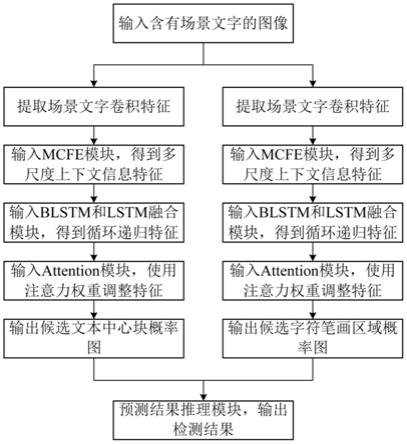
1.本发明涉及计算机分析领域,尤其涉及一种基于注意力机制的自然场景文字检测方法。
背景技术:
2.文字作为人类知识和信息的载体,广泛存在于现实日常生活场景中。提取镶嵌在场景图像中的文字信息,在许多基于图像内容信息的应用中是非常有价值和有益的,场景图像中的文字提取技术在盲人导航、盲人阅读、图像检索和标注,人机交互、无人驾驶等场景中应用前景广阔,场景文字检测是确定图像中文字的具体位置,文字识别是将边界框中的文字信息识别成刻度文字。而场景文字检测,在提取和理解场景图像中的文字信息时起着重要的作用,其性能直接决定了图像中文字识别的性能。场景文字检测与识别技术是将图像中的文字信息提取出来,以辅助或增强现实应用,已成为学术界和工业界一个富有挑战性的研究领域,引起国内外研究者的广泛关注。
3.近年来,随着通用目标检测和语义分割技术的快速发展,场景文字检测得到了广泛的研究。并取得了显著的成效。尽管许多性能优越的场景文字检测方法被提出,在一些具有挑战性的场景中,仍然难以实现场景文字的精确定位。场景文字检测的挑战主要来自三个方面:场景文字受噪声、模糊、遮挡、强光和低分辨率因素的影响;场景文字存在形式多样、高宽比变化大;场景文字具有不同的大小、颜色、字体、语种和风格。基于这三种原因,场景文字检测仍然是一个开放性问题。
4.目前主流的场景文字检测方法大致可以分为两类:基于通用目标包围盒回归的方法和基于语义分割的方法。在使用过程中发现现有技术中存在以下缺陷:
5.弯曲文本的方向不易回归:基于包装盒回归的场景文字检测方法在解决多方向场景文本示例方向时,需要对方向信息进行回归;然而对于任意形状的文本示例,比如弯曲形状,并不能对方向信息进行回归;
6.相近不同文本行间的粘连:基于语义分割的场景文字检测方法在解决任意形状、任意方向的场景文字问题时,已经取得了较好的性能;然而如果不同的文本行相离比较近时,容易造成文本行间的粘连;
7.多级特征整合产生信息冗余:基于语义分割的场景文字检测方法在预测文本区域信息时,利用了浅层和深层的多级特征;然而文本目标重要集中分布在深层特征中;另外在特征整合过程中,并没有考虑不同特征的重要性,
技术实现要素:
8.本发明的目的在于提供一种基于注意力机制的自然场景文字检测方法,从而解决现有技术中存在的前述问题。
9.为了实现上述目的,本发明采用的技术方案如下:
10.一种基于注意力机制的自然场景文字检测方法,包括以下步骤:
11.s1、搭建候选文本实例预测网络,在卷积特征提取网络中同时添加上下文特征提取模块、双向长短时记忆和特征融合模块以及基于注意力的特征整合模块构成对于自然场景文字特征提取的候选文本实例预测网络;
12.s2、获取场景文字图像,并将所述场景文字图像进行分类标签,获取场景文字图像数据集;所述场景文字图像数据集包括场景文字图像和对应的二值标签图像,所述二值标签图像包括文本中心块标签和字符笔画区域标签;
13.s3、通过步骤s1构建的所述候选文本实例预测网络对所述场景文字图像进行特征提取,具体包括以下步骤:
14.s301、通过卷积特征提取网络对所述场景文字图像进行特征提取,得到对应的场景文字图像的卷积特征图,选用vgg-16卷积网络的五个卷积阶段中的第三、第四和第五个卷积阶段对所述场景文字图像提取卷积特征图,标记为:f={f3,f4,f5},其中,f表示场景文字图像的卷积特征图集合;
15.s302、将所述卷积特征图输入至所述上下文特征提取模块中,得到相应的多尺度的上下文信息特征图,标记为f
‘
={f
′3,f
′4,f
′5};f
‘
表示所述多尺度的上下文信息特征图的集合,f
′i表示每一个卷积阶段的所述多尺度的上下文信息特征图的集合,其中i∈{3,4,5};
