1.本发明涉及一种基于双向长短时记忆神经网络的托卡马克放电建模系统,尤其是基于双向长短时记忆神经网络的特征从两端计算当前时间点的值,旨在利用该系统提前预演托卡马克放电建模的提案为后续放电实验提供参考和辅助托卡马克实验数据分析,属于机器学习和核聚变物理领域。
背景技术:
2.利用核聚变能是人类最终解决能源问题的一种非常重要的途径。现阶段人类除地热能和裂变能外所利用的能量最终来源几乎都是来自于太阳核聚变反应所产生的能量。核聚变的主要原料是海水中的氘而聚变产物则是惰性元素氦。核聚变没有原料和核废料问题。人类一旦掌握了受控核聚变技术,将可能一劳永逸的解决能源问题。
3.核聚变能工作系统,有几种不同类型的研究装置,托卡马克装置是其中之一。托卡马克是一个利用磁约束来实现磁约束聚变的环性容器。达到稳定的等离子体均衡需要围绕环面移动的螺旋形状的磁力线。并且是用于生产受控热核核聚变能中的一个最深入研究的候选类型且被认为最可能实现可控核聚变反应的装置。普通的中小型托卡马克放电实验是利用氘,氦等离子体来模拟氘氚等离子放电过程,主要的目的用来研究如何有效的进行长时间的高能量的等离子约束。
4.检索现有专利发现几乎没有用于托卡马克全过程放电的专利,现有的文献是由大多使用集成建模方法和少量使用仅基于前向信息的机器学习模型进行全过程的托卡马克放电研究构成的。
5.集成建模方法的托卡马克全过程放电是利用物理驱动的方法来进行研究的,集成模拟方法需要集成尽可能多的物理过程,即粒子输运、平衡、边界物理,加热等。集成建模的准确性根据第一性原理来说主要是取决于所涉及物理过程完整性和合理性。在过去几十年中开发了很多基于物理模型的集成建模模型,由于物理模型的通常要进行复杂的多网格偏微分方程的数值求解所以计算效率比较低,难以进行并行化加速,更加上托卡马克系统具有非线性,多尺度,多物理的特性。仅从“第一性原理”出发对整个托卡马克放电过程长时间尺度的高保真快速放电建模还是一个科学挑战。仅基于前向信息加模拟结果的机器学习托卡马克放电建模模型又不考虑放电建模实际是一个离线的过程并且上下文信息已知的事实,而且需要引入模拟结果,所以建模精度较低,速度较慢。长时间的整个托卡马克放电过程的高保真的快速建模仍然是一个科学挑战。
技术实现要素:
6.本发明为了克服现有的全过程托卡马克放电建模结果不准确,建模时间长,无法对长时间尺度的全过程放电进行建模等缺陷,提供了基于双向长短时记忆神经网络的托卡马克放电建模系统,利用放电建模任务上下文信息在建模前已知的特点结合双向长短时记忆神经网络。完成了长时间尺度全过程高保真的托卡马克放电建模。
7.本发明解决其技术问题所采用的技术方案:一种基于双向长短时记忆神经网络的托卡马克放电建模系统,其特点在于:由多个不同模块所组成,所述的不同模块指的是低耦合的功能分割,所述多个不同模块至少包括:数据转存模块、batch数据访问输入模块、训练自定义参数模块、数据可视化模块、双向长短时记忆(lstm)神经网络的建模模块;其中:
8.数据转存模块:从mdsplus数据库中不经过server层直接映射至hdf5格式的数据,此过程需要重写server层驱动直接访问mdsplus数据库的对应原始数据并且计算metadata存储至mongodb中;
9.batch数据访问输入模块:将数据转存模块中的hdf5格式的数据转换成神经网络能够接受的输入数据,同时进行分桶(bucketing)操作和并行化的batch数据输入;
10.训练自定义参数模块:根据需要训练模型的建模参数调用双向长短时记忆神经网络建模模块定制参数;调用数据转存模块生成所需要的数据;利用batch数据访问输入模块输入数据到机器学习模型中;训练自定义参数的双向长短时神经网络的机器学习模型;
11.数据可视化模块:数据可视化模块可视化的自定义参数模型训练过程和已训练好的模型的建模结果。
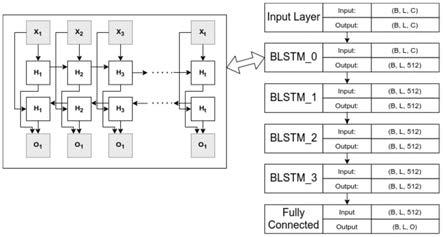
12.双向长短时记忆(lstm)神经网络的建模模块:为六个神经网络层的叠加,分别是一个输入层,四个双向长短时记忆神经网络层和一个全连接层,构成托卡马克放电建模工作的主体,利用该模型来建模托卡马克全过程放电系统。
