1.本发明涉及一种面向视频会议的文本区域修复系统和方法,属于信息技术领域,特别是属于视频会议技术领域。
背景技术:
2.目前视频会议发展迅猛,会议主持人常常使用共享桌面展示ppt、文档等文本图像内容,但当参会人处于电梯、火车等网络状况不好的时候或者带宽受限、网络丢包率较大的时候,参会人看到的常常是模糊不清的文本图像。
3.图像超分辩率(简称超分)技术常常可以有效的解决图像修复问题,模糊的图像经过超分辨率网络可以大大提高图像的质量。但是目前深度学习领域常见的图像超分辩网络将文本图像视为普通的图像,没有考虑文本图像的特定属性,例如文本级布局和文字级细节,所以修复的图像常常会出文字边缘模糊,图像过度平滑的现象。并且在视频会议场景下,共享ppt或者生成的图像常常又是包含文字外的其他图像,但是人们更多关注文本区域是否清晰可识别而不是背景。如何对视频会议场景下模糊的文本图像进行修复成为当前视频会议技术领域急需解决的一个技术难题。
技术实现要素:
4.有鉴于此,本发明的目的是发明一种系统和方法,实现对视频会议场景下模糊文本图像的修复,以达到提高视频会议场景下文本图像阅读性的目的。
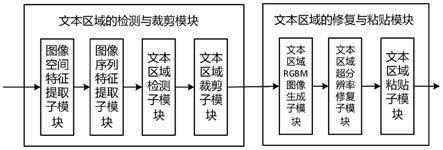
5.为了达到上述目的,本发明提出了一种面向视频会议的文本区域修复系统,所述系统包括如下模块:
6.文本区域的检测与裁剪模块:该模块的功能是首先对视频会议场景下的图像进行预处理,然后检测该图像的文本区域,得到文本区域检测框的四角顶点坐标,最后按照所得到的四角顶点坐标将文本区域剪裁出来;
7.文本区域的修复与粘贴模块:该模块的功能是首先生成所述文本区域的二进制掩码,该二进制掩码与所述的文本区域进行连接,得到所述文本区域的rgbm图像;对所得到的rgbm图像进行超分辨率修复,得到修复后的清晰的文本区域;把所得到的清晰的文本区域粘贴回原视频会议场景下的图像。
8.所述的文本区域的检测与裁剪模块包括如下子模块:
9.图像空间特征提取子模块:该子模块的功能是通过深度学习网络提取视频会议场景下的图像的空间特征;具体过程是:采用resnet网络对视频会议场景下的图像进行深层次的空间特征提取,得到第五个卷积block的第三层卷积特征图conv5_3和第四个卷积block的第三个卷积层特征图conv4_3,再将所得到特征图conv5_3经过反卷积和特征图conv4_3进行融合,得到所述会议场景下的图像的空间特征图,该空间特征图大小是w*h*c,w表示空间特征图的宽,h表示空间特征图的高,c表示空间特征图的特征通道数;
10.图像序列特征提取子模块:该子模块的功能是通过深度学习网络提取视频会议场
景下的图像的序列特征;具体过程是:使用3*3的卷积核对前述得到的空间特征图进行卷积操作,步长为16,然后将卷积操作后所获得的结果排列为3*3*c的特征向量;将该特征向量输入到bilstm网络中,经过最后的全连接层得到512维的所述会议场景下的图像的序列特征图;
11.文本区域检测子模块:该子模块的功能是通过深度学习网络提取视频会议场景下的图像的文本区域检测框的四角顶点坐标;具体过程是:将前述得到的会议场景下的图像的序列特征图输入到rpn网络,得到文本建议text proposal,然后采用文本线构造法连接成一个文本区域检测框,最后输出所检测到的文本区域检测框的四角顶点坐标;
12.文本区域裁剪子模块:该子模块的功能是根据前述所得到的文本区域检测框的四角顶点坐标,把文本区域从所述的视频会议场景下的图像中剪裁出来。
13.所述的文本区域的修复与粘贴模块包括如下子模块:
14.文本区域rgbm图像生成子模块:该子模块的功能是将所裁剪出来的文本区域生成该文本区域的rgbm图像;具体过程是:将所裁剪出来的文本区域图像的r、g、b三个通道进行加权平均,得到每个像素点对应的灰度值,灰度值采用二进制8位表示,灰度值从0到255总计256个灰度值,对应黑色到白色;然后对所有像素点的灰度值求平均值,将其作为一个标准值;依次对每个像素点的灰度值和标准值进行比较,如果大于标准值,将该点的灰度值置为0,如果小于标准值,将灰度值置为255,从而生成所述文本区域图像的二进制掩码;将文本区域图像与所述的二进制掩码连接生成所述文本区域的rgbm图像;
