一种基于注意力机制与双向gru的谣言检测方法
技术领域
1.本发明涉及一种基于注意力机制与双向gru的谣言检测方法,属于网络内容侦测技术领域。
背景技术:
2.在高速发展的互联网时代,社交媒体会在各大网络社交平台上发布新闻消息,人民群众也在这些平台上获取相关资讯。同时随着社交平台的发展,网民们也可以在平台上面发表自己的意见,大家的交流也变得非常便捷。传统的报纸和杂志受限于便利性,谣言传播的速度并不快,而且传播的范围也一般限制在一个区域内。
3.随着智能手机的普及,网络社交平台非常易于访问,新闻资讯随时随地都可获得,导致其用户量也是越来越多。因此网络谣言传播的速度非常快,传播的范围也极其广泛,它会对社会造成巨大的伤害。目前辟谣滞后造成“空窗期”,期间谣言传播广泛快速,迫切需要基于人工智能的基础之上,尽早地识别网络社交平台上的谣言,避免网络谣言导致社会人民的恐慌,造成资源的浪费。
4.2017年,北京交通大学的解男男,王星等人提出了发明专利“一种基于深度学习的社交网络谣言检测方法”(cn107180077a)。其方法包括:收集社交网络数据作为样本数据;对样本数据进行标记和分词,构建词典和以样本词在词典中的数字编号为元素的固定长度的样本词向量;将样本数据中样本句包含的样本词数限定为固定值;采用word2vec方法构建样本句矩阵,样本句矩阵的行向量组为样本句中的所有样本词的样本词向量;采用深度学习方法lstm对样本句矩阵进行训练,构建多层次的训练模型;采用与构建样本句矩阵相同的方法构建待检测句矩阵;根据多层次的训练模型对待检测句矩阵进行分类检测,得到待检测社交网络数据的谣言检测结果。本发明可对社交网络谣言进行有效的检测。
5.2018年,四川大学的梁刚,许春等人提出了发明专利“一种基于深度信念网络的单分类微博谣言检测模型”(cn109597944a)。其方法包括下述具体步骤:进行关键用户节点选择,在微博中选择有影响力和有代表性的用户;数据的爬取及数据预处理;采用深度信念网络将预处理后的数据进行特征提取与降维;采用svdd算法进行谣言甄别;该模型基于关键用户的数据收集模式,并将深度信念网络微博谣言检测之中,通过深度信念网络的非线性变换与层层递进实现了特征提取与降维,采用单分类问题中的支持向量数据描述用于谣言的识别。
6.2019年,中国科学院信息工程研究所的黄琪,周川等人提出发明专利“基于用户关系结构特征的微博谣言检测方法和系统”(cn110362818a)。其方法包括以下步骤:根据用户行为信息构造用户关系结构图,对所述用户关系结构图进行建模得到用户向量;根据微博话题流数据的传播路径构造传播树,对所述传播树进行编码得到传播树向量;将所述用户向量和所述传播树向量进行级联,并输入神经网络来判断微博话题是否为谣言。该系统包括用户编码器、传播树编码器和集成器。本发明对谣言传播过程中参与的用户进行建模,得到微博数据流中所有用户的向量表示,在谣言检测过程中增加了有用的检测因素,即体现
了用户特征的作用,提高了谣言检测系统的正确率和f1值。
7.2020年,南京邮电大学的宋玉蓉和潘德宇提出发明专利“一种微博谣言检测方法”(cn111966786a)。其方法包含如下步骤:收集微博事件和相应评论数据集作为样本数据;对所述样本数据进行预处理,分别提取原微博与评论的文本内容;采用bert预训练模型对文本进行预训练,每句文本生成固定长度的句向量;构建字典,提取原微博与对应数条评论组成微博事件向量矩阵;采用深度学习方法text cnn-attention对向量矩阵进行训练,构建多层次训练模型;根据多层次训练模型对向量矩阵进行分类检测,得到对应社交网络数据的谣言检测结果。本发明较之传统谣言检测方法提高了准确率。
