1.本技术涉及软件测试技术领域,尤其涉及一种测试用例处理方法、装置、设备及存储介质。
背景技术:
2.随着软件开发流程的不断规范,对于产品的交付周期、功能及质量等方面要求越来越高。在实际操作中,通常不仅需要在规定的项目周期内完成产品迭代,同时还要确保产品满足质量方面的功能性、可用性以及鲁棒性等要求。其中,回归测试作为质量保证的重要手段,在软件测试领域发挥着重要的作用。回归测试的方法大多采用测试用例的方式对产品功能进行覆盖测试,以尽可能的保证覆盖率。
3.然而,随着软件规模的不断增大,回归测试中的测试用例随之越来越多,所牵涉到的场景也越来越复杂。通过回归测试如何在人力及时间成本有限的情况下最大限度的把控产品质量势必至关重要。
4.回归测试一般以覆盖率为重要指标,首先编写测试用例,然后进行人工或自动化测试,每次回归按固定的测试用例进行测试。因而,在测试用例较多的情况下,往往没有侧重点,不能有效的找出对产品体验影响最大的问题所在,测试效果不佳。并且由于测试用例较多则在测试过程需要较高成本以及较长测试周期。
技术实现要素:
5.本技术提供一种测试用例处理方法、装置、设备及存储介质,用于解决现有测试没有侧重点导致测试成本较高、测试周期较长以及不能有效找出影响产品的最大的问题所在的技术问题。
6.第一方面,本技术提供一种测试用例处理方法,包括:
7.采集行驶车辆的日志信息,所述日志信息包括所述行驶车辆多个维度的属性信息;
8.根据预设权重处理策略以及各维度的属性信息确定测试用例的相关权重,所述相关权重包括所有测试用例的各关联测试场景所属维度的权重;
9.根据所述相关权重确定每个测试用例的综合权重,以根据所述每个测试用例的综合权重确定所述每个测试用例的测试优先级,所述测试优先级用于在测试阶段使得优先级高的测试用例优先测试。
10.第二方面,本技术提供一种测试用例处理装置,包括:
11.采集模块,用于采集行驶车辆的日志信息,所述日志信息包括所述行驶车辆多个维度的属性信息;
12.第一处理模块,用于根据预设权重处理策略以及各维度的属性信息确定测试用例的相关权重,所述相关权重包括所有测试用例的各关联测试场景所属维度的权重;
13.第二处理模块,用于根据所述相关权重确定每个测试用例的综合权重,以根据所
述每个测试用例的综合权重确定所述每个测试用例的测试优先级,所述测试优先级用于在测试阶段使得优先级高的测试用例优先测试。
14.第三方面,本技术提供一种电子设备,包括:处理器,以及与所述处理器通信连接的存储器;
15.所述存储器存储计算机执行指令;
16.所述处理器执行所述存储器存储的计算机执行指令,以实现第一方面所提供的任意一种可能的测试用例处理方法。
17.第四方面,本技术提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如第一方面所提供的任意一种可能的测试用例处理方法。
18.第五方面,本技术还提供一种计算机程序产品,包括计算机指令,该计算机指令被处理器执行时实现第一方面所提供的任意一种可能的测试用例处理方法。
19.本技术提供一种测试用例处理方法、装置、设备及存储介质,首先采集行驶车辆的日志信息,日志信息包括行驶车辆多个维度的属性信息,然后根据预设权重处理策略以及各维度的属性信息确定测试用例的相关权重,相关权重包括所有测试用例的各关联测试场景所属维度的权重,再根据相关权重确定每个测试用例的综合权重,进而根据每个测试用例的综合权重确定每个测试用例的测试优先级,在测试阶段对优先级高的测试用例优先测试,确保与行驶车辆实际使用中关联度最高的测试用例被优先执行,便于尽早发现对产品影响最大的问题所在。并且通过确定每个测试用例的测试优先级,使得测试具有侧重点,可以有效降低测试成本和缩短测试周期。
附图说明
20.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
21.图1为本技术实施例提供的一种应用场景示意图;
22.图2为本技术实施例提供的一种测试用例处理方法的流程示意图;
23.图3为本技术实施例提供的另一种测试用例处理方法的流程示意图;
24.图4为本技术实施例提供的再一种测试用例处理方法的流程示意图;
25.图5为本技术实施例提供的一种分布数据直方图;
26.图6为本技术实施例提供的又一种测试用例处理方法的流程示意图;
27.图7为本技术实施例提供的又一种测试用例处理方法的流程示意图;
28.图8为本技术实施例提供的又一种测试用例处理方法的流程示意图;
29.图9为本技术实施例提供的一种测试用例处理装置的结构示意图;
30.图10为本技术实施例提供的一种电子设备的结构示意图。
具体实施方式
31.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及
附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本技术相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本技术的一些方面相一致的方法和装置的例子。
32.本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本技术的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
33.随着软件规模的不断增大,回归测试中的测试用例随之越来越多,所牵涉到的场景也越来越复杂。通过回归测试如何在人力及时间成本有限的情况下最大限度的把控产品质量势必至关重要。回归测试一般以覆盖率为重要指标,首先编写测试用例,然后进行人工或自动化测试,每次回归按固定的测试用例进行测试。因而,在测试用例较多的情况下,往往没有侧重点,不能有效的找出对产品体验影响最大的问题所在,测试效果不佳。并且由于测试用例较多则在测试过程需要较高成本以及较长测试周期。
34.针对现有技术中存在的上述问题,本技术提供一种测试用例处理方法、装置、设备及存储介质。本技术提供的测试用例处理方法的发明构思在于:采集行驶车辆的日志信息,根据预设权重处理策略以及日志信息确定测试用例的相关权重,相关权重包括所有测试用例的各关联测试场景所属维度的权重,进而根据相关权重确定出每个测试用例的综合权重,再依据每个测试用例的综合权重得到其测试优先级,使得优先级高的测试用例可以优先测试,确保与行驶车辆的实际使用关联度最高的测试用例被优先执行,进而尽早发现对产品影响最大的问题所在,并使得测试具有侧重点,有效降低测试成本和缩短测试周期。
