1.本技术涉及算术运算装置。更具体地讲,本发明涉及执行卷积运算的算术运算装置和算术运算系统。
背景技术:
2.cnn(卷积神经网络)是一种深度神经网络,主要广泛用于图像识别领域。该cnn在卷积层中对输入特征图(包括输入图像)执行卷积运算,在后续级中将运算结果传输到全连接层,在其上执行运算,并在最后级中从输出层输出结果。空间卷积(sc)运算通常用于卷积层中的运算。在该空间卷积中,对所有位置处的数据执行:使用核(kernel)对输入特征图上的相同位置处的目标数据及其周边数据执行卷积运算,以及将通道方向上的所有卷积运算结果相加。因此,在使用空间卷积的cnn中,乘积求和运算量和参数数据量变得巨大。
3.另一方面,深度、逐点能分离卷积(dpsc)运算作为运算方法被提出,与空间卷积相比,它减小了运算的量和参数的数量(例如参见ptl 1)。该dpsc对输入特征图执行深度卷积并对所生成的运算结果执行逐点卷积(即1
×
1卷积运算)以生成输出特征图。
4.[引文列表]
[0005]
[专利文献]
[0006]
[专利文献1]
[0007]
美国专利申请公开号2018/0189595
技术实现要素:
[0008]
[技术问题]
[0009]
在上述常规技术中,使用dpsc运算来减小卷积层中的运算量和参数数量。然而,在该常规技术中,深度卷积的执行结果暂时存储在中间数据缓冲器中,并且从中间数据缓冲器读取执行结果以执行逐点卷积。因此,需要用于存储深度卷积的执行结果的中间数据缓冲器,lsi的内部存储器大小增加,并且lsi的面积成本和功耗增加。
[0010]
本技术是针对上述问题而提出的,并且其目的是在不增加存储器大小的情况下实现dpsc运算并减小积层中的运算量和参数数量。
[0011]
[问题的解决方案]
[0012]
本技术是为了解决上述问题而提出的,并且其第一方面提供了一种算术运算装置和算术运算系统,包括:第一乘积求和算子,该第一乘积求和算子执行输入数据和第一权重的乘积求和运算;第二乘积求和算子,该第二乘积求和算子连接到第一乘积求和算子的输出部以执行第一乘积求和算子的输出和第二权重的乘积求和运算;以及累积单元,该累积单元顺序地将第二乘积求和算子的输出相加。这具有的效果是,由第一乘积求和算子生成的运算结果直接供应给第二乘积求和算子,并且第二乘积求和算子的运算结果被顺序地加到累积单元。
[0013]
在第一方面中,累积单元可包括:累积缓冲器,该累积缓冲器保持累积结果;以及
累积加法器,该累积加法器将保持在累积缓冲器中的累积结果和第二乘积求和算子的输出相加,以将相加结果保持在累积缓冲器中作为新累积结果。这具有的效果是,第二乘积求和算子的运算结果被顺序地相加并保存在累积缓冲器中。
[0014]
在该第一方面中,第一乘积求和算子可包括:m
×
n个乘法器,所述m
×
n个乘法器执行m
×
n(m和n是正整数)条输入数据和对应的m
×
n个第一权重的相乘;以及相加单元,该相加单元将m
×
n个乘法器的输出相加并将相加结果输出到输出部。在这种情况下,加法器可包括并行地将m
×
n个乘法器的输出相加的加法器。这具有的效果是,m
×
n个乘法器的输出并行相加。在这种情况下,加法器可包括用于顺序地将m
×
n个乘法器的输出相加的串联连接的m
×
n个加法器。这具有的效果是,m
×
n个乘法器的输出被顺序相加。
[0015]
在该第一方面中,第一乘积求和算子可包括:n个乘法器,所述n个乘法器针对n条输入数据执行m
×
n(m和n是正整数)条输入数据和对应的m
×
n个第一权重的相乘;n个第二累积单元,所述n个第二累积单元顺序地将第一乘积求和算子的输出相加;以及加法器,该加法器将n个乘法器的输出相加m次以将相加结果输出到输出部。这具有的效果是,由n个乘法器生成m
×
n个乘积求和运算结果。
[0016]
在该第一方面中,第一乘积求和算子可包括m
×
n个乘法器,所述m
×
n个乘法器执行m
×
n(m和n是正整数)条输入数据和对应的m
×
n个第一权重的相乘,累积单元可包括:累积缓冲器,该累积缓冲器保持累积结果;第一选择器,该第一选择器从m
×
n个乘法器的输出和累积缓冲器的输出中选择预定输出;以及加法器,该加法器将第一选择器的输出相加,并且第二乘积求和算子可包括第二选择器,该第二选择器选择加法器的输出或输入数据以将所选择的一者输出到m
×
n个乘法器中的一者。这具有的效果是,在第一乘积求和算子和第二乘积求和算子之间共享乘法器。
[0017]
在第一方面中,算术运算装置还可包括切换电路,该切换电路执行切换以使得将第一乘积求和算子的输出或第二乘积求和算子的输出供应给累积单元,其中,累积单元可顺序地将第一乘积求和算子的输出或第二乘积求和算子的输出相加。这具有的效果是,切换电路在第一乘积求和算子的运算结果和经由第二乘积求和算子的运算结果之间切换,并且运算结果在累积单元中被顺序地相加。