8.2020年,人民网股份有限公司的毛震东和张勇东等人提出发明专利“基于网络信息传播图建模的社交媒体谣言检测方法”(cn112199608a)。其方法包括:以用户的帖子为节点,根据帖子的转发层次关系和时间维度关系建立传播图模型,并且根据用户的id信息在传播图模型中构建相同用户的帖子连接关系;将预训练模型提取的各个帖子的文本特征作为初始的节点表示特征,并利用消息传递图神经网络根据帖子之间关系进行信息的聚合,进而更新节点表示特征;将更新后的节点表示特征与初始的节点表示特征连接后,通过分类器预测帖子为谣言与非谣言的概率。该方法能够提高谣言检测的准确性,实现有效的谣言检测,并具有适用性强,易于迁移等优点。
9.2020年,北京理工大学的施重阳和劳安提出发明专利“一种基于线性和非线性传播的谣言检测方法”(cn112256981a)。其方法利用文本内容和时间信息对谣言节点进行统一建模表示,将线性与非线性传播特性相结合的方式,自动进行谣言检测。首先,使用谣言节点中所包含的文本信息和时间信息对其混合特征进行联合表示。然后,分别沿线性时间序列和非线性扩散结构聚合节点信息,增强源节点的表达,形成最终的传播表示。最后,用传播表示进行真实性标签预测。本方法从两个不同的角度提取谣言的节点特征,不仅从非线性的扩散模式中获取树感知的表示,而且还从线性的时序相互作用中捕捉传播序列的特性,能够对谣言的真实性进行准确预测。
10.综上所述,现有谣言检测技术多是通过原话题和社交信息数据进行特征的构建,然而通过对社交评论信息进行后,原话题下的评论信息在特征构建的过程中会存在错误指向的嵌套评论问题,该问题会降低模型对网络谣言判别的准确率并提升误判率。
11.随着网络的高速发展,越来越多的网民参与到网络社交活动中,在各网络社交平台上,每条发布的新闻或消息都会有不少网友发表自己的评论。然而,由于评论的机制是用户可以对发布的原新闻或消息进行评论,也可以是对其他的用户发表的评论内容进行评论。在以往的研究中,对于此类文本特征处理的方法是直接把文本内容进行拼接,然后再转换为矩阵的形式输入相应的模型进行训练。对于原话题的评论反馈,并不是所有评论数据都会指向原发布的新闻或消息,其中有部分的评论指向的是其他用户的评论,也就是说该用户发布的评论反馈并不是面向原话题的。
12.通过对社交评论数据进行分析,发现在一条发布话题下搜集的社交评论可能会存在错误的指向性问题。比如某条社交评论,此处称为评论1,相对于该条数据来说是一条负面的评论,而另一条评论,此处称为评论2,该评论是针对评论1的一条正面评论,那么根据逻辑推理,评论2相对于该条数据来说是一条负向的社交评论,但是如果将此直接输入到训练集的话,神经网络模型没有人类的推理能力,将会把评论2识别成对该条数据来说是一条
正向的评论,所以这类数据会对模型的训练产生一定的影响,导致模型最后的判别有误差。
技术实现要素:
13.本发明所要解决的技术问题是提供一种基于注意力机制与双向gru的谣言检测方法,正确分析社交话题数据与社交评论数据之间的逻辑关系,设计社交谣言检测模型,实现高效谣言检测。
14.本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种基于注意力机制与双向gru的谣言检测方法,按如下步骤a至步骤e,获得社交谣言检测模型;然后按步骤i至步骤v,应用社交谣言检测模型,针对待分析话题评论平台实现谣言检测;步骤a. 收集预设数量、已知自身内容对应正面言论标签或负面言论标签的各个社交话题样本数据,以及该各社交话题样本数据下、已知自身内容对应正面言论标签或负面言论标签的各个社交评论样本数据,然后进入步骤b;步骤b. 分别针对各社交话题样本数据、以及该各社交话题样本数据下的各社交评论样本数据,获取样本数据所对应的数据id、回复对象的数据id,构成样本数据所对应的特征组;进而获得各社交话题样本数据分别所对应的特征组,以及该各社交话题样本数据下各社交评论样本数据分别所对应的特征组,然后进入步骤c;步骤c. 根据各社交话题样本数据分别所对应的特征组,以及该各社交话题样本数据下各社交评论样本数据分别所对应的特征组,结合各社交话题样本数据自身内容对应的正面言论标签或负面言论标签,以及该各社交话题样本数据下各社交评论样本数据自身内容分别对应的正面言论标签或负面言论标签,确定各社交话题样本数据下各社交评论样本数据的指向关系,进而确定各社交话题样本数据下各社交评论样本数据分别所表达含义对应的正面言论标签或负面言论标签,然后进入步骤d;步骤d. 