1.本发明涉及自然语言处理的技术领域,尤其涉及到一种机器阅读理解方法、系统、计算机及存储介质。
背景技术:
2.随着人工智能的高速发展,人机交互的应用场景愈加广泛,如智能客服、聊天机器人、推荐系统等。在优化用户体验的过程中,如何让机器更好地理解人类语言是人机交互技术最核心的问题。
3.机器阅读理解(machine reading comprehension,mrc)为解决上述问题提供了技术支撑,其通过让计算机阅读文本段落并回答给定问题的任务形式,训练机器理解人类语言,并具备一定的推理能力。近年来,深度神经网络的创新突破以及大规模预训练模型的迭代更新,极大促进了mrc技术的发展,研究者们纷纷投入开发规模更大、层数更深的mrc模型,其参数量从几百兆到几亿甚至上百亿,导致计算开销与训练成本激增,而回答的准确率却趋于饱和。
4.如今,研究者们开始关注mrc模型的兼顾准确率与计算/参数量的综合性能,提出了各种优化方案,以实现计算/存储开销降低的同时保证准确性。其中一部分研究工作以低计算/参数开销的循环神经网络如lstm、gru为基础,通过优化mrc模型架构,提出新颖的计算模块或计算机制来提升模型回答的准确率;另一部分研究则针对高准确率的大规模mrc模型,采用矩阵分解、参数共享、剪枝与量化等方法降低其参数量。
5.但是,这些方法依然存在三个主要问题:
6.(1)基于lstm、gru的mrc模型在提取当前词的特征时,只能利用单向循环迭代的信息,无法同时兼顾上下文,造成整体模型对上下文信息的提取不够充分,进而影响回答的准确率。
7.(2)轻量处理后的大规模mrc模型虽然参数量减少,但依然存在大量的平方级复杂度的自注意力运算,因此实际计算开销并未降低,其训练过程难以大批量并行进行,且受到文本长度以及词向量维度的严重限制。
8.(3)现阶段mrc模型中使用的自注意力机制过于注重全局信息,即每个词都要与整个文段中所有词计算注意力,造成大量计算开销,而多数情况下答案的获取只需关注其所在的一段局部范围。
9.因此,如何解决上述问题,使mrc模型的兼顾准确率与计算/参数量的综合性能达到最优,是一项重要且具有实际意义的任务。
技术实现要素:
10.本发明的目的在于克服现有技术的不足,提供一种机器阅读理解方法,以提出的多样性循环单元(diversity recurrent unit,dru)为核心,将低参数/计算量的循环神经网络与提出的低时间复杂度的降维自注意力机制相结合,对文段与问题进行特征提取,得
到充分融合上下文信息的文段与问题表征,然后通过局部信息门控增强二者上下文表征中局部信息的比重,为答案获取提供关注范围,从而在低计算/参数开销的条件下提高了回答的准确率,实现mrc的综合性能最优。
11.为实现上述目的,本发明所提供的技术方案为:
12.一种机器阅读理解方法,包括以下步骤:
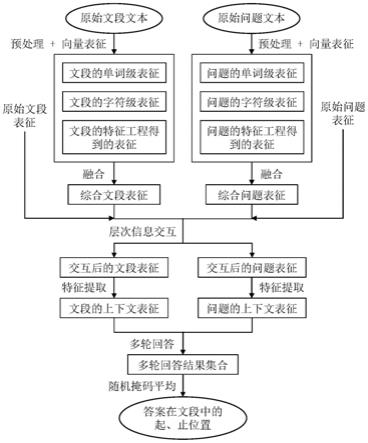
13.s1、获取原始文段文本和原始问题文本的单词级信息、字符级信息以及特征信息;
14.s2、将步骤s1获得的信息进行向量表征以及向量表征融合,得到原始文段表征de和原始问题表征qe,以及融合后的综合文段表征du和综合问题表征qu;
15.s3、将原始文段表征de、原始问题表征qe、综合文段表征du、综合问题表征qu进行层次注意力交互,并将各层的交互结果进行拼接,得到交互后的文段表征d和交互后的问题表征q;
16.s4、对交互后的文段表征d和交互后的问题表征q进行特征提取,得到文段的上下文表征d
x
和问题的上下文表征q
x
;
17.s5、利用文段的上下文表征d
x
和问题的上下文表征q
x
进行多轮回答,将每轮的生成的双指针分布结果进行汇总,并计算汇总结果的随机掩码平均值,得到最终的双指针分布,分布中最大元素对应的索引即为答案在文段中的起、止位置。
18.进一步地,所述步骤s2具体包括:
19.s2-1、使用glove和cove来表征单词向量,得到w
glove
∈r
l
×
300
以及两层w
cove
∈r
l
×
600
;使用elmo来表征字符向量,得到w
char
∈r
l
×
1024
以及两层w
elmo
∈r
l
×
1024
;通过特征工程得到特征向量w
feature
∈r
l
×
24
,将w
glove
、w
char
、w
feature
以及w
cove
与w
elmo
