1.本发明涉及避免强化学习中的脆性,具体地,涉及进行学习以通过对动态变化鲁棒的方式控制系统。
背景技术:
2.在强化学习(reinforcement learning,rl)中,系统被建模为马尔可夫决策问题(markov decision problem,mdp)。这被定义为元组《x,u,p,r,》,其中,x是状态空间,u是动作空间,p(
·
|x,u)是每个状态-动作对(x,u)的下一个状态的概率分布,r(x,u)是奖励(正实数或负实数)。概率分布p称为动态。
3.mdp的控制器称为策略。它通常被实现为给定当前状态x的动作的概率分布,表示为π(
·
|x)。配备启动状态分布和策略的mdp会产生马尔可夫奖励过程(markov reward process,mrp)。它归纳了轨迹上的概率分布(轨迹是状态、动作、奖励的序列)。
4.rl中的标准目标是优化预期回报,即总折扣奖励:
[0005][0006]
其中,μ是初始分布,其中:
[0007][0008]
假设动态p是固定的,即如果在给定状态下采取相同的动作,则在接下来的状态的分布与在其它时间在该状态下采取该动作的分布情况相同。动态与应用于mdp的任何控制策略无关。
[0009]
mdp的固定动态的这一方面是标准rl算法中的一个基本假设。但是,由此产生了几个问题。
[0010]
如果策略在某一mdp上进行训练,然后部署在具有不同动态的mdp上,则策略通常表现不佳,即策略在动态变化方面往往是脆性的。例如,如果rl代理使用模拟器(例如,汽车或机器人的模拟器)进行训练,然后部署在真实的物理系统中,则模拟器表现不完美,它模拟的动态将与现实世界的动态不完全相同。
[0011]
另一个问题是,在现实世界中在不同时间发生的动态变化将影响结果。例如,由于例如路面、承载负载的差异或轮胎气压,汽车的驾驶员会经历不同的动态。任何机器都可能由于温度或润滑的变化而出现摩擦差异。任何产生对这些动态变化脆性的控制策略的算法显然都实际上不适用。到目前为止,rl在实验室之外或游戏等受控环境之外并没有特别成功的原因之一是缺乏鲁棒性。
[0012]
先前的方法已试图制定对这种动态变化更鲁棒的策略。例如,在tessler等人的“动作鲁棒强化学习及其在连续控制中的应用(action robust reinforcement learning and applications in continuous control)”(icml 2019)中,这个问题被框定为零和博弈。策略给出了以下鲁棒性标准的动作:(i)以固定的概率,采取不同的可能是对抗性的动作,(ii)向动作本身中添加扰动。但是,尽管算法在一些mujoco任务中表现良好,但在其它
任务(如倒摆)中表现较差。
[0013]
如pinto等人在“鲁棒对抗强化学习(robust adversarial reinforcement learning)”(icml2017)中描述的另一种方法也将问题框定为零和博弈,鲁棒性是通过替代对手和代理策略迭代学习的。lecarpentier和rachelson的“非平稳马尔可夫决策使用基于模型的强化学习处理最坏情况方法(non-stationary markov decision processes a worst-case approach using model-based reinforcement learning)”(arxiv:1904.10090 2019)对随时间变化的动态进行建模,受每单位时间的wasserstein距离限制。对于环境是对抗性的最坏情况,求解树搜索算法。在网格世界上,即小规模示例上进行了实验,该方法似乎无法扩展到连续状态空间和动作空间。
[0014]
其它方法在以下文献中予以描述:jp 3465236 b2,基于经典控制理论中的h无穷大技术;cn 107856035a,专门针对特定类别的问题,而不是一般的rl算法;以及us 6665651b2,依赖于有一个控制器来训练神经网络,重点是学习过程的稳定性。
[0015]
期望进行学习以通过提高对动态变化的鲁棒性的方式控制系统。
技术实现要素:
[0016]
提供了一种系统,用于执行强化学习以生成可用作模型中的参数的值的解集,从而使所述模型针对性能度量提供一定水平的性能,所述系统用于:形成包括候选参数值集的候选解;重复执行以下步骤:通过评估具有所述候选解的所述值的模型针对所述性能度量提供高水平性能的程度,对所述候选解的质量进行第一评估;通过评估具有所述候选解的所述值的模型未能针对所述性能度量提供低水平性能的程度,对所述候选解的质量进行第二评估;根据所述第一评估和所述第二评估形成另一个候选解。