35.以下,对本技术实施例的示例性应用场景进行介绍。
36.图1为本技术实施例提供的一种应用场景示意图,如图1所示,在软件开发技术领域,开发者需要对其所开发的软件程序利用测试用例进行测试。因而,电子设备100可以被配置为执行本技术实施例提供的测试用例处理方法,以获取到测试阶段所用测试用例的优先级。假设所开发的软件程序适用于车辆,电子设备100在执行本技术实施例提供的测试用例处理方法时则可以与行驶车辆200进行交互,以采集行驶车辆200的日志信息,基于对日志信息的大数据分析得到测试用例的优先级,从而可以确保与行驶车辆200的实际使用关联度最高的测试用例被优先执行,可以尽早发现对产品影响最大的问题所在,测试具有侧重点,进而有效降低测试成本和缩短测试周期。
37.需要说明的是,上述所开发的软件程序包括但不仅限于车辆的适用范围。电子设备100可以为车载终端、计算机、服务器等任意设置,本技术实施例对于电子设备100的类型不作限定,图1中以计算机为例示出。
38.另外,上述应用场景也仅仅是示意性的,本技术实施例提供的测试用例处理方法、装置、设备及存储介质包括但不仅限于上述应用场景。
39.图2为本技术实施例提供的一种测试用例处理方法的流程示意图。如图2所示,本技术实施例包括:
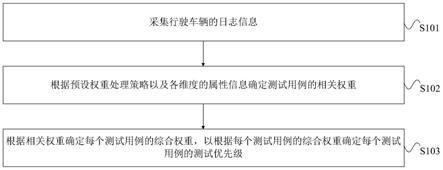
40.s101:采集行驶车辆的日志信息。
41.其中,日志信息包括行驶车辆多个维度的属性信息。
42.在行驶车辆的使用过程中,行驶车辆的日志信息会被记录,以为大数据云服务提供数据支撑。因而,可以采集可以行驶车辆的日志信息。
43.所采集到的行驶车辆的日志信息可以包括行驶车辆多个维度的属性信息。多个维度的属性信息例如可以包括车主出生地信息、车主年龄信息、车主性别信息等关于行驶车辆车主的信息,也还可以包括行驶车辆的行驶区域信息、行驶车辆的语音交互范畴信息、行驶车辆的语音交互功能信息、语音交互语速信息、语音交互数量信息以及行驶车辆的车型信息等等。
44.可以理解的是,日志信息所包括的多个维度的属性信息包括但不限于上述列举的信息。
45.s102:根据预设权重处理策略以及各维度的属性信息确定测试用例的相关权重。
46.其中,相关权重包括所有测试用例的各关联测试场景所属维度的权重。
47.基于各维度的属性信息以及预设权重处理策略获得所有测试用例所关联的各关联测试场景所属维度的权重,即得到相关权重。
48.关联测试场景是指测试用例可适用的测试场景,关联测试场景所属维度则为可适用的测试场景所属维度。
49.例如,测试用例中包含描述车主出生地的信息,比如四川、湖南等属地信息,则该测试用例的关联测试场景包含有“车主出生地”这一维度的测试场景,对应的该关联测试场景所属维度即为“车主出生地”;
50.例如,测试用例中包含描述车主年龄的信息,比如30-50岁,则该测试用例的关联测试场景包含有“车主年龄”这一维度的测试场景,对应的该关联测试场景所属维度即为“车主年龄”;
51.例如,测试用例中包含描述车主性别的信息,则该测试用例的关联测试场景包含有“车主性别”这一维度的测试场景,对应的该关联测试场景所属维度即为“车主性别”;
52.例如,测试用例中包含描述行驶车辆车型的信息,则该测试用例的关联测试场景包含有“车型”这一维度的测试场景,对应的该关联测试场景所属维度即为“车型”;
53.例如,测试用例中包含描述行驶车辆的行驶区域的信息,则该测试用例的关联测试场景包含有“行驶区域”这一维度的测试场景,对应的该关联测试场景所属维度即为“行驶区域”;
54.例如,测试用例中包含描述行驶车辆的语音交互范畴的信息,则该测试用例的关联测试场景包含有“语音交互范畴”这一维度的测试场景,对应的该关联测试场景所属维度即为“语音交互范畴”,语音交互范畴可以理解为语音交互domain;
55.例如,测试用例中包含描述行驶车辆的语音交互功能的信息,比如“音乐”、“导航”、“打开空调”等,则该测试用例的关联测试场景包含有“语音交互功能”这一维度的测试场景,对应的该关联测试场景所属维度即为“语音交互功能”;
56.例如,测试用例中包含描述行驶车辆的语音交互语速的信息,比如每秒2~10个词等,则该测试用例的关联测试场景包含有“语音交互语速”这一维度的测试场景,对应的该关联测试场景所属维度即为“语音交互语速”;
57.例如,测试用例中包含描述行驶车辆的语音交互数量的信息,则该测试用例的关联测试场景包含有“语音交互数量”这一维度的测试场景,对应的该关联测试场景所属维度即为“语音交互数量”。
58.可见,通过测试用例可以获知该测试用例的关联测试场景,关联测试场景均有对应的所属维度。因此,在所有测试用例已知的情况下,则可得知关联测试场景,进而根据预设权重处理策略和各维度的属性信息可以确定出所有测试用例的各关联测试场景所属维度的权重,即得到相关权重。
59.其中,根据预设权重处理策略和各维度的属性信息确定关联测试场景所属维度的权重,可以是在分析各维度的属性信息的基础上根据预设权重处理策略的具体内容计算得到。各相关权重基于行驶车辆的日志信息得到,使得所计算到的相关权重能够与行驶车辆的实际情况强关联,关联度更高则对应相关权重越大,从而不但有利于提高测试的准确性,基于相关权重确定测试用例的测试优先级还可以确保与行驶车辆的实际使用关联度高的测试用例被优先测试。
60.s103:根据相关权重确定每个测试用例的综合权重,以根据每个测试用例的综合权重确定每个测试用例的测试优先级。
61.其中,测试优先级用于在测试阶段使得优先级高的测试用例优先测试。
62.得到相关权重后,进一步确定每个测试用例的综合权重,进而依据每个测试用例的综合权重确定每个测试用例的测试优先级,以在测试阶段优先对优先级高的测试用例进行测试。
63.其中,每个测试用例的综合权重用于表征该测试用例在测试阶段的测试顺序,综合权重越高的测试用例则会被优先进行测试,从而在测试用例较多的情况下,通过各测试用例的综合权重确定测试用例的测试优先级,依据测试优先级进行测试,则可以使得优先级高的测试用例被优先测试。
64.在一种可能的设计中,步骤s103可能的实现方式包括:
65.为每个相关权重自定义对应的权重系数,权重系数用于表征相关权重对应的关联测试场景所属维度的重要程度,关联测试场景所属维度越重要,对应的权重系数越高。然后根据每个测试用例自身的关联测试场景确定出每个测试用例的各目标维度,针对每个测试用例,获取该测试用例的各目标维度对应的各相关权重与各相关权重对应的权重系数之间的乘积,进而将得到的各乘积求和,将求和结果确定为该测试用例的综合权重。