的第一层进行拼接,送入两层一维卷积前馈网络cff中,得到一度融合后的表征w
ffn
∈r
l
×
256
;
20.s2-2、将w
cove
与w
elmo
的第一层与w
ffn
拼接得x∈r
l
×
1880
,将x送入多样性循环单元dru中计算,得到二度融合后的表征w
dru0
∈r
l
×
256
;
21.s2-3、将w
glove
、w
elmo
的第二层与w
dru0
进行拼接,再送入一个多样性循环单元dru中,得到三度融合后的表征w
dru1
∈r
l
×
256
;
22.s2-4、将w
dru0
与w
dru1
进行拼接作为融合后的综合表征u∈r
l
×
512
;将w
cove
、w
elmo
的第二层与w
glove
进行拼接作为原始表征e∈r
l
×
1924
;
23.s2-5、分别对原始文段文本与原始问题文本执行s2-1~s2-4的过程,得到原始文段表征de、原始问题表征qe、融合后的综合文段表征du以及综合问题表征qu。
24.进一步地,所述步骤s2-2中,多样性循环单元dru内的计算包括以下分步骤:
25.a1)、对x分别进行降维自注意力计算以及可分离卷积计算,得到全局上下文表征h以及局部信息表征x
local
:
26.h=(w
·
x b)
t
·
softmax(x
·
v b)
27.x
local
=separableconvld(x)
28.其中w、v和b分别为可学习的矩阵、向量和偏置;
29.a2)、计算局部门控矩阵g并更新x:
30.g=σ(w
·
[x|h] b)
[0031]
x=g
⊙
x (1-g)
⊙
x
local
[0032]
其中σ与
⊙
分别表示矩阵元素的sigmoid运算与点积运算;
[0033]
a3)、将x与h通过一层双向长短时记忆网络bilstm,得到w
dru0
。
[0034]
进一步地,所述步骤s3具体包括:
[0035]
s3-1、将综合文段表征du与原始文段表征de进行拼接,将综合问题表征qu和综合文段表征du进行拼接,通过线性变换降低拼接表征的词向量维数来降低计算开销,得到与
[0036]dr
=relu(wd·
[du|de] bd)
[0037]
qr=relu(wq·
[qu|qe] bq)
[0038]
其中ld与lq分别为文段和问题的序列长度;relu为激活函数;qd和wq为可学习的矩阵;bd和bq为可学习的偏置;
[0039]
s3-2、将文段与问题各自的综合表征u拆分为两层w
dru0
和w
dru1
,同时将u送入一层多样性循环单元dru中得到w
dru2
,将这三层具有递进关系的表征作为层次表征,记文段与问题各自的三个层次表征分别为与i=0,1,2;
[0040]
s3-3、对每个层次i对应的文段与问题表征进行双向注意力交互计算,得到交互后的各层次文段表征i=0,1,2,将其与文段综合表征du进行拼接作为最终交互后的整体文段表征同时将第三层次问题表征q2作为最终交互后的整体问题表征
[0041]
进一步地,所述步骤s3-3中,的计算步骤包括:
[0042]
b1)、通过矩阵乘法,矩阵一向量乘法以及行方向的掩码softmax计算得到文段到问题的注意力分数矩阵i=0,1,2;
[0043][0044]
其中vd、vq为两个可训练向量,分别代表文段和问题的整体信息;
[0045]
b2)、取出每一行的最大值并进行softmax计算,得到问题到文段的注意力分数
[0046][0047]
b3)、通过与问题层次表征的矩阵乘法以及与文段层次表征的向量-矩阵乘法,得到双向注意力下两个充分信息交互后的文段表征与
[0048][0049][0050]
其中为a2在行方向扩展后的结果;
[0051]
b4)、将交互后的文段表征、文段层次表征及其对应点积进行拼接,通过一次线性变换,得到最终的各层次文段表征
[0052][0053]
其中wi、bi分别为可学习的矩阵、偏置。
[0054]
进一步地,所述步骤s4包括以下分步骤:
[0055]
s4-1,将交互后的文段表征d经过一层多样性循环单元dru后得到d
dru
,将d
dru
与d进行拼接,经过一层线性变换得到
[0056]dsr
=relu(w
·
[d
dru
|d] b)
[0057]
计算d
sr
的自注意力分数
[0058]
sd=softmax(d
sr
·
(d
sr
)
t
)
[0059]
将sd与d
dru
