1.本发明涉及审计管理技术领域,具体涉及一种工程项目审计风险识别方法。
背景技术:
2.目前为止,国内外工程项目审计风险的识别主要是靠审计管理人员进行资料翻阅、访谈获取和解释,这需要经验丰富的专业人员根据资料之间关联进行判定,没有充分利用管理信息系统中的信息,且科学性和准确性受限。如何不依赖专业审计人员,从数据中发现审计管理知识,提高风险点识别效率,成为亟待解决的审计管理问题。此问题的解决提升企业数据重用性,并能为审计部门和企业决策提供科学支撑。
技术实现要素:
3.本发明要解决的技术问题是:克服现有技术的不足,提供一种不依赖专业审计人员,能够识别工程项目审计风险的工程项目审计风险识别方法。
4.本发明为解决其技术问题所采用的技术方案为:工程项目审计风险识别方法,包括以下步骤:
5.步骤一:构建操作集合;
6.步骤二:对操作集合中数据预处理,获取待定风险点及其取值;
7.步骤三:构建待定风险点之间的关系连边,判断风险点之间关系方向;
8.步骤四:输出风险点因果关系网络。
9.所述步骤一中,收集项目生命周期数据、项目结算数据和审计报告语料,构建操作集合u的计算公式如下:
[0010][0011]
其中,公示(1)中n是审计管理中的工程项目总数,u表示总操作集合,p1,p2…
pn分别是第1、2、
…
n个工程项目。
[0012]
所述步骤二中用文本挖掘技术对操作集合中数据预处理,获取待定风险点及其取值;
[0013]
所述步骤二包括以下子步骤:
[0014]
2-1:对审计报告语料集进行分词,去掉中文停用词,得到审计报告关键词集合w;
[0015]
2-2:参照tf-idf算法,对w中任意关键词w
p
计算权重,获取关键词词频ti
p
;
[0016]
2-3:按照降序对关键词词频ti排序,筛选权重总和占80%的关键词作为待定风险点名称,构成待定风险点集合r
′
;
[0017]
2-4:依据审计业务规则,为每一个工程项目从项目生命周期数据、项目结算数据中获取待定风险点取值pj,若符合审计规则取0,否则取1,其表示如下:
[0018]
pj=pj(r
′
j1
,r
′
j2
...r
′
jk
)
ꢀꢀꢀ
(6);
[0019]
其中,公示(6)表示第j个项目的k个待定风险点及其取值;
[0020]
所述步骤2-1中,审计报告关键词集合w的计算公式如下:
[0021]
w={w1,w2...wn}={w1,w2...wm},w1∪w2...wn=w
ꢀꢀꢀ
(2);
[0022][0023]
其中,公示(2)中n是审计管理中的工程项目总数,w表示n个项目的审计报告关键词总集和,w1,w2...wn分别是第1、2、...n个工程项目对应审计报告关键词集合,m表示w中的关键词总数;公示(3)中l是第j个工程项目审计报告关键词个数。
[0024]
所述步骤2-2中,关键词词频ti
p
的计算公式如下:
[0025][0026]
其中,公示(4)中n
pj
是关键词w
p
在wj中出现的频率,∑kn
pj
是wj中关键词总数,|j:w
p
∈wj|是包含关键词w
p
的工程项目数量。
[0027]
所述步骤2-3中,待定风险点集合r
′
表示如下:
[0028]r′
={r
′1,r
′2...r
′k}
ꢀꢀꢀ
(5);
[0029]
其中,公示(5)中k是待定风险点数量。
[0030]
所述步骤三包括以下子步骤:
[0031]
3-1:构建审计风险点之间的完全图g(v,e),v={v1,v2...,vn},其中节点vj∈v是g中的节点,其属性取值为vj=(p1(r
′
1j
),p2(r
′
2j
)...pn(r
′
nj
)},n是节点个数,e={e1,e2...,em},其中边ek(vi,vj)∈e是g中的边,m是边的数量;
[0032]
3-2:筛选完全图上的连边;
[0033]
3-3:确定完全图上的连边方向。
[0034]
所述步骤3-2包括以下子步骤:
[0035]
3-2-1:输入g=(v,e),令l=-1;g
′
=g。设定集合o为节点集合,并将其初始化为空集合,集合o包含两个子集合,分别是o(i,j)和o(j,i),用于存放令节点对vi,vj或节点对vj,vi的取值相互独立的节点集合;
[0036]
3-2-2:l=l 1;
[0037]
3-2-3:对任意的节点对vi,vj,取出节点vi的邻居节点集合adj(g
′
,vi),并令集合k=adj(g
′
,vi)\vj∪adj(g
′
,vi)\vi;
[0038]
