1.本发明属于声学技术领域,涉及一种轻量级说话人识别方案。
背景技术:
2.说话人识别(speakerrecognition),又称声纹识别、语音生物识别,是指通过语音判断说话人的身份的技术,是一种非常便捷、有效的身份识别技术。从生物学上,由于不同的人的发声器官,包括声带、声管等存在大小形状等方面的差异,每个人的声音存在“独一无二”的特点,即使通过模仿,也很难改变说话者本身的发声方式,这种区分说话人身份的声音特性被称为“声纹(voiceprint)”,其概念由“指纹”一词延伸而来。相比指纹识别,说话人识别技术具有非接触式特点,更加地具有易用性,随着包括智能家居系统在内的技术的广泛应用,现在说话人识别技术已经在许多生活中的人机交互应用场景中得到了广泛的应用。
3.在智能家居场景下,说话人识别系统的工作环境通常是小型的嵌入式设备,这种工作场景下设备的算力非常有限,所以对模型的复杂度压缩有很高的要求,所以实现一种要求算力低、轻量级的说话人识别模型具有极强的实际意义。
4.本发明构建一种轻量级的基于深度学习的说话人识别模型,并利用知识蒸馏技术提升模型性能。
技术实现要素:
5.本发明结合轻量级神经网络架构和知识蒸馏方法,可以在计算力有限的设备上进行说话人识别任务。
6.本发明所采用的技术方案提供一种基于bottleneck和通道切分的轻量级说话人识别方法,包括以下步骤,步骤1,基于bottleneck和通道切分构建基于深度神经网络的说话人识别模型,所述说话人识别模型的网络框架包括轻量级说话人识别网络主体和说话人识别模型池化模块,语音特征首先作为轻量级说话人识别网络主体的输入,输出为不定长的特征,将其作为说话人识别模型池化模块处理后,生成定长的说话人嵌入;步骤2,使用知识蒸馏进一步提高模型准确率,包括对基于步骤1所得说话人识别模型实现的教师模型进行预训练,定义知识蒸馏的损失函数,使用知识蒸馏训练轻量级的学生网络模型,根据训练结果实现说话人识别。
7.而且,步骤1的实现包括以下子步骤,步骤1.1,构建轻量级说话人识别网络主体;步骤1.2,构建说话人识别模型池化模块;步骤1.3,声学特征提取;步骤1.4,基于深度神经网络的说话人识别模型训练。
8.而且,所述轻量级说话人识别网络主体实现如下,
1)模型第一层使用时间通道分离一维卷积,所述时间通道分离一维卷积由一个深度一维卷积和一个点卷积组成,然后经由批归一化和激活函数处理,输入一维最大值池化处理;2)模型第一层处理完成后,将进行多层残差块处理,每一个残差块包括主分支和残差连接分支,主分支包括有三个cs-ctcsconv1d子模块和一个时间通道分离一维卷积分支,残差连接分支包括一个一维点卷积和批归一化,两个分支输出结构相加后使用prelu激活函数处理;cs-ctcsconv1d子模块中,首先进行一次通道切分运算,将输入沿着通道的维度均等切分成两个部分,每个部分分别形成一个分支的输入,其中一个分支作为直连分支不进行额外的运算,另一个分支包含三个计算单元,第一个计算单元包含的一维卷积、批归一化、relu激活函数,第二个计算单元包括一维深度分离卷积、批归一化,第三个计算单元包括一个卷积核大小为1的一维点卷积、批归一化、relu激活函数;最后将两个分支的输出沿着通道维度进行拼接操作后完成整个单元的运算;3)多层残差块处理后,经由与第一层相同的时间通道分离一维卷积、批归一化和激活函数处理,然后进行点卷积和批归一化,再经由激活函数处理,最后使用ghostvlad层进行池化,将帧级别的信息聚合起来,其结果是输入语音的说话人嵌入。
9.而且,步骤2的实现包括以下子步骤,步骤2.1,对教师模型进行预训练,所述教师网络通过将步骤1中构建的说话人识别模型中所有卷积核数量增加至原本的三倍实现;步骤2.2,定义知识蒸馏的损失函数;步骤2.3,使用知识蒸馏训练轻量级的学生网络模型,基于所得说话人识别模型进行应用,获得识别结果;步骤2.4,对步骤2.3训练所得模型进行测试,分别进行声纹识别模型准确率测试,以及声纹识别模型推理速度测试。
