1.本技术涉及互联网技术领域,具体涉及计算机技术领域,尤其涉及一种资源推荐方法、装置、计算机设备及存储介质。
背景技术:
2.随着计算机技术的发展,越来越多的终端或应用支持为对象群体进行资源推荐,例如为对象群体推荐聚餐地点或旅游景点等资源。目前,当需为某对象群体进行资源推荐时,通常采用如下方式实现:通过确定对象群体中的各对象的资源偏好,将资源偏好相同的对象分到一个群体,以得到不同偏好的对象组;然后,分别在每个对象组中构建不同的推荐模型并进行模型训练,进而利用训练好的各个推荐模型分别为每个对象组进行资源推荐。可见,这样的资源推荐方式本质上是将对象群体进一步细分成多个对象组,从而分别对每个对象组进行资源推荐的,其并不适用于为整个对象群体进行资源推荐;那么,当利用此资源推荐方式为对象群体进行资源推荐时,会导致资源推荐的准确性较差。
技术实现要素:
3.本技术实施例提供了一种资源推荐方法、装置、计算机设备及存储介质,可以提升资源推荐的准确性。
4.一方面,本技术实施例提供了一种资源推荐方法,所述方法包括:获取目标对象群体中的每个对象的一个或多个对象特征,一个对象的一个或多个对象特征包括:根据相应对象针对至少一个资源的操作信息确定的特征;根据所述每个对象的一个或多个对象特征对所述目标对象群体进行聚类,得到至少两个对象类别;基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述目标对象群体的特征序列的目标递归信息熵;其中,所述特征序列是采用获取到的每个对象特征构成的;根据所述目标递归信息熵从所述特征序列中选取出关键对象特征,并在确定待向所述目标对象群体推荐的多个候选资源后,基于所述关键对象特征对所述多个候选资源进行推荐决策。
5.另一方面,本技术实施例提供了一种资源推荐装置,所述装置包括:获取单元,用于获取目标对象群体中的每个对象的一个或多个对象特征,一个对象的一个或多个对象特征包括:根据相应对象针对至少一个资源的操作信息确定的特征;处理单元,用于根据所述每个对象的一个或多个对象特征对所述目标对象群体进行聚类,得到至少两个对象类别;所述处理单元,还用于基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述目标对象群体的特征序列的目标递归信息熵;其中,所述特征序列是采用获取到的每个对象特征构成的;
所述处理单元,还用于根据所述目标递归信息熵从所述特征序列中选取出关键对象特征;推荐单元,用于在确定待向所述目标对象群体推荐的多个候选资源后,基于所述关键对象特征对所述多个候选资源进行推荐决策。
6.再一方面,本技术实施例提供了一种计算机设备,所述计算机设备包括输入接口和输出接口,所述计算机设备还包括:处理器,适于实现一条或多条指令;以及,计算机存储介质,所述计算机存储介质存储有一条或多条指令,所述一条或多条指令适于由所述处理器加载并执行如下步骤:获取目标对象群体中的每个对象的一个或多个对象特征,一个对象的一个或多个对象特征包括:根据相应对象针对至少一个资源的操作信息确定的特征;根据所述每个对象的一个或多个对象特征对所述目标对象群体进行聚类,得到至少两个对象类别;基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述目标对象群体的特征序列的目标递归信息熵;其中,所述特征序列是采用获取到的每个对象特征构成的;根据所述目标递归信息熵从所述特征序列中选取出关键对象特征,并在确定待向所述目标对象群体推荐的多个候选资源后,基于所述关键对象特征对所述多个候选资源进行推荐决策。
7.再一方面,本技术实施例提供了一种计算机存储介质,所述计算机存储介质存储有一条或多条指令,所述一条或多条指令适于由处理器加载并执行上述所提及的资源推荐方法。
8.再一方面,本技术实施例提供了一种计算机程序产品,该计算机程序产品包括计算机程序;所述计算机程序被处理器执行时,实现上述所提及的资源推荐方法。
9.本技术实施例可通过目标对象群体中的每个对象的一个或多个对象特征,对目标对象群体进行聚类,来得到至少两个对象类别。其次,可综合考虑各个对象类别与每个对象特征之间的相关性信息,来确定特征序列的目标递归信息熵,并利用目标递归信息熵从特征序列中选取出关键对象特征,这样可提升关键对象特征的选取准确性。然后,可利用关键对象特征对多个候选资源进行推荐决策,这样可减少不重要的对象特征对推荐决策的干扰,提升资源推荐的准确性。
附图说明
10.为了更清楚地说明本技术实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
11.图1是本技术实施例提供的一种获取对象特征的示意图;图2是本技术实施例提供的一种资源推荐方法的流程示意图;图3是本技术另一实施例提供的一种资源推荐方法的流程示意图;图4a是本技术实施例提供的一种获取当前地理位置的示意图;
图4b本技术实施例提供的一种为对象进行导航的示意图;图5是本技术再一实施例提供的一种资源推荐方法的流程示意图;图6是本技术实施例提供的一种资源推荐装置的结构示意图;图7是本技术实施例提供的一种计算机设备的结构示意图。
具体实施方式
12.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述。
13.在本技术实施中,后续所提及的资源可以包括但不限于以下任一种:餐饮商品或其他商品、旅游景点、娱乐项目、资讯信息等。不管是哪一种资源,其均可细分为多个资源类别;例如,针对餐饮商品这一种资源而言,其可细分为火锅、粤菜、潮州菜等等;又如,针对旅游景点这一种资源而言,其可细分为自然景观景点、人文景观景点、民俗风情景点等等;又如,针对娱乐项目这一资源而言,其可细分为唱歌项目、跳舞项目、游戏项目等等。针对任一种资源而言,其可通过一个场所、地点或店铺来进行提供;本技术实施中,可将提供资源的场所、地点或店铺统称为资源提供方。即后续所提及的资源提供方可以是指用于提升餐饮商品的餐饮店铺,也可以是指用于提供娱乐项目的地点等。
14.为了实现为对象群体较为准确地进行资源推荐,本技术实施例提出了一种基于递归信息熵的资源推荐方法。通常来说,信息熵是指接收的每条消息中包含的信息的平均量,且熵的公式可以表示为:h(x)=e[i(x)]=e [-ln(p(x))],其中,e[*]表示期望,x表示输入的消息,p(x)表示相应概率;递归信息熵是指将熵的计算推广到时间空间后,上一时间维度的累计信息熵加上在当前时间维度下计算出的信息熵的累计信息熵。基于此,本技术实施例后续所提及的对象特征的信息熵可理解成是:对象特征中包含的信息的平均量;递归信息熵则是指对一个或多个特征的信息熵进行递归累加所得到的累加结果。
[0015]
具体的,该资源推荐方法先通过搜集目标对象群体中的每个对象的一个或多个对象特征(如图1所示);并通过聚类的方式根据每个对象的各个对象特征,来确定目标对象群体所涉及的至少两个对象类别,如资源偏好集中的对象类别以及资源偏好不集中的对象类别等。接着,可基于每个对象类别与获取到的每个对象特征之间的相关性信息,对由各个对象特征构成的特征序列进行信息熵的递归计算,以从特征序列中选取出关键对象特征。然后,可确定待向目标对象群体推荐的多个候选资源,并基于关键对象特征对多个候选资源进行推荐决策。进一步的,基于关键对象特征对多个候选资源进行推荐决策这一步骤的具体原理可以是:采用关键对象特征以及多个候选资源的对应的资源分类标签构建多分类模型,并通过该多分类模型的模型训练优化,实现调用优化的多分类模型来预测目标对象群体偏好每个资源分类标签的概率,进而基于预测结果对多个候选资源进行推荐决策。
[0016]