15.文本区域超分辨率修复子模块:该子模块的功能是根据所述的文本区域rgbm图像,通过深度学习网络对文本区域进行超分辨率修复;
16.文本区域粘贴子模块:该子模块的功能是将修复后的文本区域按照文本区域检测框的四角顶点坐标,粘贴回原视频会议场景下的图像中。
17.所述的文本区域超分辨率修复子模块进一步包括如下子模块:
18.信息提取和增强子模块:该子模块的功能是通过深度学习网络分层提取所述文本区域rgbm图像的低频特征信息,最后得到该图像的空间特征和序列特征;该子模块第一层是卷积层,后面由八个相同的网络块顺序连接而成,每个网络块由残差网络单元和bilstm单元顺序连接构成;
19.重建子模块:该子模块的功能是通过亚像素卷积,集成所述文本区域rgbm图像的全局特征和局部特征,将低频特征信息转换为高频特征信息;
20.信息细化子模块:该子模块的功能是细化所述重建子模块得到的高频特征信息,以得到文本区域的更加精确的超分辨率修复图像。
21.所述的残差网络单元的具体结构为:为了消除冗余信息,减少参数数量、计算量和内存消耗,每个残差网络单元中采用异构架构;具体为第1、3、6、9、12、15、18、21和24层采用3*3conv relu结构,第2、5、8、11、14、17、20和23层采用1*1conv relu结构;其中第1层的尺寸大小是3*3*3*64,即输入通道数为3,卷积核的大小是3*3,输出通道数是64,第3、6、9、12、15、18、21和24层的尺寸大小是64*3*3*64,即输入通道数为64,卷积核的大小是3*3,输出通道数是64;
22.卷积层的输出公式如下:
[0023][0024]
其中,表示第i层卷积的输出,oi表示第i层的输出,c3表示3*3的卷积函数,c1表示1*1的卷积函数;
[0025]
每一层的输出公式如下:
[0026][0027]
其中,r代表激活函数relu;
[0028]
所述的重建子模块由亚像素卷积层构成,所述的亚像素卷积层的组成为conv shuffle*2,卷积核大小为3*3,输入和输出通道都是64;所述的亚像素卷积层将所述文本区域rgbm图像超分为2倍大小;为了解决长期依赖问题,所述亚像素卷积层分别将所述残差网络单元的第1层和第24层的输出作为全局特征和局部特征分别进行上采样,然后进行融合,再将融合结果经过relu函数转换为非线性的;
[0029]
所述的信息细化子模块的具体结构为:由4层conv relu和1层conv构成,其中conv relu卷积层的卷积核尺寸大小为3*3,输入通道数和输出通道数都为64;最后1层conv的卷积核尺寸大小为3*3,输入通道数是64,输出通道数是3。
[0030]
先使用像素损失函数l1对所述的文本区域的修复与粘贴模块进行训练,训练完成设定的批次epoch后,再使用感知损失函数l
text
对所述的文本区域的修复与粘贴模块进行训练,完成设定的批次epoch;
[0031]
其中像素损失函数l1定义如下:
[0032][0033]
上式中,是指训练集中高分辨率文本区域图像;i是指训练集中把与所述高分辨率文本区域图像所对应的低分辨率文本区域图像,输入到所述的文本区域超分辨率修复子模块,所得到的超分辨率修复后的文本区域图像;训练集中所述高分辨率文本区域图像和低分辨率文本区域图像是一一对应的图像对,所述低分辨率文本区域图像由对应的高分辨率文本区域图像经过下采样处理得到;
[0034]
其中感知损失函数l
text
定义如下:
[0035][0036]
上式中,表示所述训练集中高分辨率图像经过vgg网络第j个卷积层后得到的特征图,表示所述超分辨率修复后的文本区域图像i经过vgg网络第j个卷积层后得到的特征图,c