3-2-4:若|k|》l,则依次检查其中节点vk能否令节点对vi,vj的取值相互独立,若能则删除两点之间的连边,否则将k加入集合o(i,j)和o(j,i);
[0039]
重复步骤3-2-2至步骤3-2-4,直到图中所有的邻接点集规模都小于l。
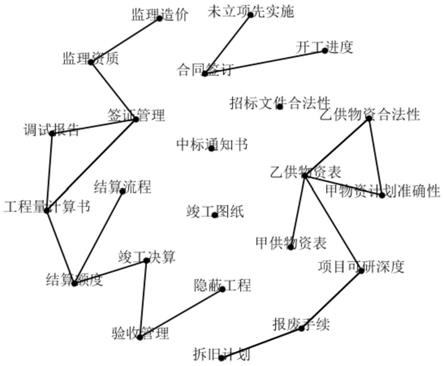
[0040]
所述步骤3-3包括以下子步骤:
[0041]
3-3-1:输入g
′
和o集合;
[0042]
3-3-2:对任意的节点对vi,vj,其中i,j为自然数,若其邻居,vk!∈o(i,j)oro(j,i),则更新g
′
,删除无向边e(vi,vk)和e(vk,vj),并增加有向边e《vi,vk》和e《vj,vk》。
[0043]
3-3-3:按照下述规则更新g
′
,将剩余无向边转变为有向边:
[0044]
规则1:若同时存在e《vi,vk》和e(vk,vj),则删除e(vk,vj),增加e《vj,vk》。
[0045]
规则2:若同时存在e《vi,vk》和e《vk,vj》,则删除e(vi,vj),增加e《vi,vj》。
[0046]
规则3:若同时存在e《vi,v
k1
》和e《v
k1
,vj》,及e《vi,v
k2
》和e《v
k2
,vj》,且v
k1
和v
k2
不相邻,则删除e(vi,vj),增加e《vi,vj》。
[0047]
规则4:若同时存在e《vi,v
k1
》和e《v
k1
,v
k2
》,及e《v
k1
,v
k2
》和e《v
k2
,vj》,且v
k1
和v
k2
不
相邻,则删除e(vi,vj),增加e《vi,vj》。
[0048]
所述步骤四包括以下子步骤:
[0049]
4-1:输出g
′
(v,e);
[0050]
4-2:网络g
′
中的非孤立节点为审计风险点;
[0051]
4-3:网络g
′
中的连边表示风险点之间的因果关系。
[0052]
与现有技术相比,本发明具有以下有益效果:
[0053]
1、利用项目生命周期数据、项目结算数据和审计报告语料可自动识别工程项目中的审计风险;
[0054]
2、本方法具有处理多源工程项目审计数据及风险识别的能力,为审计管理中的风险管理提供风险点关联和处置指导;利文本处理技术将工程项目生命周期数据、工程项目结算数据和审计报告语料数据进行量化处理,提高审计风险的识别效率,提供了一种有效的方法;
[0055]
3、对风险点及其因果关系构建的网络图进行分析,可以发现风险扩散的方式,提供风险点及其产生原因溯源,是对专业人员经验不足情况下的审计管理业务的指导,在工程项目审计风险管理中具有重要作用。
附图说明
[0056]
图1是本发明实施例2筛选完全图上的连边的示意图。
[0057]
图2是本发明实施例2确定完全图上的连边方向示意图。
[0058]
图3是本发明实施例2输出g
′
(v,e)示意图。
具体实施方式
[0059]
下面结合附图对本发明实施例做进一步描述:
[0060]
实施例1
[0061]
如图1至图3所示,包括以下步骤:
[0062]
步骤一:构建操作集合;从管理信息系统、工程项目施工现场、审计业务现场,以导出、拍照、填充方式收集项目生命周期数据、项目结算数据和审计报告语料,构建操作集合u的计算公式如下:
[0063][0064]
其中,公示(1)中n是审计管理中的工程项目总数,u表示总操作集合,p1,p2...pn分别是第1、2、...n个工程项目。
[0065]
步骤二:对操作集合中数据预处理,获取待定风险点及其取值;所述步骤二中用文本挖掘技术对操作集合中数据预处理,获取待定风险点及其取值;
[0066]
所述步骤二包括以下子步骤:
[0067]
2-1:对审计报告语料集进行分词,去掉中文停用词,得到审计报告关键词集合w;所述步骤2-1中,审计报告关键词集合w的计算公式如下:
[0068]
w={w1,w2...wn}={w1,w2...wm},w1∪w2...wn=w
ꢀꢀꢀ
(2);
[0069][0070]
其中,公示(2)中n是审计管理中的工程项目总数,w表示n个项目的审计报告关键
词总集和,w1,w2...wn分别是第1、2、...n个工程项目对应审计报告关键词集合,m表示w中的关键词总数;公示(3)中l是第j个工程项目审计报告关键词个数。
[0071]
2-2:参照tf-idf算法,对w中任意关键词w
p
计算权重,获取关键词词频ti
p
;所述步骤2-2中,关键词词频ti
p
的计算公式如下:
