具有命令关键词调节的网络麦克风设备
1.相关申请的交叉引用
2.本技术要求于2019年6月12日提交的题为“network microphone with command keyword conditioning”的美国专利申请no.16/439,009的优先权,其全部内容通过引用并入本文。
技术领域
3.本技术涉及消费者产品,并且更具体地,涉及与媒体回放系统的语音辅助控制或其某个方面有关的方法、系统、产品、特征、服务和其他元素。
背景技术:
4.在外放设置下访问和收听数字音频的选项受到限制,直到2002年sonos公司开始开发新型回放系统。然后,sonos于2003年提交了题为“method for synchronizing audio playback between multiple networked devices”的其首批专利申请之一,并于2005年开始提供其首批媒体回放系统以供销售。sonos无线家庭音响系统使人们能够经由一个或多个联网回放设备体验来自许多源的音乐。通过安装在控制器(例如,智能手机、平板电脑、计算机、语音输入设备)上的软件控制应用,人们可以在具有联网的回放设备的任何房间中播放自己想要的内容。媒体内容(例如,歌曲、播客、视频声音)可以被流式传输到回放设备,使得具有回放设备的每个房间可以回放对应的不同媒体内容。另外,可以将房间分组在一起以同步回放相同的媒体内容,和/或可以在所有房间中同步收听相同的媒体内容。
附图说明
5.参考以下说明书、所附权利要求和附图,可以更好地理解当前公开的技术的特征、方面和优点,在附图中:
6.参考下面列出的以下说明书、所附权利要求和附图,可以更好地理解当前公开的技术的特征、方面和优点。相关领域的技术人员将理解,附图中所示的特征是出于说明的目的,并且包括不同和/或附加特征及其布置的变型是可能的。
7.图1a是具有根据所公开技术的各方面配置的媒体回放系统的环境的局部剖视图。
8.图1b是图1a的媒体回放系统和一个或多个网络的示意图。
9.图2a是示例回放设备的功能框图。
10.图2b是图2a的回放设备的示例壳体的立体图。
11.图2c是示例语音输入的图。
12.图2d是描绘了根据本公开的各方面的示例声音样本的图。
13.图3a、3b、3c、3d和3e是示出了根据本公开的各方面的示例回放设备配置的图。
14.图4是根据本公开的各方面的示例控制器设备的功能框图。
15.图5a和图5b是根据本公开的各方面的控制器接口。
16.图6是媒体回放系统的消息流程图。
17.图7a是根据本公开的各方面的第一示例网络麦克风设备的某些组件的功能框图。
18.图7b是根据本公开的各方面的第二示例网络麦克风设备的某些组件的功能框图。
19.图7c是示出了根据本公开的各方面的示例状态机的功能框图。
20.图8示出了示出与背景话音相关联的分析后的声音元数据的示例噪声图。
21.图9a示出了示出根据本公开的各方面的示例命令关键词和相关联的条件的表的第一部分。
22.图9b示出了示出根据本公开的各方面的示例命令关键词和相关联的条件的表格的第二部分。
23.图10是示出了根据本公开的各方面的示例媒体回放系统和云网络的示意图。
24.图11示出了示出根据本公开的各方面的示例播放列表的表。
25.图12是根据本公开的各方面的基于命令关键词执行操作的示例方法的流程图。
26.图13是根据本公开的各方面的基于命令关键词执行操作的示例方法的流程图。
27.图14是根据本公开的各方面的基于命令关键词执行操作的示例方法的流程图。以及
28.图15a、图15b、图15c和图15d示出了根据本公开的各方面配置的示例nmd的示例性输出。
29.附图是出于说明示例实施例的目的,但是应当理解的是,本发明不限于附图中所示的布置和手段。在附图中,相同的附图标记识别至少大致相似的元件。为了促进对任何特定元件的讨论,任何参考数字中的一个或多个最高有效位指的是首次引入该元件的附图。例如,首先参照图1a介绍和讨论元件103a。
具体实施方式
30.i.概述
31.本文描述的示例技术涉及被配置为检测命令的唤醒词引擎。示例网络麦克风设备(“nmd”)可以与调用语音助手服务(“vas”)的唤醒词引擎并行地实现这种唤醒词引擎。虽然vas唤醒词引擎可以涉及随机唤醒词,但命令关键词引擎是通过命令调用的,例如,“播放”或“跳过”。
32.网络麦克风设备可以用于促进智能家居设备的语音控制,例如,无线音频回放设备、照明设备、电器和家庭自动化设备(例如,恒温器、门锁等)。nmd是一种网络计算设备,其通常包括麦克风的布置(例如,麦克风阵列),该麦克风的布置被配置为检测nmd环境中存在的声音。在一些示例中,nmd可以在另一个设备内实现,例如,音频回放设备。
33.这种nmd的语音输入通常包括唤醒词,其后跟包括用户请求的话语。在实践中,唤醒词通常是预定的随机单词或短语,用于“唤醒”nmd并使其调用特定的语音助手服务(“vas”)以解释检测到的声音中的语音输入的意图。例如,用户可能会说出唤醒词“alexa”以调用vas、“ok,google”以调用vas、“嘿,siri”以调用vas、或“嘿,sonos”以调用由提供的vas、以及其他示例。在实践中,唤醒词也可以被称为例如激活词、触发词、叫醒词或短语,并且可以采用任何合适的单词、单词的组合(例如,特定短语)和/或一些其他音频提示的形式。
34.为了识别由nmd检测到的声音是否包含包括特定唤醒词的语音输入,nmd通常利用通常板载在nmd上的唤醒词引擎。唤醒词引擎可以被配置为使用一种或多种识别算法来识别(即,“发现”或“检测”)录制音频中的特定唤醒词。这种识别算法可以包括被训练以检测说出唤醒词所创建的频域和/或时域模式的模式识别。该唤醒词识别过程通常被称为“关键词发现”。在实践中,为了帮助促进关键词发现,nmd可以缓冲nmd的麦克风检测到的声音,然后使用唤醒词引擎来处理该缓冲的声音以确定录制音频中是否存在唤醒词。
35.当唤醒词引擎在录制的音频中检测到唤醒词时,nmd可以确定发生了唤醒词事件(即,“唤醒词触发”),这表明nmd已检测到包括潜在语音输入的声音。唤醒词事件的发生通常会使nmd执行涉及检测到的声音的附加过程。对于vas唤醒词引擎,这些附加过程可以包括:从缓冲器提取检测到的声音数据,以及其他可能的附加过程,例如,输出指示已经识别唤醒词的警报(例如,可听提示音和/或指示灯)。提取检测到的声音可以包括:根据特定格式读出并封装检测到的声音的流,并向适当的vas发送该封装的声音数据以用于解释。
36.继而,与由唤醒词引擎识别的唤醒词相对应的vas通过通信网络从nmd接收发送的声音数据。传统上,vas采用远程服务的形式,该远程服务是使用一个或多个配置为处理语音输入的云服务器(例如,amazon的alexa、apple的siri、microsoft的cortana、google的assistant等)来实施的。在一些情况下,vas的某些组件和功能可能分布在本地设备和远程设备上。
37.当vas接收到所检测到的声音数据时,该vas会处理该数据,这涉及识别语音输入并确定在该语音输入中捕捉的单词的意图。然后,vas可以根据该确定的意图使用某指令将响应提供回nmd。基于该指令,nmd可以使一个或多个智能设备执行操作。例如,在其他示例中,根据来自vas的指令,nmd可以使回放设备播放特定歌曲,或者使照明设备打开/关闭。在一些情况下,nmd或具有nmd的媒体系统(例如,具有配备有nmd的回放设备的媒体回放系统)可以被配置为与多个vas交互。实际上,nmd可以基于在nmd检测到的声音中识别的特定唤醒词,选择一个vas而不是另一个。
38.传统唤醒词引擎面临的一个挑战是,它们容易出现由“错误唤醒词”触发器引起的误报。nmd上下文中的误报通常是指错误地调用了vas的检测到的声音输入。对于vas唤醒词引擎,即使实际上没有用户旨在向nmd说出唤醒词,误报也可能会调用vas。
39.例如,当唤醒词引擎从nmd环境中播放的音频(例如,音乐、播客等)中识别出检测到的声音中的唤醒词时,可能会发生误报。该输出音频可以从nmd附近的回放设备播放,或者由nmd本身播放。例如,当amazon的alexa服务的商业广告的音频在nmd附近输出时,该商业广告中的单词“alexa”可能触发误报。导致误报的输出音频中的单词或短语在本文中可以被称为“虚假唤醒词”。
40.在其他示例中,语音上与实际唤醒词相似的单词会导致误报。例如,当汽车的商业广告的音频在nmd附近输出时,单词“lexus”可能是导致误报的虚假唤醒词,因为该单词在语音上与“alexa”相似。作为其他示例,当一个人在对话中说出vas唤醒词或语音相似的单词时,可能会发生误报。
41.误报的发生是不期望的,因为它们可能会导致nmd消耗附加的资源或中断音频回放,以及其他可能的负面后果。一些nmd可以通过要求按下按钮以调用vas来避免误报,例如在amazon firetv遥控器或apple tv遥控器上。在实践中,由vas唤醒词引擎产生的误报的
影响通常通过vas处理检测到的声音数据并确定检测到的声音数据不包括可识别的语音输入来部分地减轻。
42.与调用vas的预定的随机唤醒词相比,调用命令的关键词(在本文中被称为“命令关键词”)可以是用作命令本身的单词或单词的组合(例如,短语),例如,回放命令。在一些实施方式中,命令关键词可以用作唤醒词和命令本身。即,当命令关键词引擎在录制的音频中检测到命令关键词时,nmd可以确定命令关键词事件已经发生,并且响应地执行与检测到的关键词相对应的命令。例如,基于检测到命令关键词“暂停”,nmd导致回放暂停。命令关键词引擎的一个优点是,录制的音频不一定需要被发送给vas进行处理,这可能会导致对语音输入的更快响应以及增加的用户隐私,以及其他可能的好处。在下文描述的一些实施方式中,检测到的命令关键词事件可以导致一个或多个后续动作,例如,语音输入的本地自然语言处理。在一些实施方式中,命令关键词事件可以是在导致此类动作之前必须检测的一个或多个其他条件中的一个条件。
43.根据本文描述的示例技术,在检测到命令关键词之后,示例nmd可以仅在满足与检测到的命令关键词相对应的某些条件时才生成命令关键词事件(并执行与检测到的命令关键词相对应的命令)。例如,在检测到命令关键词“跳过”之后,示例nmd仅在满足指示应该执行跳过的某些回放条件时才生成命令关键词事件(并跳到下一个曲目)。这些回放条件可以包括:例如,(i)正在回放媒体项的第一条件;(ii)队列处于活动状态的第二条件;以及(iii)队列包括正在回放的媒体项之后的媒体项的第三条件。如果不满足这些条件中的任何一个,则不会生成命令关键词事件(并且不执行跳过)。
44.通过在生成命令关键词事件之前要求(a)检测命令关键词以及(b)与检测到的命令关键词相对应的某些条件,可以减少误报的发生率。例如,在播放tv音频时,对话或其他tv音频不会针对“跳过”命令关键词生成误报,因为tv音频输入处于活动状态(而不是队列)。此外,nmd可以持续地侦听命令关键词(而不是需要按下按钮以使nmd处于接收语音输入的状态)作为与受控设备门唤醒词事件生成的状态相关的条件。
45.调节关键词事件的各个方面也可以适用于vas唤醒词引擎和其他传统的随机唤醒词引擎。例如,除了可能容易出现误报的命令关键词引擎之外,这种调节还可能使其他唤醒词引擎变得实用。例如,nmd可以包括流式音频服务唤醒词引擎,该引擎支持流式音频服务独有的某些唤醒词。例如,在检测到流式音频服务唤醒词之后,示例nmd仅在满足某个流式音频服务时才生成流式音频服务唤醒词事件。这些回放条件可以包括:例如,(i)对流式音频服务的有效订阅;以及(ii)来自队列中的流式音频服务的音频曲目;以及其他示例。
46.此外,命令关键词可以是单个单词或短语。短语通常包括更多音节,这通常使命令关键词更加独特,并且更容易被命令关键词引擎识别。因此,在一些情况下,作为短语的命令关键词可能不太容易出现误报检测。此外,使用短语可以允许将更多意图并入到命令关键词中。例如,“向前跳过”的命令关键词表示应该在队列中向前跳到后续曲目,而不是后退到前一个曲目。
47.此外,nmd可以包括本地自然语言单元(nlu)。与在一个或多个能够识别多种语音输入的云服务器中实现的nlu相比,示例本地nlu能够识别相对较小的关键词库(例如,10,000个单词和短语),这有助于在nmd上实际实现。当命令关键词引擎在检测到语音输入中的命令关键词之后生成命令关键词事件时,本地nlu可以处理语音输入的语音话语部分以从
库中查找关键词,并从找到的关键词中确定意图。
48.如果语音输入的语音发声部分包括来自库的至少一个关键词,则nmd可以根据与该至少一个关键词相对应的一个或多个参数来执行与命令关键词相对应的命令。换言之,关键词可以改变或定制与命令关键词相对应的命令。例如,命令关键词引擎可以被配置为将“播放”检测为命令关键词,并且本地nlu库可以包括短语“低音量”。然后,如果用户说出“以低音量播放音乐”作为语音输入,则命令关键词引擎针对“播放”生成命令关键词事件,并使用关键词“低音量”作为“播放”命令的参数。因此,nmd不仅导致基于该语音输入进行回放,而且还降低了音量。
49.示例技术涉及为媒体回放系统的用户定制库中的关键词。例如,nmd可以使用已经在媒体回放系统中配置的名称(例如,区名、智能设备名称和用户名)来填充库。此外,nmd可以用最爱的播放列表、互联网无线电台等的名称来填充本地nlu库。这种定制允许本地nlu更高效地帮助用户使用语音命令。这种定制也可能是有利的,因为可以限制本地nlu库的大小。
50.本地nlu的一个可能优点是增加了隐私。通过在本地处理语音话语,用户可以避免向云(例如,向语音助手服务的服务器)传输语音记录。此外,在一些实施方式中,nmd可以使用局域网来发现连接到网络的回放设备和/或智能设备,这可以避免向云提供该数据。此外,用户的偏好和定制可以保留在家庭中nmd的本地,可能仅使用云作为可选备份。其他优点也是可能的。
51.如上所述,示例技术与命令关键词相关。第一示例实施方式涉及一种设备,该设备包括:网络接口;一个或多个处理器;至少一个麦克风,被配置为检测声音;至少一个扬声器;唤醒词引擎,被配置为接收表示由至少一个麦克风检测到的声音的输入声音数据,并在唤醒词引擎在输入声音数据中检测到vas唤醒词时生成语音助手服务(vas)唤醒词事件,其中,当生成vas唤醒词事件时,设备向语音助手服务的一个或多个服务器流式传输表示由至少一个麦克风检测到的声音的声音数据;以及命令关键词引擎,被配置为接收表示由至少一个麦克风检测到的声音的输入声音数据,并在(a)第二唤醒词引擎在输入声音数据中检测到由第二唤醒词引擎支持的多个命令关键词之一,以及(b)满足与检测到的命令关键词相对应的一个或多个回放条件时,生成命令关键词事件,其中,多个命令关键词中的每个命令关键词是相应的回放命令。设备经由命令关键词引擎检测第一命令关键词,并且确定是否满足与第一命令关键词相对应的一个或多个回放条件。基于(a)检测到第一命令关键词,以及(b)确定满足与第一命令关键词相对应的一个或多个回放条件,设备经由命令关键词引擎生成与第一命令关键词相对应的命令关键词事件。响应于命令关键词事件,以及确定满足一个或多个回放条件,设备执行与第一命令关键词相对应的第一回放命令。
52.第二示例实施方式涉及一种设备,该设备包括:网络接口;一个或多个处理器;至少一个麦克风,被配置为检测声音;至少一个扬声器;唤醒词引擎,被配置为接收表示由至少一个麦克风检测到的声音的输入声音数据,并在唤醒词引擎在输入声音数据中检测到vas唤醒词时生成语音助手服务(vas)唤醒词事件,其中,当生成vas唤醒词事件时,设备向语音助手服务的一个或多个服务器流式传输表示由至少一个麦克风检测到的声音的声音数据;命令关键词引擎,被配置为接收表示由至少一个麦克风检测到的声音的输入声音数据。设备经由命令关键词引擎检测作为由设备支持的多个命令关键词之一的第一命令关键
词,并经由本地自然语言单元(nlu)确定基于至少一个关键词的意图。在检测到第一命令关键词事件并确定意图之后,设备根据确定的意图执行与第一命令关键词相对应的第一回放命令。
53.尽管本文所述的一些实施例可以涉及由给定的行动者(例如,“用户”和/或其他实体)执行的功能,但是应当理解的是,该描述仅出于解释的目的。除非权利要求本身的语言明确要求,否则不应将权利要求解释为要求任何此类示例行动者进行动作。
54.此外,一些功能在本文中被描述为“基于”或“响应于”另一元件或功能而执行。“基于”应被理解为一个元件或功能与另一功能或元件相关。“响应于”应被理解为一个元件或功能是另一功能或元件的必要结果。为了简洁起见,通常将功能描述为在存在功能链时基于另一个功能;然而,此类公开应理解为公开了任一类型的功能关系。
55.ii.示例操作环境
56.图1a和图1b示出了媒体回放系统100(或“mps 100”)的示例配置,在媒体回放系统100中可以实现本文公开的一个或多个实施例。首先参考图1a,所示的mps 100与具有多个房间和空间的示例家居环境相关联,其可以被统称为“家居环境”、“智能家居”或“环境101”。环境101包括具有若干个房间、空间和/或回放区的家庭,包括主浴室101a、主卧室101b(在本文中被称为“尼克的房间”)、第二卧室101c、家庭房或书房101d、办公室101e、客厅101f、餐厅101g、厨房101h和室外露台101i。尽管下文在家居环境的上下文中描述了某些实施例和示例,但是本文所述的技术可以在其他类型的环境中实现。在一些实施例中,例如,mps 100可以在一个或多个商业设置(例如,餐厅、购物中心、机场、酒店、零售店或其他商店)、一个或多个交通工具(例如,运动型多功能车、巴士、汽车、轮船、轮船、飞机)、多个环境(例如,家庭和交通工具环境的组合)和/或可能需要多区音频的其他合适环境中实现。
57.在这些房间和空间中,mps 100包括一个或多个计算设备。一起参考图1a和1b,这样的计算设备可以包括:回放设备102(分别识别为回放设备102a-102o)、网络麦克风设备103(分别识别为“nmd”103a-102i)以及控制器设备104a和104b(统称为“控制器设备104”)。参照图1b,家居环境可以包括附加和/或其他计算设备,包括本地网络设备,例如,一个或多个智能照明设备108(图1b)、智能恒温器110和本地计算设备105(图1a)。在下文所述的实施例中,各种回放设备102中的一个或多个可以被配置为便携式回放设备,而其他回放设备可以被配置为固定回放设备。例如,耳机102o(图1b)是便携式回放没备,而书架上的回放设备102d可以是固定设备。作为另一示例,露台上的回放设备102c可以是电池供电的设备,允许其在未插入墙壁插座等时被运输到环境101内以及环境101外部的各个区域。