[0018]
在第一方面中,算术运算装置还可包括算术控制单元,算术控制单元在累积单元将第一乘积求和算子的输出相加时,供应用作第二乘积求和算子中的识别元素的预定值而不是第二权重。这具有的效果是,根据算术控制单元的控制切换第一乘积求和算子的运算结果和经由第二乘积求和算子的运算结果,并且运算结果在累积单元中被顺序地相加。
[0019]
在第一方面中,输入数据可为传感器的测量数据,并且算术运算装置可为神经网络加速器。输入数据可为一维数据,并且算术运算装置可为一维数据信号处理装置。输入数据可为二维数据,并且算术运算装置可为视觉处理器。
附图说明
[0020]
图1是cnn的总体配置的示例。
[0021]
图2是cnn的卷积层中的空间卷积运算的概念图。
[0022]
图3是cnn的卷积层中的深度、逐点能分离卷积运算的概念图。
[0023]
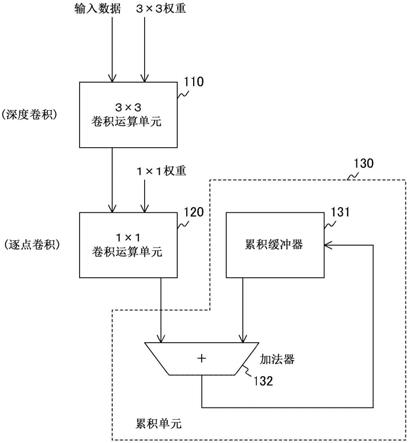
图4是示出根据本技术的实施例的dpsc运算装置的基本配置的示例的示图。
[0024]
图5是示出根据本技术的实施例的一个输入特征图21中的目标数据23的dpsc运算的示例的示图。
[0025]
图6是示出根据本技术的实施例的p个输入特征图21中的目标数据23的dpsc运算的示例的示图。
[0026]
图7是示出根据本技术的实施例的层间dpsc运算的示例的示图。
[0027]
图8是示出根据本技术的实施例的dpsc运算装置的第一实施例的示图。
[0028]
图9是示出根据本技术的实施例的dpsc运算装置的第二示例的示图。
[0029]
图10是示出根据本技术的实施例的dpsc运算装置的第三示例的示图。
[0030]
图11是示出根据本技术的实施例的dpsc运算装置的第三示例中的深度卷积期间的运算示例的示图。
[0031]
图12是示出根据本技术的实施例的dpsc运算装置的第三示例中的逐点卷积期间的运算示例的示图。
[0032]
图13是示出根据本技术的实施例的dpsc运算装置的第四示例的示图。
[0033]
图14是示出根据本技术的实施例的输入数据的示例的示图。
[0034]
图15是示出根据本技术的实施例的dpsc运算装置的第四示例的运算定时示例的示图。
[0035]
图16是示出根据本技术的第二实施例的算术运算装置的第一配置示例的示图。
[0036]
图17是示出根据本技术的第二实施例的算术运算装置的第二配置示例的示图。
[0037]
图18是示出根据本技术的实施例的使用算术运算装置的并行算术运算装置的配置示例的示图。
[0038]
图19是示出根据本技术的实施例的使用算术运算装置的识别处理装置的配置示例的示图。
[0039]
图20是示出根据本技术的实施例的算术运算装置中的一维数据的第一应用示例的示图。
[0040]
图21是示出根据本技术的实施例的算术运算装置中的一维数据的第二应用示例的示图。
具体实施方式
[0041]
以下,将描述用于执行本技术的模式(以下称为实施例)。说明将按以下顺序进行。
[0042]
1.第一实施例(执行dpsc运算的示例)
[0043]
2.第二实施例(在dpsc运算和sc运算之间切换的示例)
[0044]
3.应用示例
[0045]
<1.第一实施例>
[0046]
[cnn]
[0047]
图1是cnn的总体配置的示例。该cnn是一种类型的深度神经网络,并且包括卷积层20、全连接层30和输出层40。
[0048]
卷积层20是用于提取输入图像10的特征值的层。卷积层20具有多个层,并且接收输入图像10并在每一层中顺序地执行卷积运算过程。全连接层30将卷积层20的运算结果组合成一个节点并且生成通过激活功能转换的特征变量。输出层40对由全连接层30生成的特
征变量进行分类。
[0049]
例如,在对象识别的情况下,在学习100个标记对象后输入识别目标图像。此时,对应于输出层的每个标签的输出指示输入图像的匹配概率。
[0050]
图2是cnn的卷积层中的空间卷积运算的概念图。
[0051]
在cnn的卷积层中通常使用的空间卷积(sc)运算中,使用核22对特定层#l(l是正整数)处的输入特征图(ifm)21上的相同位置处的目标数据23及其周边数据24执行卷积运算。例如,假设核22具有3
×
3的核大小,并且相应值为k11至k33。另外,对应于核22的输入数据的每个值被设置为a11至a33。此时,执行以下等式的乘积求和运算作为卷积运算。
[0052]
卷积运算结果=a11
×
k11 a12
×
k12
…
a33
×
k33
[0053]
在这之后,在通道方向上将所有卷积运算结果相加。因此,获得下一层#(l 1)的相同位置处的数据。