[0072][0073]
其中,公示(4)中n
pj
是关键词w
p
在wj中出现的频率,∑kn
pj
是wj中关键词总数,|j:w
p
∈wj|是包含关键词w
p
的工程项目数量。
[0074]
tf-idf算法是文本挖掘算法中的用于评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度,其假设是字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。适用于当语料集合中文件数量比较多时,计算词的重要程度。本方法中审计报告文本数量多,因此该算法适用度高。
[0075]
2-3:按照降序对关键词词频ti排序,筛选权重总和占80%的关键词作为待定风险点名称,构成待定风险点集合r
′
;所述步骤2-3中,待定风险点集合r
′
表示如下:
[0076]r′
={r
′1,r
′2...r
′k}
ꢀꢀꢀ
(5);
[0077]
其中,公示(5)中k是待定风险点数量。
[0078]
2-4:依据审计业务规则,为每一个工程项目从项目生命周期数据、项目结算数据中获取待定风险点取值pj,若符合审计规则取0,否则取1,其表示如下:
[0079]
pj=pj(r
′
j1
,r
′
j2
...r
′
jk
)
ꢀꢀꢀ
(6);
[0080]
其中,公示(6)表示第j个项目的k个待定风险点及其取值。
[0081]
步骤三:构建待定风险点之间的关系连边,判断风险点之间关系方向;所述步骤三包括以下子步骤:
[0082]
3-1:为工程项目构建审计风险点之间的完全图g(v,e),其中节点vj∈v是g中的节点,其属性取值为vj=(p1(r
′
1j
),p2(r
′
2j
)...pn(r
′
nj
)},n是节点个数。e={e1,e2...,em},其中边ek(vi,vj)∈e是g中的边,m是边的数量。
[0083]
3-2:筛选完全图上的连边;所述步骤3-2包括以下子步骤:
[0084]
3-2-1:输入g=(v,e),令l=-1;g
′
=g。设定集合o为节点集合,并将其初始化为空集合。集合o包含两个子集合,分别是o(i,j)和o(j,i),用于存放令节点对vi,vj或节点对vj,vi的取值相互独立的节点集合;
[0085]
3-2-2:l=l 1;
[0086]
3-2-3:对任意的节点对vi,vj,其中i,j为节点编号,取出节点vi的邻居节点集合adj(g
′
,vi),并令集合k=adj(g
′
,vi)\vj∪adj(g
′
,vi)\vi;
[0087]
3-2-4:若|k|》l,则依次检查其中节点vk能否令节点对vi,vj的取值相互独立,若能则删除两点之间的连边,否则将k加入集合o(i,j)和o(j,i);
[0088]
重复步骤3-2-2至步骤3-2-4,直到图中所有的邻接点集规模都小于l。3-2-4中独立性检验时采用了fisher z test方法;
[0089]
fisher z test方法即f检验法,是英国统计学家fisher提出的,又叫方差齐性检验。主要通过比较两组数据的方差,确定他们的精密度是否有显著性差异,适用范围比较广。在本方法中,能通过这个检验,快速识别两个节点方差的差别是否具有显著意义。
[0090]
3-3:确定完全图上的连边方向。所述步骤3-3包括以下子步骤:
[0091]
3-3-1:输入g
′
和o集合;
[0092]
3-3-2:对任意的节点对vi,vj,若其邻居,vk!∈o(i,j)oro(j,i),则更新g
′
,删除无向边e(vi,vk)和e(vk,vj),并增加有向边e《vi,vk》和e《vj,vk》。
[0093]
3-3-3:按照下述规则更新g
′
,将剩余无向边转变为有向边:
[0094]
规则1:若同时存在e《vi,vk》和e(vk,vj),则删除e(vk,vj),增加e《vj,vk》。
[0095]
规则2:若同时存在e《vi,vk》和e《vk,vj》,则删除e(vi,vj),增加e《vi,vj》。
[0096]
规则3:若同时存在e《vi,v
k1
》和e《v
k1
,vj》,及e《vi,v
k2
》和e《v
k2
,vj》,且v
k1
和v
k2
不相邻,则删除e(vi,vj),增加e《vi,vj》。
[0097]
规则4:若同时存在e《vi,v
k1
》和e《v
k1
,v
k2
》,及e《v
k1
,v
k2
》和e《v
k2
,vj》,且v
k1
和v
k2
不相邻,则删除e(vi,vj),增加e《vi,vj》。