58.仍参考图1b,mps 100的各种回放、网络麦克风和控制器设备102、103和104和/或其他网络设备可以经由点对点连接和/或通过经由网络111(例如,包括网络路由器109的lan)的其他连接彼此耦合,该连接可以是有线的和/或无线的。例如,可以被指定为“左”设备的书房101d(图1a)中的回放设备102j可以与回放设备102a具有点对点连接,该回放设备102a也在书房101d中并且可以被指定为“右”设备。在相关实施例中,左回放设备102j可以经由点对点连接和/或经由网络111的其他连接与其他网络设备(例如,回放设备102b)通信,该其他网络设备可以被指定为“前”设备。
59.如图1b进一步所示,mps 100可以通过广域网(“wan”)107耦合到一个或多个远程计算设备106。在一些实施例中,每个远程计算设备106可以采取一个或多个云服务器的形
式。远程计算设备106可以被配置为以各种方式与环境101中的计算设备进行交互。例如,远程计算设备106可以被配置为在家居环境101中促进流式传输和/或控制媒体内容(例如,音频)的回放。
60.在一些实施方式中,各种回放设备、nmd和/或控制器设备102-104可以通信地耦合到与vas相关联的至少一个远程计算设备和与媒体内容服务(“mcs”)相关联的至少一个远程计算设备。例如,在图1b的所示示例中,远程计算设备106与vas 190相关联,并且远程计算设备106b与mcs 192相关联。尽管为了清楚起见在图1b的示例中仅示出了单个vas 190和单个mcs 192,但是mps 100可以耦合到多个不同的vas和/或mcs。在一些实施方式中,vas可以由amazon、google、apple、microsoft、sonos或其他语音助手提供商中的一个或多个来操作。在一些实施方式中,mcs可以由spotify、pandora、amazon music或其他媒体内容服务中的一个或多个来操作。
61.如图1b进一步所示,远程计算设备106还包括远程计算设备106c,该远程计算没备106c被配置为执行某些操作,例如,远程促进媒体回放功能、管理设备和系统状态信息、指导mps 100的设备与一个或多个vas和/或mcs之间的通信,以及其他操作。在一个示例中,远程计算设备106c为一个或多个sonos无线hifi系统提供云服务器。
62.在各种实施方式中,一个或多个回放设备102可以采用或包括板载(例如,集成的)网络麦克风设备的形式。例如,回放设备102a-e分别包括或配备有对应的nmd 103a-e。除非在说明书中另外指出,否则包括或配备有nmd的回放设备在本文中可以互换地被称为回放设备或nmd。在一些情况下,一个或多个nmd 103可以是独立设备。例如,nmd 103f和103g可以是独立设备。独立nmd可以省略通常包括在回放设备(例如,扬声器或相关电子设备)中的组件和/或功能。例如,在这种情况下,独立nmd可能不会产生音频输出或可能会产生有限的音频输出(例如,相对低质量的音频输出)。
63.mps 100的各种回放和网络麦克风设备102和103可以各自与唯一名称相关联,该唯一名称可以例如在设置这些设备中的一个或多个期间由用户分配给各个设备。例如,如图1b的所示示例所示,用户可以将名称“书架”分配给回放设备102d,因为它实际上位于书架上。类似地,可以将名称“岛”分配给nmd 103f,因为它实际上位于厨房101h(图1a)中的岛台面上。可以根据区或房间为一些回放设备分配名称,例如,回放设备102e、1021、102m和102n,它们分别被命名为“卧室”、“餐厅”、“客厅”和“办公室”。此外,某些回放设备可以具有功能描述性名称。例如,回放设备102a和102b分别被分配了名称“右”和“前”,因为这两个设备被配置为在书房101d(图1a)的区中媒体回放期间提供特定的音频声道。露台中的回放设备102c可以命名为便携式设备,因为它是电池供电的和/或易于运输到环境101的不同区域。其他命名约定也是可能的。
64.如上所述,nmd可以检测和处理来自其周围环境的声音,例如,包括背景噪声的声音,该背景噪声与该nmd附近的人说出的语音混合。例如,当nmd在环境中检测到声音时,该nmd可以处理检测到的声音以确定该声音是否包括语音,该语音包含用于该nmd并最终用于特定vas的语音输入。例如,nmd可以识别语音是否包括与特定vas相关联的唤醒词。
65.在图1b的所示示例中,nmd 103被配置为经由网络111和路由器109通过网络与vas 190交互。例如,当nmd在检测到的声音中识别出潜在唤醒词时,可以发起与vas 190的交互。该识别导致唤醒词事件,这又导致nmd开始向vas 190发送检测到的声音数据。在一些实施
方式中,mps 100的各种本地网络设备102-105(图1a)和/或远程计算设备106c可以与远程计算设备交换各种反馈、信息、指令和/或相关数据,该远程计算设备与所选择的vas相关联。这样的交换可以与包含语音输入的发送消息有关或独立于该消息。在一些实施例中,远程计算设备和mps 100可以通过如本文所述的通信路径和/或使用如在2017年2月21日提交的美国申请no.15/438,749中所述的元数据交换信道来交换数据,该美国申请题为“voice control of a media playback system”,其全部内容通过引用并入本文。
66.在接收到声音数据流之后,vas 190确定来自nmd的流数据中是否存在语音输入,如果存在,则vas 190还将确定该语音输入中的潜在意图。vas 190接下来可以将响应发送回mps 100,这可以包括直接向导致唤醒词事件的nmd发送该响应。该响应通常基于vas 190确定的存在于语音输入中的意图。作为示例,响应于vas 190接收到语音提示为“播放披头士乐队的hey jude”的语音输入,vas 190可以确定该语音输入的基本意图是发起回放,并进一步确定该语音输入的意图是播放特定歌曲“hey jude”。在这些确定之后,vas 190可以向特定mcs 192发送命令以检索内容(即,歌曲“hey jude”),并且随后,该mcs 192直接向mps 100提供(例如,流)这个内容或间接通过vas 190提供。在一些实施方式中,vas 190可以向mps 100发送命令,该命令使mps 100本身从mcs 192检索内容。
67.在某些实施方式中,当在由彼此相邻的两个或多个nmd检测到的语音中识别出语音输入时,nmd可以促进彼此之间的仲裁。例如,环境101(图1a)中配备有nmd的回放设备102d与配备有nmd的客厅回放设备102m相对接近,并且设备102d和102m都可以至少有时检测到相同的声音。在这种情况下,这可能需要仲裁,以确定最终由哪个设备负责向远程vas提供检测到的声音数据。例如,可以在先前引用的美国申请no.15/438,749中找到在nmd之间进行仲裁的示例。
68.在某些实施方式中,nmd可以被分配给可能不包含nmd的指定的或默认的回放设备,或与该回放设备相关联。例如,可以将厨房101h(图1a)中的岛nmd 103f分配给离该岛nmd 103f相对较近的餐厅回放设备102l。在实践中,响应于远程vas接收到来自nmd的语音输入以播放音频,nmd可以指示分配的回放设备播放音频,该nmd可能已经响应于用户说出的命令而向该vas发送语音输入以播放特定的歌曲、专辑、播放列表等。例如,在先前引用的美国专利申请no.中可以找到关于将nmd和回放设备分配为指定设备或默认设备的附加细节。
69.可以在以下部分中找到与示例mps 100的不同组件以及不同组件如何交互以向用户提供媒体体验有关的其他方面。尽管本文的讨论通常可以参考示例mps 100,但本文所述的技术不仅限于除其他以外的上述家居环境中的应用。例如,本文所述的技术在其他家居环境配置中可能是有用的,该其他家居环境配置包括更多或更少的回放、网络麦克风和/或控制器设备102-104中的任何一个。例如,本文的技术可以在具有单个回放设备102和/或单个nmd 103的环境中使用。在这种情况的一些示例中,网络111(图1b)可以被去除,并且单个回放设备102和/或单个nmd 103可以直接地与远程计算设备106-d通信。在一些实施例中,电信网络(例如,lte网络、5g网络等)可以独立于lan与各种回放、网络麦克风和/或控制器设备102-104通信。
70.a.示例回放和网络麦克风设备
71.图2a是示出了图1a和图1b的mps 100的回放设备102之一的某些方面的功能框图。
如图所示,回放设备102包括各种组件,下文进一步详细讨论每个组件,并且回放设备102的各种组件可以通过系统总线、通信网络或某个其他连接机制可操作地彼此耦合。在图2a的所示示例中,回放设备102可以被称为“配备有nmd”的回放设备,因为它包括支持nmd功能的组件,例如,图1a中所示的nmd 103之一。
72.如图所示,回放设备102包括至少一个处理器212,该处理器212可以是时钟驱动的计算组件,该计算组件被配置为根据存储在存储器213中的指令来处理输入数据。存储器213可以是有形的、非暂时性的计算机可读介质,其被配置为存储可由处理器212执行的指令。例如,存储器213可以是数据存储设备,其可以加载有可由处理器212执行以实现某些功能的软件代码214。
73.在一个示例中,这些功能可以涉及回放设备102从音频源获取音频数据,该音频源可以是另一回放设备。在另一示例中,该功能可以涉及回放设备102经由至少一个网络接口224向网络上的另一设备发送音频数据、检测到的声音数据(例如,对应于语音输入)和/或其他信息。在又一示例中,该功能可以涉及回放设备102使一个或多个其他回放设备与回放设备102同步地回放音频。在又一示例中,该功能可以涉及回放设备102促进与一个或多个其他回放设备配对或以其他方式绑定以创建多声道音频环境。许多其他示例功能也是可能的,下面讨论其中一些功能。
74.如刚刚提到的,某些功能可以涉及回放设备102与一个或多个其他回放设备同步回放音频内容。在同步回放期间,听众可能无法感知同步回放设备在音频内容回放之间的时间延迟差异。通过引用整体并入本文的2004年4月4日提交的题为“system and method for synchronizing operations among a plurality of independently clocked digital data processing devices”的美国专利no.8,234,395,更详细地提供了回放设备之间的音频回放同步的一些示例。
75.为了促进音频回放,回放设备102包括音频处理组件216,该音频处理组件216通常被配置为在回放设备102呈现音频之前处理该音频。在这方面,音频处理组件216可以包括一个或多个数模转换器(“dac”)、一个或多个音频预处理组件、一个或多个音频增强组件、一个或多个数字信号处理器(“dsp”)等。在一些实施方式中,一个或多个音频处理组件216可以是处理器212的子组件。在操作中,音频处理组件216接收模拟和/或数字音频,并且处理和/或有意更改音频以产生音频信号进行播放。
76.然后,可以向一个或多个音频放大器217提供产生的音频信号,以通过可操作地耦合到放大器217的一个或多个扬声器218进行放大和回放。音频放大器217可以包括被配置为将音频信号放大到用于驱动一个或多个扬声器218的电平的组件。
77.扬声器218中的每一个可以包括单独的传感器(例如,“驱动器”),或者扬声器218可以包括完整的扬声器系统,该扬声器系统包括具有一个或多个驱动器的外壳。扬声器218的特定驱动器可以包括例如超低音扬声器(例如,用于低频)、中音驱动器(例如,用于中频)和/或高音扬声器(例如,用于高频)。在一些情况下,传感器可以由音频放大器217的各个对应的音频放大器驱动。在一些实施方式中,回放设备可以不包括扬声器218,而是可以包括用于将该回放设备连接到外部扬声器的扬声器接口。在某些实施例中,回放设备可以既不包括扬声器218也不包括音频放大器217,而是可以包括用于将该回放设备连接到外部音频放大器或视听接收机的音频接口(未示出)。
78.除了产生用于由回放设备102回放的音频信号之外,音频处理组件216可以被配置为处理要通过网络接口224向一个或多个其他回放设备发送以进行回放的音频。在示例场景中,如下所述,可以例如通过回放设备102(未示出)的音频线路输入接口(例如,自动检测3.5mm音频线路输入连接)或通过网络接口224从外部源接收要由回放设备102处理和/或回放的音频内容。
79.如图所示,至少一个网络接口224可以采取一个或多个无线接口225和/或一个或多个有线接口226的形式。无线接口可以为回放设备102提供网络接口功能,以根据通信协议(例如,任何无线标准,包括ieee 802.11a、802.11b、802.11g、802.11n、802.11ac、802.15、4g移动通信标准等)与其他设备(例如,其他回放设备、nmd和/或控制器设备)无线通信。有线接口可以为回放设备102提供网络接口功能,以根据通信协议(例如,ieee 802.3)通过有线连接与其他设备进行通信。尽管图2a中所示的网络接口224包括有线接口和无线接口,但是在一些实施方式中,回放设备102可以仅包括无线接口或仅包括有线接口。
80.通常,网络接口224促进回放设备102与数据网络上的一个或多个其他设备之间的数据流。例如,回放设备102可以被配置为通过数据网络从一个或多个其他回放设备、lan内的网络设备和/或wan(例如,互联网)上的音频内容源接收音频内容。在一个示例中,回放设备102发送和接收的音频内容和其他信号可以以数字分组数据的形式来发送,该数字分组数据包括基于互联网协议(ip)的源地址和基于ip的目的地地址。在这种情况下,网络接口224可以被配置为解析数字分组数据,使得去往回放设备102的数据被回放设备102正确地接收和处理。
81.如图2a所示,回放设备102还包括可操作地耦合到一个或多个麦克风222的语音处理组件220。麦克风222被配置为检测回放设备102的环境中的声音(即,声波),然后将其提供给语音处理组件220。更具体地,每个麦克风222被配置为检测声音并将该声音转换成表示检测到的声音的数字或模拟信号,然后这可以使语音处理组件220基于检测到的声音执行各种功能,如下文更详细地描述。在一个实施方式中,麦克风222被布置为麦克风阵列(例如,六个麦克风的阵列)。在一些实施方式中,回放设备102包括六个以上麦克风(例如,八个麦克风或十二个麦克风)或少于六个麦克风(例如,四个麦克风、两个麦克风或单个麦克风)。
82.在操作中,语音处理组件220通常被配置为检测和处理通过麦克风222接收到的声音,识别检测到的声音中潜在的语音输入,并提取检测到的声音数据以启用vas(例如,vas 190(图1b)),以处理在检测到的声音数据中识别的语音输入。语音处理组件220可以包括一个或多个模数转换器、回声消除器(“aec”)、空间处理器(例如,一个或多个多声道维纳滤波器、一个或多个其他滤波器和/或一个或多个波束形成器组件)、一个或多个缓冲器(例如,一个或多个循环缓冲器)、一个或多个唤醒词引擎、一个或多个语音提取器和/或一个或多个语音处理组件(例如,被配置为识别与家庭相关联的特定用户或特定用户组的语音的组件)以及其他示例语音处理组件。在示例实施方式中,语音处理组件220可以包括或者采取一个或多个dsp或一个或多个dsp模块的形式。在这方面,某些语音处理组件220可以被配置有特定参数(例如,增益和/或频谱参数),该特定参数可以被修改或被调谐以实现特定功能。在一些实施方式中,一个或多个语音处理组件220可以是处理器212的子组件。
83.如图2a进一步所示,回放设备102还包括电源组件227。电源组件227至少包括外部电源接口228,该外部电源接口228可以通过将回放设备102物理地连接至电源插座或某个其他外部电源的电缆等耦合到电源(未示出)。其他电源组件可以包括例如变压器、转换器以及被配置为格式化电源的类似组件。
84.在一些实施方式中,回放设备102的电源组件227可以附加地包括内部电源229(例如,一个或多个电池),该内部电源229被配置为在未物理连接到外部电源的情况下为回放设备102供电。当配备有内部电源229时,回放设备102可以独立于外部电源进行操作。在一些这样的实施方式中,外部电源接口228可以被配置为促进对内部电源229的充电。如之前所讨论的,包括内部电源的回放设备在本文中可以被称为“便携式回放设备”。另一方面,使用外部电源操作的回放设备在本文中可以被称为“固定回放设备”,尽管这种设备实际上可以在家居或其他环境中移动。
85.回放设备102还包括用户界面240,该用户界面240可以独立于或与一个或多个控制器设备104所促进的用户交互相结合来促进用户交互。在各种实施例中,用户界面240包括一个或多个物理按钮和/或支持在触敏屏幕和/或表面上提供的图形界面等,以便用户直接提供输入。用户界面240还可以包括灯(例如,led)和扬声器中的一个或多个,以向用户提供视觉和/或音频反馈。
86.作为说明性示例,图2b示出了回放设备102的示例壳体230,在壳体230的顶部234处包括控制区域232形式的用户界面。控制区域232包括用于控制音频回放、音量水平和其他功能的按钮236a-c。控制区域232还包括用于将麦克风222切换到开启状态或关闭状态的按钮236d。
87.如图2b进一步所示,控制区域232至少部分地由形成在壳体230的顶部234中的孔围绕,麦克风222(在图2b中不可见)通过该孔接收回放设备102的环境中的声音。麦克风222可以沿着顶部234和/或在顶部230或壳体230的其他区域内的各种位置中布置,以便从相对于回放设备102的一个或多个方向检测声音。
88.举例来说,sonos公司目前提供(或已经提供)销售可以实现本文公开的某些实施例的某些回放设备,包括“play:1”、“play:3”、“play:5”、“playbar”、“connect:amp”、“playbase”、“beam”、“connect”和“sub”。任何其他过去、现在和/或将来的回放设备可以附加地或备选地用于实现本文公开的示例实施例的回放设备。此外,应当理解的是,回放设备不限于图2a或图2b所示的示例或sonos产品供应。例如,回放设备可以包括有线或无线耳机组,或者采取有线或无线耳机组的形式,该耳机组可以通过网络接口等作为mps 100的一部分进行操作。在另一示例中,回放设备可以包括个人移动媒体回放设备的扩展基座,或与其交互。在又一示例中,回放设备可以集成到另一设备或组件,例如,电视、照明器材或在室内或室外使用的一些其他设备。