在具体实现中,本技术实施例所提出的资源推荐方法可由计算机设备执行,该计算机设备可以是终端或服务器;或者,该资源推荐方法也可由终端和服务器共同执行,对此不作限定。其中,此处所提及的终端可以包括但不限于:智能手机、电脑(如平板电脑、笔记本电脑、台式计算机等)、智能穿戴设备(如智能手表、智能眼镜)、智能语音交互设备、智能家电(如智能电视)、车载终端或飞行器等。此处所提及的服务器可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数
据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn(content delivery network,内容分发网络)、以及大数据和人工智能平台等基础云计算服务的云服务器,等等。进一步的,终端和服务器可位于区块链网络内或区块链网络外,对此不作限定。更进一步的,终端和服务器还可将内部所存储的任一数据上传至区块链网络进行存储,以防止内部所存储的数据被篡改,提升数据安全性。
[0017]
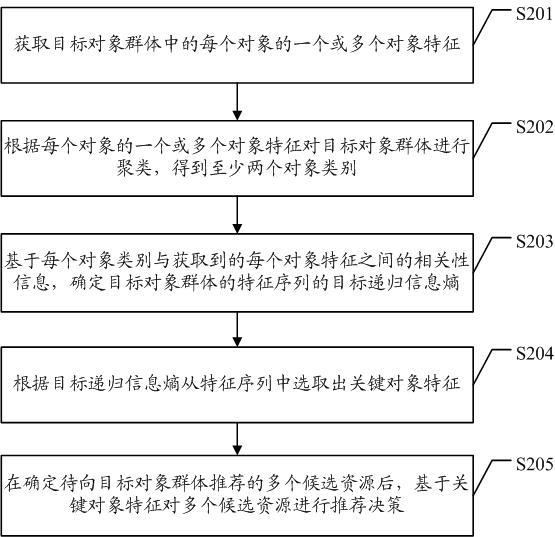
下面结合图2所示的流程图,对本技术实施例所提出的资源推荐方法的各个步骤进行具体说明;为便于阐述,本技术实施例主要以计算机设备执行该资源推荐方法为例进行说明。请参见图2,该资源推荐方法可包括以下步骤s201-s205:s201,获取目标对象群体中的每个对象的一个或多个对象特征。
[0018]
在具体实现中,目标对象群体包括多个对象;计算机设备可获取目标对象群体中的每个对象的资源操作信息,从而基于每个对象的资源操作信息确定每个对象的一个或多个对象特征。其中,一个对象的资源操作信息可至少包括:相应对象针对至少一个资源的操作信息,针对一个资源的操作信息的数量均可以是一个或多个,对此不作限定。此处所提及的操作信息可具体包括但不限于:浏览信息、点击信息、付费信息、点赞信息、评论信息等。可选的,一个对象的资源操作信息还可包括:相应对象针对一个或多个资源提供方的操作信息;在此情况下,同一资源操作信息所涉及的各个资源具体是指:相应被操作的一个或多个资源提供方中的资源。
[0019]
具体的,计算机设备根据任一对象的资源操作信息,确定任一对象的一个或多个对象特征的一种方式可以是:将任一对象中的资源操作信息中的每个操作信息,分别作为一个对象特征,从而得到任一对象的一个或多个对象特征,即一个对象特征为一个操作信息。或者,计算机设备根据任一对象的资源操作信息,确定任一对象的一个或多个对象特征的另一种方式可以是:对任一对象中的资源操作信息中的每个操作信息分别进行特征提取,从而得到任一对象的一个或多个对象特征,即一个对象特征是对一个操作信息进行特征提取得到的。
[0020]
基于上述描述可知,一个对象的一个或多个对象特征至少包括:根据相应对象针对至少一个资源的操作信息确定的特征。可选的,当对象的资源操作信息包括对象针对一个或多个资源提供方的操作信息时,一个对象的一个或多个对象特征还可包括:根据相应对象针对一个或多个资源提供方的操作信息所确定的特征。且在此情况下,一个对象的各个对象特征还可以资源提供方为单位,的各个资源具体是指:相应被操作的一个或多个资源提供方中的资源应理解的是,在其他实施例中,一个对象的资源操作信息也可只包括:相应对象针对至少一个资源的操作信息。在此情况下,针对任一对象而言,根据任一对象针对任一资源提供方的操作信息所确定的特征,以及根据任一对象针对任一资源提供方中的一个或多个资源的操作信息所确定的特征,可构成任一对象在任一资源提供方中的对象特征。
[0021]
由前述可知,上述所提及的资源可以是指餐饮商品或其他商品、旅游景点、娱乐项目、资讯信息等;相应的,资源提供方可以是指餐饮店铺、地点等。示例性的,当资源为餐饮商品,资源提供方为餐饮店铺时,步骤s201的具体实现方式可理解如下:首先,可获取目标对象群体中的每个对象的资源操作信息;一个对象的资源操作信息可包括:相应对象针对信息平台(如地图平台、外卖平台等)中的一个或多个餐饮店铺的一个或多个操作信息,如
点击信息(点击数据)、浏览信息(浏览数据)、点赞信息(点赞数据)、评论信息(评论数据)等,以及相应对象针对每个餐饮店铺中的餐饮菜单中的一个或多个餐饮商品的一个或多个操作信息,如点击信息、付费信息、浏览信息、点赞信息、评论信息等。然后,计算机设备可基于每个对象的资源操作信息确定每个对象的一个或多个对象特征。
[0022]
可以理解的是,在本技术实施例的具体实施方式中,涉及到对象的相关数据(如各种操作信息、对象特征等),均是在获取对象的许可或者同意后获取到的;也就是说,当本技术实施例运用到具体产品或技术中时,需要获得对象许可或者同意来实现相关数据的获取,且相关数据的使用和处理需要遵守相关国家和地区的相关法律法规和标准。
[0023]
s202,根据每个对象的一个或多个对象特征对目标对象群体进行聚类,得到至少两个对象类别。
[0024]
在具体实现中,计算机设备可根据每个对象的一个或多个对象特征,计算各个对象之间的对象相似度,从而按照预设的类中心的数量,根据各个对象之间的对象相似度对目标对象群体进行聚类,得到至少两类对象,一类对象对应一个类中心;然后,分别为每类对象分配一个对象类别,从而得到至少两个对象类别。可见,对象类别的数量与类中心的数量相同,且类中心的数量可根据实际需求或经验值设置,例如设置类中心k=2,那么此情况下便实现将目标对象群体聚类成两类对象,从而得到两个对象类别。
[0025]
当类中心的数量为2时,计算机设备在根据各个对象之间的对象相似度对目标对象群体进行聚类时,可认为对象相似度大于第一阈值的各个对象的资源偏好比较集中,因此可将对象相似度大于第一阈值的各个对象聚成一类,以得到第一类对象;以及,可认为除第一类对象以外的其他对象的资源偏好不太集中,因此可将除第一类对象以外的其他对象聚成一类,以得到第二类对象。以此类推:当类中心的数量为3时,计算机设备在根据各个对象之间的对象相似度对目标对象群体进行聚类时,可将对象相似度大于第一阈值的各个对象聚成一类,以得到第一类对象;将对象相似度小于或等于第一阈值,且大于第二阈值的各个对象聚成一类,以得到第二类对象;以及将除第一类对象和第二类对象以外的其他对象聚成一类,以得到第三类对象。
[0026]
其中,为第一类对象分配的对象类别可称为第一对象类别,为第二类对象分配的对象类别可称为第二对象类别,为第三类对象分配的对象类别可称为第三对象类别,以此类推。基于上述可知,不管类中心的数量为多少,计算机设备通过聚类所得到的至少两个对象类别中,可至少包括第一对象类别;该第一对象类别对应的第一类对象中的各对象的资源偏好分布集中,资源偏好分布集中的含义可理解成各对象的资源偏好相同或相似。
[0027]
进一步的,计算机设备还可为每类对象中的各对象分别标记相应的对象类别标签,以便于后续可基于对象类别标签识别对象所属的对象类别。以通过步骤s202得到两个对象类别,即第一对象类别和第二对象类别为例,计算机设备可为第一对象类别对应的第一类对象中的各个对象,分别标记“1”这一个对象类别标签,以指示相应对象为资源偏好比较集中的对象;可为第二对象类别对应的第二类对象中的各个对象,分别标记“0”这一个对象类别标签,以指示相应对象为其他对象类别(即资源偏好不太集中)的对象。
[0028]
s203,基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定目标对象群体的特征序列的目标递归信息熵;其中,特征序列是采用获取到的每个对象特征构成的。
[0029]