获得各社交话题样本数据自身内容分别对应的情感极性,并根据各社交话题样本数据下各社交评论样本数据的指向关系,获得各社交话题样本数据下各社交评论样本数据分别所表达含义对应的情感极性,然后进入步骤e;步骤e. 基于各社交话题样本数据、以及该各社交话题样本数据下的各社交评论样本数据,以社交话题样本数据自身内容对应的情感极性、结合该社交话题样本数据下各社交评论样本数据分别所表达含义对应的情感极性为输入,该社交话题样本数据自身内容对应的正面言论标签或负面言论标签、结合该社交话题样本数据下各社交评论样本数据分别所表达含义对应的正面言论标签或负面言论标签为输出,针对预设分类模型进行训练,获得社交谣言检测模型;步骤i. 收集待分析话题评论平台中、包含待分析社交话题数据与待分析社交评论数据的各个待分析社交数据,然后进入步骤ii;步骤ii. 分别针对各个待分析社交数据,获取待分析社交数据所对应的数据id、回复对象的数据id,构成待分析社交数据所对应的特征组,进而获得各待分析社交数据分别所对应的特征组,然后进入步骤iii;步骤iii. 根据各待分析社交数据分别所对应的特征组,区分各待分析社交话题数据与各待分析社交评论数据,并确定各待分析社交话题数据下的各待分析社交评论数据、以及各待分析社交评论数据的指向关系,然后进入步骤iv;
步骤iv. 根据各待分析社交话题数据下的各待分析社交评论数据、以及各待分析社交评论数据的指向关系,获得各待分析社交话题数据自身内容分别对应的情感极性,以及该各待分析社交话题数据下各待分析社交评论数据分别所表达含义对应的情感极性,然后进入步骤v;步骤v. 根据各待分析社交话题数据自身内容分别对应的情感极性,以及该各待分析社交话题数据下各待分析社交评论数据分别所表达含义对应的情感极性,应用社交谣言检测模型,获得各待分析社交话题数据自身内容分别对应的正面言论标签或负面言论标签、以及该各待分析社交话题数据下各待分析社交评论数据分别所表达含义对应的正面言论标签或负面言论标签,针对待分析话题评论平台实现谣言检测。
15.作为本发明的一种优选技术方案:所述步骤b中,分别针对各个样本数据,获取样本数据所对应的数据自身内容、数据id、发表数据的用户id、发表数据的时间、发表数据的次数、回复对象的数据id、回复对象的用户id,构成样本数据所对应的特征组;所述步骤ii中,分别针对各个待分析社交数据,获取待分析社交数据所对应的数据自身内容、数据id、发表数据的用户id、发表数据的时间、发表数据的次数、回复对象的数据id、回复对象的用户id,构成待分析社交数据所对应的特征组。
16.作为本发明的一种优选技术方案:所述步骤c中,分别针对各社交话题样本数据,执行如下步骤c1至步骤c2,确定各社交话题样本数据下各社交评论样本数据的指向关系,进而确定各社交话题样本数据下各社交评论样本数据分别所表达含义对应的正面言论标签或负面言论标签,然后进入步骤d;步骤c1. 分别针对社交话题样本数据下各个社交评论样本数据,判断社交评论样本数据所对应特征组中回复对象的数据id是否为其他社交评论样本数据的数据id,是则将该社交评论样本数据划分至该其他社交评论样本数据所对应的集合中;否则将该社交评论样本数据划分至该社交话题样本数据所对应的集合中;待完成对该社交话题样本数据下各社交评论样本数据的上述划分,即获得该社交话题样本数据下各社交评论样本数据的指向关系,然后进入步骤c2;步骤c2. 根据该社交话题样本数据自身内容所对应的正面言论标签或负面言论标签、以及该社交话题样本数据下各社交评论样本数据自身内容分别所对应的正面言论标签或负面言论标签,结合该社交话题样本数据下各社交评论样本数据的指向关系,确定该社交话题样本数据下各社交评论样本数据分别所表达含义对应的正面言论标签或负面言论标签。
