1.本发明涉及领域新词的提取技术领域,特别是涉及一种领域新词的提取方法及系统。
背景技术:
2.随着技术数据化的发展,从垂直行业ugc(user generated content,用户生成内容,即用户原创内容)内容数据、专业文献、行业新闻、企业内参等专业领域中,领域新词和特定业务场景下的口语化表达方式更新的越来越快,然而,快速从海量异构的行业语料中发掘领域新词,扩充领域词库,对于提升词法分析任务的精度,进而提升无结构数据分析的下游任务性能具有关键的作用。所以如何为相关从业人员提供该领域的最新信息,更好地挖掘分析该领域的最新事件动态、发展趋势、社区舆情,为办公室写作抓取精准的素材内容成为目前一大难点。
技术实现要素:
3.本发明的目的在于,提出一种领域新词的提取方法及系统,实现提升针对行业ugc、专业文献、内容数据的分词准确率,从而提升语义检索、智能推荐等下游任务的精度。
4.一方面,提供一种领域新词的提取方法,包括:
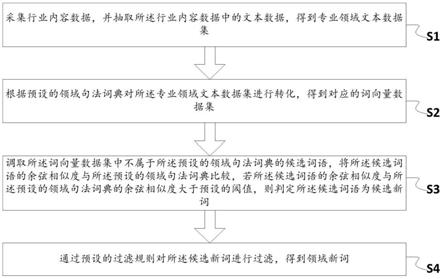
5.采集行业内容数据,并抽取所述行业内容数据中的文本数据,得到专业领域文本数据集;
6.根据预设的领域句法词典对所述专业领域文本数据集进行转化,得到对应的词向量数据集;
7.调取所述词向量数据集中不属于所述预设的领域句法词典的候选词语,将所述候选词语的余弦相似度与所述预设的领域句法词典比较,若所述候选词语的余弦相似度与所述预设的领域句法词典的余弦相似度大于预设的阈值,则判定所述候选词语为候选新词;
8.通过预设的过滤规则对所述候选新词进行过滤,得到领域新词。
9.优选地,获取所述预设的领域句法词典通过以下过程包括:
10.根据预设的通用领域词典对专业领域文本数据集进行清洗并标注,得到初步序列标注结果;
11.根据预设的电力专业领域标准词汇对所述初步序列标注结果进行补充标注,得到专业领域词典。
12.优选地,获取所述预设的领域句法词典通过以下过程还包括:
13.根据预设的自然语言处理算法逐句对所述专业领域词典进行重新分词和词性标注,统计每个领域词汇的tf-idf值;并根据预设的自然语言处理算法对专业领域文本数据集逐句进行分析,得到具有依存关系的词汇序列及每个词汇序列对应的词性标注序列;
14.按所述词性标注序列分组统计依存关系词汇序列的数量,当符合特定词性标注序列的依存关系词汇序列数量超过预设阈值时,将所述词性标注序列加入到句法模板列表
中,得到领域句法模板;
15.不重复的抽取所述词汇序列,当所述词汇序列中存在tf-idf值大于判定阈值的词汇且所述词汇序列存在所述专业领域词典中的词汇时,将所述词汇序列加入是领域句法模板,得到预设的领域句法词典。
16.优选地,所述得到对应的词向量数据集具体包括:
17.从预设的领域句法词典中抽取的领域句法模板;
18.根据所述领域句法模板从专业领域文本数据集中抽取符合所述领域句法模板的词汇或词组,并通过所述领域句法模板中的语言模块对抽取的词汇或词组进行训练,得到对应的词向量;
19.将所有对应的词向量组成对应的词向量数据集。
20.优选地,所述预设的过滤规则具体包括:
21.频次过滤,用以统计所述词向量数据集中候选新词的出现频次,并过滤出现频次小于预设出现频次阈值的候选新词;
22.最长子串过滤,用以抽取候选新词时,将按照预设长度的抽取候选新词的并将某个候选新词标定为关联的候选新词的子串,若最长长度的子串出现频率等于所述关联的候选新词,则将该候选新词过滤掉;
23.常见词过滤,用以过滤掉出现在预设的通用领域词典中的候选新词;
24.构词规则过滤,用以过滤无法通过词性标注抽取构词词性序列的候选新词。
25.另一方面,还提供一种领域新词的提取系统,用以实现所述的领域新词的提取方法,包括:
26.数据采集模块,用以采集行业内容数据,并抽取所述行业内容数据中的文本数据,得到专业领域文本数据集;
27.词向量模块,用以根据预设的领域句法词典对所述专业领域文本数据集进行转化,得到对应的词向量数据集;
