一种基于dsp的混合位宽加速器及融合计算方法
技术领域
1.本发明涉及混合位宽神经网络加速器设计,具体涉及一种基于高位宽dsp的混合位宽加速器及融合计算方法。
背景技术:
2.本发明中提到的dsp均指fpga中的dsp ip,即实现数字信号处理技术的ip。dsp的优势在于处理信号的高速和实时特性。dsp内部具有专门的硬件乘法器,可以用来快速的实现各种数字信号处理算法。以xilinx 7系列fpga的dsp48e1 ip为例,其内部主要包含一个25
×
18位宽的乘法器,48位的累加器等,可以无需借助fpga资源实现乘、乘累加、按位逻辑操作等运算,在图形图像处理、语音处理、信号处理等通信领域应用广泛。
3.为提高神经网络计算速度,缓解参数存储压力,量化方法大量使用在深度神经网络中。量化后的网络参数位宽变小,带来计算效率的提升,减少了存储资源开销并降低了能耗,使硬件性能有了大的改善。由于不同的网络层参数对损失函数的影响程度不同,因此如果使用统一的量化精度对神经网络进行量化,如果量化精度过低,则会造成网络性能大大降低,若量化精度过高,则不能充分发挥量化的优势。基于此考虑,需要探索混合位宽量化来优化网络量化问题。基于混合位宽量化的量化方法对网络的不同层选择不同精度的量化。存内计算对于混合位宽量化的使用非常普遍,一方面,更低位宽的参数对于有限的存储容量是友好的,另一方面,支持混合位宽量化实际上已经成为上层生成的网络模型对神经网络加速器的一种需求,因为上层的网络模型为了提高运算速度,降低量化位宽是行之有效的方法。混合位宽量化可以在保证准确性的情况下显著降低参数量。
4.研究显示要保持同样的准确性,深度学习推断中无需浮点计算,对于图像分类等许多应用只需要int8或更低定点计算精度来保持可接受的推断准确性。在量化精度降低的背景下,固定位宽的dsp必然存在计算资源浪费的情况。且由于神经网络更新迭代周期短、变化快、不同网络量化参数差异大的特点,针对特定网络设计相应的低位宽dsp是不现实的。因此一种解决方法便是尝试利用高位宽dsp并行实现多个低位宽的乘累加运算。在这方面,xilinx基于其dsp48e2提出了int8量化下的并行方法,实现了一个含27
×
18的dsp并行实现两个8位宽乘法的方案,达到1.75倍的峰值计算性能的提升。但其存在的问题是:1)神经网络量化位宽仅考虑了8bit,而对于混合位宽量化的网络,更低位宽的量化参数(如4bit,2bit,1bit等)是常见的;2)仅考虑权值共享的情况,即并行的两组乘法中乘数固定,因此通用性不强;3)受限于其8bit的量化位宽考虑,没有提出更高并行度(即同时实现更多组乘法)的实现方案。
技术实现要素:
5.为了解决上述现有技术的问题,本发明提供一种基于高位宽dsp的混合位宽加速器及融合计算方法,支持乘数固定和不固定两种情况,通用性更好;能并行实现多组任意低位宽乘累加运算,最大化dsp计算性能。
6.本发明通过一下技术方案实现:
7.一种基于dsp的混合位宽加速器,包括第一信号输入端、第二信号输入端、第三信号输入端、第四信号输入端、第一移位单元、第一加法器、第一选择器、第三选择器、第二移位单元、第二加法器、第二选择器、第四选择器和dsp;
8.第一信号输入端和第二信号输入端分别用于接收被乘数,第三信号输入端和第四信号输入端分别用于接收乘数;
9.当并行度为1时,第一信号输入端的被乘数直接经第一选择器选择进入dsp,第三信号输入端的乘数直接经第二选择器选择进入dsp,被乘数和乘数在dsp中进行乘法累加运算;
10.当并行度大于1时,第一信号输入端的被乘数在第一移位单元中进行移位操作,移位操作后进入第一加法器与第二信号输入端的被乘数进行加法运算,加法运算后得到的被乘数进入第三选择器,经第三选择器选择进入第一加法器,继续与移位操作后的第一信号输入端的被乘数进行加法运算,直至所有被乘数均完成加法运算;所有被乘数均完成加法运算之后,第一加法器得到的高位宽被乘数经第一选择器选择进入dsp;第三信号输入端的乘数在第二移位单元中进行移位操作,移位操作后进入第二加法器与第四信号输入端的乘数进行加法运算,加法运算后得到的乘数进入第四选择器,经第四选择器选择进入第二加法器,继续与移位操作后的第三信号输入端的乘数进行加法运算,直至所有乘数均完成加法运算;所有乘数均完成加法运算之后,第二加法器得到的高位宽乘数经第二选择器选择进入dsp;进入dsp的高位宽被乘数和高位宽乘数在dsp中进行乘法累加运算。
