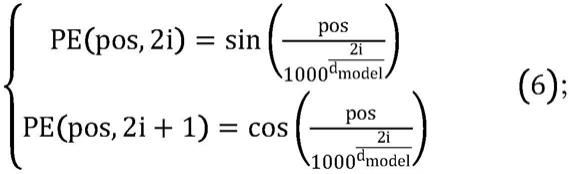
1.本发明涉及交通技术领域,更具体的说是涉及一种针对非均匀轨迹序列的预测方法。
背景技术:
2.相比于其他领域,飞机轨迹预测有两大难点。一、飞机轨迹数据的时间间隔不均匀。飞机轨迹数据通常以秒为单位,由于数据来源并非单一、传感器工作实效、数据特征信息缺失较为严重的原因,飞机轨迹数据中相邻轨迹点之间的时间间隔通常是不一致的,而时间对位置信息有着严重的影响,因此如何处理时间及准确提取时间信息是一个难点;二、需要预测精确时间的飞机轨迹。飞机轨迹预测有着更为精确的预测要求,由于飞机速度较快,即使较短的时间飞机位置也有较大的变化,因此飞机轨迹预测需要精确到秒,而且能够预测指定某一刻时间的飞机位置,这无疑增加了飞机轨迹预测的难度。
3.轨迹预测经历了从手工制作的基于能量的线性优化方法到数据驱动的优化方法的稳步发展,普遍采用两种预测方法,第一种预测是采用基于多元线性回归的轨迹预测,例如卡尔曼滤波器、线性或高斯回归模型、时间序列分析和自回归模型,优化手工制作的能量函数,实现对飞机轨迹的预测判别;第二种预测是采用基于神经网络的轨迹预测,神经网络由于其更好的学习非线性能力,在轨迹预测任务上取得了更好的效果。回归模型主要是采用lstm和rnn模型,并使用大量数据进行训练。
4.但是,上述方法存在以下缺点:基于多元线性回归的轨迹预测方法,其核心是利用回归模型优化手工制作的能量函数,以实现对轨迹的预测,然而,飞机的运动轨迹千变万化,线性模型很难适用于复杂的非线性运动轨迹;非线性回归模型典型代表是lstm,该模型可用于直接对预测值进行回归,或在x、y坐标上产生均值和(对角线)协方差,以表达与预测相关的不确定性,此模型称为高斯lstm。lstm在开始自动回归预测之前顺序处理观察结果,却无法查看所有可用观察结果,并根据注意力机制对它们进行加权。
5.因此,如何解决飞机轨迹数据时间间隔不均匀问题,提高预测精度是本领域技术人员亟需解决的问题。
技术实现要素:
6.有鉴于此,本发明提供了一种针对非均匀轨迹序列的预测方法,利用用于自然语言处理的transformer(tf)网络来对轨迹序列进行建模,针对飞机轨迹数据时间间隔不均匀和需要预测精确时间的轨迹两大难点,本发明对网络结构进行了改进,设计了时空嵌入模块和预测精确时间轨迹,提出了非均匀轨迹序列预测方法。实现飞机的精确时间轨迹预测,充分挖掘其深层特征和知识,从而对飞机轨迹进行准确的预测,在民航领域的冲突检测、路线规划可以发挥巨大的作用。
7.为了实现上述目的,本发明采用如下技术方案:
8.一种针对非均匀轨迹序列的预测方法,包括以下步骤:
9.步骤1:采集飞机轨迹点数据,并进行预处理,获得各类飞机的飞机轨迹数据;
10.步骤2:采用滑动窗口对所述飞机轨迹数据进行采样,获得采样数据,并对采样数据进行特征提取,获得预测模型输入数据;
11.步骤3:所述预测模型输入数据和待预测时间输入tf架构模型,依次经过时空嵌入模块、编码器和解码器输出轨迹预测结果。
12.优选的,所述步骤1中预处理过程包括:
13.步骤11:对采集的所述飞机轨迹点数据进行要素分析,建立表结构,采用es分布式数据库进行数据存储,获得冷库;
14.步骤12:从所述冷库中按照type字段进行飞机类型区分,抽取各种类型目标飞机的飞机轨迹点数据,每种类型的飞机轨迹点数据构建表格并存入mysql数据库,获得热库;由于原始数据中存在type字段信息缺失导致该轨迹点通过type字段不能抽取到,故根据已得到的数据中的飞机其他特征信息在冷库中反向抽取、确认,补全每种类型飞机缺失的轨迹点;飞机其他特征信息包括精度、维度和呼号等;
15.步骤13:对所述热库中每种类型的所述飞机轨迹点数据进行过滤处理,并采用设定规则进行每种类型的飞机轨迹数据生成,获得按照时间顺序组合轨迹点的飞机轨迹数据。
16.优选的,所述设定规则为通过呼号和type字段唯一确定飞机轨迹点,将飞机轨迹点数据按时间排序,如果两个轨迹点时间间隔大于两小时,那么切分为不同的轨迹。
