一种整合高光谱和多频段全极化sar影像的沼泽植被堆栈集成学习分类方法
技术领域
1.本发明涉及植物分类的技术领域,具体涉及一种整合高光谱和多频段全极化sar影像的沼泽植被堆栈集成学习分类方法。
背景技术:
2.湿地内部生物物种丰富,但是人类难以深入湿地内部,且传统方法耗时耗力,而利用遥感对湿地进行信息获取是十分高效的方法。高光谱影像数据具有高光谱分辨率但易受云雨天气的影响,极化sar影像不惧云雨的干扰且不同频段sar数据具有不同的穿透能力,但其缺乏丰富的光谱信息。以往的分割多采用单一分割尺度,会出现分割效果不够良好从而导致分类精度不高的问题。由于湿地景观异质性高、组成复杂,使用单一分类器进行湿地分类仍然具有挑战性。
3.如专利申请201910079097.2公开了一种基于深度学习和植物分类学的植物识别方法。将样本植物图像进行科、属、种的标记;将样本植物图像输入深度卷积神经网络中进行训练。将损失函数设定为科、属、种标签的交叉熵损失的加权和,通过随机梯度下降算法更新神经网络的权值,待该深度卷积神经网络收敛后结束训练并固定各层权值不再改变得到训练好的深度卷积神经网络。
4.然而上述方法需要采集的数据太多,对于湿地的信息,我们仍处于摸索阶段,所以现有阶段实施效果并不是很好,一种可行的方式,是通过stacking模型集成多个模型的长处可以产生更好的结果,但stacking模型的基模型未经过参数调优,无法将模型的优势发挥到最大。而且,现有科学文献中也有很多基于遥感影像数据利用机器学习算法进行湿地植被分类的研究。然而,传统方法未将高光谱分辨率和不同频段全极化sar数据的穿透识别能力整合,或使用分类器单一且没有进行参数优化,导致无法将分类器的效果发挥到最优,从而无法对湿地植被进行高精度的分类。
技术实现要素:
5.为解决上述问题,本发明的目的是提供一种整合高光谱和多频段全极化sar影像的沼泽植被堆栈集成学习分类方法,该方法使用高光谱分辨率和不同频段全极化sar数据的穿透识别能力整合,解决单一数据源或单一分类器导致沼泽湿地植被无法被正确识别且易于混淆的问题。
6.本发明的另一个目的是提供一种整合高光谱和多频段全极化sar影像的沼泽植被堆栈集成学习分类方法,该方法对不同频段的全极化sar数据进行提取后向散射系数和极化分解参数,并与高光谱数据进行整合构建多源数据集,将高光谱影像数据的高光谱分辨率优势和极化sar影像可以穿透植被冠层获得丰富极化信息的优势充分结合,利用stacking算法将不同的优化参数后的分类器进行堆栈集成来构建沼泽植被分类模型,实现对沼泽湿地植被的高精度分类。
7.本发明的另一个目的是提供一种整合高光谱和多频段全极化sar影像的沼泽植被堆栈集成学习分类方法,该方法使用stacking算法将不同的优化参数后的分类器作为基分类器进行堆栈集合,构建沼泽湿地植被分类模型。通过找寻最佳相关系数剔除高相关变量,并使用boruta算法进行变量优选,降低输入训练数据的冗余,提高分类模型的效率和分类准确率,从而提高沼泽湿地植被的识别分类效率和精度。
8.本发明的另一个目的是提供一种整合高光谱和多频段全极化sar影像的沼泽植被堆栈集成学习分类方法,该方法利用拥有32个波段的高光谱数据、c频段全极化sar数据和l频段全极化sar数据作为数据源,提取后向散射系数和极化分解参数,建立多维数据集,解决数据信息少而导致识别分类精度不高的问题;利用基于继承的多尺度分割算法,对不同的植被类型找寻到最佳的分割参数并进行阈值分割,并使用分割指标定性评估分割结果,找寻最佳的分割结果,为后续的分类模型的建立提供最佳训练数据,提高沼泽湿地植被的识别分类精度。
9.一种整合高光谱和多频段全极化sar影像的沼泽植被堆栈集成学习分类方法,该方法将高光谱影像和不同频段全极化sar影像进行整合,通过多尺度分割、剔除高相关变量和boruta算法进行变量优选,构建多维变量数据集,利用stacking算法将不同的参数优化后的分类模型进行堆栈集成,构建沼泽植被识别分类模型,最后使用该模型对待分类数据进行分类得到沼泽湿地植被分类结果,并对分类结果使用评价指标进行定量评价。
