤:
[0175]
接收用户输入的语音,并利用asr将语音转换为文本;利用预先训练得到的意图实体识别模型对文本进行识别,得到文本中的实体、第一催收意图及第一催收意图的概率;意图实体识别模型为利用催收对应的文本库训练得到的模型;当第一催收意图的概率大于或等于第一阈值时,则根据实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据,并根据第一预设模板及回复数据对用户进行回复。
[0176]
本技术实施例还提供了一种可读存储介质,可读存储介质上存储有计算机程序,计算机程序被处理器执行时可实现如下步骤:
[0177]
接收用户输入的语音,并利用asr将语音转换为文本;利用预先训练得到的意图实体识别模型对文本进行识别,得到文本中的实体、第一催收意图及第一催收意图的概率;意图实体识别模型为利用催收对应的文本库训练得到的模型;当第一催收意图的概率大于或等于第一阈值时,则根据实体及第一催收意图从催收对应的知识图谱中获取对应的回复数据,并根据第一预设模板及回复数据对用户进行回复。
[0178]
该可读存储介质可以包括:u盘、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
[0179]
本技术提供的一种催收机器人交互装置、催收机器人及可读存储介质中相关部分的说明可以参见本技术实施例提供的一种催收机器人交互方法中对应部分的详细说明,在此不再赘述。
[0180]
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。另外,本技术实施例提供的上述技术方案中与现有技术中对应技术方案实现原理一致的部分并未详细说明,以免过多赘述。
[0181]
对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。