基于spark的地铁站疏散风险分析方法
技术领域
1.本发明涉及地铁站应急疏散管理技术领域,具体地,涉及基于spark的地铁站疏散风险分析方法。
背景技术:
2.地铁事故会导致重大的财产损失和人员伤亡,其主要伤亡损失是由事故本身的危害性造成的,但也有一部分伤亡损失是由于事故发生后没有及时和有效的进行安全疏散,而导致事故严重性扩大甚至造成二次事故的发生。由于地铁站的封闭性和本身结构的复杂性,突发事件发生时,疏散不利会使得事故的严重程度进一步升级,造成了额外的人员伤亡。每一起重大事故背后都隐藏着数倍的安全隐患。如果我们可以从地铁站在应急疏散过程中的安全隐患入手,预先找出并消除其中的隐患,就可以降低重大事故的发生可能性。
3.在当今时代下,各类行业安全问题的研究朝着大数据的方向发展是不可逆转的趋势,大数据环境下基于历史事故信息,运用关联规则算法对地铁站疏散风险进行分析,从而实现对地铁站运营过程中安全隐患进行及时排除,保障乘客和工作人员的安全。使得地铁站安全管理人员能够全面的了解地铁站运营的当前状况,一旦发生恶性突发事故和风险就可以及时作出合适的反应措施,规避可能存在的风险。
技术实现要素:
4.针对现有技术中的缺陷,本发明的目的是提供一种基于spark的地铁站疏散风险分析方法。
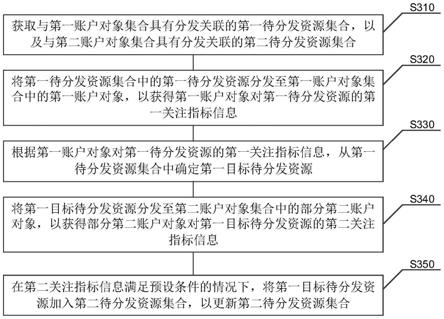
5.根据本发明提供的一种基于spark的地铁站疏散风险分析方法,包括如下步骤:
6.对地铁站疏散失败的历史相关事故进行致因分析处理,确定导致事故发生的风险主要因素,将所述主要因素进行分类,确定疏散风险指标;
7.搭建分布式流式处理框架构建数据仓库,将所述数据仓库中所述疏散风险指标的数据进行处理,建立风险指标库;
8.采用关联规则算法并行关联规则挖掘算法对风险指标库中各个所述疏散风险指标进行强关联规则的挖掘分析,建立并行关联规则挖掘算法的风险分析模型。
9.可选地,致因分析从人员因素、设备因素、管理因素和环境因素四个方面进行详细分析与筛选,确定人因风险、设备风险、管理风险和环境风险四种类型。
10.可选地,通过flume集群和hdfs集群对疏散风险指标数据和地铁站客流量进行采集并存贮在数据仓库中。
11.可选地,将疏散风险指标的数据进行处理包括抽取、清洗、转换和统计。
12.可选地,采用关联规则算法并行关联规则挖掘算法对各个疏散风险指标进行强关联规则的挖掘分析进一步包括:
13.使用flatmap将事务集以字符串函数的形式分布到多个机器上来产生频繁1-项集,使用flatmap将事务集以字符串函数的形式分布到多个机器上;
14.使用reducebykey累计候选项1-项集数量,使用过滤器筛除小于最小值支持度的项集;
15.通过频繁k项集产生候选k 1项集。
16.可选地,通过将vue.js框架和echarts开源库的融合,对风险分析模型输出的数据分析结果进行实时调取和展示。
17.与现有技术相比,本发明具有如下的有益效果:
18.本发明提供的基于spark的地铁站疏散风险分析方法,首先通过搭建数据仓库完成数据的处理工作,然后采用并行化的apriori关联规则算法对风险指标数据进行进一步的分析和挖掘,最后通过得到的风险分析模型输出风险分析结果。安全管理人员通过分析结果可以找出地铁站内应急疏散漏洞,提出具有针对性的预防对策和建议,有助于站内疏散管理方法和预案的制定、应急疏散设施的设计提供相应的改进措施,提高地铁站的安全性,为大数据时代下地铁站安全运营提供一定的参考价值。
附图说明
19.通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
20.图1是本发明实施例的基于spark的地铁站疏散风险分析方法的总体流程图;
21.图2是本发明实施例的基于spark的地铁站疏散风险分析方法的架构设计图;
22.图3是本发明实施例的基于spark的地铁站疏散风险分析方法的层级图;
23.图4是本发明实施例的基于并行化的apriori算法风险分析处理流程图。