17.作为本发明的一种优选技术方案:所述步骤iii包括如下步骤iii-1至步骤iii-2;步骤iii-1. 根据各待分析社交数据分别所对应的特征组,分别针对各个待分析社交数据,判断待分析社交数据所对应特征组中回复对象的数据id是否为空,是则判定该待分析社交数据为待分析社交话题数据,否则判定该待分析社交数据为待分析社交评论数据;待完成对各待分析社交数据的上述判定,即区分各待分析社交话题数据与各待分析社交评论数据,然后进入步骤iii-2;步骤iii-2. 分别针对各个待分析社交评论数据,若待分析社交评论数据所对应特征组中回复对象的数据id为其他待分析社交评论数据的数据id,则将该待分析社交评论数据划分至该其他待分析社交评论数据所对应的集合中;若待分析社交评论数据所对应特
征组中回复对象的数据id为待分析社交话题数据的数据id,则将该待分析社交评论数据划分至该待分析社交话题数据所对应的集合中;待完成对各待分析社交评论数据的上述划分,即确定各待分析社交话题数据下的各待分析社交评论数据、以及各待分析社交评论数据的指向关系。
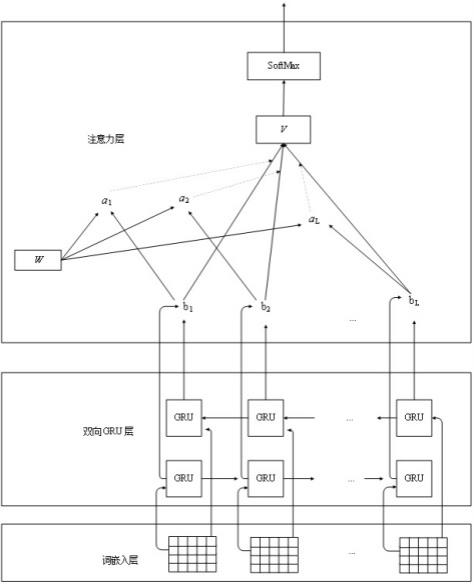
18.作为本发明的一种优选技术方案:所述步骤e中的预设分类模型自输入端至输出端依次包括词嵌入层、双向gru层、注意力层、softmax层,其中,词嵌入层中各节点的输入端构成预设分类模型的各输入端,词嵌入层中各节点的输入端分别用于接收社交话题数据自身内容分别对应的情感极性,以及该社交话题数据下各社交评论数据分别所表达含义对应的情感极性;双向gru层中各方向上gru模块数量彼此相等,且其中一方向的各gru模块与另一方向的各gru模块彼此一一对应,词嵌入层中节点的数量与双向gru层各方向上gru模块数量相等,且词嵌入层中各节点的输出端分别一一对接双向gru层其中一方向的各gru模块,以及双向gru层另一方向的对应gru模块;双向gru层另一方向的各gru模块的输出端分别对接注意力层的输入端,注意力层的各输出端对接softmax层的各输入端,softmax层的输出端构成预设分类模型的输出端,用于输出社交话题数据自身内容对应的正面言论标签或负面言论标签、以及该社交话题数据下各社交评论数据分别所表达含义对应的正面言论标签或负面言论标签。
19.本发明所述一种基于注意力机制与双向gru的谣言检测方法,采用以上技术方案与现有技术相比,具有以下技术效果:本发明所设计基于注意力机制与双向gru的谣言检测方法,设计通过嵌套社交评论分离、重指向、以及评论样本筛选方法,解决数据之间的误指向问题,减少错误评论指向问题带来的噪声,基于各社交话题样本数据下各社交评论样本数据间的正确指向关系,确定各社交话题样本数据下各社交评论样本数据分别所表达含义对应的言论标签,并结合各社交样本数据的情感极性,构建社交谣言检测模型,实现谣言检测,且在实际应用当中,能够有效提升谣言检测的准确率、查准率、召回率和值指标。
附图说明
20.图1是微博数据集嵌套评论数占比情况分析示意图;图2是twitter数据集嵌套评论数占比情况分析示意图;图3是本发明设计中社交谣言检测模型的框架;图4是本发明设计对数据进行优化后根据模型训练日志绘制的损失曲线图和准确率曲线图。
具体实施方式
21.下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。
22.本发明所设计一种基于注意力机制与双向gru的谣言检测方法,实际应用当中,首先按如下步骤a至步骤e,获得社交谣言检测模型。
23.步骤a. 收集预设数量、已知自身内容对应正面言论标签或负面言论标签的各个社交话题样本数据,以及该各社交话题样本数据下、已知自身内容对应正面言论标签或负
面言论标签的各个社交评论样本数据,然后进入步骤b。
24.步骤b. 分别针对各社交话题样本数据、以及该各社交话题样本数据下的各社交评论样本数据,获取样本数据所对应的数据自身内容、数据id、发表数据的用户id、发表数据的时间、发表数据的次数、回复对象的数据id、回复对象的用户id,构成样本数据所对应的特征组;进而获得各社交话题样本数据分别所对应的特征组,以及该各社交话题样本数据下各社交评论样本数据分别所对应的特征组,然后进入步骤c。