17.优选的,所述步骤2中滑动窗口大小为36,步长为2;对所述采样数据进行直接特征提取和间接特征提取,获得轨迹特征,将所述轨迹特征分为观测序列和真实待预测序列;所述观测序列作为预测模型输入数据;所述轨迹特征包括飞机编号、时间、经纬度、高度、速度、加速度、航向、均值和方差。
18.优选的,所述步骤3中输入所述预测模型输入数据和待预测时间td,依次通过时空嵌入模块编码器encoder、解码器decoder后得到轨迹预测结果p'
red
,所述tf架构模型如公式(1)所示:
[0019][0020]
其中,o
bd
为观测序列;td为待预测时间;为时空嵌入模块;encoder为编码器;decoder为解码器;p'
red
为所述轨迹预测结果;输入所述待预测时间进行预测时间嵌入,将所述待预测时间处理成时间间隔后进行embedding,待预测时间是用户指定的需要预测的时间点,如果用户不指定,则默认为一个小时内每隔五分钟预测一次;
[0021]
其中时空嵌入模块如公式(2)所示,输出时空嵌入结果i
np
:
[0022][0023]
编码器输入为时空嵌入结果i
np
,le表示编码器的层数,we为编码器网络权重参数,δe为编码器激活函数,biase为编码器偏差参数,编码器输出结果为注意力信息attn,如公式(3)所示:
[0024]
attn=encoder(i
np
;le,we,δe,biase)
ꢀꢀꢀ
(3);
[0025]
解码器输入为注意力信息attn,ld表示解码器模块的层数,wd为解码器网络权重参
数,δd为解码器激活函数,biasd为解码器偏差参数,解码器输出结果为所述轨迹预测结果p'
red
,如公式(4)所示:
[0026]
p’red
=decoder(attn;ld,wd,δd,biasd)
ꢀꢀꢀ
(4)。
[0027]
优选的,所述步骤3中所述tf架构模型采用目标函数进行模型优化,所述目标函数公式如公式(5)所示:
[0028][0029]
通过反向传播最小化真实待预测序列yk和轨迹预测结果的方差来寻找tf架构模型最优网络权值参数w=(wi,we,wd)和网络偏重参数bias=(biasi,biase,biasd)从而使得模型能够准确地预测飞机一定时间范围内的位置序列。
[0030]
优选的,所述时空嵌入模块对所述预测模型输入数据从时间特征、其他特征和位置特征三方面进行特征嵌入,输出的输出特征维度均为512,将三个方面的输出特征进行融合得到输出数据;
[0031]
对时间特征进行特征嵌入时,将其他轨迹点时间特征值减去第一个轨迹点时间特征值得到整条轨迹的时间间隔,设定第一个轨迹点时间特征值为0,然后对此时间间隔建立字典,采用onehot的方式进行多维嵌入,维度为512维;
[0032]
所述其他特征为所述预测模型输入数据中除去时间的其他轨迹信息,采用全链接网络进行维度变换,使得输出纬度为512维,全链接网络中的权重参数和偏差信息在训练中不断更新,即在所述tf架构模型中的网络权值参数和网络偏重参数优化中不断更新;
[0033]
所述位置特征进行特征嵌入生成输入轨迹每一个轨迹点位置和每一个轨迹点具体维度信息,通过正弦余弦函数进行位置特征嵌入生成一张序列长度x特征维度的位置空间图,所述正弦余弦函数进行位置特征嵌入的公式如公式(6)所示:
[0034][0035]
其中,pos表示轨迹点具体位置;2i和2i 1分别表示轨迹点嵌入后在偶数列和奇数列的维度,分别采用sin函数和cos函数进行映射;d
model
为模型嵌入的维度,即512;1000表示轨迹序列的最大长度。
[0036]
优选的,所述编码器有6层结构完全相同、参数不同的编码层,编码层由4个模块构成,分别由1个多头自注意力模块、2个残差及层归一化和1个前馈网络依次串接而成,每一个编码层的输入特征维度和输出特征维度完全相同,从而保证了编码层可以多个串接;
[0037]
所述多头自注意力模块输入端为三个线性层,依次经过缩放点积注意力层和合并层,在输出端的线性层输出,输入端的三个线性层分别输入查询向量q、键向量k和值向量v,分别为所述时空嵌入结果乘以矩阵wq、wk、wv得到,其中wq、wk、wv是不同的权值矩阵,实现对轨迹特征矩阵进行不同的线性变换,将其映射到不同子空间;