16.s303、对每一个卷积阶段中的所有所述多尺度的上下文信息特征图进行编码,并使用3*3的滑动窗在所述多尺度的上下文信息特征图上从左向右滑动,从而得到相应的特征序列集合,标记为征序列集合,标记为其中k∈{1,
…
,hi},t∈{1i,
…
,wi},c表示通道数,hi和wi是特征图f
′i的高和宽的位置序列,i∈{3,4,5},表示卷积阶段的序号,将所述特征序列集合si以向前和向后的次序输入至所述双向长短时记忆和特征融合模块中,得到每一个卷积阶段中所述多尺度的上下文信息特征图中每一个滑动窗的状态图中存在场景文字的概率图标记为:下文信息特征图中每一个滑动窗的状态图中存在场景文字的概率图标记为:其中d∈{0,1}表示每一个所述状态图中显示有场景文字的两种预测类别;
17.s304、根据所述状态图映射在预测类别(0,1)取值的概率分布,得到所述状态图中显示场景文字的权重图wm={w
conv33
,w
conv43
,w
conv53
},从而输出所述场景文字图像中每一个像素位置中显示有场景文字的概率图:像素位置中显示有场景文字的概率图:其中,σ[
·
]是一个激活函数,
⊙
表示元素相乘,w
l
、b
l
是显示场景文字的卷积层l∈l的权重和偏置,w
l
反应了在不同位置对特征图的关注程度。
[0018]
s4、对文本中心块模型和字符笔画区域模型进行训练,通过步骤s2中所述场景文字图像数据集的训练集中的文本中心块标签和对所述文本中心块模型进行训练至收敛,通过所述字符笔画区域标签对所述字符笔画区域模型进行训练至手链,并在所述训练集的基础上进行微调,生成所述文本中心模块和字符笔画区域模型;
[0019]
s5、通过所述文本中心模型和所述字符笔画区域模型对经过步骤s3处理后的待测的所述场景文字图像的测试图像f
out
进行计算,最终生成所述场景文字图像对应的文本中
心块的概率图和字符笔画区域的概率图;
[0020]
s6、通过所述文本中心块的面积限制对所述文本中心块进行判断,剔除虚假的候选文本中心块,最终得到所述场景文字图像中检测出的文字文本,并进行标记。
[0021]
优选的,上下文特征提取模块包括四个平行的空洞卷积层构成,其膨胀系数分别为1、3、5、7,卷积核大小为3
×
3,在所述在卷积特征提取网络中的每一个卷积层后均添加有所述上下文特征提取模块。
[0022]
优选的,所述双向长短时记忆和特征融合模块包括前向的lstm层、后向的lstm层和concat层,所述双向长短时记忆和特征融合模块中的特征提取步骤为:
[0023]
将特征序列s∈si输入到所述双向长短时记忆和特征融合模块中;对于特征序列分别使用一个前向和后向的lstm层计算隐藏层的状态序列,在每个时间步,将所有隐藏层的状态进行拼接,从而获得所有隐藏层的状态图其中其中b表示每一个特征图的隐藏层的状态图,i∈{3,4,5},表示卷积阶段的序号;再将所述隐藏层序列分别映射至对应的去卷积层中,并分别输出得到每一个卷积阶段中所述多尺度的上下文信息特征图中每一个滑动窗的状态图中存在场景文字的概率图,标记为:其中d∈{0,1}表示每一个所述状态图中显示有场景文字的两种预测类别;将md裁剪成为与输入的所述场景文字图像相同大小的特征图,标记为经过concat层进行拼接,输入到两个卷积层中,第一个卷积层含有512通道,卷积核的大小为3
×
3;第二个卷积层含有3个通道,卷积核大小为1
×
1。
[0024]
优选的,所述基于注意力的特征整合模块包括两个卷积层、一个softmax层、一个slice层和三个spatialproduct层;所述基于注意力的特征整合模块的执行步骤为:
[0025]
所述第二个卷积层的三个通道分别对应于特征图所述第二个卷积层的三个通道分别对应于特征图的注意力特征权重,在所述softmax层中,将所述特征图fc的权重映射到在(0,1)取值的概率分布,得到所述概率分布;在所述slice层中,将所述概率分布划分为权重图wm={w
conv33
,w
conv43
,w
conv53