[0017]
因此,所述系统可以评估策略的总体性能,以优化模型的性能,并评估在最坏情况动态下具有这些参数的模型,以最大限度地减少低水平性能的发生。然后,所述系统可以根据这些第一评估和第二评估迭代地形成策略参数的另一个候选解。
[0018]
所述系统可以用于通过测试根据所述候选解的所述值配置的所述模型在应用于参考值集时的行为来评估所述候选解的质量。这可以实现一种评估候选解的质量的方便方式。
[0019]
所述系统还可以用于通过以下步骤评估所述候选解的质量:生成适配参考值集,所述适配参考值集包括在所述参考值集中的至少一些参考值附近的一个或多个适配参考数据项;测试根据所述候选解的所述值配置的所述模型在应用于所述适配参考值集时的行为。这可以实现针对与参考动态不同的动态测试候选解的质量。
[0020]
所述一个或多个适配参考数据项可以在所述参考值集的预定wasserstein距离内。所述适配参考值集可以表示所述参考值集的最坏情况值。因此,策略的质量可以在wasserstein球内的最坏情况下进行评估。通过评估策略最的坏情况动态,可以提高策略的鲁棒性。因此,wasserstein度量可以有助于以有用和直观合理的方式衡量模型或模拟器的“错误”程度。
[0021]
所述参考值集可以包括神经网络的参数。这种方法可以实现高效计算更新的参考值和另一个候选解。
[0022]
所述参考值集可以包括从模拟器或微分方程求解器输出的值。这种方法可以实现
高效计算更新的参考值和另一个候选解,并可以使得参考值以与某些规则集一致的方式变化。例如,机器人或汽车等物理系统的模拟器将允许摩擦、质量、长度等量的变化,但该系统应遵守牛顿定律。
[0023]
所述参考值集可以包括一组参考动态。这可以使得系统应用于现实世界的动态情况。
[0024]
所述系统可以用于执行优化,包括对所述候选解的质量的所述第一评估和所述第二评估。
[0025]
所述模型可以是经过训练的人工智能模型。所述模型可以是神经网络。
[0026]
根据第二方面,提供了一种方法,用于执行强化学习以生成可用作模型中的参数的值的解集,从而使所述模型针对性能度量提供一定水平的性能,所述方法包括:形成包括候选参数值集的候选解;重复执行以下步骤:通过评估具有所述候选解的所述值的模型针对所述性能度量提供高水平性能的程度,对所述候选解的质量进行第一评估;通过评估具有所述候选解的所述值的模型未能针对所述性能度量提供低水平性能的程度,对所述候选解的质量进行第二评估;根据所述第一评估和所述第二评估形成另一个候选解。
[0027]
因此,所述方法可以评估策略的总体性能,以优化模型的性能,并评估在最坏情况动态下具有这些参数的模型,以最大限度地减少低水平性能的发生。然后,所述方法可以根据这些第一评估和第二评估迭代地形成策略参数的另一个候选解。
[0028]
所述评估所述候选解的质量可以包括测试根据所述候选解的所述值配置的所述模型在应用于参考值集时的行为。这可以实现一种评估候选解的质量的方便方式。
[0029]
所述评估所述候选解的质量还可以包括:生成适配参考值集,所述适配参考值集包括在所述参考值集中的至少一些参考值附近的一个或多个适配参考数据项;测试根据所述候选解的所述值配置的所述模型在应用于所述适配参考值集时的行为。这可以实现针对与参考动态不同的动态测试候选解的质量。
[0030]
所述一个或多个适配参考数据项可以在所述参考值集的预定wasserstein距离内。因此,策略的质量可以在wasserstein球内的最坏情况下进行评估。通过评估策略最的坏情况动态,可以提高策略的鲁棒性。因此,wasserstein度量可以有助于以有用和直观合理的方式衡量模型或模拟器的“错误”程度。
附图说明
[0031]
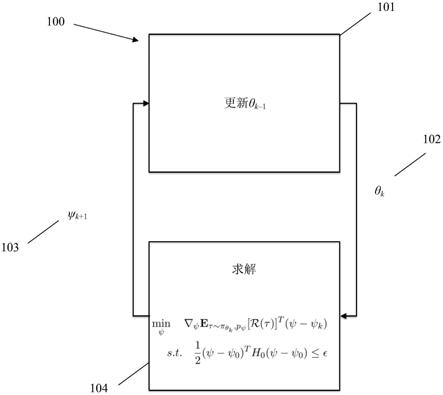
现将结合附图通过示例的方式对本发明进行描述。
[0032]
在附图中:
[0033]
图1示出了迭代更新参数化策略和动态;
[0034]
图2示出了本发明实施例提供的方法的流程图;
[0035]
图3示出了用于实现图2所示方法的系统的示例;
[0036]
图4示出了本发明又一实施例提供的方法的流程图;
[0037]
图5示出了作为图4所示方法的一部分执行的子例程提供的方法的流程图;
[0038]
图6示出了用于实现图4和图5中所示方法的系统的示例;