25.实际实施应用中,数据诸如来自微博数据和twitter数据,对于数据所对应特征组的获得,即如下表1表示关于twitter数据的特征组、以及表2表示关于微博数据的特征组。
26.表1表示关于twitter数据的特征组;表2表示关于微博数据的特征组;步骤c. 根据各社交话题样本数据分别所对应的特征组,以及该各社交话题样本数据下各社交评论样本数据分别所对应的特征组,结合各社交话题样本数据自身内容对应的正面言论标签或负面言论标签,以及该各社交话题样本数据下各社交评论样本数据自身内容分别对应的正面言论标签或负面言论标签,确定各社交话题样本数据下各社交评论样本数据的指向关系,进而确定各社交话题样本数据下各社交评论样本数据分别所表达含义
对应的正面言论标签或负面言论标签,然后进入步骤d。
27.上述步骤c在实际应用中,分别针对各社交话题样本数据,具体执行如下步骤c1至步骤c2,确定各社交话题样本数据下各社交评论样本数据的指向关系,进而确定各社交话题样本数据下各社交评论样本数据分别所表达含义对应的正面言论标签或负面言论标签,然后进入步骤d。
28.步骤c1. 分别针对社交话题样本数据下各个社交评论样本数据,判断社交评论样本数据所对应特征组中回复对象的数据id是否为其他社交评论样本数据的数据id,是则将该社交评论样本数据划分至该其他社交评论样本数据所对应的集合中;否则将该社交评论样本数据划分至该社交话题样本数据所对应的集合中;待完成对该社交话题样本数据下各社交评论样本数据的上述划分,即获得该社交话题样本数据下各社交评论样本数据的指向关系,然后进入步骤c2。
29.步骤c2. 根据该社交话题样本数据自身内容所对应的正面言论标签或负面言论标签、以及该社交话题样本数据下各社交评论样本数据自身内容分别所对应的正面言论标签或负面言论标签,结合该社交话题样本数据下各社交评论样本数据的指向关系,确定该社交话题样本数据下各社交评论样本数据分别所表达含义对应的正面言论标签或负面言论标签。
30.具体代码诸如如下设计:通过借助情感极性来代表评论的支持度,提出通过情感分析模型对原话题以及每条社交评论进行情感分析,并根据情感极性分析结果以及该条记录的标签对社交评论进行一定的筛选。每条社交评论不仅依赖于自己对父评论的情感极性,还依赖于父评论对该原话题的情感极性。通过父评论对原话题主体的情感极性以及自己本身相对于父评论的情感极性来推断出该社交评论对于该原话题的情感极性是正向还是负向。
31.步骤d. 获得各社交话题样本数据自身内容分别对应的情感极性,并根据各社交
话题样本数据下各社交评论样本数据的指向关系,获得各社交话题样本数据下各社交评论样本数据分别所表达含义对应的情感极性,然后进入步骤e。
32.实际应用中,这里关于情感极性的具体代码实施如下:步骤e. 基于各社交话题样本数据、以及该各社交话题样本数据下的各社交评论样本数据,以社交话题样本数据自身内容对应的情感极性、结合该社交话题样本数据下各社交评论样本数据分别所表达含义对应的情感极性为输入,该社交话题样本数据自身内容对应的正面言论标签或负面言论标签、结合该社交话题样本数据下各社交评论样本数据分别所表达含义对应的正面言论标签或负面言论标签为输出,针对预设分类模型进行训练,获得社交谣言检测模型。
33.对于网络社交平台发表的话题,包括其下的网友评论,通常包含成百上千个词语,热点的话题则会更多,而其中就会有许多与检测分类任务无关的词语,它们会对模型的分类性能产生一定的影响。因此,提出了结合注意力机制的文本分类方法。在基于双向gru模型的基础上,能考虑不同词语对于模型分类贡献度的大小,提供了更加丰富的文本表征;单向gru模型是根据前面的信息来推出后面的信息,但是有时候只看前面的词是不够的,而双向gru模型能了解到上下文的信息,更有利于增强模型的理解能力。