66.例如,所有测试用例的各关联测试场景所属维度包括“车主出生地”、“车主年龄”、“车主性别”、“车型”、“行驶区域”、“语音交互范畴”、“语音交互功能”、“语音交互语速”以及“语音交互数量”,则相关权重包括“车主出生地”、“车主年龄”、“车主性别”、“车型”、“行驶区域”、“语音交互范畴”、“语音交互功能”、“语音交互语速”以及“语音交互数量”这些维度各自的权重。
67.为上述所属维度各自的权重也即每个相关权重自定义对应的权重系数。假设各相关权重依次采用w
bp
,w
ag
,w
gender
,wm,wr,wd,wf,ws,w
pm
表示。自定义每个相关权重对应的权重系数为υ
bp
,υ
ag
,υ
gender
,υm,υr,υd,υf,υs,υ
pm
。则针对每个测试用例的综合权重w
t
可以如下公式(1)表示:
68.w
t
=w.υ
t
ꢀꢀꢀ
(1)
69.其中,w可以w
bp
,w
ag
,w
gender
,wm,wr,wd,wf,ws,w
pm
中的一个或多个,根据w确定对应的υ,即υ对应地为υ
bp
,υ
ag
,υ
gender
,υm,υr,υd,υf,υs,υ
pm
中的一个或多个,w和其对应的υ具体为哪些相关权重以及权重系数具体由每个测试用例的各目标维度决定。
70.比如,确定出每个测试用例的各目标维度分别为“车主性别”、“车型”、“行驶区域”,则w为w
gender
、wm及wr,对应的权重系数υ则为υ
gender
、υm及υr,根据公式(1)则可得到如下表达式(1')以确定出该测试用例的综合权重w
t
′
;
71.w
′
t
=w
gender
*υ
gender
wm*υm wr*υrꢀꢀ
(1')
72.进一步地,按照每个测试用例的综合权重由大到小的顺序对各测试用例进行排序,排名越靠前则表明该测试用例的综合权重越大,该测试用例的优先级越高,从而得到每个测试用例的测试优先级,在测试阶段对按照每个测试用例的优先级进行测试,使得优先级高的测试用例优先进行测试。
73.本技术实施例提供的测试用例处理方法,基于所采集到的行驶车辆的日志信息以及预设权重处理策略确定所有测试用例的各关联测试场景所属维度的权重,即得到相关权重,再根据相关权重确定每个测试用例的综合权重,进而根据每个测试用例的综合权重对各测试用例进行排序,得到每个测试用例的测试优先级,在测试阶段对优先级高的测试用例优先进行测试,从而可以确保与行驶车辆实际使用中关联度最高的测试用例被优先执行,便于尽早发现对产品影响最大的问题所在。并且通过确定每个测试用例的测试优先级,使得测试具有侧重点,可以有效降低测试成本和缩短测试周期。
74.图3为本技术实施例提供的另一种测试用例处理方法的流程示意图。如图3所示,本技术实施例包括:
75.s201:采集行驶车辆的日志信息。
76.其中,日志信息包括行驶车辆多个维度的属性信息。
77.步骤s201的具体实现方式、原理以及技术效果与步骤s101的具体实现方式、原理以及技术效果相类似,在此不再赘述。
78.s202:利用预设分类处理规则对各维度的属性信息进行分类处理,得到各分类属性信息。
79.其中,各分类属性信息包括排行类属性信息、比重类属性信息、分布类属性信息以及统计类属性信息。
80.对采集到的行驶车辆多个维度的属性信息利用预设分类处理规则进行分类处理,以将多个维度的属性信息分类为排行类属性信息、比重类属性信息、分布类属性信息以及统计类属性信息这四类。
81.例如,排行类属性信息可以包括行驶车辆的车主出生地信息、行驶车辆的行驶区域信息、行驶车辆的语音交互范畴信息、行驶车辆的语音交互功能信息以及行驶车辆的车型信息,属于排行类属性信息这一类属性信息的各维度能够被排名处理,故认为这一类属性信息具有排名属性的维度特征。
82.比重类属性信息包括行驶车辆的车主性别信息,比如车主为男性或女性,属于比重类属性信息的这一类属性信息的各维度具有比例属性的维度特征。
83.分布类属性信息可以包括行驶车辆的车主年龄信息以及语音交互语速信息,属于分布类属性信息的这一类属性信息的各维度具有分布属性的维度特征。
84.统计类属性信息可以包括行驶车辆的语音交互数量信息,属于统计类属性信息的这一类属性信息的各维度具有计数属性的维度特征。
85.预设分类处理规则可以理解为按照各维度的属性信息的维度特征对其进行分类的规则,以便于针对不同维度特征的属性信息采取不同的进一步分析,实现各维度的属性信息的维度细化。
86.s203:基于各分类属性信息确定各分类属性信息的数据权重。
87.其中,数据权重用于表征各分类属性信息中的各特征数据的权重。
88.不同的分类属性信息具有不同的维度特征,因而对各分类属性信息分别进行处理,以确定每个分类属性信息中的各特征数据的权重,即确定各分类属性信息的数据权重。
89.其中,特征数据为每个分类属性信息具体包括的元素,例如,行驶车辆的车主出生地信息中的“湖南、四川”等元素即为行驶车辆的车主出生地信息这一排行类属性信息的特征数据。各特征数据的权重即为该分类属性信息的数据权重。
90.在一种可能的设计中,步骤s203可能的实现方式如图4所示。图4为本技术实施例提供的再一种测试用例处理方法的流程示意图。如图4所示,本技术实施例包括:
91.s2031:对排行类属性信息进行排序及数值化处理,以将排行类属性信息转化为序列数据,并采用预设数值权重算法确定序列数据中各数值的权重。
92.其中,各数值的权重用于表征排行类属性信息中各特征数据的权重;
93.首先对排行类属性信息进行排序及数值化的处理,再计算数值化后得到的序列数据中各数值的权重,以获得排行类属性信息中各特征数据的权重,也即获得该排行类属性信息的数据权重。
94.以行驶车辆的车主出生地信息这一排行类属性信息为例说明如下:
95.例如,假设从行驶车辆的车主出生地信息中车主出生地为“浙江”的最多,其次为“广东”,接着为“江苏”,那么车主出生地信息中车主出生地前三的排名即为【浙江,广东,江苏】,该排行类属性信息中的特征数据即为“浙江”、“广东”和“江苏”。因此,可以根据由大到小的顺序进行排序,获取排名靠前的车主出生地,比如获取前n排名即topn排行的序列,n可以根据实际需要设置为相应正整数,前三排名n即为3。
96.进一步对排行后得到的序列进行数值化,将排行类属性信息转化为的序列数据。比如对于topn排行的序列记为(x1,x2,x3,x4…