具体实施方式
24.下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
25.在对本发明的实施例进行解释说明之前,先对涉及的名词结合本实施例进行介绍说明:
26.apriori:是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。而且算法已经被广泛的应用到商业、网络安全等各个领域;
27.spark streaming框架:spark streaming是一个基于spark core之上的实时计算框架,可以从很多数据源消费数据并对数据进行处理。
28.spark streaming是spark核心api的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理,他支持从多种数据源来获取数据,kafka,flume,twitter,zeromq,kinesis以及tcp sockets,从数据源获取数据之后,可以使用诸如map,reduce,join和window等高级函数进行复杂算法的处理,最后我们还可以将处理结果存储到文件系统、数据库和现场仪表盘。在“one stack rule them all”的基础上,还可以使用spark的其他子框架,如集群学习、图计算等,对流数据进行处理。
29.map:其作用很容易理解就是对rdd(弹性分布式数据集)之中的元素进行逐一进行函数操作映射为另外一个rdd。
30.flatmap:其是将函数应用于rdd之中的每一个元素,将返回的迭代器的所有内容构成新的rdd,通常用来切分单词。
31.reducebykey:其作用就是对相同key的数据进行处理,最终每个key只保留一条记录。
32.saveassequencefile:其用于将rdd以sequencefile文件格式保存在hdfs上;
33.flume:是cloudera提供的一个高可用的高可靠的,分布式的海量日志采集、聚合和传输的系统;
34.kafka:其是一种高吞吐量的分布式发布订阅消息系统;
35.vue.js框架:是一个javascriptmvvm库,是一套构建用户界面的渐进式框架;
36.echarts开源库:是一款基于javascript的数据可视化图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。
37.图1为本发明提供的基于spark的地铁站疏散风险分析方法的原理框图,如图1所示,本发明中的方法可以包括如下步骤:
38.对地铁站疏散失败的历史相关事故进行致因分析,确定导致事故发生的风险主要因素,将主要因素进行分类,确定疏散风险指标;
39.在本实施例中,致因分析从人员因素、设备因素、管理因素和环境因素四个方面进行分析与筛选;
40.从而确定出确定人因风险、设备风险、管理风险和环境风险四种类型;
41.其中,人因风险:包括乘客倒地、惊跑、折返逆行、推搡拥挤以及地铁站工作人员安全意识低、应急能力差等不安全行为;
42.设备风险:包括电力系统故障、自动扶梯故障、自动闸门故障、信号系统故障、报警系统故障、消防系统故障、照明系统故障、广播系统故障和疏散标识系统故障等;
43.管理风险包括疏散预案制定不合理、车站设备检查频率低、疏散设施维护不及时、疏散演练实效性低、应急组织机构不完善、疏散安全信息宣传少、站内风险隐患排查不及时、员工安全培训不到位、安全规范未能有效落实、信息沟通不畅和应急疏散设施不足等;
44.环境风险包括火灾、水灾、爆炸、恐怖袭击、地面湿滑、站内能见度低、人群密度严超地铁站承载和地铁隧道建设不达标等。
45.搭建分布式spark streaming框架构建数据仓库,将数据仓库中疏散风险指标的数据进行处理,建立风险指标库;