进行矩阵相乘,得到
[0060]dsa
=sd·ddru
;
[0061]
s4-2,将d
sa
与d
dru
进行拼接,送入一层多样性循环单元dru中,得到最终用于多轮回答的文段表征
[0062]
s4-3,使用一个可训练的向量v作为问题信息的概括,将其与问题表征q进行向量-矩阵乘法,经过softmax后得到自注意力分数sq,
[0063]
sq=softmax(q
·vt
b)
[0064]
将sq与线性变换后的问题表征进行向量-矩阵相乘,得到自注意力下的问题表征q
x
∈r
256
,作为最终用于多轮回答的初始一维问题表征q
x0
,
[0065]qx0
=(sq)
t
·
(w
·
q b)。
[0066]
进一步地,所述步骤s5包括以下分步骤:
[0067]
s5-1、将初始的问题向量表征q
x0
经过一层线性变换转化为与文段矩阵表征相同的词向量维度,通过矩阵-向量乘法及softmax得到文段与问题的注意力分数,作为初始的答案起始位置的概率分布
[0068]
p
s0
=softmax(d
x
·
(w
·qx0
b)
t
),
[0069]
将p
s0
与文段的上下文表征d
x
进行向量-矩阵相乘,得到初始的带有答案起始位置信息的表征h
s0
∈r
256
,
[0070]hs0
=(p
s0
)
t
·dx
;
[0071]
s5-2、将h
s0
作为提示与q
x0
拼接作为新的初始问题表征,与文段的上下文表征d
x
进行矩阵-向量注意力计算,得到初始的答案结束位置的概率分布
[0072]
p
e0
=softmax(d
x
·
(w
·
[q
x0
|h
s0
] b)
t
)
[0073]
以及初始的带有答案结束位置信息的表征h
e0
∈r
256
,
[0074]he0
=(p
e0
)
t
·dx
,
[0075]
将h
e0
与h
s0
进行拼接,作为初始的答案信息表征h
ans0
∈r
512
;
[0076]
s5-3、将h
ans0
与g
x0
进行门控循环单元gru的一次迭代操作,得到更新后的问题表征q
x1
,使用q
x1
重复s5-1与s5-2的步骤得到p
s1
、h
s1
、p
e1
、h
e1
和h
ans1
;
[0077]
s5-4、重复执行3次s5-3,将各轮结果p
si
与p
ei
进行随机掩码平均,得到最终的答案起、止位置分布其中ps与pe中最大元素对应的索引即为答案在文段中的起、止位置。
[0078]
为实现上述目的,本发明另外提供一种机器阅读理解系统,该机器阅读理解系统用于实现上面所述的机器阅读理解方法,其包括:表征融合模块、信息交互模块、特征提取模块、多轮回答模块;
[0079]
其中,
[0080]
所述表征融合模块,用于获取原始文段文本和原始问题文本的单词级信息、字符级信息以及特征信息;并将获得的信息进行向量表征以及向量表征融合,得到原始文段表征de和原始问题表征qe,以及融合后的综合文段表征du和综合问题表征qu;
[0081]
所述信息交互模块,用于将原始文段表征de、原始问题表征qe、综合文段表征du、综合问题表征qu进行层次注意力交互,并将各层的交互结果进行拼接,得到交互后的文段表征d和交互后的问题表征q;
[0082]
所述特征提取模块,用于对交互后的文段表征d和交互后的问题表征q进行特征提取,得到文段的上下文表征d
x
和问题的上下文表征q
x
;
[0083]
所述多轮回答模块,用于利用文段的上下文表征d
x
和问题的上下文表征q
x
进行多轮回答,将每轮的生成的双指针分布结果进行汇总,并计算汇总结果的随机掩码平均值,得到最终的双指针分布,分布中最大元素对应的索引即为答案在文段中的起、止位置。
[0084]
为实现上述目的,本发明另外提供一种计算机,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上面所述的机器阅读理解方法的步骤。
[0085]
为实现上述目的,本发明另外提供一种存储介质,其存储有计算机程序,该程序被处理器执行时实现上面所述的机器阅读理解方法的步骤。
[0086]
与现有技术相比,本技术方案的原理及优点如下:
[0087]
本技术方案以提出的多样性循环单元dru为核心,将低参数/计算量的循环神经网络与提出的低时间复杂度的降维自注意力机制相结合,来获取充分融合上下文信息的文段与问题表征,并通过局部信息门控增强二者上下文表征中局部信息的比重,从而在低计算/参数开销的条件下提高了回答的准确率,实现mrc的综合性能最优。