10.进一步,所述方法进一步包括如下步骤:
11.步骤(1):对高光谱影像、c波段全极化sar影像、l波段全极化sar影像进行数据预处理;
12.利用envi5.3对高光谱影像进行辐射定标、大气校正和正射校正,对c波段全极化sar影像、l波段全极化sar影像进行提取后向散射系数,在polsarpro_v6.0中对c波段全极化sar影像、l波段全极化sar影像使用包括极化相干分解和极化非相干分解的多种极化分解方法进行极化分解,提取极化分解参数;
13.进一步,krogager分解可表示为:
[0014][0015]
式中,绝对相位δ为不相关参量,δs和ks用来描述球散射分量,相位参量θ和δs分别为球散射分量相对于二面角分量和螺旋体分量的偏移量,二面角分量和螺旋体分量的方位角,ks表示对最终散射矩阵[s]的贡献,ks,kd和kh分别是球分量、二面角分量和螺旋体分量的权重;
[0016]
huynen分解是将mueller矩阵分解为单一目标散射矩阵和分布式目标的矩阵之和,用相干散射矩阵进行表示,则时变目标的相干矩阵《[t3]》可以用9个自由度的实参数表示为:
[0017]
[0018][0019][0020][0021][0022][0023][0024]
其中,各个参数的具体含义如下:
[0025]
a0,目标的对称性因子;
[0026]b0-b,目标的非对称性因子;
[0027]
b0 b,目标的非规则性因子;
[0028]
c,构型因子;
[0029]
d,局部曲率差的度量;
[0030]
e,表面扭转;
[0031]
f,目标的螺旋性:
[0032]
g,对称和非对称部分的耦合;
[0033]
h,目标的方向性。
[0034]
三个分解参数为:t
11
=2a0、
[0035]
使用freeman-durden三分量散射机制模型进行极化分解,总的后向散射模型的协方差矩阵c3可表示为:
[0036][0037][0038]
公式中,fv、fs和fd为极化分解参数,分别代表了体散射分量、二次散射分量和奇次散射分量的权;
[0039]
yamaguchi四分量散射模型在三分量散射模型的基础上添加了第四个散射分量,等价于一个螺旋散射体的散射功率,总的后向散射模型的协方差矩阵可表示为:
[0040][0041]
式中,选择当10log(|s
vv
|2/|d
hh
|2)>2db时对应的体散射分量:
[0042][0043]fs
、fh、fv、fh为四种极化分解参数,分别对应表面散射、二次散射、体散射和螺旋散射分量的权重;
[0044]
步骤(2):对预处理后的影像进行波段合成、地理配准、裁剪等操作构建分割数据集;
[0045]
在arcgis 10.6中对步骤(1)中处理好的高光谱影像、极化分解参数和后向散射系数进行波段合成、地理配准、裁剪等操作,构建分割的多源数据集;
[0046]
步骤(3):对分割数据集进行基于继承的多尺度分割;
[0047]
具体地说,在ecognition developer9.4对分割数据集进行基于继承的多尺度分割,通过反复测试和调整,确定最佳分割尺度和参数,为每种地类在不同分割尺度内进行阈值分割,最后将分割好的各地类合并为一个多尺度分割的图层;
[0048]
步骤(4):通过分割评价指标对分割结果进行定量评价;
[0049]
进一步,使用以下分割指标来评价分割质量:
[0050][0051]
v为全局方差,用来衡量对象内部的同质性,v越小对象内部的同质性越好,式中vi是分割对象i的标准差,ai是分割对象i的面积,n为整个影像区域分割对象的总数;
[0052][0053]
i为莫兰指数,用来评估分割对象之间的异质性,式中n为分割对象的总数,w
ij
表示对象ai和对象bj之间的邻接关系,如果对象ai和对象bj对之间邻接,则w
ij
=1,否则w
ij
=0;yi为对象ai的光谱平均值,为整个影像的光谱平均值,i越低,影像分割对象之间的相关性越低,即影像对象之间的可分性越好;
