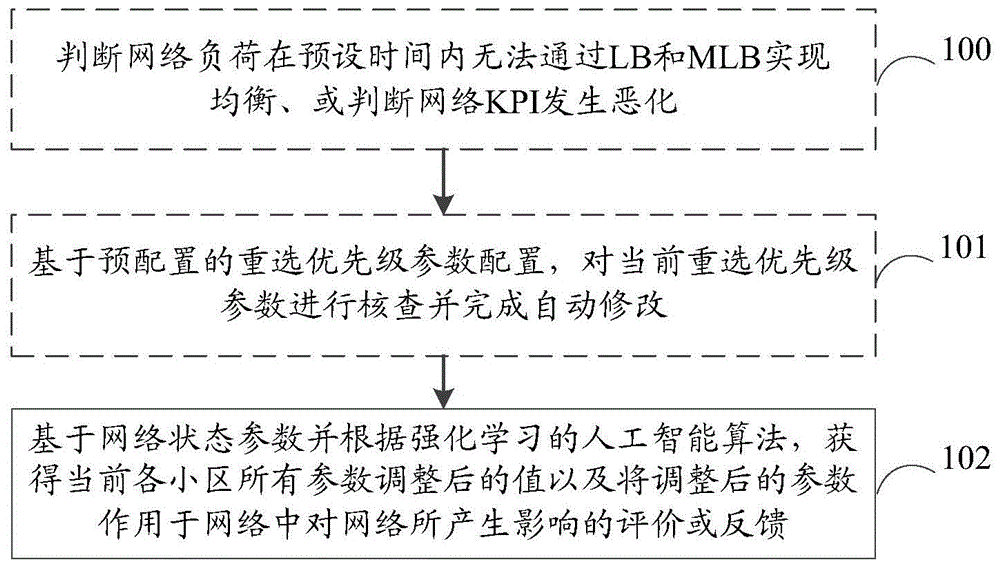
本发明涉及移动通信
技术领域:
,尤其涉及一种负载均衡优化方法、装置和计算机可读存储介质。
背景技术:
随着4G终端的普及,4G网络的用户数逐渐增加,网络负荷随之增加。若不能通过负载均衡功能使得不同载波间的负荷达到均衡,可能会导致某一个或几个载波上的小区负荷较高,用户的QoS难以达到保障。现网中,由于4G网络中频段多而零散,邻区配置工作量较大;其次,影响负载均衡效果的参数较多,参数优化调整工作量大且需考虑的因素较多;最后,由于不同小区的负载均衡参数千变万化,加剧了参数的优化难度。技术实现要素:有鉴于此,本发明实施例期望提供一种负载均衡优化方法、装置和计算机可读存储介质。为达到上述目的,本发明实施例的技术方案是这样实现的:本发明实施例提供了一种负载均衡优化方法,该方法应用于网络设备,包括:基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈。其中,所述网络状态参数包括但不限于以下一种或多种:小区负荷以及小区间的负荷差;网络的关键性能指标KPI;当前各小区的参数配置值。其中,所述参数配置值包括但不限于以下一种或多种:负载均衡参数配置值;切换参数配置值;重选参数配置值。可选的,所述基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈之前,该方法还包括:判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化;基于预配置的重选优先级参数配置,对当前重选优先级参数进行核查并完成自动修改。可选的,所述判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化之前,该方法还包括:基于基站工参中的基站形态和/或通道数,对不同小区的负载均衡触发门限进行差异化配置和调整;其中,所述负载均衡触发门限包括但不限于:物理资源块PRB利用率门限、用户数门限。其中,所述强化学习的人工智能算法包括但不限于:策略梯度policygradient算法、行为评判算法actor-critic。其中,所述强化学习的人工智能算法为行为评判算法actor-critic时,训练时至少需要两个神经网络,所述两个神经网络的输入为:所述网络状态参数;一个神经网络的输出为:在网络状态S下,当前各小区所有参数调整后的结果;另一个神经网络的输出为:在网络状态S下执行参数调整动作后的价值。其中,所述人工智能算法的输入的调整方法包括但不限于以下几种:当出现小区间用户数差异较大时,优先调整评估周期大小、用户数触发门限、以及单个周期内选取的最大用户数门限;当出现小区间PRB利用率差异较大时,优先调整评估周期大小、PRB利用率触发门限、选取用户的PRB占比门限、以及单个周期内选取的最大用户数门限;在对本小区负载均衡的A4门限、邻区覆盖的A2、A5门限自动调整时,保持本小区A4门限不小于邻区A5第一门限的原则、或者保持本小区A4不小于邻区A2门限的原则;其中,所述A2、A4和A5门限为小区级门限或用户级门限。可选的,该方法还包括:在小区间交互如下信息至少之一:网络的KPI信息;小区重选参数配置信息;小区级和/或用户级切换参数配置信息;负载均衡参数配置信息;实时的负载信息。其中,所述信息的交互为:周期性交互、或为事件触发交互。其中,所述信息的交互通过如下一种或多种方式实现:在小区间通过基站内部的接口交互;在小区间通过网管交互;在小区间通过Xn和/或X2和/或S1和/或NG接口交互。其中,所述在小区间通过Xn和/或X2和/或S1和/或NG接口交互时,该方法包括:在Xn和/或X2和/或S1和/或NG交互流程中增设网络KPI信息、参数配置信息、实时负载信息的交互;或者,增设新的Xn和/或X2和/或S1和/或NG交互流程。可选的,该方法还包括:基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。