89.图2c是可以由nmd或配备有nmd的回放设备处理的示例语音输入280的图。语音输入280可以包括关键词部分280a和话语部分280b。关键词部分280a可以包括唤醒词或命令关键词。在唤醒词的情况下,关键词部分280a对应于检测到的引起唤醒词的声音。话语部分280b对应于检测到的可能包括在关键词部分280a之后的用户请求的声音。响应于由关键词部分280a引起的事件,nmd可以处理话语部分280b以识别检测到的声音数据中的任何单词的存在。在各种实施方式中,可以基于话语部分280b中的单词来确定潜在意图。在某些实施
方式中,例如当关键词部分包括命令关键词时,潜在意图也可以基于或至少部分地基于关键词部分280a中的某些单词。在任何情况下,这些单词可以对应于一个或多个命令,以及某个命令和某些关键词。语音话语部分280b中的关键词可以是例如识别mps 100中的特定设备或组的单词。例如,在所示的示例中,语音话语部分280b中的关键词可以是识别要在其中播放音乐的一个或多个区(例如,客厅和餐厅(图1a))的一个或多个单词。在一些情况下,话语部分280b可以包括附加信息,例如,检测到的用户说出的单词之间的停顿(例如,非话音的时间段),如图2c所示。该停顿可以在话语部分280b内划分由用户说出的单独命令、关键词或其他信息的位置。
90.基于某些命令标准,nmd和/或远程vas可以作为识别语音输入中的一个或多个命令的结果来采取动作。命令标准可以基于在语音输入中包含某些关键词以及其他可能性。附加地或备选地,用于命令的命令标准可以涉及对一个或多个控制状态和/或区状态变量的识别,该控制状态和/或区状态变量与一个或多个特定命令的识别相结合。控制状态变量可以包括:例如,识别音量级别的指示符、与一个或多个设备相关联的队列以及回放状态,例如,设备是否正在播放队列、是否暂停等。区状态变量可以包括:例如,识别哪些区播放器被分在一组的指示符。
91.在一些实施方式中,mps 100被配置为当在关键词部分280a中检测到某个关键词(例如,唤醒词)时,暂时地减小它正在播放的音频内容的音量。mps 100可以在处理语音输入280之后恢复音量。这样的过程可以被称为回避(ducking),其示例在通过引用整体并入本文的美国专利申请no.15/438,749中公开。
92.图2d示出了示例声音样本。在该示例中,声音样本对应于与图2a的关键词部分280a中发现的唤醒词或命令关键词相关联的声音数据流(例如,一个或多个音频帧)。如图所示,示例声音样本包括:(i)紧接在说出唤醒词或命令词之前在nmd的环境中检测到的声音,该声音可以被称为前滚动部分(在时间t0和t1之间);(ii)在说出唤醒词或命令词时在nmd的环境中检测到的声音,该声音可以被称为唤醒计部分(在时间t1和t2之间);和/或(iii)在说出唤醒词或命令词之后在nmd的环境中检测到的声音,该声音可以被称为后滚动部分(在时间t2和t3之间)。其他声音样本电是可能的。在各种实施方式中,可以根据声学模型评估声音样本的各方面,该声学模型旨在将梅尔(mels)/频谱特征映射到给定语言模型中的音素以供进一步处理。例如,自动语音识别(asr)可以包括这种用于命令关键词检测的映射。相比之下,唤醒词检测引擎可以精确地调谐以识别特定唤醒词和调用vas的下游动作(例如,通过仅针对由回放设备处理的语音输入中的随机词)。
93.可以调谐用于命令关键词检测的asr以适应范围广泛的关键词(例如,5、10、100、1000、10000个关键词)。与唤醒词检测相比,命令关键词检测可以涉及将asr输出馈送到板载本地nlu,该nlu与asr一起确定何时发生了命令词事件。在以下描述的一些实施方式中,本地nlu可以基于由特定语音输入产生的asr输出中的一个或多个其他关键词来确定意图。在这些或其他实施方式中,仅当回放设备确定已经满足某些条件(例如,环境条件(例如,低背景噪声))时,回放设备才可以对检测到的命令关键词事件采取行动。
94.b.示例回放设备配置
95.图3a-3e示出了回放设备的示例配置。首先参考图3a,在一些示例实例中,单个回放设备可以属于一个区。例如,露台上的回放设备102c可以属于a区。在以下所述的一些实
施方式中,多个回放设备可以被“绑定”以形成“绑定对”,它们一起形成单个区。例如,可以将图3a中名为“床1”的回放设备102f(图1a)绑定到图3a中名为“床2”的回放设备102g(图1a)以形成b区。绑定的回放设备可以具有不同的回放职责(例如,声道职责)。在以下所述的另一实施方式中,多个回放设备可以被合并以形成单个区。例如,可以将名为“书架”的回放设备102d与名为“客厅”的回放设备102m合并以形成单个c区。合并的回放设备102d和102m可以不被具体地分配不同的回放职责。即,合并的回放设备102d和102m除了可以同步播放音频内容之外,还可以如未合并时那样各自播放音频内容。
96.为了控制的目的,mps 100中的每个区可以被表示为单个用户界面(“ui”)实体。例如,如控制器设备104所显示的,a区可以被提供为名为“便携”的单个实体,b区可以被提供为名为“立体声”的单个实体,以及c区可以被提供为名为“客厅”的单个实体。
97.在各种实施例中,一个区可以采用属于该区的回放设备之一的名称。例如,c区可以采用客厅设备102m的名称(如图所示)。在另一示例中,c区可以采用书架设备102d的名称。在另一示例中,c区可以采用书架设备102d和客厅设备102m的某种组合的名称。用户可以通过控制器设备104处的输入来选择所选择的名称。在一些实施例中,可以将区命名为与属于该区的设备不同的名称。例如,图3a中的b区被命名为“立体声”,但是b区中的所有设备都没有此名称。在一方面,b区是表示名为“立体声”的单个设备的单个ui实体,该单个设备由名为“床1”和“床2”的组成设备组成。在一个实施方式中,床1设备可以是主卧室101h(图1a)中的回放设备102f,并且床2设备也可以是主卧室101h(图1a)中的回放设备102g。
98.如上所述,绑定的回放设备可以具有不同的回放职责,例如,某些音频声道的回放职责。例如,如图3b所示,床1和床2设备102f和102g可以被绑定,以产生或增强音频内容的立体声效果。在该示例中,床1回放设备102f可以被配置为播放左声道音频分量,而床2回放设备102g可以被配置为播放右声道音频分量。在一些实施方式中,这种立体声绑定可以被称为“配对”。
99.另外,被配置为被绑定的回放设备可以具有附加的和/或不同的相应的扬声器驱动器。如图3c所示,可以将名为“前”的回放设备102b与名为“sub”的回放设备102k绑定。前设备102b可以呈现中高频范围,而sub设备102k可以呈现低频,例如,重低音扬声器。当未绑定时,前设备102b可以被配置为呈现整个频率范围。作为另一示例,图3d示出了分别与右回放设备102a和左回放设备102j进一步绑定的前设备102b和sub设备102k。在一些实施方式中,右设备102a和左设备102j可以形成家庭影院系统的环绕或“卫星”声道。绑定的回放设备102a、102b、102j和102k可以形成单个d区(图3a)。
100.在一些实施方式中,回放设备也可以被“合并”。与某些绑定的回放设备相比,合并的回放设备可能没有分配回放职责,但可以分别呈现每个回放设备能够回放的音频内容的全部范围。然而,合并的设备可以被表示为单个ui实体(即,如上所述的区)。例如,图3e示出了客厅中的回放设备102d和102m的合并,这将导致这些设备由c区的单个ui实体表示。在一个实施例中,回放设备102d和102m可以同步回放音频,在此期间,每个回放设备输出每个相应的回放设备102d和102m能够呈现的完整范围的音频内容。
101.在一些实施例中,独立nmd本身可以在一个区中。例如,来自图1a的nmd 103h被命名为“壁橱”,并形成图3a中的i区。nmd也可以与其他设备绑定或合并,以形成区。例如,可以将名为“岛”的nmd设备103f与回放设备102i厨房绑定,两者一起形成f区,该f区也被命名为“厨房”。例如,在先前引用的美国专利申请no.15/438,749中可以找到关于将nmd和回放设备分配为指定设备或默认设备的附加细节。在一些实施例中,可以不将独立nmd分配给区。
102.单个、绑定和/或合并的设备的区可以被布置为形成一组同步回放音频的回放设备。这样的一组回放设备可以被称为“组”、“区组”、“同步组”或“回放组”。响应于通过控制器设备104提供的输入,可以动态地对回放设备进行分组和取消分组以形成同步回放音频内容的新的或不同的组。例如,参考图3a,a区可以与b区分在一组,以形成区组,该区组包括两个区的回放设备。作为另一示例,a区可以与一个或多个其他区c-i分在一组。a-i区可以以多种方式进行分组和取消分组。例如,可以将a-i区中的三个、四个、五个或更多个(例如,全部)分在一组。如先前参考的美国专利no.8,234,395中所述,当被分在一组时,单个和/或绑定的回放设备的区可以彼此同步地回放音频。分在一组并绑定的设备是便携和固定回放设备之间的关联的示例类型,其可以响应于触发事件而引起,如上文所讨论并且在下文更详细地描述。
103.在各种实施方式中,可以为环境中的区分配特定名称,该特定名称可以是区组内的区的默认名称或区组内的区的名称的组合,例如,如图3a所示的“餐厅 厨房”。在一些实施例中,还可以将区组命名为由用户选择的唯一名称,例如,如图3a所示的“尼克的房间”。名称“尼克的房间”可以是用户在该区组的先前名称上选择的名称,例如,房间名称“主卧室”。
104.再次参考图2a,某些数据可以作为一个或多个状态变量被存储在存储器213中,该状态变量被周期性地更新并且用于描述回放区、回放设备和/或关联的区组的状态。存储器213还可以包括与mps 100的其他设备的状态相关联的数据,其可以不时地在设备之间共享,使得一个或多个设备具有与该系统相关联的最新数据。
105.在一些实施例中,回放设备102的存储器213可以存储与状态相关联的各种变量类型的实例。变量实例可以与对应于类型的标识符(例如,标签)一起存储。例如,某些标识符可以是用于识别区的回放设备的第一类型“a1”、用于识别可以绑定在该区中的回放设备的第二类型“b1”和用于识别该区可能所属的区组的第三类型“c1”。作为相关示例,在图1a中,与露台相关联的标识符可以指示该露台是特定区的唯一回放设备,而不是在区组中。与客厅相关联的标识符可以指示该客厅没有与其他区分组,而是包括绑定的回放设备102a、102b、102j和102k。与餐厅相关联的标识符可以指示该餐厅是餐厅 厨房组的一部分,并且设备103f和102i被绑定。由于厨房是餐厅 厨房区组的一部分,因此与该厨房关联的标识符可以指示相同或相似的信息。其他示例区变量和标识符如下所述。
106.在又一示例中,如图3a所示,mps 100可以包括表示区和区组的其他关联的变量或标识符,例如,与区域相关联的标识符。区域可以涉及区组和/或不在区组内的区的集群。例如,图3a示出了名为“第一区域”的第一区域和名为“第二区域”的第二区域。第一区域包括露台、书房、餐厅、厨房和浴室的区和区组。第二区域包括浴室、尼克的房间、卧室和客厅的区和区组。在一个方面,区域可以用于调用区组和/或区的集群,其共享另一集群的一个或多个区和/或区组。在这方面,这样的区域不同于区组,该区组不与另一区组共享区。用于实现区域的技术的其他示例可以在例如2017年8月21日提交的题为“room association based on name”的美国申请no.15/682,506和2007年9月11日提交的题为“controlling and manipulating groupings in a multi-zone media system”的美国专利no.8,483,
853中找到。这些申请中的每一个通过引用整体并入本文。在一些实施例中,mps 100可以不实现区域,在这种情况下,系统可以不存储与区域相关联的变量。
107.存储器213还可以被配置为存储其他数据。这样的数据可以属于回放设备102可访问的音频源或该回放设备(或一些其他回放设备)可以与之关联的回放队列。在以下所述的实施例中,存储器213被配置为在处理语音输入时存储用于选择特定vas的一组命令数据。在操作过程中,图1a环境中的一个或多个回放区可能每个都在播放不同的音频内容。例如,用户可能正在露台区烧烤并收听由回放设备102c播放的嘻哈音乐,而另一用户可能正在厨房区中准备食物并收听由回放设备102i播放的古典音乐。在另一示例中,回放区可以与另一回放区同步地播放相同的音频内容。
108.例如,用户可以在办公室区中,其中,回放设备102n正在播放与露台区中的回放设备102c正在播放的嘻哈音乐相同的音乐。在这种情况下,回放设备102c和102n可以同步地播放嘻哈音乐,使得用户可以在不同回放区之间移动时无缝地(或者至少基本上无缝地)欣赏被外放的音频内容。如先前参考的美国专利no.8,234,395中所述,可以以类似于回放设备之间的同步的方式来实现回放区之间的同步。
109.如上所述,可以动态地修改mps 100的区配置。因此,mps 100可以支持多种配置。例如,如果用户将一个或多个回放设备物理地移入或移出区,则可以将mps 100重新配置以适应变化。例如,如果用户将回放设备102c从露台区物理地移动到办公室区,则办公室区现在可以包括回放设备102c和102n。在一些情况下,用户可以使用例如控制器设备104之一和/或语音输入来将移动的回放设备102c与办公室区配对或分在一组和/或重命名办公室区中的播放器。作为另一示例,如果将一个或多个回放设备102移动到家居环境中还不是回放区的特定空间,则可以将移动的回放设备重命名或与该特定空间的回放区相关联。
110.此外,mps 100的不同回放区可以被动态地组合成区组或划分成单独的回放区。例如,餐厅区和厨房区可以被组合成用于宴会的区组,使得回放设备102i和1021可以同步地呈现音频内容。作为另一示例,可以将书房区中的绑定的回放设备分为(i)电视区和(ii)独立的收听区。电视区可以包括前回放没备102b。收听区可以包括右回放设备102a、左回放设备102j和低音炮(sub)回放设备102k,如上所述,它们可以被组合、配对或合并。以这种方式划分书房区可以允许一个用户在客厅空间的一个区域中的收听区中收听音乐,而另一用户在客厅空间的另一区域中观看电视。在相关示例中,用户可以在将书房区划分为电视区和收听区之前,利用nmd 103a或103b(图1b)中的任何一个来控制书房区。一旦划分,可以例如由nmd 103a附近的用户控制收听区,并且可以例如由nmd 103b附近的用户控制电视区。然而,如上所述,任何nmd 103可以被配置为控制mps 100的各种回放设备和其他设备。
111.c.示例控制器设备
112.图4是示出了图1a的mps 100的所选控制器设备104中的一个的某些方面的功能框图。这样的控制器设备在本文中也可以被称为“控制设备”或“控制器”。图4中所示的控制器设备可以包括通常类似于上述网络设备的某些组件的组件,例如,处理器412、存储程序软件414的存储器413、至少一个网络接口424以及一个或多个麦克风422。在一个示例中,控制器设备可以是用于mps 100的专用控制器。在另一示例中,控制器设备可以是网络设备,例如,iphone
tm
、ipad
tm
或任何其他智能手机、平板电脑或网络设备(例如,网络计算机(例如,pc或mac
tm
)),可以在该网络设备上安装媒体回放系统控制器应用软件。
113.控制器设备104的存储器413可以被配置为存储控制器应用软件和与mps 100和/或系统100的用户相关联的其他数据。存储器413可以加载有软件414中的指令,该指令可由处理器412执行以实现某些功能,例如,促进mps 100的用户访问、控制和/或配置。如上所述,控制器设备104被配置为通过网络接口424与其他网络设备通信,该网络接口424可以采取无线接口的形式。
114.在一个示例中,系统信息(例如,状态变量)可以通过网络接口424在控制器设备104和其他设备之间传送。例如,控制器设备104可以从回放设备、nmd或另一网络设备接收mps 100中的回放区和区组配置。类似地,控制器设备104可以通过网络接口424向回放没备或另一网络设备发送这样的系统信息。在一些情况下,另一网络设备可以是另一控制器设备。
115.控制器设备104还可以经由网络接口424向回放设备传送回放设备控制命令,例如,音量控制和音频回放控制。如上所述,也可以由用户使用控制器设备104来执行对mps 100的配置更改。配置更改可以包括:将一个或多个回放设备添加到区/从区中删除;将一个或多个区添加到区组/从区组中删除;形成绑定或合并的播放器;将一个或多个回放设备与绑定或合并的播放器分离等。
116.如图4所示,控制器设备104还包括用户界面440,该用户界面440通常被配置为促进用户对mps 100的访问和控制。用户界面440可以包括触摸屏显示器或其他物理界面,例如,图5a和5b中所示的控制器界面540a和540b,该触摸屏显示器或其他物理界面被配置为提供各种图形控制器界面。一起参考图5a和图5b,控制器界面540a和540b包括回放控制区域542、回放区区域543、回放状态区域544、回放队列区域546和源区域548。所示的用户界面仅是可以在网络设备(例如,图4所示的控制器设备)上提供、并且由用户访问以控制媒体回放系统(例如,mps 100)的界面的一个示例。备选地,可以在一个或多个网络设备上实现变化的格式、样式和交互序列的其他用户界面,以提供对媒体回放系统的类似的控制访问。
117.回放控制区域542(图5a)可以包括可选择图标(例如,通过触摸或通过使用光标),当其被选择时,使所选择的回放区或区组中的回放设备播放或暂停、快进、快退、跳到下一个、跳到前一个、进入/退出随机播放模式、进入/退出重复模式、进入/退出交叉淡入淡出模式等。回放控制区域542还可以包括可选择图标,当其被选择时,修改均衡设置、回放音量等。
118.回放区区域543(图5b)可以包括mps 100内的回放区的表示。如图所示,回放区区域543还可以包括区组的表示,例如,餐厅 厨房区组。
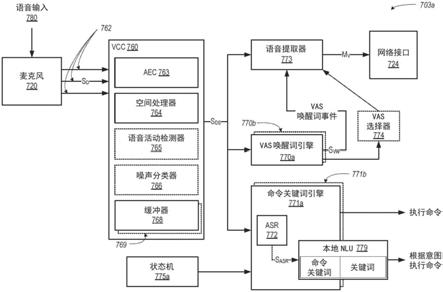
119.在一些实施例中,回放区的图形表示可以是可选择的,以调出附加的可选择图标来管理或配置mps 100中的回放区,例如,绑定区的创建、区组的创建、区组的分离以及区组的重命名等。