在具体实现中,计算机设备可基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定每个对象特征的信息熵。然后,按照每次累加一个信息熵的原则,依次对特征序列中的各个对象特征的信息熵进行递归累加;若在递归累加的过程中,检测到当前累加得到的当前递归信息熵满足递归结束条件,则将当前递归信息熵确定为目标对象群体的特征序列的目标递归信息熵。具体的,计算机设备可在递归累加的过程中,每累加得到一个递归信息熵,则比较当前累加得到的当前递归信息熵和信息熵阈值(如80%)之间的大小关系;若当前递归信息熵大于信息熵阈值,则确定当前递归信息熵满足递归结束条件,此时可停止递归;若当前递归信息熵小于或等于信息熵阈值,则确定当前递归信息熵不满足递归结束条件,此时可继续递归,直到累加得到的当前递归信息熵大于信息熵阈值为止。
[0030]
需要说明的是,对于特征序列中的第一个对象特征而言,可理解成是在零值的基础上对第一个对象特征的信息熵进行累加处理的。那么可理解的是:通过第一次递归累加所得到的当前递归信息熵,等于第一个对象特征的信息熵;通过第二次递归累加所得到的当前递归信息熵,等于第一个对象特征的信息熵和第二对象特征的信息熵的总和,以此类推。基于此,对确定目标递归信息熵的方式进行举例说明:先在零值的基础上递归累加特征序列中的第一个特征的信息熵,得到当前递归信息熵h1;若h1》80%(即信息熵阈值),则将h1作为特征序列的目标递归信息熵;若h1≤80%,则在h1的基础上递归累加特征序列中的第二个特征的信息熵,得到当前递归信息熵h2;若h2》80%,则将h2作为特征序列的目标递归信息熵;若h2≤80%,则继续在h2的基础上递归累加特征序列中的第三个特征的信息熵,得到当前递归信息熵h3,以此类推。
[0031]
需要说明的是,上述步骤s203的实施方式是以先计算出每个对象特征的信息熵,再对各个对象特征的信息熵进行递归累加处理为例进行说明的;在其他实施例中,计算机设备在执行步骤s203时,也可先不计算每个对象特征的信息熵,而是每次执行递归累加,实时计算当前需被递归累加的对象特征的信息熵,从而对计算出的信息熵进行递归累加以得到当前递归信息熵。也就是说,计算机设备在执行步骤s203时,可在第一次执行递归累加时,实时计算第一个特征的信息熵,从而在零值的基础上递归累加第一个特征的信息熵,得到当前递归信息熵h1;在第二次执行递归累加时,实时计算第二个特征的信息熵,从而在h1的基础上递归累加第二个特征的信息熵,以此类推。
[0032]
s204,根据目标递归信息熵从特征序列中选取出关键对象特征。
[0033]
由前述步骤s203的具体实施方式可知,目标递归信息熵是对特征序列中的至少一个对象特征的信息熵进行递归累加得到的;相应的,步骤s204的具体实施方式可以是:确定用于递归累加得到目标递归信息熵的各个信息熵,并确定各个信息熵分别对应的对象特征;然后,从特征序列中选取各个信息熵分别对应的对象特征,作为关键对象特征。
[0034]
例如,若目标递归信息熵是h1,则用于递归累加得到h1的信息熵包括第一个对象特征的信息熵,因此可从特征序列中选取第一个对象特征作为关键对象特征;若目标递归信息熵是h2,则用于递归累加得到h2的信息熵包括:第一个对象特征的信息熵以及第二个对象特征的信息熵,因此可从特征序列中选取第一个对象特征和第二对象特征作为关键对象特征;若目标递归信息熵是h3,则用于递归累加得到h3的信息熵包括:第一个对象特征的信息熵、第二个对象特征的信息熵,以及第三个对象特征的信息熵,因此可从特征序列中选取第一个对象特征、第二对象特征以及第三个对象特征作为关键对象特征,以此类推。
[0035]
需要说明的是,上述步骤s203-s204所提及的特征序列可以是对通过步骤s201获取到的每个对象特征进行随机排列所得到的。进一步的,考虑到对象特征的排列方式可能会在一定程度上影响到关键对象特征的选取准确性;例如,本来关键对象特征应当是对象特征a和对象特征b,但是因为特征排列时将特征a和特征b排到了第100位和第101位,但是若递归累加到第90个对象特征的信息熵时,递归信息熵就大于80%了,此时就会导致对象特征a和对象特征b无法被选取出来作为关键对象特征,从而导致选取出的关键对象特征往往是不太关键的对象特征。基于此,为了提升后续关键对象特征的选取准确性,计算机设备可根据获取到的每个对象特征的信息熵,分别确定所述每个对象特征的重要度,任一对象特征的重要度和信息熵成正比;然后,按照重要度从高到低的顺序,根据每个对象特征的重要度对所述每个对象特征进行排序,得到目标对象群体的特征序列。这样可保证特征序列中的越靠前的对象特征是越重要(即越关键)的,从而避免在进行关键对象特征选取时,这些重要的对象特征无法被选取出的情况。
[0036]
s205,在确定待向目标对象群体推荐的多个候选资源后,基于关键对象特征对多个候选资源进行推荐决策。
[0037]
在具体实现中,由于计算机设备在执行前述步骤s202时,会得到至少两个对象类别,且该至少两个对象类别中的第一对象类别对应的第一类对象中的各个对象的资源偏好比较集中,其所偏好的资源可以在一定程度上满足目标对象群体中的大多数对象的偏好。因此,计算机设备可根据第一类对象中的各对象的对象特征,确定第一类对象所偏好的多个资源;即可将第一类对象中的各对象的每个对象特征,将第一类对象中的各对象所操作过的资源作为第一类对象所偏好的多个资源。然后,计算机设备可将确定出的多个资源,确定为待向目标对象群体推荐的多个候选资源,使得多个候选资源在一定程度可满足大多数对象的偏好,这样可初步提升资源推荐的准确性。当然,确定多个候选资源的方式可不局限于这一种;例如,计算机设备还可将目标对象群体中的全部对象的对象特征所对应的资源,均作为候选资源;又如,计算机设备还可获取互联网的多个热点资源作为多个候选资源,等等。
[0038]
在确定待向目标对象群体推荐的多个候选资源后,计算机设备便可基于关键对象特征对多个候选资源进行推荐决策。在一种实施方式中,计算机设备可对每个候选资源进行特征提取,基于提取到的每个候选资源的资源特征和关键对象特征之间的相似度,对多个候选资源进行推荐决策。另一种实施方式中,计算机设备可基于机器学习/深度学习技术,通过基于关键对象特征并结合模型来对多个候选资源进行推荐决策;具体的,计算机设备可基于关键对象特征来构建一个多分类模型,从而通过多分类模型的模型优化,实现调用优化后的多分类模型对多个候选资源进行推荐决策。
[0039]
本技术实施例可通过目标对象群体中的每个对象的一个或多个对象特征,对目标对象群体进行聚类,来得到至少两个对象类别。其次,可综合考虑各个对象类别与每个对象特征之间的相关性信息,来确定特征序列的目标递归信息熵,并利用目标递归信息熵从特征序列中选取出关键对象特征,这样可提升关键对象特征的选取准确性。然后,可利用关键对象特征对多个候选资源进行推荐决策,这样可减少不重要的对象特征对推荐决策的干扰,提升资源推荐的准确性。
[0040]
基于上述图2所示的方法实施例,本技术实施例进一步提出了一种更具体的资源
推荐方法,本技术实施例仍以计算机设备执行该资源推荐方法为例进行说明。请参见图3,该资源推荐方法可包括以下步骤s301-s310:s301,获取目标对象群体中的每个对象的一个或多个对象特征。
[0041]
s302,根据每个对象的一个或多个对象特征对目标对象群体进行聚类,得到至少两个对象类别。
[0042]
在具体实现中,步骤s301-s302的具体实施方式可参见上述实施例的相关描述,在此不再赘述。其中,通过步骤s301获取到的一个对象的一个或多个对象特征包括:根据相应对象针对至少一个资源的操作信息确定的特征,以及根据相应对象针对一个或多个资源提供方的操作信息所确定的特征。通过步骤s302得到的每个对象类别均具有一个对象类别标签,例如至少两个对象类别可包括第一对象类别和第二对象类别,第一对象类别的对象类别标签为“1”,第二对象类别的对象类别标签为“0”。
[0043]
s303,基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定每个对象特征的信息熵。