xi..xn),其中x
i-1
》xi,(0《i《n 1),以排名作为当前topi的数值,即xi的数值即为i,例如x1的数值即为1,从而将topn排行的序列数值化,将排行类属性信息转化为数值型的序列数据。再利用预设数值权重算法确定该序列数据中各数值的权重。
97.预设数值权重算法具体为,将序列数据中所有数值的和作为预设数值权重算法的分母,然后将n 1减去topi的数值作为预设数值权重算法的分子,即计算xi的权重时预设数值权重算法的分子d为n 1-i,计算topn各排行中各特征数据的权重所采用的预设数值权重算法如下公式(2)表示:
[0098][0099]
例如,对于行驶车辆的车主出生地信息进行top3排行得到的序列【浙江,广东,江苏】进行数值化后得到的序列数据即为{1,2,3},该序列数据中所有数值的和s=1 2 3,即s
=6为公式(2)的分母,则利用公式(2)计算特征数据“浙江”、“广东”、“江苏”的权重分别如下公式(3)-(5)所示:
[0100][0101][0102][0103]
其中,序列数据中各数值的权重w
浙江
、w
广东
和w
江苏
分别表示特征数据“浙江”、“广东”、“江苏”的权重,也即【浙江,广东,江苏】这一排行类属性信息的数据权重。
[0104]
其它排行类属性信息,例如行驶车辆的行驶区域信息、行驶车辆的语音交互范畴信息、行驶车辆的语音交互功能信息以及行驶车辆的车型信息,均可以采用如上所示的排序及数值化处理以及预设数值权重算法得到各自的数据权重,在此不再赘述。
[0105]
s2032:根据比重类属性信息中各特征数据的数量比重确定比重类属性信息中各特征数据的权重。
[0106]
如前所描述,比重类属性信息包括行驶车辆的车主性别信息,比如车主为男性或女性,比重类属性信息中的特征数据即车主为男性或车主为女性,因而只要计算出行驶车辆的车主性别信息中男女数量比重,即得到比重类属性信息中各特征数据的权重,也即获得比重类属性信息的数据权重。
[0107]
例如从行驶车辆的车主性别信息中表示车主为男性和女性的数量分别为cm和cf,利用如下公式(6)或(7)可以确定各特征数据的数量比重:
[0108]w男
=cm/(cm cf)
ꢀꢀꢀꢀꢀꢀꢀ
(6)
[0109]w女
=cf/(cm cf)
ꢀꢀꢀꢀꢀꢀꢀ
(7)
[0110]
其中,各特征数据的数量比重w
男
和w
女
则分别表示行驶车辆的车主性别信息中车主为男性和车主为女性的权重,即比重类属性信息的数据权重。
[0111]
s2033:利用分布数据直方图确定分布类属性信息中各特征数据的分布频数。
[0112]
其中,各特征数据的分布频数用于表征分布类属性信息中各特征数据的权重。
[0113]
分布类属性信息的数据权重可以基于分布类属性信息所对应构建的分布数据直方图得以确定。
[0114]
构建分类属性信息对应的分布数据直方图的过程如下所示:
[0115]
得图5为本技术实施例提供的一种分布数据直方图,参照图5所示,根据分布类属性信息构建其对应的分布数据直方图。具体地,首先找出分布类属性信息中特征数据的最大值x
max
(如图5中的s2所示)和最小值x
min
(如图5中的s1所示),比如分布类属性信息为行驶车辆的车主年龄信息,特征数据为车主年龄区间,最大的车主年龄和最小的车主年龄假设分布为55岁和25岁,则x
max
和x
min
分别为55和25。其次求得分布类属性信息中特征数据的分布范围区间s
′
,即s
′
=x
max-x
min
(如图5中的s8所示区间)。然后将分布范围区间均分为n等份,每份的间距为
△
(如图5中的s5所示),再统计出每个间距的横坐标xj,(如图5中的s9所示),最后计算出各特征数据均等分割后的各分布区间的频率分布直方图(如图5所示),即得到该分布类属性信息对应的分布数据直方图。
[0116]
均等分割后的各分布区间的分布数据直方图计算方法详述如下:
[0117]
分别计算分布类属性信息中的各特征数据在对应间距a的[xj,x
j 1
]上分布的数量fj,假设间距
△
设置为5岁,即相邻的横坐标xj和x
j 1
分别表示车主年龄相差5岁的特征数据。假设车主年龄为30~35岁之间的数量即为fj,即特征区间30~35对应的数量为fj。进一步使用fi除以分布类属性信息中最大特征区间(即特征区间x
max
与x
min
)对应的数量(c
sample
),比如车主年龄为25~55岁之间的总数量,即得到车主年龄为30~35岁的特征区间的分布频数s
′△
如下公式(8)所示:
[0118]s′
△
=fj/c
sample
ꢀꢀꢀ
(8)
[0119]
利用公式(8)得到每个间距
△
在区间[xj,x
j 1
]的分布频数。
[0120]
其中,若使用s
′
△
除以间距
△
的区间长度x
j 1-xj,则可获得以间距
△
为底,h
△
为高的矩形,其中则将每个间距
△
矩形的面积近似表示该间距对应的特征区间分布频数,当lim
△→0h
△
时,纵轴函数值近似于图5中的s
12
所示的虚线曲线,至此则构建完成分布数据直方图。
[0121]
在分布数据直方图中,各间距所形成的矩形的面积即为该间距所对应的特征数据的分布频数,即为分布类属性信息中对应特征数据的权重,也则得到分布类属性信息的数据权重。
[0122]
分布类属性信息为行驶车辆的语音交互语速信息时,其特征数据即为语音交互语速区间,例如每秒2~10个词这一区间等。行驶车辆的语音交互语速信息这一分布类属性信息对应的分布数据直方图的构建方式以及利用所构建的分布数据直方图确定行驶车辆的语音交互语速信息中各特征数据的分布频数的方式与行驶车辆的车主年龄信息的相应方式类似,在此不再赘述。
[0123]
s2034:在多个等长时间周期内,获取统计类属性信息中各特征数据的数据量,确定每个等长时间周期对应的数据量在多个等长时间周期内总的数据量中的数据量占比。
[0124]
其中,各数据量占比用于表征统计类属性信息中各特征数据的权重。
[0125]
统计类属性信息可以包括行驶车辆的语音交互数量信息,行驶车辆的语音交互数量信息中的特征数据是指语音交互数量。设置多个等长时间周期,例如每月,统计每月行驶车辆的语音交互信息中语音交互数量,语音交互数量的具体条数即为数据量,然后计算每月的语音交互数量在总的月数的语音交互数量中的占比,所得到的占比即为对应月的语音交互数量的数据量占比,采用该数据量占比表征语音交互数量信息中各特征数据的权重,得到语音交互数量信息这一统计类属性信息的数据权重。