10.本发明还提供一种基于bottleneck和通道切分的轻量级说话人识别系统,用于实现如上所述的一种基于bottleneck和通道切分的轻量级说话人识别方法。
11.而且,包括以下模块,第一模块,用于基于bottleneck和通道切分构建基于深度神经网络的说话人识别模型,所述说话人识别模型的网络框架包括轻量级说话人识别网络主体和说话人识别模型池化模块,语音特征首先作为轻量级说话人识别网络主体的输入,输出为不定长的特征,将其作为说话人识别模型池化模块处理后,生成定长的说话人嵌入;第二模块,用于使用知识蒸馏进一步提高模型准确率,包括对基于第一模块所得说话人识别模型实现的教师模型进行预训练,定义知识蒸馏的损失函数,使用知识蒸馏训练轻量级的学生网络模型,根据训练结果实现说话人识别。
12.或者,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用存储器中的存储指令执行如上所述的一种基于bottleneck和通道切分的轻量级说话人识别方法。
13.或者,包括可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序执行时,实现如上所述的一种基于bottleneck和通道切分的轻量级说话人识别方法。
14.本发明方法构建了一个有效的轻量级说话人识别模型架构。实验结果证明,本发
明解决了说话人识别模型实际应用场景算力有限,因此需要足够轻量级网络的问题,可供实际应用场景使用。
附图说明
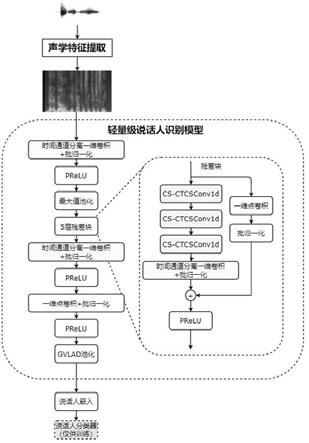
15.图1是本发明实施例轻量级说话人识别方法总体技术路线图;图2是本发明实施例深度神经网络总体示意图;图3是本发明实施例网络主体中的子模块结构示意图;图4是本发明实施例池化层流程图;图5是本发明实施例说话人表征分布图。
具体实施方式
16.为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施例对本发明作进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
17.本发明公开了一种轻量级说话人识别模型构建方案,进行轻量级基于深度神经网络的说话人模型的建模,包括设计一种基于bottleneck和通道切分轻量级神经网络模型;对轻量级说话人识别模型进行训练;基于知识蒸馏技术,使得轻量级的网络对复杂的高性能网络进行学习,从而提高轻量级网络的性能。与现有技术相比,本发明结合轻量级神经网络的设计和知识蒸馏方法,可以解决在小型的算力非常有限的嵌入式设备应用场景下的说话人识别任务。
18.本发明实施例提供一种轻量级说话人识别方法,主要在网络中使用一种新的模块,命名为通道切分-通道时间通道分离一维卷积(channel split time-channel-time separable 1-dimensional convolution,简称cs-ctcsconv1d)。另外使用一种知识蒸馏方法提升轻量级网络性能。
19.参见图1,本发明实施例提供的一种轻量级说话人识别方法,具体实施步骤如下:步骤1:基于bottleneck和通道切分的轻量级说话人识别模型建模;包括构建一种基于bottleneck(瓶颈层,即本发明提供的残差块中主分支,主要是cs-ctcsconv1d子模块部分)和通道切分的基于深度神经网络的说话人识别模型的构建,训练基于深度学习的轻量级说话人识别模型,包括声学特征提取,基于深度神经网络的说话人识别模型训练。