[0038]
缩放点积注意力层主要为自注意力操作,为一个查询(q)到一系列(k-v)对的映
射;自注意力操作包括以下步骤:
[0039]
步骤31:将查询向量q和每个键向量k进行相似度计算,采用点积的方式得到权重;
[0040]
步骤32:使用softmax函数对权重进行归一化;
[0041]
步骤33:将权重和相应的值向量v进行加权求和得到最后的自注意力向量,自注意力运算的公式如下:
[0042][0043]
其中dk为向量q的维度,以进行缩放起到分散注意力的作用,使得模型有更好的泛化能力;k为键向量k,k
t
为键向量k的转置,使其能够进行矩阵乘法;
[0044]
卷积注意力机制具有多头结构,是因为几个注意力层以相同输入进行不同线性变换并进行堆叠,而这种堆叠有助于模型捕获输入的各个维度信息,提高模型特征提取能力;图6中a表示注意力头的数量,a取值为8;合并层便是对多个注意力头的结果进行合并,公式如(8)、(9)所示:
[0045]
multihead(q,k,v)=concat(head1,
…
,headh)woꢀꢀꢀ
(8);
[0046][0047]
其中,multihead函数为拆分层,将数据输入分为八份独立计算,一共有8个头,每个头各负责一个head;wo为对数据的变换参数;wq、wk、wv分别为查询向量q、键向量k和值向量v的变换参数;
[0048]
concat函数为图6中合并层,将每个注意力头的生成结果合并;线性层对合并结果再进行一次空间映射,输出注意力信息,其输出为多头自注意力模块输出结果。
[0049]
优选的,前馈网络用于逼近任意映射函数,包含线性变换和激活函数;在前馈神经网络中,通过线性变换对输入向量的维度d
model
进行扩维,采用了4*d
model
的维度;激活函数采用bert模型的gelu激活函数,公式如(10)所示:
[0050][0051]
其中,x为输入,是模型中流转的数据;
[0052]
优选的,残差及层归一化在多头自注意力模块和前馈网络之间均进行了残差和层归一化操作;残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率,其内部的残差块使用了跳跃链接,缓解了在深度神经网络中增加深度带来了梯度消失的问题和传统的神经网络在信息传递的时候,或多或少会存在信息丢失,损耗等问题,残差网络使得层数很高的模型训练变得可行;层归一化是在特征维度这一维度进行归一化,可以将特征转为正态分布,将数据重新拉到激活函数的不饱和区间,有减缓梯度消失、增加模型精度和加快训练速度的作用;
[0053]
残差及层归一化公式如公式(11)所示:
[0054]
sub_layer_output=layernorm(x sublayer(x))
ꢀꢀꢀ
(11)
[0055]
其中x为输入,sublayer为残差操作,layernorm为层归一化操作。
[0056]
优选的,解码器有6层结构完全相同、参数不同的解码层;6个解码层串接而成,前一层的输出为下一层的输入,解码层由1个多头自注意力模块、1个多头注意力模块、1个前馈网络层和三个残差及层归一化层构成,数据每通过一次注意力模块或者前馈网络层,都会进行残差及层归一化;所述多头自注意力模块输入待预测时间经过三个不同线性层的线性变换分别得到的输入的查询向量q、键向量k和值向量v;所述多头注意力模块输入所述编码器输出的注意力信息和经过所述多头自注意力模块和一个残差及层归一化层处理过的待预测时间信息;解码器拥有两个输入,分别是编码器输出的注意力信息和待预测时间的高维嵌入,注意力信息attn是连接编码器和解码器之间的桥梁;每一个解码层的输入特征维度和输出特征维度完全相同,保证了多个解码层可以串接。编码层和解码层之间的区别在于两个注意力模块,其余部分与编码层完全相同。
[0057]