[0044]
其中,任一对象类别与任一对象特征之间的相关性信息中包括:任一对象类别与所述任一对象特征之间的相关系数,相关系数的取值与对象类别和对象特征之间的相关程度成正比。在具体实现中,计算机设备可通过采用相关性公式,来计算得到每个对象类别和获取到的每个对象特征之间的相关系数;针对任一对象类别而言,该任一对象类别和每个对象特征之间的相关系数,可构成该任一对象类别对应的相关系数序列{ρ1,
…
,ρn},ρk表示任一对象类别和第k个对象特征之间的相关系数,k∈[1,n],n为获取到的对象特征的总数。
[0045]
相应的,步骤s303的具体实施方式可以是:根据每个对象类别与每个对象特征之间的相关系数的绝对值,和预设的r个相关性等级对应的取值范围,确定每个对象特征在每个对象类别下的相关性等级,r为大于1的整数。然后,可根据每个对象特征在每个对象类别下的相关性等级,分别在每个对象类别下对每个对象特征进行分组处理,得到每个对象类别下的r个相关性分组,一个相关性特征组对应一个相关性等级。其中,r个相关性等级以及每个相关性等级对应的取值范围,均可根据经验值或者实际需求设置;例如,可设置3个相关性等级:低度线性相关、显著性相关和高度线性相关,且低度线性相关对应的取值范围为|ρ|《0.4,对应的相关性特征组可被标记为组1,显著性相关对应的取值范围为0.4≤|ρ|《0.7,对应的相关性特征组可被标记为组2,高度线性相关对应的取值范围为0.7≤|ρ|《1,对应的相关性特征组可被标记为组3。
[0046]
基于上述描述,针对第k个对象特征,可计算第k个对象特征在每个对象类别下的每个相关性分组中出现的比例;具体的,针对任一对象类别下的任一相关性分组,计算机设备可以根据任一相关性分组中的各个对象特征所属的对象,确定任一相关性分组对应的对象总数(采用ni表示,i∈[1,r]);统计任一相关性分组所对应的对象中,具有第k个对象特征的对象的数量(采用表示,j的取值为各个对象类别标签,如j=0,1);将统计得到的数量和任一相关性分组对应的对象总数之间的比值,确定为第k个对象特征在任一相关性分组中出现的比例(采用表示,即)。例如,针对第一个对象类别下的第一个相关性特征组(如组1)而言,若组1总共对应100个对象,即ni的取值等于100,且组1对应的100个对象中有10个对象具有第一个对象特征,即相应的取值等于10,那么第一个对象特征
在该组1中出现的比例等于10/100=0.1。
[0047]
然后,计算机设备可根据比例计算结果以及每个对象类别对应的对象占比(采用pj表示),计算第k个对象特征的信息熵。其中,比例计算结果包括:第k个对象特征在每个对象类别下的每个相关性分组中出现的比例;任一对象类别对应的对象占比是指:任一对象类别下的对象的数量,与目标对象群体的对象总数之间的比值。具体的,以r等于3(即i=1,2,3),且两个对象类别标签(即j=0,1)为例,第k个对象特征的信息熵(采用h(k)表示)可通过下述公式1.1计算得到:式1.1基于上述描述,计算机设备可通过构建递归信息熵模型,从而使得后续可调用该递归信息熵模型实现信息熵的递归累加,以确定出特征序列的目标递归信息熵,即可通过调用该递归信息熵模型执行步骤s304-s305。并且,通过该递归信息熵模型,还可得到递归信息熵序列{h1,h2,
…
,hn};其中,递归信息熵模型可如下述公式1.2所示:式1.2s304,按照每次累加一个信息熵的原则,依次对特征序列中的各个对象特征的信息熵进行递归累加。
[0048]
s305,若在递归累加的过程中,检测到当前累加得到的当前递归信息熵满足递归结束条件,则将当前递归信息熵确定为目标对象群体的特征序列的目标递归信息熵。
[0049]
s306,根据目标递归信息熵从特征序列中选取出关键对象特征,并确定待向目标对象群体推荐的多个候选资源;其中,多个候选资源包括:根据第一类对象中的各对象的对象特征,所确定的第一类对象所偏好的多个资源。
[0050]
s307,对多个候选资源进行标签分类以得到多个资源分类标签,并基于多个资源分类标签和关键对象特征构建一个多分类模型。
[0051]
在具体实现中,可根据每个候选资源实际所属的资源类别,对多个候选资源进行标签分类,得到多个资源分类标签,一个资源分类标签用于指示一个资源类别。例如,得到的资源分类标签可以例如是:1(表示粤菜);2(表示潮州菜);3(表示安徽菜);4(表示火锅),等等。
[0052]
计算机设备在基于多个资源分类标签和关键对象特征进行模型构建后,得到的多分类模型中可包括这多个资源分类标签,且多分类模型包含如下计算公式1.3:式1.3其中,x={x
t
|t=1,2,
…
,m},其表示关键特征矩阵(或称为重要特征矩阵),m为关键对象特征的数量;w={w
t
|t=1,2,
…
,m},其表示多分类模型的模型权重矩阵;y表示资源分类标签,y=s表示第s个资源分类标签,a表示输入至多分类模型的样本,p(y=s|x)表示根据输
入的样本预测出第s个资源分类标签被偏好的概率。
[0053]
s308,将目标对象群体中的至少一个对象的各对象特征,与多个资源分类标签进行匹配以构建得到多个样本。
[0054]
其中,一个样本包括:与一个资源分类标签匹配的至少一个对象特征;并且,多个样本至少包括:训练样本和预测样本。此处提及的训练样本是指用于对多分类模型进行模型优化的样本,预测样本是指在多分类模型停止优化后,用于优化后的多分类模型进行概率预测的样本。可选的,多个样本中还可包括测试样本,该测试样本是指在优化多分类模型后,用于测试多分类模型的模型性能的样本。需要说明的是,本技术实施例对训练样本、预测样本和测试样本的数量,以及样本划分方式不作限定,例如可随机将多个样本中的部分样本作为训练样本、随机将另一部分样本中的至少一个样本作为测试样本等。
[0055]
在一种具体实现中,计算机设备将目标对象群体中的每个对象的各对象特征,均与多个资源分类标签进行匹配以构建得到多个样本。另一种具体实现中,可着重考虑目标对象群体中的资源偏好集中的各对象的对象特征,来进行模型训练优化,这样可使得优化后的多分类模型较为准确地进行预测,使得基于预测结果所决策出的目标资源符合目标对象群体中的大多数对象的偏好。基于此,计算机设备可从目标对象群体所涉及的全部对象特征中,获取第一类对象中的各对象的各对象特征;将第一类对象中的各对象的各对象特征,和多个资源分类标签进行匹配,以构建得到多个样本。
[0056]
具体的,计算机设备在采用将第一类对象中的各对象的各对象特征,和多个资源分类标签进行匹配,以构建得到多个样本时,针对第一类对象中的任一对象,计算机设备可直接将任一对象的各个对象特征与多个资源分类标签中的任一资源分类标签进行匹配,从而采用与任一资源分类标签匹配的对象特征以及该任一资源分类标签,构建一个样本。
[0057]
或者,计算机设备也可通过对第一类对象中的各对象所操作的所有资源提供方的标识(如餐饮店铺id)进行打标(如餐饮店铺id1标记为1,餐饮店铺id1标记为2,以此类推),从而通过对象id和资源提供方的打标结果,将多个资源分类标签和对象在每个资源提供方中的对象特征进行匹配,来得到多个样本。具体的,可根据第一类对象中的各对象的各对象特征,确定第一类对象所操作的各个资源提供方;并遍历各个资源提供方,确定当前遍历的当前资源提供方。针对第一类对象中的任一对象,从任一对象的各对象特征中筛选出任一对象在当前资源提供方中的各对象特征;将任一对象在所述当前资源提供方中的各对象特征,与多个资源分类标签中的任一资源分类标签进行匹配,得到匹配结果;从而根据匹配结果,从任一对象在所述当前资源提供方中的各对象特征中,获取与任一资源分类标签相匹配的对象特征;并采用获取到的对象特征构建一个样本,并为构建得到的样本标记该任一资源分类标签。
[0058]
