1.本发明涉及计算机技术领域,涉及多目标追踪技术,特别涉及一种基于目标运动预测和端到端神经网络的多目标追踪方法。
背景技术:
2.多目标追踪技术旨在和人类视觉系统一样,为每一个目标预测、绘制其运动轨迹,并以此作为其行动判断的依据。随着近年来相关研究的飞速发展,多目标追踪已经在刑侦安防、机器人视觉、自动驾驶等许多应用场景发挥重要作用。多目标追踪与目标检测类似,通常需要为每一个目标输出一个矩形框,即用坐标、高度、宽度等来辨别每一个目标;但与目标检测不同的地方在于,多目标追踪还需要为每一个目标赋予一个id,同一个目标在不同帧之间,需要拥有相同的id。多目标追踪在某种程度上与行人搜索更为相似,既要关注检测,又需要处理匹配问题。不同之处在于,行人搜索任务行人搜索是基于图像的,没有时间维的上下文信息;多目标追踪是基于视频的,是在连续的帧中搜索目标,目标的位置和外表变化不会太大。换句话说,行人搜索是一个一对多的任务,而多目标追踪是一个多对多的任务。
3.多目标追踪的探索过程经历了以下几个阶段:早期的研究以视觉追踪 (visual tracking)为主,传统方法使用各种各样的视觉追踪框架,例如判别式相关滤波器(discriminative correlation filters,dcf),轮廓追踪 (silhouette tracking),核追踪(kernel tracking)等。一般来说,传统的追踪方法会假设目标的结构、运动方式保持不变,寻求合适的手工特征,因此无法解释目标的语义信息,也无法处理外貌的变化等。sort使用卡尔曼滤波器来预测目标在下一帧的位置,计算其与下一帧中的检测结果的重合度。 iou-tracker通过比较相邻帧的检测结果之间的重合度来直接匹配检测结果。 sort和iou-tracker因为其简单易用的特性而被广泛使用,但也因为较为简单,而无法处理较为复杂的场景,例如密集的人群、相机运动等。bae使用线性判别分析(linear discriminant analysis)来为每个目标提取id特征,从而得到了更加鲁棒的追踪结果。xiang使用马尔可夫决策过程参与追踪轨迹预测,也取得了不错的效果。
4.随着近年来深度学习的兴起与发展,许多研究者开始使用基于深度学习的方法来进行目标追踪。由于深度神经网络强大的拟合能力,在数据足够的条件下,可以直接得到更具鲁棒性的特征,效率大大提高。早期算法通常将目标追踪任务分成目标检测和id特征提取这两个步骤,通常首先使用faster r-cnn 等目标检测算法来定位每一帧中的目标,再在原图中切割检测结果的图片,最后对这些切割得到的图片进行匹配。标准的匹配过程通常包括计算id特征或者检测结果的代价矩阵,再使用卡尔曼滤波器和匈牙利算法(hungarian algorithm) 等完成匹配过程。有一些研究工作使用rnn来参与匹配过程,例如使用图匹配,也取得了不错的效果。
5.孪生网络模型通过共享网络参数,使用一组参数便能将一个子序列中的所有信息关联起来,使得大部分运算可以并行化,提高了运算效率。
6.孪生网络模型具有两个或者多个输入分支,用于处理多个数据,方便提取其特征。当不同的输入分别通过输入分支提取特征之后,便会整合并进行统一处理,从而获取他们之间的相关信息。由于两个分支共享参数,且整个模型统一进行优化,最终学习到的模型能够很好的提取不同输入之间的相关性,这正是多目标追踪所需要的。
7.相关性(correlation)是数字信号处理中的术语,用于描述两个或多个信号之间的相对关系。对于单目标追踪方法来说,基于相关性滤波器的方法是主流,因为这类场景只需要考虑一对一的匹配问题。相关滤波器也广泛应用于光流估计
技术实现要素:
8.本发明的目的在于提供一种基于目标运动预测的多目标追踪方法,该方法在密集场景的多目标追踪任务上达到良好效果。本发明以孪生网络结构的目标检测模型为基础的预训练模型,引入相关性模块和匹配损失函数,通过直接预测运动运动量实现目标追踪,得到了一个鲁棒的多目标追踪模型。
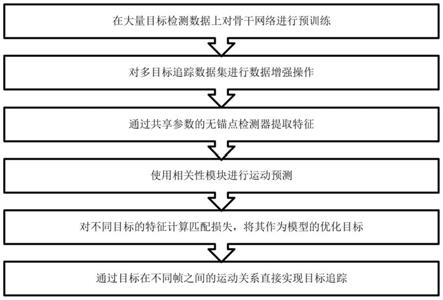