优选的,解码层的多头自注意力模块保证在预测每一个轨迹点时,只有当前位置及以前位置能够被看到,其为一个倒三角矩阵,长度和宽度均为所述预测模型输入数据的长度,即为观测序列的长度。采用了mask机制来保证在预测每一个轨迹点时,只有当前位置及以前能够被看到,每一个轨迹点及之前的均不遮挡,该轨迹点后面是遮挡的,从而保证了模型看到当前位置后续输入。
[0058]
优选的,解码层的多头注意力公式如公式(12)所示,其中qd是解码层的查询特征;ke和ve均为编码器输出的注意力信息attn的线性变化数据;dk为嵌入维度512;attention为预测轨迹点位置;在这个模块中解码层利用了编码器输出的注意力信息,其实也就是存储的观测序列o
bd
的特征和规律,从而使得解码层能够充分利用已经观测到的轨迹信息,预测出精确的下一个轨迹点位置;
[0059][0060]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种针对非均匀轨迹序列的预测算法,基于神经网络transformer(tf)网络对轨迹进行建模,充分挖掘非均匀轨迹序列数据中各维度特征信息和飞机轨迹的复杂运动模式,并针对飞机轨迹数据时间间隔不均匀和需要预测精准时间的轨迹两大难点,对网络模型进行改进,在模型中加入时空嵌入模块和改变解码器的输入,实现对飞机的精确时间轨迹预测。其中,针对飞机轨迹数据时间间隔不均匀的问题,为了能更好地表示输入轨迹,提取到充足的特征信息采用时空嵌入模块进行输入轨迹的表示学习,时空嵌入模块由三部分构成:一、时间特征生成,处理时间特征生成时间间隔,然后以第一个轨迹点为基准,生成精确的时间间隔特征表示;二、轨迹特征生成,对于经度、纬度、高度、加速度、均值、方差等轨迹信息,使用全链接网络进行线性映射,生成高维轨迹特征;三、位置特征生成,根据轨迹序列长度和位置进行位置嵌入,对每一个位置的每一个嵌入维度都生成独一无二的数据纹理加以区分。最后将这三部分特征加以融合作为时空嵌入模块的输出。现有的tf网络结构通常是顺序输出预测的序列,第一个位置由初始符和编码层生成的特征矩阵通过解码器得到,之后每一个位置是都将之前模型生成的所有序列和编码层的特征矩阵经过解码器进行预测,这种预测方式只有轨迹点的先后次序,并没有需要预测的精确时间信息,本发明对tf网络中解码器的输入进行改变,除了编码器生成的特征矩阵,还对需要预测的精确时间进行时间嵌入作为额外输入,编码器通过特征矩阵和精确时间信息预测某一个特定时刻的飞机位置。
附图说明
[0061]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0062]
图1附图为本发明提供的轨迹数据预处理流程示意图;
[0063]
图2附图为本发明提供的生成的轨迹样例示意图;
[0064]
图3附图为本发明提供的滑动窗口采样及特征提取示意图;
[0065]
图4附图为本发明提供的tf架构模型结构示意图;
[0066]
图5附图为本发明提供的时空嵌入模块结构示意图;
[0067]
图6附图为本发明提供的编码层结构示意图;
[0068]
图7附图为本发明提供的解码层结构示意图;
[0069]
图8附图为本发明提供的解码层mask机制示意图。
具体实施方式
[0070]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0071]
本发明实施例公开了一种针对非均匀轨迹序列的预测方法。
[0072]
s1:数据预处理;
[0073]
飞机轨迹点数据是按时间排列所有飞机轨迹点数据的混合,存在数据量大、部分数据信息缺失的问题,采用了一系列数据预处理流程来生成各类飞机的轨迹,轨迹数据预处理流程如图1所示;
[0074]
预处理步骤如下:
[0075]
(1)对得到的数据要素进行分析,建立相应的表结构,由于数据量为十亿级及以上,为了保证查询效率,故采用es分布式数据库进行数据的存储,该数据库使用频率较少,称为冷库;
[0076]
(2)从冷库中按照type字段进行飞机类型的区分,抽取各种目标飞机的轨迹点数据,每种类型一张表存入mysql数据库,由于原始数据中存在type字段信息缺失导致该轨迹点通过type字段不能抽取到,故根据已得到的数据中的飞机其他特征信息在冷库中反向抽取、确认,补全每种类型飞机缺失的轨迹点,该数据库使用频率较高,称其为热库;