[0126]
通过上述步骤s2031、步骤s2032、步骤s2033及步骤s2034的描述可知,基于不同维度特征的分类属性信息确定每个分类属性信息的数据权重,以备后续测试用例的相关权重的确定。
[0127]
s204:根据各测试用例和分类属性信息各自的数据权重确定测试用例的相关权重。
[0128]
每个测试用例都具有其关联测试场景,而关联测试场景所属维度的维度特征可能不同。因此,可以根据所有测试用例的关联测试场景所属维度的维度特征选择与其维度特征相同的分类属性信息,进而利用所选择的分类属性信息的数据权重确定相关权重。其中,
维度特征不同,确定相关权重的手段不同。
[0129]
在一种可能的设计中,步骤s204可能的实现方式包括:
[0130]
根据各测试用例的关联测试场景确定目标属性信息,关联测试场景是指测试用例可适用的测试场景,在测试用例已知的情况下,可获知测试用例的关联测试场景,测试用例中描述关联测试场景的信息即为目标属性信息,因此,关联测试场景所属维度也就是描述该关联测试场景的目标属性信息所属维度。
[0131]
如图1所示实施例,测试用例的关联测试场景所属维度可以为“车主出生地”、“车主年龄”、“车主性别”、“车型”、“行驶区域”、“语音交互功能”、“语音交互范畴”、“语音交互语速”以及“语音交互数量”等。因此,目标属性信息所属维度也可以为“车主出生地”、“车主年龄”、“车主性别”、“车型”、“行驶区域”、“语音交互功能”、“语音交互范畴”、“语音交互语速”以及“语音交互数量”等。
[0132]
其中,目标属性信息是基于所有测试用例而言,换言之,是根据各测试用例的关联测试场景确定出的。
[0133]
得到目标属性信息后,对于与排行类属性信息具有相同维度特征的目标属性信息,根据目标属性信息、排行类属性信息的数据权重以及排行类属性信息确定目标属性信息所属维度的权重。其中,这些目标属性信息具有排名属性的维度特征。
[0134]
对于与比重类属性信息具有相同维度特征的目标属性信息,根据目标属性信息、比重类属性信息的数据权重以及比重类属性信息确定目标属性信息所属维度的权重。其中,这些目标属性信息具有比例属性的维度特征。
[0135]
对于与分布类属性信息具有相同维度特征的目标属性信息,根据目标属性信息、分布类属性信息的数据权重以及分布类属性信息确定目标属性信息所属维度的权重。其中,这些目标属性信息具有分布属性的维度特征。
[0136]
对于与统计类属性信息具有相同维度特征的目标属性信息,根据目标属性信息、统计类属性信息的数据权重以及统计类属性信息确定目标属性信息所属维度的权重。其中,这些目标属性信息具有计数属性的维度特征。
[0137]
通过确定各目标属性信息所属维度的权重得到所有测试用例的各关联测试场景所属维度的权重,也即得到测试用例的相关权重。
[0138]
基于每个测试用例的关联测试场景所属维度的维度特征,选择具有相同维度特征的分类属性信息的数据权重以及所选取的该分类属性信息确定各目标属性信息所属维度的权重,以得到测试用例的相关权重。
[0139]
s205:根据相关权重确定每个测试用例的综合权重,以根据每个测试用例的综合权重确定每个测试用例的测试优先级。
[0140]
其中,测试优先级用于在测试阶段使得优先级高的测试用例优先测试。
[0141]
步骤s205的实现方式、原理及技术效果与步骤s103的实现方式、原理及技术效果,详细内容可参考前述描述,在此不再赘述。
[0142]
本技术实施例提供的测试用例处理方法,对于采集到的行驶车辆的多个维度的属性信息利用预设分类处理规则基于属性信息的维度特征进行分类,然后基于不同类型的各分类属性信息获得每个分类属性信息的数据权重,进而根据所有测试用例的各关联测试场景选择与其具有相同维度特征的分类属性信息确定每个测试用例的相关权重,最后根据相
关权重得到该测试用例的综合权重,以最终确定每个测试用例的测试优先级。基于不同维度特征对多个维度的属性信息进行分类可以细化维度,并针对不同的维度特征采用不同的计算方法得到各分类属性信息的数据权重,进而可以获取到所有测试用例的所有关联测试场景所属维度的权重,也即相关权重。进一步从维度特征的角度进行测试用例处理,以得到每个测试用例所关联测试场景所属维度的权重,确保每个测试用例的关联测试场景所属维度的权重与行驶车辆的实际使用情况强关联,有利于提高最终所确定的测试用例的综合权重的准确性。
[0143]
在上述实施例的基础上,针对维度特征具有排名属性的目标属性信息,确定目标属性信息所属维度的权重的可能实现方式如图6所示。图6为本技术实施例提供的又一种测试用例处理方法的流程示意图。如图6所示,本技术实施例包括:
[0144]
s301:获取目标属性信息中的特征数据与对应排行类属性信息中的特征数据之间的交集。
[0145]
s302:若交集为空,则目标属性信息所属维度的权重为零。
[0146]
s303:若交集非空,对非空的交集包括的各特征数据的权重进行求和运算,将得到的求和运算结果确定为目标属性信息所属维度的权重。
[0147]
目标属性信息假设为所有测试用例中描述车主出生地的信息,则关联测试场景即为“车主出生地”这一维度的测试场景。假设目标属性信息的各特征数据为【广东,广西,江苏】,根据步骤s2031中得到“车主出生地”这一维度特征的排行类属性信息的top3的排行为【浙江,广东,江苏】,显然,测试用例的特征数据与对应排行类属性信息的特征数据的交集为【广东,江苏】,为非空的交集,进一步对非空的交集所包括的各特征数据的权重进行求和运算,将得到的求和运算结果确定为目标属性信息所属维度的权重。在步骤s2031中已得到特征数据的权重分别为w
广东
和w
江苏
,将两者求和,得到的求和结果即为“车主出生地”这一维度特征的目标属性信息所属维度的权重w
bp
如下公式(9)所示:
[0148][0149]
反之,若交集为空,则该目标属性信息所属维度的权重为零。
[0150]
上述描述是以“车主出生地”这一具有排名属性维度特征的目标属性信息为例说明,可以理解的是,对于其他具有排名属性维度特征的目标属性信息,均可以采用图6所示方式得到该目标属性信息所属维度的权重,在此不再赘述。例如对于“行驶区域”、“语音交互范畴”、“语音交互功能”以及“车型”具有排名属性维度特征的目标属性信息所属维度的权重,依次可以表示为wr,wd,wf,wm。
[0151]