本发明实施例还提供了一种负载均衡优化方法,该方法应用于网络设备,包括:基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。本发明实施例还提供了一种负载均衡优化装置,该装置应用于网络设备,包括:处理模块,用于基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈。本发明实施例还提供了一种负载均衡优化装置,该装置应用于网络设备,包括:调整配置模块,用于基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。本发明实施例还提供了一种负载均衡优化装置,该装置包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,其中,所述处理器用于运行所述计算机程序时,执行上述方法的步骤。本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。本发明实施例提供的负载均衡优化方法、装置和计算机可读存储介质,网络设备基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈。本发明实施例基于基站工参等网络状态参数差异化配置各小区的参数,可实现对负载均衡参数自动的差异化配置,使得不同基站配置的参数合理,从而保障均衡用户切换前后的业务体验。而且,本发明实施例通过采用强化学习的人工智能算法,可实现对二十多个参数的自动优化,加快网络负载的均衡,改善网络的KPI。此外,本发明实施例实现了网络的自动优化,大大减少了人工调整参数的工作量。同时,支持为不同能力终端配置或调整其负载均衡优先级,降低某些能力等级终端被负载均衡的概率,以降低对用户体验的影响。附图说明图1为本发明实施例所述负载均衡优化方法流程示意图;图2为本发明实施例所述负载均衡优化装置结构示意图;图3为本发明场景实施例所述对影响负载均衡效果的参数进行优化的示意图;图4为本发明场景实施例所述强化学习的架构示意图;图5为本发明场景实施例所述强化学习为策略梯度时的神经网络示意图;图6为本发明场景实施例所述强化学习为行为评判算法时的神经网络示意图;图7为本发明场景实施例所述强化学习采用行为评判算法的训练流程图。具体实施方式下面结合附图和实施例对本发明进行描述。可知,由于4G网络中频段多而零散,包括TDD的F频段、D频段、E频段、A频段(3G重耕)以及FDD900、1800M,且每个频段中有不止一个4G载波,使得4G网络中就存在10余个载波,邻区配置工作量较大;其次,影响负载均衡效果的参数较多,包括空闲态重选参数、连接态切换参数,以及LB/MLB参数共计20余个参数,且参数之间有相应的制约和联动的关系(如负载触发的MLB功能调整的为CIO即切换参数,则会对切换的KPI产生影响(如出现过早或过晚切换现象),故不能对CIO参数调整范围过大(协议定义该参数调整范围[-24,24]dB)),参数优化调整工作量大且需考虑的因素较多;最后,不同小区的覆盖情况、不同时间的负荷情况、重选/切换参数各不相同,导致不同小区的负载均衡参数也需千变万化,需要“一时一策、一站一策”,进一步加剧了参数的优化难度,可见,负载均衡现网应用效果不佳。基于此,本发明实施例提供了一种负载均衡优化方法,该方法应用于网络设备,如图1所示,包括:步骤102:基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈。本发明实施例中,当前各小区的参数至少包括:负载均衡参数、切换参数和重选参数等。本发明实施例中,所述网络状态参数包括但不限于以下一种或多种:小区负荷以及小区间的负荷差;网络的关键性能指标KPI;当前各小区的参数配置值。本发明实施例中,所述参数配置值包括但不限于以下一种或多种:负载均衡参数配置值;切换参数配置值;重选参数配置值。