jhj
wj表示vgg网络第j卷积层后的特征图的尺寸大小。
[0037]
本发明还提出了一种面向视频会议的文本区域修复方法,所述方法包括下列操作步骤:
[0038]
(1)对视频会议场景下的图像进行预处理,检测该图像的文本区域,得到文本区域检测框的四角顶点坐标,按照所得到的四角顶点坐标将文本区域剪裁出来;
[0039]
(2)生成所述文本区域的二进制掩码,将该二进制掩码与所述的文本区域进行连接,得到所述文本区域的rgbm图像;对所得到的rgbm图像进行超分辨率修复,得到修复后的清晰的文本区域;把所得到的清晰的文本区域粘贴回原视频会议场景下的图像。
[0040]
本发明的有益效果在于通过融合不同层的空间特征,使得文本检测的准确率更高;通过加入bilstm网络对文本的序列特征进行提取,进一步提高修复的准确性,使得文本图像更加清晰可读;使用像素损失函数和文本感知损失函数共同训练系统,克服了传统文本图像修复中出现过度平滑纹理的缺点,增加更多的高频细节,对视频会议场景下文本图像的阅读性有了很大提升。
附图说明
[0041]
图1是本发明提出的一种面向视频会议的文本区域修复系统的结构图。
[0042]
图2是本发明的实施例中的文本区域超分辨率修复子模块的结构示意图。
[0043]
图3是本发明的实施例中的信息提取和增强子模块的结构示意图。
[0044]
图4是本发明提出的一种面向视频会议的文本区域修复方法的流程图。
[0045]
图5是本发明的实施例中一幅视频会议场景下的模糊图像。
[0046]
图6是本发明的实施例中对图5进行文本区域检测后的结果图。
[0047]
图7是本发明的实施例中从图5所裁剪出来的文本区域结果图。
[0048]
图8是本发明的实施例中对图7进行超分辨率修复后的结果图。
[0049]
图9是本发明的实施例中将图8粘贴回图5后的结果图。
具体实施方式
[0050]
为使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步的详细描述。
[0051]
参见图1,介绍本发明所提出的一种面向视频会议的文本区域修复系统,所述系统包括如下模块:
[0052]
文本区域的检测与裁剪模块:该模块的功能是首先对视频会议场景下的图像进行预处理,然后检测该图像的文本区域,得到文本区域检测框的四角顶点坐标,最后按照所得到的四角顶点坐标将文本区域剪裁出来;
[0053]
文本区域的修复与粘贴模块:该模块的功能是首先生成所述文本区域的二进制掩码,该二进制掩码与所述的文本区域进行连接,得到所述文本区域的rgbm图像;对所得到的rgbm图像进行超分辨率修复,得到修复后的清晰的文本区域;把所得到的清晰的文本区域粘贴回原视频会议场景下的图像。
[0054]
所述的文本区域的检测与裁剪模块包括如下子模块:
[0055]
图像空间特征提取子模块:该子模块的功能是通过深度学习网络提取视频会议场景下的图像的空间特征;具体过程是:采用resnet网络对视频会议场景下的图像进行深层次的空间特征提取,得到第五个卷积block的第三层卷积特征图conv5_3和第四个卷积block的第三个卷积层特征图conv4_3,再将所得到特征图conv5_3经过反卷积和特征图
conv4_3进行融合,得到所述会议场景下的图像的空间特征图,该空间特征图大小是w*h*c,w表示空间特征图的宽,h表示空间特征图的高,c表示空间特征图的特征通道数;
[0056]
关于resnet网络,详细信息参见文献:he k,zhang x,ren s,et al.deep residual learning for image recognition[c],proceedings of the ieee conference on computer vision and pattern recognition.2016:770-778.
