1.本发明涉及生物医学信号处理领域,尤其涉及一种面向可穿戴设备光电容积脉搏波信号发现和识别新用户的身份识别方法。
背景技术:
2.与指纹、虹膜和面部等生物特征身份识别技术相比,面向可穿戴设备光电容积脉搏波信号(photoplethysmography,ppg)的信号的生物特征身份识别技术因其高安全性成为当前研究的热点。ppg可以从人体多个位置的可穿戴设备手指,手腕等,这使得它比其他生物医学信号,如心电图(electrocardiogram,ecg)和脑电图(electroencephalogram,eeg)信号。此外,ppg传感器体积小,开发成本低,为人们提供了更有效的身份识别手段。
3.通常,基于ppg信号的生物特征身份识别技术有两种应用:验证应用(一对一匹配)通过获取的特征与其数据库中的已存储的模板是否匹配来证明某人的身份,而识别应用(一对多匹配)通过将待识别用户的特征与所有存储的模板进行比较来识别用户。
4.对于验证应用而言,最早使用传统手工分析方法进行身份的验证,如使用傅里叶变换、模糊逻辑分析和线性判别分析处理和分析ppg信号进行用户认证,可以达到超过90%的准确率。但是以这种传统信号处理方法并手工提取特征的方法十分复杂和繁琐,使得将该技术应用于实际生活不具备可行性。为了降低传统方法的复杂性,有学者提出了一种基于卷积神经网络(convolutional neural networks,cnn)结合长短期记忆(long short-term memory,lstm)神经网络的方法用来摆脱提取手工特征的复杂性和不稳定性。以此网络为基础的研究,能够很好的利用一维周期信号的时序性,无需对原始信号进行大量数学上的复杂计算和特征提取,仅花费训练分类器网络的时间代价就能达到可以超过传统手工特征提取方法的准确性。
5.而对于识别应用,有学者提出使用离散小波变换和支持向量机分类器对用户进行分类,同时有研究从ppg原始信号、它的一阶导数信号及二阶导数信号上提取手工特征进行用户识别,取得了不错的效果。另有研究提出了一种乌鸦搜索算法(crow search algorithm,csa)来优化支持向量机分类模型。但是,同验证应用一样,现有的方法和研究仅仅是在已知的老用户(已知用户)上进行手工特征特取,过程十分复杂和繁琐。尽管使用深度神经网络可以很好地降低复杂度,但目前未有在识别应用下使用深度神经网络进行多分类的实际研究。一方面是由于直接使用深度神经网络进行多分类难度大且分类效果不理想;另一方面是在实践中,存在随时可能加入的新用户,由深度网络直接进行分类无法很好地发现和识别这些新用户,反而更倾向于将他们分类为某一类老用户而导致识别错误。因此,将具有实际应用价值的深度神经网络使用在身份识别场景,探寻利用其发现和识别新用户的方法存在很大的挑战。
技术实现要素:
6.本发明的发明目的在于:针对上述存在的问题,提供了一种面向可穿戴设备光电容积脉搏波信号的,使用深度神经网络、聚类算法和距离相似度相结合的发现和识别新用户的身份识别方法。
7.本发明采用的技术方案为:
8.面向可穿戴设备光电容积脉搏波信号发现和识别新用户的身份识别方法,包括下列步骤:
9.步骤s1:以用户的面向可穿戴设备光电容积脉搏波信号(ppg信号)设置训练集s;
10.对训练集s中的ppg信号进行信号预处理,获取指定长度的心跳周期信号(单周期ppg信号),将每个心跳周期信号作为一个样本,每个样本对应的用户作为样本标签,得到输入信号训练集t;
11.进一步的,信号预处理包括:滤波去噪、正则化归一化处理、波峰检测和心跳周期提取,对心跳周期的信号样本点进行插值处理,从而得到指定长度的心跳周期信号;
12.进一步的,去噪的处理方式可以是:通过截止频率为0.5hz-5hz的二阶巴特沃斯带通滤波器来消除噪声。
13.进一步的,正则化归一化处理方式为:归一化为零均值和单位方差。
14.此外,在去噪处理中,也可以采用诸如经验模式分解(empirical mode decomposition,emd)、小波变换(wavelet transform,wt)、奇异谱分析(singular spectrum analysis,ssa)等方法对信号数据进行预处理。