[0077]
(3)我们对热库中的每种类型飞机的轨迹数据进行筛选、去重、清洗等操作,提升数据质量,减少噪音的影响,在此基础上我们使用特定的设定规则进行每种类型飞机轨迹数据的生成,飞机轨迹的可视化展现如图2所示,每隔5分钟左右一个轨迹点,轨迹点按照时间顺序组合得到飞机的轨迹;设定规则为:首先将轨迹数据的所有轨迹点按照飞机类别进行分类,每个类别的轨迹点再根据飞机具体航班号进行分类,得到了每个类别具体每一架飞机的轨迹点;然后对每一架飞机的轨迹点按照时间进行排序,再按照两小时间隔对排好序的序列进行切分,得到了所有飞机的每条轨迹;
[0078]
s2:特征提取;
[0079]
出于数据增强、神经网络批训练对齐的考虑,采用滑动窗口的方式对飞机轨迹进行采样,滑动窗口大小为36,步长为2,滑动窗口示意如图3所示;采样的36个轨迹点中,前24个轨迹点作为训练的基础,我们称为观测序列o
bd
,后12个轨迹点为真实的需要预测的轨迹,我们称为真实待预测序列y;
[0080]
对于采样的结果,需要进行特征的提取作为模型的输入,提取飞机编号、时间、经纬度、高度、速度、加速度、航向、均值、方差等特征,其中部分特征直接可以从轨迹数据中得到,剩余特征需要进行生成,对每条轨迹进行特征提取后,将其作为预测模型的输入;
[0081]
s3:构建模型,预测轨迹;
[0082]
整个轨迹预测模型的整体结构如图4所示,其中左边部分为encoder编码器,右侧部分为decoder解码器。输入轨迹为o
bd
,其通过时空嵌入模块后作为编码层的输入;编码器一共有6层编码层,每一层结构详图,每一层的输出作为下一层的输入,最后一层的注意力矩阵为o
bd
在编码层生成的信息深度提取结果,我们称为注意力信息attn;解码器一共有两个输入,一个是attn,另一个为需要预测的时间进行时间嵌入的结果,解码器一共6层解码层,每层结构完全相同,层之间上一层输出作为下一层的输入,最后一层的输出结果为预测轨迹序列p
red
';
[0083]
整个模型的表示如公式(1)所示,tf是指模型采用transforemer架构,输入分别是观测序列o
bd
和待预测时间td,依次通过时空嵌入模块编码器encoder、解码器decoder后得到轨迹预测结果p'
red
;
[0084]
时空嵌入模块如公式(2)所示,输入为观测序列o
bd
,wi为该模块的权值参数,biasi为该模块的偏差参数,经过时空模块后输出结果i
np
作为编码器输入;
[0085]
编码层模块如公式(3)所示,输入为时空嵌入结果i
np
,le表示编码器的层数,we为编码器网络权重参数,δe为编码器激活函数,biase为编码器偏差参数,编码器输出结果为注意力信息attn;
[0086]
解码器如公式(4)所示,输入为注意力信息attn,ld表示解码器模块的层数,wd为解码器网络权重参数,δd为解码器激活函数,biasd为解码器偏差参数,解码器输出结果为注意力信息p'
red
;
[0087][0088][0089]
attn=encoder(i
np
;le,we,δe,biase)
ꢀꢀꢀ
(3)
[0090]
p
′
red
=decoder(attn;ld,wd,δd,biasd)
ꢀꢀꢀ
(4)
[0091]
神经网络理论上能够很好地无限逼近任意连续映射,对于此回归任务,可以通过训练神经网络得到一个满足要求的映射函数;目标函数如公式(5)所示,通过反向传播最小化真实值yk和预测值的方差来寻找tf模型最合适的网络权值参数w=(wi,we,wd)和网络偏重参数bias=(biasi,biase,biasd)从而使得模型能够准确地预测飞机一定时间范围内的位置序列;
[0092][0093]
s31:时空嵌入模块;
[0094]
由于轨迹数据具有部分特征值缺失、轨迹点之间时间间隔不均匀的问题,为了能更好地表示输入轨迹,提取到充足的特征信息,设计了时空嵌入模块进行输入轨迹的表示学习,如图5所示。该模块对预测模型输入数据(即观测序列)从时间、其他特征、位置三个方面独立进行了特征嵌入,输出的特征维度均为512,然后将这三部分特征进行融合得到输出;