本技术实施例提供的测试用例处理方法,针对与排行类属性信息具有相同维度特征的目标属性信息,获取目标属性信息中的特征数据与对应排行类属性信息中的特征数据之间交集,若交集为空则该目标属性信息所属维度的权重为零。若交集非空,将该非空的交集所包括的各特征数据的权重进行求和运算,求和结果对目标属性信息所属维度的权重,得到维度特征为排名属性的该维度的权重,以备后续获得每个测试用例综合权重使用。
[0152]
在上述实施例的基础上,针对维度特征具有比重属性的目标属性信息,确定目标属性信息所属维度的权重可能实现方式如图7所示。图7为本技术实施例提供的又一种测试用例处理方法的流程示意图。如图7所示,本技术实施例包括:
[0153]
s401:获取目标属性信息中的性别字段;
[0154]
s402:将比重类属性信息中的各特征数据与性别字段进行一致性匹配操作,以将匹配到的特征数据的数量比重确定为目标属性信息所属维度的权重。
[0155]
获取目标属性信息中的性别字段,性别字段可以例如车主为男性或车主为女性。将步骤s2032中得到的比重类属性信息中的各特征数据的数量比重w
男
和w
女
与目标属性信息中的性别字段进行一致性匹配,若性别字段为车主为男性,则目标属性信息所属维度的权重即为w
男
,若性别字段为车主为男性,则目标属性信息所属维度的权重即为w
女
。
[0156]
换言之,若目标属性信息中的性别字段是车主为男性,则目标属性信息所属维度的权重w
gender
为w
男
,相应地,若目标属性信息中的性别字段是车主为女性,则目标属性信息所属维度的权重w
gender
为w
女
。
[0157]
其中,本技术实施例对于实现一致性匹配操作和获取性别字段的方式的具体手段不作限定。
[0158]
本技术实施例提供的测试用例处理方法,针对与比重类属性信息具有相同维度特征的目标属性信息,获取目标属性信息中的性别字段,然后将性别字段与比重类属性信息中的各特征数据进行一致性匹配,将匹配到的特征数据的数量比重确定为目标属性信息所属维度的权重,得到维度特征为比重属性的该维度的权重,以备后续获得测试用例综合权重使用。
[0159]
在上述实施例的基础上,针对维度特征具有分布属性的目标属性信息,确定目标属性信息所属维度的权重可能实现方式如图8所示。图8为本技术实施例提供的又一种测试用例处理方法的流程示意图。如图8所示,本技术实施例包括:
[0160]
s501:根据目标属性信息对应的分布数据直方图确定目标属性信息中的特征数据的分布边界。
[0161]
s502:根据分布边界以及对应分布类属性信息中各特征数据的分布频数,确定目标属性信息对应的目标总频数以及边界频数。
[0162]
s503:对目标总频数与边界频数进行求差运算,将得到的求差运算结果确定为目标属性信息所属维度的权重。
[0163]
本技术实施例提供的确定目标属性信息所属维度的权重适用于维度特征具有分布属性的维度,例如“车主年龄”和“语音交互语速”的这些维度的权重计算。
[0164]
首先根据目标属性信息对应的分布数据直方图找出目标属性信息中的特征数据的分布边界,若目标属性信息的维度为“车主年龄”,则该维度的目标属性信息对应的分布数据直方图为行驶车辆的车主年龄信息对应的分布数据直方图,若目标属性信息的维度为“语音交互语速”,则该维度的目标属性信息对应的分布数据直方图为行驶车辆的语音交互语速信息对应的分布数据直方图。
[0165]
从目标属性信息对应的分布数据直方图中找出目标属性信息中的特征数据的分布边界,假设找出的目标属性信息中的特征数据的左边界为x
left
(如果x
left
≤x
min
,则令x
left
=x
min
ε)和右边界为x
right
(如果x
right
≥x
max
,则令x
right
=x
max-ε),(如图5中s3和s4所示),其中ε为趋近于0的阈值。其次在左边界处找到与x
left
紧邻且小于x
left
的分布坐标xk(如图5中s6所示),在右边界处找到与x
right
紧邻且大于x
right
的分布坐标x
k m
(如图5中s7所示)。再计算xk~x
k m
之间所有矩形的面积之和s
sum
,该面积之和即为目标属性信息对应的目标总频数,
其中矩形的底和高在步骤s2023中已得到,可直接使用矩形的面积公式计算即可。
[0166]
最后进行左右边界的处理得到目标属性信息对应的边界频数。具体地,在左边界矩形处(如图5中s
10
所示的矩形的面积)计算出矩形的面积s
left
,在右边界矩形出(如图5中s
11
所示的矩形的面积)计算出矩形的面积s
right
,然后利用如下公式(10)和(11)计算出分布边界的左边界未包括在内区域的矩形面积s
r_left
和分布边界中右边界未包括在内区域的矩形面积s
r_right
,左右侧未包括在内区域的矩形面积之和为边界频数。公式(10)和(11)如下所示:
[0167][0168][0169]
进一步对目标总频数与边界频数进行求差运算,即从xk~x
k m
之间所有矩形的面积之和中剔除分布边界x
left
和x
right
未包括在内区域的面积,得到求差运算结果即为分布边界所包括在内区域矩形的面积,该面积即为目标属性信息所属维度的权重。
[0170]
求差运算如下公式(12)所示:
[0171]
w0=s
sum-(s
r_left
s
r_right
)
ꢀꢀꢀ
(12)
[0172]
其中,若目标属性信息的维度为“车主年龄”,则w0为w
ag
以表示测试用例中“车主年龄”这一维度的权重,若目标属性信息的维度为“语音交互语速”,则w0为ws以表示测试用例中“语音交互语速”这一维度的权重。
[0173]
以下以目标属性信息的维度为“车主年龄”举例说明本实施例。
[0174]
假设日志信息中行驶车辆的车主年龄信息具体为:车主年龄在21~25岁年龄区间的为993人,车主年龄在26~30岁年龄区间的为1250人,车主年龄在31~35岁年龄区间的为1790人,车主年龄在36~40岁年龄区间的为2037人,车主年龄在41~45岁年龄区间的为3041人,车主年龄在46~50岁年龄区间的为2132人,车主年龄在51~55岁年龄区间的为1630人,车主年龄在56~60岁年龄区间的为1103人,车主年龄在61~65岁年龄区间的为893人,则各特征数据的总数量c
sample
如下公式(13)所示:
[0175]csample
=993 1250 1790 2037 3041 2132 1630 1103 893=14869
ꢀꢀꢀ
(13)
[0176]