[0039]
图7示出了执行强化学习以生成可用作模型中参数的值的解集的方法示例。
具体实施方式
[0040]
本发明涉及一种用于执行强化学习以生成可用作模型中对动态变化鲁棒的参数的值的解集的系统和方法。
[0041]
在标准rl算法中,模型参数候选解的质量是通过测试根据候选解的值配置的模型在应用于一组参考动态p0(作为系统的输入)时的行为来评估的。在标准算法中,使用这些参考动态训练控制策略,而不考虑其它可能的动态。在本发明的实施例中,考虑围绕p0(例如,以其为中心)分布的一组可能的动态。这些参考值表示训练模型的起点。
[0042]
在一个实施例中,在控制策略的训练期间考虑在参考动态的预定wasserstein距离内的动态。wasserstein距离用作动态之间发散的度量,并定义用于相对于度量空间定义的概率测度。具体地,假设状态空间x是度量空间,度量表示为d(
·
,
·
)。设m(s)表示集合s上的一组概率测度,概率测度μ和v上的耦合集定义为:
[0043][0044]
也就是说,它是乘积空间上的一组概率测度,沿一个维度边缘化为μ,沿另一个维度边缘化为ν。p-wasserstein距离定义为:
[0045][0046]
一般来说,wasserstein距离没有闭合形式解,但可以数值估计。但是,高斯之间的平方2-wasserstein具有闭合形式。
[0047]
使用的一组动态是p,当用wasserstein度量衡量时,其与p0的距离在某个预定义的限制内。wasserstein度量可以是wasserstein度量类中的任何一个。预定义的限制可以称为围绕p0的ε-wasserstein球,定义为
[0048][0049]
系统用于学习最佳控制策略,其中,策略π的质量是标准rl目标函数,但在wasserstein球内的最坏情况动态(对于π)下进行评估。通过对可能遇到的动态保持“悲观”(即通过评估策略的最坏情况动态),可以提高策略的鲁棒性。因此,wasserstein度量可以有助于以有用和直观合理的方式衡量模型或模拟器的“错误”程度。
[0050]
wasserstein距离的形式为(距离
×
概率质量)。因此,如果这个乘积受到某个数字的约束,则它意味着如果距离大,则概率小,如果概率大,则距离小。即,模型可能是严重错误的(大距离),但这不太可能,或者很可能是错误的(高概率),但不可以过于不准确。如果参考动态经常高度不准确,则它是无用的,对它的训练是毫无意义的,并且最终,试图实现鲁棒性是徒劳的。
[0051]
并不是wasserstein球中的所有动态都是可信的;例如,有些动态可能违反牛顿运动定律。在本发明中,动态可能会受到干扰,但保持可信。考虑到这一点,策略π使用向量参数化,并写为π
θ
。θ参数是神经网络的参数(权重),可以随着时间的推移而更新。
[0052]
动态也用另一个向量参数化。同样,这些参数ψ可以随着时间的推移而更新。这些参数可以是例如神经网络、模拟器或实现系统动态的其它处理器(例如,微分方程求解器或真实系统)的参数。对应于参考动态p0的参数向量表示为ψ0。
[0053]
该系统可以生成适配参考动态参数集,所述适配参考动态参数集包括在预定
wasserstein距离内ψ0附近的适配参考数据。然后,系统通过测试根据候选解的值配置的模型在应用于适配参考动态参数时的行为来评估候选解策略参数的质量。
[0054]
该系统通过评估具有候选解的值的模型针对性能度量提供高水平性能的程度,对候选解的质量进行第一评估,即,系统评估策略的总体性能,以优化模型的性能。该系统还通过评估具有候选解的值的模型未能针对性能度量提供低水平性能的程度来对候选解的质量进行第二评估,即,系统评估在最坏情况动态下具有这些参数的模型,旨在最大限度地减少低水平性能的发生。该系统根据这些第一评估和第二评估迭代地形成策略参数的另一个候选解。
[0055]
该系统待解决的优化问题可以表示为:
[0056][0057]
其中,在连续rl设置中:
[0058][0059]
在周期性rl设置中:
[0060][0061]
其中,这些是“占有测度”,在持续的情况下,它是通过具有动态ψ和策略的mdp归纳的马尔可夫链的平稳分布,在周期性的情况下,它是与平稳分布目的相似的一种概率分布。
[0062]
该系统迭代地求解上述优化问题的近似值,如图1所示。如101所示,根据更新的动态参数ψ
k 1 102更新前一个候选解的策略参数θ
k-1