[0054][0055]
[0056][0057]
rmas表示对象与邻域的平均差分的绝对值同对象标准差的比值,用来评价影像分割尺度的好坏,其中l为分割数据集的影像波段层数,δc
l
为分割数据集l波段层单个尺度分割对象的与邻域均值差分绝对值,s
l
为l波段层单个分割尺度下分割对象的标准差,c
li
为l波段层i像素点的灰度值,为单个尺度分割层上的波段均值,n为像素个数,m为与目标对象直接相邻的对象个数,d为目标对象的边界长度,d
sj
为目标对象和第j个直接相邻对象的公共边界长度;
[0058]
步骤(5):通过对分割结果进行特征计算和输出,构建多维度特征数据集;
[0059]
进一步,在ecognition developer9.4中对分割结果计算5种植被指数(cigreen、cireg、ndvi、rvi、gndvi)和归一化水指数(ndwi);基于统计描述的灰度共生矩阵被证明对于提高湿地分类精度具有重要作用,故利用灰度共生矩阵计算常用于提取遥感影像中纹理信息的八种纹理特征(同质性、对比度、非相似性、熵、角度二阶矩、均值、相关性、标准差)作为输入纹理特征变量;另外还计算并输出了位置特征、光谱特征、后向散射系数、极化分解参数,最终构建了具有多维度的特征数据集,其中植被指数计算公式为:
[0060][0061]
ci
green
为绿色叶绿素指数,其中nir代表高光谱的近红外波段,green代表高光谱的绿波段;
[0062][0063]
ci
reg
为红边叶绿素指数,其中reg代表了高光谱的红边波段;
[0064][0065]
ndvi为归一化差异植被指数,其中red代表了高光谱的红波段;
[0066][0067]
rvi为比值植被指数;
[0068][0069]
gndvi为绿色归一化差异植被指数;
[0070][0071]
ndwi为归一化差异水指数;
[0072]
步骤(6):通过剔除高相关变量和boruta算法对特征数据集进行降维优选;
[0073]
将相关系数的调优值设为0-1,步长为0.05,剔除大于相关系数阈值范围的变量,将剔除高相关变量后的特征数据集使用boruta算法进行变量选择,将模型训练精度最高的特征数据集作为优选特征数据集,对应的相关系数为最佳相关系数;
[0074]
进一步,boruta算法进行变量选择的算法如下所示:
[0075]
1)对特征矩阵x的各个特征取值进行随机打乱得到影子特征,将影子特征与原特
征拼接构成新的特征矩阵;
[0076]
3)通过添加特性来移除它们与响应的相关性;
[0077]
3)在扩展的特征集上使用随机森林计算每个特征的重要性得分;
[0078]
4)对于每一个真实特征变量,统计检验其与所有影子特征的重要性最大值的差别,重要性显著高于影子特征的真实特征定义为“重要”,重要性显著低于影子特征的真实特征定义为“不重要”;
[0079]
5)移除影子特征和被定义为“不重要”的特征;
[0080]
6)重复以上过程,直到所有变量被指定为“重要”或“不重要”。
[0081]
步骤(7):使用优选特征数据集作为训练数据对基分类器进行参数调优;
[0082]
进一步,使用的基分类器为rf、xgboost和catboost,使用网格调优法为每种分类器进行参数调优;
[0083]
使用multi_logloss作为评价指标,选取multi_logloss最小时对应的参数值作为最优参数,将设置了最优参数的模型作为调优后的最佳基模型;
[0084]
步骤(8):使用stacking算法将优化的基分类器进行堆栈集成构建沼泽湿地植被识别模型;
[0085]
进一步,使用stacking算法将将步骤(7)中优化后的三种分类器作为基模型进行堆栈集成,使用stacking集成训练模型的过程如下所示:
[0086]
输入:
[0087]
优选特征数据集d={(x1,y1),(x2,y2),
…
,(xm,ym)};
[0088]
初级学习算法δ1,δ2,δ3,
…
,δ
t
;
[0089]
次级学习算法δs;
[0090]