};所述基于注意力的特征整合模块根据所述特征图fc的权重图,输出所述场景文字图像中每一个像素位置显示有场景文字的概率图f
out
。
[0026]
优选的,所述文本中心块的判断条件为:
[0027]smin
≤s
tcb
≤s
max
[0028]
其中s
min
和s
max
分别为所述文本中心块最小面积的阈值和最大面积的阈值,s
tcb
表示候选文本中心块的面积。
[0029]
优选的,步骤s6中对于检测出的文字文本的标记方式为:对于弯曲形状的文本,采用文本区域的轮廓对文本实例进行标记;对于直线形的文本,利用最小矩形对文本区域的轮廓进行拟合,采用矩形框对文本实例进行标记。
[0030]
优选的,步骤s4中所述文本中心模块和字符笔画区域模型的损失函数为l=-∑
i,jgij
log(p
ij
) (1-g
ij
)log(1-p
ij
),其中,g
ij
是像素在(i,j)处的标签,p
ij
表示(i,j)处的像素属于前景的概率。
[0031]
本发明的有益效果是:本发明公开了一种基于注意力机制的自然场景文字检测方法,基于vgg-16框架,加入上下文特征提取模块、双向长短时记忆和特征融合模块、基于注意力的特征整合模块,构造一个能够有效预测场景图像中文字区域的网络模型,以克服现有技术在场景文字检测中遇到的问题:弯曲文本的方向信息不易回归、相近不同文本行间的粘连和多级特征整合产生信息冗余。
附图说明
[0032]
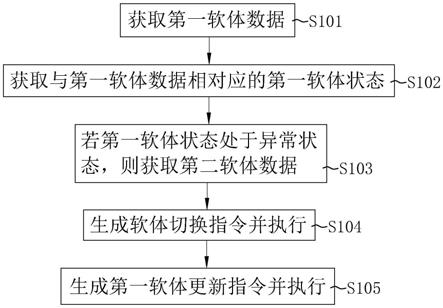
图1是基于注意力机制的自然场景文字检测方法的测试流程图;
[0033]
图2是上下文特征提取模块、双向长短时记忆和特征融合模块、基于注意力的特征整合模块三个模块对检测性能影响的对比图;
具体实施方式
[0034]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
[0035]
s1、搭建候选文本实例预测网络,在卷积特征提取网络中同时添加上下文特征提取模块、双向长短时记忆和特征融合模块以及基于注意力的特征整合模块构成对于自然场景文字特征提取的候选文本实例预测网络;
[0036]
卷积特征提取网络是基于vgg-16进行创建,删除vgg-16结构中最后一个池化层和三个全连接层,同时增加了三种模块:上下文特征提取模块、双向长短时记忆和特征融合模块、基于注意力的特征整合模块;其中,所述上下文特征提取模块包括四个平行的空洞卷积层构成,其膨胀系数分别为1、3、5、7,卷积核大小为3
×
3,在所述在卷积特征提取网络中的每一个卷积层后均添加有所述上下文特征提取模块;所述双向长短时记忆和特征融合模块包括前向的lstm层、后向的lstm层和concat层;所述基于注意力的特征整合模块包括两个卷积层、一个softmax层、一个slice层和三个spatialproduct层。
[0037]
s2、获取场景文字图像,并将所述场景文字图像进行分类标签,获取场景文字图像数据集;所述场景文字图像数据集包括场景文字图像和对应的二值标签图像,所述二值标签图像包括文本中心块标签和字符笔画区域标签;
[0038]
所述文本中心块标签的生成方法为采用代数方法,通过缩放因子直接计算获得所述数集中每个场景文字的坐标:假设场景文字图像数据集中每个实例多边形p含有2n个顶点,其中n≥2,假设是由一组顶点{p1,
…
,pn,p
′1,
…
,p
′n}表示,其中(pi,p
′i)称为一个点对,i∈{1,
…
,n};缩放后的多边形p
‘
仍然具有2n个顶点,使用一组顶点{p
01
,
…
,p
0n
,p
′
01
,
…
,p
′
0n
}表示。假设顶点pi、p
′i、p
0i
、p
′
0i
的坐标分别表示为:(xi,yi),(x
′i,y
′i),(x
0i
,y
0i
),(x
′
0i
,y
′
0i
)。给定(xi,yi),(x