[0095]
时间特征:
[0096]
由于轨迹数据的时间特征值为时间戳,时间戳的值基于一个非常大基数,该基数对轨迹预测并无实际作用反而增大了噪音干扰,因此将其他轨迹点时间特征值减去第一个轨迹点时间特征值得到整条轨迹的时间间隔,第一个轨迹点时间特征值为0,然后对此时间间隔建立字典,采用onehot的方式进行多维嵌入,维度为512维,图5中展示的是数据嵌入后通过pca降维到3维的展示效果;
[0097]
其他特征:
[0098]
其他特征为预测模型输入数据中除去时间的其他轨迹信息,例如经度、纬度、高度、速度、航向、加速度、均值、方差等,由于这些特征值均为浮点数,直接采用全链接网络进行维度变换,使得输出维度为512,该网络的权重参数和偏差信息可以在训练中不断更新;
[0099]
位置:
[0100]
使用位置嵌入来生成输入轨迹每一个轨迹点位置和每一个轨迹点具体维度的信息,通过输入轨迹得到输入维度和需要嵌入的维度512,然后通过正弦余弦函数生成一张序列长度x特征维度的位置空间图,从而保证不同轨迹点的不同维度拥有独一无二的位置纹理信息,位置空间图如图5中所示,位置嵌入具体实现如公式(6)所示:
[0101][0102]
其中,pos表示轨迹点具体位置,2i和2i 1分别表示轨迹点嵌入后在偶数列和奇数列的维度,分别采用sin函数和cos函数进行映射,d
model
为模型嵌入的维度,即512,1000表示轨迹序列的最大长度;
[0103]
s32:编码器;
[0104]
每一个编码器有6层结构完全相同,参数不同的编码层,每一层结构如图6所示,编码层由4个模块构成,分别由1个多头自注意力模块(multi-head convolution self-attention block)、2个残差及层归一化(sub-layer)和1个前馈神经网络(feed-forward network)依次串接而成,每一个编码层的输入特征维度和输出特征维度完全相同,从而保证了编码层可以多个串接;
[0105]
多头自注意力机制:
[0106]
多头自注意力模块细节如图6右侧所示,q、k、v为航迹特征矩阵乘以矩阵wq、wk、wv得到,分别为查询特征(query)、键特征(key)和值特征(value)。其中wq、wk、wv是不同的权值矩阵,它们轨迹特征矩阵进行不同的线性变换,将其映射到不同子空间;
[0107]
如图6中缩放点击自注意力层主要为自注意力操作,该操作可以被描述为一个查询(q)到一系列(k-v)对的映射。自注意力操作主要分为三步,第一步是将q和每个k进行相似度计算得到权重,实验采用点积的方式得到权重;然后第二步一般是使用softmax函数对这些权重进行归一化;最后将权重和相应的键值value进行加权求和得到最后的自注意力向量,自注意力运算的公式如下:
[0108][0109]
其中,k为键向量k,k
t
为键向量k的转置,使其能够进行矩阵乘法;dk为向量q的维度,以进行缩放起到分散注意力的作用,使得模型有更好的泛化能力,卷积注意力机制具有多头结构,是因为几个注意力层以相同输入进行不同线性变换并进行堆叠,而这种堆叠有助于模型捕获输入的各个维度信息,提高模型特征提取能力,图6中a表示注意力头的数量,在本实验中a取值为8,合并层便是对多个注意力头的结果进行合并,公式如(8)、(9)所示:
[0110]
multihead(q,k,v)=concat(head1,
…
,headh)woꢀꢀꢀ
(8)
[0111][0112]
其中,multihead函数为拆分层,将数据输入分为八份独立计算,一共有8个头,每个头各负责一个head;wo为对数据的变换参数;wq、wk、wv分别为查询向量q、键向量k和值向量v的变换参数;concat函数为图6中合并层,将每个注意力头的生成结果合并,线性层对合并结果再进行一次空间映射,其输出为多头自注意力模块输出结果。
[0113]
前馈网络:
[0114]