15.进一步的,插值处理为:三次样条插值方法。
16.步骤s2:基于所述输入信号训练集t对设置的深度神经网络进行训练,将训练好的深度神经网络作为特征提取器;
17.在一种可能的实现方式中,所述深度神经网络的网络结构为:一维卷积神经网络(cnn)加长短期记忆网络(lstm),用于从单周期ppg信号中提取具有可辨识性和和具有时间稳定性的特征。具体地,网络首先经过两层cnn模块,每层cnn模块由一个正则化层、一个最大池化层、一个dropout层(在每一个batch的训练当中随机减掉指定数量的神经元)和非线性激活函数单元(relu)组成,随后则通过两层lstm网络来捕获具有时间稳定性的特征,最后则使用全连接层保留最具有区别的特征,其中全连接层的神经元数量取决于提取特征的维度(即模板维度),由用户基于实际需求进行设置。
18.在一种可能的实现方式中,在训练设置的深度神经网络时,使用中心损失函数lc配合原始的softmax多分类交叉熵损失函数ls,以使训练得到的特征提取器提取的特征尽可能呈圆形分布。普通softmax多分类器使用的损失函数为交叉熵损失函数:
[0019][0020]
其中,n代表样本数,p
i,k
表示第i个样本预测为第k个标签值的概率,y
i,k
表示第i个样本的样本标签,即所对应的用户索引,k表示标签数量,即类别数(本发明中,具体指输入信号训练集t中的用户数),中心损失函数为:
[0021][0022]
其中,xi代表第i个样本,代表训练过程中第yi个老用户的样本中心。
[0023]
本发明中,所述深度神经网络的损失为两者的结合,即:
[0024]
l
new
=ls λlc[0025]
其中,标量λ(也可称为系数或权重)是用于平衡两个损失函数的参数。
[0026]
步骤s3:基于所述特征提取器对输入信号训练集t的各样本进行特征向量提取,以构建模板数据库:
[0027]
即对深度神经网络特征提取器提取的具有辨识性的特征,在训练阶段构建模板数据库,其过程包括针对训练集t中提取的特征依次进行聚类、转换、距离相似度计算、模板存储构建数据库;在识别处理时,则跳过聚类,仅依次进行转换、距离相似度计算、模板匹配以进行用户(包括新用户)的身份识别;
[0028]
步骤s301:针对训练集t中提取的特征向量(每个样本对应一个特征向量),利用聚类算法将所有特征向量聚类得到各用户yi的聚类中心
[0029]
在一种可能的实现方式中,可以使用k-means聚类算法进行聚类,步骤具体为:
[0030]
1)首先确定一个k值,即预输入训练样本集t中的的用户数量;
[0031]
2)接着从预输入训练样本集t中随机选取k个样本作为质心;然后对每一个样本xi,计算其与每一个质心的距离,并将其划分到距离最近质心所属的集合;
[0032]
3)从已分好的集合中重新计算每个集合的质心
[0033]
4)如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值,则认为聚类已经达到期望的结果,算法终止,否则重新迭代步骤2~3。
[0034]
k-means算法得到的每个用户的中心位置可以很好地看作该用户的分类特征向量。
[0035]
步骤s302:基于同一个用户的所有特征向量xj到各用户聚类中心的马氏距离的平均值得到每个用户的分类特征向量
[0036]
其中,mi表示第i个用户的总体训练样本个数,表示第i个用户上的第j个样本的特征向量,d(
·
)表示马氏距离;
[0037]
本发明中,通过计算每个特征向量xj到各用户聚类中心的距离,将深度神经网络提取的抽象特征向量转换为基于距离的特征向量x
′j。在此处,考虑到样本分布引起的误差,采用马氏距离(mahalanobis distance)作为距离度量,计算每个特征向量xj到各用户聚类中心的距离,以消除不同特征之间相关性的干扰,马氏距离的计算公式如下:
[0038][0039]
其中,表示第yi个用户的协方差矩阵。将深度神经网络提取的抽象特征向量转
换为基于距离的特征向量x
′j,具体公式为:
[0040][0041]
其中,转换后的特征向量x
′j是由转换前的特征向量xj到所有k个用户的聚类中心点的马氏距离组成。