以资源提供方为餐饮店铺,资源为餐饮商品为例进行举例说明:第一类对象中包括50个对象,分别是对象1-对象50;假设根据对象1针对餐饮店铺1的操作信息确定出了对象特征a,且根据对象1针对餐饮店铺1中的一个或多个餐饮商品的操作信息确定出了对象特征b和对象特征c,那么对象1在餐饮店铺1中的特征包括特征a、特征b和特征c。其中,若特征a和特征b与火锅这一资源类别相关,则可确定特征a和特征b均与用于指示火锅的资源分类标签“4”相匹配,那么可采用特征a和特征b构成一个样本,并为该样本打上“4”这个商品分类标签;若特征c与粤菜这一资源类别相关,则可确定特征c和特征b与用于指示粤菜的资
源分类标签“1”相匹配,那么可采用特征c构成一个样本,并为该样本打上“1”这个商品分类标签,这样便可得到对象1的两个样本,依次类推,可得到每个对象的至少一个样本,从而得到多个样本。
[0059]
s309,采用训练样本对多分类模型进行一次或多次模型优化,并调用优化后的多分类模型根据预测样本中的对象特征,预测目标对象群体偏好各个资源分类标签的概率。
[0060]
其中,采用训练样本对多分类模型进行一次模型优化的方式可以是:调用多分类模型根据训练样本中的对象特征,预测目标对象群体偏好各个资源分类标签的概率,并将最大概率对应的资源分类标签作为训练样本的预测资源分类标签,根据预测资源分类标签和训练样本携带的资源分类标签之间的差异,计算多分类模型的模型损失值,从而按照减少模型损失值的方向,优化多分类模型的模型权重。
[0061]
s310,根据预测结果从多个资源分类标签中选取目标资源分类标签,并将目标资源分类标签指示的资源类别下的候选资源,决策为待推荐的目标资源。
[0062]
其中,预测结果可包括:各个资源分类标签对应的概率;计算机设备在根据预测结果从多个资源分类标签中选取目标资源分类标签时,直接将预测结果中的最大概率对应的资源分类标签选取作为目标资源分类标签。或者,为便于执行选取操作,计算机设备可按照概率从大到小的顺序,根据预测结果对各个资源分类标签进行排序,得到资源推荐列表,从而基于资源推荐列表得到{对象id,资源分类标签,概率,排序号}矩阵,进而根据此矩阵将第一位的资源分类标签作为目标资源分类标签,以实现选取概率最大的资源分类标签作为目标资源分类标签。当然,应理解的是,在其他实施例中,计算机设备也可根据预测结果将概率大于概率阈值的一个或多个资源分类标签均作为目标资源分类标签。
[0063]
在确定出目标资源后,计算机设备可向目标对象群体中的各对象,推荐决策出的目标资源;或者,将决策出的目标资源对应的资源提供方,确定为待推荐的目标资源提供方,并向目标对象群体中的每个对象推荐目标资源提供方。进一步的,为便于目标对象群体中的各对象的出行,计算机设备还可获取目标资源提供方的目标地理位置,以及目标对象群体中的每个对象的当前地理位置;根据目标地理位置和每个对象的当前地理位置,生成每个对象到达目标资源提供方的路线;将生成的各个路线,分别推送给每个对象。
[0064]
应理解的是,在本技术实施例的具体实施方式中,涉及到对象的相关数据(如各种操作信息、对象特征以及地理位置等),均是在获取对象的许可或者同意后获取到的;也就是说,当本技术实施例运用到具体产品或技术中时,需要获得对象许可或者同意来实现相关数据的获取,且相关数据的使用和处理需要遵守相关国家和地区的相关法律法规和标准。例如,计算机设备在需获取目标对象群体中的任一对象的当前地理位置时,可在任一对象的终端中输出位置获取提示,从而在接收到任一对象针对该位置获取提示的确认操作后,获取该任一对象的当前地理位置,如图4a所示。
[0065]
进一步的,计算机设备可通过任一对象的终端中的导航应用(或地图应用),向任一对象推送相应的路线,即可以在导航应用中显示相应的路线以及导航组件。当任一对象对该导航组件执行了触发操作(如点击操作、按压操作等),可为任一对象生成导航路线,从而通过导航路线引导任一对象到达目标资源提供方,如图4b所示。
[0066]
本技术实施例可通过目标对象群体中的每个对象的一个或多个对象特征,对目标对象群体进行聚类,来得到至少两个对象类别。其次,可综合考虑各个对象类别与每个对象
特征之间的相关性信息,来确定特征序列的目标递归信息熵,并利用目标递归信息熵从特征序列中选取出关键对象特征,这样可提升关键对象特征的选取准确性。然后,可利用关键对象特征对多个候选资源进行推荐决策,这样可减少不重要的对象特征对推荐决策的干扰,提升资源推荐的准确性。并且,通过考虑同一对象群体中具有不同资源偏好的对象的对象特征,提出采用同一个多分类模型进行群体模型训练,可有效提升多分类模型的泛化性,从而进一步提升资源决策的准确性。
[0067]
在实际应用中,上述所提及的图2或图3所示的资源推荐方法可应用到各种各样的应用场景中,如群体聚餐推荐场景、群体旅游景点推荐场景、群体娱乐项目推荐场景,等等。其中,群体聚餐推荐是指:向一个对象群体推荐同一个聚餐地点(即餐饮店铺),使得该聚餐地点满足对象群体中绝大部分对象的兴趣偏好;相应的,群体旅游景点推荐是指:向一个对象群体推荐同一个旅游景点,使得旅游景点满足对象群体中绝大部分对象的兴趣偏好;群体娱乐项目推荐是指:向一个对象群体推荐同一个娱乐项目,使得该娱乐项目满足对象群体中绝大部分对象的兴趣偏好。
[0068]
下面以将该资源推荐方法运用到群体聚餐推荐场景为例,对该资源推荐方法的应用过程进行阐述;参见图5所示,此应用过程可大致包括以下十个阶段:群体聚餐数据采集阶段、群体聚类阶段、递归信息熵模型构建阶段、重要特征选择阶段、商品分类标签及样本构建阶段、softmax(一种激活函数)多分类模型构建阶段、多分类模型训练测试阶段、多分类模型预测阶段、商店匹配阶段以及路线导航阶段。其中,各阶段具体如下:step1、群体聚餐数据采集阶段。采集每个对象针对地图平台上的一个或多个餐饮店铺的点击信息、浏览信息、点赞信息、评论信息等操作信息,以及每个对象针对每个餐饮店铺中菜单上的一个或多个餐饮商品的点击信息、付费信息、浏览信息、点赞、评论信息等操作信息,从而得到每个对象的聚餐数据(即资源操作信息)。
[0069]
step2、群体聚类阶段。输入step1的每个对象的聚餐数据,以得到每个对象的一个或多个对象特征,并采用聚类算法根据每个对象的对象特征进行聚类(设置类中心k=2,即按两类进行聚类,一类为兴趣偏好较集中的对象,并标记相应的对象分类标签为1;另一类为其他类别的对象,并标记相应的对象分类标签为0),从而得到兴趣偏好较为集中的第一对象类别和兴趣偏好不集中的第二对象类别。
[0070]
step3、递归信息熵构建阶段。输入step2中的对象分类标签及每个对象的各个对象特征,计算每个对象类别y与每个特征的相关系数,得到每个对象类别对应的相关系数序列{ρ1,
…
,ρn}。根据每个对象类别对应的相关系数系列中的各个相关系数的绝对值,分别在每个对象类别下对各个对象特征进行分组(在每个对象类别下分为3个相关性特征组:|ρ|《0.4为低度线性相关,标记为组2;0.4≤|ρ|《0.7为显著性相关,标记为组2;0.7≤|ρ|《1为高度线性相关,标记为组3),从而计算每个特征在每个组内落入对象类别标签y的对象的数量(i=1,2,3;j=0,1),从而计算每个特征在每个组中出现的比例。通过聚类对象的对象数计算每个对象类别对应的对象占比pj;其中,p0表示第二对象类别对应的对象占比,p1表示第一对象类别对应的对象占比。基于此,可构建得到前述公式1.2所示的递归信息熵模型。
[0071]
step4、重要特征选择阶段。输入由各个对象特征构成的特征序列,计算每个特征下的信息熵,并且进行循环累加,如果当前累加得到的当前递归信息熵》80%(即信息熵阈
值),则停止,选择用于递归累加得到当前递归信息熵的各个信息熵对应的对象特征作为重要特征(即关键对象特征)。否则,继续迭代计算递归信息熵,直到当前递归信息熵》80%为止。