28.新词筛选模块,用以调取所述词向量数据集中不属于所述预设的领域句法词典的候选词语,将所述候选词语的余弦相似度与所述预设的领域句法词典比较,若所述候选词语的余弦相似度与所述预设的领域句法词典的余弦相似度大于预设的阈值,则判定所述候选词语为候选新词;并通过预设的过滤规则对所述候选新词进行过滤,得到领域新词。
29.优选地,所述词向量模块还用于根据预设的通用领域词典对专业领域文本数据集进行清洗并标注,得到初步序列标注结果;
30.根据预设的电力专业领域标准词汇对所述初步序列标注结果进行补充标注,得到专业领域词典。
31.优选地,所述词向量模块还用于根据预设的自然语言处理算法逐句对所述专业领域词典进行重新分词和词性标注,统计每个领域词汇的tf-idf值;并根据预设的自然语言处理算法对专业领域文本数据集逐句进行分析,得到具有依存关系的词汇序列及每个词汇序列对应的词性标注序列;
32.按所述词性标注序列分组统计依存关系词汇序列的数量,当符合特定词性标注序列的依存关系词汇序列数量超过预设阈值时,将所述词性标注序列加入到句法模板列表中,得到领域句法模板;
33.不重复的抽取所述词汇序列,当所述词汇序列中存在tf-idf值大于判定阈值的词汇且所述词汇序列存在所述专业领域词典中的词汇时,将所述词汇序列加入是领域句法模板,得到预设的领域句法词典。
34.优选地,所述词向量模块还用于从预设的领域句法词典中抽取的领域句法模板;
35.根据所述领域句法模板从专业领域文本数据集中抽取符合所述领域句法模板的词汇或词组,并通过所述领域句法模板中的语言模块对抽取的词汇或词组进行训练,得到对应的词向量;
36.将所有对应的词向量组成对应的词向量数据集。
37.优选地,所述新词筛选模块还用于根据以下预设的过滤规则进行过滤:
38.频次过滤,用以统计所述词向量数据集中候选新词的出现频次,并过滤出现频次小于预设出现频次阈值的候选新词;
39.最长子串过滤,用以抽取候选新词时,将按照预设长度的抽取候选新词的并将某个候选新词标定为关联的候选新词的子串,若最长长度的子串出现频率等于所述关联的候选新词,则将该候选新词过滤掉;
40.常见词过滤,用以过滤掉出现在预设的通用领域词典中的候选新词;
41.构词规则过滤,用以过滤无法通过词性标注抽取构词词性序列的候选新词。
42.综上,实施本发明的实施例,具有如下的有益效果:
43.本发明提供的领域新词的提取方法及系统,通过新词发现并融合多种新词提取的方法可实现特定领域词汇的提取,可实现多角度、全方面的领域新词提取,且可提高专业文献、行业新闻的文本分析的分词准确率,从而提升自然语言处理下游任务的性能。
44.采集专业文献、行业新闻、企业内参、工作日志、行业ugc内容等行业内容数据,对抽取文本数据进行预处理,包括分句、分词、去停用词及无意义的符号、词性标注、句法分析。采用两种新词发现的算法发现领域新词;采用n元递增算法抽取语料中固定长度范围内的字符串作为候选新词。通过信息增益、邻接熵、词频-逆文档频率、骰子系数、邻接类别、点互信息等统计量结合多种筛选规则对候选新词进行新词发现。并基于依存句法分析与词向量表示分别实现新词抽取与新词判定。通过依存句法分析得到句法模板,利用句法模板确定新词边界。使用采集到的语料数据训练word2vec模型,将候选新词转换成向量的表示,计算候选词与已登录词的语义相似度,完成领域新词的判定。随后自动生成人工标注任务,由用户确认完成新词核准与入库。通过两种新词发现方法的融合,改善新词发现的效率,降低人工标注的工作量。
附图说明
45.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,根据这些附图获得其他的附图仍属于本发明的范畴。
46.图1为本发明实施例中一种领域新词的提取方法的主流程示意图。
47.图2为本发明实施例中一种领域新词的提取系统的示意图。
具体实施方式
48.为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
49.如图1所示,为本发明提供的一种领域新词的提取方法的一个实施例的示意图。在该实施例中,所述方法包括以下步骤:
50.采集行业内容数据,并抽取所述行业内容数据中的文本数据,得到专业领域文本数据集;也就是,采集专业文献、行业新闻、企业内参、工作日志、行业ugc内容等行业内容数据,抽取其中的文本数据,得到规范的专业领域文本数据集。