训练过程:
[0091][0092]
输出:
[0093]
h(x)=h
′
(h1(x),h2(x),
…
,h
t
(x))
[0094]
h(x)为最终的优化stacking沼泽植被堆栈集成学习分类模型;
[0095]
步骤(9):使用构建好的沼泽湿地植被分类模型进行分类,得到沼泽湿地植被分类结果;
[0096]
使用上述构建好的优化分类模型,输入待分类数据,得到沼泽湿地植被分类及分布结果;
[0097]
步骤(10):对分类结果进行精度评价;
[0098]
输入验证样本,通过混淆矩阵计算相应评价指标对分类结果进行精度评价,包括以下指标:
[0099][0100]
ua为用户精度,代表被正确分为i类沼泽植被的样本总数(对角线值)与分类器将样本分为i类地物总数(混淆矩阵中i类沼泽植被行的总和)的比率;
[0101][0102]
pa为用户精度,指分类器将整个影像的样本正确分为i类沼泽植被的样本数(对角线值)与真实i类沼泽植被真实样本总数(混淆矩阵中i类沼泽植被列的总和)的比率;
[0103][0104]
oa为总体分类精度,指所有正确分类的类别样本个数之和(混淆矩阵中对角线的总和)与所有检验样本个数的总和的比率,式中m为样本总数;
[0105][0106]
kappa系数为表示分类结果比随机分类好多少的指标,x
ii
表示混淆矩阵的对角线元素,x
i
表示类别的列总和,x
i
表示类别的行总和。
[0107]
相比于现有技术,本发明优点在于:
[0108]
本发明通过将高光谱影像丰富的光谱信息优势和极化sar影像能穿透植被冠层的优势进行整合来实现沼泽植被高精度识别与分类;具体地说,是通过对全极化sar数据提取后向散射系数和提取极化分解参数,并整合高光谱数据构建多维度分割数据集以提高分类信息维度;通过使用基于继承的多尺度分割算法分割影像数据集,提高分割精度;通过设置相关系数剔除高相关变量和使用boruta算法对数据集进行变量选择,降低数据冗余来提高分类模型的效率与精度;通过stacking堆栈算法集成多种已经过调优的机器学习分类模型构建沼泽植被分类模型,实现对沼泽湿地植被的高精度识别和分类。
附图说明
[0109]
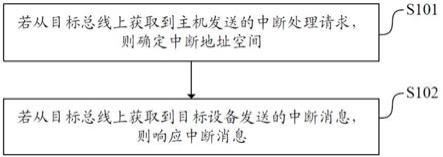
图1是本发明实现的流程图。
[0110]
图2是不同数据源方案沼泽植被分类结果图。
[0111]
图3是本发明整合高光谱和不同频段全极化sar数据方案的湿地各地类的生产者精度和用户精度热力图。
[0112]
图4不同方案相关系数、优选变量个数与各分类器分类精度之间相关性矩阵散点
图。
具体实施方式
[0113]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0114]
如图1所示是本发明实现的流程图,将高光谱影像和不同频段全极化sar影像进行整合,通过多尺度分割、剔除高相关变量和boruta算法进行变量优选,构建多维变量数据集,利用stacking算法将不同的参数优化后的分类模型进行堆栈集成,构建沼泽植被识别分类模型,最后使用该模型对待分类数据进行分类得到沼泽湿地植被分类结果,并对分类结果使用评价指标进行定量评价。
[0115]
以下分别说明各个实现步骤,以提供参考。
[0116]
步骤(1):对高光谱影像、c波段全极化sar影像、l波段全极化sar影像进行数据预处理;
[0117]
利用envi5.3对高光谱影像进行辐射定标、大气校正和正射校正,对c波段全极化sar影像、l波段全极化sar影像进行提取后向散射系数,在polsarpro_v6.0中对c波段全极化sar影像、l波段全极化sar影像使用包括极化相干分解和极化非相干分解的多种极化分解方法进行极化分解,提取极化分解参数;
[0118]
krogager分解可表示为:
[0119][0120]
式中,绝对相位δ为不相关参量,δs和ks用来描述球散射分量,相位参量θ和δs分别为球散射分量相对于二面角分量和螺旋体分量的偏移量,二面角分量和螺旋体分量的方位角,ks表示对最终散射矩阵[s]的贡献,ks,kd和kh分别是球分量、二面角分量和螺旋体分量的权重;