,并且如104所示,将如103所示的更新的策略参数θk用于优化问题的下一次迭代。
[0063]
内部优化问题由以下公式给出:
[0064][0065]
项h0是对在ψ0下评估的函数f的hessian的估计值,其中
[0066][0067]
上述问题的解由以下公式给出:
[0068][0069]
其中,
[0070]
上述定义的优化问题可以在某些假设(例如,h0存在且是对称正定的)下求解,以计算动态ψ的更新。
[0071]
然后,更新的动态参数用于更新策略参数,然后在优化的后续迭代中使用这些参
数,如图1所示。
[0072]
因此,用于对等式(6)中优化问题进行求解的高级策略具有更新θ的外环和对给定固定θ的最小化问题求解的内环。
[0073]
因此,系统学习最佳控制策略,其中,策略的质量是标准rl目标函数,但质量在wasserstein球内的最坏情况动态下进行评估。通过对模型可能遇到的动态持悲观,可以提高策略的鲁棒性。
[0074]
现在将描述本发明的两个示例性实施例。
[0075]
首先将参考图2和图3描述使用神经网络定义高斯分布的一种通用方法。这种方法可以实现高效计算更新的动态参数ψ
k 1
。
[0076]
在该实施例中,ψk是神经网络的权重,该神经网络输出高斯过程的均值和协方差,即使用应用于以下优化问题的共轭梯度算法和自动微分(例如,autograd,参见:https://github.com/hips/autograd)高效计算量
[0077][0078]
在图2的流程图中的步骤201中,系统300可以访问参数ψ0,这些参数是神经网络(neural network,nn)nn2的参数,在图3的系统图中的301中示出,表示参考动态p0。nn2 301将状态-动作对(x,u)作为输入,并输出均值向量和协方差矩阵这些被馈送到采样器302中,该采样器302从分别具有平均值和协方差的多元高斯分布中采样下一个状态x
′
。这是一种在强化学习中对动态建模的标准方法。
[0079]
该系统还假定它可以访问固定策略该策略被实现为神经网络nn1,如图3的303中所示。nn1将状态x作为输入,并将一些参数提供给采样器304,该采样器304使用这些参数根据概率分布对动作进行采样。这是一种在强化学习中实现随机策略的标准方法。
[0080]
在图2中的步骤202中,系统任意地将策略参数向量初始化为θ0,作为欧几里德向量。系统将hessian矩阵估计初始化为d
×
d零矩阵,其中,d是动态参数ψk的维度。
[0081]
在步骤203中,系统然后使用最新参数ψk和θk对轨迹的批次b进行采样。这是使用图3中分别在305和306中示出的nn3和nn4以及它们的关联采样器302和307来完成的。由于轨迹是(状态、动作、奖励)的序列,每个新的状态-动作对作为输入被馈送到nn3 305(馈送到其采样器中),以采样新的状态,并且每个新状态被馈送到nn4 306(馈送到其采样器中)以采样新动作。假设有一种可以从采样轨迹中提取奖励的机制。例如,如果奖励函数是状态-动作对的已知函数,或应用模拟器。
[0082]
梯度由以下公式给出:
[0083][0084]
可以借助以下公式进行估计:
[0085][0086]
也就是说,可以通过使用批次b对方括号中的量进行平均来对方程(15)右侧进行
经验估计。该函数由梯度估计器(图3中的308)在图2的步骤204中执行。
[0087]
从图2的流程图可以看出,在步骤205中的初始化之后的下一阶段是包括步骤206-210的循环,其最终目的是估计这是通过生成v1,v2,
…
,vm并最终对其进行平均来完成的,其中,每个vi都是的估计值。为了生成vi,完成以下操作:在步骤206中,抽取样本,由以下公式给出:
[0088][0089]
该样本通过应用nn1 303及其采样器304和nn3 305及其采样器302抽取。将样本输入到nn3 305中,以获得作为nn3的输出。这作为输入馈送到高斯wasserstein计算网络(gaussian wasserstein computation network,gwcn)309。如图3所示,gwcn也将作为输入。在步骤207中,在内部,计算并输出:
[0090][0091]
这等于即多元正态分布之间2-wasserstein距离的平方。由于nn3 305直接馈送到gwcn 309中,在步骤208中,使用自动微分引擎(例如,autograd:https://github.com/hips/autograd)高效计算逆hessian向量乘积