′i,y
′i)和缩放因子λ0、x
0i
、y
0i
、x
′
0i
和y
′
0i
由下式计算:
[0039][0040]
所述字符笔画区域标签的生成方式为通过区域生长算法获得,并且对于具有简单
背景的场景图像文字,本发明选择较少的种子来生成笔画水平区域;对于具有复杂背景的场景图像文字,则需要选择较多的种子;对于具有复杂背景的场景文字,如果选择的种子数量超过10个,并且生成的区域不完美,在这种情况下,将丢弃已经选择的种子,更换其他种子来生成笔画水平区域,直至采用1~10个种子,可以完整生成具有场景图像文字的区域。
[0041]
s3、通过步骤s1构建的所述候选文本实例预测网络对所述场景文字图像进行特征提取,具体包括以下步骤:
[0042]
s301、通过卷积特征提取网络对所述场景文字图像进行特征提取,得到对应的场景文字图像的卷积特征图,选用vgg-16卷积网络的五个卷积阶段中的第三、第四和第五个卷积阶段对所述场景文字图像提取卷积特征图,标记为:f={f3,f4,f5},其中,f表示场景文字图像的卷积特征图集合;
[0043]
s302、将所述卷积特征图输入至所述上下文特征提取模块中,得到相应的多尺度的上下文信息特征图,标记为f
‘
={f
′3,f
′4,f
′5};f
‘
表示所述多尺度的上下文信息特征图的集合,f
′i表示每一个卷积阶段的所述多尺度的上下文信息特征图的集合,其中i∈{3,4,5};
[0044]
s303、对每一个卷积阶段中的所有所述多尺度的上下文信息特征图进行编码,并使用3*3的滑动窗在所述多尺度的上下文信息特征图上从左向右滑动,从而得到相应的特征序列集合,标记为征序列集合,标记为其中k∈{1,
…
,hi},t∈{1i,
…
,wi},c表示通道数,hi和wi是特征图f
′i的高和宽的位置序列,i∈{3,4,5},表示卷积阶段的序号,将特征序列s∈si输入到所述双向长短时记忆和特征融合模块中;对于特征序列分别使用一个前向和后向的lstm层计算隐藏层的状态序列,在每个时间步,将所有隐藏层的状态进行拼接,从而获得所有隐藏层的状态图其中其中b表示每一个特征图的隐藏层的状态图,i∈{3,4,5},表示卷积阶段的序号;再将所述隐藏层序列分别映射至对应的去卷积层中,并分别输出得到每一个卷积阶段中所述多尺度的上下文信息特征图中每一个滑动窗的状态图中存在场景文字的概率图,标记为:其中d∈{0,1}表示每一个所述状态图中显示有场景文字的两种预测类别;将md裁剪成为与输入的所述场景文字图像相同大小的特征图,标记为图,标记为经过concat层进行拼接,输入到两个卷积层中,第一个卷积层含有512通道,卷积核的大小为3
×
3;第二个卷积层含有3个通道,卷积核大小为1
×
1;
[0045]
s304、步骤s303中第二个卷积层的三个通道分别对应于特征图s304、步骤s303中第二个卷积层的三个通道分别对应于特征图的注意力特征权重,在所述softmax层中,将所述特征图fc的权重映射到在(0,1)取值的概率分布,得到所述概率分布;在所述slice层中,将所述概率分布划分为权重图wm={w
conv33
,w
conv43
,w
conv53
};所述基于注意力的特征整合模块根据
所述特征图fc的权重图,输出所述场景文字图像中每一个像素位置显示有场景文字的概率图图其中,σ[
·
]是一个激活函数,
⊙
表示元素相乘,w
l
、b
l
是显示场景文字的卷积层l∈l的权重和偏置,w
l
反应了在不同位置对特征图的关注程度。
[0046]
s4、对文本中心块模型和字符笔画区域模型进行训练,通过步骤s2中所述场景文字图像数据集的训练集中的文本中心块标签和对所述文本中心块模型进行训练至收敛,通过所述字符笔画区域标签对所述字符笔画区域模型进行训练至收敛,并在所述训练集的基础上进行微调,生成所述文本中心模块和字符笔画区域模型;
[0047]