120.例如,如图所示,可以在回放区的每个图形表示内提供“分组”图标。在特定区的图形表示内提供的“分组”图标可以是可选择的,以调出用于选择要与特定区分在一组的mps 100中的一个或多个其他区的选项。一旦被分组,已经与特定区分在一组的区中的回放设备将被配置为与该特定区中的回放设备同步地播放音频内容。类似地,可以在区组的图形表示内提供“分组”图标。在这种情况下,“分组”图标可以是可选择的,以调出用于取消选择区组中的要从该区组中移除的一个或多个区的选项。通过用户界面对区进行分组和取消分组
的其他交互和实现也是可能的。当回放区或区组配置被修改时,可以动态地更新回放区区域543(图5b)中的回放区的表示。
121.回放状态区域544(图5a)可以包括在所选择的回放区或区组中当前正在播放、先前播放或被安排为接下来播放的音频内容的图形表示。可以在用户界面上可视地区分所选择的回放区或区组,例如,在回放区区域543和/或回放状态区域544内。图形表示可以包括曲目标题、艺术家姓名、专辑名称、专辑年份、曲目长度和/或其他相关信息,当用户通过控制器界面控制mps 100时,这些信息可能对用户有用。
122.回放队列区域546可以包括与所选择的回放区或区组相关联的回放队列中的音频内容的图形表示。在一些实施例中,每个回放区或区组可以与回放队列相关联,该回放队列包括与该回放区或区组回放的零个或多个音频项相对应的信息。例如,回放队列中的每个音频项可以包括统一资源标识符(uri)、统一资源定位符(url)或一些其他标识符,该其他标识符可以由回放区或区组中的回放设备用于从本地音频内容源或网络音频内容源查找和检索音频项,然后可以由回放设备回放该音频项。
123.在一个示例中,可以将播放列表添加到回放队列,在这种情况下,可以将与播放列表中的每个音频项对应的信息添加到回放队列。在另一示例中,回放队列中的音频项可以被保存为播放列表。在另一示例中,当回放区或区组正在连续播放流式音频内容(例如,互联网收音机,其可以持续播放直到被停止),而不是具有回放持续时间的分立音频项时,回放队列可以为空或被填充但“未使用”。在替代实施例中,回放队列可以包括互联网收音机和/或其他流音频内容项,并且当回放区或区组正在播放这些项时处于“使用中”。其他示例也是可能的。
124.当回放区或区组被“分组”或“取消分组”时,可以清除与受影响的回放区或区组相关联的回放队列,或者重新关联。例如,如果包括第一回放队列的第一回放区与包括第二回放队列的第二回放区被分在一组,则所建立的区组可以具有相关联的回放队列,其最初是空的,包含来自第一回放队列的音频项(例如,如果第二回放区被添加到第一回放区),或包含来自第二回放队列的音频项(例如,如果第一回放区被添加到第二回放区),或包含来自第一回放队列和第二回放队列二者的音频项的组合。随后,如果所建立的区组被取消分组,则所得到的第一回放区可以与先前的第一回放队列重新关联,或者与新的回放队列相关联,该新的回放队列是空的,或者包含与来自在所建立的区组被取消分组之前所建立的区组相关联的回放队列的音频项。类似地,所得到的第二回放区可以与先前的第二回放队列重新关联,或者与新的回放队列相关联,该新的回放队列是空的,或者包含来自在与所建立的区组被取消分组之前所建立的区组相关联的回放队列的音频项。其他示例也是可能的。
125.仍然参考图5a和5b,回放队列区域646(图5a)中的音频内容的图形表示可以包括曲目标题、艺术家名称、曲目长度以及与回放队列中的音频内容相关联的其他相关信息。在一个示例中,音频内容的图形表示可以是可选择的,以调出附加的可选择图标来管理和/或操纵回放队列和/或回放队列中表示的音频内容。例如,可以将所表示的音频内容从回放队列中移除,将所表示的音频内容移动到回放队列内的不同位置,或者选择所表示的音频内容以立即播放,或者在任何当前播放的音频内容之后进行播放等。与回放区或区组相关联的回放队列可以存储于该回放区或区组中的一个或多个回放设备上、不在该回放区或区组中的回放设备上和/或一些其他指定设备上的存储器中。这种回放队列的回放可以涉及一
个或多个回放设备可能按顺序或随机顺序回放队列中的媒体项。
126.源区域548可以包括与对应的vas相关联的可选择音频内容源和/或可选择语音助手的图形表示。可以选择性地分配vas。在一些示例中,同一nmd可以调用多个vas,例如,amazon的alexa、microsoft的cortana等。在一些实施例中,用户可以将vas专门分配给一个或多个nmd。例如,用户可以将第一vas分配给图1a所示的客厅中的nmd 102a和102b中的一个或两个,并将第二vas分配给厨房中的nmd 103f。其他示例是可能。
127.d.示例音频内容源
128.源区域548中的音频源可以是音频内容源,可以通过所选择的回放区或区组从该音频内容源中获取音频内容并播放。区或区组中的一个或多个回放设备可以被配置为从各种可用音频内容源中获取回放音频内容(例如,根据音频内容的对应uri或url)。在一个示例中,回放设备可以直接从对应的音频内容源(例如,通过线路输入连接)中检索音频内容。在另一示例中,可以在网络上,经由一个或多个其他回放设备或网络设备向回放设备提供音频内容。如下文更详细描述的,在一些实施例中,音频内容可以由一个或多个媒体内容服务提供。
129.示例音频内容源可以包括:媒体回放系统(例如,图1的mps 100)中的一个或多个回放设备的存储器、一个或多个网络设备(例如,控制器设备、启用网络的个人计算机或附接网络的存储器(“nas”))上的本地音乐库、通过互联网(例如,基于云的音乐服务)提供音频内容的流式音频服务、或者通过回放设备或网络设备上的线路输入连接连接至媒体回放系统的音频源等。
130.在一些实施例中,可以从媒体回放系统(例如,图1a的mps 100)中添加或移除音频内容源。在一个示例中,每当添加、移除或更新一个或多个音频内容源时,可以执行对音频项编索引。对音频项编索引可以包括:扫描由媒体回放系统中的回放设备可访问的网络上共享的所有文件夹/目录中的可识别音频项,并且生成或更新包括元数据(例如,标题、艺术家、专辑、曲目长度等)及其他关联信息(例如,找到的每个可识别音频项的uri或url)的音频内容数据库。用于管理和维护音频内容源的其他示例也是可能的。
131.图6是示出了mps 100的设备之间的数据交换的消息流程图。在步骤650a处,mps 100经由控制设备104接收对所选媒体内容(例如,一个或多个歌曲、专辑、播放列表、播客、视频、电台)的指示。所选媒体内容可以包括例如本地存储在连接到媒体回放系统的一个或多个设备(例如,图1c的音频源105)上的媒体项和/或存储在一个或多个媒体服务服务器(图1b的一个或多个远程计算设备106)上的媒体项。响应于接收到对所选媒体内容的指示,控制设备104向回放设备102发送消息651a(图1a-图1c),以将所选媒体内容添加到回放设备102上的回放队列。
132.在步骤650b处,回放设备102接收消息651a,并将所选媒体内容添加到回放队列以进行回放。
133.在步骤650c处,控制设备104接收与回放所选媒体内容的命令相对应的输入。响应于接收到与回放所选媒体内容的命令相对应的输入,控制设备104向回放设备102发送消息651b,使回放设备102回放所选媒体内容。响应于接收到消息651b,回放设备102向计算设备106发送消息651c,以请求所选媒体内容。响应于接收到消息651c,计算设备106发送消息651d,该消息651d包括与所请求的媒体内容相对应的数据(例如,音频数据、视频数据、url、
uri)。
134.在步骤650d处,回放设备102接收具有与所请求的媒体内容相对应的数据的消息651d,并回放相关联的媒体内容。
135.在步骤650e处,回放设备102可选地使一个或多个其他设备回放所选媒体内容。在一个示例中,回放设备102是两个或更多个播放器的绑定区之一(图1m)。回放设备102可以接收所选媒体内容,并向绑定区中的其他设备发送媒体内容的全部或一部分。在另一示例中,回放设备102是组的协调器,并且被配置为从组中的一个或多个其他设备发送和接收定时信息。组中的其他一个或多个设备可以从计算设备106接收所选媒体内容,并响应于来自回放设备102的消息开始回放所选媒体内容,使得组中的所有设备同步回放所选媒体内容。
136.iii.示例命令关键词事件
137.图7a和图7b是示出了根据本公开的实施例配置的nmd 703a和nmd 703的各方面的功能框图。nmd 703a和nmd 703b统称为nmd 703。nmd 703通常可以类似于nmd 103,并且包括类似的组件。如以下更详细描述的,nmd 703a(图7a)被配置为在本地处理某些语音输入,而不必向语音助手服务发送表示语音输入的数据。然而,nmd 703a还被配置为使用语音助手服务处理其他语音输入。nmd 703b(图7b)被配置为使用语音助手服务处理语音输入,并且可以具有有限的本地nlu或命令关键词检测,或者没有本地nlu或命令关键词检测。
138.参照图7a,nmd 703包括语音捕捉组件(“vcc”)760、vas唤醒词引擎770a和语音提取器773。vas唤醒词引擎770a和语音提取器773可操作地耦合到vcc 760。nmd 703a还包括可操作地耦合到vcc 760的命令关键词引擎771a。
139.nmd 703还包括上述麦克风720和至少一个网络接口720,并且还可以包括其他组件,例如,音频放大器、扬声器、用户界面等,为清楚起见该其他组件未在图7a中示出。nmd 703a的麦克风720被配置为从nmd 703的环境向vcc 760提供检测到的声音sd。检测到的声音sd可以采用一个或多个模拟或数字信号的形式。在示例实施方式中,检测到的声音sd可以由与馈送到vcc 760的各个声道762相关联的多个信号组成。
140.每个声道762可以对应于特定的麦克风720。例如,具有六个麦克风的nmd可以具有六个对应的声道。检测到的声音sd的每个声道可以与其他声道具有某些相似性,但在某些方面可能有所不同,这可能是由于给定声道的相应麦克风相对于其他声道的麦克风的位置。例如,检测到的声音sd的一个或多个声道可以具有比其他声道更大的话音与背景噪声的信噪比(“snr”)。
141.如图7a进一步所示,vcc 760包括aec 763、空间处理器764和一个或多个缓冲器768。在操作中,aec 763接收检测到的声音sd并过滤或以其他方式处理该声音以抑制回声和/或改善检测到的声音sd的质量。然后可以向空间处理器764传递该处理后的声音。
142.空间处理器764通常被配置为分析检测到的声音sd并识别某些特性,例如,声音的幅度(例如,分贝级)、频谱、方向性等。一方面,如上所述,空间处理器764可以基于所检测到的声音sd的组成声道762的相似性和差异性来帮助过滤或抑制所检测到的来自潜在用户语音的声音sd中的周围环境噪声。作为一种可能性,空间处理器764可以监视将语音与其他声音区分开的度量。例如,这种度量可以包括语音带内相对于背景噪声的能量以及该语音带内的熵(频谱结构的一种测量),该语音带内的熵通常比大多数常见背景噪声低。在一些实施方式中,空间处理器764可以被配置为确定语音存在概率,这种功能的示例在2018年5月
18日提交的题为“linear filtering for noise-suppressed speech detection”的美国专利申请no.15/984,073中公开,其全部内容通过引用并入本文。
143.在操作中,一个或多个缓冲器768(其中一个或多个可以是存储器213(图2a)的一部分或与之分离)捕捉与检测到的声音sd相对应的数据。更具体地说,一个或多个缓冲器768捕捉由上游aec 764和空间处理器766处理的检测到的声音数据。
144.然后,网络接口724可以向可以与mps 100相关联的远程服务器提供该信息。在一个方面中,存储在附加缓冲器769中的信息不揭示任何话音的内容,而是指示检测到的声音本身的某些独特特征。在相关方面中,可以在诸如mps 100的各种计算设备之类的计算设备之间传送信息,而不必涉及隐私问题。在实践中,mps 100可以使用该信息来调整和微调语音处理算法,包括如下所述的灵敏度调谐。在一些实施方式中,附加缓冲器可以包含或包括类似于例如在2018年5月25日提交的题为“determining and adapting to changes in microphone performance of playback devices”的美国专利申请no.15/989,715;2018年9月25日提交的题为“voice detection optimization based on selected voice assistant service”的美国专利申请no.16/141,875;以及2018年9月21日提交的题为“voice detection optimization using sound metadata”的美国专利申请no.16/138,111中公开的回溯缓冲器的功能,这些申请通过引用整体并入本文。
145.在任何事件中,检测到的声音数据形成由麦克风720检测到的声音的数字表示(即,声音数据流)s
ds
。在实践中,声音数据流s
ds
可以采用多种形式。作为一种可能性,声音数据流s
ds
可以由帧组成,每个帧可以包括一个或多个声音样本。可以从一个或多个缓冲器768流式传输(即,读出)帧,以由下游组件(例如,nmd 703的vas唤醒词引擎770和语音提取器773)进行进一步处理。
146.在一些实施方式中,至少一个缓冲器768利用滑动窗口方法来捕捉检测到的声音数据,其中,在至少一个缓冲器768中保留给定数量(即,给定窗口)的最新捕捉的检测到的声音数据,而当较旧的检测到的声音数据落在窗口之外时,它们将被覆写。例如,至少一个缓冲器768可以在给定时间临时保留20个声音样本的帧,在到期时间之后丢弃最旧的帧,然后捕捉新的帧,将其添加到声音样本的19个先前帧中。
147.在实践中,当声音数据流s
ds
由帧组成时,这些帧可以采用具有各种特性的各种形式。作为一种可能性,这些帧可以采用具有一定分辨率(例如,16比特分辨率)的音频帧的形式,该分辨率可以基于采样率(例如,44,100hz)。附加地或备选地,这些帧可以包括与这些帧定义的给定声音样本相对应的信息,例如,元数据,该元数据指示频率响应、功率输入电平、snr、麦克风声道标识和/或给定声音样本的其他信息,以及其他示例。因此,在一些实施例中,帧可以包括声音的一部分(例如,给定声音样本的一个或多个样本)和关于声音的一部分的元数据。在其他实施例中,帧可以仅包括声音的一部分(例如,给定声音样本的一个或多个样本)或关于声音的一部分的元数据。
148.在任何情况下,nmd 703的下游组件可以处理声音数据流s
ds
。例如,vas唤醒词引擎770可以被配置为将一种或多种识别算法应用于声音数据流s
ds
(例如,流声音帧),以在检测到的声音sd中发现潜在唤醒词。该过程可以称为自动话音识别。vas唤醒词引擎770a和命令关键词引擎771a应用与它们各自的唤醒词相对应的不同识别算法,并且还基于在检测到的声音sd中检测到唤醒词而生成不同事件。
149.示例唤醒词检测算法接受音频作为输入,并且提供在该音频中是否存在唤醒词的指示。许多第一方和第三方唤醒词检测算法是已知的并且可商购的。例如,语音服务的运营商可以使其算法可用于第三方设备。备选地,可以训练算法以检测某些唤醒词。
150.例如,当vas唤醒词引擎770a检测到潜在vas唤醒词时,vas唤醒词引擎770a提供“vas唤醒词事件”(也称为“vas唤醒词触发”)的指示。在图7a的所示示例中,vas唤醒词引擎770a向语音提取器773输出指示vas唤醒词事件发生的信号s
vw
。
151.在多vas实施方式中,nmd 703可以包括vas选择器774(以虚线示出),该vas选择器774通常被配置为:当给定的唤醒词由特定唤醒词引擎(以及相应的唤醒词触发器)(例如,vas唤醒词引擎770a和至少一个附加的vas唤醒词引擎770b(以虚线示出))识别时,由语音提取器773直接提取,并向适当的vas传输声音数据流s
ds
。在这样的实施方式中,nmd 703可以包括多个不同的vas唤醒词引擎和/或语音提取器,每一个都由相应的vas支持。
152.与以上讨论类似,每个vas唤醒词引擎770可以被配置为从一个或多个缓冲器768接收声音数据流s
ds
作为输入,并且应用识别算法为适当的vas引起唤醒词触发。因此,作为一个示例,vas唤醒词引擎770a可以被配置为识别唤醒词“alexa”,并且当发现“alexa”时使nmd 703a调用amazon vas。作为另一示例,唤醒词引擎770b可以被配置为识别唤醒词“ok,google”,并且当发现“ok,google”时使nmd 520调用google vas。在单个vas实施方式中,可以省略vas选择器774。
153.响应于vas唤醒词事件(例如,响应于指示唤醒词事件的信号s
vw
),语音提取器773被配置为接收和格式化(例如,封装)声音数据流s
ds
。例如,语音提取器773将声音数据流s
ds
的帧封装成消息。语音提取器773经由网络接口724向远程vas发送或流式传输可能包含实时或接近实时语音输入的这些消息mv。
154.该vas被配置为处理从nmd 703发送的消息mv中包含的声音数据流s
ds
。更具体地说,nmd 703a被配置为基于声音数据流s
ds
来识别语音输入780。如结合图2c所述,语音输入780可以包括关键词部分和话语部分。关键词部分对应于检测到的引起唤醒词事件的声音,或者当满足一个或多个特定条件(例如,特定回放条件)时导致命令关键词事件。例如,当语音输入780包括vas唤醒词时,关键词部分对应于检测到的使唤醒词引擎770a将唤醒词事件信号svw输出到语音提取器773的声音。在这种情况下,话语部分对应于检测到的声音,该检测到的声音潜在地包括跟随关键词部分的用户请求。
155.当vas唤醒词事件发生时,vas可以首先处理声音数据流s
ds
内的关键词部分以验证vas唤醒词的存在。在一些实例中,vas可以确定关键词部分包括错误的唤醒词(例如,当单词“alexa”是目标vas唤醒词时,单词“election”)。在这种情况下,vas可以向nmd 703a发送响应,指示nmd 703a停止提取声音数据,这导致语音提取器773停止检测到的声音数据向vas的进一步流式传输。vas唤醒词引擎770a可以恢复或继续监视声音样本,直到它发现导致另一vas唤醒词事件的另一潜在vas唤醒词。在一些实施方式中,vas不处理或接收关键词部分,而是仅处理话语部分。