[0092]
循环将继续,直到完成所需数量的训练场景。每个v1,v2,
…
,vm都被提供给动态参数更新计算器(dynamics parameters update calculator,dpuc)310,该计算器计算平均值,然后计算为的估计值。在步骤211中,这被dpuc用于计算ψ
k 1
:
[0093][0094]
在步骤212中,该dpuc将ψ
k 1
馈送到策略参数更新引擎(policy parameters update engine,ppue)311中,该策略参数更新引擎计算θ
k 1
并将其馈送到nn4 306中。这样完成了循环。
[0095]
然后,在优化问题的下一次迭代中使用新的策略参数θ
k 1
,并重复上述步骤。
[0096]
在另一个示例中,现在将参考图4至图6描述,ψk对应于模拟器的参数。
[0097]
系统600可以访问图6中601所示的模拟器,该模拟器可以实现使用向量ψk∈rd对动态进行参数化。
[0098]
在图4中的步骤401中,系统访问参数ψ0。ψ0是表示参考动态的模拟器的参数。在步骤402中,θ0设置为零向量,设置为零矩阵。系统进入一个循环,该循环以h0的估计值结束。这通过应用文献中称为“进化策略”的方法来实现。
[0099]
在该实施例中,使用以下公式估计h0:
[0100]
[0101]
其中,x=ψ0,f(参见等式(10))是使用由样本ψ=ψ0 ∈生成的点的经验分布的wasserstein距离计算来估计的。
[0102]
动态是参数化模拟器的d维向量。随机向量∈~n(0,σ2i)∈rd由多元高斯采样器603采样,系统设置ψ
←
ψ0 ∈并将其传递给模拟器601,如步骤404所示。
[0103]
在步骤405中,系统然后进入图5的流程图中所示的子程序a,该子程序在步骤501和步骤502中取ψ和作为其输入,并且将ψ和用于抽取样本,由以下公式给出:
[0104][0105]
图6中的604中所示的神经网络nn1及其采样器605用于从采样动作,并将使用ψ参数化的模拟器601用于执行上述采样。分别在步骤503和504中,将上述样本馈送到模拟器601中,以产生多个样本和这些样本以数据集和(分别在步骤505和506中示出)保存在存储器中。这些数据集被馈送到wasserstein计算引擎(wasserstein computation engine,wce)606中,以便在步骤507中计算经验wasserstein距离,该距离被视为下式的估计值:
[0106][0107]
步骤502至步骤508的这个循环重复多次,并在步骤510中取得估计值的平均值。这是通过将估计值从存储器607传递到算术平均计算器608来完成的,如步骤509所示。结果在图4中被称为hi。针对每个样本∈重复外循环(调用子程序a),计算平均值并将其设置为h0的估计值。
[0108]
从图4可以看出,系统然后进入循环,进入点在步骤409,该步骤409使用θk和ψk对轨迹的批次b进行采样。这是使用模拟器601以及nn2 602及其采样器610完成的。在步骤410中,系统使用b来估计:
[0109][0110]
使用公式:
[0111][0112]
该函数由图6中的梯度估计器609执行。
[0113]
在步骤411中,系统然后通过将共轭梯度估计器611中的共轭梯度算法应用于优化问题来计算的估计:
[0114][0115]
在步骤412中,结果被传递到执行以下计算的新的动态参数计算引擎612中:
[0116][0117]
这确定了新的动态参数ψ
k 1
。随后,新的参数被传递到策略参数更新引擎613中,该策略参数更新引擎613在步骤413计算新的策略参数θ
k 1
。策略参数的更新可以由以下算法
执行,例如ppo(描述于schulman、john、filip wolski、prafulla dhariwal、alec radford和oleg klimov的“近端策略优化算法(proximal policy optimization algorithms)”arxiv preprint arxiv:1707.06347(2017))、trpo(描述于schulman,j.、levine,s.、abbeel,p.、jordan,m.、&moritz,p(2015年,6月)的“信任区域策略优化(trust region policy optimization)”,国际机器学习大会(第1889-1897页))或有“原始”策略梯度更新执行。
[0118]