[0054]
通过对所有位置处的数据执行这些运算,生成一个输出特征图(ofm)。然后,通过改变核来将这些运算重复输出特性图的数量。
[0055]
如上所述,在使用空间卷积的cnn中,乘积求和运算量和参数数据量变得巨大。因此,如上所述,使用以下深度、逐点能分离卷积(dpsc)运算。
[0056]
图3是cnn的卷积层中的深度、逐点能分离卷积运算的概念图。
[0057]
在该深度、逐点能分离卷积(dpsc)运算中,如图中的“a”所示,对输入特征图21执行深度卷积以生成中间数据26。然后,如图中的“b”所示,使用逐点卷积核28对所生成的中间数据26执行作为1
×
1卷积运算的逐点卷积,并且生成输出特征图29。
[0058]
在深度卷积中,使用深度卷积核25(在该示例中具有3
×
3的核大小)对一个输入特征图21执行卷积运算以生成一条中间数据26。这针对所有输入特征图21执行。
[0059]
在逐点卷积中,对中间数据26中的特定位置处的数据执行具有1
×
1的核大小的卷积运算。针对所有条中间数据26的相同位置执行该卷积,并且在通道方向上将所有卷积运算结果相加。通过对所有位置处的数据执行这些运算,生成一个输出特征图29。通过改变1
×
1核来将上述处理重复执行输出特征图29的数量。
[0060]
[基本配置]
[0061]
图4是示出根据本技术的实施例的dpsc运算装置的基本配置的示例的示图。
[0062]
该dpsc运算装置包括3
×
3卷积运算单元110、1
×
1卷积运算单元120和累积单元130。在下面的示例中,假定深度卷积核25具有3
×
3的核大小,但通常,它可具有m
×
n的任何大小(m和n是正整数)。
[0063]3×
3卷积运算单元110执行深度卷积运算。3
×
3卷积运算单元110对输入特征图21的“输入数据”执行其深度卷积核25为“3
×
3权重”的卷积运算。也就是说,执行输入数据和3
×
3权重的乘积求和运算。
[0064]1×
1卷积运算单元120执行逐点卷积运算。1
×
1卷积运算单元120对3
×
3卷积运算单元110的输出执行其逐点卷积核28为“1
×
1权重”的卷积运算。也就是说,执行3
×
3卷积运算单元110的输出和1
×
1权重的乘积求和运算。
[0065]
累积单元130顺序地将1
×
1卷积运算单元120的输出相加。累积单元130包括累积缓冲器131和加法器132。累积缓冲器131是保持加法器132的相加结果的缓冲器(累加缓冲器)。加法器132是将累积缓冲器131中保持的值与1
×
1卷积运算单元120的输出相加并将相
加结果保持在累积缓冲器131中的加法器。因此,累积缓冲器131保持1
×
1卷积运算单元120的输出的累积和。
[0066]
这里,3
×
3卷积运算单元110的输出直接连接到1
×
1卷积运算单元120的一个输入。也就是说,在此期间,不需要保持矩阵数据的如此大容量的中间数据缓冲器。然而,如在后面描述的示例中,可插入保持单条数据的触发器等以主要用于定时调整。
[0067]
图5是示出根据本技术的实施例的一个输入特征图21中的目标数据23的dpsc运算的示例的示图。
[0068]
聚焦于一个输入特征图21中的单条数据(目标数据23),该dpsc运算装置根据以下过程执行运算。
[0069]
(a)由3
×
3卷积运算单元110进行的深度卷积
[0070]
r1
←
a11
×
k11 a12
×
k12
…
a33
×
k33
[0071]
(b)由1
×
1卷积运算单元120进行的逐点卷积(k11:权重)
[0072]
r2
←
r1
×
k11
[0073]
(c)由累积单元130进行的累积相加(ab:保持在累积缓冲器131中的内容)
[0074]
ab
←
ab r2
[0075]
也就是说,在本实施例中,通过dpsc运算装置的一个运算执行针对一个输入特征图21中的目标数据23的dpsc运算。
[0076]
图6是示出根据本技术的实施例的p个输入特征图21中的目标数据23的dpsc运算的示例的示图。
[0077]
假设输入特征图21的数据条数为m
×
n并且输入特征图21的数量为p(m、n、p为正整数),通过将本实施例中的dpsc运算装置的运算执行m
×
n
×
p次来生成一个输出特征图29。
[0078]
图7是示出根据本技术的实施例的层间dpsc运算的示例的示图。
[0079]
如上所述,根据本技术的实施例的dpsc运算装置,可在没有用于存储深度卷积结果的中间数据缓冲器的情况下执行dpsc运算装置。然而,如该图所示,由于需要以输出特征图29的数量重复执行针对一个输出特征图29的处理,因此深度卷积的执行数量增加。
[0080]
[第一示例]
[0081]