[0121]
huynen分解是将mueller矩阵分解为单一目标散射矩阵和分布式目标的矩阵之和,用相干散射矩阵进行表示,则时变目标的相干矩阵《[t3]》可以用9个自由度的实参数表示为:
[0122][0123][0124][0125][0126]
[0127][0128][0129]
其中,各个参数的具体含义如下:
[0130]
a0,目标的对称性因子;
[0131]b0-b,目标的非对称性因子;
[0132]
b0 b,目标的非规则性因子;
[0133]
c,构型因子;
[0134]
d,局部曲率差的度量;
[0135]
e,表面扭转;
[0136]
f,目标的螺旋性:
[0137]
g,对称和非对称部分的耦合;
[0138]
h,目标的方向性。
[0139]
三个分解参数为:t
11
=2a0、
[0140]
使用freeman-durden三分量散射机制模型进行极化分解,总的后向散射模型的协方差矩阵c3可表示为:
[0141][0142][0143]
公式中,fv、fs和fd为极化分解参数,分别代表了体散射分量、二次散射分量和奇次散射分量的权;
[0144]
yamaguchi四分量散射模型在三分量散射模型的基础上添加了第四个散射分量,等价于一个螺旋散射体的散射功率,总的后向散射模型的协方差矩阵可表示为:
[0145][0146]
式中,选择当10log(|s
vv
|2/|s
hh
|2)>2db时对应的体散射分量:
[0147][0148]fs
、fh、fv、fh为四种极化分解参数,分别对应表面散射、二次散射、体散射和螺旋散射分量的权重;
[0149]
步骤(2):对预处理后的影像进行波段合成、地理配准、裁剪等操作构建分割数据集;
[0150]
在arcgis 10.6中对步骤(1)中处理好的高光谱影像、极化分解参数和后向散射系数进行波段合成、地理配准、裁剪等操作,构建分割的多源数据集;
[0151]
步骤(3):对分割数据集进行基于继承的多尺度分割;
[0152]
在ecognition developer9.4对分割数据集进行基于继承的多尺度分割,通过反复测试和调整,确定最佳分割尺度和参数,为每种地类在不同分割尺度内进行阈值分割,最后将分割好的各地类合并为一个多尺度分割的图层;
[0153]
步骤(4):通过分割评价指标对分割结果进行定量评价;
[0154]
理想的影像分割结果为:(1)分割得到的对象内部具有良好的同质性;(2)分割得到的对象应该与邻接对象具有良好的异质性。根据以上分割标准,使用以下分割指标来评价分割质量:
[0155][0156]
v为全局方差,用来衡量对象内部的同质性,v越小对象内部的同质性越好,式中vi是分割对象i的标准差,ai是分割对象i的面积,n为整个影像区域分割对象的总数;
[0157][0158]
i为莫兰指数,用来评估分割对象之间的异质性,式中n为分割对象的总数,w
ij
表示对象ai和对象bj之间的邻接关系,如果对象ai和对象bj对之间邻接,则w
ij
=1,否则w
ij
=0;yi为对象ai的光谱平均值,为整个影像的光谱平均值,i越低,影像分割对象之间的相关性越低,即影像对象之间的可分性越好;
[0159][0160][0161][0162]
rmas表示对象与邻域的平均差分的绝对值同对象标准差的比值,用来评价影像分割尺度的好坏,其中l为分割数据集的影像波段层数,δc
l
为分割数据集l波段层单个尺度分割对象的与邻域均值差分绝对值,s
l
为l波段层单个分割尺度下分割对象的标准差,c
li
为l波段层i像素点的灰度值,为单个尺度分割层上的波段均值,n为像素个数,m为与目标对象直接相邻的对象个数,d为目标对象的边界长度,d
sj
为目标对象和第j个直接相邻对象的公共边界长度;
[0163]
步骤(5):通过对分割结果进行特征计算和输出,构建多维度特征数据集;
[0164]