156.在任何情况下,vas处理话语部分以识别在检测到的声音数据中任何单词的存在并从这些单词确定潜在意图。这些单词可以对应于一个或多个命令,以及某些关键词。关键词可以是例如语音输入中的识别mps 100中特定设备或分组的词。例如,在所示的示例中,关键词可以是识别要在其中播放音乐的一个或多个区(例如,客厅和餐厅(图1a))的一个或
多个单词。
157.为了确定单词的意图,vas通常与和vas(未示出)关联的一个或多个数据库和/或mps 100的一个或多个数据库(未示出)进行通信。这样的数据库可以存储多种用户数据、分析、目录和其他信息以用于自然语言处理和/或其他处理。在一些实施方式中,可以基于语音输入处理来更新这样的数据库以用于神经网络的自适应学习和反馈。在一些情况下,话语部分可以包括附加信息,例如,检测到的用户说出的单词之间的停顿(例如,非语音的时间段),如图2c所示。该停顿可以在话语部分内划分由用户说出的单独命令、关键词或其他信息的位置。
158.在处理语音输入之后,vas可以基于其从语音输入确定的意图,向mps 100发送具有指令的响应以执行一个或多个动作。例如,基于语音输入,vas可以指导mps 100在一个或多个回放设备102上发起回放、控制这些回放设备102中的一个或多个(例如,提高/降低音量、分组/取消分组设备等)、或打开/关闭某些智能设备以及其他动作。如以上所讨论的,在接收到来自vas的响应之后,nmd 703的唤醒词引擎770a可以恢复或继续监视声音数据流s
ds1
,直到它发现另一潜在唤醒词为止。
159.通常,特定vas唤醒词引擎(例如,vas唤醒词引擎770a)应用的一种或多种识别算法被配置为分析检测到的声音流s
ds
的某些特性,并将这些特性与特定vas唤醒词引擎的一个或多个特定vas唤醒词的相应特性进行比较。例如,唤醒词引擎770a可以应用一种或多种识别算法来发现检测到的声音流s
ds
中与引擎的一个或多个唤醒词的频谱特性相匹配的频谱特性,从而确定检测到的声音sd包括包含特定的vas唤醒词的语音输入。
160.在一些实施方式中,一种或多种识别算法可以是第三方识别算法(即,由提供nmd 703a的公司以外的公司开发的识别算法)。例如,语音服务(例如,amazon)的运营商可以使他们各自的算法(例如,与amazon的alexa相对应的识别算法)可用于第三方设备(例如,nmd 103),然后对其进行训练以识别特定语音助手服务的一个或多个唤醒词。附加地或备选地,一种或多种识别算法可以是第一方识别算法,其被开发和训练以识别不一定特定于给定语音服务的某些唤醒词。还存在其他可能性。
161.如上所述,nmd 703a还包括与vas唤醒词引擎770a并行的命令关键词引擎771a。与vas唤醒词引擎770a类似,命令关键词引擎771a可以应用与一个或多个唤醒词相对应的一种或多种识别算法。当在检测到的声音sd中识别出特定的命令关键词时,生成“命令关键词事件”。与通常用作vas唤醒词的随机词相比,命令关键词既作为激活词又作为命令本身。例如,示例命令关键词可以对应于回放命令(例如,“播放”、“暂停”、“跳过”等)以及控制命令(“打开”)等。在适当的条件下,基于检测到这些命令关键词之一,nmd 703a执行对应的命令。
162.命令关键词引擎771a可以使用自动话音识别器772。asr 772被配置为基于声音数据流s
ds
中的声音向文本输出拼音或表型表示,例如,与单词相对应的文本。例如,asr 772可以将声音数据流s
ds
中表示的口语单词转录为将语音输入780表示为文本的一个或多个字符串。命令关键词引擎771可以将asr输出(标记为s
asr
)馈送到本地自然语言单元(nlu)779,该本地自然语言单元(nlu)779将特定关键词识别为用于调用命令关键词事件的命令关键词,如下所述。
163.如上所述,在一些示例实施方式中,nmd 703a被配置为执行自然语言处理,自然语
言处理可以使用板载自然语言处理器来执行,自然语言处理器在本文中被称为自然语言单元(nlu)779。本地nlu 779被配置为分析命令关键词引擎771a的asr 772的文本输出,以发现(即,检测或识别)语音输入780中的关键词。在图7a中,该输出被示出为信号s
asr
。本地nlu 779包括与相应命令和/或参数相对应的关键词(即,单词和短语)库。
164.在一个方面中,本地nlu 779的库包括命令关键词。当本地nlu 779识别出信号s
asr
中的命令关键词时,命令关键词引擎771a生成命令关键词事件,并执行与信号s
asr
中的命令关键词相对应的命令(假设满足与该命令关键词相对应的一个或多个条件)。
165.此外,本地nlu 779的库还可以包括与参数相对应的关键词。然后,本地nlu 779可以从语音输入780中的匹配关键词确定潜在意图。例如,如果本地nlu结合播放命令匹配关键词“大卫鲍伊”和“厨房”,则本地nlu 779可以确定在厨房101h中在回放设备102i上播放大卫鲍伊的意图。与基于云的vas对语音输入780的处理相比,本地nlu 779对语音输入780的本地处理可以相对不那么复杂,因为nlu 779无法访问相对更大的处理能力和vas通常可以访问的更大的语音数据库。
166.在一些示例中,本地nlu 779可以确定具有一个或多个时隙(slot)的意图,该一个或多个时隙对应于相应的关键词。例如,返回参照厨房示例中的播放大卫鲍伊,当处理语音输入时,本地nlu 779可以确定意图是播放音乐(例如,意图=播放音乐),而第一时隙包括大卫鲍伊作为目标内容(例如,时隙1=大卫鲍伊),并且第二时隙包括厨房101h作为目标回放设备(例如,时隙2=厨房)。这里,意图(“播放音乐”)基于命令关键词,并且时隙是修改特定目标内容和回放设备的意图的参数。
167.在示例中,命令关键词引擎771a向本地nlu 779输出指示命令关键词事件发生的信号s
cw
。响应于命令关键词事件(例如,响应于指示命令关键词事件的信号s
cw
),本地nlu 779被配置为接收和处理信号s
asr
。具体地,本地nlu 779查看信号s
asr
中的单词以查找与本地nlu 779的库中的关键词匹配的关键词。
168.预计在执行本地自动语音识别时的一些错误。在示例中,asr 772可以在将口语单词转录成文本时生成置信度分数,该置信度分数指示语音输入780中的口语单词与该单词的声音模式的匹配程度。在一些实施方式中,生成命令关键词事件基于给定命令关键词的置信度分数。例如,命令关键词引擎771a可以在给定声音的置信度分数超过给定阈值(例如,0-1标度内的0.5,指示给定声音更有可能是命令关键词)时生成命令关键词事件。相反地,当给定声音的置信度分数等于或低于给定阈值时,命令关键词引擎771a不生成命令关键词事件。
169.类似地,预计在执行关键词匹配时的一些错误。在示例中,本地nlu可以在确定意图时生成置信度分数,该置信度分数指示信号s
asr
中的转录单词与本地nlu的库中的对应关键词的匹配程度。在一些实施方式中,根据确定的意图执行操作基于在信号s
asr
中匹配的关键词的置信度分数。例如,nmd 703可以在给定声音的置信度分数超过给定阈值(例如,0-1标度内的0.5,指示给定声音更有可能是命令关键词)时,根据确定的意图执行操作。相反地,当给定声音的置信度分数等于或低于给定阈值时,nmd 703不根据确定的意图执行操作。
170.如上所述,在一些实施方式中,短语可以用作命令关键词,其提供附加的音节来匹配(或不匹配)。例如,短语“给我放点音乐”比“播放”有更多音节,其提供了附加的声音模式
来匹配单词。因此,作为短语的命令关键词通常可能不太容易出现虚假唤醒词。
171.如上所述,nmd 703a可以仅在满足与检测到的命令关键词相对应的某些条件时才生成命令关键词事件(并执行与检测到的命令关键词相对应的命令)。这些条件旨在降低误报命令关键词事件的发生率。例如,在检测到命令关键词“跳过”之后,nmd 703a仅在满足指示应该执行跳过的某些回放条件时才生成命令关键词事件(并跳到下一个曲目)。这些回放条件可以包括:例如,(i)正在回放媒体项的第一条件;(ii)队列处于活动状态的第二条件;以及(iii)队列包括正在回放的媒体项之后的媒体项的第三条件。如果不满足这些条件中的任何一个,则不会生成命令关键词事件(并且不执行跳过)。
172.nmd 703a包括一个或多个状态机775a以便于确定是否满足适当的条件。状态机775a基于是否满足与检测到的命令关键词相对应的一个或多个条件,在第一状态和第二状态之间转换。具体地,对于与需要一个或多个特定条件的特定命令相对应的给定命令关键词,状态机775a在满足一个或多个特定条件时转换到第一状态,并且在不满足一个或多个特定条件中的至少一个条件时转换到第二状态。
173.在示例实施方式中,命令条件基于状态变量中指示的状态。如上所述,mps 100的设备可以存储描述相应设备的状态的状态变量。例如,回放设备102可以存储指示回放设备102的状态的状态变量,例如,当前播放(或暂停)的音频内容、音量级别、网络连接状态等。这些状态变量被更新(例如,周期性地,或基于事件(即,当状态变量中的状态变化时)),并且状态变量还可以在mps 100的设备(包括nmd 703)之间共享。
174.类似地,nmd 703可以维护这些状态变量(通过在回放设备中实现或作为独立的nmd)。状态机775a监视在这些状态变量中指示的状态,并确定在适当的状态变量中指示的状态是否指示满足命令条件。基于这些确定,状态机775a在第一状态和第二状态之间转换,如上所述。
175.在一些实施方式中,可以禁用命令关键词引擎771,除非已经经由状态机满足了某些条件。例如,状态机775a的第一状态和第二状态可以作为对命令关键词引擎771a的启用/禁用切换来操作。具体地,当与特定命令关键词相对应的状态机775a处于第一状态时,状态机775a启用特定命令关键词的命令关键词引擎771a。相反地,当与特定命令关键词相对应的状态机775a处于第二状态时,状态机775a禁用特定命令关键词的命令关键词引擎771a。因此,禁用的命令关键词引擎771a停止分析声音数据流s
ds
。在不满足至少一个命令条件的这种情况下,当命令关键词引擎771a检测到命令关键词时,nmd 703a可以抑制命令关键词事件的生成。抑制生成可以涉及选通、阻塞或以其他方式防止来自命令关键词引擎771a的输出生成命令关键词事件。备选地,抑制生成可以涉及nmd 703停止将声音数据流s
ds
馈送到asr772。这种抑制防止在不满足至少一个命令条件时执行与检测到的命令关键词相对应的命令。在这样的实施例中,命令关键词引擎771a可以在状态机775a处于第一状态时继续分析声音数据流s
ds
,但是命令关键词事件被禁用。
176.其他示例条件可以基于语音活动检测器(“vad”)765的输出。vad 765被配置为检测声音数据流s
ds
中语音活动的存在(或不存在)。具体地,vad 765可以用一种或多种语音检测算法分析与语音输入780(图2d)的前滚动部分相对应的帧,以确定在语音输入780的关键词部分之前的某些时间窗口中的环境中是否存在语音活动。
177.vad 765可以利用任何合适的语音活动检测算法。示例语音检测算法涉及确定给
定帧是否包括对应于语音活动的一个或多个特征或质量,并且还确定这些特征或质量是否从噪声叉开给定程度(例如,如果值超过给定帧的阈值)。一些示例语音检测算法涉及在识别特征或质量之前过滤或以其他方式减少帧中的噪声。
178.在一些示例中,vad 765可以基于一个或多个度量来确定环境中是否存在语音活动。例如,vad 765可以被配置为区分包括语音活动的帧和不包括语音活动的帧。vad确定有语音活动的帧可能是由话音引起的,无论其是近场还是远场。在该示例和其他示例中,vad 765可以确定在语音输入780的前滚动部分中指示语音活动的帧的计数。如果该计数超过阈值百分比或帧数,则vad 765可以被配置为输出信号或设置状态变量以指示环境中存在语音活动。除了这种计数之外,或者作为这种计数的备选,也可以使用其他度量。
179.环境中语音活动的存在可以指示语音输入被定向到nmd 73。因此,当vad 765指示环境中不存在语音活动时(可能由vad 765设置的状态变量指示),这可以被配置为命令关键词的命令条件之一。当满足该条件时(即,vad 765指示环境中存在语音活动),状态机775a将转换到第一状态以启用基于命令关键词执行命令,只要满足针对特定命令关键字词的任何其他条件。
180.此外,在一些实施方式中,nmd 703可以包括噪声分类器766。噪声分类器766被配置为确定声音元数据(频率响应、信号电平等),并识别声音元数据中与各种噪声源相对应的签名。噪声分类器766可以包括被配置为识别所检测到的声音数据或元数据中的不同类型噪声的神经网络或其他数学模型。噪声的一种分类可以是话音(例如,远场话音)。另一种分类可以是特定类型的话音(例如,背景话音),并且参照图8更详细地描述了其示例。背景话音可以与其他类型的类语音活动(例如,由vad 765检测到的类语音活动的更一般的语音活动(例如,节奏、停顿或其他特性))区分开来。
181.例如,分析声音元数据可以包括:将声音元数据的一个或多个特征与已知噪声参考值进行比较,或将样本群体数据与已知噪声进行比较。例如,声音元数据的任何特征(例如,信号电平、频率响应谱等)都可以与噪声参考值或在样本群体上收集和平均的值进行比较。在一些示例中,分析声音元数据包括:将频率响应谱投影到对应于来自群体nmd的聚合频率响应谱的特征空间上。此外,可以执行将频率响应谱投影到特征空间上作为预处理步骤以促进下游分类。
182.在各种实施例中,可以使用用于使用声音元数据对噪声进行分类的任何数量的不同技术,例如,使用决策树的机器学习、或贝叶斯分类器、神经网络或任何其他分类技术。备选地或附加地,可以使用各种聚类技术,例如,k-means聚类、均值偏移聚类、期望最大化聚类或任何其他合适的聚类技术。对噪声进行分类的技术可以包括在2018年12月20日提交的题为“optimization of network microphone devices using noise classification”的美国申请no.16/227,308中公开的一种或多种技术,该申请通过引用整体并入本文。
183.为了说明,图8示出了第一曲线882a和第二曲线882b。第一曲线882a和第二曲线882b示出了与背景话音相关联的分析的声音元数据。曲线中所示的这些签名是使用主分量分析(pca)生成的。从各种nmd收集到的数据提供可能的频率响应谱的整体分布。通常,主分量分析可以用于找到描述所有现场数据的方差的正交基。该特征空间反映在图8的各曲线图中所示的轮廓中。曲线中的每个点表示投影到特征空间上的已知噪声值(例如,来自暴露于指定噪声源的nmd的单个频率响应谱)。如图8所示,这些已知噪声值在被投影到特征空间
上时聚集在一起。在该示例中,图8的曲线表示四向量分析,其中每个向量对应于相应的特征。这些特征共同是背景话音的签名。
184.返回参考图7a,在一些实施方式中,附加缓冲器769(以虚线示出)可以存储关于由上游aec 763和空间处理器764处理的检测到的声音sd的信息(例如,元数据等)。该附加缓冲器769可以被称为“声音元数据缓冲器”。这种声音元数据的示例包括:(1)频率响应数据,(2)回声回波损耗增强测量,(3)语音方向测量;(4)仲裁统计;和/或(5)话音频谱数据。在示例实施方式中,噪声分类器766可以分析缓冲器769中的声音元数据,以对检测到的声音sd中的噪声进行分类。
185.如上所述,声音的一种分类可以是背景话音,例如,指示远场话音的话音和/或指示不涉及nmd 703的对话的话音。噪声分类器766可以输出信号和/或设置状态变量以指示环境中存在背景话音。语音输入780的前滚动部分中的语音活动(即,语音)的存在指示语音输入780可能不定向到nmd 703,而是环境内的会话话音。例如,家庭成员可能会说“我们的孩子应该很快有一个玩耍约会”之类的话,而不旨在将命令关键词“玩耍(play)”定向到nmd 703。
186.此外,当噪声分类器指示环境中存在背景话音时,该条件可以禁用命令关键词引擎771a。在一些实施方式中,环境中不存在背景话音的条件(可能由噪声分类器766设置的状态变量指示)被配置为命令关键词的命令条件之一。因此,当噪声分类器766指示环境中存在背景话音时,状态机775a将不会转换到第一状态。
187.此外,噪声分类器766可以基于一个或多个度量来确定环境中是否存在背景话音。例如,噪声分类器766可以确定语音输入780的前滚动部分中指示背景话音的帧的计数。如果该计数超过阈值百分比或帧数,则噪声分类器766可以被配置为输出信号或设置状态变量以指示环境中存在背景话音。除了这种计数之外,或者作为这种计数的备选,也可以使用其他度量。
188.在示例实施方式中,nmd 703a可以支持多个命令关键词。为了促进这种支持,命令关键词引擎771a可以实现与相应的命令关键词相对应的多种识别算法。备选地,nmd 703a可以实现附加的命令关键词引擎771b,该命令关键词引擎771b被配置为识别相应的命令关键词。此外,本地nlu 779的库可以包括多个命令关键词,并且被配置为在信号s
asr
中搜索与这些命令关键词相对应的文本模式。
189.此外,命令关键词可能需要不同的条件。例如,“跳过”的条件可能与“播放”的条件不同,因为“跳过”可能需要正在回放媒体项的条件,而播放可能需要没有正在回放媒体项的相反条件。为了促进这些相应的条件,nmd 703a可以实现与每个命令关键词相对应的相应状态机775a。备选地,nmd 703a可以实现状态机775a,该状态机775a对于每个命令关键词具有相应的状态。其他示例也是可能的。
190.在一些示例实施方式中,当满足某些条件时,vas唤醒词引擎770a生成vas唤醒词事件。nmd 703b包括状态机775b,其类似于状态机775a。状态机775b基于是否满足与vas唤醒词相对应的一个或多个条件,在第一状态和第二状态之间转换。
191.例如,在一些示例中,仅当在检测到vas唤醒词事件之前环境中不存在背景话音时,vas唤醒词引擎770a才可以生成vas唤醒词事件。环境中是否存在语音活动的指示可以来自噪声分类器766。如上所述,噪声分类器766可以被配置为输出信号和/或设置状态变量
以指示环境中存在远场语音。此外,vas唤醒词引擎770a可以仅当环境中存在语音活动时才生成vas唤醒词事件。如上所述,vad 765可以被配置为输出信号和/或设置状态变量以指示环境中存在语音活动。