图8是示出根据本技术的实施例的dpsc运算装置的第一示例的示图。
[0082]
在该第一示例中,提供了九个乘法器111、一个加法器118和触发器119作为3
×
3卷积运算单元110。
[0083]
每个乘法器111是将输入数据的一个值与深度卷积中的3
×
3权重的一个值相乘的乘法器。也就是说,九个乘法器111并行地执行深度卷积中的九个相乘。
[0084]
加法器118是将九个乘法器111的相乘结果相加的加法器。该加法器118在深度卷积中生成乘积求和运算结果r1。
[0085]
触发器119保持由加法器118生成的乘积求和运算结果r1。触发器119主要保持用于定时调整的单条数据,并且不一起保持矩阵数据。
[0086]
在该第一示例中,乘法器121被设置为1
×
1卷积运算单元120。乘法器121是在逐点卷积中将由加法器118生成的乘积求和运算结果r1与1
×
1权重k11相乘的乘法器。
[0087]
累积单元130与上述实施例的累积单元相同,并且包括累积缓冲器131和加法器132。
[0088]
[第二示例]
[0089]
图9是示出根据本技术的实施例的dpsc运算装置的第二示例的示图。
[0090]
在该第二示例中,提供三个乘法器111、三个加法器112、三个缓冲器113、一个加法器118和一个触发器119作为3
×
3卷积运算单元110。也就是说,在上述第一示例中,由九个乘法器111并行执行深度卷积中的九个相乘。然而,在第二示例中,由三个乘法器111分三次执行深度卷积中的九个相乘。因此,在每个乘法器111中设置加法器112和缓冲器113,并且将三次的相乘结果累积地相加。
[0091]
也就是说,缓冲器113是保持加法器112的相加结果的缓冲器。加法器112是将保持在缓冲器113中的值与乘法器111的输出相加并将相加结果保持在缓冲器113中的加法器。因此,缓冲器113保持乘法器111的输出的累积和。加法器118和触发器119与上述第一示例中的那些相同。
[0092]
将乘法器121设置为1
×
1卷积运算单元120这一点与上述第一示例相同。累积单元130包括累积缓冲器131和加法器132这一点与上述第一示例相同。
[0093]
如上所述,在该第二示例中,可通过由三个乘法器111分三次执行深度卷积中的九个乘法来减小乘法器111的数量。
[0094]
[第三示例]
[0095]
图10是示出根据本技术的实施例的dpsc运算装置的第三示例的示图。
[0096]
在该第三示例中,组合地使用深度卷积所需的乘法器和逐点卷积所需的乘法器。也就是说,在该第三示例中,九个乘法器111由3
×
3卷积运算单元110和1
×
1卷积运算单元120共享。
[0097]
在该第三示例中,累积单元130包括累积缓冲器133、选择器134和加法器135。如后文将描述,选择器134根据操作状态选择九个乘法器111的输出和累积缓冲器133中保持的值中的一者。
[0098]
加法器135是根据操作状态将保持在累积缓冲器133中的值或选择器134的输出相加并将相加结果保持在累积缓冲器133中的加法器。因此,累积缓冲器133保持选择器134的输出的累积和。
[0099]
第三示例的dpsc运算装置还包括选择器124。如后文将描述,选择器124根据操作状态选择输入数据或权重。
[0100]
图11是示出根据本技术的实施例的dpsc运算装置的第三示例中的深度卷积期间的运算示例的示图。
[0101]
在深度卷积期间,每个乘法器111将输入数据的一个值与深度卷积中的3
×
3权重的一个值相乘。此时,选择器124选择输入数据的一个值和深度卷积中的3
×
3权重的一个值并且将所选择的值供应给一个乘法器111。因此,在该深度卷积期间的算术处理与上述第一示例的算术处理相同。
[0102]
图12是示出根据本技术的实施例的dpsc运算装置的第三示例中的逐点卷积期间的运算示例的示图。
[0103]
在逐点卷积期间,选择器124选择1
×
1权重和来自加法器135的输出并且将选择的值提供给一个乘法器111。因此,被供应值的乘法器111执行乘法以用于逐点卷积。另一方面,其他八个乘法器111不操作。
[0104]
选择器134选择一个乘法器111的相乘结果和累积缓冲器133中保持的值并且将所选择的值供应给加法器135。因此,加法器135将一个乘法器111的相乘结果与累积缓冲器133中保持的值相加并且将该相加结果保持在累积缓冲器133中。
[0105]
因此,在该第三示例中,通过将逐点卷积所需的一个乘法器与深度卷积所需的乘法器共享,与第一示例相比,可减小乘法器的数量。然而,在这种情况下,与深度卷积相比,乘法器111在逐点卷积期间的利用率减小到1/9。
[0106]
[第四示例]
[0107]
图13是示出根据本技术的实施例的dpsc运算装置的第四示例的示图。