[0088]
本技术方案中,多样性循环单元dru以及多轮回答模块具有高泛化性,其中多样性循环单元dru可移植到其他任意mrc模型中作为特征提取器,提升模型的综合性能;而多轮回答模块可移植到相关的mrc以及其他问答相关模型中,提升回答的鲁棒性。
附图说明
[0089]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的服务作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以
根据这些附图获得其他的附图。
[0090]
图1为本发明实施例一一种机器阅读理解方法的原理流程图;
[0091]
图2为本发明实施例一一种机器阅读理解方法中多样性循环单元dru的算法机制图;
[0092]
图3为本发明实施例一一种机器阅读理解方法中双向交互注意力算法机制图;
[0093]
图4为本发明实施例一一种机器阅读理解方法中使用的随机掩码平均计算机制图;
[0094]
图5为本发明实施例二一种机器阅读理解系统的结构示意图。
具体实施方式
[0095]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0096]
实施例一:
[0097]
如图1所示,本实施例所述的一种机器阅读理解方法,包括以下步骤:
[0098]
s1、对原始文段文本和原始问题文本进行预处理,获取原始文段文本和原始问题文本的单词级信息、字符级信息以及特征信息;
[0099]
s2、将步骤s1获得的信息进行向量表征以及向量表征融合,得到原始文段表征de和原始问题表征qe,以及融合后的综合文段表征du和综合问题表征qu;
[0100]
具体地说,步骤s2包括以下分步骤:
[0101]
s2-1、使用glove(global vectors)和cove(contextualized vectors)来表征单词向量,得到w
gloe
∈r
l
×
300
以及两层w
cove
∈r
l
×
600
;使用elmo来表征字符向量,得到w
char
∈r
l
×
1024
以及两层w
elmo
∈r
l
×
1024
;通过特征工程得到特征向量w
feature
∈r
l
×
24
,将w
glove
、w
char
、w
feature
以及w
cove
与w
elmo
的第一层进行拼接,送入两层一维卷积前馈网络cff中,得到一度融合后的表征w
ffn
∈r
l
×
256
;
[0102]
s2-2、将w
cove
与w
elmo
的第一层与w
ffn
拼接得x∈r
l
×
1880
,将x送入多样性循环单元dru中计算,得到二度融合后的表征w
dru0
∈r
l
×
256
;
[0103]
具体地,如图2所示,多样性循环单元dru内的计算包括以下分步骤:
[0104]
a1)、对x分别进行降维自注意力计算以及可分离卷积计算,得到全局上下文表征h以及局部信息表征x
local
:
[0105]
h=(w
·
x b)
t
·
softmax(x
·
v b)
[0106]
x
local
=separableconv1d(x)
[0107]
其中w、v和b分别为可学习的矩阵、向量和偏置;
[0108]
a2)、计算局部门控矩阵g并更新x:
[0109]
g=σ(w
·
[x|h] b)
[0110]
x=g
⊙
x (1-g)
⊙
x
local
[0111]
其中σ与
⊙
分别表示矩阵元素的sigmoid运算与点积运算;
[0112]
a3)、将x与h通过一层双向长短时记忆网络bilstm,得到w
dru0
。
[0113]
s2-3、将w
glove
、w
elmo
的第二层与w
dru0
进行拼接,再送入一个多样性循环单元dru中,得到三度融合后的表征w
dru1
∈r
l
×
256
;
[0114]
s2-4、将w
dru0
与w
dru1
进行拼接作为融合后的综合表征u∈r
l
×
512
;将w
cove
、w
elmo
的第二层与w
glove
进行拼接作为原始表征e∈r
l
×
1924
;
[0115]
s2-5、分别对原始文段文本与原始问题文本执行s2-1~s2-4的过程,得到原始文段表征de、原始问题表征qe、融合后的综合文段表征du以及综合问题表征qu。