本发明一个实施例中,如图1所示,所述基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈之前,该方法还包括:步骤100:判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化;步骤101:基于预配置的重选优先级参数配置,对当前重选优先级参数进行核查并完成自动修改。本发明另一个实施例中,所述判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化之前,该方法还包括:基于基站工参中的基站形态和/或通道数,对不同小区的负载均衡触发门限进行差异化配置和调整;其中,所述负载均衡触发门限包括但不限于:物理资源块PRB利用率门限、用户数门限。本发明实施例中,所述强化学习的人工智能算法包括但不限于:策略梯度policygradient算法、行为评判算法actor-critic。本发明实施例中,所述强化学习的人工智能算法为行为评判算法actor-critic时,训练时至少需要两个神经网络,所述两个神经网络的输入为:所述网络状态参数;一个神经网络的输出为:在网络状态S下,当前各小区所有参数(各小区的负载均衡参数、切换参数和重选参数等)调整后的结果;另一个神经网络的输出为:在网络状态S下执行参数调整动作后的价值。本发明实施例中,所述人工智能算法的输入的调整方法包括但不限于以下几种:当出现小区间用户数差异较大时,优先调整评估周期大小、用户数触发门限、以及单个周期内选取的最大用户数门限;当出现小区间PRB利用率差异较大时,优先调整评估周期大小、PRB利用率触发门限、选取用户的PRB占比门限、以及单个周期内选取的最大用户数门限;在对本小区负载均衡的A4门限、邻区覆盖的A2、A5门限自动调整时,保持本小区A4门限不小于邻区A5第一门限的原则、或者保持本小区A4不小于邻区A2门限的原则;其中,所述A2、A4和A5门限为小区级门限或用户级门限。本发明一个实施例中,该方法还包括:在小区间交互如下信息至少之一:网络的KPI信息;小区重选参数配置信息;小区级和/或用户级切换参数配置信息;负载均衡参数配置信息;实时的负载信息。本发明实施例中,所述信息的交互为:周期性交互、或为事件触发交互。本发明实施例中,所述信息的交互通过如下一种或多种方式实现:在小区间通过基站内部的接口交互;在小区间通过网管交互;在小区间通过Xn和/或X2和/或S1和/或NG接口交互。本发明一个实施例中,所述在小区间通过Xn和/或X2和/或S1和/或NG接口交互时,该方法包括:在Xn和/或X2和/或S1和/或NG交互流程中增设网络KPI信息、参数配置信息、实时负载信息的交互;或者,增设新的Xn和/或X2和/或S1和/或NG交互流程。本发明一个实施例中,该方法还包括:基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。本发明实施例还提供了一种负载均衡优化方法,该方法应用于网络设备,包括:基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。为了实现上述方法实施例,本发明实施例还提供了一种负载均衡优化装置,如图2所示,该装置应用于网络设备,包括:处理模块201,用于基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈。本发明实施例中,当前各小区的参数至少包括:负载均衡参数、切换参数和重选参数等。本发明实施例中,所述网络状态参数包括但不限于以下一种或多种:小区负荷以及小区间的负荷差;网络的关键性能指标KPI;当前各小区的参数配置值。本发明实施例中,所述参数配置值包括但不限于以下一种或多种:负载均衡参数配置值;切换参数配置值;重选参数配置值。本发明一个实施例中,如图2所示,该装置还包括:判断模块200;所述处理模块201基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈之前,所述判断模块200,用于判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化;相应的,所述处理模块201,还用于基于预配置的重选优先级参数配置,对当前重选优先级参数进行核查并完成自动修改。