[0042]
转换后的特征向量具有一些优点:一是抽象的深层次多维特征向量被降维成低维距离特征向量;二是经训练后的样本将会靠近各自类别的中心,而未训练的样本将远离所有中心,可以以此识别老用户和新用户。
[0043]
然后计算同一个用户的所有特征向量到各用户聚类中心的马氏距离的平均值,并作为该用户的分类特征向量基于所以用户的分类特征向量得到模板匹配分类数据库;进而使得在识别处理时,由于在识别过程中连续收集ppg信号,因此我们使用由原始信号中所有周期的平均距离组成的特征向量进行识别。
[0044]
再将计算得到的每个训练用户的分类特征向量存入模板匹配数据库,以供用户身份识别处理时使用。
[0045]
步骤s4:基于特征提取器和模板匹配数据库对待识别的ppg信号进行身份识别处理:
[0046]
步骤s401:采集待识别用户(包含老用户(模板匹配数据库中已存在的用户)和新用户)的ppg信号,得到待识别信号;
[0047]
对待识别信号进行信号预处理,得到待识别的心跳周期信号,其中,信号预处理与对训练集s中的ppg信号进行信号预处理的方式相同;
[0048]
步骤s402:基于所述特征基于所述特征提取器对待识别的心跳周期信号进行特征向量提取,得到待识别特征向量;
[0049]
步骤s403:计算待识别特征向量到各用户聚类中心的马氏距离,得到待识别分类特征向量
[0050]
计算待识别分类特征向量与模板匹配数据库中的各分类特征向量之间的余弦相似度若存在一个大于或等于预设阈值的余弦相似度则待识别用户为当前分类特征向量所对应的用户yi,若所有余弦相似度均小于预设阈值,则判定待识别用户为新用户,并将待识别分类特征向量加入至模板匹配数据库。
[0051]
进一步的,余弦相似度为:
[0052][0053]
其中,为表示模板匹配数据库中的所有用户的分类特征向量的平均值,符号||
·
||表示范数。
[0054]
本发明的面向可穿戴设备光电容积脉搏波信号发现和识别新用户的身份识别方法精确度高,计算复杂度低,适用于实际生活中的日常生活场景,能够达到在办公室或其他室内进行用户身份识别的目的,可以方便的应用于可穿戴设备中。
附图说明
[0055]
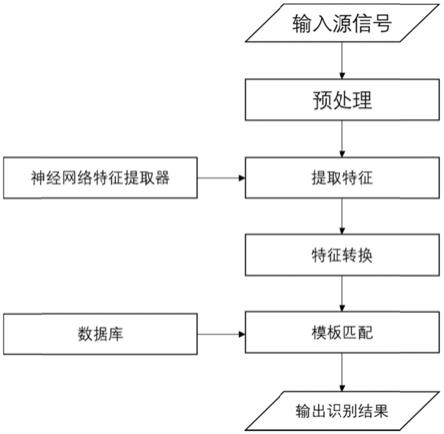
图1是本发明实施例提供的的面向可穿戴设备光电容积脉搏波信号发现和识别新用户的身份识别方法训练阶段流程图;
[0056]
图2是本发明实施例提供的面向可穿戴设备光电容积脉搏波信号发现和识别新用户的身份识别方法的识别阶段流程图。
具体实施方式
[0057]
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
[0058]
本发明公开了一种面向可穿戴设备光电容积脉搏波信号发现和识别新用户的身份识别方法。本发明主要包括输入信号处理、深度神经网络特征提取器训练、聚类寻找类别中心点、特征向量转换以及调整余弦相似度识别五部分。输入信号处理为:将输入信号依次经过带通滤波、正则化归一化处理、波峰检测、心跳周期划分后得到深度神经网络统一的输入信号;深度神经网络特征提取器训练为:训练由一维卷积神经网络和长短期记忆网络构成的深度神经网络作为输入信号的特征提取器,以提取输入信号具有时间稳定性的可辨别性的特征;聚类寻找类别中心点为:利用相应的聚类算法找到各类别的类别中心,并将深度网络提取的抽象的深度特征转换为基于到类别中心的距离特征向量构建识别模板数据库;再基于调整余弦相似度,将超过预设阈值的特征向量识别为模板数据库中已有的老用户,将所有相似度均低于预设阈值的特征向量识别为新用户的特征向量。本发明用于身份识别,其实施便捷、实用性高、识别精度高,可以进行跨时期的身份识别,同时能够有效地识别未在数据库中的新用户。
[0059]
实施例
[0060]
参见图1,2,本发明的方法主要包括两个阶段:训练阶段和测试阶段(识别阶段)。其中训练阶段包括输入信号预处理、训练深度网络特征提取器、提取特征、聚类算法聚类特征、基于距离的特征转换五部分,测试阶段包括输入信号预处理、深度神经网络特征提取、基于距离的特征转换、基于余弦相似度的身份识别四部分;
[0061]