假设根据步骤s2033得到的行驶车辆的车主年龄信息对应的分布数据直方图,得到上述各年龄区间在分布数据直方图中所对应矩形的高度依次如下公式(14)~(22)所示:
[0177][0178]
假设测试用例的关联测试场景所涉及的车主年龄区间为32~53岁,则该目标属性
信息即为描述该关联测试场景的信息,确定该目标属性信息所属维度的权重也即“车主年龄”这一维度的权重w
ag
计算方法如下:
[0179]
(1)、首先在行驶车辆的车主年龄信息对应的分布直方图中找到与数值32相邻且小于32的分布坐标31,与数值53相邻且大于53的分布坐标55,分布坐标31和55则为目标属性信息中特征数据的分布边界;
[0180]
(2)、30~55岁区间中所有直方图矩形的面积如下公式(23)所示:
[0181]s′
sum
=5*(0.024 0.027 0.040 0.028 0.021)=0.7
ꢀꢀꢀ
(23)
[0182]
0.7即为年龄区间为32~53岁的该目标属性信息对应的目标总频数。
[0183]
(3)、左右边界处理;
[0184]
根据上述公式(10)和(11)则分别得到左侧和右侧的边界频数,如下公式(24)和(25)所示:
[0185][0186][0187]
0.024与0.042之和即为年龄区间为32~53岁的该目标属性信息对应的边界频数。
[0188]
(4)、年龄区间为32~53岁之间的该目标属性信息所属维度的权重w
′
ag
如下公式(26)所示:
[0189]w′
ag
=0.7-(0.024 0.042)=0.634
ꢀꢀꢀ
(26)
[0190]
本技术实施例提供的测试用例处理方法,针对与分布类属性信息具有相同维度特征的目标属性信息,基于目标属性信息对应的分布数据直方图首先得到目标属性信息中特征数据的分布边界,然后得到目标属性信息对应的目标总频数和边界频数,最后得到目标属性信息所属维度的权重,以计算出维度特征为分布属性的该维度的权重,以便于后续获得测试用例综合权重使用。
[0191]
在上述实施例的基础上,针对维度特征具有计数属性的目标属性信息,确定目标属性信息所属维度的权重可能实现方式包括:
[0192]
从统计类属性信息中各特征数据的数据量占比中获取最大的数据量占比,然后将最大的数据量占比确定为具有计数属性的维度特征的这一维度的的权重,也即目标属性信息所属维度的权重。其中,最大的数据量占比用于表征维度特征为计数属性的该目标属性信息的最大并发数量。
[0193]
例如,多个等长时间周期分别为本月和上月,假设从上月行驶车辆的语音交互数量信息中获知上月语音交互数量为c
i-1
,本月语音交互数量为ci,则目标属性信息为“语音交互数量”这一维度的权重w
pm
可以如下公式(27)得到:
[0194]wpm
=max(c
i-1
,ci)/(c
i-1
ci)
ꢀꢀꢀ
(27)
[0195]
在实际工况中,将“语音交互数量”这一维度的权重可以看作压测权重,压测权重越大,则在压力测试时可适当增大测试用例的并发数量。
[0196]
本技术实施例提供的测试用例处理方法,针对与计数类属性信息具有相同维度特征的目标属性信息,将统计类属性信息中各特征数据的数据量占比中最大的数据量占比确定为该维度特征的目标属性信息所属维度的权重,以计算出维度特征为计数属性的该维度
的权重,以便于后续获得测试用例综合权重使用。
[0197]
上述实施例描述了对于不同维度特征的维度如何确定其权重的实现方式,以能够得到所有测试用例的各关联测试场景所属维度的权重,即测试用例的相关权重。在确定相关权重的方式中结合行驶车辆的日志信息,可以确保关联测试场景所属维度的权重与行驶车辆的实际使用情况强关联,进而利用综合权重确定测试用例的优先级,能够确保与行驶车辆实际使用中关联度最高的测试用例被优先执行,便于尽早发现对产品影响最大的问题所在。并且通过确定每个测试用例的测试优先级,使得测试具有侧重点,可以有效降低测试成本和缩短测试周期。
[0198]
图9为本技术实施例提供的一种测试用例处理装置的结构示意图。如图9所示,本技术实施例提供的测试用例处理装置600,包括:
[0199]
采集模块601,用于采集行驶车辆的日志信息。
[0200]
其中,日志信息包括行驶车辆多个维度的属性信息。
[0201]
第一处理模块602,用于根据预设权重处理策略以及各维度的属性信息确定测试用例的相关权重。
[0202]
其中,相关权重包括所有测试用例的各关联测试场景所属维度的权重。
[0203]
第二处理模块603,用于根据相关权重确定每个测试用例的综合权重,以根据每个测试用例的综合权重确定每个测试用例的测试优先级,测试优先级用于在测试阶段使得优先级高的测试用例优先测试。
[0204]
在一种可能的设计中,第一处理模块602,包括:
[0205]
分类模块,用于利用预设分类处理规则对各维度的属性信息进行分类处理,得到各分类属性信息,各分类属性信息包括排行类属性信息、比重类属性信息、分布类属性信息以及统计类属性信息;
[0206]
第一权重处理模块,用于基于各分类属性信息确定各分类属性信息的数据权重,数据权重用于表征各分类属性信息中的各特征数据的权重;
[0207]
第二权重处理模块,用于根据各测试用例和各分类属性信息各自的数据权重确定测试用例的相关权重。
[0208]
在一种可能的设计中,第一权重处理模块,具体用于:
[0209]
对排行类属性信息进行排序及数值化处理,以将排行类属性信息转化为序列数据,并采用预设数值权重算法确定序列数据中各数值的权重,各数值的权重用于表征排行类属性信息中各特征数据的权重;
[0210]
根据比重类属性信息中各特征数据的数量比重确定比重类属性信息中各特征数据的权重;
[0211]
利用分布数据直方图确定分布类属性信息中各特征数据的分布频数,各特征数据的分布频数用于表征分布类属性信息中各特征数据的权重;
[0212]
在多个等长时间周期内,获取统计类属性信息中各特征数据的数据量,确定每个等长时间周期对应的数据量在多个等长时间周期内总的数据量中的数据量占比,各数据量占比用于表征统计类属性信息中各特征数据的权重。
[0213]
在一种可能的设计中,第二权重处理模块,包括:
[0214]
第一处理子模块,用于根据各测试用例的关联测试场景确定目标属性信息,目标
属性信息用于描述测试用例的关联测试场景;
[0215]
第二处理子模块,用于针对与排行类属性信息具有相同维度特征的目标属性信息,根据目标属性信息、排行类属性信息的数据权重以及排行类属性信息确定目标属性信息所属维度的权重;
[0216]