20.轻量级网络模型架构如图2所示,包括轻量级说话人识别网络主体和说话人识别模型池化模块,语音特征首先作为轻量级说话人识别网络主体的输入,其输出为不定长的特征,将其作为说话人识别模型池化模块的输入处理后,生成定长的说话人嵌入。
21.针对步骤1,可以采用以下步骤实现:步骤1.1:构建轻量级说话人识别网络主体; 本发明提供的优选实施方式如下:1)模型第一层使用时间通道分离一维卷积,它由一个深度一维卷积和一个点卷积组成,其中为了获得更大的感受野,深度一维卷积的卷积核大小优选取为15;为了平衡模型的计算量和准确度,点卷积的卷积核数量优选设为96。然后经由批归一化和激活函数prelu(parametric rectified linear unit)处理,之后为了将对输入图的时间长度减半,从而
减少一半的计算量,优选使用大小为3、步长为2的一维最大值池化处理。
22.2)模型第一层处理完成后,将进行多层(实施例采用5层)残差块处理,每一个残差块包括主分支和残差连接分支,主分支包括有三个cs-ctcsconv1d子模块和一个时间通道分离一维卷积(和模型第一层实现方式相同),残差连接分支包括一个一维点卷积和批归一化,两个分支输出结构相加后使用prelu激活函数处理。
23.残差层越深模型的参数量和复杂度就越高,这里的设置与卷积核数量96的原理相同,在兼顾计算复杂度和模型识别性能的情况下,实施例中优选采用5层,是合适的选择。
24.残差块内部包含的子模块为cs-ctcsconv1d,cs-ctcsconv1d的结构如图3所示,首先进行一次通道切分运算,将输入沿着通道的维度均等切分成两个部分,每个部分分别形成一个分支的输入,其中一个分支作为直连分支不进行额外的运算,另一个分支包含三个计算单元,第一个计算单元包含一个卷积核大小为1的一维卷积、批归一化、relu激活函数,第二个计算单元包括卷积核大小为15的一维深度分离卷积、批归一化,第三个计算单元和第一个计算单元类似,包括一个卷积核大小为1的一维点卷积、批归一化、relu激活函数。第一个计算单元和第三个计算单元中的一维点卷积的卷积核数量均设为96。最后将两个分支的输出沿着通道维度进行拼接操作后完成整个单元的运算。其中在本发明中,三次重复的子模块处理之后经由时间通道分离的一维卷积处理,起到通道间信息交流的作用。
25.3)五层残差块处理后,经由与第一层相同的时间通道分离一维卷积和批归一化结构、prelu激活函数处理。然后进行点卷积和批归一化,再经由prelu处理,最后使用ghost局部聚合描述子向量(ghostvlad)层进行池化,将帧级别的信息聚合起来,其结果是输入语音的说话人嵌入。
26.说话人识别模型可以有多种池化方法,本发明优选gvlad的优点在于复杂度较低,并且识别准确率较高。
27.在训练阶段,说话人嵌入优选经由增加角度边界损失函数(aam-softmax)损失函数计算训练误差,其中aam-softmax可训练参数包含一个全连接层,输入神经元数量为说话人嵌入的维度,输出神经元数量为训练集中说话人的个数。
28.步骤1.2,构建说话人识别模型池化模块;整个轻量级说话人识别网络分为轻量级说话人识别网络主体和说话人识别模型池化模块两个部分。主体负责提取帧级别的信息,此时,如果输入语音长度长那么帧数就多;而池化模块负责把帧级别的信息聚合起来,无论输入语音长度是多少,输出的说话人特征的长度都是固定长度。
29.ghostvlad的池化过程可采用相应技术,为便于实施参考起见提供相应说明:如图4所示,在池化前,模型将提取出帧级别的特征,则现有t个d维(由于设置前一层点卷积的卷积核数量为96,所以d为96)的帧级别特征组成特征集合,特征标识i=1,2,
…
t,设置o个聚类中心,其中有k个普通聚类中心和g个ghost聚类中心(ghost cluster),优选设定k的值为32,g的值为3,则o为35。