本发明另一个实施例中,所述判断模块200判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化之前,还用于基于基站工参中的基站形态和/或通道数,对不同小区的负载均衡触发门限进行差异化配置和调整;其中,所述负载均衡触发门限包括但不限于:物理资源块PRB利用率门限、用户数门限。本发明实施例中,所述强化学习的人工智能算法包括但不限于:策略梯度policygradient算法、行为评判算法actor-critic。本发明实施例中,所述强化学习的人工智能算法为行为评判算法actor-critic时,训练时至少需要两个神经网络,所述两个神经网络的输入为:所述网络状态参数;一个神经网络的输出为:在网络状态S下,当前各小区所有参数(各小区的负载均衡参数、切换参数和重选参数等)调整后的结果;另一个神经网络的输出为:在网络状态S下执行参数调整动作后的价值。本发明实施例中,所述处理模块201对人工智能算法的输入的调整方法包括但不限于以下几种:当出现小区间用户数差异较大时,优先调整评估周期大小、用户数触发门限、以及单个周期内选取的最大用户数门限;当出现小区间PRB利用率差异较大时,优先调整评估周期大小、PRB利用率触发门限、选取用户的PRB占比门限、以及单个周期内选取的最大用户数门限;在对本小区负载均衡的A4门限、邻区覆盖的A2、A5门限自动调整时,保持本小区A4门限不小于邻区A5第一门限的原则、或者保持本小区A4不小于邻区A2门限的原则;其中,所述A2、A4和A5门限为小区级门限或用户级门限。这里,所述A2、A4和A5门限为切换流程中A2、A4、A5事件对应的门限。本发明一个实施例中,所述处理模块201,还用于在小区间交互如下信息至少之一:网络的KPI信息;小区重选参数配置信息;小区级和/或用户级切换参数配置信息;负载均衡参数配置信息;实时的负载信息。本发明实施例中,所述信息的交互为:周期性交互、或为事件触发交互。本发明实施例中,所述信息的交互通过如下一种或多种方式实现:在小区间通过基站内部的接口交互;在小区间通过网管交互;在小区间通过Xn和/或X2和/或S1和/或NG接口交互。本发明一个实施例中,所述处理模块201在小区间通过Xn和/或X2和/或S1和/或NG接口交互时,包括:在Xn和/或X2和/或S1和/或NG交互流程中增设网络KPI信息、参数配置信息、实时负载信息的交互;或者,增设新的Xn和/或X2和/或S1和/或NG交互流程。本发明一个实施例中,处理模块201还用于基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。本发明实施例还提供了一种负载均衡优化装置,该装置应用于网络设备,包括:调整配置模块,用于基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。本发明实施例还提供了一种负载均衡优化装置,该装置包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,其中,所述处理器用于运行所述计算机程序时,执行:基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈。其中,所述网络状态参数包括但不限于以下一种或多种:小区负荷以及小区间的负荷差;网络的关键性能指标KPI;当前各小区的参数配置值。其中,所述参数配置值包括但不限于以下一种或多种:负载均衡参数配置值;切换参数配置值;重选参数配置值。所述基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈之前,所述处理器还用于运行所述计算机程序时,执行:判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化;基于预配置的重选优先级参数配置,对当前重选优先级参数进行核查并完成自动修改。