[0116]
s3、将原始文段表征de、原始问题表征qe、综合文段表征du、综合问题表征qu进行层次注意力交互,并将各层的交互结果进行拼接,得到交互后的文段表征d和交互后的问题表征q;
[0117]
具体地,步骤s3具体包括:
[0118]
s3-1、将综合文段表征du与原始文段表征de进行拼接,将综合问题表征qu和综合文段表征du进行拼接,通过线性变换降低拼接表征的词向量维数来降低计算开销,得到与
[0119]dr
=relu(wd·
[du|de] bd)
[0120]
qr=relu(wq·
[qu|qe] bq)
[0121]
其中ld与lq分别为文段和问题的序列长度;relu为激活函数;wd和wq为可学习的矩阵;bd和bq为可学习的偏置;
[0122]
s3-2、将文段与问题各自的综合表征u拆分为两层w
dru0
和w
dru1
,同时将u送入一层多样性循环单元dru中得到w
dru2
,将这三层具有递进关系的表征作为层次表征,记文段与问题各自的三个层次表征分别为与i=0,1,2;
[0123]
s3-3、对每个层次i对应的文段与问题表征进行双向注意力交互计算,如图3所示,得到交互后的各层次文段表征i=0,1,2,将其与文段综合表征du进行拼接作为最终交互后的整体文段表征同时将第三层次问题表征q2作为最终交互后的整体问题表征
[0124]
具体地,的计算步骤包括:
[0125]
b1)、通过矩阵乘法,矩阵-向量乘法以及行方向的掩码softmax计算得到文段到问题的注意力分数矩阵i=0,1,2;
[0126][0127]
其中vd、vq为两个可训练向量,分别代表文段和问题的整体信息;
[0128]
b2)、取出每一行的最大值并进行softmax计算,得到问题到文段的注意力分擞
[0129][0130]
b3)、通过与问题层次表征的矩阵乘法以及与文段层次表征的向量-矩阵乘
法,得到双向注意力下两个充分信息交互后的文段表征与
[0131][0132][0133]
其中为a2在行方向扩展后的结果;
[0134]
b4)、将交互后的文段表征、文段层次表征及其对应点积进行拼接,通过一次线性变换,得到最终的各层次文段表征
[0135][0136]
其中wi、bi分别为可学习的矩阵、偏置。
[0137]
s4、对交互后的文段表征d和交互后的问题表征q进行特征提取,得到文段的上下文表征d
x
和问题的上下文表征q
x
;
[0138]
具体地,步骤s4包括以下分步骤:
[0139]
s4-1,将交互后的文段表征d经过一层多样性循环单元dru后得到d
dru
,将d
dru
与d进行拼接,经过一层线性变换得到
[0140]dsr
=relu(w
·
[d
dru
|d] b)
[0141]
计算d
sr
的自注意力分数
[0142]
sd=softmax(d
sr
·
(d
sr
)
t
)
[0143]
将sd与d
dru
进行矩阵相乘,得到
[0144]dsa
=sd·ddru
;
[0145]
s4-2,将d
sa
与d
dru
进行拼接,送入一层多样性循环单元dru中,得到最终用于多轮回答的文段表征
[0146]
s4-3,使用一个可训练的向量v作为问题信息的概括,将其与问题表征q进行向量-矩阵乘法,经过softmax后得到自注意力分数sq,
[0147]
sq=softmax(q
·vt
b)
[0148]
将sq与线性变换后的问题表征进行向量-矩阵相乘,得到自注意力下的问题表征q
x
∈r
256
,作为最终用于多轮回答的初始一维问题表征q
x0
,
[0149]qx0
=(sq)
t
·
(w
·
q b)。
[0150]
s5、利用文段的上下文表征d
x
和问题的上下文表征q
x
进行多轮回答,将每轮的生成的双指针分布结果进行汇总,并计算汇总结果的随机掩码平均值,得到最终的双指针分布,分布中最大元素对应的索引即为答案在文段中的起、止位置。
[0151]
具体地,步骤s5包括以下分步骤:
[0152]
s5-1、将初始的问题向量表征q
x0
经过一层线性变换转化为与文段矩阵表征相同的词向量维度,通过矩阵-向量乘法及softmax得到文段与问题的注意力分数,作为初始的答
案起始位置的概率分布
[0153]
p
s0
=softmax(d
x
·
(w
·qx0
b)
t
),
[0154]
将p
s0
与文段的上下文表征d