[0072]
step5、商品分类标签及样本构建阶段。将第一类对象所偏好的多个商品作为多个候选商品,并对多个候选商品进行标签分类,得到多个商品分类标签。输入step2中类别为1的各对象(即第一类对象中的各对象)所点击的所有餐饮店铺id,并对餐饮店铺id进行打标。通过对象id和餐饮店铺的打标结果将分类标签和对象在每个餐饮店铺中的对象特征进行匹配,得到训练样本、测试样本、预测样本。
[0073]
step6、softmax多分类模型构建阶段。基于多个商品分类标签和关键对象特征构建softmax多分类模型,该模型包括上述1.3所示的公式。
[0074]
step7、多分类模型训练测试阶段。输入step5训练样本并代入step6的多分类算法模型进行模型优化,并在模型优化后,输入step5测试样本并代入优化后的多分类模型中进行模型测试,若测试通过,则得到模型权重w。
[0075]
step8、多分类模型预测阶段。输入step7的模型权重以及预测样本,代入优化后的多分类模型,得到每个商品分类标签对应的概率,并将概率按从大到小进行排序,得到{对象id,商品分类标签,概率,排序号}矩阵。
[0076]
step9、餐饮店铺匹配阶段。输入step8的{对象id,商品分类标签,概率,排序号}矩阵,选择概率最大的商品分类标签下的候选商品作为待推荐的目标商品,并匹配得到该目标商品对应的目标餐饮店铺。将该目标餐饮店铺的餐饮店铺id与餐饮店铺地理位置信息库的餐饮店铺id进行匹配,以得到该目标餐饮店铺的目标地理位置。
[0077]
step10、路线导航阶段。输入step9匹配得到的目标地理位置,输入群体聚会中各个对象的当前地理位置,生成每个对象的当前地理位置与目标餐饮店铺的目标地理位置之间的路线,并将路线返回到每个对象的地图应用,对象点击导航,从而生成导航路线。其中,此处所提及的地理位置可以是lbs(location based services,基于位置的服务)位置。
[0078]
本技术实施例先通过构建聚类确定相同饮食兴趣偏好的对象类别,再采用递归信息熵模型,得到重要特征,最后对由重要特征构成的全体样本构建softmax多分类模型,进行群体模型训练和测试,从而得到推荐的目标商品,进而匹配目标商品对应的目标餐饮店铺以推荐给对象群体,可提升聚餐推荐的准确性。并且,通过获取每个用户的lbs位置,规划每个对象到目标餐饮店铺的导航路径,可提升便利性。
[0079]
基于上述资源推荐方法实施例的描述,本技术实施例还公开了一种资源推荐装置,所述资源推荐装置可以是运行于计算机设备中的一个计算机程序(包括程序代码)。该资源推荐装置可以执行图2或图3所示的资源推荐方法。请参见图6,所述资源推荐装置可以运行如下单元:获取单元601,用于获取目标对象群体中的每个对象的一个或多个对象特征,一个对象的一个或多个对象特征包括:根据相应对象针对至少一个资源的操作信息确定的特征;处理单元602,用于根据所述每个对象的一个或多个对象特征对所述目标对象群体进行聚类,得到至少两个对象类别;所述处理单元602,还用于基于每个对象类别与获取到的每个对象特征之间的相
关性信息,确定所述目标对象群体的特征序列的目标递归信息熵;其中,所述特征序列是采用获取到的每个对象特征构成的;所述处理单元602,还用于根据所述目标递归信息熵从所述特征序列中选取出关键对象特征;推荐单元603,用于在确定待向所述目标对象群体推荐的多个候选资源后,基于所述关键对象特征对所述多个候选资源进行推荐决策。
[0080]
在一种实施方式中,处理单元602在用于基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述目标对象群体的特征序列的目标递归信息熵时,可具体用于:基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述每个对象特征的信息熵;按照每次累加一个信息熵的原则,依次对所述特征序列中的各个对象特征的信息熵进行递归累加;若在所述递归累加的过程中,检测到当前累加得到的当前递归信息熵满足递归结束条件,则将所述当前递归信息熵确定为所述目标对象群体的特征序列的目标递归信息熵。
[0081]
另一种实施方式中,处理单元602还可用于:在所述递归累加的过程中,每累加得到一个递归信息熵,则比较当前累加得到的当前递归信息熵和信息熵阈值之间的大小关系;若所述当前递归信息熵大于所述信息熵阈值,则确定所述当前递归信息熵满足递归结束条件;若所述当前递归信息熵小于或等于所述信息熵阈值,则确定所述当前递归信息熵不满足递归结束条件。
[0082]
另一种实施方式中,任一对象类别与任一对象特征之间的相关性信息中包括:所述任一对象类别与所述任一对象特征之间的相关系数;相应的,处理单元602在用于基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述每个对象特征的信息熵时,可具体用于:根据每个对象类别与每个对象特征之间的相关系数的绝对值,和预设的r个相关性等级对应的取值范围,确定所述每个对象特征在所述每个对象类别下的相关性等级,r为大于1的整数;根据所述每个对象特征在所述每个对象类别下的相关性等级,分别在所述每个对象类别下对所述每个对象特征进行分组处理,得到所述每个对象类别下的r个相关性分组,一个相关性特征组对应一个相关性等级;针对第k个对象特征,计算所述第k个对象特征在所述每个对象类别下的每个相关性分组中出现的比例,k∈[1,n],n为获取到的对象特征的总数;根据比例计算结果以及所述每个对象类别对应的对象占比,计算所述第k个对象特征的信息熵;其中,任一对象类别对应的对象占比是指:所述任一对象类别下的对象的数量,与所述目标对象群体的对象总数之间的比值。
[0083]
另一种实施方式中,处理单元602在用于计算所述第k个对象特征在所述每个对象
类别下的每个相关性分组中出现的比例时,可具体用于:针对任一对象类别下的任一相关性分组,根据所述任一相关性分组中的各个对象特征所属的对象,确定所述任一相关性分组对应的对象总数;统计所述任一相关性分组所对应的对象中,具有所述第k个对象特征的对象的数量;将统计得到的数量和所述任一相关性分组对应的对象总数之间的比值,确定为所述第k个对象特征在所述任一相关性分组中出现的比例。
[0084]
另一种实施方式中,所述目标递归信息熵是对所述特征序列中的至少一个对象特征的信息熵进行递归累加得到的;相应的,处理单元602在用于根据所述目标递归信息熵从所述特征序列中选取出关键对象特征时,可具体用于:确定用于递归累加得到所述目标递归信息熵的各个信息熵,并确定所述各个信息熵分别对应的对象特征;从所述特征序列中选取所述各个信息熵分别对应的对象特征,作为关键对象特征。
[0085]
另一种实施方式中,所述至少两个对象类别包括第一对象类别,所述第一对象类别对应的第一类对象中的各对象的资源偏好分布集中;推荐单元603还可用于:根据所述第一类对象中的各对象的对象特征,确定所述第一类对象所偏好的多个资源;将确定出的所述多个资源,确定为待向所述目标对象群体推荐的多个候选资源。
[0086]
另一种实施方式中,推荐单元603在用于基于所述关键对象特征对所述多个候选资源进行推荐决策时,可具体用于:对所述多个候选资源进行标签分类以得到多个资源分类标签,并基于所述多个资源分类标签和所述关键对象特征构建一个多分类模型;将所述目标对象群体中的至少一个对象的各对象特征,与所述多个资源分类标签进行匹配以构建得到多个样本;所述多个样本至少包括:训练样本和预测样本,且一个样本包括:与一个资源分类标签匹配的至少一个对象特征;采用所述训练样本对所述多分类模型进行一次或多次模型优化,并调用优化后的多分类模型根据所述预测样本中的对象特征,预测所述目标对象群体偏好各个资源分类标签的概率;根据预测结果从所述多个资源分类标签中选取目标资源分类标签,并将所述目标资源分类标签指示的资源类别下的候选资源,决策为待推荐的目标资源。