所述判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化之前,所述处理器还用于运行所述计算机程序时,执行:基于基站工参中的基站形态和/或通道数,对不同小区的负载均衡触发门限进行差异化配置和调整;其中,所述负载均衡触发门限包括但不限于:物理资源块PRB利用率门限、用户数门限。其中,所述强化学习的人工智能算法包括但不限于:策略梯度policygradient算法、行为评判算法actor-critic。其中,所述强化学习的人工智能算法为行为评判算法actor-critic时,训练时至少需要两个神经网络,所述两个神经网络的输入为:所述网络状态参数;一个神经网络的输出为:在网络状态S下,当前各小区所有参数调整后的结果;另一个神经网络的输出为:在网络状态S下执行参数调整动作后的价值。调整所述人工智能算法的输入时,所述处理器还用于运行所述计算机程序时,执行但不限于以下几种方法:当出现小区间用户数差异较大时,优先调整评估周期大小、用户数触发门限、以及单个周期内选取的最大用户数门限;当出现小区间PRB利用率差异较大时,优先调整评估周期大小、PRB利用率触发门限、选取用户的PRB占比门限、以及单个周期内选取的最大用户数门限;在对本小区负载均衡的A4门限、邻区覆盖的A2、A5门限自动调整时,保持本小区A4门限不小于邻区A5第一门限的原则、或者保持本小区A4不小于邻区A2门限的原则;其中,所述A2、A4和A5门限为小区级门限或用户级门限。所述处理器还用于运行所述计算机程序时,执行:在小区间交互如下信息至少之一:网络的KPI信息;小区重选参数配置信息;小区级和/或用户级切换参数配置信息;负载均衡参数配置信息;实时的负载信息。其中,所述信息的交互为:周期性交互、或为事件触发交互。所述交互信息时,所述处理器还用于运行所述计算机程序时,执行如下一种或多种方式:在小区间通过基站内部的接口交互;在小区间通过网管交互;在小区间通过Xn和/或X2和/或S1和/或NG接口交互。所述在小区间通过Xn和/或X2和/或S1和/或NG接口交互时,所述处理器还用于运行所述计算机程序时,执行:在Xn和/或X2和/或S1和/或NG交互流程中增设网络KPI信息、参数配置信息、实时负载信息的交互;或者,增设新的Xn和/或X2和/或S1和/或NG交互流程。所述处理器还用于运行所述计算机程序时,执行:基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。本发明实施例还提供了一种负载均衡优化装置,该装置包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器,其中,所述处理器用于运行所述计算机程序时,执行:基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。需要说明的是:上述实施例提供的装置在进行负载均衡优化时,仅以上述各程序模块的划分进行举例说明,实际应用中,可以根据需要而将上述处理分配由不同的程序模块完成,即将设备的内部结构划分成不同的程序模块,以完成以上描述的全部或者部分处理。另外,上述实施例提供的装置与相应方法实施例属于同一构思,其具体实现过程详见方法实施例,这里不再赘述。在示例性实施例中,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质可以是FRAM、ROM、PROM、EPROM、EEPROM、FlashMemory、磁表面存储器、光盘、或CD-ROM等存储器;也可以是包括上述存储器之一或任意组合的各种设备,如移动电话、计算机、平板设备、个人数字助理等。本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时,执行:基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈。其中,所述网络状态参数包括但不限于以下一种或多种:小区负荷以及小区间的负荷差;网络的关键性能指标KPI;当前各小区的参数配置值。其中,所述参数配置值包括但不限于以下一种或多种:负载均衡参数配置值;切换参数配置值;重选参数配置值。所述基于网络状态参数并根据强化学习的人工智能算法,获得当前各小区所有参数调整后的值以及将调整后的参数作用于网络中对网络所产生影响的评价或反馈之前,所述计算机程序被处理器运行时,还执行:判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化;基于预配置的重选优先级参数配置,对当前重选优先级参数进行核查并完成自动修改。所述判断网络负荷在预设时间内无法通过LB和MLB实现均衡、或判断网络KPI发生恶化之前,所述计算机程序被处理器运行时,还执行:基于基站工参中的基站形态和/或通道数,对不同小区的负载均衡触发门限进行差异化配置和调整;其中,所述负载均衡触发门限包括但不限于:物理资源块PRB利用率门限、用户数门限。其中,所述强化学习的人工智能算法包括但不限于:策略梯度policygradient算法、行为评判算法actor-critic。其中,所述强化学习的人工智能算法为行为评判算法actor-critic时,训练时至少需要两个神经网络,所述两个神经网络的输入为:所述网络状态参数;一个神经网络的输出为:在网络状态S下,当前各小区所有参数调整后的结果;另一个神经网络的输出为:在网络状态S下执行参数调整动作后的价值。调整所述人工智能算法的输入时,所述计算机程序被处理器运行时,还执行但不限于以下几种方法:当出现小区间用户数差异较大时,优先调整评估周期大小、用户数触发门限、以及单个周期内选取的最大用户数门限;当出现小区间PRB利用率差异较大时,优先调整评估周期大小、PRB利用率触发门限、选取用户的PRB占比门限、以及单个周期内选取的最大用户数门限;在对本小区负载均衡的A4门限、邻区覆盖的A2、A5门限自动调整时,保持本小区A4门限不小于邻区A5第一门限的原则、或者保持本小区A4不小于邻区A2门限的原则;其中,所述A2、A4和A5门限为小区级门限或用户级门限。所述计算机程序被处理器运行时,还执行:在小区间交互如下信息至少之一:网络的KPI信息;小区重选参数配置信息;小区级和/或用户级切换参数配置信息;负载均衡参数配置信息;实时的负载信息。其中,所述信息的交互为:周期性交互、或为事件触发交互。所述交互信息时,所述计算机程序被处理器运行时,还执行如下一种或多种方式:在小区间通过基站内部的接口交互;在小区间通过网管交互;在小区间通过Xn和/或X2和/或S1和/或NG接口交互。所述在小区间通过Xn和/或X2和/或S1和/或NG接口交互时,所述计算机程序被处理器运行时,还执行:在Xn和/或X2和/或S1和/或NG交互流程中增设网络KPI信息、参数配置信息、实时负载信息的交互;或者,增设新的Xn和/或X2和/或S1和/或NG交互流程。所述计算机程序被处理器运行时,还执行:基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时,执行:基于终端能力调整不同能力终端的负载均衡优先级;或者,支持配置不同能力终端的负载均衡优先级。下面结合场景实施例对本发明进行描述。本实施例针对影响负载均衡效果的参数进行自动优化,整体流程如图3所示,包括:步骤301:根据基站工参对参数进行差异化配置;这里,由于不同基站站型的空间复用能力不同(普通宏站空分复用能力差于MIMO站)、通道数不同等,不同小区所能承载的最大连接态用户数比率和最大PRB利用率(用户感知相当)不同。当前,所有参数配置中采用统一配置的方式,未根据基站工参进行差异化配置。基于上述原因,网管或其他自动化平台可根据基站工参中的基站形态、通道数等,自动对不同小区的负载均衡参数(如负载均衡的PRB利用率触发门限、用户数触发门限)进行差异化配置和调整。