所述文本中心模块和字符笔画区域模型的损失函数为l=-∑
i,jgij
log(p
ij
) (1-g
ij
)log(1-p
ij
),其中,g
ij
是像素在(i,j)处的标签,p
ij
表示(i,j)处的像素属于前景的概率;
[0048]
s5、通过所述文本中心模型和所述字符笔画区域模型对经过步骤s3处理后的待测的所述场景文字图像的测试图像f
out
进行计算,最终生成所述场景文字图像对应的文本中心块的概率图和字符笔画区域的概率图;
[0049]
将含有场景文字的测试图像f
out
分别输入到所述文本中心模型和所述字符笔画区域模型,生文本中心块的概率图(f
tcb
)和单词笔画区域的概率图(f
wsr
);
[0050]
s6、通过所述文本中心块的面积限制对所述文本中心块进行判断,提出虚假的候选文本中心块,最终得到所述场景文字图像中检测出的文字文本,并针对不同的文本对象采用不同的标注方式。
[0051]
所述文本中心块的判断条件为:
[0052]smin
≤s
tcb
≤s
max
[0053]
其中s
min
和s
max
分别为所述文本中心块最小面积的阈值和最大面积的阈值s
tcb
表示候选文本中心块的面积;
[0054]
在根据文本中心块的面积对候选文本中心块进行判断时s
min
和s
max
分别取211和81179,是因为99%的文本中心块面积大于等于211,而小于81179;最终筛选出的文本中心块和单词笔画区域实例进行标记;得到最后的文字区域,完成场景图像文字检测任务;并且对于检测出的文字文本的标记方式为:对于弯曲形状的文本,采用文本区域的轮廓对文本实例进行标记;对于直线形的文本,利用最小矩形对文本区域的轮廓进行拟合,采用矩形框对文本实例进行标记。
[0055]
实施例
[0056]
本实施例中进行了对比实验,从而验证实施例一所描述的场景文字检测方法的技术效果,实验环境和实验结果如下:
[0057]
(1)实验环境
[0058]
系统环境:ubuntu 16.04;
[0059]
硬件环境:gpu:gtx 1080ti,内存:512g。
[0060]
(2)实验数据集
[0061]
训练数据:首先,使用mlt2017的7200张训练数据进行对文本中心块模型预训练4
×
105次;然后,在total-test(1255张训练集)上对所述文本中心块模型和所述单词笔画区域模型进行微调4
×
105次。
[0062]
测试数据:total-test(300张测试集)。
[0063]
(3)评估方法
[0064]
弯曲形状文本:pascal评估方法。
[0065]
为展示本发明的有效性,采用相同的训练集分别设置了四组实验对模型进行训练,并在total-test数据集的测试集分别进行评估:
[0066]
第一组实验:使用“双向长短时记忆和特征融合模块”和“基于注意力的特征整合模块”两模块的组合进行训练,记为“双向长短时记忆和特征融合模块 基于注意力的特征整合模块”,使用双向长短时记忆和特征融合模块和基于注意力的特征整合模块两模块的组合来预测目标区域,验证上下文特征提取模块模块的有效性;
[0067]
第二组实验:使用“上下文特征提取模块”和“基于注意力的特征整合模块”两模块的组合进行训练,记为“上下文特征提取模块 基于注意力的特征整合模块”,使用上下文特征提取模块和基于注意力的特征整合模块两模块的组合来预测目标区域,验证双向长短时记忆和特征融合模块模块的有效性;
[0068]
第三组实验:使用“双向长短时记忆和特征融合模块”和“上下文特征提取模块”两模块的组合进行训练,记为“双向长短时记忆和特征融合模块 上下文特征提取模块”,使用上下文特征提取模块、双向长短时记忆和特征融合模块两模块的组合用来预测目标区域,验证基于注意力的特征整合模块的有效性;
[0069]