30.其中t表示时间维度的大小,与输入语音的长度直接相关,即如果需要识别的语音长度更长,则t的值更大。比如,对于2秒语音而言,t的值为100(2秒语音的输入帧是200,但是由于在模型中有大小为3、步长为2的池化运算,所以实施例中相应设置t是100);对于4秒的语
音而言,t是200。
31.具体实施时,k、g的取值和计算量相关,如果取过大的值会造成计算量增加,而数值较小会导致最终识别效果不好。
32.1)首先,在gvlad中定义局部聚合描述子向量(vlad)是一个的矩阵,可以用下式表示:其中,表示局部聚合描述子向量,表示输入进行l2归一化后的第i帧的特征在第j维数值,表示第k个聚类中心在第j维数值,表示特征与第k个聚类中心之间的关系。计算得到聚类残差。
33.2)在vlad中的数值只能取离散的值0或1,为了让神经网络能够学习到系数,采用softmax的软分配系数,得到下式:其中,i是指第i帧,n是指一共有n帧,、是可训练的参数,e是自然指数,使用输出通道数为k的一维卷积层来实现软分配系数的训练。在计算完成o=35个softmax的软分配系数后,将3个ghost聚类中心的软分配系数移除,将软分配系数与聚类残差相乘后,进行逐帧累加聚合,则得到局部聚合描述子向量。
34.3)将局部聚合描述子向量进行l2归一化,再对进行投影,投影过程为将与可训练的矩阵进行点乘,将其结果沿着第一个维度计算均值,得到d维的向量,最后对该向量依次进行批归一化、全连接层、批归一化的处理,其输出就是说话人嵌入。
35.步骤1.3:声学特征提取,首先对2到5秒的长度进行均匀随机采样,每次读取长度为均匀采样结果时长的语音序列,若原始语音文件长度不足随机采样的长度,则使用循坏补充的方式拼接到采样结果的长度。
36.获取到指定长度的音频后,对音频进行预加重处理,从而弥补声音高频部分的损耗,然后采用梅尔倒谱系数(mel-scale frequency cepstral coefficients,简称mfcc)作为模型输入的声学特征,特征提取采用16khz采样率、25毫秒帧长、10毫秒帧移、hamming窗加窗,mfcc维度为64维。
37.模型训练集使用公开数据voxceleb2数据集的开发集,该数据集包含5994人的语音,一共包含有1092009个语音片段。
38.步骤1.4:基于深度神经网络的声纹识别模型训练,对之前步骤1.1和步骤1.2中构
建的说话人识别模型进行训练,从而得到合适的参数,使用深度学习框架pytorch进行训练,使用adam优化器,学习率采用warmup和steplr策略,该策略具体指学习率从0开始,每次迭代后学习率将线性上升,直到第一轮训练完成25%时,学习率升至最大值0.001,此后每10轮,学习率衰减50%。训练环境为3张geforce rtx 2080ti显卡,mini-batch大小为128。损失函数采用aam-softmax,其中设置aam-softmax中的超参数margin为0.3、scale为30,为防止过拟合采用0.0005权值衰减的正则化方法,模型共训练100轮。该模型的等错误率可达到2.773%。
39.步骤2:可以选择使用知识蒸馏进一步提高模型准确率:包括对教师模型进行预训练,构建高性能、高复杂度的说话人识别模型、定义知识蒸馏的损失函数、使用知识蒸馏训练轻量级的学生网络模型。
40.知识蒸馏是一种让小规模的学生模型学习大规模的教师模型的技术,在本方法中,使用本发明的轻量级网络的变体作为教师网络,这个教师网络通过将步骤1中构建的轻量级网络模型中所有卷积核数量增加至原本的三倍实现,该模型的参数量为1.79m。