如下实施例所示,在未考虑基站工参的情况下,不同站型、通道数配置的参数相同,如PRB利用率触发门限均为N%,用户数触发门限均为M%,若差异化配置负载均衡触发门限可以如下表1所示:站型通道数PRB利用率门限(需配置)用户数门限(需配置)普通宏站8通道N%M%普通宏站8通道N%M%MIMO站64通道2N%或N 30%2M%或M 30%MIMO站32通道2N%或N 20%2M%或M 20%表1需要说明的是,PRB利用率=实际占用的PRB个数/总的可用PRB个数*100%,用户数=小区当前连接态用户数/小区允许的最大连接态用户数*100%。步骤302:基站或网管或其他自动化平台核查重选优先级是否正确,如果是,则执行步骤303;否则,执行步骤304,对重选优先级进行调整;这里,基站或网管或其他自动化平台保存正确的重选优先级参数配置,当网络负荷在一段时间内无法通过传统的LB和MLB方案实现均衡,或网络KPI发生恶化(如切换成功率低于某一门限值)时,基站或网管或其他自动化平台对重选优先级参数进行核查并完成自动修改。步骤303:当网络负荷还无法实现均衡,或网络KPI未达到目标(如切换成功率低于优化目标门限)时,执行参数的自动优化。这里,由于影响负载均衡效果的参数较多(除重选优先级之外,由于重选优先级较固定,且调整该参数对网络影响较大,因此自动参数优化不包含此参数),且在不同网络负荷、不同时间、不同小区对情况下的参数各不相同,且调整某些参数对网络的影响较广,如调整CIO参数,既影响负载均衡效果,又影响切换的KPI指标,因此,采用强化学习的人工智能方式,让基站具有自动调整和优化参数的能力,降低网络优化的工作量和难度。其中,强化学习的架构如图4所示。其中,强化学习的网络中包含三个元素:1)输入:网络状态;网络状态包括但不限于:小区的负荷及负荷差、网络的KPI(如切换成功率、过早切换次数、过晚切换次数、乒乓切换次数(切换相关KPI包含同频异频、站内和站间、以及系统内和系统间等)、无线/E-RAB掉话率/接通率、RRC/E-RAB连接建立成功率等)、当前各小区参数配置值,其中参数包括不限于以下表2中所列:表22)输出:将输入值输入到神经网络中,得到参数调整行为,即所有参数(各小区的参数)调整后的值;3)输出(反馈):参数调整后作用在网络中,对网络产生的影响的评价或反馈。上述强化学习的架构的组成中,可包含一到多个神经网络:方案一:强化学习网络采用策略梯度(PolicyGradient)进行训练,需包含至少一个神经网络,神经网络的输入和输出如图5所示:神经网络πθ(s)的初始值可通过随机方式产生,也可通过随机方式加人工经验方式产生(为了避免对参数的调整范围过大严重影响网络KPI指标,可限制每个参数可调整的范围),然后与环境互动收集样本,根据样本更新πθ。其中反馈函数表达式为:该表达式的含义为期望收益,即采取某一个行动状态序列τ的概率(即:Pθ(τ)),以及该行动状态序列对应的收益reward(即:R(τ))的乘积之和(因为在某一个状态St下采取某个行为at后获取到的下一状态st 1随机(受网络中业务变化、用户移动等影响),得到的reward值随机,因此需获取期望值)。其中τ=(st,at,st 1)为行动action和状态state的序列,此序列对应的概率为:Pθ(τ)=P(st)P(at|st)P(st 1|st,at);此状态序列下对应的反馈为:其中,ri为KPI的变化情况;r1=小区间负荷差降低值r2=切换成功率提升值r3=过早切换次数降低值r4=过晚切换次数降低值r5=乒乓切换次数降低值等,wi为每个ri对应的权值,根据现网优化的经验值确定。此方法训练的目标是将最大化,可通过采用梯度上升方法求取其最大值,上述训练可以为单步更新,即每得到一个r都会对神经网络参数进行更新,也可采用多步更新,即得到N个r后对神经网络参数进行更新,防止过拟合发生。方案二:强化学习网络采用行为评判算法actor-critic进行训练,需包含至少2个神经网络,神经网络的输入和输出如图6所示。