11.优选的,当并行度大于1时,进行移位操作时的移位数计算方法为:
12.设第一信号输入端的被乘数位宽为n1,经第三选择器进入第一加法器的乘数位宽为n2,第三信号输入端的乘数位宽为n3,经第四选择器进入第二加法器的乘数位宽为n4;n1和n3的移位数分别为x n4和y n2,其中x、y、n1、n2、n3和n4满足如下约束:
13.x y 2(n2 n4)≥max(n1 x n4 n2 n4,n3 y n2 n4 n2) 1
ꢀꢀꢀ
(1)。
14.优选的,在第一加法器得到的高位宽被乘数中的各被乘数之前插入冗余位宽。
15.优选的,冗余位宽的位数计算方法为:
16.设每个被乘数前插入冗余位宽的位数为q,则q的计算公式如式(6)
[0017][0018]
其中,m为dsp的最高位宽,d为并行度,mult1和mult2分别为第一加法器得到的高位宽被乘数和第二加法器得到的高位宽乘数的位宽。
[0019]
进一步的,并行度为2时,设第一信号输入端的被乘数位宽为n1,经第三选择器进入第一加法器的乘数位宽为n2,第三信号输入端的乘数位宽为n3,经第四选择器进入第二加法器的乘数位宽为n4;
[0020]
设冗余位宽可支持的最大累加次数为num_acc,计算公式如式(3),max_w1为高位部分积、中间部分积和低位部分积的最大位宽,计算公式如式(4),其中mp_w为中间部分积的位宽,计算公式如式(5);
[0021][0022]
max_w1=max(n1 n3,n2 n4,mp_w)
ꢀꢀꢀ
(4)
[0023]
mp_w=max(n1 n4 x n4 n2,n2 n3 y n2 n4) 1-min(x n2 n4,y n2 n4)
ꢀꢀꢀ
(5)
[0024]
其中,x、y、n1、n2、n3和n4满足如下约束:
[0025]
x y 2(n2 n4)≥max(n1 x n4 n2 n4,n3 y n2 n4 n2) 1
ꢀꢀꢀ
(1)。
[0026]
进一步的,并行度大于2时,将多组乘法先合并为两组乘法,然后利用处理并行度为2的方法计算最大累加次数。
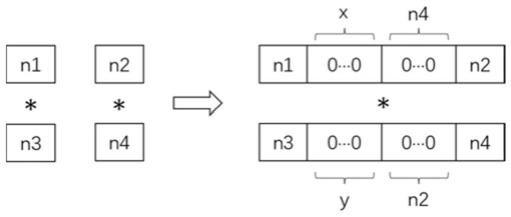
[0027]
优选的,当并行度大于1且为固定乘数时,第一信号输入端的被乘数在第一移位单元中进行移位操作,移位操作后进入第一加法器与第二信号输入端的被乘数进行加法运算,加法运算后得到的被乘数进入第三选择器,经第三选择器选择进入第一加法器,继续与移位操作后的第一信号输入端的被乘数进行加法运算,直至所有被乘数均完成加法运算;所有被乘数均完成加法运算之后,第一加法器得到的高位宽被乘数经第一选择器选择进入dsp;第三信号输入端的固定乘数直接经第二选择器选择进入dsp;进入dsp的高位宽被乘数和固定乘数在dsp中进行乘法累加运算。
[0028]
进一步的,移位操作具体是:在被乘数之后插入乘数位宽个0。
[0029]
进一步的,在第一加法器得到的高位宽被乘数中的各被乘数之前插入冗余位宽;设并行度为d,固定乘数位宽为n,冗余位宽能支持的最大累加次数num_acc的计算公式如式(9);其中max_w2表示被乘数中最大位宽与乘数位宽之和;q是每个被乘数前插入冗余位宽的位数,计算公式如式(10),其中ni表示被乘数位宽;
[0030][0031][0032]
一种基于dsp的混合位宽融合计算方法,基于所述的加速器,
[0033]
当并行度为1时,第一信号输入端的被乘数直接经第一选择器选择进入dsp,第三信号输入端的乘数直接经第二选择器选择进入dsp,被乘数和乘数在dsp中进行乘法累加运算;
[0034]