41.步骤2.1 首先对教师模型进行预训练,使用和步骤1.3中相同的声学特征提取方法,构建高性能、高复杂度的说话人识别模型。使用adam优化器,学习率采用warmup和steplr策略,该策略具体指学习率从0开始,每次迭代后学习率将线性上升,直到第一轮训练完成25%时,学习率升至最大值0.001,此后每10轮,学习率衰减50%。训练环境为3张geforce rtx 2080ti显卡,mini-batch大小为128。数据扩充对大规模模型性能有显著提升,所以本发明采用数据扩充方,共使用两种数据扩充方法,其一是musan数据集中的噪声数据对输入语音进行加噪的数据扩充方式,噪声包括日常噪声、音乐噪声和人声噪声,其二是使用rir数据集对输入语音进行加混响的数据扩充方式,具体地,是使用数据集中的房间冲激响应对说话人语音进行信号卷积运算。由于数据扩充具有更多的多样性,所以采用损失函数采用aam-softmax训练时使用更小的超参数margin,设置aam-softmax中的超参数margin为0.2、scale为30,模型共训练100轮。
42.步骤2.2 定义知识蒸馏的损失函数。
43.定义学生模型输出的说话人嵌入为,教师模型输出的说话人嵌入为。定义知识蒸馏的损失函数如下,其中n为mini-batch的大小,并且令每个batch中每个说话人只有一个语音,对和分别表示说话人i的语音所提取的说话人表征,使用余弦相似度。
44.另外,除了上式的损失函数,同时使用训练教师模型时所使用的aam-softmax损失函数,总体的损失函数用下式表示,其中用于平衡两个损失函数的权重,优选建议设定为10:步骤2.3 使用知识蒸馏训练学生网络模型,基于所得说话人识别模型进行应用,
获得识别结果。
45.本步骤是训练轻量级的学生网络模型。使用步骤1中的模型作为学生模型,知识蒸馏过程中对教师模型网络参数进行冻结,只对学生模型网络参数进行训练,使用步骤1.3中描述的相同的特征输入和训练配置进行模型训练。
46.模型在公开数据集voxceleb1上进行测试,voxceleb1说话人验证任务上的数据集包含有40人数据集,共有语音4,874段。使用官方发布的测试语音对进行测试,一共包含37720条语音对,语音对是指一条注册语音和一条测试语音组成的用于测试的一种组合,当注册语音和测试语音来自同一人时,真实标签为1,若两条语音来自不同人,则真实标签为0。模型性能评价使用等错误率作为评价指标,等错误率越小代表模型的准确率越高。
47.该说话人识别模型可作为小型的嵌入式设备上的说话人识别模型使用,以获取识别结果,典型应用场景有:1. 智能音箱提供个性化服务的解决方案。当前,由于语音交互具有无接触的优势,在智能音响设备通常会使用语音进行交互,而在家具环境中,智能音箱的使用者通常为多人共同使用,在多人使用的场景下需要对说话人的身份进行区分,以便提供更加精细化、个性化的服务,比如为不同说话人提供不同的歌单服务。
48.2. 利用说话人识别技术,提供声纹密码的服务,通过使用声纹密码可以代替或辅助传统的字符密码或者手势密码,解决用户忘记密码的困扰的同时,极大地减少登陆时间,方便用户使用。
49.3. 构建声纹打卡系统,说话人识别技术作为一种识别用户身份的手段,可以提供以语音作为生物特征的识别认证系统,可以代替或辅助其他生物识别如指纹考勤、人脸识别考勤使用,声纹打卡具有使用便捷、无接触的优势。
50.在本发明中,不同用户首先在注册阶段录制一段语音,经由本发明的说话人识别模型处理后,生成说话人表征,并将说话人身份和对应的说话人表征存储在设备中。在识别阶段,当有未知说话人进行语音交互时,说话人识别模型提取说话人表征,随后与在注册阶段存储在设备中的所有说话人表征进行相似度比对,比对方式为计算说话人表征之间的余弦相似度,余弦相似度取值为-1到1之间,数值越大代表相似度越大,首先找到余弦相似度数值最大的结果,若其数值超过一个人工预定义的阈值,则将该未知说话人识别为此说话人。