神经网络1用于训练行为策略,神经网络2用于训练价值函数,其训练的流程如图7所示:步骤一:πθ初始值可通过随机方式产生,也可通过随机方式加人工经验方式产生,与环境互动后产生一些样本;步骤二:结合样本,通过采用蒙特卡洛或时间差分法对Vπ(S)进行训练;步骤三:基于训练更新后的Vπ(S),对采用梯度上升方法对πθ进行更新,由于增加了Vπ(S)的训练过程,因此,上述的R(τ)更新为如下公式:R(τ)=rt Vπ(st 1)-Vπ(St)本实施例中,进行上述人工智能算法的模块可置于基站内部,也可置于基站外部(如网管或新增的智能网元等),控制多个基站完成参数优化过程。基于强化学习的自动参数优化过程,需要提前输入一些参数进行调整,避免参数迭代时间过长以及进入参数调整的恶性循环中。输入的原则包括但不限于以下几种:1、当出现小区间用户数差异较大时,优先调整评估周期大小、用户数触发门限、单个周期内选取的最大用户数门限,调整的趋势如下表3所示;2、当出现小区间PRB利用率差异较大时,优先调整评估周期大小、PRB利用率触发门限、选取用户的PRB占比门限、单个周期内选取的最大用户数门限,调整的趋势如下表3所示;表33、为了避免用户发生基于负载均衡和基于覆盖间的乒乓切换,在对本小区负载均衡的A4门限、邻区覆盖的A2、A5门限自动调整时,保持本小区A4门限不小于邻区A5第一门限的原则或者保持本小区A4不小于邻区A2门限的原则,此时的A2、A4和A5门限可以是小区级门限,也可以是用户级门限。其中,参数优化过程中,小区间需增设交互如下信息至少之一:网络的KPI信息、小区重选/切换参数、负载均衡参数配置信息,以及实时的负载信息。其中,上述信息的交互可以是周期性交互,也可以是事件触发交互:对于周期性交互:可以以一定周期(可配)交互;对于事件触发交互,可为如下一种或多种方式:当网络的KPI出现恶化,可触发交互网络的KPI信息,其他信息可选交互;当小区重选/切换参数、负载均衡参数配置信息出现变化,可触发交互参数配置信息,其他信息可选交互;当小区负载变化高于一定门限(如PRB利用率变化5%),触发交互实时的负载信息,其他信息可选交互。上述交互可通过以下三种方式实现:小区间通过基站内部的接口交互,此方案适用于小区处于同一设备中(如同站的三个扇区间)或同一机房,是厂家私有实现;小区间通过网管交互,此方案适用于小区和网管为同一设备厂家,网管和基站间的交互接口是厂家私有实现;小区间通过Xn/X2/S1/NG等标准化接口交互,此方案适用于小区为异厂家设备小区,此时需要现有标准的Xn/X2/S1/NG交互流程中新增相关信息的交互,或在现有标准中增加新的Xn/X2/S1/NG交互流程。上述强化学习的算法可首先应用在模拟平台上,获取到不同小区负载、不同移动性参数配置下的最优负载均衡参数配置值,再将获取到的最优参数配置值和负载的组合应用到现网中,继续不断自我优化。完成影响负载均衡效果的参数优化后,在执行负载均衡时,网络可根据终端能力调整不同能力终端的负载均衡优先级,或支持配置不同能力终端的负载均衡优先级,如NSA终端的优先级较低。NSA终端被负载均衡的概率或均衡到不支持NSA的小区的概率变低,以至于降低对用户体验的影响。可见,本发明实施例基于基站工参差异化配置参数,可实现对负载均衡参数自动的差异化配置,使得不同基站配置的参数合理,从而保障均衡用户切换前后的业务体验。而且,本发明实施例通过采用强化学习的人工智能算法,可实现对二十多个参数的自动优化,加快网络负载的均衡,改善网络的KPI。此外,通过上述优化方案,实现了网络的自动优化,大大减少了人工调整参数的工作量。同时,支持为不同能力终端配置或调整其负载均衡优先级,降低某些能力等级终端被负载均衡的概率,以降低对用户体验的影响。以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。当前第1页12
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。