13.双向长短时记忆(lstm)神经网络的建模模块,采用六个神经网络层的叠加,分别是输入层,四个双向长短时记忆神经网络层和一个全连接层,该建模模块是整个托卡马克放电建模系统的核心模块,该模块的主要创新点在在于引入了托卡马克放电实验提案阶段的上下文(contextual)信息,并进行端对端(end-to-end)的模型训练和推理,相对于已有的“集成建模”工作而言,该系统的构建直接从实验数据中抽取出执行器信号和诊断信号映射关系,而不用从“第一性原理”出发集成多个物理过程如堆芯输运,托卡马克平衡,稳定性,边界物理,加热,加料,燃烧和电流驱动等推导出映射关系;基于“第一性原理”模型的准确性和可靠性取决于包含的物理过程的完整性。在过去的几十年中,复杂的物理模块已经被开发了并集成于集成建模之中,用以获得更加贴近实际的建模结果。托卡马克放电建模的典型工作流是使用很多复杂的模块,然后利用这些复杂的模块集成许多物理过程。而且由于物理模型的通常要进行复杂的多网格偏微分方程的数值求解所以计算效率比较低,难以进行并行化加速,更加上托卡马克系统具有非线性,多尺度,多物理的特性。仅从“第一性原理”出发整个托卡马克放电过程长时间尺度的高保真快速放电建模还是一个科学挑战。本发明所提出的模型从实验数据提取的映射关系则规避了复杂的物理概念理解并且可以使用gpu进行数据的并行化加速所以可以快速和准确的进行建模。相对于已有机器学习的托卡马克建模本发明的系统仅利用了托卡马克放电实验提案的上下文信息和可直接构建的执行器数据而不是执行器信号的前向信息加部分模拟结果进行建模。本发明的系统同时从前向和后向基于执行器信号建模托卡马克诊断信号当前时间的实验数据。所以相对速度较快,结果也会更加准确。此建模模块是训练自定义参数模块的后端模型同时也是该放电建模系统的核心模块,可以产生可供数据可视化模块可视化的建模数据。
14.所述数据转存模块直接的将mdsplus数据库的原始数据转存至hdf5格式的文件中,同时计算metadata存储至mongodb中。
15.利用双向长短时记忆神经网络进行托卡马克全过程放电建模,该模型的主要特征是四个长短时记忆神经网络的堆叠。其中双向长短时记忆网络是重点。双向长短时记忆神经网络有效的利用了托卡马克放电实验提案的上下文信息,从前后两端综合计算当前时刻的建模数据,已有的托卡马克放电建模的机器学习模型,仅利用了前向信息,已有的基于“第一性原理”的模型需要进行复杂的模型推导和演化。该双向长短时神经网络模型直接从实验数据端到端的快速提取托卡马克执行器信号和诊断信号的映射关系。所以该模型相对于其他模型的速度更快效率更高而且也更加准确。
16.所述双向长短时记忆(lstm)神经网络的建模模块具体为:
17.输入层:作为整个网络的起点,双向将65道输入的时间序列信号转化为输入的张量而后将输入张量分配到gpu上进行计算;
18.四个双向长短时记忆层:承接来自于输入层的输出数据;
19.第一个双向lstm层首先将输入的65维的时间序列数据经过一个双向lstm的权重计算而后扩展成512维的输出数据;
20.第二到第四双向lstm层:在进行权重计算,利用上下文信息推测当前的建模的结果;
21.输出层:将四个堆叠的双向lstm的输出,转换成目标信号所对应的输出维度大小。
22.本模型的架构相对于物理模型和已有的托卡马克放电建模均有较大的不同,即利用了放电建模的上下文信息,同时也不需要进行基于“第一性原理”的模型理解和推导。
23.所述batch数据访问输入模块中数据分桶和多进程的batch数据并行数据输入。
24.所述自定义的参数训练模块可以根据需求自定义模型训练的参数:
25.a)保存默认参数和接受用户输入(修改)参数,参数包括模型的堆叠方式,大小和输入输出数据,同时该操作会调用数据转存模块对转存的数据进行修改,会对缺失的数据进行增补;
26.b)使用用户设置的参数进行双向神经网络的模型训练,根据这些参数,调用batch数据输入模块产生数据输入到双向长短时记忆神经网络中进行训练;
27.c)生成模型训练的可视化中间数据,调用可视化模型进行模型训练过程,损失函数、准确率、模型结构等的可视化。
28.本发明的实现步骤如下:
29.(1)使用基于双向长短时记忆神经网络的机器学习模型进行的基于上下文信息的托卡马克放电建模工作;