第三处理子模块,用于针对与比重类属性信息具有相同维度特征的目标属性信息,根据目标属性信息、比重类属性信息的数据权重以及比重类属性信息确定目标属性信息所属维度的权重;
[0217]
第四处理子模块,用于针对与分布类属性信息具有相同维度特征的目标属性信息,根据目标属性信息、分布类属性信息的数据权重以及分布类属性信息确定目标属性信息所属维度的权重;
[0218]
第五处理子模块,用于针对与统计类属性信息具有相同维度特征的目标属性信息,根据目标属性信息、统计类属性信息的数据权重以及统计类属性信息确定目标属性信息所属维度的权重。
[0219]
在一种可能的设计中,第二处理子模块,具体用于:
[0220]
获取目标属性信息中的特征数据与对应排行类属性信息中的特征数据之间的交集;
[0221]
若交集为空,则目标属性信息所属维度的权重为零;
[0222]
若交集非空,对非空的交集包括的各特征数据的权重进行求和运算,将得到的求和运算结果确定为目标属性信息所属维度的权重。
[0223]
在一种可能的设计中,第三处理子模块,具体用于:
[0224]
获取目标属性信息中的性别字段;
[0225]
将比重类属性信息中的各特征数据与性别字段进行一致性匹配操作,以将匹配到的特征数据的数量比重确定为目标属性信息所属维度的权重。
[0226]
在一种可能的设计中,第四处理子模块,具体用于:
[0227]
根据目标属性信息对应的分布数据直方图确定目标属性信息中的特征数据的分布边界;
[0228]
根据分布边界以及对应分布类属性信息中各特征数据的分布频数,确定目标属性信息对应的目标总频数以及边界频数;
[0229]
对目标总频数与边界频数进行求差运算,将得到的求差运算结果确定为目标属性信息所属维度的权重。
[0230]
在一种可能的设计中,第五处理子模块,具体用于:
[0231]
从统计类属性信息中各特征数据的数据量占比中获取最大的数据量占比,以将最大的数据量占比确定为目标属性信息所属维度的权重,最大的数据量占比用于表征目标属性信息的最大并发数量。
[0232]
在一种可能的设计中,第二处理模块,具体用于:
[0233]
为每个相关权重自定义对应的权重系数;
[0234]
根据每个测试用例的关联测试场景确定每个测试用例的各目标维度;
[0235]
获取各目标维度对应的各相关权重和权重系数之间的乘积,并将得到的各乘积求和,确定求和结果为每个测试用例的综合权重。
[0236]
在一种可能的设计中,第二处理模块,还具体用于:
[0237]
对每个测试用例的综合权重按照由大到小排序,得到每个测试用例的测试优先级。
[0238]
可选地,排行类属性信息包括行驶车辆的车主出生地信息、行驶车辆的行驶区域信息、行驶车辆的语音交互范畴信息、行驶车辆的语音交互功能信息以及行驶车辆的车型信息;
[0239]
比重类属性信息包括行驶车辆的车主性别信息;
[0240]
分布类属性信息包括行驶车辆的车主年龄信息以及语音交互语速信息;
[0241]
统计类属性信息包括行驶车辆的语音交互数量信息。
[0242]
本技术实施例提供的测试用例处理装置,可以执行上述方法实施例中的测试用例处理方法的相应步骤,其实现原理和技术效果类似,在此不再赘述。
[0243]
图10为本技术实施例提供的一种电子设备的结构示意图。如图10所示,该电子设备700可以包括:处理器701,以及与处理器701通信连接的存储器702。
[0244]
存储器702,用于存放程序。具体地,程序可以包括程序代码,程序代码包括计算机执行指令。
[0245]
存储器702可能包含高速ram存储器,也可能还包括非易失性存储器(mom-volatile memory),例如至少一个磁盘存储器。
[0246]
处理器701用于执行存储器702存储的计算机执行指令,以实现测试用例处理方法。
[0247]
其中,处理器701可能是一个中央处理器(cemtral processimg umit,简称为cpu),或者是特定集成电路(applicatiom specific imtegrated circuit,简称为asic),或者是被配置成实施本技术实施例的一个或多个集成电路。
[0248]
可选地,存储器702既可以是独立的,也可以跟处理器701集成在一起。当存储器702是独立于处理器701之外的器件时,电子设备700,还可以包括:
[0249]
总线703,用于连接处理器701以及存储器702。总线可以是工业标准体系结构(industry standard architecture,简称为isa)总线、外部设备互连(peripheral component,pci)总线或扩展工业标准体系结构(extended industry standard architecture,eisa)总线等。总线可以分为地址总线、数据总线、控制总线等,但并不表示仅有一根总线或一种类型的总线。
[0250]
可选的,在具体实现上,如果存储器702和处理器701集成在一块芯片上实现,则存储器702和处理器701可以通过内部接口完成通信。
[0251]
本技术还提供了一种计算机可读存储介质,该计算机可读存储介质可以包括:u盘、移动硬盘、只读存储器(rom,read-omly memory)、随机存取存储器(ram,ramdom accessmemory)、磁盘或者光盘等各种可以存储程序代码的介质,具体的,该计算机可读存储介质中存储有计算机执行指令,计算机执行指令用于上述实施例中的测试用例处理方法。
[0252]
本技术还提供了一种计算机程序产品,包括计算机指令,该计算机指令被处理器执行时实现上述实施例中的测试用例处理方法。
[0253]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本技术的其
它实施方案。本技术旨在涵盖本技术的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本技术的一般性原理并包括本技术未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本技术的真正范围和精神由权利要求书指出。
[0254]
应当理解的是,本技术并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本技术的范围仅由所附的权利要求书来限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。