34.实际应用中,如图3所示,所设计社交谣言检测模型基于双向gru,其原理与lstm类似,依赖于历史信息,在现时间点做出相应的预测,而且也是基于门的机制。lstm的门机制主要通过输入门,遗忘门和输出门来对记忆单元的信息进行控制,来解决信息的长依赖问题。而gru模型对lstm中门机制的结构做了一定的改进,相对lstm来说结构上更为简洁。
35.具体如图3所示,预设分类模型自输入端至输出端依次包括词嵌入层、双向gru层、注意力层、softmax层,其中,词嵌入层中各节点的输入端构成预设分类模型的各输入端,词嵌入层中各节点的输入端分别用于接收社交话题数据自身内容分别对应的情感极性,以及
该社交话题数据下各社交评论数据分别所表达含义对应的情感极性。
36.双向gru层中各方向上gru模块数量彼此相等,且其中一方向的各gru模块与另一方向的各gru模块彼此一一对应,词嵌入层中节点的数量与双向gru层各方向上gru模块数量相等,且词嵌入层中各节点的输出端分别一一对接双向gru层其中一方向的各gru模块,以及双向gru层另一方向的对应gru模块。
37.双向gru层另一方向的各gru模块的输出端分别对接注意力层的输入端,注意力层的各输出端对接softmax层的各输入端,softmax层的输出端构成预设分类模型的输出端,用于输出社交话题数据自身内容对应的正面言论标签或负面言论标签、以及该社交话题数据下各社交评论数据分别所表达含义对应的正面言论标签或负面言论标签。
38.具体来说,gru有两个门,一个是重置门(reset gate),另一个是更新门(update gate)。在第个时间步,更新门的计算方式见公式1所示。
39.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)其中为第个时间步输入的向量,它会经过一个线性变换,保存的是前一个时间步的信息,同样也经过一个线性变换。将以上经过变化后信息相加,并输入到激活函数当中,最后结果将变换到0和1之间。这可以决定继续往下传递的历史信息的比例,从过去复制信息来减少梯度消失的风险。
40.在第个时间步,重置门的计算方式见公式2。
41.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)重置门的计算方式与更新门一样,只不过线性变换用的参数有所改变,重置门可以计算非重点信息的比例,然后将这些信息过滤掉。
42.在第个时间步,候选隐藏层的计算方式见公式3所示。
43.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)候选隐藏层可以理解为当前的记忆内容。最后控制隐藏层里被过滤的信息比例,然后与现时刻的隐藏层信息相加,得到最后输出的隐藏层的信息,也是当前时间步的最终记忆,其计算方式见公式4。
44.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)模型借助注意力机制把更多的资源分配给文本序列上下文中相对重要的信息,而其它的资源则以更低的比例进行分配。在某些特殊的情况下,甚至会直接将与模型判别无关的信息进行丢弃,这就能在一定程度上解决信息过多导致模型无法全部接收的问题,提高模型判别的效率。
45.随着注意力机制的发展,根据不同的场景其计算方式也会有不同的设计,使用的是softattention,首先 计算方式见公式5所示。
46.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)得分依赖于decoder端时刻的前一个时刻的隐状态和encoder端时刻的
隐状态,其计算方式见公式6所示。
47.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)衡量输出单词和输入单词的对齐程度,计算方式见公式7所示。