192.为了说明,如图7b所示,vas唤醒词引擎770a连接到状态机775b。当满足一个或多个条件时,状态机775b可以保持在第一状态,该一个或多个条件可以包括在环境中不存在语音活动的条件。当状态机775b处于第一状态时,vas唤醒词引擎770a被启用,并且将生成vas唤醒词事件。如果不满足一个或多个条件中的任何一个,则状态机775b转换到第二状态,该第二状态禁用vas唤醒词引擎770a。
193.此外,nmd 703可以包括一个或多个传感器,其输出指示一个或多个用户是否接近nmd 703的信号。示例传感器包括温度传感器、红外传感器、成像传感器和/或电容传感器等。nmd 703可以使用来自这些传感器的输出来设置一个或多个状态变量,以指示一个或多个用户是否接近nmd 703。然后,状态机775b可以使用其存在或不存在作为状态机775b的条件。例如,当至少一个用户接近nmd 703时,状态机775b可以启用vas唤醒词引擎和/或命令关键词引擎771a。
194.为了说明示例性状态机操作,图7c是示出了用于需要一个或多个命令条件的示例命令关键词的状态机775的框图。在777a处,状态机775保持在第一状态778a,同时满足所有命令条件。当状态机775保持在第一状态778a(并且满足所有命令条件)时,当命令关键词引擎771a检测到命令关键词时,nmd 703a将生成命令关键词事件。
195.在777b处,当不满足任何一个命令条件时,状态机775转换到第二状态778b。在777c处,当不满足任何一个命令条件时,状态机775保持在第二状态778b。当状态机775保持在第二状态778b时,当命令关键词引擎771a检测到命令关键词时,nmd 703a将不会作用于命令关键词事件。
196.返回参考图7a,在一些示例中,一个或多个附加命令关键词引擎771b可以包括定制命令关键词引擎。云服务提供商(例如,流式音频服务)可以提供预先配置有识别算法的定制关键词引擎,该识别算法被配置为发现特定于服务的命令关键词。这些特定于服务的命令关键词可以包括用于定制服务特征的命令和/或用于访问服务的定制名称。
197.例如,nmd 703a可以包括特定的流式音频服务(例如,apple音乐)命令关键词引擎771b。该特定命令关键词引擎771b可以被配置为检测特定于特定流式音频服务的命令关键词,并生成流式音频服务唤醒词事件。例如,一个命令关键词可以是“朋友混合”,其对应于回放从特定流式音频服务内的一个或多个“朋友”的回放历史生成的定制播放列表的命令。
198.定制命令关键词引擎771b可能比vas唤醒词引擎770a相对更容易出现虚假唤醒词,因为通常vas唤醒词引擎770a比定制命令关键词引擎771b更复杂。为了缓解这种情况,定制命令关键词可能需要在生成定制命令关键词事件之前满足一个或多个条件。此外,在一些实施方式中,为了减少误报的发生率,可以强加多个条件作为在nmd 703a中包括定制命令关键词引擎771b的要求。
199.这些定制命令关键词条件可以包括特定于服务的条件。例如,与高级特征或播放列表相对应的命令关键词可能需要订阅作为条件。作为另一示例,与特定流式音频服务相对应的定制命令关键词可能需要来自回放队列中的该流式音频服务的媒体项。其他条件也是可能的。
200.为了基于定制命令关键词条件选通定制命令关键词引擎,nmd 703a可以包括与每个定制命令关键词相对应的附加状态机775a。备选地,nmd 703a可以实现状态机775a,该状态机775a对于每个定制命令关键词具有相应的状态。其他示例也是可能的。这些定制命令条件可以取决于由mps 100内的设备维护的状态变量,并且还可以取决于表示云服务(例如,流式音频服务)的用户账户状态的状态变量或其他数据结构。
201.图9a和图9b示出了示出示例性命令关键词和对应条件的表985。如图所示,示例命令关键词可以包括具有相似意图和需要相似条件的同源词。例如,“下一个”命令关键词具有“跳过”和“向前”的同源词,其中每一个都在适当的条件下调用跳过命令。表985中所示的条件是说明性的;各种实施方式可以使用不同的条件。
202.返回参考图7a,在示例实施例中,vas唤醒词引擎770a和命令关键词引擎771a可以采用多种形式。例如,vas唤醒词引擎770a和命令关键词引擎771a可以采用存储在nmd 703a和/或nmd 703b的存储器(例如,图1f的存储器112b)中的一个或多个模块的形式。作为另一示例,vas唤醒词引擎770a和命令关键词引擎771a可以采用通用或专用处理器或其模块的形式。在这方面,多个唤醒词引擎770和771可以是nmd 703a的相同组件的一部分,或者每个唤醒词引擎770和771可以采用专用于特定唤醒词引擎的组件的形式。还存在其他可能性。
203.为了进一步减少误报,命令关键词引擎771a可以利用与vas唤醒词引擎770a相比相对低的灵敏度。在实践中,唤醒词引擎可以包括可修改的敏感度级别设置。灵敏度级别可以定义在检测到的声音流s
ds1
中识别的单词和唤醒词引擎的一个或多个特定唤醒词之间的相似度,其被认为是一个匹配(即,触发vas唤醒词或命令关键词事件)。换言之,作为一个示例,灵敏度级别定义了检测到的声音流s
ds2
中的频谱特性必须与引擎的一个或多个唤醒词的频谱特性匹配到何种程度才能成为唤醒词触发器。
204.在这方面中,敏感度级别通常控制vas唤醒词引擎770a和命令关键词引擎771a识别出多少误报。例如,如果vas唤醒词引擎770a被配置为以相对高的灵敏度识别唤醒词“alexa”,则虚假唤醒词“election”或“lexus”可能导致唤醒词引擎770a标记唤醒词“alexa”的存在。相反,如果命令关键词引擎771a被配置为具有相对低的灵敏度,则虚假唤醒词“may”或“day”将不会导致命令关键词引擎771a标记命令关键词“播放(play)”的存在。
205.在实践中,灵敏度级别可以采用多种形式。在示例实施方式中,灵敏度级别采用置信度阈值的形式,该置信度阈值定义唤醒词引擎的最小置信度(即,概率)级别,当唤醒词引擎正在分析检测到的针对其特定唤醒词的声音时,最小置信度级别用作触发或不触发唤醒词事件之间的分界线。在这方面中,较高的灵敏度级别对应于较低的置信度阈值(和更多的误报),而较低的灵敏度级别对应于较高的置信度阈值(和较少的误报)。例如,降低唤醒词引擎的置信度阈值会将其配置为在其识别出不太可能是实际特定唤醒词的单词时触发唤醒词事件,而提高置信度阈值会将引擎配置为在其识别出更有可能是实际特定唤醒词的单词时触发唤醒词事件。在示例中,命令关键词引擎771a的灵敏度级别可以基于更多置信度分数,例如,发现命令关键词时的置信度分数和/或确定意图时的置信度分数。其他灵敏度级别的示例也是可能的。
206.在示例实施方式中,可以更新特定唤醒词引擎的灵敏度级别参数(例如,灵敏度范围),这可以以多种方式发生。作为一种可能性,给定唤醒词引擎的vas或其他第三方提供者可以向nmd 703提供修改给定vas唤醒词引擎770a的一个或多个灵敏度级别参数的唤醒词
引擎更新。相比之下,命令关键词引擎771a的灵敏度级别参数可以由nmd 703a的制造商或另一个云服务(例如,用于定制唤醒词引擎771b)配置。
207.值得注意的是,在某些示例中,当处理包括命令关键词的语音输入780时,nmd 703a放弃向vas发送表示检测到的声音sd的任何数据(例如,消息mv)。在包括本地nlu 779的实施方式中,nmd 703a还可以处理语音输入780的语音话语部分(除了关键词部分),而不必向vas发送语音输入780的语音话语部分。因此,相对于使用vas处理所有语音输入的其他nmd,向nmd 703说出语音输入780(具有命令关键词)可以提供增加的隐私。
208.如上所述,本地nlu 779的库中的关键词对应于参数。这些参数可以定义执行与检测到的命令关键词相对应的命令。当在语音输入780中识别出关键词时,根据与检测到的关键词相对应的参数执行与检测到的命令关键词相对应的命令。
209.例如,示例语音输入780可以是“播放低音量的音乐”,其中“播放”是命令关键词部分(与回放命令相对应),并且“低音量的音乐”是语音话语部分。当分析该语音输入780时,nlu 779可以识别出“低音量”是其库中与表示某个(低)音量级别的参数相对应的关键词。因此,nlu 779可以确定以该低音量级别播放的意图。然后,当执行与“播放”相对应的回放命令时,根据表示某个音量级别的参数来执行该命令。
210.在第二示例中,另一示例语音输入780可以是“在厨房中播放我的最爱”,其中“播放”再次是命令关键词部分(与回放命令相对应),并且“在厨房中我的最爱”作为语音话语部分。当分析该语音输入780时,nlu 779可以识别出“最爱”和“厨房”与其库中的关键词匹配。具体地,“最爱”对应于表示特定音频内容的第一参数(即,包括用户最爱的音频曲目的特定播放列表),而“厨房”对应于表示回放命令的目标的第二参数(即,厨房101h区)。因此,nlu 779可以确定在厨房101h区中播放该特定播放列表的意图。
211.在第三示例中,另一示例语音输入780可以是“音量调高”,其中“音量”是命令关键词部分(与音量调整命令相对应),并且“调高”是语音话语部分。当分析该语音输入780时,nlu 779可以识别出“调高”是其库中与表示某个音量提高的参数(在100点音量标度上增加10点)相对应的关键词。因此,nlu 779可以确定提高音量的意图。然后,当执行与“音量”相对应的音量调整命令时,根据表示某个音量提高的参数来执行该命令。
212.在示例中,某些命令关键词在功能上链接到本地nlu 779的库中的关键词的子集,这可以加快分析。例如,命令关键词“跳过”可以是链接到关键词“向前”和“向后”及其同源词的功能。因此,当在给定语音输入780中检测到命令关键词“跳过”时,使用本地nlu 779分析该语音输入780的语音话语部分可以涉及确定语音输入780是否包括与这些功能链接的关键词匹配的任何关键词(而不是确定语音输入780是否包括与本地nlu 779的库中的任何关键词匹配的任何关键词)。由于检查的关键字要少得多,因此这种分析比完全搜索库相对较快。相比之下,诸如“alexa”之类的随机vas唤醒词没有提供有关伴随语音输入范围的指示。
213.一些命令可能需要一个或多个参数,因此单独的命令关键字不能提供足够的信息来执行地应的命令。例如,命令关键词“音量”可能需要指定音量增加或减少的参数,因为仅音量的“音量”的意图尚不清楚。作为另一示例,命令关键词“组”可能需要识别要分组的目标设备的两个或更多个参数。
214.因此,在一些示例实施方式中,当命令关键词引擎771a在语音输入780中检测到给
定命令关键词时,本地nlu 779可以确定语音输入780是否包括与对应于所需参数的在库中的关键词匹配的关键词。如果语音输入780确实包括与所需参数匹配的关键词,则nmd 703a根据由关键词指定的参数继续执行命令(与给定的命令关键词相对应)。
215.然而,如果语音输入780确实包括与命令的所需参数匹配的关键词,则nmd 703a可以提示用户提供参数。例如,在第一示例中,nmd 703a可以播放声音提示,例如,“我听到了命令,但我需要更多信息”或“我可以帮你做点什么吗?”备选地,nmd 703a可以经由控制应用(例如,控制设备104的软件组件132c)向用户的个人设备发送提示。
216.在其他示例中,nmd 703a可以播放根据检测到的命令关键词定制的声音提示。例如,在检测到与音量调整命令相对应的命令关键词(例如,“音量”)之后,声音提示可以包括更具体的请求,例如,“您要调高还是调低音量?”作为另一示例,对于与命令关键词“组”相对应的分组命令,声音提示可以是“您要对哪些设备进行分组?”通过支持相对有限数量的命令关键词(例如,少于100个)可以使支持这种特定的声音提示变得切实可行,但是其他实施方式可以支持更多的命令关键词,其中,需要附加的内存和处理能力的权衡。
217.在附加的示例中,当语音话语部分不包括与一个或多个所需参数相对应的关键词时,nmd 703a可以根据一个或多个默认参数执行对应的命令。例如,如果回放命令不包括指示用于回放的目标回放设备102的关键词,则nmd 703a可以默认地在nmd 703a本身上回放(例如,如果nmd 703a在回放设备102内实现)或在一个或多个相关联的回放设备102(例如,与nmd 703a在同一房间或区中的回放设备102)上回放。此外,在一些示例中,用户可以使用图形用户界面(例如,用户界面430)或语音用户界面来配置默认参数。例如,如果分组命令未指定要分组的回放设备102,则nmd 703a可以默认指示两个或更多个预先配置的默认回放设备102形成同步组。默认参数可以存储在数据存储没备(例如,存储器112b(图1f))中,并在nmd 703a确定关键词排除某些参数时被访问。其他示例也是可能的。
218.在一些情况下,当本地nlu 779无法处理语音输入780时(例如,当本地nlu无法在库中找到与关键词的匹配时,或者当本地nlu 779具有关于意图的低置信度分数时),nmd 703a向vas发送语音输入780。在示例中,为了触发发送语音输入780,nmd 703a可以生成桥接事件,该桥接事件使语音提取器773处理声音数据流sd,如上所述。即,nmd 703a生成桥接事件以触发语音提取器773,而vas唤醒词引擎770a没有检测到vas唤醒词(而是基于语音输入780中的命令关键词以及nlu 779无法处理语音输入780)。
219.在向vas发送语音输入780之前(例如,经由消息mv),nmd 703a可以从用户获得用户默许向vas发送语音输入780的确认。例如,nmd 703a可以播放声音提示,以向默认或以其他方式配置的vas发送语音输入,例如,“对不起,我不明白这一点。我可以问问alexa吗?”在另一示例中,nmd 703a可以使用vas语音(即,大多数用户知道的与特定vas相关联的语音)播放声音提示,例如,“我可以帮你做点什么吗?”在这样的示例中,桥接事件的生成(以及语音提取器773的触发)取决于来自用户的第二肯定语音输入780。
220.在某些示例实施方式中,本地nlu 779可以处理信号s
asr
,而不必由命令关键词引擎771a(即,直接地)生成命令关键词事件。即,自动语音识别772可以被配置为对声音数据流sd执行自动话音识别,本地nlu 779对其进行处理以匹配关键词而不需要命令关键词事件。如果发现语音输入780中的关键词匹配与命令相对应的关键词(可能具有与一个或多个参数相对应的一个或多个关键词),则nmd 703a根据一个或多个参数执行命令。
221.此外,在这样的示例中,本地nlu 779可以仅在满足某些条件时直接处理信号s
asr
。具体地,在一些实施例中,本地nlu 779仅在状态机775a处于第一状态时处理信号s
asr
。特定条件可以包括与环境中没有背景话音相对应的条件。环境中是否存在背景话音的指示可以来自噪声分类器766。如上所述,噪声分类器766可以被配置为输出信号和/或设置状态变量以指示环境中存在远场语音。此外,另一条件可以与环境中的语音活动相对应。vad 765可以被配置为输出信号和/或设置状态变量以指示环境中存在语音活动。类似地,可以使用由状态机775a确定的条件来减少使用直接处理方法的命令的误报检测的发生率。
222.在一些示例中,本地nlu 779的库部分地针对单个用户定制。在第一方面中,可以针对在nmd的家庭(例如,环境101(图1a)内的家庭)内的设备定制库。例如,本地nlu的库可以包括与家庭内的设备的名称相对应的关键词,例如,mps 100中的回放设备102的区名。在第二方面中,可以针对家庭内的设备的用户定制库。例如,本地nlu 779的库可以包括与用户的优选播放列表、艺术家、专辑等的名称或其他标识符相对应的关键词。然后,当将语音输入定向到命令关键词引擎771a和本地nlu 779时,用户可以参考这些名称或标识符。
223.在示例实施方式中,nmd 703a可以在网络111(图1b)内本地填充本地nlu 779的库。如上所述,nmd 703a可以维护或访问指示连接到网络111的设备(例如,回放设备104)的相应状态的状态变量。这些状态变量可以包括各种设备的名称。例如,厨房101h可以包括被分配了区名“厨房”的回放设备101b。nmd 703a可以从状态变量中读取这些名称,并通过训练本地nlu 779将它们识别为关键词来将它们包括在本地nlu 779的库中。然后,可以将给定名称的关键词条目与相关联的参数中的对应设备相关联(例如,通过设备的标识符,例如,mac地址或ip地址)。然后,nmd 703a可以使用这些参数来定制控制命令,并将命令定向到特定设备。
224.在其他示例中,nmd 703a可以通过发现连接到网络111的设备来填充库。例如,nmd 703a可以根据针对设备发现配置的协议(例如,通用即插即用(upnp)或零配置联网)经由网络111发送发现请求。然后,网络111上的设备可以响应发现请求,并交换表示设备名称、标识符、地址等的数据,以促进经由网络111的通信和控制。nmd 703a可以从交换消息中读取这些名称,并通过训练本地nlu 779将它们识别为关键词来将它们包括在本地nlu 779的库中。
225.在其他示例中,nmd 703a可以使用云来填充库。为了说明,图10是mps 100和云网络902的示意图。云网络902包括云服务器906,分别被识别为媒体回放系统控制服务器906a、流式音频服务服务器906b和iot云服务器906c。流式音频服务服务器906b可以表示不同的流式音频服务的云服务器。类似地,iot云服务器906c可以表示与mps 100中支持智能设备990的不同云服务相对应的云服务器。
226.一个或多个通信链路903a、903b和903c(在下文中被称为“链路903”)将mps 100和云服务器906通信地耦合。链路903可以包括一个或多个有线网络和一个或多个无线网络(例如,互联网)。此外,类似于网络111(图1b),网络911将链路903与mps 100的设备(例如,回放设备102、nmd 103和703a、控制设备104和/或智能设备990中的一个或多个)的至少一部分通信地耦合。
227.在一些实施方式中,媒体回放系统控制服务器906a便于用nmd 703a(表示mps 100内的一个或多个nmd 703a(图7a))填充本地nlu 779的库。在示例中,媒体回放系统控制服
务器906a可以从nmd 703a接收表示填充本地nlu 779的库的请求的数据。基于该请求,媒体回放系统控制服务器906a可以与流式音频服务服务器906b和/或iot云服务器906c通信以获得特定于用户的关键词。