51.进一步的,根据预设的领域句法词典对所述专业领域文本数据集进行转化,得到对应的词向量数据集;也就是,基于预设的领域句法词典(包括句法词典和句法模板),结合依存句法分析和词向量技术,对特定领域最新文本集合进行领域新词发现。
52.具体实施例中,获取所述预设的领域句法词典通过以下过程包括:
53.根据预设的通用领域词典对专业领域文本数据集进行清洗并标注,得到初步序列标注结果;也就是,基于通用领域词典,使用hanlp自然语言处理工具包对抽取的文本数据进行预处理,完成句子切分、分词、去停用词、去标点符号基础的清洗处理操作,得到对采集语料的初步序列标注结果。
54.根据预设的电力专业领域标准词汇对所述初步序列标注结果进行补充标注,得到专业领域词典;也就是,对序列标注的结果进行校验(可采用人工或模型自动校验),补充标注电力专业领域中有价值的领域实体、实体属性、专有名词、术语等领域词汇,形成专业领域词典d1。
55.根据预设的自然语言处理算法逐句对所述专业领域词典进行重新分词和词性标注,统计每个领域词汇的tf-idf值;并根据预设的自然语言处理算法对专业领域文本数据集逐句进行分析,得到具有依存关系的词汇序列及每个词汇序列对应的词性标注序列;也就是,加载第一步清洗得到的规范的电力专业领域文本数据集;加载第一步得到的领域词典d1,使用hanlp自然语言处理工具包逐句进行重新分词和词性标注;计算每个领域词汇的tf-idf值,生成从当前语料中抽取的领域词表l1,每个词表中的一行数据为(word,postag,tf、tf-idf)。使用hanlp自然语言处理工具包对电力专业领域文本数据集逐句执行依存句法分析,基于每个识别的依存关系,得到具有依存关系的词汇序列以及每个词汇序列对应的词性标注序列。f-idf(term frequency
–
inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。tf是词频(term frequency),idf是逆文本频率指数(inverse document frequency)。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了tf-idf以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
56.按所述词性标注序列分组统计依存关系词汇序列的数量,当符合特定词性标注序列的依存关系词汇序列数量超过预设阈值时,将所述词性标注序列加入到句法模板列表中,得到领域句法模板;也就是,按词性标注序列分组统计依存关系词汇序列的数量,当符
合特定词性标注序列的依存关系词汇序列数量超过阈值θ1,(θ1》1)时,将词性标注序列加入到句法模板列表中。生成当前语料的句法模板全集。
57.不重复的抽取所述词汇序列,当所述词汇序列中存在tf-idf值大于判定阈值的词汇且所述词汇序列存在所述专业领域词典中的词汇时,将所述词汇序列加入是领域句法模板,得到预设的领域句法词典。也就是,逐条分析语料中抽取的不重复的依存词汇序列,当每个依存词汇序列中包含重要的领域词汇,且依存词汇序列是句法模板中特定模板的实例时,则将依存词汇序列加入句法词典。按如下规则判定一个词汇是否是领域中的重要词汇:a.序列中存在tf-idf值大于特定阈值θ2的词汇(对于采集的专业语料,θ2取0.01时,算法的f1-score最高);b.序列中存在专业领域词典d1的词汇。
58.具体地,所述得到对应的词向量数据集具体包括:从预设的领域句法词典中抽取的领域句法模板;根据所述领域句法模板从专业领域文本数据集中抽取符合所述领域句法模板的词汇或词组,并通过所述领域句法模板中的语言模块对抽取的词汇或词组进行训练,得到对应的词向量;将所有对应的词向量组成对应的词向量数据集。也就是,首先依据抽取的句法模板,从采集的文本中抽取符合模板的词汇或词组,采用gensim中的word2vec模块训练词向量。word2vec模块加载训练语料数据集,训练专业领域词向量,按如下配置设置模型参数,训练词向量。其中,size:每个词的向量维度;设定词向量的维度为200维;window:词向量训练时的上下文扫描窗口大小,窗口设置为5,即考虑样本句子的前5个词和后5个词;min-count:设置词汇最低出现频率,如果一个词语在文档中出现的次数小于3,则丢弃;workers:训练进程并发数,默认为当前运行机器的处理器核数。sg({0,1},optional)