x
进行向量-矩阵相乘,得到初始的带有答案起始位置信息的表征h
s0
∈r
256
,
[0155]hs0
=(p
s0
)
t
·dx
;
[0156]
s5-2、将h
s0
作为提示与q
x0
拼接作为新的初始问题表征,与文段的上下文表征d
x
进行矩阵-向量注意力计算,得到初始的答案结束位置的概率分布
[0157]
p
e0
=softmax(d
x
·
(w
·
[q
x0
|h
s0
] b)
t
)
[0158]
以及初始的带有答案结束位置信息的表征h
e0
∈r
256
,
[0159]he0
=(p
e0
)
t
·dx
,
[0160]
将h
e0
与h
s0
进行拼接,作为初始的答案信息表征h
ans0
∈r
512
;
[0161]
s5-3、将h
ans0
与q
x0
进行门控循环单元gru的一次迭代操作,得到更新后的问题表征q
x1
,使用q
x1
重复s5-1与s5-2的步骤得到p
s1
、h
s1
、p
e1
、h
e1
和h
ans1
;
[0162]
s5-4、重复执行3次s5-3,将各轮结果p
si
与p
ei
(i=0,1,2,3,4)进行随机掩码平均,如图4所示,得到最终的答案起、止位置分布其中ps与pe中最大元素对应的索引即为答案在文段中的起、止位置。
[0163]
实施例二:
[0164]
如图5所示,本实施例为一种机器阅读理解系统,所述机器阅读理解系统用于上面所述的机器阅读理解方法,具体包括:表征融合模块1、信息交互模块2、特征提取模块3、多轮回答模块4;
[0165]
其中,
[0166]
所述表征融合模块1,用于获取原始文段文本和原始问题文本的单词级信息、字符级信息以及特征信息;并将获得的信息进行向量表征以及向量表征融合,得到原始文段表征de和原始问题表征qe,以及融合后的综合文段表征du和综合问题表征qu;
[0167]
所述信息交互模块2,用于将原始文段表征de、原始问题表征qe、综合文段表征du、综合问题表征qu进行层次注意力交互,并将各层的交互结果进行拼接,得到交互后的文段表征d和交互后的问题表征q;
[0168]
所述特征提取模块3,用于对交互后的文段表征d和交互后的问题表征q进行特征提取,得到文段的上下文表征d
x
和问题的上下文表征q
x
;
[0169]
所述多轮回答模块4,用于利用文段的上下文表征d
x
和问题的上下文表征q
x
进行多轮回答,将每轮的生成的双指针分布结果进行汇总,并计算汇总结果的随机掩码平均值,得到最终的双指针分布,分布中最大元素对应的索引即为答案在文段中的起、止位置。
[0170]
表1是机器阅读理解任务中各模型性能对比,使用的数据集为squad-v1.0,模型性能的评估指标为em值和f1值,即精准匹配率和宽松匹配率。从实验结果可以看出基于多样性循环单元的模型在机器阅读理解任务上的表现优于传统的逻辑回归(lr)、bi
□
lstm网络以及小规模自注意力网络等模型。
[0171]
模型em值(%)f1值(%)
lr(rajpurkar et al.,2016)40.051.0bidaf(seo et al.,2017)69.277.8equant(aubet et al.,2019)69.378.8qanet(yu et al.,2018)73.682.7fusionnet(huang et al.,2018)75.383.6san(liu et al.,2018)76.284.1vs3-net(park et al.,2019)76.784.6word bpe-frq(zhang et al.,2019)77.885.5gf-net(lee et al.,2019)78.785.8基于dru的机器阅读理解方法81.087.2
[0172]
表1实体关系抽取任务各网络性能对比表
[0173]
实施例三
[0174]
本实施例为一种计算机,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上面所述的机器阅读理解方法的步骤。
[0175]
实施例四
[0176]
本实施例为一种存储介质,其存储有计算机程序,该程序被处理器执行时实现上面所述的机器阅读理解方法的步骤。
[0177]
以上所述之实施例子只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
