一种面向数据i/o优化的自适应微服务调度系统
技术领域
1.本发明属于涉及信息技术领域,尤其是涉及一种面向数据i/o优化的自适应微服务调度方法,主要用于提升云计算和边缘计算复杂环境中基于微服务的应用系统的运行性能,特别是降低存储i/o延迟。
背景技术:
2.智慧园区和智慧城市作为典型大规模人工智能应用场景,涉及大量重量繁杂的数据i/o,特别是计算、存储和网络环境配置复杂,引出i/o速率收应用程序运行位置及数据源所在位置影响。云计算和边缘计算协同的方式使数据密集和通信密集的应用系统对缩短数据通路提升i/o成为提升应用系统运行效率的主要计算调整。微服务1为提供应用系统构建提供了模块化标准,并具备高可用特性,作为构建大型应用系统的实现方式已经广泛落地。
3.面向人工智能计算的微服务往往需要访问多种数据源或数据湖系统,数据的位置对数据i/o效率产生关键影响,例如在分布式存储系统中,微服务的执行节点与数据存储节点一致或接近,将极大提升数据处理的效率。本项发明通过以动态采样机制获取微服务对数据源的i/o频率和容量的统计数据,并根据其运行环境的数据通道进行动态调整,缩短数据通路,降低i/o延迟,从而提升微服务运行的效率。
技术实现要素:
4.本发明提供了一种基于运行时状态分析来进行微服务调度并提升数据读写效率的技术。微服务系统已经成为构建大型复杂应用的基础技术平台之一,通过将模块化的信息处理单元以轻量级虚拟机方式进行封装,实现高容错能力。通过服务网格的方式将各种应用功能进行编排,实现稳定的大型复杂应用系统。微服务需要访问多种数据源,数据的位置是影响数据读写效率的关键因素,大型复杂应用系统的数据访问涉及结构化数据看、非结构化数据库、对象存储、文件存储等,而各种数据源可以集中式存储系统或分布式数据平台来实现,因此数据本地化往往会成为应用性能优化的关键,特别是在网络环境下构建的分布式存储系统中,缩短访i/o通道延迟是提升访存效率的关键。针对大型应用中微服务对数据访问密集场景的效率问题,本项发明提出了一种基于对数据读写的运行时状态进行分析,确定微服务调度执行的最佳位置的技术,通过缩短数据通路来有效提升数据i/o效率,提升在构建基于微服务的大型数据密集性应用系统的性能。
5.为实现上述目的,本发明通过编译器技术3在微服务中植入与存储i/o相关的采样点,并向微服务调度器发送采样信息,由调度器分析存储读写效率并搜索更优化的微服务运行位置,实现降低存储读写延迟。调度优化过程发生在基于微服务应用的运行过程中,并在运行环境改变是自动进行重新决策,保持应用系统的访存成本始终控制在优化水平。本项发明适用于云-边协同环境,即计算效能、通信和存储i/o速率存在复杂配置的运行环境。
6.本项发明包含3部分:1.基于编译器技术的存储i/o采样代码植入;2. 调度器通过采样代码获取的存储i/o信息,在运行时分析基于微服务系统的存储i/o状态,计算最佳访
存位置;3.基于最佳访存位置进行动态调度,将微服务安排至访存效率最优的位置,并通过运行环境改变动态触发访存位置的重计算与调度。
附图说明
7.图1采样代码植入;图2基于价值模型来计算优化任务调度策略(即微服务的优化调配)的例子;图3为操作执行流程图;图4为效果流程图。
具体实施方式
8.本项发明的实现方式包括静态代码分析与植入和运行时的存储i/o状态分析、微服务重调度。静态代码分析与植入通过编译器插件分析微服务代码,主要关注在与存储操作相关的代码(api)部分植入采样代码。微服务调度系统在运行时收集存储i/o状态统计信息,为微服务搜索最佳执行位置,并进行在线重调度。当运行环境改变时重新计算防存位置并进行调度,这里运行环境改变是指存储读写的位置发生变化(例如应用微服务从一个对象存储转向另一个对象存储的场景)。
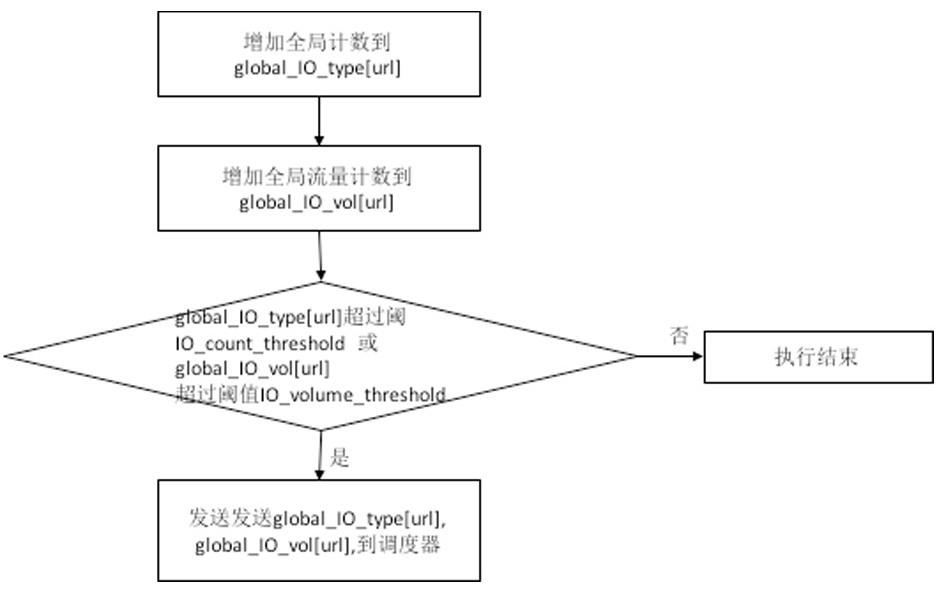