48.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)而是时刻所有 encoder 的隐状态基于该对齐程度得到的上下文向量,是所有对齐情况下的期望。注意力机制使得只需要关注原句子部分的信息,而不是像此前非要将原句子所有的信息都集中在一起,然后进行统一的编码,转换为特定的特征向量输入到模型中训练。注意力机制能够更好地提取样本中重要的特征,它能根据句子中各个部分的关键信息分配对应的权重,根据权重决定每个部分的保留比例。
49.在通过上述设计步骤获得社交谣言检测模型后,继续按步骤i至步骤v,应用社交谣言检测模型,针对待分析话题评论平台实现谣言检测。
50.步骤i. 收集待分析话题评论平台中、包含待分析社交话题数据与待分析社交评论数据的各个待分析社交数据,然后进入步骤ii。
51.步骤ii. 分别针对各个待分析社交数据,获取待分析社交数据所对应的数据自身内容、数据id、发表数据的用户id、发表数据的时间、发表数据的次数、回复对象的数据id、回复对象的用户id,构成待分析社交数据所对应的特征组,进而获得各待分析社交数据分别所对应的特征组,然后进入步骤iii。
52.步骤iii. 根据各待分析社交数据分别所对应的特征组,区分各待分析社交话题数据与各待分析社交评论数据,并确定各待分析社交话题数据下的各待分析社交评论数据、以及各待分析社交评论数据的指向关系,然后进入步骤iv。
53.实际应用当中,上述步骤iii具体执行如下步骤iii-1至步骤iii-2。
54.步骤iii-1. 根据各待分析社交数据分别所对应的特征组,分别针对各个待分析社交数据,判断待分析社交数据所对应特征组中回复对象的数据id是否为空,是则判定该待分析社交数据为待分析社交话题数据,否则判定该待分析社交数据为待分析社交评论数据;待完成对各待分析社交数据的上述判定,即区分各待分析社交话题数据与各待分析社交评论数据,然后进入步骤iii-2。
55.步骤iii-2. 分别针对各个待分析社交评论数据,若待分析社交评论数据所对应特征组中回复对象的数据id为其他待分析社交评论数据的数据id,则将该待分析社交评论数据划分至该其他待分析社交评论数据所对应的集合中;若待分析社交评论数据所对应特征组中回复对象的数据id为待分析社交话题数据的数据id,则将该待分析社交评论数据划分至该待分析社交话题数据所对应的集合中;待完成对各待分析社交评论数据的上述划分,即确定各待分析社交话题数据下的各待分析社交评论数据、以及各待分析社交评论数据的指向关系。
56.步骤iv. 根据各待分析社交话题数据下的各待分析社交评论数据、以及各待分析社交评论数据的指向关系,获得各待分析社交话题数据自身内容分别对应的情感极性,以及该各待分析社交话题数据下各待分析社交评论数据分别所表达含义对应的情感极性,然
后进入步骤v。
57.步骤v. 根据各待分析社交话题数据自身内容分别对应的情感极性,以及该各待分析社交话题数据下各待分析社交评论数据分别所表达含义对应的情感极性,应用社交谣言检测模型,获得各待分析社交话题数据自身内容分别对应的正面言论标签或负面言论标签、以及该各待分析社交话题数据下各待分析社交评论数据分别所表达含义对应的正面言论标签或负面言论标签,针对待分析话题评论平台实现谣言检测。
58.将上述设计应用于实际当中关于微博中文数据与twitter英文数据的分析,诸如收集微博中文数据的数量是28213条,twitter英文数据的数量是16263条,经过分析,首先对微博数据集和twitter数据集中话题数据的嵌套社交评论占比情况进行分析,进一步明确数据集中存在的大量嵌套评论,这样的评论如果不进行处理会导致指向性的问题。接着针对此问题,提出嵌套评论分离和重定向算法,使得每个评论都分到对应的回复对象的用户id的集合中;最后通过对错误指向的嵌套评论进行过滤,在一定程度上对样本进行修正。
59.基于上述所收集数据进行嵌套评论数占比情况的分析,即分析平均每条数据附带的嵌套评论数相对于该条数据附带的总评论数的占比情况,其中,微博数据集的分析情况见图1所示,在标签为谣言的数据集中,网民的交流互动情况有所增加,而非谣言的数据集中,嵌套评论的占比也不低。所以,对于评论的分离以及子评论的重定向是非常有必要的,否则会对模型的判别产生一定的误差。