30.(2)该系统有数据转存模块、batch数据访问输入模块、训练自定义参数模块、数据可视化模块、双向长短时记忆(lstm)神经网络的建模模块组成。
31.(3)该系统可以进行自定义参数的模型端对端的训练。
32.(4)该系统模型的训练过程和建模结果都可以由可视化模块给出可视化的结果。
33.(5)该系统利用batch数据访问输入模块,进行分桶操作和并行化的batch输入。
34.(6)该系统可以自动化的将托卡马克mdsplus数据库原始数据文件和相应的metadata转换成可以进行高io的hdf5和mongodb构成的自定义数据库中。
35.基于双向长短时记忆神经网络的托卡马克放电建模系统,是利用数据驱动的建模方法。综合五个建模模块:分别是数据转存模块,batch数据访问输入模块,训练自定义参数
模块,数据可视化模块以及双向长短时记忆(lstm)神经网络的建模模块,构建了基于双向lstm神经网络的托卡马克全过程放电建模系统。
36.本发明与现有技术相比的有益效果在于:本发明的双向长短时神经网络的托卡马克放电建模系统,采用了双向长短时记忆神经网络的方法,利用托卡马克放电提案阶段的上下文信息,有效的消除了仅基于前向信息的机器学习模型建模不够准确的缺陷,分别提高了5%和1%的托卡马克环电压vloop和电子密度ne平均相似度同时该模型不引入模拟结果,也不使用自适应采样所以建模速度较快。同时该模型仅直接从实验数据中提取输入数据和诊断数据的映射关系,克服了基于“第一性原理”的托卡马克模拟系统无法进行长时间尺度的,准确的全过程放电建模的缺陷。
附图说明
37.图1为本发明的总体建模架构图;
38.图2为本发明的机器学习模型架构图;
39.图3为本发明的具体实施用例图;
40.图4为本发明和已有文献中仅利用前向信息的建模结果对比。
具体实施方式
41.下面结合附图和实施用例对本发明进一步说明。
42.如图1所示,从下至上分别是建模模块,数据转存模块,batch数据输入模块,训练自定义的参数模型模块。
43.数据转存模块:构建托卡马克原始mdsplus数据库原始数据数据文件不经过server层和hdf5数据文件的直接映射。其中主要有以下四个功能:1.mdsplus数据库原始数据的读取。2.利用参考信号的斜率和实际放电信号的滤波斜率识别平顶段长度。3.转换数据至hdf5格式,此时同步进行数据填充,对齐,筛选等操作。4.分布式计算并存储metadata至mongodb数据库中。
44.batch数据输入模块:该模块有两个分支,分别是多进程的数据处理和分桶的数据生成。将数据按照放电时间和显存容量利用自定义的分割算法分成不同的桶(bucket),而后根据显存容量和gpu数量产生对应批次大小的炮号序列。而后利用多进程池根据炮号序列产生对应的batch序列输入。
45.训练自定义参数模块:提供二次开发接口,屏蔽模型开发细节定制化的开发不同的参数模型训练。主要的过程是:1.检查是否如果是否满足训练条件并调用数据转存模块生成缺少的数据,2.训练模块自动调用batch数据输入模块进行自动训练,3.生成可视化模块所需的训练过程数据,调用可视化模块进行训练过程可视化。
46.数据可视化模块:该模块有两个分支,分别是调用tensorboard的可视化训练自定义参数模块的模型训练和对于双向lstm神经网络建模模块的建模结果和基于python语言matplotlib包提供的可视化建模结果。
47.图2中的右边是双向长短时记忆(bilstm)神经网络的建模模块网络的主要组成部分由六个主要的顺序连接层组成:一个输入层,四个双向长短时记忆层,以及一个全连接层。
48.输入层(input layer):作为整个网络的起点,将65道输入的时间序列信号转化为输入的张量而后将输入张量分配到gpu上进行计算。其中图中b代表输入批次的大小,l代表输入序列的长度,c代表输入序列一共有多少道(特征数量)。
49.四个双向长短时记忆层(blstm_0
–
blstm_3):承接来自于输入层的输出数据。
50.第一双向lstm层首先将输入的65维的时间序列数据利用一个双向lstm的权重计算并扩展成512维的输出数据。
51.第二到第四双向lstm层:在进行权重计算,利用上下文信息推测当前的建模的结果。