当并行度大于1时,第一信号输入端的被乘数在第一移位单元中进行移位操作,移位操作后进入第一加法器与第二信号输入端的被乘数进行加法运算,加法运算后得到的被乘数进入第三选择器,经第三选择器选择进入第一加法器,继续与移位操作后的第一信号输入端的被乘数进行加法运算,直至所有被乘数均完成加法运算;所有被乘数均完成加法运算之后,第一加法器得到的高位宽被乘数经第一选择器选择进入dsp;第三信号输入端的乘数在第二移位单元中进行移位操作,移位操作后进入第二加法器与第四信号输入端的乘数进行加法运算,加法运算后得到的乘数进入第四选择器,经第四选择器选择进入第二加法器,继续与移位操作后的第三信号输入端的乘数进行加法运算,直至所有乘数均完成加法运算;所有乘数均完成加法运算之后,第二加法器得到的高位宽乘数经第二选择器选择进入dsp;进入dsp的高位宽被乘数和高位宽乘数在dsp中进行乘法累加运算。
[0035]
与现有技术相比,本发明具有如下的有益效果:
[0036]
本发明是以dsp作为主要计算单元的混合位宽神经网络加速器,对乘数和被乘数分别连接,并分别进行移位即插入不同的隔离位宽,可以实现多组任意低位宽乘累加运算。本发明加速器支持任意乘法并行度,最大化dsp计算性能;支持任意位宽的乘数和被乘数,支持乘数固定和不固定两种情况,通用性更好,适用范围广。
附图说明
[0037]
图1为高位宽乘法器同时实现两个低位宽乘法方案;
[0038]
图2为高位宽乘法器同时实现两个低位宽乘法数据格式;
[0039]
图3为高位宽乘法同时实现三个低位宽乘法方案;(a)高位宽乘法同时实现三个低位宽乘法方案第一步;(b)高位宽乘法同时实现三个低位宽乘法方案第二步;
[0040]
图4为中间部分积位宽分析;
[0041]
图5为高位宽乘法实现两个同乘数乘法插值方案;
[0042]
图6为高位宽乘法实现三个同乘数乘法插值方案;
[0043]
图7为高位宽乘法实现三个同乘数乘法被乘数数据格式;
[0044]
图8为网络计算中的pe分配;
[0045]
图9为pe内部结构;
[0046]
图10为dsp内部结构。
具体实施方式
[0047]
为了进一步理解本发明,下面结合实施例对本发明进行描述,这些描述只是进一步解释本发明的特征和优点,并非用于限制本发明的权利要求。
[0048]
首先阐述高位宽dsp同时实现两个低位宽乘累加的方案,如图1所示。对于两组要进行的低位宽乘法,被乘数和乘数的位宽分别为n1和n3,n2和n4。两个被乘数和乘数通过移位拼接的方法组成两个高位宽数的乘法,拼接时的移位数分别为x n4和y n2。其中x,y,n1,n2,n3,n4需满足如下约束:
[0049]
x y 2(n2 n4)≥max(n1 x n4 n2 n4,n3 y n2 n4 n2) 1
ꢀꢀꢀ
(1)
[0050]
在此约束下,通过计算图1右半部分的高位宽数据乘,并在结果中分别取高(n1 n3)位和低(n2 n4)位的结果,即可同时得到图1左半部分两组低位宽数据的相乘结果(即n1*n3和n2*n4)。
[0051]
考虑到乘法之后的累加运算,为防止溢出,在图1右半部分的数据格式中,需要在每一个被乘数的左边计算数据和右边计算数据的前部分别插入多余的位宽。以插入2bit位宽为例,最终的数据格式如图2所示。
[0052]
设每个被乘数可以分配的最大冗余位宽为q,则q的计算公式如式(2)。其中m为dsp乘法器的最高位宽,d为并行度,即一个dsp同时做几组乘累加。
[0053][0054]
设冗余位宽可支持的最大累加次数为num_acc,计算公式如式(3),其中q为每个被乘数可以分配的最大冗余位宽,计算公式如式(2);max_w1为高位部分积、中间部分积和低位部分积的最大位宽,计算公式如式(4),其中mp_w为中间部分积的位宽,计算公式如式(5)。
[0055][0056]
max_w1=max(n1 n3,n2 n4,mp_w)
ꢀꢀꢀ
(4)
[0057]
mp_w=max(n1 n4 x n4 n2,n2 n3 y n2 n4) 1-min(x n2 n4,y n2 n4)
ꢀꢀꢀ
(5)
[0058]
接着考虑一个dsp同时实现更多个(大于2)乘累加运算的方案,如图3所示。对于三组要进行的低位宽乘法,被乘数和乘数的位宽分别为n1’,n2’和n3’,n4’,n5’和n6’。方案的