60.twitter数据集的分析情况见图2所示,twitter数据为英文数据集,从统计结果上看,嵌套评论数相对单条数据总评论数平均占比情况与微博中文数据集相差不大。
61.经过本发明设计方案的具体实施,获得获得社交谣言检测模型针对待分析话题评论平台进行谣言检测过程中,所使用的服务器硬件环境为显卡gtx1080ti双卡,22g显存,cpu 2.6ghz,16线程数,32g内存容量,240g硬盘容量,操作系统为ubuntu16.04。实验将数据集分成三个部分,分别是占比为60%的训练集、20%的测试集和20%的验证集。
62.实验中模型的超参数见表3所示,词嵌入维度为300,batch size大小为50,迭代次数为50k,学习率为0.0015,使用的优化器为adam,dropout比例为0.5,最大序列长度为256,time range参数为该条数据中的评论的时间跨度范围,设置为120小时,即保留的是从该条话题发布起的5天内的社交评论。损失函数使用的是交叉熵损失函数,计算方式见公式8所示。
63.ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)基于twitter英文数据集,经过提出的嵌套评论优化方法前后对比实验结果见表3所示。
64.表3表示经过提出的嵌套评论优化方法前后对比实验结果;由表4实验结果可知,在经过新的方法的优化后,模型在网络谣言检测任务中的准确率、查准率、召回率和值指标都有所提升。其中模型判别的准确率在优化后提升了
2.4%。这表明嵌套社交评论分离和重指向、以及评论样本筛选方法,能够在一定的程度上避免样本的误指向,构建更好的文本特征,减少因为错误的评论指向问题带来的噪声。模型在进行训练的时候能够更加稳定,从而在网络谣言检测任务的测试时能给模型带来进一步的提升。
65.基于微博中文数据集,并且经过提出的嵌套评论优化方法处理前后,对比实验结果见表4所示。从实验结果可以看到,在优化后模型判别的准确率提升了1.8%,并且其它的评估指标也有所提升。
66.表4表示经过提出的嵌套评论优化方法处理前后对比实验结果;并且如图4所示,对数据进行优化后,根据模型训练日志所绘制的损失曲线图和准确率曲线图,可以看到,对于twitter数据集,模型在训练迭代次数超过30k左右就开始收敛。而对于微博数据集,训练迭代次数在25k左右时,模型开始收敛,而且也表明使用新的方法对文本特征进行优化后,模型对网络谣言检测的判别达到了比较高的准确率。
67.实际应用中,采用多个不同的模型进行实验,测试网络谣言检测分类的效果,包括rnn,cnn,lstm,gru,双向lstm,双向gru和提出的基于注意力机制的双向gru模型。实验的主要目的为了测试提出的模型相对于其它模型在网络谣言检测中的性能,以及研究卷积神经网络相对于循环神经网络在网络谣言检测的数据集中的表现,其中,在twitter英文数据集上,其实验结果见表5所示。
68.表5表示在twitter英文数据集上,其实验结果;从实验结果来看,注意力机制的确能够增强模型对文本特征的理解能力,一定程度上提升模型的性能,提高判别的准确率。而双向gru模型在与时间强相关的数据集上,能够保留一定的长距离信息,在网络社交评论中学习到更多的语义信息。实验结果表明基于注意力机制的双向gru模型在网络谣言检测任务上能发挥比较好的效果。
69.并且在微博中文数据集上,其实验结果见表6所示。
70.表6表示在微博中文数据集上,其实验结果;
从表5和表6的实验结果可以看出,循环神经网络在网络谣言检测的数据集中的表现比较好。在测试的准确率、查准度、召回率和的指标中都要比卷积神经网络要高,这也说明网络谣言检测的数据集是与时间强相关的数据,基于循环神经网络的模型对网络谣言的检测更为准确。
71.上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。