[0108]
在该第四示例中,提供九个乘法器111和九个加法器118作为3
×
3卷积运算单元110。九个乘法器111中的每一者与上述第一示例的乘法器类似,它将输入数据的一个值与深度卷积中的3
×
3权重的一个值相乘。九个加法器118串联连接,并且某一加法器118的输出连接到下一级加法器118的一个输入。然而,0被供应给第一级加法器118的一个输入。乘法器111的输出连接到加法器118的另一个输入。
[0109]
将乘法器121设置为1
×
1卷积运算单元120这一点与上述第一示例相同。累积单元130包括累积缓冲器131和加法器132这一点与上述第一示例的点相同。
[0110]
图14是示出本技术的实施例中的输入数据的示例的示图。
[0111]
输入特征图21被分成与核大小3
×
3相对应的九条,并作为输入数据输入到3
×
3卷积运算单元110。此时,在3
×
3输入数据#1旁边,输入向右移位一的3
×
3输入数据#2。当到达输入特征图21的右端时,输入数据向下移位一并且类似地从左端输入数据。
[0112]
这些条输入数据如下处理。
[0113]
(a)将输入特征图的输入数据#1的编号1的数据和核编号1的数据输入到乘法器#1。从加法器#1输出乘法器#1的运算结果。
[0114]
(b)在下一个时钟,由乘法器#2计算输入数据#1的编号2的数据和核编号2的数据的乘积。从加法器#2输出加法器#1的运算结果与乘法器#2的运算结果的总和。
[0115]
(c)通过重复上述运算直到输入数据#1的编号9的数据,从加法器#9输出深度卷积的运算结果。
[0116]
(d)在紧接上述(c)的时钟处,乘法器121执行逐点卷积。
[0117]
(e)由加法器132将逐点卷积的运算结果与累积缓冲器131的数据相加,并用相加结果更新累积缓冲器131的值。
[0118]
通过上述运算,以与上述第一示例中相同的方式获得运算结果。由于第四示例具有其中加法器串联的流水线配置(pipeline configuration),因此乘法器#1可在(b)的运算期间对输入数据#2的编号1的数据执行算术处理,并且在下一个时钟对输入数据#3的编号1的数据执行算术处理。这样,通过顺序地输入下一个输入数据,可一直利用十个乘法器。在上述示例中,按照输入数据编号1至9的顺序处理数据,但即使任意改变顺序,也获得相同的运算结果。
[0119]
图15是示出根据本技术的实施例的dpsc运算装置的第四示例的运算定时示例的示图。
[0120]
在该第四示例中,在卷积运算开始后的第一周期中使用乘法器#1,并且在下一个周期中使用乘法器#1和#2。在此之后,所使用的乘法器增加到乘法器#3和#4,在第十周期中
从乘法器121输出卷积运算结果,并且此后的每一周期输出卷积运算结果。也就是说,该第四示例的配置像一维收缩阵列一样操作。
[0121]
假设输入数据大小为n
×
m(n和m为正整数),输入特征图的数量为i,并且输出特征图的数量为o,运算所需的总周期数为i
×
o
×
n
×
m 9,从卷积运算过程开始后的9个周期到i
×
o
×
n
×
m周期,每个周期顺序输出卷积运算结果。
[0122]
在一般cnn中,输入数据大小n
×
m在层的前级中较大,并且i和o在层的后级中较大,在整个网络中i
×
o
×
n
×
m>>9为真。因此,根据第四示例的吞吐量可以看作几乎是1。
[0123]
另一方面,在上述第三示例中,由于在下一个周期中执行深度卷积并执行逐点卷积,所以每两个周期输出卷积运算结果。也就是说,吞吐量是0.5。
[0124]
因此,根据第四示例,可以提高整个运算中的算子的利用率,并且与上述第三示例相比,获得两倍的吞吐量。
[0125]
如上所述,在本技术的第一实施例中,由3
×
3卷积运算单元110进行的深度卷积的结果被供应给1
×
1卷积运算单元120以用于逐点卷积,而不经过中间数据缓冲器。因此,可在不使用中间数据缓冲器的情况下执行dpsc运算,并且可减小卷积层中的运算量和参数数量。
[0126]
也就是说,根据本技术的第一实施例,可通过取消中间数据缓冲器并由此减小芯片大小来降低成本。在本技术的第一实施例中,由于不需要中间数据缓冲器,并且只要提供至多一个输入特征图就可执行运算,因此即使在大规模网络中,也可以不受缓冲器大小的限制地执行dpsc运算。
[0127]
<2.第二实施例>
[0128]
在上述第一实施例中,假定卷积层20中的dpsc运算,但是取决于所使用的网络和层,可能期望执行未分离成深度卷积和逐点卷积的sc运算。因此,在第二实施例中,将描述执行dpsc运算和sc运算两者的算术运算装置。
[0129]
图16是示出根据本技术的第二实施例的算术运算装置的第一配置示例的示图。