51.步骤2.4对模型进行测试,分别进行声纹识别模型准确率测试,以及声纹识别模型推理速度测试。
52.模型速度测试分三个维度考量,分别是模型参数量、乘法累加运算数macs和推理时间。
53.模型分别在性能较强的cpu和较弱的cpu上进行推理速度,性能较强的cpu为intel(r) xeon(r) cpu e5-2637 v4 @ 3.50ghz,性能较弱的cpu为嵌入式设备树莓派4b中的armv7 processor rev 3 (v7l)。其中,推理时间的计算为说话人识别模型从长度为两秒的语音中提取说话人嵌入的平均推理时间。
54.本发明结合轻量级神经网络架构和知识蒸馏方法,可以在计算力有限的设备上进行说话人识别任务;说话人识别模型对应的实验结果如下表所示。
55.实验结果表明本发明的模型大大减少了模型的推理时间,尤其是在算力有限的嵌入式设备中,速度有明显提升,并且能够维持准确率在较高水平,等错误率达到2.667%。
56.为进一步解释本发明的说话人模型的效果,对模型输出的高维度的说话人表征进行降维并可视化。首先在测试集中随机抽取10个说话人,并对每个说话人随机抽取30条语音,然后使用本发明模型提取说话人表征,从而得到300个高维向量的说话人表征。采用t-随机邻近嵌入算法(t-distributed stochastic neighbor embedding,简称t-sne)将高维度的说话人表征降维到二维空间中,并绘制出来,结果如图5所示,其中不同的形状代表不同的说话人。可以观察得知,在这个二维空间中,同一个说话人的说话人表征的距离更近,不同说话人的说话人表征的距离更远,不同说话人的说话人表征之间存在间隔,说明本发明模型能够区分出不同的说话人。
57.本发明构建了一个有效的轻量级说话人识别模型架构。实验结果证明,本发明解决了说话人识别模型实际应用场景算力有限,因此需要足够轻量级网络的问题,可供实际应用场景使用。
58.具体实施时,本发明技术方案提出的方法可由本领域技术人员采用计算机软件技术实现自动运行流程,实现方法的系统装置例如存储本发明技术方案相应计算机程序的计算机可读存储介质以及包括运行相应计算机程序的计算机设备,也应当在本发明的保护范围内。
59.在一些可能的实施例中,提供一种基于bottleneck和通道切分的轻量级说话人识别系统,包括以下模块,第一模块,用于基于bottleneck和通道切分构建基于深度神经网络的说话人识别模型,所述说话人识别模型的网络框架包括轻量级说话人识别网络主体和说话人识别模型池化模块,语音特征首先作为轻量级说话人识别网络主体的输入,输出为不定长的特征,将其作为说话人识别模型池化模块处理后,生成定长的说话人嵌入;第二模块,用于使用知识蒸馏进一步提高模型准确率,包括对基于第一模块所得说话人识别模型实现的教师模型进行预训练,定义知识蒸馏的损失函数,使用知识蒸馏训练轻量级的学生网络模型,根据训练结果实现说话人识别。
60.在一些可能的实施例中,提供一种基于bottleneck和通道切分的轻量级说话人识
别系统,包括处理器和存储器,存储器用于存储程序指令,处理器用于调用存储器中的存储指令执行如上所述的一种基于bottleneck和通道切分的轻量级说话人识别方法。
61.在一些可能的实施例中,提供一种基于bottleneck和通道切分的轻量级说话人识别系统,包括可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序执行时,实现如上所述的一种基于bottleneck和通道切分的轻量级说话人识别方法。
62.应当理解的是,本说明书未详细阐述的部分均属于现有技术。
63.应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。