9.为了实现上述目的,设计一种基于目标运动预测的多目标追踪方法,其特征在于,该方法包括如下步骤:
10.步骤一:基于大量目标检测数据集预训练出基本的目标检测模型,所述预训练模型为孪生网络结构的端对端神经网络,有两个输入分支,预训练后可得到网络的初始参数;
11.步骤二:对多目标追踪数据集进行数据增强操作,获得不同视角、图像畸变、遮挡后的数据;
12.步骤三:增强后的数据通过共享参数的无锚点检测器提取特征;
13.步骤四:使用相关性模块对目标进行进行运动预测,所述的相关性模块是一种获取目标在相邻帧之间的位置关系,用于对运动信息进行建模的计算模块;
14.步骤五:对不同目标的特征计算匹配损失,将其作为模型的优化目标,所述的匹配损失作为整个模型训练时的优化目标,通过提升同一目标特征的相似度、降低不同目标特征的相似度的准则来学习表征;
15.步骤六:通过目标在不同帧之间的运动关系直接实现目标追踪。
16.本发明还具有如下优选的技术方案:
17.1.步骤二所述的数据增强操作是指:对于原始图像,进行翻转、裁剪、旋转或仿射变换,详细步骤包括:
18.步骤a1:随机对图像进行左右翻转,保持所有目标仍在原图像内;
19.步骤a2:随机对图像进行裁剪、旋转、仿射变换,保证图像内至少还剩一个目标;
20.步骤a3:随机对图像进行高斯模糊、hsv色彩变换。
21.2.步骤三所述的通过无锚点检测器直接对整张图片提取特征,同时预测每个目标的位置和大小,两个分支的检测器共享参数,同时优化,减少了参数数量。
22.3.步骤四所述的相关性模块是一种获取目标在相邻帧之间的位置关系,对运动信息进行建模而设计的计算模块,详细步骤包括:对于两张高度为h,宽度为w,通道数为c的特征图f1,f2∈r
hw
×c,对于f1中的点每一个像素点p1与f2中的点p2,需要在p1周围半径为d(displacement)的方形区域内寻找相关性最高的点,即p1,p2满足p1=p2 off,其中off∈[-d,d]
×
[-d,d],令其输出的相关性图表示为假定corr
(p1,p2)
表示
p1与p2两处的相关性,令fi(pi o)∈rc为ii中的点pi的某个半径为k(kernel)的邻域内点pi o处的特征,则有:
[0023]
corr
(p1,p2)
=∑
o∈[-k,k]
×
[-k,k]
《f1(p1 o),f2(p2 o)》;
[0024]
这里《f1,f2》表示两个子特征图的点积。
[0025]
4.通过控制p1与p2之间的位置关系来减少计算量。
[0026]
5.引入stride,间隔取点计算相关性。
[0027]
6.通过双线性插值或者其他上采样方法提升分辨率。
[0028]
7.步骤五所述的匹配损失作为整个模型训练时的优化目标,通过提升同一目标特征的相似度、降低不同目标特征的相似度的准则来学习表征,符合下列式子:
[0029][0030][0031][0032]
l
id
=l
identity
λl
matching
[0033]
其中f1,f2是归一化的特征向量,idi是fi对应的id,k
和k-分别表示正样 本对和负样本对的数目,和分别表示正样本对和负样本对的 损失,其损失值大小与id特征向量之间存在夹角关系,λ是用于平衡损失的系 数;详细步骤包括:
[0034]
步骤c1:在所有数据中选择一个批集合,将其中选择经过同一个数据增强得到的相邻两帧作为训练样本送入网络;
[0035]
步骤c2:通过检测器提取每个目标的特征fi,具有相同id的特征对(fi,fj) 计算其余的计算
[0036]
步骤c3:对本批集合中的匹配损失求和,加上其他的检测损失,并使用adam 优化器进行梯度更新;
[0037]
步骤c4:处理其他批集合中的数据,重复c1-c3直到对比损失下降到收敛停止训练。
[0038]
8.步骤六所述的通过目标在不同帧之间的运动关系直接实现目标追踪是指:在模型推理过程中,对每个目标优先使用预测得到的运动量,计算得到其在下一帧中的位置,从而直接将两帧中的两个目标联系起来,构成一段轨迹,从而减少遮挡导致的误差。
[0039]
本发明同现有技术相比,其优点在于:本发明结合以上技术训练出一种多目标追踪模型,这个模型在密集场景的多目标追踪数据上具有良好的性能并减少了遮挡导致的误差。具体包括:
[0040]
1.将大量目标检测预训练得到的基本模型迁移到多目标追踪的任务中;
[0041]
2.使用一种相关性模块对不同帧的目标之间的相关性进行建模,提取运动信息;
[0042]
3.对各个目标的特征计算匹配损失,将其作为模型的优化目标,增加了模型的泛化能力;
[0043]
4.通过目标在不同帧之间的运动关系直接实现目标追踪,减少遮挡问题产生的干扰,增加了模型的鲁棒性和密集场景下的准确性。
附图说明
[0044]
图1为本发明流程图;
[0045]
图2为相关性模块原理示意图;
[0046]
图3为整体网络架构图。
具体实施方式
[0047]
下面结合附图对本发明作进一步说明,本发明的结构和原理对本专业的人来说是非常清楚的。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0048]
本发明提出一种新的多目标追踪模型,本发明以孪生网络结构的目标检测模型为基础的预训练模型,引入相关性模块和匹配损失函数,通过直接预测运动运动量实现目标追踪,得到了一个鲁棒的多目标追踪模型。
[0049]
由于多目标追踪数据集规模较小,难以支持较大的模型训练,因此,本发明在首先在大量目标检测数据集上对用于提取特征的骨干网络进行预训练,使得参数从中得到初始化。骨干网络可以根据需要进行更换,包括但不限于resnet、 unet等。
[0050]
本发明采用数据增强的方式对多目标追踪数据集进行进一步的扩充。从而能够针对性地在特定场景数据集上进行微调。
[0051]
本发明通过共享网络参数的无锚点检测器提特征提取特征,并预测得到单帧图像中每个目标的位置和大小信息。共享参数使得模型能够对同一目标提取到相同的特征信息,从而提升之后追踪的效果。
[0052]
本发明通过引入相关性模块,计算相邻两帧的特征图的相关性,从而对各个目标的运动信息进行建模,并最终预测得到每个目标的运动运动量,可以直接实现目标追踪。
[0053]
此外本发明提出了一种损失函数,通过提升同一目标特征的相似度、降低不同目标特征的相似度的准则来学习表征。这种方法与具体目标无关,从而使得模型的泛化能力更强。
[0054]
本发明包括如下步骤:
[0055]
1、基于大量目标检测数据集对提取特征的骨干网络进行预训练。
[0056]
多目标追踪数据集通常较小,直接用于从头开始训练容易发生过拟合,导致实际的检测和追踪效果较差。
[0057]
2、对多目标追踪数据集进行数据增强操作,确定数据增强的变化组合,生成训练数据。
[0058]
数字图像处理包含了随机的反转、旋转、裁剪、平移、色彩空间变换、增加随机噪声等。其中,不同的变换组合方式是可选择的。经过不同的变换组合,可以使得数据量大大增加。
[0059]
3、使用共享参数的无锚点检测器提取特征。
[0060]
由于检测器已经在目标检测数据集上进行了预训练,能够提取到每个目标的纹
理、语义特征,这些特征会用做后续的运动量预测以及匹配。同时检测器也会输出每个目标在图像中的位置、大小,作为该目标的几何表示。
[0061]
4、使用相关性模块获取目标在相邻帧之间的位置关系,对运动信息进行建模,进而对目标进行进行运动预测。
[0062]
多目标追踪区别于一般目标检测的地方在于,需要提取不同图像帧之间的关联信息。本方法提出的相关性模块能够计算两张特征图各个位置处的相关性强弱,进而用于预测各个目标的运动信息。
[0063]
5、确定匹配损失函数中的相似度。
[0064]
本发明在在孪生网络结构下对各个目标的特征向量计算对比损失。为了使得同一目标具有相同的表征,且差异化不同目标的表征,需要定义特征之间的距离函数,也称之为相似度。常用的距离函数有欧几里得距离、曼哈顿距离、明可夫斯基距离、余弦相似度等函数,可以从不同的角度描述特征向量之间的距离以及相似程度。
[0065]
5、训练端到端多目标追踪模型。
[0066]
端到端网络以匹配损失和其他检测损失为优化目标可以对直接对网络进行训练,并对参数进行优化。本发明使用adam算法训练模型,adam算法利用指数滑动平均估计梯度的一阶矩和二阶矩,缩小了随机梯度的方差,使模型能够更快收敛。