[0130]
第一配置示例的算术运算装置包括k
×
k卷积运算单元116、1
×
1卷积运算单元117、切换电路141和累积单元130。
[0131]
k
×
k卷积运算单元116执行k
×
k(k是正整数)卷积运算。输入数据被供应给k
×
k卷积运算单元116的一个输入并且k
×
k权重被供应给另一个输入。k
×
k卷积运算单元116可以被视为执行sc运算的算术电路。另一方面,k
×
k卷积运算单元116也可以被视为执行dpsc运算中的深度卷积的算术电路。
[0132]1×
1卷积运算单元117执行1
×
1卷积运算。1
×
1卷积运算单元117是执行dpsc运算中的逐点卷积的算术电路,并且对应于上述第一实施例中的1
×
1卷积运算单元120。k
×
k卷积运算单元116的输出被供应给1
×
1卷积运算单元117的一个输入并且1
×
1权重被供应给另一个输入。
[0133]
切换电路141是连接到k
×
k卷积运算单元116的输出或1
×
1卷积运算单元117的输出的开关。当连接到k
×
k卷积运算单元116的输出时,sc运算的结果被输出到累积单元130。另一方面,当连接到1
×
1卷积运算单元117的输出时,dpsc运算的结果被输出到累积单元130。
[0134]
累积单元130具有与上述第一实施例的配置相同的配置并且顺序地将切换电路
141的输出相加。因此,dpsc运算或sc运算的结果被累积地相加到累积单元130。
[0135]
图17是示出根据本技术的第二实施例的算术运算装置的第二配置示例的示图。
[0136]
在上述第一配置示例中,需要用于将连接目的地切换到累积单元130的切换电路141。另一方面,在该第二配置示例中,1
×
1卷积运算单元117的一个输入通过算术控制单元140的控制被设置为1
×
1权重或值“1”。当输入1
×
1权重时,1
×
1卷积运算单元117的输出是dpsc运算的结果。当输入值“1”时,由于1
×
1卷积运算单元117原样输出k
×
k卷积运算单元116的输出,因此输出sc运算的结果。如上所述,在第二示例中,通过由算术控制单元140控制加权系数,可以在不提供切换电路141的情况下实现与上述第一示例的功能相同的功能。
[0137]
在本实施例中,假设输入值“1”以便从1
×
1卷积运算单元117原样输出k
×
k卷积运算单元116的输出,但只要可原样输出k
×
k卷积运算单元116的输出,也可以使用其他值。也就是说,可使用作为1
×
1卷积运算单元117中的识别元素的预定值。
[0138]
如上所述,根据本技术的第二实施例,可根据需要选择dpsc运算和sc运算的结果。因此,它可用于cnn的各种网络。而且,sc运算和dpsc运算都可以在网络中的任一层中进行。即使在这种情况下,也可以在不提供中间数据缓冲器的情况下执行dpsc运算。
[0139]
<3.应用示例>
[0140]
[并行算术运算装置]
[0141]
图18是示出根据本技术的实施例的使用算术运算装置的并行算术运算装置的配置示例的示图。
[0142]
该并行算术运算装置包括多个算子210、输入特征图保持单元220、核保持单元230和输出数据缓冲器290。
[0143]
根据上述实施例,多个算子210中的每一者是算术运算装置。也就是说,该并行算术运算装置通过将根据上述实施例的多个算术运算装置布置为并行算子210来配置。
[0144]
输入特征图保持单元220保持输入特征图,并且将输入特征图的数据作为输入数据供应给多个算子210中的每一者。
[0145]
核保持单元230保持用于卷积运算的核并且将核提供给多个算子210中的每一者。
[0146]
输出数据缓冲器290是保持从多个算子210中的每一者输出的运算结果的缓冲器。
[0147]
算子210中的每一者在一个运算中对输入特征图的数据的一个片段(例如,一个像素的数据)执行运算。通过并行布置算子210并同时执行运算,可在短时间内完成整个运算。
[0148]
[识别处理装置]
[0149]
图19是示出根据本技术的实施例的使用算术运算装置的识别处理装置的配置示例的示图。
[0150]
该识别处理装置300是执行图像识别处理的视觉处理器,并且包括算术运算单元310、输出数据缓冲器320、内置存储器330和处理器350。
[0151]
算术运算单元310执行识别处理所需的卷积运算,并且包括多个算子311和算术控制单元312,如上述并行算术运算装置中的那样。输出数据缓冲器320是保持从多个算子311中的每一者输出的运算结果的缓冲器。内置存储器330是保持运算所需数据的存储器。处理器350是控制整个识别处理装置300的控制器。
[0152]
另外,在识别处理装置300的外部设置传感器组301、存储器303和识别结果显示单元309。传感器组301是用于获取要识别的传感器数据(测量数据)的传感器。作为传感器组