第四组实验:使用“双向长短时记忆和特征融合模块”、“上下文特征提取模块”和“基于注意力的特征整合模块”三模块的组合进行训练,记为双向长短时记忆和特征融合模块 上下文特征提取模块 基于注意力的特征整合模块”,使用上下文特征提取模块、双向长短时记忆和特征融合模块和基于注意力的特征整合模块三模块的组合来预测目标区域,作为对比组,验证三个模块的有效性;
[0070]
参数设置:tw和tb分别设置为0.55、0.60;
[0071]
上下文特征提取模块模块的有效性:为了获得多尺度的上下文信息,本发明设计了上下文特征提取模块;从图2可以看出“双向长短时记忆和特征融合模块 基于注意力的特征整合模块”的方法在没有使用上下文特征提取模块的情况下,f-measure降低了1.54%(76.99%vs.78.53%),precision降低了4.52%(74.39%vs.78.91%),但recall提高了1.63%(79.79%vs.78.16%)。
[0072]
双向长短时记忆和特征融合模块的有效性:为了利用文本对象(单词和文本行)中字符的空间序列特性,本发明设计了双向长短时记忆和特征融合模块模块。从图2可以看到“上下文特征提取模块 基于注意力的特征整合模块”的方法在没有使用双向长短时记忆和特征融合模块的情况下,f-measure降低了3.25%(75.28%vs.78.53%),precision降低了7.19%(71.72%vs.78.91%),但recall提高了1.06%(79.22%vs.78.16%)。
[0073]
基于注意力的特征整合模块的有效性:为了让训练的模型增强对场景图像中文本区域的关注,本发明设计了基于注意力的特征整合模块。从图2可以看到“上下文特征提取模块 双向长短时记忆和特征融合模块”的方法在没有使用基于注意力的特征整合模块的情况下,f-measure降低了0.71%(77.82%vs.78.53%),recall降低了1.94%(76.22%vs.78.16%),但precision提高了0.51%(79.48%vs.78.91%)。
[0074]
测试结果如图2所示,可以看出本发明所涉及的“上下文特征提取模块”、“双向长短时记忆和特征融合模块”和“基于注意力的特征整合模块”三个模块对检测性能的影响。
分别将第一组实验和第四组实验、第二组实验和第四组实验进行对比,发现“上下文特征提取模块”和“双向长短时记忆和特征融合模块”两模块均可以显著提高本发明方法的precision,但稍微会降低recall;将第三组实验和第四组实验进行对比,发现“基于注意力的特征整合模块”模块可以显著提高本发明方法的recall,但稍微会降低precision;同时,从对比实验的结果可以看出,“上下文特征提取模块”、“双向长短时记忆和特征融合模块”和“基于注意力的特征整合模块”三个模块在提高本发明方法的precision、recall和f-measure方面具有互补性。
[0075]
以上实施例仅用来说明本发明的技术方案而非对其进行限制,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质中例如:cd-rom,u盘,移动硬盘等,包括若干指令用以使得一台计算机设备,例如:个人计算机,服务器,或者网络设备等,执行本发明各个实施例所述的方法。
[0076]
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
[0077]
本发明公开了一种基于注意力机制的自然场景文字检测方法,基于vgg-16框架,加入上下文特征提取模块、双向长短时记忆和特征融合模块、基于注意力的特征整合模块,构造一个能够有效预测场景图像中文字区域的网络模型,以克服现有技术在场景文字检测中遇到的问题:弯曲文本的方向信息不易回归、相近不同文本行间的粘连和多级特征整合产生信息冗余。
[0078]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。