基本思路为将三组乘法先合并为两组乘法,然后利用处理两组乘法并行的方案依次处理。方案的第一步如图3(a)所示,首先将n1=n1’ n2’,n3=n4’ n5’,n2=n3’和n4=n6’各自代入公式(1),得到x1和y1大小;第二步中,将n1=n1’,n3=n4’,n2=n2’ x1 n6’ n3’,n4=n5’ y1 n6’ n3’各自代入公式(1),得到x2和y2大小,如图3(b)所示。
[0059]
划分后的乘法运算中被乘数包含5个部分,其中三个实际被乘数的前面需分别空出冗余位宽用于累加操作时防止溢出。计算冗余位宽和最大累加次数的方法可由前述并行度为2的方案类推得到。
[0060]
设插入最大冗余位宽的位数为q,则q的计算公式如式(6)。其中m为dsp乘法器最高位宽;d为并行度,即一个dsp同时做几组乘累加;mult1和mult2分别为移位拼接后的两个乘数的位宽,即
[0061]
mult1=n1’ n2’ n3’ x1 x2 n3’ n5’ n6’ y1 n6’[0062]
mult2=n4’ n5’ n6’ y1 y2 n2’ n3’ n6’ x1 n3’。
[0063][0064]
冗余位宽可支持的累加次数为num_acc,计算公式如式(3),其中q为每个被乘数可以分配的最大冗余位宽,计算公式如式(6);max_w1为高位部分积、中间部分积和低位部分积的最大位宽,计算公式如式(8),其中mp_w为中间部分积的位宽。此时并行度为3,因此mp_w应包含两部分计算。首先计算如图4灰色部分的部分积,绿色部分为两组乘法,按并行度为2分析即可。将n1=n2’,n2=n3’,n3=n5’,n4=n6’,x=x1,y=y1分别代入公式(5),得到mp_w1;再分析加入高位后的部分积,即将图4中绿色部分看作一组乘法,将n1’*n2’看作另一组乘法,则此时,仍按并行度为2分析即可。将n1=n1’,n2=n2’ x1 n6’ n3’,n3=n4’,n4=n5’ y1 n3’ n6’,x=x2,y=y2分别带入公式(5),得到mp_w2;则mp_w=max(mp_w1,mp_w2),代入公式(8)即可得到并行度为3时部分积的最大位宽max_w1;此时再将max_w1代入公式(7),即可得到最大累加次数。
[0065][0066]
max_w1=max(n1
′
n4
′
,n2
′
n5
′
,n3
′
n6
′
,mp_w)
ꢀꢀꢀ
(8)
[0067]
对于更高并行度的实现,首先根据图3,将数据合并后按并行度为2的情况分析,得到每个乘数拼接时的移位位宽;然后类推并行度为3的冗余位宽和最大累加次数分析方法,同样先将乘数依次合并降为并行度2的情况,并计算得到相应高并行度下冗余位宽的位数和最大累加次数。
[0068]
接着考虑多组乘法中一个乘数固定的情况,对应实际网络计算时的权值共享。对于并行两组乘法的情况,此时0值插入的方法如图5所示。两个位宽n1和n2的数乘以同一个位宽为n3的乘数,只需在n2前插入n3个0即可隔离;对于三组乘法并行的情况,插0值方法如图6所示,固定乘数位宽为n4,需在三个被乘数两两之间插入n4个0值;与此类似,对于更多组乘法并行的情况,只需在被乘数两两之间插入乘数位宽个0即可起到隔离效果。最后在各个被乘数前还需插入冗余位防止累加溢出,即可得到最终的数据格式,如图7所示,图中冗余位宽以2为例。
[0069]
一个乘数固定的情况下,设并行度为d,并行计算的固定乘数位宽为n,最大累加次数num_acc的计算公式如式(9)。其中max_w2表示被乘数中最大位宽与乘数位宽之和;q是每
个被乘数可以分配的最大冗余位宽,计算公式如式(10),其中ni表示被乘数位宽。
[0070][0071][0072]
当累加次数达到冗余位宽的极限时,需引入额外的dsp继续进行累加。引入的额外dsp数为d-1(d为并行度)。由此可计算dsp的加速比r,如式(11)。
[0073][0074]
本发明以xilinx 7系列fpga芯片作为平台,实现神经网络加速器。加速器的计算阵列主要包括8
×
9个pe(processing element),其中每个pe的计算功能基于xilinx 7系列芯片的dsp48e1实现,该类型dsp含有的乘法器位宽为25