[0057]
图像序列特征提取子模块:该子模块的功能是通过深度学习网络提取视频会议场景下的图像的序列特征;具体过程是:使用3*3的卷积核对前述得到的空间特征图进行卷积操作,步长为16,然后将卷积操作后所获得的结果排列为3*3*c的特征向量;将该特征向量输入到bilstm(bi-directional long short-term memory)网络中,经过最后的全连接层得到512维的所述会议场景下的图像的序列特征图;
[0058]
文本区域检测子模块:该子模块的功能是通过深度学习网络提取视频会议场景下的图像的文本区域检测框的四角顶点坐标;具体过程是:将前述得到的会议场景下的图像的序列特征图输入到rpn网络,得到文本建议text proposal,然后采用文本线构造法连接成一个文本区域检测框,最后输出所检测到的文本区域检测框的四角顶点坐标;
[0059]
关于rpn网络的详细信息参见文献:ren s,he k,girshick r,et al.faster r-cnn:towards real-time object detection with regionproposal networks[j].advances in neural information processing systems,2015,28:91-99.
[0060]
文本区域裁剪子模块:该子模块的功能是根据前述所得到的文本区域检测框的四角顶点坐标,把文本区域从所述的视频会议场景下的图像中剪裁出来。
[0061]
所述的文本区域的修复与粘贴模块包括如下子模块:
[0062]
文本区域rgbm图像生成子模块:该子模块的功能是将所裁剪出来的文本区域生成该文本区域的rgbm图像;具体过程是:将所裁剪出来的文本区域图像的r、g、b三个通道进行加权平均,得到每个像素点对应的灰度值,灰度值采用二进制8位表示,灰度值从0到255总计256个灰度值,对应黑色到白色;然后对所有像素点的灰度值求平均值,将其作为一个标准值;依次对每个像素点的灰度值和标准值进行比较,如果大于标准值,将该点的灰度值置为0,如果小于标准值,将灰度值置为255,从而生成所述文本区域图像的二进制掩码m;将文本区域图像r、g、b三个通道与所述的二进制掩码m连接生成所述文本区域的rgbm图像;
[0063]
文本区域超分辨率修复子模块:该子模块的功能是根据所述的文本区域rgbm图像,通过深度学习网络对文本区域进行超分辨率修复;
[0064]
文本区域粘贴子模块:该子模块的功能是将修复后的文本区域按照文本区域检测框的四角顶点坐标,粘贴回原视频会议场景下的图像中。
[0065]
参见图2,所述的文本区域超分辨率修复子模块进一步包括如下子模块:
[0066]
信息提取和增强子模块:该子模块的功能是通过深度学习网络分层提取所述文本区域rgbm图像的低频特征信息,最后得到该图像的空间特征和序列特征;
[0067]
参见图3,该子模块第一层是卷积层,后面由八个相同的网络块顺序连接而成,每个网络块由残差网络单元和bilstm单元顺序连接构成;
[0068]
重建子模块:该子模块的功能是通过亚像素卷积,集成所述文本区域rgbm图像的全局特征和局部特征,将低频特征信息转换为高频特征信息;
[0069]
信息细化子模块:该子模块的功能是细化所述重建子模块得到的高频特征信息,
以得到文本区域的更加精确的超分辨率修复图像。
[0070]
所述的残差网络单元的具体结构为:为了消除冗余信息,减少参数数量、计算量和内存消耗,每个残差网络单元中采用异构架构;具体为第1、3、6、9、12、15、18、21和24层采用3*3conv relu结构,其中第1层的尺寸大小是3*3*3*64,即输入通道数为3,卷积核的大小是3*3,输出通道数是64;第3、6、9、12、15、18、21和24层的尺寸大小是64*3*3*64,即输入通道数为64,卷积核的大小是3*3,输出通道数是64;第2、5、8、11、14、17、20和23层采用1*1conv relu结构,其中,1*1conv的结构是卷积核的大小为1*1,输入通道和输出通道为64;relu是修正线性单元激活函数;
[0071]
卷积层的输出公式如下:
[0072][0073]