[0067]
6、训练完毕后进行测试,对多目标追踪数据集进行测试。
[0068]
在各项损失的数值趋于收敛时,模型训练完毕,模型参数达到最优。此时可以固定模型参数,将多目标追踪数据集中划分出来的测试集输入到模型中进行测试。
[0069]
实施例
[0070]
以下是训练多目标追踪模型的具体实施例。在这个实施例中用于预训练的数据集为coco,在多目标追踪数据集mot20上进行微调。训练过程分为预训练与迁移学习后的训练两部分。
[0071]
1、选取dla-34作为骨干网络,在图片总数约为330k的coco数据集上进行特征提取网络的预训练,得到骨干网络的初始化参数。
[0072]
2、mot20数据集上已经对训练集和测试集进行了划分,我们只使用训练集参与网络训练。
[0073]
3、对训练数据采用不同的数据增强变化组合生成大量数据。为了保证实验的公平性,基线模型与实验模型所采用的数据增强保持一致。
[0074]
4、配置相关性模块。步骤如下:
[0075]
步骤1:对于两张高度为h,宽度为w,通道数为c的特征图f1,f2∈r
hw
×c,对于f1中的点每一个像素点p1与f2中的点p2,需要在p1周围半径为d (displacement)的方形区域内寻找相关性最高的点,即p1,p2满足p1=p2 off,其中off∈[-d,d]
×
[-d,d]。令其输出的相关性图表示为假定corr
(p1,p2)
表示p1与p2两处的相关性,令fi(pi o)∈rc为ii中的点pi的某个半径为k(kernel)的邻域内点pi o处的特征,则有:
[0076][0077]
这里《f1,f2》表示两个子特征图的点积。
[0078]
步骤2:由于上式与神经网络中卷积的定义相近,每次计算corr
(p1,p2)
需要进行c
·
(2k 1)2次乘法,比较所有的区块需要进行w2·
h2次计算。由于在整张特征图全部位置搜索计算会导致计算量过大,必须限制参与相关性计算的区块范围。实验时,可以通过控制p1与p2之间的位置关系来减少计算量,即控制displacement的范围。与此同时,可以引入stride,间隔取点计算相关性,如有必要可再通过双线性插值或者其他上采样方法提升分辨率。
[0079]
在本实验中,设置最大displacement为20,stride为2。
[0080]
5、对于不同的目标,使用不同的匹配损失函数,公式表述如下:
[0081][0082][0083][0084]
l
id
=l
identity
λl
matching
[0085]
其中f1,f2是归一化的特征向量,idi是fi对应的ud,k
和k-分别表示正样 本对和负样本对的数目,和分别表示正样本对和负样本对的 损失,其损失值大小与ud特征向量之间存在夹角关系,λ是用于平衡损失的系 数;在本实验中,λ取值为1。
[0086]
6、在多目标追踪数据集上训练网络,详细步骤包括:
[0087]
步骤c1:在所有数据中选择一个批集合,将其中选择经过同一个数据增强得到的相邻两帧作为训练样本送入网络;
[0088]
步骤c2:通过检测器提取每个目标的特征fi,具有相同id的特征对(fi,fj) 计算其余的计算
[0089]
步骤c3:对本批集合中的匹配损失求和,加上其他的检测损失,并使用adam 优化器进行梯度更新;
[0090]
步骤c4:处理其他批集合中的数据,重复c1-c3直到对比损失下降到收敛停止训练;
[0091]
7、训练完毕后,对多目标追踪数据集mot20中的测试集进行性能测试。对追踪结果的mota、motp、idf1、ids值进行计算。将本模型与其他基线模型的性能进行比较并记录在表1。这些基线模型包括了transtrack、trackcenter、 gsdt、cstrack和fairmot。这些监督模型和本发明提出的模型具有类似的骨干网络。
[0092][0093]
表1基于目标运动预测的多目标追踪模型与其他基线模型的比较。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