[0087]
另一种实施方式中,所述至少两个对象类别包括第一对象类别,所述第一对象类别对应的第一类对象中的各对象的资源偏好分布集中;相应的,推荐单元603在用于将所述目标对象群体中的至少一个对象的各对象特征,与所述多个资源分类标签进行匹配以构建得到多个样本时,可具体用于:从所述目标对象群体所涉及的全部对象特征中,获取所述第一类对象中的各对象的各对象特征;将所述第一类对象中的各对象的各对象特征,和所述多个资源分类标签进行匹配,以构建得到多个样本。
[0088]
另一种实施方式中,一个对象的一个或多个对象特征还包括:根据相应对象针对一个或多个资源提供方的操作信息所确定的特征;相应的,推荐单元603在用于将所述第一类对象中的各对象的各对象特征,和所述多个资源分类标签进行匹配,以构建得到多个样本时,可具体用于:根据所述第一类对象中的各对象的各对象特征,确定所述第一类对象所操作的各个资源提供方;并遍历所述各个资源提供方,确定当前遍历的当前资源提供方;针对所述第一类对象中的任一对象,从所述任一对象的各对象特征中筛选出所述任一对象在所述当前资源提供方中的各对象特征;将所述任一对象在所述当前资源提供方中的各对象特征,与所述多个资源分类标签中的任一资源分类标签进行匹配,得到匹配结果;根据所述匹配结果,从所述任一对象在所述当前资源提供方中的各对象特征中,获取与任一资源分类标签相匹配的对象特征;采用获取到的对象特征构建一个样本,并为构建得到的样本标记所述任一资源分类标签。
[0089]
另一种实施方式中,推荐单元603还可用于:向所述目标对象群体中的各对象,推荐决策出的目标资源;或者,将决策出的目标资源对应的资源提供方,确定为待推荐的目标资源提供方,并向所述目标对象群体中的每个对象推荐所述目标资源提供方。
[0090]
另一种实施方式中,推荐单元603还可用于:获取目标资源提供方的目标地理位置,以及所述目标对象群体中的每个对象的当前地理位置;根据所述目标地理位置和所述每个对象的当前地理位置,生成所述每个对象到达所述目标资源提供方的路线;将生成的各个路线,分别推送给所述每个对象;其中,资源是指餐饮商品,资源提供方是指餐饮店铺。
[0091]
根据本技术的另一个实施例,图6所示的资源推荐装置中的各个单元可以分别或全部合并为一个或若干个另外的单元来构成,或者其中的某个(些)单元还可以再拆分为功能上更小的多个单元来构成,这可以实现同样的操作,而不影响本技术的实施例的技术效果的实现。上述单元是基于逻辑功能划分的,在实际应用中,一个单元的功能也可以由多个单元来实现,或者多个单元的功能由一个单元实现。在本技术的其它实施例中,基于资源推荐装置也可以包括其它单元,在实际应用中,这些功能也可以由其它单元协助实现,并且可以由多个单元协作实现。
[0092]
根据本技术的另一个实施例,可以通过在包括中央处理单元(cpu)、随机存取存储介质(ram)、只读存储介质(rom)等处理元件和存储元件的例如计算机的通用计算设备上运行能够执行如图2或图3中所示的相应方法所涉及的各步骤的计算机程序(包括程序代码),来构造如图6中所示的资源推荐装置设备,以及来实现本技术实施例的资源推荐方法。所述计算机程序可以记载于例如计算机可读记录介质上,并通过计算机可读记录介质装载于上述计算设备中,并在其中运行。
[0093]
本技术实施例可通过目标对象群体中的每个对象的一个或多个对象特征,对目标
对象群体进行聚类,来得到至少两个对象类别。其次,可综合考虑各个对象类别与每个对象特征之间的相关性信息,来确定特征序列的目标递归信息熵,并利用目标递归信息熵从特征序列中选取出关键对象特征,这样可提升关键对象特征的选取准确性。然后,可利用关键对象特征对多个候选资源进行推荐决策,这样可减少不重要的对象特征对推荐决策的干扰,提升资源推荐的准确性。并且,通过考虑同一对象群体中具有不同资源偏好的对象的对象特征,提出采用同一个多分类模型进行群体模型训练,可有效提升多分类模型的泛化性,从而进一步提升资源决策的准确性。
[0094]
基于上述方法实施例以及装置实施例的描述,本技术实施例还提供一种计算机设备。请参见图7,该计算机设备至少包括处理器701、输入接口702、输出接口703以及计算机存储介质704。其中,计算机设备内的处理器701、输入接口702、输出接口703以及计算机存储介质704可通过总线或其他方式连接。计算机存储介质704可以存储在计算机设备的存储器中,所述计算机存储介质704用于存储计算机程序,所述计算机程序包括程序指令,所述处理器701用于执行所述计算机存储介质704存储的程序指令。处理器701(或称cpu(central processing unit,中央处理器))是计算机设备的计算核心以及控制核心,其适于实现一条或多条指令,具体适于加载并执行一条或多条指令从而实现相应方法流程或相应功能。
[0095]
在一个实施例中,本技术实施例所述的处理器701可以用于进行一系列的资源推荐,具体包括:获取目标对象群体中的每个对象的一个或多个对象特征,一个对象的一个或多个对象特征包括:根据相应对象针对至少一个资源的操作信息确定的特征;根据所述每个对象的一个或多个对象特征对所述目标对象群体进行聚类,得到至少两个对象类别;基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述目标对象群体的特征序列的目标递归信息熵;其中,所述特征序列是采用获取到的每个对象特征构成的;根据所述目标递归信息熵从所述特征序列中选取出关键对象特征,并在确定待向所述目标对象群体推荐的多个候选资源后,基于所述关键对象特征对所述多个候选资源进行推荐决策,等等。
[0096]
本技术实施例还提供了一种计算机存储介质(memory),所述计算机存储介质是计算机设备中的记忆设备,用于存放程序和数据。可以理解的是,此处的计算机存储介质既可以包括计算机设备中的内置存储介质,当然也可以包括计算机设备所支持的扩展存储介质。计算机存储介质提供存储空间,该存储空间存储了计算机设备的操作系统。并且,在该存储空间中还存放了适于被处理器加载并执行的一条或多条的指令,这些指令可以是一个或一个以上的计算机程序(包括程序代码)。需要说明的是,此处的计算机存储介质可以是高速ram存储器,也可以是非不稳定的存储器(non-volatile memory),例如至少一个磁盘存储器;可选的,还可以是至少一个位于远离前述处理器的计算机存储介质。
[0097]
在一个实施例中,可由处理器加载并执行计算机存储介质中存放的一条或多条指令,以实现上述有关图2或图3所示的资源推荐方法实施例中的方法的相应步骤;具体实现中,计算机存储介质中的一条或多条指令由处理器加载并执行如下步骤:获取目标对象群体中的每个对象的一个或多个对象特征,一个对象的一个或多个对象特征包括:根据相应对象针对至少一个资源的操作信息确定的特征;根据所述每个对象的一个或多个对象特征对所述目标对象群体进行聚类,得到至
少两个对象类别;基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述目标对象群体的特征序列的目标递归信息熵;其中,所述特征序列是采用获取到的每个对象特征构成的;根据所述目标递归信息熵从所述特征序列中选取出关键对象特征;在确定待向所述目标对象群体推荐的多个候选资源后,基于所述关键对象特征对所述多个候选资源进行推荐决策。
[0098]