其中,表示第i层卷积的输出,oi表示第i层的输出,c3表示3*3的卷积函数,c1表示1*1的卷积函数;
[0074]
每一层的输出公式如下:
[0075][0076]
其中,r代表激活函数relu;
[0077]
所述的重建子模块由亚像素卷积层构成,所述的亚像素卷积层的组成为conv shuffle*2,卷积核大小为3*3,输入和输出通道都是64;shuffle是将卷积层得到的64通道的特征图的特征通道进行重新排列,shuffle*2代表将图像放大两倍;所述的亚像素卷积层将所述文本区域rgbm图像超分为2倍大小;为了解决长期依赖问题,所述亚像素卷积层分别将所述残差网络单元的第1层和第24层的输出作为全局特征和局部特征分别进行上采样,然后进行融合,再将融合结果经过relu函数转换为非线性的;
[0078]
所述的信息细化子模块的具体结构为:由4层conv relu和1层conv构成,其中conv relu卷积层的卷积核尺寸大小为3*3,输入通道数和输出通道数都为64,relu为激活函数;最后1层conv的卷积核尺寸大小为3*3,输入通道数是64,输出通道数是3。
[0079]
先使用像素损失函数l1对所述的文本区域的修复与粘贴模块进行训练,训练完成设定的批次epoch后,再使用感知损失函数l
text
对所述的文本区域的修复与粘贴模块进行训练,完成设定的批次epoch;
[0080]
在实施例中,使用像素损失函数l1对所述的文本区域的修复与粘贴模块进行训练35epoch后,再使用感知损失函数l
text
对所述的文本区域的修复与粘贴模块进行训练60epoch。
[0081]
其中像素损失函数l1定义如下:
[0082][0083]
上式中,是指训练集中高分辨率文本区域图像;i是指训练集中把与所述高分辨
率文本区域图像所对应的低分辨率文本区域图像,输入到所述的文本区域超分辨率修复子模块,所得到的超分辨率修复后的文本区域图像;训练集中所述高分辨率文本区域图像和低分辨率文本区域图像是一一对应的图像对,所述低分辨率文本区域图像由对应的高分辨率文本区域图像经过下采样处理得到;
[0084]
其中感知损失函数l
text
定义如下:
[0085][0086]
上式中,表示所述训练集中高分辨率图像经过vgg网络第j个卷积层后得到的特征图,表示所述超分辨率修复后的文本区域图像i经过vgg网络第j个卷积层后得到的特征图,c
jhj
wj表示vgg网络第j卷积层后的特征图的尺寸大小。
[0087]
vgg网络的详细信息参见文献:simonyan k,zissermana.very deep convolutional networks for large-scale image recognition[j].arxivpreprint arxiv:1409.1556,2014.
[0088]
参见图4,介绍本发明提出的一种面向视频会议的文本区域修复方法,所述方法包括下列操作步骤:
[0089]
(1)对视频会议场景下的图像进行预处理,检测该图像的文本区域,得到文本区域检测框的四角顶点坐标,按照所得到的四角顶点坐标将文本区域剪裁出来;
[0090]
参见图5~图7,图5是一幅视频会议场景下的模糊图像,图6是进行文本区域检测后的结果,图7是所裁剪出来的文本区域。在实施例中,使用python的pillow库,利用该pillow库的image类的crop方法将文本区域剪裁出来;
[0091]
(2)生成所述文本区域的二进制掩码,将该二进制掩码与所述的文本区域进行连接,得到所述文本区域的rgbm图像;对所得到的rgbm图像进行超分辨率修复,得到修复后的清晰的文本区域;把所得到的清晰的文本区域粘贴回原视频会议场景下的图像;
[0092]
图8是对图7进行超分辨率修复后的结果,图9是将图8粘贴回原视频会议场景下的图像后的结果。在实施例中,使用python的pillow库,利用该pillow库的image类的copy方法进行粘贴。
[0093]
发明人对本发明的系统和方法进行了大量实验,获得了良好的实验结果,这表明本发明的系统和方法是有效可行的。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。