301,例如使用声音传感器(麦克风)、图像传感器等。存储器303是保存来自传感器组301的传感器数据、卷积运算中使用的权重参数等的存储器。识别结果显示单元309显示识别处理装置300的识别结果。
[0153]
当传感器组301获取传感器数据时,传感器数据被加载到存储器303中并且与权重参数等一起加载到内置存储器330中。还可以将数据直接从存储器303加载到算术运算单元310中,而不经过内置存储器330。
[0154]
处理器350控制将数据从存储器303加载到内置存储器330、将卷积运算的执行命令加载到运算单元310等。算术控制单元312是控制卷积运算过程的单元。因此,运算单元310的卷积运算结果被存储在输出数据缓冲器320中,并用于下一个卷积运算、在卷积运算完成后向存储器303的数据传输等。在所有运算完成之后,数据被存储在存储器303中,并且例如,对应于所收集的声音数据的类型的语音数据被输出到识别结果显示单元309。
[0155]
为了减小累积缓冲器131的容量,也可以设想其中将深度卷积的结果存储在存储器303中的配置。然而,需注意,由于对芯片外部的存储器的访问通常比对芯片内部的缓冲器的访问更慢并且消耗大量的功率。
[0156]
[一维数据应用实例]
[0157]
根据本技术的实施例的算术运算装置可用于各种目标,不仅可用于图像数据,而且可用于其中例如一维数据被二维布置的数据。也就是说,本实施例中的算术运算装置可以是一维数据信号处理装置。例如,具有对准相位的特定周期的波形数据可二维地布置。这样,可通过深度学习等来学习波形形状的特性。也就是说,本技术的实施例的利用范围不限于图像领域。
[0158]
图20是示出根据本技术的实施例的算术运算装置中的一维数据的第一应用示例的示图。
[0159]
在该第一应用示例中,如图中的“a”所示,将考虑其相位对准的多个采样波形。每个波形都是一维时间序列数据,水平方向指示时间方向,并且垂直方向表示信号的量值。
[0160]
如图中“b”所示,当这些波形在每个时间的数据值垂直布置时,其可被表示为二维数据。通过相对于二维数据执行根据本技术实施例的算术处理,可提取相应波形的公共特征。因此,可获得如图中“c”所示的特征提取结果。
[0161]
图21是示出算术运算装置中的一维数据的第二应用示例的示图。
[0162]
在第二应用示例中,如图中的“a”所示,将考虑一个波形。该波形都是一维时间序列数据,并且水平方向指示时间方向,并且垂直方向表示信号的量值。
[0163]
如图中“b”所示,可将此波形视为按时间顺序的三条数据(1
×
3维数据)的数据集,并且可执行dpsc运算。此时,包括在相邻数据集中的这些条数据部分重叠。
[0164]
这里,已经描述了1
×
3维数据的示例,但它一般可以应用于1
×
n维数据(n为正整数)。另外,即使对于具有三维或更多维的数据,也可以将数据的一部分视为二维数据,并且可以执行dpsc运算。也就是说,本技术的实施例可适用于各种维度的数据。
[0165]
在上述实施例中已经描述了识别过程,但本技术的实施例可用作用于学习的神经网络的一部分。也就是说,根据本技术的实施例的算术运算装置可以作为神经网络加速器执行推理处理和学习处理。因此,本技术适用于包含人工智能的产品。
[0166]
上述实施例分别描述了用于体现本技术的示例,并且实施例中的事项与权利要求
中指定本发明的事项具有对应关系。类似地,权利要求中规定本发明的事项和本技术的实施例中由相同名称表示的事项具有对应关系。然而,本技术不限于实施例,并且可以通过在不脱离其要旨的情况下对实施例进行各种修改来体现。
[0167]
上述实施例中描述的处理过程可以被认为是包括一系列这些过程的方法,或者可以被认为是致使计算机执行一系列这些过程的程序或存储该程序的记录介质。例如,可使用光盘(cd)、微型光盘(md)、数字通用盘(dvd)、存储器卡或蓝光(注册商标)盘作为该记录介质。
[0168]
在说明书中描述的效果仅是示例,并且本技术的效果不限于它们并可包括其他效果。
[0169]
本技术也可以如下所述配置。
[0170]
(1)一种算术运算装置,包括:第一乘积求和算子,第一乘积求和算子执行输入数据和第一权重的乘积求和运算;第二乘积求和算子,第二乘积求和算子连接到第一乘积求和算子的输出部以执行第一乘积求和算子的输出和第二权重的乘积求和运算;以及累积单元,累积单元顺序地将第二乘积求和算子的输出相加。
[0171]
(2)根据(1)所述的算术运算装置,其中,累积单元包括:累积缓冲器,累积缓冲器保持累积结果;以及累积加法器,累积加法器将保持在累积缓冲器中的累积结果和第二乘积求和算子的输出相加,以将相加结果保持在累积缓冲器中作为新累积结果。