在ecognition developer9.4中对分割结果计算5种植被指数(cigreen、cireg、ndvi、rvi、gndvi)和归一化水指数(ndwi);基于统计描述的灰度共生矩阵被证明对于提高湿地分类精度具有重要作用,故利用灰度共生矩阵计算常用于提取遥感影像中纹理信息的八种纹理特征(同质性、对比度、非相似性、熵、角度二阶矩、均值、相关性、标准差)作为输入纹理特征变量;另外还计算并输出了位置特征、光谱特征、后向散射系数、极化分解参数,最终构建了具有多维度的特征数据集,其中植被指数计算公式为:
[0165][0166]
ci
green
为绿色叶绿素指数,其中nir代表高光谱的近红外波段,green代表高光谱的绿波段;
[0167][0168]
ci
reg
为红边叶绿素指数,其中reg代表了高光谱的红边波段;
[0169][0170]
ndvi为归一化差异植被指数,其中red代表了高光谱的红波段;
[0171][0172]
rvi为比值植被指数;
[0173][0174]
gndvi为绿色归一化差异植被指数;
[0175][0176]
ndwi为归一化差异水指数;
[0177]
步骤(6):通过剔除高相关变量和boruta算法对特征数据集进行降维优选;
[0178]
将相关系数的调优值设为0-1,步长为0.05,剔除大于相关系数阈值范围的变量,将剔除高相关变量后的特征数据集使用boruta算法进行变量选择,将模型训练精度最高的特征数据集作为优选特征数据集,对应的相关系数为最佳相关系数,其中boruta算法是一种基于随机森林算法的特征排序和选择算法,boruta算法的优点在于它考虑了森林中树木之间平均准确度损失的波动,可以清楚地决定一个变量是否重要,boruta算法进行变量选择的算法如下所示:
[0179]
1)对特征矩阵x的各个特征取值进行随机打乱得到影子特征,将影子特征与原特征拼接构成新的特征矩阵;
[0180]
4)通过添加特性来移除它们与响应的相关性;
[0181]
3)在扩展的特征集上使用随机森林计算每个特征的重要性得分;
[0182]
4)对于每一个真实特征变量,统计检验其与所有影子特征的重要性最大值的差别,重要性显著高于影子特征的真实特征定义为“重要”,重要性显著低于影子特征的真实特征定义为“不重要”;
[0183]
5)移除影子特征和被定义为“不重要”的特征;
[0184]
6)重复以上过程,直到所有变量被指定为“重要”或“不重要”。
[0185]
步骤(7):使用优选特征数据集作为训练数据对基分类器进行参数调优;
[0186]
本方法使用的基分类器为rf、xgboost和catboost,使用网格调优法为每种分类器进行参数调优;
[0187]
rf分类器是利用多棵决策树对样本进行训练并预测的一种分类器,它具有不易过拟合、能处理高维数据、实现简单、训练速度快等优点,对于rf分类器优化的参数为节点值mtry和决策树数目ntree,将mtry的调优范围设为500-2500,步长设为500;
[0188]
xgboost分类器是在gbdt基础上对boosting算法进行的改进,内部决策树使用的是回归树,具有速度快、效果好、能处理大规模数据、支持自定义损失函数等优点,对于xgboost分类器进行优化的参数设置如下:
[0189][0190]
catboost分类器也是在gbdt算法框架下的一种改进实现,catboost解决了梯度偏差以及预测偏移的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力,对于catboost分类器进行优化的参数设置如下:
[0191][0192]
使用multi_logloss作为评价指标,选取multi_logloss最小时对应的参数值作为最优参数,将设置了最优参数的模型作为调优后的最佳基模型;
[0193]
步骤(8):使用stacking算法将优化的基分类器进行堆栈集成构建沼泽湿地植被识别模型;
[0194]
使用stacking算法将将步骤(7)中优化后的三种分类器作为基模型进行堆栈集成,使用stacking集成训练模型的过程如下所示:
[0195]
输入:
[0196]
优选特征数据集d={(x1,y1),(x2,y2),
…
,(xm,ym)};
[0197]
初级学习算法δ1,δ2,δ3,
…
,δr;
[0198]
次级学习算法δs;
[0199]
训练过程:
[0200][0201][0202]
输出:
[0203]
h(x)=h
′
(h1(x),h2(x),
…
,h
t
(x))
[0204]
h(x)为最终的优化stacking沼泽植被堆栈集成学习分类模型;
[0205]
步骤(9):使用构建好的沼泽湿地植被分类模型进行分类,得到沼泽湿地植被分类结果;
[0206]
使用上述构建好的优化分类模型,输入待分类数据,得到沼泽湿地植被分类及分布结果;
[0207]
步骤(10):对分类结果进行精度评价;
[0208]
输入验证样本,通过混淆矩阵计算相应评价指标对分类结果进行精度评价,包括以下指标:
[0209][0210]
ua为用户精度,代表被正确分为i类沼泽植被的样本总数(对角线值)与分类器将样本分为i类地物总数(混淆矩阵中i类沼泽植被行的总和)的比率;
[0211][0212]
pa为用户精度,指分类器将整个影像的样本正确分为i类沼泽植被的样本数(对角线值)与真实i类沼泽植被真实样本总数(混淆矩阵中i类沼泽植被列的总和)的比率;
[0213][0214]
oa为总体分类精度,指所有正确分类的类别样本个数之和(混淆矩阵中对角线的总和)与所有检验样本个数的总和的比率,式中m为样本总数;
[0215]
[0216]
kappa系数为表示分类结果比随机分类好多少的指标,x
ii
表示混淆矩阵的对角线元素,x
i
表示类别的列总和,x
i
表示类别的行总和。
[0217]
图2为不同数据源方案沼泽植被分类结果图,通过分类结果的对比可以看出,整合高光谱数据和不同频段全极化sar数据可以获得较好的分类提取效果,地类区分明显,分布精确。
[0218]
图3为整合高光谱和不同频段全极化sar数据方案的沼泽各地类的生产者精度和用户精度热力图,从中看出,各植被类型的生产者精度和用户精度都比较高。
[0219]
图4为不同方案相关系数、优选变量个数与各分类器分类精度之间相关性矩阵散点图。图中所示,各植被类型的优选变量个数与各分类器分类精度都比较高。
[0220]
本发明通过将高光谱影像丰富的光谱信息优势和极化sar影像能穿透植被冠层的优势进行整合来实现沼泽植被高精度识别与分类;通过对全极化sar数据提取后向散射系数和提取极化分解参数,并整合高光谱数据构建多维度分割数据集以提高分类信息维度;通过使用基于继承的多尺度分割算法分割影像数据集,提高分割精度;通过设置相关系数剔除高相关变量和使用boruta算法对数据集进行变量选择,降低数据冗余来提高分类模型的效率与精度;通过stacking堆栈算法集成多种已经过调优的机器学习分类模型构建沼泽植被分类模型,实现对沼泽湿地植被的高精度识别和分类。
[0221]
总之,本发明的优点如下:
[0222]
1.通过整合高光谱影像和不同频段全极化sar影像,充分利用高光谱分辨率优势和不同频段极化sar数据对于植被结构的穿透识别能力,解决由于数据源单一而导致的各类沼泽植被产生混淆而无法被精确识别的问题。
[0223]
2.通过对分割数据集使用经过定量评价之后的最佳分割参数进行基于继承的多尺度阈值分割,提高分割质量,为后续的模型建立提供了良好的训练数据。
[0224]
3.通过寻找并设置最佳的相关系数剔除高相关变量和使用boruta算法来进行特征优选,解决由于数据冗余而导致的模型运行效率低、分类精度不高的问题。
[0225]
4.通过使用stacking算法将多种分类器分别进行参数优化并进行堆栈集合,整合各个分类器的优点,提高了模型对于景观异质性高、组成复杂的沼泽湿地植被的分类能力。
[0226]
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。