×
18,累加器位宽为48。
[0075]
神经网络计算过程中的pe分配以图8所示为例。图中表示一层卷积的实现,特征图大小为80通道13
×
13,卷积核共64个,每个卷积核为80通道3
×
3大小。以共享权重的情况为例,每行pe计算卷积核的一个通道,则每个pe接收来自卷积核的一个元素,同时根据dsp设置的并行度d,接收来自特征图的d个值,图8所示是并行度为2的情况,每个pe同时接收来自特征图的两个值,相当于两步卷积同时在做。此时pe内部的数据流如图9。端口
①
输入共享权值,经过多选器sel1,输入到dsp端口b;特征图的两个值中一个值输入到端口
③
,另一个值输入到端口
④
,端口
③
的值经过移位后与端口
④
的值相加,得到拼接结果,拼接后的值经过多选器sel2,输入到dsp端口a,然后由dsp进行乘法运算。dsp的内部结构如图10所示,四个输入端口b、a、d、c位宽分别为18、30、25、48。对于并行度更高的情况,加法器一次拼接后的值经过选择器sel4输入到加法器一端,新的乘数从端口
③
经过移位后进入加法器的另一端,相加后得到二次拼接结果,依此方法,进行乘数的多次拼接,再输入到dsp的a端口,即可实现固定乘数的高并行度计算。对于非固定乘数的情况,只需要按此方法在图9的端口
①
和
②
以及
③
和
④
都进行乘数拼接,然后将拼接结果分别经过sel1和sel2,输入到dsp端口b和端口a,即可实现非固定乘数的高并行度乘法。
[0076]
基于上述并行计算方法,对于非固定乘数的情况,以被乘数、乘数位宽均为2为例:当并行度为2时,此时n1=n2=n3=n4=2,代入公式(1),取满足条件的x和y的最小值x=y=1;再代入公式(2)-(5),分别求得q=9,mp_w=5,max_w1=5,num_acc=528。将d=2,num_acc=528代入公式(11),求得此时的加速比为1.996;当并行度为3时,根据图3(a)的步骤,将n1=n3=4,n2=n4=2代入公式(1),取满足条件的x和y的最小值x1=y1=3;再进行图3(b)的步骤,发现n4’ n2’ n3’ n6’ x1 y1 n5’ n3’ n6’=20》18,超出了dsp的乘法器位宽,因此dsp48e1不能支持并行度为3的2bit乘法;
[0077]
以被乘数和乘数位宽均为1为例,当并行度为3时,根据图3(a)的步骤,将n1=n3=2,n2=n4=1代入公式(1),取满足条件的x和y的最小值,得到x1=y1=1;再进行图3(b)的步骤,将n1=n3=1,n2=n4=4代入公式(1),取满足条件的x和y的最小值,得到x2=y2=-3。说明此时插入的n2’ n3’ n6’ x1和n5’ n3’ n6’ y1(用于隔绝高位乘积,隔离出低位乘积不受影响)可以做到隔绝低位乘积,防止高位乘积受到低位乘积影响,因此取x2=y2=0即可(即,当根据式(1)计算出的x和y为负数时,两者取0即可)。再代入公式(6)-(8),分别求得q=5,mp_w1=3,mp_w2=6,max_w1=6,num_acc=32。将d=3,num_acc=32代入公式
(11),求得此时的加速比为2.824。
[0078]
对于固定乘数的情况,以乘数和被乘数均为4bit为例,支持并行度为2、3,加速比分别为1.969、1.5;对于乘数和被乘数均为3bit的情况,支持并行度为2、3、4,加速比分别为1.992、2.4、1.6;对于乘数和被乘数均为2bit的情况,支持并行度为2、3、4、5,加速比分别为1.996、2.833、2.286、1.667;对于乘数和被乘数均为1bit的情况,支持并行度为2、3、4、5、6、7、8,加速比分别为1.999、2.931、3.5、3.571、3、1.75、1.778。
[0079]
本发明与现有方法的对比,如表1。
[0080]
表1本发明与现有方法的对比
[0081]
方法并行度乘数位宽乘数限制xilinx int828固定一个乘数本发明任意任意任意乘数/固定乘数
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