[0172]
(3)根据(1)或(2)所述的算术运算装置,其中,第一乘积求和算子包括:m
×
n个乘法器,m
×
n个乘法器执行m
×
n(m和n是正整数)条输入数据和对应的m
×
n个第一权重的相乘;以及相加单元,相加单元将m
×
n个乘法器的输出相加并将相加结果输出到输出部。
[0173]
(4)根据(3)所述的算术运算装置,其中,加法单元包括并行地将m
×
n个乘法器的输出相加的加法器。
[0174]
(5)根据(3)所述的算术运算装置,其中,加法单元包括用于顺序地将m
×
n个乘法器的输出相加的串联连接的m
×
n个加法器。
[0175]
(6)根据(1)或(2)所述的算术运算装置,其中,第一乘积求和算子包括:n个乘法器,n个乘法器针对每n条数据执行m
×
n(m和n是正整数)条输入数据和对应的m
×
n个第一权重的相乘;n个第二累积单元,n个第二累积单元顺序地将第一乘积求和算子的输出相加;以及加法器,加法器将n个乘法器的输出相加m次以将相加结果输出到输出部。
[0176]
(7)根据(1)或(2)所述的算术运算装置,其中,第一乘积求和算子包括m
×
n个乘法器,m
×
n个乘法器执行m
×
n(m和n是正整数)条输入数据和对应的m
×
n个第一权重的相乘,累积单元包括:累积缓冲器,累积缓冲器保持累积结果;第一选择器,第一选择器从m
×
n个乘法器的输出和累积缓冲器的输出中选择预定输出;以及加法器,加法器将第一选择器的输出相加,并且第二乘积求和算子包括第二选择器,第二选择器选择加法器的输出或输入数据以将所选择的一者输出到m
×
n个乘法器中的一者。
[0177]
(8)根据(1)至(7)中任一项所述的算术运算装置,还包括:切换电路,切换电路执行切换以使得将第一乘积求和算子的输出或第二乘积求和算子的输出供应给累积单元,其中,累积单元顺序地将第一乘积求和算子的输出或第二乘积求和算子的输出相加。
[0178]
(9)根据(1)至(7)中任一项所述的算术运算装置,还包括:算术控制单元,算术控制单元在累积单元将第一乘积求和算子的输出相加时,供应用作第二乘积求和算子中的识
别元素的预定值而不是第二权重。
[0179]
(10)根据(1)至(9)中任一项所述的算术运算装置,其中,输入数据为传感器的测量数据,并且算术运算装置为神经网络加速器。
[0180]
(11)根据(1)至(9)中任一项所述的算术运算装置,其中,输入数据为一维数据,并且算术运算装置为一维数据信号处理装置。
[0181]
(12)根据(1)至(9)中任一项所述的算术运算装置,其中,输入数据为二维数据,并且算术运算装置为视觉处理器。
[0182]
(13)一种算术运算系统,包括:多个算术运算装置,多个算术运算装置均包括:第一乘积求和算子,第一乘积求和算子执行输入数据和第一权重的乘积求和运算;第二乘积求和算子,第二乘积求和算子连接到第一乘积求和算子的输出部以执行第一乘积求和算子的输出和第二权重的乘积求和运算;以及累积单元,累积单元顺序地将第二乘积求和算子的输出相加;输入数据供应单元,输入数据供应单元将输入数据供应给多个算术运算装置;权重供应单元,权重供应单元将第一权重和第二权重供应给多个算术运算装置;以及输出数据缓冲器,输出数据缓冲器保持多个算术运算装置的输出。
[0183]
[参考符号列表]
[0184]
110 3
×
3卷积运算单元
[0185]
111 乘法器
[0186]
112、118 加法器
[0187]
113 缓冲器
[0188]
116 k
×
k卷积运算单元
[0189]
117 1
×
1卷积运算单元
[0190]
119 触发器
[0191]
120 1
×
1卷积运算单元
[0192]
121 乘法器
[0193]
124 选择器
[0194]
130 累积单位
[0195]
131、133 累积缓冲器
[0196]
132、135 加法器
[0197]
134 选择器
[0198]
140 算术控制单元
[0199]
141 切换电路
[0200]
210 算子
[0201]
220 输入特征图保持单元
[0202]
230 核保持单元
[0203]
290 输出数据缓冲器
[0204]
300 识别处理装置
[0205]
301 传感器组
[0206]
303 存储器
[0207]
309 识别结果显示单元
[0208]
310 算术运算单元
[0209]
311 算子
[0210]
312 算术控制单元
[0211]
320 输出数据缓冲器
[0212]
330 内置存储器
[0213]
350 处理器。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。