46.请参阅图2,在本实施例中,flume集群获取日志服务器中的数据,通过flume集群和hdfs集群对疏散风险指标数据和地铁站客流量进行采集并存贮在数据仓库中,数据仓库采用hive数据仓库,其中,hive数据仓库包括数据目标源层、数据分析层、数据运算层和数据存储层,kafka集群对flume集群获取日志服务器中的数据进行获取发送至处理系统,其中,处理系统能够进行实时计算和离线计算,完成致因分析,然后,疏散分析系统对数据仓库中疏散风险指标的数据进行处理的方式为抽取、清洗、转换和统计;
47.请参阅图4,对hdfs集群中疏散风险指标的数据进行转换的流程包括:
48.读取疏散风险指标文本文件中的数据,获取风险因子,若干风险因子组成疏散风
险指标数据;然后,
49.stag1,将疏散风险指标数据依次进行flatmap和map操作;
50.stag2,对进行flatmap和map操作后的数据,进行reducebykey处理,最后通过saveassequencefile将文件以sequencefile文件格式保存在hdfs集群上。
51.采用关联规则算法并行apriori(关联规则挖掘算法)对各个疏散风险指标进行强关联规则的挖掘分析,建立并行apriori的风险分析模型。
52.在本实施例中,建立并行apriori的风险分析模型的具体包括两步骤:
53.第一步为产生频繁1-项集,首先使用flatmap将事务集d以《string,1》的形式分布到多个机器上,其中《string,1》的形式为字符串函数的形式;然后使用reducebykey累计候选1-项集数量,使用filter筛除小于最小值支持度的项集;
54.第二步为从频繁k项集产生频繁k 1项集。通过频繁k项集产生候选k 1项集,根据步第一步的方法产生频繁k 1项集。
55.在一种可选的实施方式中,通过将vue.js框架和echarts开源库的融合,对风险分析模型输出的数据分析结果进行实时调取和展示。
56.在本实施例中,通过上述方法对数据分析结果进行实时调取和展示,风险分析结果可以实现可视化,其中可视化是指将原始数据进行一系列处理后,以图形化的方式进行表示,使繁杂的、不能直接读取的数据信息,转换成数据结果和结论。让相对复杂的原始数据更加直观、容易理解。要实现疏散风险分析结果的可视化需要生成很多图表,例如折线图、饼状图等各种形状和样式的图表以及图的嵌套组合,而且这些图表得是可交互的,要实现这个功能必须选用数据可视化的工具库。
57.echarts是一个基于javascript语言的实现数据可视化的百度开源库。通过特色各异的工具箱等基础组件组成了功能完备、形态各异的图表库。通常包括饼状图、趋势图、柱状图、词云。vue.js是一种开源的用来建构用户界面的渐进式javascript框架,是一种建构单页面应用的web应用框架。
58.vue.js专注于视图的操作,vue.js框架可以完美的融合echarts从而实现地铁站疏散风险分析结果的可视化。
59.请参阅图3,通过上述方法可以构建基于spark的地铁站疏散风险分析系统,其系统包括:
60.服务层:服务层包括地铁安全管理人员和地铁工作人员;
61.业务层:包括各类风险分析结果图表查询、风险指标管理、历史事故信息上传与查询、地铁站工作人员日志管理等功能;
62.应用层:包括数据查询、数据分析和数据可视化等功能;
63.数据层:包括数据采集、数据存储、数据处理和数据整合等功能,其中,数据采集采集的数据包括结构化数据和非结构化数据,数据存储的数据类型包括sql和non-sql,数据处理包括数据标准管理和数据质量管理,数据整合包括格式转换和数据拼接;
64.技术层:包括采集框架、实时计算、离线计算和系统集成等功能,其中,采集框架包括云计算、开源工具、采集系统和流处理平台,实时计算包括数据仓库、数据技术、并行计算和分布式数据库,离线计算包括全文搜索引擎、hdfs、计算引擎和分布式数据库,系统集成包括应用系统整合、业务流程整合和企业应用整合;
65.设备层:包括服务器、存储器、输入设备、智能终端、运算器、控制器、输出设备和信息安全设备。
66.以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。