–
模型的训练算法:1:skip-gram;0:cbow,当语料数据集小于500mb时,采用skip-gram模型,当语料数据集比较大时,采用cbow模型。alpha(float,optional)
–
初始学习率;iter(int,optional)
–
迭代次数,默认为5;保存训练生成的词向量数据集。基于训练生成的领域词向量数据集,采用group-max的向量融合算法,生成句法词典中每个词组的向量化的表示,即词组的向量表示。具体的转化方法是:将构成词组的每个词的词向量的第i维进行比较,取最大值作为词组向量的第i维,从而得到句法词典中每个词组的向量表示,保存句法词典的向量化表示。
59.进一步的,调取所述词向量数据集中不属于所述预设的领域句法词典的候选词语,将所述候选词语的余弦相似度与所述预设的领域句法词典比较,若所述候选词语的余弦相似度与所述预设的领域句法词典的余弦相似度大于预设的阈值,则判定所述候选词语为候选新词;也就是,计算每个词汇或词组的向量表示与专业领域词典及句法词典的余弦相似度。在句法模板库中,对于符合模板的未登录实例,如果存在相似度大于一定阈值的已登录词组或词汇,则可以认为未登录词是属于某个领域的候选新词。
60.进一步的,通过预设的过滤规则对所述候选新词进行过滤,得到领域新词。也就是,对候选新词,应用训练好的过滤规则模型进行过滤,提升领域新词发现的领域符合性和新颖性。
61.具体实施例中,所述预设的过滤规则具体包括:频次过滤,用以统计所述词向量数据集中候选新词的出现频次,并过滤出现频次小于预设出现频次阈值的候选新词;在新词发现任务中,有意义的新词会多次出现,代表特定语境下有意义的表达。通过设定字符串出现频次阈值过滤大量的低频字符串。最长子串过滤,用以抽取候选新词时,将按照预设长度
的抽取候选新词的并将某个候选新词标定为关联的候选新词的子串,若最长长度的子串出现频率等于所述关联的候选新词,则将该候选新词过滤掉;由于抽取候选新词的过程是将语料切分成一定长度的字符串,那么会存在某个候选新词是另一个候选新词的子串。设置最长子串过滤规则,如果最长子串出现频率等于父串,也就意味着最长子串不是单独的一个词语出现,而是作为父串的一部分出现,将最长子串的出现频率等于父串的这种最长子串过滤掉。常见词过滤,用以过滤掉出现在预设的通用领域词典中的候选新词;过滤掉出现在已登录词典(基础词库)中的候选词。构词规则过滤,用以过滤无法通过词性标注抽取构词词性序列的候选新词。通过词性标注抽取构词词性序列规则,过滤不符合规则的候选词。
62.具体地,抽取候选新词时,抽取语料中固定长度范围内的字符串,字符串长度设置为2~n,根据语料的情况,n最大设置为7。采用n-gram切分候选新词并统计词频。由于候选字符串是直接从语料中通过切分文本抽取出来的,其中,包含大量的低频字符串,通常为出现频率设置一个阈值,仅保留超过阈值的高频字符串,低于阈值的字符串会被过滤掉,从而大大降低候选新词的规模,降低后续操作的计算复杂度。计算互信息评价凝结度、左右邻接熵衡量候选新词的自由度。根据计算的统计量,应用多种过滤规则进行候选词过滤,主要的规则有:
63.频次过滤:在新词发现任务中,有意义的新词会多次出现,代表特定语境下有意义的表达。通过设定字符串出现频次阈值过滤大量的低频字符串。
64.最长子串过滤:由于抽取候选新词的过程是将语料切分成一定长度的字符串,那么会存在某个候选新词是另一个候选新词的子串。设置最长子串过滤规则,如果最长子串出现频率等于父串,也就意味着最长子串不是单独的一个词语出现,而是作为父串的一部分出现,将最长子串的出现频率等于父串的这种最长子串过滤掉。
65.常见词过滤:过滤掉出现在已登录词典(基础词库)中的候选词。