52.每一个lstm层都等价于图2左子图中的结构,该结构主要是由两个基本的lstm层叠加,分别从前向和后向两个方向计算当前时刻的输出,该结构相对于其他结构而言可以利用离线托卡马克放电建模中上下文信息已知的特点。
53.输出层(fully connected):将四个堆叠的双向lstm层的输出,转换成目标信号所对应的输出维度大小。图中“o”代表输出的信号维度。
54.该模块可以是训练自定义参数模块的训练过程的后端训练模块同时也是该放电建模系统的核心模块可以产生数据供数据可视化模块可视化建模数据。
55.文件交换:
56.系统中各个模块之间使用不同的文件的交换格式,数据转存模块将mdsplus原始tree层级结构的原始数据数据转换成hdf5格式的文件,并保存至自定义的数据库中。其中原始数据的转换过程是利用多进程的socket池进行操作。batch数据输入,提取hdf5数据加载至内存中,并读取mongodb中存储的metadata并且将数据转换到合适的参数范围输入至建模模型或者是训练模型中。可视化模块是直接读取磁盘上的文件,对于建模模型是读取磁盘上的tensorboard的log文件用以实现训练过程的可视化;对于模型结果的可视化则是读取磁盘上的建模结果文件,这个文件会直接的附加在原始的hdf5文件中。
57.系统的运行流程:
58.本系统的数据流主要分成两个部分即数据训练部分和建模部分。数据训练部分的运行流程分成以下几步:1.数据转存模块利用原始数据生成hdf5和mongodb构成的自定义数据库中。2.batch模块读取数据产生批tensor的输入数据,同时产生批tensor的标签数据。3.模型读取批tensor的输入数据和批tensor的标签数据训练自定义的参数模型。4.可视化模块读取训练过程中产生的log数据,画出可视化的训练过程图形。数据建模部分:1.读取hdf5数据库中对应的放电参数或者人工设置具体的放电参数。2.产生tensor输入数据。3.读取输入数据进行建模。4.可视化模块读取建模结果,并且可视化该结果。其中建模模块可以被自定义参数训练模块调用用以测试训练后模型的效果。
59.【实施例1】
60.可视化的建模结果,首先选择了81440炮作为测试数据,具体过程为1.设置放电参数,本例直接用81440的主动控制数据作为设置的参数。2.调用batch输入模块将列表型的数据转换至tensor类型的输入数据。3.将输入数据输入到对应的模型中得到建模的结果。
61.可视化的建模结果。选择east托卡马克放电炮#81440作为测试数据,具体过程为1.调用数据转换模块将mdsplus中原始的数据库文件中对应炮的数据转换成hdf5格式。2.设置执行器参数,本例直接使用#81440炮的执行器数据作为手工设置的输入数据。3.调用
batch数据访问输入模块访问已转换hdf5数据和对应的mongodb数据库中的metadata将数据转换至对应分布的tensor类型的输入数据。4.将batch数据访问输入模块的数据输入到双向长短时记忆神经网络的建模模块中得到建模的结果。5.调用可视化模块可视化对应的建模结果,结果如图3所示,该系统可以同时对11个托卡马克诊断信号进行建模分别是:实际的等离子电流i
p
,托卡马克磁轴等离子体平均电子密度ne,等离子体储能w
mhd
,托卡马克环电压v
loop
,托卡马克归一化磁比压βn,环向磁比压β
t
,极向磁比压β
p
,拉长比κ,内感li,安全因子q0,在95%通量面上的安全因子q
95
。
62.如图4所示在中国east托卡马克装置中2016-2018的实验数据中选择了696炮作为测试集,对比了利用上下文信息的本发明和已有的文献中基于前向信息,使用自适应采样且引入了物理模型结果的机器学习模型的结果。本发明在不使用物理模型和自适应采样的前提下对于v
loop
和ne分别提高了~5%和~1%。说明本发明的建模结果更加准确可靠。
63.本发明相对于物理“集成建模”而言,建模速度块,建模结果更加准确,而且可以对于长时间尺度的全过程托卡马克放电演化进行高保真的建模。相对于已有文献所提出基于前向神经网络的建模,因为本发明考虑了上下文信息而不仅仅是前向信息,勿须引入物理建模的结果,也不需要进行自适应采样,所以本发明的结果更加准确可靠,而且实用性更强。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