前馈网络用于逼近任意映射函数,图6中的前馈网络层包含线性变换和激活函数;在前馈网络中,通过线性变换对输入向量的维度d
model
进行扩维,实验采用了4*d
model
的维度;在激活函数的选择上,采用了bert模型的gelu激活函数,本发明采用的近似公式如(10)所示:
[0115][0116]
其中,x为输入,是模型中流转的数据。
[0117]
残差及层归一化:
[0118]
在多头自注意力模块和前馈网络之间均进行了残差(residual connection)和层归一化操作(layer normalization);残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率,其内部的残差块使用了跳跃链接,缓解了在深度神经网络中增加深度带来了梯度消失的问题和传统的神经网络在信息传递的时候,或多或少会存在信息丢
失,损耗等问题,残差网络使得层数很高的模型训练变得可行;层归一化是在特征维度这一维度进行归一化,可以将特征转为正态分布,将数据重新拉到激活函数的不饱和区间,有减缓梯度消失、增加模型精度和加快训练速度的作用;
[0119]
残差及归一化层公式如公式(11)所示:
[0120]
sub_layer_output=layernorm(x sublayer(x))
ꢀꢀꢀ
(11)
[0121]
其中x为输入,sublayer为残差操作,layernorm为层归一化操作;
[0122]
s33:解码器:
[0123]
同编码器一样,每一个解码器有6层结构完全相同,参数不同的解码层。6个解码层串接而成,前一层的输出为下一层的输入;解码层的结构如图7所示,不同于编码层结构,解码层由1个多头自注意力模块、1个多头注意力模块、1个前馈网络层和三个残差及层归一化层构成;数据每通过一次注意力层或者前馈网络层,都会进行残差及层归一化;不同于编码器的单个输入,解码器拥有两个输入,分别是编码器输出的注意力信息和待预测时间的高维嵌入,注意力信息attn是连接编码器和解码器之间的桥梁,每一个解码层的输入特征维度和输出特征维度完全相同,保证了多个解码层可以串接;编码层和解码层之间的区别在于两个注意力模块,其余部分与编码层完全相同;
[0124]
多头自注意力模块(mask):
[0125]
多头自注意力模块(mask)与编码层的多头自注意力模块相似,主要区别在于mask机制的不同;
[0126]
当模型在训练时,解码器一次性输入整条需要预测的轨迹,如待预测轨迹序列为12,假设当前已经预测了前5个,需要预测第6个,此时如果模型能够看到输入的全部待预测轨迹,那么它可以直接看到输入的第6个即答案,相当于模型不必去更新优化只需要从输入序列找到答案即可,这种
‘
偷懒’行为不是想要看到的,为了避免模型在当前位置看到后续需要预测的答案,采用了mask机制来保证在预测每一个轨迹点时,只有当前位置及以前能够被看到,mask机制如图8所示,它是一个倒三角矩阵,长度和宽度均为输入轨迹序列的长度,深色表示不遮挡,浅色表示遮挡,每一个轨迹点及之前的均不遮挡,该轨迹点后面是遮挡的,从而保证了模型看到当前位置后续输入;mask机制作用在计算q和k的点积结果之后,深色位置的值不变,浅色位置的值变为一个无穷小的数,设置为10-6
;
[0127]
多头注意力模块:
[0128]
解码层的多头注意力公式如公式(12)所示,其中qd是解码层的查询特征,ke和ve均为编码器输出的注意力信息attn的线性变化数据,dk为嵌入维度512;在这个模块中解码层利用了编码器输出的注意力信息,其实也就是存储的观测序列o
bd
的特征和规律,从而使得解码层能够充分利用已经观测到的轨迹信息,预测出精确的下一个轨迹点位置;
[0129][0130]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0131]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。
对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。