66.构词规则过滤:通过词性标注抽取构词词性序列规则,过滤不符合规则的候选词。
67.未被过滤的候选词形成新词,进入新词标注任务,由人工进行审核。人工审核通过后,发现的新词将导入领域词典。
68.如图2所示,为本发明提供的一种领域新词的提取系统的一个实施例的示意图。在该实施例中,包括:
69.数据采集模块,用以采集行业内容数据,并抽取所述行业内容数据中的文本数据,得到专业领域文本数据集。
70.词向量模块,用以根据预设的领域句法词典对所述专业领域文本数据集进行转化,得到对应的词向量数据集。
71.具体地,所述词向量模块还用于根据预设的通用领域词典对专业领域文本数据集进行清洗并标注,得到初步序列标注结果;根据预设的电力专业领域标准词汇对所述初步序列标注结果进行补充标注,得到专业领域词典。
72.所述词向量模块还用于根据预设的自然语言处理算法逐句对所述专业领域词典进行重新分词和词性标注,统计每个领域词汇的tf-idf值;并根据预设的自然语言处理算法对专业领域文本数据集逐句进行分析,得到具有依存关系的词汇序列及每个词汇序列对应的词性标注序列;按所述词性标注序列分组统计依存关系词汇序列的数量,当符合特定词性标注序列的依存关系词汇序列数量超过预设阈值时,将所述词性标注序列加入到句法
模板列表中,得到领域句法模板;不重复的抽取所述词汇序列,当所述词汇序列中存在tf-idf值大于判定阈值的词汇且所述词汇序列存在所述专业领域词典中的词汇时,将所述词汇序列加入是领域句法模板,得到预设的领域句法词典。
73.所述词向量模块还用于从预设的领域句法词典中抽取的领域句法模板;根据所述领域句法模板从专业领域文本数据集中抽取符合所述领域句法模板的词汇或词组,并通过所述领域句法模板中的语言模块对抽取的词汇或词组进行训练,得到对应的词向量;将所有对应的词向量组成对应的词向量数据集。
74.新词筛选模块,用以调取所述词向量数据集中不属于所述预设的领域句法词典的候选词语,将所述候选词语的余弦相似度与所述预设的领域句法词典比较,若所述候选词语的余弦相似度与所述预设的领域句法词典的余弦相似度大于预设的阈值,则判定所述候选词语为候选新词;并通过预设的过滤规则对所述候选新词进行过滤,得到领域新词。
75.具体地,所述新词筛选模块还用于根据以下预设的过滤规则进行过滤:频次过滤,用以统计所述词向量数据集中候选新词的出现频次,并过滤出现频次小于预设出现频次阈值的候选新词;最长子串过滤,用以抽取候选新词时,将按照预设长度的抽取候选新词的并将某个候选新词标定为关联的候选新词的子串,若最长长度的子串出现频率等于所述关联的候选新词,则将该候选新词过滤掉;常见词过滤,用以过滤掉出现在预设的通用领域词典中的候选新词;构词规则过滤,用以过滤无法通过词性标注抽取构词词性序列的候选新词。
76.综上,实施本发明的实施例,具有如下的有益效果:
77.本发明提供的领域新词的提取方法及系统,通过新词发现并融合多种新词提取的方法可实现特定领域词汇的提取,可实现多角度、全方面的领域新词提取,且可提高专业文献、行业新闻的文本分析的分词准确率,从而提升自然语言处理下游任务的性能。
78.采集专业文献、行业新闻、企业内参、工作日志、行业ugc内容等行业内容数据,对抽取文本数据进行预处理,包括分句、分词、去停用词及无意义的符号、词性标注、句法分析。采用两种新词发现的算法发现领域新词;采用n元递增算法抽取语料中固定长度范围内的字符串作为候选新词。通过信息增益、邻接熵、词频-逆文档频率、骰子系数、邻接类别、点互信息等统计量结合多种筛选规则对候选新词进行新词发现。并基于依存句法分析与词向量表示分别实现新词抽取与新词判定。通过依存句法分析得到句法模板,利用句法模板确定新词边界。使用采集到的语料数据训练word2vec模型,将候选新词转换成向量的表示,计算候选词与已登录词的语义相似度,完成领域新词的判定。随后自动生成人工标注任务,由用户确认完成新词核准与入库。通过两种新词发现方法的融合,改善新词发现的效率,降低人工标注的工作量。
79.以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。