然后,在优化的下一次迭代中使用新的策略参数θ
k 1
,并重复上述步骤。
[0119]
使用模拟器中的参数比上文中之前描述的通用方法有优势,因为通常,模拟器可以使其参数以与某一规则集一致的方式变化。例如,机器人或汽车等物理系统的模拟器将允许摩擦、质量、长度等量的变化,但该系统应遵守牛顿定律。
[0120]
或者,在本实施例中使用的参数可以来自微分方程求解器,该微分方程求解器可以实现使用向量ψk∈rd对动态进行参数化。
[0121]
图7总结了一种方法,用于执行强化学习以生成可用作模型中的参数的值的解集,从而使所述模型针对性能度量提供一定水平的性能。在步骤701中,该方法包括形成包括候选参数值集的候选解。然后,该方法包括重复执行以下步骤702-704。在步骤702中,通过评估具有候选解的值的模型针对性能度量提供高水平性能的程度,对候选解的质量进行第一评估。在步骤703中,通过评估具有候选解的值的模型未能针对性能度量提供低水平性能的程度,对候选解的质量进行第二评估。在步骤704中,根据第一评估和第二评估形成另一个候选解。
[0122]
在上述方法中,形成了用于分析数据并提供该输入数据的一个或多个属性的指示的模型。该模型是泛化的,并根据控制模型性能的值进行操作。例如,模型可以是神经网络,值可以是应用于网络的权重。上述系统通过针对参考或训练数据训练来选择值。训练数据包括模型的一组可能的输入数据,以及每个模型的对应预期输出。为了选择这些值,系统运行第一个循环和第二个循环。第二个循环在第一个循环内运行。在第一循环中,通过针对训练数据选择具有这些值的模型的高性能,形成候选值集。换句话说,根据使用取训练数据作为输入的那些值配置的模型的输出与所述训练数据的期望输出之间是否存在相对高的一致性的确定来选择或评估候选值集。在内循环中,测试候选值集是否具有针对训练数据的这些值的低性能模型。换句话说,根据使用取训练数据作为输入的那些值配置的模型的输出与所述训练数据的期望输出之间是否存在相对低的一致性的确定来选择或评估候选值集。该过程被重复多次,每次迭代的候选值集被选择为使得它已被确定为对于较好性能,呈现相对(例如,相对于先前的候选数据集)高的倾向,对于较差性能,呈现相对低的倾向。
[0123]
本文描述的方法有助于解决强化学习中的脆性问题,具体地可以提供一种系统和方法,用于学习以对动态变化鲁棒的方式控制系统。因此,本发明可以使用户在模拟器上训练并以良好的性能部署在现实世界中。
[0124]
本发明的实施例可以提供优于先前方法的优点。本发明方法在实验中表现较好,可用于连续状态和动作空间。具体地,lecarpentier and rachelson的“非平稳马尔可夫决策使用基于模型的强化学习处理最坏情况方法(non-stationary markov decision processes a worst-case approach using model-based reinforcement learning)”(arxiv:1904.10090 2019)中描述的方法仅适用于具有有限离散状态和动作空间的场景。
所描述的方法在连续的状态和动作空间中运行,这是实际适用于现实世界环境的基本要求。
[0125]
可以应用本发明的一种特别有利的情况是自动驾驶汽车。汽车的动态会因多种因素而变化,包括路面的变化、道路倾斜度、轮胎压力、摩擦力以及由于承载的重量而产生的变化。显然,在这个示例中,汽车在整个生命周期中甚至在很短的时间段内都不会经历任何单一的一组动态。本发明算法对这种变化更鲁棒,并且可以应对新的动态,而不必学习在环境中应对它们。
[0126]
因此,本文公开的方案可以学习对其训练的环境与其部署的环境之间的动态变化鲁棒的控制策略。
[0127]
在上面的描述中,在控制策略的训练期间考虑参考动态的预定wasserstein距离内的动态。但是,其它度量也可以用作距离函数。
[0128]
申请人在此单独公开本文描述的每一个别特征及两个或两个以上此类特征的任意组合。以本领域技术人员的普通知识,能够基于本说明书将此类特征或组合作为整体实现,而不考虑此类特征或特征的组合是否能解决本文所公开的任何问题;且不对权利要求书的范围造成限制。本技术表明本发明的各方面可由任何这类个别特征或特征的组合构成。鉴于上文描述,对本领域技术人员来说显而易见的是可在本发明的范围内进行各种修改。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