228.在一些示例中,媒体回放系统控制服务器906a可以利用用户账户和/或用户简档来获得特定于用户的关键词。如上所述,mps 100的用户可以设置用户简档以定义mps 100内的设置和其他信息。然后,可以依次向一个或多个流式音频服务的用户账户注册用户简档,以便于将音频从这些服务流式传输到mps 100的回放设备102。
229.通过使用这些注册的流式音频服务,流式音频服务服务器906b可以经由使用历史或经由用户输入(例如,经由将媒体项指定为保存或最爱的用户输入)收集指示用户保存或优选的播放列表、艺术家、专辑、曲目等的数据。该数据可以存储在流式音频服务服务器906b上的数据库中,以便于向用户提供流式音频服务的某些特征,例如,定制播放列表、推荐和类似特征。在适当的条件下(例如,在接收到用户许可之后),流式音频服务服务器906b可以通过链路903b与媒体回放系统控制服务器906a共享该数据。
230.因此,在示例中,媒体回放系统控制服务器906a可以维护或访问指示用户保存或优选的播放列表、艺术家、专辑、曲目、流派等的数据。如果用户已经向多个流式音频服务注册了他们的用户简档,则保存的数据可以包括来自两个或更多个流式音频服务的保存的播放列表、艺术家、专辑、曲目等。此外,与只能访问通过使用自己的服务生成的数据的流式音频服务相比,媒体回放系统控制服务器906a可以通过聚合来自两个或更多个流式音频服务的数据来更全面地了解用户的优选播放列表、艺术家、专辑、曲目等。
231.此外,在一些实施方式中,除了从流式音频服务服务器906b共享的数据之外,媒体回放系统控制服务器906a可以在接收到用户许可之后通过链路903a从mps 100收集使用数据。这可以包括以区为基础指示用户的保存或优选的媒体项的数据。在不同房间中可能偏好不同类型的音乐。例如,用户可能在厨房101h中偏好欢快音乐,以及在办公室101e中偏好更柔和的音乐以帮助集中注意力。
232.使用指示用户的保存或优选的播放列表、艺术家、专辑、曲目等的数据,媒体回放系统控制服务器906a可以识别用户在经由语音输入向nmd 703a提供回放命令时可能参考的播放列表、艺术家、专辑、曲目等的名称。然后,可以经由链路903a和网络904向nmd 703a发送表示这些名称的数据,然后将其作为关键词添加到本地nlu 779的库中。例如,媒体回放系统控制服务器906a可以向nmd 703a发送指令,以将某些名称作为关键词包括在本地nlu 779的库中。备选地,nmd 703a(或mps 100的另一设备)可以识别用户在经由语音输入向nmd 703a提供回放命令时可能参考的播放列表、艺术家、专辑、曲目等的名称,然后将这些名称包括在本地nlu 779的库中。
233.由于这种定制,与由vas处理相比,当本地nlu 779处理语音输入时,相似的语音输入可能导致执行不同的操作。例如,第一语音输入“alexa,在办公室中播放我的最爱”可以触发vas唤醒词事件,因为它包括vas唤醒词(“alexa”)。第二语音输入“在办公室中播放我的最爱”可以触发命令关键词,因为它包括命令关键词(“播放”)。因此,第一语音输入由nmd 703a发送给vas,而第二语音输入由本地nlu 779处理。
234.虽然这些语音输入几乎相同,但它们可以导致不同的操作。具体地,vas可以尽其所能地确定要添加到办公室101e中的回放设备102f的队列中的第一音频曲目播放列表。类
似地,本地nlu 779可以识别第二语音输入中的关键词“最爱”和“厨房”。因此,nmd 703a使用参数《最爱播放列表》和《厨房101h区》执行语音命令“播放”,这使得第二音频曲目播放列表被添加到办公室101e中的播放设备102f的队列中。然而,第二音频曲目播放列表可以包括用户的最爱音频曲目的更完整和/或更准确的集合,因为第二音频曲目播放列表可以利用来自多个流式音频服务的指示用户的保存或优选的播放列表、艺术家、专辑和曲目的数据,和/或由媒体回放系统控制服务器906a收集的使用数据。相比之下,vas在确定第一播放列表时可以利用其对用户的保存或优选的播放列表、艺术家、专辑和曲目的相对有限的概念。
235.为了说明,图11示出了表1100,其示出了基于相似语音输入确定但不同地处理的第一播放列表和第二播放列表的相应内容。具体地,第一播放列表由vas确定,而第二播放列表由nmd 703a(可能与媒体回放系统控制服务器906a结合)确定。如图所示,虽然两个播放列表都声称包括用户的最爱,但这两个播放列表包括来自不同艺术家和流派的音频内容。具体地,第二播放列表是根据办公室101e中回放设备102f的使用以及用户与多个流式音频服务的交互来配置的,而第一播放列表基于多个用户与vas的交互。结果,第二播放列表更适合用户偏好在办公室101e中收听的音乐类型(例如,独立摇滚和民谣),而第一播放列表更能代表与整个vas的交互。
236.一个家庭可以包括多个用户。两个或更多个用户可以使用mps 100来配置他们各自的用户简档。每个用户简档可以具有其自己的与相应的用户简档相关联的一个或多个流式音频服务的用户帐户。此外,媒体回放系统控制服务器906a可以维护或访问指示每个用户的保存或优选的播放列表、艺术家、专辑、曲目、流派等的数据,该数据可以与该用户的用户简档相关联。
237.在各种示例中,与用户简档相对应的名称可以被填充到本地nlu 779的库中。这可以有助于引用特定用户的保存或优选的播放列表、艺术家、专辑、曲目或流派。例如,当本地nlu 779处理语音输入“在露台上播放安妮的最爱”时,本地nlu 779可以确定“安妮”与对应于特定用户的存储的关键词匹配。然后,当执行与该语音输入相对应的回放命令时,nmd 703a将该特定用户最爱的音频曲目的播放列表添加到露台101i中的回放设备102c的队列。
238.在一些情况下,语音输入可能不包括与特定用户相对应的关键词,但是mps 100配置有多个用户简档。在一些情况下,nmd 703a可以确定在使用语音识别执行命令时要使用的用户简档。备选地,nmd 703a可以默认为某个用户简档。此外,当执行与未识别特定用户简档的语音输入相对应的命令时,nmd 703a可以使用来自多个用户简档的偏好。例如,nmd 703a可以从向mps 100注册的每个用户简档中确定包括优选或保存的音频曲目的最爱播放列表。
239.iot云服务器906c可以被配置为向智能设备990提供支持云服务。智能设备990可以包括各种“智能”互联网连接设备,例如,灯、恒温器、相机、安全系统、电器等。例如,iot云服务器906c可以提供支持智能恒温器的云服务,该云服务允许用户通过互联网经由智能手机app或网站控制智能恒温器。
240.因此,在示例中,iot云服务器906c可以维护或有权访问与用户的智能设备990相关联的数据,例如,设备名称、设置和配置。在适当的条件下(例如,在接收到用户许可之后),iot云服务器906c可以经由链路903c与媒体回放系统控制服务器906a和/或nmd 703a
共享该数据。例如,提供智能恒温器云服务的iot云服务器906c可以向nmd 703a提供表示这些关键词的数据,这有助于用与温度相对应的关键词填充本地nlu 779的库。
241.此外,在一些情况下,iot云服务器906c还可以提供特定于控制其对应的智能设备990的关键词。例如,提供支持智能恒温器的云服务的iot云服务器906c可以提供与恒温器的语音控制相对应的关键词集合,例如“温度”、“更温暖”或“更凉爽”等。表示这些关键词的数据可以通过链路903和网络904从iot云服务器906c向nmd 703a发送。
242.如上所述,一些家庭可以包括多个nmd 703a。在示例实施方式中,两个或更多个nmd 703a可以同步或以其他方式更新它们各自的本地nlu 779的库。例如,第一nmd 703a和第二nmd 703a可以共享表示它们各自的本地nlu 779的库的数据,可能使用网络(例如,网络904)。这种共享可以促进nmd 703a能够类似地响应语音输入,以及其他可能的好处。
243.在一些实施例中,上述组件中的一个或多个可以与麦克风720结合操作以检测和存储用户的语音简档,该语音简档可以与mps 100的用户账户相关联。在一些实施例中,语音简档可以被存储为存储在一组命令信息或数据表中的变量和/或与存储在一组命令信息或数据表中的变量进行比较。语音简档可以包括用户语音的音调或频率方面和/或用户的其他独特方面,例如,先前引用的美国专利申请no.15/438,749中所描述的那些。
244.在一些实施例中,上述组件中的一个或多个可以与麦克风720结合操作以确定用户在家居环境中的位置和/或相对于一个或多个nmd 103的位置。用于确定用户的位置或接近度的技术可以包括在先前引用的美国专利申请no.15/438,749、2011年12月29日提交的题为“sound field calibration using listener localization”的美国专利no.9,084,058、以及2012年8月31日提交的题为“acoustic optimization”的美国专利no.8,965,033中公开的一个或多个技术。这些申请中的每一个通过引用整体并入本文。
245.iv.示例命令关键词技术
246.图12是示出了基于命令关键词事件执行第一回放命令的示例方法1200的流程图。方法1100可以由诸如nmd 103s(图1a)之类的联网麦克风设备执行,联网麦克风设备可以包括nmd 703a(图7a)的特征。在一些实施方式中,nmd在回放设备内实现,如回放设备102r(图1g)所示。
247.在框1202处,方法1200涉及监视(i)唤醒词事件和(ii)第一命令关键词事件的输入声音数据流。例如,nmd 703a的vas唤醒词引擎770a可以将一种或多种唤醒词识别算法应用于声音数据流s
ds
(图7a)。此外,命令关键词引擎770可以监视命令关键词的声音数据流s
ds
,可能使用asr 772和本地nlu 779,如上面结合图7a所描述的。
248.在框1204处,方法1200涉及检测唤醒词事件。检测唤醒词事件可以涉及nmd 703a的vas唤醒词引擎770a检测到经由麦克风720检测到的第一声音包括包含唤醒词的第一语音输入。vas唤醒词引擎770a可以使用识别算法在第一语音输入中检测这种唤醒词。
249.在框1206处,方法1200涉及向语音助手服务的一个或多个远程服务器流式传输与第一语音输入相对应的声音数据。例如,语音提取器773可以从声音数据流s
ds
(图7a)中提取第一语音输入的至少一部分(例如,唤醒词部分和/或语音话语部分)。然后,nmd 703可以经由网络接口724向语音助手服务的一个或多个远程服务器流式传输该提取的数据。
250.在框1208处,方法1200涉及检测第一命令关键词事件。例如,在检测到第二声音之后,nmd 703a的命令关键词引擎771a可以检测声音数据流sd中与第二声音中的第二语音输
入相对应的第一命令关键词。其他示例也是可能的。
251.在框1210处,方法1200涉及确定是否满足与第一命令关键词相对应的一个或多个回放条件。确定是否满足与第一命令关键词相对应的一个或多个回放条件可以涉及确定状态机的状态。例如,nmd 703a的状态机775可以在满足与第一命令关键词相对应的一个或多个回放条件时转换到第一状态,并且在不满足与第一命令关键词相对应的一个或多个回放条件中的至少一个条件时转换到第二状态(图7c)。示例回放条件在表985(图9a和图9b)中示出。
252.在框1212处,方法1200涉及执行与第一命令关键词相对应的第一回放命令。例如,nmd 703a可以基于检测到第一命令关键词事件并确定满足与第一命令关键词相对应的一个或多个回放条件来执行第一回放命令。在示例中,执行第一回放命令可以涉及生成一个或多个指令以执行该命令,该一个或多个指令使目标回放设备执行第一回放命令。
253.在示例中,执行第一回放命令的目标回放设备102可以被显式地或隐式地定义。例如,目标回放设备102可以通过在语音输入780中引用一个或多个回放设备的名称(例如,通过引用区或区组名称)来显式地定义。备选地,语音输入可能不包括对一个或多个回放设备的名称的任何引用,而是可以隐式地指的是与nmd 703a相关联的回放设备102。与nmd 703a相关联的回放设备102可以包括实现nmd 703a的回放设备(如实现nmd 103d的回放设备102d(图1b)所示)或被配置为关联的回放设备(例如,其中回放设备102与nmd 703a位于同一房间或区域)。
254.在示例中,执行第一回放操作可以涉及通过一个或多个网络发送一个或多个指令。例如,nmd 703a可以通过网络903在本地向一个或多个回放设备102发送指令,以执行诸如传输控制(图10)之类的指令,类似于图6所示的消息交换。此外,nmd 703a可以向流式音频服务服务906b发送请求,以向目标回放设备102流式传输一个或多个音频曲目,以通过链路903(图10)回放。备选地,指令可以在内部(例如,通过本地总线或其他互连系统)提供给一个或多个软件或硬件组件(例如,回放设备102的电子器件112)。
255.此外,传输指令可以涉及本地和基于云的操作。例如,nmd 703a可以通过网络903在本地向一个或多个回放设备102发送指令,以通过网络903将一个或多个音频曲目添加到回放队列。然后,一个或多个回放设备102可以向流式音频服务服务906b发送请求,以向目标回放设备102流式传输一个或多个音频曲目,以通过链路903回放。其他示例也是可能的。
256.图13是示出了基于命令关键词事件根据一个或多个参数执行第一回放命令的示例方法1300的流程图。类似于方法1100,方法1300可以由诸如nmd 120(图1a)之类的联网麦克风设备执行,联网麦克风设备可以包括nmd 703a(图7a)的特征。在一些实施方式中,nmd在回放设备内实现,如回放设备102r(图1g)所示。
257.在框1302处,方法1300涉及监视(i)唤醒词事件和(ii)第一命令关键词事件的输入声音数据流。例如,nmd 703a的vas唤醒词引擎770a可以将一种或多种唤醒词识别算法应用于声音数据流s
ds
(图7a)。此外,命令关键词引擎770可以监视命令关键词的声音数据流s
ds
,可能使用asr 772和本地nlu 779,如上面结合图7a所描述的。
258.在框1304处,方法1300涉及检测唤醒词事件。检测唤醒词事件可以涉及nmd 703a的vas唤醒词引擎770a检测到经由麦克风720检测到的第一声音包括包含唤醒词的第一语音输入。vas唤醒词引擎770a可以使用识别算法在第一语音输入中检测这种唤醒词。
259.在框1306处,方法1300涉及向语音助手服务的一个或多个远程服务器流式传输与第一语音输入相对应的声音数据。例如,语音提取器773可以从声音数据流s
ds
(图7a)中提取第一语音输入的至少一部分(例如,唤醒词部分和/或语音话语部分)。然后,nmd 703可以经由网络接口724向语音助手服务的一个或多个远程服务器流式传输该提取的数据。
260.在框1308处,方法1300涉及检测第一命令关键词事件。例如,在检测到第二声音之后,nmd 703a的命令关键词引擎771a可以检测声音数据流sd中与第二声音中的第二语音输入相对应的第一命令关键词(图7a)。此外,本地nlu 779可以检测到第二语音输入包括来自本地nlu 779的库的至少一个关键词。例如,本地nlu 779可以确定语音输入是否包括与本地nlu 779的库中的关键词匹配的任何关键词。本地nlu 779被配置为分析信号s
asr
以发现(即,检测或识别)语音输入中的关键词。
261.在框1310处,方法1300涉及基于至少一个关键词来确定意图。例如,本地nlu 779可以根据第二语音输入中的一个或多个关键词来确定意图。如上所述,本地nlu 779的库中的关键词对应于参数。语音输入中的关键词可以指示意图,例如在特定区中播放特定音频内容。
262.在框1312处,方法1300涉及根据确定的意图执行第一回放命令。在示例中,执行第一回放命令可以涉及生成一个或多个指令以根据确定的意图执行命令,该一个或多个指令使目标回放设备执行由语音输入的语音话语部分中的参数定制的第一回放命令。如上面结合框1212(图12)所指示的,将执行第一回放命令的目标回放设备102可以被显式地或隐式地定义。此外,执行第一回放操作可以涉及通过一个或多个网络发送一个或多个指令,或者可以涉及在内部(例如,向回放设备组件)提供指令。
263.图14是示出了基于与命令关键词相对应的命令关键词事件根据一个或多个参数执行第一回放命令的示例方法1400的流程图。只有在满足某些条件时,才可以生成命令关键词事件。第一条件是,在检测到命令关键词时环境中不存在背景话音。
264.类似于方法1200和1300,方法1400可以由诸如nmd 120(图1a)之类的联网麦克风设备执行,联网麦克风设备可以包括nmd 703a(图7a)的特征。在一些实施方式中,nmd在回放设备内实现,如回放设备102r(图1g)所示。
265.在框1402处,方法1400涉及经由一个或多个麦克风检测声音。例如,nmd 703可以经由麦克风720(图7a)检测声音。此外,nmd 703可以使用vcc 760的一个或多个组件来处理检测到的声音。
266.在框1404处,方法1400涉及确定(i)检测到的声音包括语音输入,(ii)检测到的声音不包括背景话音,以及(iii)语音输入包括命令关键词。
267.例如,为了确定检测到的声音是否包括语音输入,语音活动检测器765可以分析检测到的声音以确定声音数据流s
ds
(图7a)中语音活动的存在(或不存在)。此外,为了确定检测到的声音是否不包括背景话音,噪声分类器766可以分析与检测到的声音相对应的声音元数据,并确定声音元数据是否包括与背景话音相对应的特征。
268.此外,为了确定语音输入是否包括命令关键词,命令关键词引擎771a可以分析声音数据流s
ds
(图7a)。具体地,asr 772可以将声音数据流s
ds
转录为文本(例如,信号s
asr
),并且本地nlu 779可以确定与命令关键词匹配的单词在转录的文本中。在其他示例中,命令关键词引擎771a可以对声音数据流s
ds
使用一种或多种关键词识别算法。其他示例也是可能
的。
269.在框1406处,方法1400涉及执行对应于命令关键词的回放功能。例如,nmd可以基于确定(i)检测到的声音包括语音输入,(ii)检测到的声音不包括背景话音,以及(iii)语音输入包括命令关键词来执行回放功能。图12和图13的框1212和框1312分别提供了执行回放功能的示例。
270.v说明性示例
271.图15a、图15b、图15c和图15d示出了根据本公开的各方面配置的示例nmd的示例性输入和输出。