本实施例中,信号预处理阶段,采用截止频率为0.5hz-5hz的二阶巴特沃斯带通滤波器来消除噪声。然后,将原始ppg信号归一化为零均值和单位方差以进行后续处理。应用收缩峰值检测将原始ppg信号分割为单个心跳周期。在此之后,使用pan tompkins算法来寻找正确的峰值ppg信号。由于数据集中每个用户的心跳周期约为70-90个样本,利用三次样条插值将其缩放到128个样本,形成深度神经网络的统一输入格式,以便训练深度神经网络。
[0062]
本实施例中,深度神经网络特征提取器训练阶段,采用并改进了由l.everson提出的基于cnn结合lstm的完全数据驱动的方法,以自动从ppg循环序列中提取特征。不同的是,现有方式中是将其用作验证应用程序的二元分类器,本发明实施例中,则是将其训练为识别应用程序的特征提取器。一旦经过训练,输入信号就会被输入到经过训练的网络中以提取特定的特征。具体地:
[0063]
在模型设计部分,使用128个样本的心跳周期信号作为网络的输入。在输入层之后是两个一维卷积层,由一个批范数层、一个最大池化层、一个dropout层和一个修正线性单
元(relu)激活函数组成。然后使用两个lstm层来捕获时间属性。最后,使用具有32个神经元的密集层来保留最具辨别力的特征以进行聚类。
[0064]
在训练优化部分,考虑到传统损失函数训练出来的特征提取器存在一些不利于聚类算法的缺陷,一个典型的例子是模型提取的特征不会均匀紧密地聚集在一起,而是倾向于呈线性或椭圆形聚集,这使得某些类的类内距离甚至超过类间距离。因此本发明采用了中心损失与传统交叉熵损失相结合的方法,其过程是通过在传统的softmax损失ls上加上中心损失lc来训练模型,并在训练过程中使用新的损失函数l=ls λlc来指导网络训练。普通softmax多分类器使用的损失函数为交叉熵损失函数:
[0065][0066]
其中n代表样本数,第i个样本预测为第k个标签值的概率为p
i,k
,中心损失函数为:
[0067][0068]
其中xi代表第i个样本,代表训练过程中第yi个用户的样本中心,结合后的损失函数:
[0069]
l
new
=ls λlc[0070]
其中,标量λ是用于平衡两个损失函数的参数。
[0071]
本实施例中,在聚类特征阶段,一旦得到了深层特征,下一步则期望寻找最具代表性的特征向量,它可以通过基于距离度量、相似性和相关性的方法来识别所有用户。在此基础上,采用k-means聚类算法拟合数据是最好的选择。一方面,由于提前已知所有的特征将被聚类成k个类(其中k表示k个训练过的老用户),这样的先决条件使算法更简单、更高效。另一方面,k-means得到的每个训练用户的中心位置可以很好地看作特征向量,使得后续的基于距离的特征转换更加快捷和高效。
[0072]
本实施例中,在特征转换阶段,采用基于距离的方式将深度神经网络提取的抽象特征转换为距离特征。由于一个点在三维坐标系中的位置由它到x轴、y轴和z轴的距离组成的向量决定。类似地,本实施例中的一个样本在k维空间中的位置由它到k个中心的距离组成的向量决定。同时考虑到样本分布引起的误差,采用马氏距离作为距离度量,以消除不同特征之间相关性的干扰。转换特征后,训练样本靠近各自的中心,而未训练的样本远离所有中心,因此可以用来识别老用户和新用户。
[0073]
由于在识别过程中连续收集ppg信号,因此可以使用由原始信号中所有周期的平均距离组成的特征向量进行识别。本实施例中,在识别阶段,采用调整的余弦相似度来对特征向量进行识别。即计算转换后的待分类的特征向量到模板数据库中各用户分类特征向量的调整余弦相似度其中,调整余弦相似度的计算公式具体为:
[0074]
[0075]
其中,为数据库中所有已有用户的分类特征向量的平均值。
[0076]
计算得到该信号到数据库中所有已有的老用户的调整余弦相似度判断待识别信号是否为新用户:若存在一个大于或等于预设阈值s,则判定为老用户yi;若全部低于预设阈值s时,判定为新用户,并将作为该用户的分类特征向量加入至数据库以供后续识别。
[0077]
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。