在一种实施方式中,在基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述目标对象群体的特征序列的目标递归信息熵时,所述一条或多条指令可由处理器加载并具体执行:基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述每个对象特征的信息熵;按照每次累加一个信息熵的原则,依次对所述特征序列中的各个对象特征的信息熵进行递归累加;若在所述递归累加的过程中,检测到当前累加得到的当前递归信息熵满足递归结束条件,则将所述当前递归信息熵确定为所述目标对象群体的特征序列的目标递归信息熵。
[0099]
另一种实施方式中,所述一条或多条指令还可由处理器加载并具体执行:在所述递归累加的过程中,每累加得到一个递归信息熵,则比较当前累加得到的当前递归信息熵和信息熵阈值之间的大小关系;若所述当前递归信息熵大于所述信息熵阈值,则确定所述当前递归信息熵满足递归结束条件;若所述当前递归信息熵小于或等于所述信息熵阈值,则确定所述当前递归信息熵不满足递归结束条件。
[0100]
另一种实施方式中,任一对象类别与任一对象特征之间的相关性信息中包括:所述任一对象类别与所述任一对象特征之间的相关系数;相应的,在基于每个对象类别与获取到的每个对象特征之间的相关性信息,确定所述每个对象特征的信息熵时,所述一条或多条指令可由处理器加载并具体执行:根据每个对象类别与每个对象特征之间的相关系数的绝对值,和预设的r个相关性等级对应的取值范围,确定所述每个对象特征在所述每个对象类别下的相关性等级,r为大于1的整数;根据所述每个对象特征在所述每个对象类别下的相关性等级,分别在所述每个对象类别下对所述每个对象特征进行分组处理,得到所述每个对象类别下的r个相关性分组,一个相关性特征组对应一个相关性等级;针对第k个对象特征,计算所述第k个对象特征在所述每个对象类别下的每个相关性分组中出现的比例,k∈[1,n],n为获取到的对象特征的总数;根据比例计算结果以及所述每个对象类别对应的对象占比,计算所述第k个对象特征的信息熵;其中,任一对象类别对应的对象占比是指:所述任一对象类别下的对象的数量,与所述目标对象群体的对象总数之间的比值。
[0101]
另一种实施方式中,在计算所述第k个对象特征在所述每个对象类别下的每个相关性分组中出现的比例时,所述一条或多条指令可由处理器加载并具体执行:针对任一对象类别下的任一相关性分组,根据所述任一相关性分组中的各个对象特征所属的对象,确定所述任一相关性分组对应的对象总数;统计所述任一相关性分组所对应的对象中,具有所述第k个对象特征的对象的数量;将统计得到的数量和所述任一相关性分组对应的对象总数之间的比值,确定为所述第k个对象特征在所述任一相关性分组中出现的比例。
[0102]
另一种实施方式中,所述目标递归信息熵是对所述特征序列中的至少一个对象特征的信息熵进行递归累加得到的;相应的,在根据所述目标递归信息熵从所述特征序列中选取出关键对象特征时,所述一条或多条指令可由处理器加载并具体执行:确定用于递归累加得到所述目标递归信息熵的各个信息熵,并确定所述各个信息熵分别对应的对象特征;从所述特征序列中选取所述各个信息熵分别对应的对象特征,作为关键对象特征。
[0103]
另一种实施方式中,所述至少两个对象类别包括第一对象类别,所述第一对象类别对应的第一类对象中的各对象的资源偏好分布集中;推荐单元603还可用于:根据所述第一类对象中的各对象的对象特征,确定所述第一类对象所偏好的多个资源;将确定出的所述多个资源,确定为待向所述目标对象群体推荐的多个候选资源。
[0104]
另一种实施方式中,在基于所述关键对象特征对所述多个候选资源进行推荐决策时,所述一条或多条指令可由处理器加载并具体执行:对所述多个候选资源进行标签分类以得到多个资源分类标签,并基于所述多个资源分类标签和所述关键对象特征构建一个多分类模型;将所述目标对象群体中的至少一个对象的各对象特征,与所述多个资源分类标签进行匹配以构建得到多个样本;所述多个样本至少包括:训练样本和预测样本,且一个样本包括:与一个资源分类标签匹配的至少一个对象特征;采用所述训练样本对所述多分类模型进行一次或多次模型优化,并调用优化后的多分类模型根据所述预测样本中的对象特征,预测所述目标对象群体偏好各个资源分类标签的概率;根据预测结果从所述多个资源分类标签中选取目标资源分类标签,并将所述目标资源分类标签指示的资源类别下的候选资源,决策为待推荐的目标资源。
[0105]
另一种实施方式中,所述至少两个对象类别包括第一对象类别,所述第一对象类别对应的第一类对象中的各对象的资源偏好分布集中;相应的,在将所述目标对象群体中的至少一个对象的各对象特征,与所述多个资源分类标签进行匹配以构建得到多个样本时,所述一条或多条指令可以由处理器加载并具体执行:从所述目标对象群体所涉及的全部对象特征中,获取所述第一类对象中的各对象的各对象特征;将所述第一类对象中的各对象的各对象特征,和所述多个资源分类标签进行匹
配,以构建得到多个样本。
[0106]
另一种实施方式中,一个对象的一个或多个对象特征还包括:根据相应对象针对一个或多个资源提供方的操作信息所确定的特征;相应的,推荐单元603在用于将所述第一类对象中的各对象的各对象特征,和所述多个资源分类标签进行匹配,以构建得到多个样本时,可具体用于:根据所述第一类对象中的各对象的各对象特征,确定所述第一类对象所操作的各个资源提供方;并遍历所述各个资源提供方,确定当前遍历的当前资源提供方;针对所述第一类对象中的任一对象,从所述任一对象的各对象特征中筛选出所述任一对象在所述当前资源提供方中的各对象特征;将所述任一对象在所述当前资源提供方中的各对象特征,与所述多个资源分类标签中的任一资源分类标签进行匹配,得到匹配结果;根据所述匹配结果,从所述任一对象在所述当前资源提供方中的各对象特征中,获取与任一资源分类标签相匹配的对象特征;采用获取到的对象特征构建一个样本,并为构建得到的样本标记所述任一资源分类标签。
[0107]
另一种实施方式中,所述一条或多条指令还可由处理器加载并具体执行:向所述目标对象群体中的各对象,推荐决策出的目标资源;或者,将决策出的目标资源对应的资源提供方,确定为待推荐的目标资源提供方,并向所述目标对象群体中的每个对象推荐所述目标资源提供方。
[0108]
另一种实施方式中,所述一条或多条指令还可由处理器加载并具体执行:获取目标资源提供方的目标地理位置,以及所述目标对象群体中的每个对象的当前地理位置;根据所述目标地理位置和所述每个对象的当前地理位置,生成所述每个对象到达所述目标资源提供方的路线;将生成的各个路线,分别推送给所述每个对象;其中,资源是指餐饮商品,资源提供方是指餐饮店铺。
[0109]
本技术实施例可通过目标对象群体中的每个对象的一个或多个对象特征,对目标对象群体进行聚类,来得到至少两个对象类别。其次,可综合考虑各个对象类别与每个对象特征之间的相关性信息,来确定特征序列的目标递归信息熵,并利用目标递归信息熵从特征序列中选取出关键对象特征,这样可提升关键对象特征的选取准确性。然后,可利用关键对象特征对多个候选资源进行推荐决策,这样可减少不重要的对象特征对推荐决策的干扰,提升资源推荐的准确性。并且,通过考虑同一对象群体中具有不同资源偏好的对象的对象特征,提出采用同一个多分类模型进行群体模型训练,可有效提升多分类模型的泛化性,从而进一步提升资源决策的准确性。
[0110]
需要说明的是,根据本技术的一个方面,还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述图2或图3所示的资源推荐方法实施例方面的各种可选方式中提供的方法。
[0111]
并且,应理解的是,以上所揭露的仅为本技术较佳实施例而已,当然不能以此来限定本技术之权利范围,因此依本技术权利要求所作的等同变化,仍属本技术所涵盖的范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。