9.基于编译器的存储i/o采样代码植入通过编译器扫描微服务程序,并在每个存储i/o 操作之前插入采样函数,如图1所示。采样函数每次被调用都会更新针对存储i/o地址的计数,如果计数达到阈值,则向调度中心发送统计信息,包括计数内容、参与读写的地址。
10.采样函数伪代码执行步骤如图3所示:url表示设备编号,size表示流量计数计数信息包括进行存储读写的次数和读写数据容量,触发向调度器发送统计信息的条件也包含读写数据容量达到容量阈值。读写次数阈值和读写数据容量阈值均对应用某类存储(通过url来表示),因此需要一个全局表来维护。存储类型包含本地磁盘读写、san读写、nas读写、对象存储读写以及数据库访问等。
11.对于不同类型编程语言实现的微服务,可以通过不同类型编译器以基于源代码、中间代码或二进制代码的方式进行分析和代码植入。采样函数作为单独的函数库挂接于微服务实现中。语言类型分析与采样代码植入方式c/c 分析二进制文件并插入采样函数调用java分析bytecode文件并插入采样函数调用python分析源程序文件并插入采样函数调用
12.计算最佳访存位置,并基于最佳访存位置进行动态调度:最佳访存位置通过搜索计算集群中对于微服务a访存成本最低的节点,如果该节点已被占用,则搜索剩余节点中访存成本最低的节点。调度器通过收集采样信息得到微服务a的存储访问信息,包括a访问存储的列表s = {s0, s1,
ꢀ…ꢀ
sn}和访问列表中存储系统的频率f={f0, f1,
ꢀ…ꢀfn }和数据容量v = {v0, v 1
,
ꢀ…ꢀ
v n
}。通过f和v计算出每项存储在计算访存成本时的权重。最佳防存位置计算的算法表示如图4所示。
13.输入:当前微服务a,计算集群cluster输出:a的最佳运行节点该算法通过计算微服务a在计算集群中每个节点中的存储i/o操作成本,寻找最优节点,即存储i/o操作成本最低的节点。如果找到的最优节点无法成功分配,则寻找次优节点。
14.计算存储i/o操作成本的函数sc(a, node)可表示为:sc(a, node) = sum
1..n (channel_cost(si,node) * wi), si这里对应于被a访问存储系统列表只能够第i个存储,wi表示其对应的权重,channel_cost表示计算计算存储到节点node之间的访问成本。channel_cost函数的定义需要根据用户实际部署场景中的经验值来设定。sum表示为求和。
15.wi的计算表示为wi= (f
i * r / sum
1..n
(fi) v
i * (1
ꢀ‑ꢀ
r) / sum
1..n (vi)) / 2;r表示为大于0且小于等于1的数值,这里可以看出对于权重的计算将存储访问频率和数据读写量同时考虑,通过r来界定频率与容量之间的占比。
16.图2给出了通过动态优化,计算最佳防存位置的例子。图中微服务b在节点1和2都有访存操作(防存的流量通过数据流线的粗细表达),其中对远程节点(节点2)的数据流量大于本地节点(节点1),因此计算所得的最佳执行位置为节点。
17.通过运行环境改变动态触发访存位置的重计算与调度:上述调度安排时基于当前微服务访问存储的成本在计算集群中搜索最佳运行节点,集群包含云端计算节点和边缘端计算节点,因此距离数据最近的位置通常为最佳运行节点,且位置相对固定。对于微服务可能的重调度仅发生与2种情况:1. 集群环境发生变化:包括新加入计算节点,其访存成本较之当前运行节点可能更低,或当前节点变为不可用;又或者存储系统的访问成本发生变化,需要重新计算总体防存成本;2. 微服务本身的防存状态发生变化:一部分存储不再被访问,或新增加一部分存储访问,因此需要重新计算访存成本。
18.对于上述2类情况,集群调度器需要重新计算每个微服务的访存成本并安排进行重新调度,以确保微服务始终处于优化的访存状态。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。