272.图15a示出了第一场景,其中,nmd的唤醒词引擎被配置为检测三个命令关键词(“播放”、“停止”和“恢复”)。本地nlu被禁用。在该场景中,用户已经向nmd说出了语音输入“播放”,这会触发对命令关键词之一的新识别(例如,与播放相对应的命令关键词事件)。
273.此外,语音活动检测器(vad)和噪声分类器已经分析了语音输入的前滚动部分的150个帧。如图所示,vad已经在150个前滚动帧中的140个帧中检测到了语音,这指示检测到的声音中可能存在语音输入。此外,噪声分类器已经在11个帧中检测到了周围环境噪声,在127个帧中检测到了背景话音,并且在12个帧中检测到了风扇噪声。在该nmd中,噪声分类器对每一帧中的主要噪声源进行分类。这指示存在背景话音。因此,nmd已经确定不对检测到的命令关键词“播放”进行触发。
274.图15b示出了第二个场景,其中,nmd的唤醒词引擎被配置为检测命令关键词(“播放”)以及该命令关键词的两个同源词(“播放一些内容”和“给我播放一首歌”)。本地nlu被禁用。在该第二场景中,用户已经向nmd说出了语音输入“播放一些内容”,这会触发对命令关键词之一的新识别(例如,命令关键词事件)。
275.此外,语音活动检测器(vad)和噪声分类器已经分析了语音输入的前滚动部分的150个帧。如图所示,vad已经在150个前滚动帧中的87个帧中检测到了语音,这指示检测到的声音中可能存在语音输入。此外,噪声分类器已经在18个帧中检测到了周围环境噪声,在8个帧中检测到了背景话音,并且在124个帧中检测到了风扇噪声。这指示不存在背景话音。鉴于上述情况,nmd已经确定对检测到的命令关键词“播放”进行触发。
276.图15c示出了第三场景,其中,nmd的唤醒词引擎被配置为检测三个命令关键词(“播放”、“停止”和“恢复”)。本地nlu被启用。在该第三场景,用户已经向nmd说出了语音输入“在厨房中播放披头士(beatles)”,这会触发对命令关键词之一的新识别(例如,与播放相对应的命令关键词事件)。
277.如图所示,asr已经将语音输入转录为“在厨房中播放beet les”。预计在执行asr时会出现一些错误(例如,“beet les”)。这里,本地nlu已经将关键词“beet les”与本地nlu库中的“the beatles”(“披头士”)进行了匹配,从而将该艺术家设置为播放命令的内容参数。此外,本地nlu已经将关键词“厨房”与本地nlu库中的“厨房”进行了匹配,从而将该厨房区设置为播放命令的目标参数。本地nlu产生与意图确定相关联的置信度分数0.63428231948273443。
278.这里,语音活动检测器(vad)和噪声分类器已经分析了语音输入的前滚动部分的150个帧。如图所示,噪声分类器已经在142个帧中检测到了周围环境噪声,在8个帧中检测到了背景话音,并且在0个帧中检测到了风扇噪声。这指示不存在背景话音。vad已经在150
个前滚动帧中的112个帧中检测到了语音,这指示检测到的声音中可能存在语音输入。这里,nmd已经确定对检测到的命令关键词“播放”进行触发。
279.此外,语音活动检测器(vad)和噪声分类器已经分析了语音输入的前滚动部分的150个帧。如图所示,vad已经在150个前滚动帧中的140个帧中检测到了语音,这指示检测到的声音中可能存在语音输入。此外,噪声分类器已经在11个帧中检测到了周围环境噪声,在127个帧中检测到了背景话音,并且在12个帧中检测到了风扇噪声。这指示存在背景话音。因此,nmd已经确定不对检测到的命令关键词“播放”进行触发。
280.图15d示出了第四场景,其中,nmd的关键词引擎没有被配置为发现任何命令关键词。相反,关键词引擎将执行asr,并将asr的输出传递给本地nlu。启用并配置本地nlu以检测与命令和参数相对应的关键词。在第四场景中,用户已经向nmd说出了语音输入“在办公室中播放(play)一些音乐”。
281.如图所示,asr已经将语音输入转录为“在办公室中lay一些音乐”。这里,本地nlu将关键词“lay”与本地nlu库中的“播放(play)”进行了匹配,从而对应回放命令。此外,本地nlu已经将关键词“办公室”与本地nlu库中的“办公室”进行了匹配,从而将该办公室区设置为播放命令的目标参数。本地nlu产生与关键词匹配相关联的置信度分数0.14620494842529297。在一些示例中,该低置信度分数可能导致nmd不接受语音输入(例如,如果该置信度分数低于阈值,例如,0.5)。
282.结论
283.以上描述尤其公开了各种示例系统、方法、装置和尤其包括在硬件上执行的固件和/或软件的制品。应当理解的是,这些示例仅是示意性的,而不应当被认为是限制性的。例如,可以想到,这些固件、硬件和/或软件方面或组件中的任意一个或全部可以专门在硬件中实现、专门在软件中实现、专门在固件中实现、或在硬件、软件和/或固件的任意组合中实现。因此,所提供的示例不是实现这些系统、方法、装置和/或制品的唯一方式。
284.主要在说明性的环境、系统、过程、步骤、逻辑块、处理以及直接或间接地与耦合到网络的数据处理设备的操作相类似的其他象征性表示的方面上,提出本说明书。本领域技术人员通常使用这些处理描述和表示,以向本领域技术人员的其他技术人员传播他们的工作内容。阐述了各种具体细节,以提供本公开的透彻理解。然而,本领域技术人员应理解,不需要特定、具体细节就可以实施本公开。在其他实例中,没有描述熟知的方法、过程、组件和电路,以避免不必要地使实施例的方面模糊不清。因此,本公开的范围由随附权利要求、而不是以上实施例的描述来界定。
285.当随附权利要求中的任一项权利要求被理解成涵盖纯软件和/或固件实现时,在此明确限定至少一个示例中的至少一个元素以包括存储软件和/或固件的非暂时性有形介质,如存储器、dvd、cd、蓝光等。
286.例如,根据以下所述的各个方面示出了本技术。为了方便起见,将本技术各方面的各种示例描述为编号示例(1、2、3等)。这些仅作为示例提供,并不限制本技术。请注意,任何从属示例可以以任何组合被组合,并且被放置在相应的独立示例中。可以以类似的方式呈现其他示例。
287.示例1:一种由回放设备执行的方法,所述回放设备包括网络接口和至少一个被配置为检测声音的麦克风,所述方法包括:监视用于(i)唤醒词事件和(ii)第一命令关键词事
件的表示由所述至少一个麦克风检测到的声音的输入声音数据流;检测所述唤醒词事件,其中,检测所述唤醒词事件包括:在经由所述一个或多个麦克风检测到第一声音之后,确定检测到的第一声音包括第一语音输入,所述第一语音输入包括唤醒词;经由所述网络接口向语音助手服务的一个或多个远程服务器流式传输与所述第一语音输入的至少一部分相对应的声音数据;检测所述第一命令关键词事件,其中,检测所述第一命令关键词事件包括:在经由所述一个或多个麦克风检测到第二声音之后,确定检测到的第二声音包括第二语音输入,所述第二语音输入包括第一命令关键词,其中,所述第一命令关键词是所述回放设备支持的多个命令关键词之一;确定满足与所述第一命令关键词相对应的一个或多个回放条件;以及响应于检测到所述第一命令关键词事件,以及确定满足与所述第一命令关键词相对应的所述一个或多个回放条件,执行与所述第一命令关键词相对应的第一回放命令。
288.示例2:根据示例1所述的方法,还包括:在检测到所述第一命令关键词事件之后,检测后续的第一命令关键词事件,其中,检测所述后续的第一命令关键词事件包括:在经由所述至少一个麦克风检测到第三声音之后,确定所述第三声音包括第三语音输入,所述第三语音输入包括所述第一命令关键词;确定不满足与所述第一命令关键词相对应的所述一个或多个回放条件中的至少一个回放条件;以及响应确定不满足所述至少一个回放条件,放弃执行与所述第一命令关键词相对应的第一回放命令。
289.示例3:根据示例1和2中任一项所述的方法,还包括:检测第二命令关键词事件,其中,检测所述第二命令关键词事件包括:在经由所述至少一个麦克风检测到第三声音之后,确定所述第三声音包括第三语音输入,所述第三语音输入包括检测到的第三声音中的第二命令关键词;确定满足与所述第二命令关键词相对应的一个或多个回放条件;以及响应于检测到所述第二命令关键词,以及确定满足与所述第二命令关键词相对应的所述一个或多个回放条件,执行与所述第二命令关键词相对应的第二回放命令。
290.示例4:根据示例3所述的方法,其中,与所述第二命令关键词相对应的所述一个或多个回放条件中的至少一个回放条件不是与所述第一命令关键词相对应的所述一个或多个回放条件中的回放条件。
291.示例5:根据示例1-4中任一项的方法,其中,所述第一命令关键词是跳过命令,其中,与所述第一命令关键词相对应的所述一个或多个回放条件包括:(i)第一条件,即,正在所述回放设备上回放媒体项,(ii)第二条件,即,队列在回放设备上处于活动状态,以及(iii)第三条件,即,所述队列包括在所述回放设备上正在回放的媒体项之后的媒体项,并且其中,执行与所述第一命令关键词相对应的所述第一回放命令包括:在所述队列中向前跳过,以回放在所述回放设备上正在回放的媒体项之后的媒体项。
292.示例6:根据示例1-4中任一项所述的方法,其中,所述第一命令关键词为暂停命令,其中,与所述第一命令关键词相对应的所述一个或多个回放条件包括在所述回放设备上正在回放音频内容的条件,并且其中,执行与所述第一命令关键词相对应的所述第一回放命令包括暂停回放所述回放设备上的音频内容。
293.示例7:根据示例1-4中任一项所述的方法,其中,所述第一命令关键词为音量增加命令,其中,与所述第一命令关键词相对应的所述一个或多个回放条件包括:第一条件,即,在所述回放设备上正在回放音频内容;以及第二条件,即,所述回放设备上的音量级别未处
于最大音量级别,其中,执行与所述第一命令关键词相对应的所述第一回放命令包括增加所述回放设备上的音量级别。
294.示例8:根据示例1-8中任一项的方法,其中,与所述第一命令关键词相对应的所述一个或多个回放条件包括检测到的第一声音中不存在背景话音的第一条件。
295.示例9:一种有形的、非暂时性的计算机可读介质,其上存储有指令,所述指令可由一个或多个处理器执行,以使回放设备执行根据示例1-8中任一项所述的方法。
296.示例10:一种回放设备,包括:扬声器;网络接口;一个或多个麦克风,被配置为检测声音;一个或多个处理器;以及有形的、非有形的计算机可读介质,其上存储有指令,所述指令可由所述一个或多个处理器执行,以使所述回放设备执行根据示例1-8中任一项所述的方法。
297.示例11:一种由回放设备执行的方法,所述回放设备包括网络接口和至少一个被配置为检测声音的麦克风,所述方法包括:监视用于(i)唤醒词事件和(ii)第一命令关键词事件的表示由所述至少一个麦克风检测到的声音的输入声音数据流;检测所述唤醒词事件,其中,检测所述唤醒词事件包括:在经由所述一个或多个麦克风检测到第一声音之后,确定检测到的第一声音包括第一语音输入,所述第一语音输入包括唤醒词;经由所述网络接口向语音助手服务的一个或多个远程服务器流式传输与所述第一语音输入的至少一部分相对应的声音数据;检测所述第一命令关键词事件,其中,检测所述第一命令关键词事件包括:在经由所述一个或多个麦克风检测到第二声音之后,确定检测到的第二声音包括第二语音输入,所述第二语音输入包括第一命令关键词和至少一个关键词,其中,所述第一命令关键词是所述回放设备支持的多个命令关键词之一,并且其中,所述第一命令关键词对应于第一回放命令;经由本地自然语言单元(nlu)基于所述至少一个关键词确定意图,其中,所述nlu包括预定的关键词库,所述预定的关键词库包括所述至少一个关键词;以及在(a)检测到所述第一命令关键词事件并(b)确定所述意图之后,根据确定的意图执行所述第一回放命令。
298.示例12:根据示例11所述的方法,其中,所述方法还包括检测第二命令关键词事件,其中,检测所述第二命令关键词事件包括:在经由所述至少一个麦克风检测到第三声音之后,确定所述第三声音包括第三语音输入,所述第三语音输入包括所述第二命令关键词;确定包括所述第二命令关键词的所述第三语音输入不包括来自所述预定的关键词库的至少一个其他关键词;以及在确定包括所述第二命令关键词的所述第三语音输入不包括来自所述预定的关键词库的所述至少一个关键词之后,向所述语音助手服务的一个或多个服务器流式传输表示包括所述第二命令关键词的所述语音输入的至少一部分的声音数据,以供所述语音助手服务的所述一个或多个远程服务器处理。
299.示例13:根据示例12所述的方法,其中,所述方法还包括:回放声音提示以请求确认调用所述语音助手服务以处理所述第二命令关键词的信息;以及在回放所述声音提示之后,接收表示确认调用所述语音助手服务以处理所述第二命令关键词的数据,其中,向所述语音助手服务的一个或多个服务器流式传输表示包括所述第二命令关键词的所述语音输入的至少一部分的声音数据只有在接收到表示确认调用所述语音助手服务的数据之后才会发生。
300.示例14:根据示例10-13中任一项所述的方法,还包括检测第二命令关键词事件,
其中,检测所述第二命令关键词事件包括:在经由所述至少一个麦克风检测到第三声音之后,确定所述第三声音包括第三语音输入,所述第三语音输入包括所述第二命令关键词;确定包括所述第二命令关键词的所述第三语音输入不包括来自所述预定的关键词库的至少一个其他关键词;以及在确定包括所述第二命令关键词的所述第三语音输入不包括所述预定的关键词库中的所述至少一个关键词之后,根据一个或多个默认参数执行所述第一回放命令。
301.示例15:根据示例10-14中任一项所述的方法,其中,检测到的第二声音中的所述至少一个关键词的第一关键词表示与媒体回放系统的第一区相对应的区名,其中,根据确定的意图执行所述第一回放命令包括发送一个或多个指令以在所述第一区中执行所述第一回放命令,并且其中,所述媒体回放系统包括所述回放设备。
302.示例16:根据示例10-15中任一项所述的方法,还包括用与所述媒体回放系统内的各区相对应的区名填充所述预定的关键词库,其中,每个区包括一个或多个相应的回放设备,并且其中,所述预定的关键词库填充有与所述媒体播放系统的所述第一区相对应的区名。
303.示例17:根据示例10-16中任一项所述的方法,还包括:经由所述网络接口发现连接到局域网的智能家居设备;以及利用与在所述局域网上发现的相应的智能家居设备相对应的名称来填充所述预定的关键词库。
304.示例18:根据示例10-17中任一项所述的方法,其中,媒体回放系统包括所述回放设备,其中,所述媒体回放系统注册到一个或多个用户简档,并且其中,所述功能还包括:利用与由所述一个或多个用户简档指定为最爱的播放列表相对应的名称来填充所述预先定义的关键词库。
305.示例19:根据示例18所述的方法,其中,所述一个或多个用户简档中的第一用户简档与第一流式音频服务的用户账户和第二流式音频服务的用户账户相关联,并且其中,所述播放列表包括:第一流式音频服务的第一播放列表,由所述第一流式音频服务的所述用户帐户指定为最爱;以及第二播放列表,包括来自所述第一流式音频服务和所述第二流式音频服务的音频曲目。
306.示例20:根据示例10-16中任一项所述的方法,其中,检测所述第一命令关键词事件还包括确定满足与所述第一命令关键词相对应的一个或多个回放条件。
307.示例21:根据示例20所述的方法,其中,与所述第一命令关键词相对应的所述一个或多个回放条件包括检测到的第一声音中不存在背景话音的第一条件。
308.示例22:一种有形的、非暂时性的计算机可读介质,其上存储有指令,所述指令可由一个或多个处理器执行,以使回放设备执行根据示例10-21中任一项所述的方法。
309.示例23:一种回放设备,包括:扬声器;网络接口;一个或多个麦克风,被配置为检测声音;一个或多个处理器;以及有形的、非有形的计算机可读介质,其上存储有指令,所述指令可由所述一个或多个处理器执行,以使所述回放设备执行根据示例10-21中任一项所述的方法。
310.示例24:一种由回放设备执行的方法,所述回放设备包括网络接口和至少一个被配置为检测声音的麦克风,所述方法包括:经由所述一个或多个麦克风检测声音;确定(i)检测到的声音包括语音输入,(ii)检测到的声音不包括背景话音,以及(iii)所述语音输入
包括命令关键词;以及响应于确定(i)检测到的声音包括语音输入,(ii)检测到的声音不包括背景话音,以及(iii)所述语音输入包括命令关键词,执行与所述命令关键词相对应的回放功能。
311.示例25:根据示例24所述的方法,其中,检测到的声音是第一检测声音,并且其中,所述方法还包括:经由所述至少一个麦克风检测第二声音;确定检测到的第二声音包括唤醒词;以及在确定检测到的第二声音包括所述唤醒词之后,经由所述回放设备的网络接口,向语音助手服务的一个或多个远程服务器流式传输检测到的第二声音中的语音输入。
312.示例26:根据示例24和示例25中任一项所述的方法,其中,确定在检测到的第二声音中不存在背景话音包括:确定与检测到的声音相对应的声音元数据;以及分析所述声音元数据以根据从多个签名中选择的一个或多个特定签名对检测到的声音进行分类,其中,所述多个签名中的每个签名与噪声源相关联,并且其中,所述多个签名中的至少一个签名是指示背景话音的背景话音签名。
313.示例27:根据示例26所述的方法,其中,分析所述声音元数据包括:将与检测到的声音相关联的帧分类为具有不同于所述背景话音签名的特定话音签名;以及将用所述背景话音签名分类的多个帧(如果有的话)与用除了所述背景话音签名之外的签名分类的多个帧进行比较。
314.示例28:根据示例24和示例25中任一项所述的方法,其中,确定检测到的声音中存在语音输入包括检测所述检测到的声音中的语音活动。
315.示例29:根据示例28所述的方法,其中,在检测到的声音中检测语音活动包括:将与检测到的声音相关联的多个第一帧确定为包含话音;以及将所述多个第一帧与(a)与检测到的声音相关联并且(b)不指示话音的多个第二帧进行比较。
316.示例30:根据示例29所述的方法,其中,所述第一帧包括:响应于近场语音活动而生成的一个或多个帧;以及响应于远场语音活动而生成的一个或多个帧。
317.示例31:一种有形的、非暂时性的计算机可读介质,其上存储有指令,所述指令可由一个或多个处理器执行,以使回放设备执行根据示例10-21中任一项所述的方法。
318.示例32:一种回放设备,包括:一个或多个麦克风,被配置为检测声音;一个或多个处理器;以及有形的、非有形的计算机可读介质,其上存储有指令,所述指令可由所述一个或多个处理器执行,以使所述回放设备执行根据示例24-30中任一项所述的方法。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。