[0098]
步骤四:输出风险点因果关系网络。所述步骤四包括以下子步骤:
[0099]
4-1:输出g
′
(v,e);
[0100]
4-2:网络g
′
中的非孤立节点为审计风险点;
[0101]
4-3:网络g
′
中的连边表示风险点之间的因果关系。
[0102]
实施例2
[0103]
步骤一:收集项目生命周期数据、项目结算数据和第三方中介审计报告,构建操作集合;
[0104]
从管理信息系统、工程项目施工现场、审计业务现场,以导出、拍照、填充方式收集154个中低压配网工程项目生命周期数据、项目结算数据和审计报告语料,构建操作集合:
[0105][0106]
步骤二:用文本挖掘技术对操作集合中数据预处理,获取待定风险点及其取值:
[0107]
2-1:对审计报告语料集进行分词,去掉中文停用词,得到审计报告关键词集合w:
[0108]
w={w1,w2...w
154
}={w1,w2...w
3019
},w1∪w2...w
154
=w
ꢀꢀ
(2);
[0109]
wj={档案、资料、项目、开竣工、签证单、时间}
ꢀꢀ
(3);
[0110]
2-2:对w中任意关键词w
p
计算权重,获取关键词词频ti
p
:
[0111]
关键词“签证单”的词频:
[0112]
2-3:按照降序对关键词词频ti排序,筛选权重总和占80%的关键词,结合审计业务确定待定风险点名称,构成待定风险点集合r
′
:
[0113]r′
={项目可研深度,未立项先实施,招标文件,中标通知书,合同签订,开工进度,监理资质试报告,隐蔽工程,甲供物资表,甲物资计划准确,乙供物资表,乙供物资合法性,竣工图纸,工程量计算书,验收管理,报废手续,拆旧计划,结算流程,结算额度,竣工决算}
ꢀꢀ
(5)
[0115]
2-4:依据审计业务规则,为每一个工程项目从项目生命周期数据、项目结算数据中获取待定风险点取值,若符合审计规则取0,否则取1:
[0116]
pj=pj(0,1,1,1,1,0,0,0,0,1,1,1,0,0,0,1,0,1,1,1,1,1,0)
ꢀꢀ
(6);
[0117]
其中,公示(6)表示第j个项目的k个待定风险点及其取值;
[0118]
步骤三:构建待定风险点之间的关系连边,判断风险点之间关系方向:
[0119]
3-1:为工程项目构建审计风险点之间的完全图g(v,e),v={v1,v2...,v
n154
},其中vj=(1,1,1,1,1,0,0,0,1,1,0,0,1,0,1,0,1,0,1,0,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,0,0,0,0,0,1,1,1,1,0,0,1,1,1,1,0,0,1,1,1,0,0,0,1,1,1,1,0,0,1,1,1,0,0,0,1,1,1,0,0,0,1,1,1,1,1)。
[0120]
3-2:参照图1,筛选完全图上的连边;
[0121]
3-3:参照图2,确定完全图上的连边方向;
[0122]
步骤四:输出风险点因果关系网络:
[0123]
(1)输出g
′
(v,e),如图3所示;
[0124]
(2)网络g
′
中的非孤立节点为非审计风险点,此应用中共20个审计风险点;
[0125]
(3)网络g
′
中的连边表示风险点之间的因果关系。
[0126]
综合宏观模块度、微观网络结构指标排名可得审计风险子系统的扩散模式及关键风险点如表1所示。在1号子系统中有3个关键风险点,它们的接近中心性取值都比较大。因此,1号子系统(绿色节点构成)的风险关系距离较近,也就是其中关键风险点发生问题时,会扩散到其邻居风险点。在2号子系统(紫色节点构成)中有3个关键风险点,它们的中介中心性取值偏大。这说明此子系统存在较大概率的风险传递可能,也就是若关键风险点发生问题,子系统中其它风险点会逐一沿着关系链路发生问题。3号子系统(红色节点构成)节点数量只有3个,其关键风险点只有1个,且在因果关系网络中只有指向它的连边。因此,此风险点的风险产生是滞后的,也就是后续节点的风险发生时,合同管理风险才突显。
[0127]
表1子系统风险传播模式
[0128][0129]
本发明考虑到审计管理业务中风险点识别及其关系判断问题,其算例结果表明,可以识别工程项目中的审计风险点和风险关系,提高工程项目数据重用度,为审计管理提供决策指导。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
