1.本发明涉及搜索和信息抽取技术领域,特别是一种面向人物名片的任职关系抽取方法和系统。
背景技术:
2.名片是当今商务交往以及日常生活中一种重要的身份信息传递载体,它在日常中的使用对建立交流加深印象以及建立初步商务互信有着巨大作用,也是提高个人影响力、增加合作可能的性价比较高的工具。早期人们往往通过手工录入的形式将名片上的内容转化为电子信息录入到数字存储设备中进行保存、管理。但这样做一方面是效率低下,在有大批量数据需要处理时有心无力;二是成本高昂,一个简单的录入工作却需要会使用计算机的人员重复劳动,并且后期需要耗费大量时间与精力来管理和维护数据库,而且还往往不方便与其他人的数据库对接。随着当今交流的日益频繁使得名片录入需求日益增加,通过技术手段来实现对名片的自动录入与存储已经变得可能并且需求迫切。
3.现有的针对名片的处理方法中,通常只实现了对其中联系方式例如手机号码、电子邮箱等信息的存取。而为了对人脉关系进行组织和管理,名片当中的任职关系是非常重要的。任职关系由《人名,工作单位,职位》三元组表达,现有方法没有解决如下问题:(1)从文字提取的结果中识别出人名,工作单位,职位三种实体;(2)对识别错误的文字,根据实体的特点进行修正;(3)对于多个工作单位和职位,进行匹配,生成正确的《人名,工作单位,职位》三元组。
技术实现要素:
4.本发明所要解决的技术问题是克服现有技术的不足而提供一种面向人物名片的任职关系抽取方法和系统,本发明从图片中进行文字提取,对人名、工作单位、职位三种实体进行自动识别,并根据不同实体的特点对提取错误的实体进行修正,最后进行匹配生成若干任职关系的方法,从而实现对名片的任职关系自动录入与存储,对人脉关系进行扩充和管理。
5.本发明为解决上述技术问题采用以下技术方案:根据本发明提出的一种面向人物名片的任职关系抽取方法,包括以下步骤:步骤1、获得人物名片图片,并对人物名片图片进行预处理;步骤2、对预处理后的人物名片图片中的文字进行提取,得到文字区域;步骤3、识别出文字区域中的三种实体,三种实体包括人名、工作单位和职位;步骤4、对步骤3中识别出的人名、工作单位和职位进行修正;步骤5、根据修正后的人名、工作单位和职位,形成若干个用来表达任职关系的三元组并存储在电子名片数据库中,每个三元组为《人名,工作单位,职位》。
6.作为本发明所述的一种面向人物名片的任职关系抽取方法进一步优化方案,步骤
1的人物名片图片的获得方式是:拍摄、爬虫或用户提供;预处理包括:如果人物名片图片中包含多个名片,首先分割为单个的人物名片,随后对单个的人物名片进行二值化、平滑噪声、倾斜角检测和纠正处理。
7.作为本发明所述的一种面向人物名片的任职关系抽取方法进一步优化方案,步骤2中的提取包括文字检测和文字识别。
8.作为本发明所述的一种面向人物名片的任职关系抽取方法进一步优化方案,步骤1之后还包括对预处理后的人物名片图片自动生成图片训练测试集;步骤2中采用自动生成图片训练测试集中的人物名片图片对文字进行提取,自动生成训练测试集的方法包括生成汉字的多种字体的不同噪音的图片,以及对人物名片图片自动进行角度调整所生成的多个测试样例。
9.作为本发明所述的一种面向人物名片的任职关系抽取方法进一步优化方案,步骤3中,基于命名实体识别的方法识别出人名、工作单位和职位三种实体,对于当同一个文字区域中包含两个以上实体时,利用中文词法工具将其划分为单个的实体。
10.作为本发明所述的一种面向人物名片的任职关系抽取方法进一步优化方案,步骤4中,修正方法如下:步骤
①
、对于识别出的人名,在人物名片图片中存在对应人名拼音的情况下,利用中文汉字拼音库中获得具有相同拼音且字形最接近的汉字进行修正;在不存在拼音的情况下,利用字形相似度度量选择字型最接近汉字进行修正;步骤
②
、对于识别出的工作单位,根据其位置和字体判断是否为徽标,如果是徽标则调用徽标识别算法进行识别和修正;如果不是徽标但其中包含工作单位的英文、拼音或地址信息,则使用英文、拼音或地址信息作为输入,调用搜索引擎的接口搜索获得工作单位的正确名称进行修正;如果不包含以上信息,则首先利用语言模型得到字,然后在字中利用字形相似度度量选择字型最接近汉字进行修正;步骤
③
、对于识别出的职位,根据职位词典库选择编辑距离最小的职位名称进行修正;如果词典中的职位名称的距离都大于预设阈值,则将修正过的工作单位名称和待修正的职位一同输入到语言模型中,得到最有可能的字,然后在该字中利用字形相似度度量选择字型最接近汉字进行修正。
11.作为本发明所述的一种面向人物名片的任职关系抽取方法进一步优化方案,步骤5中,对于存在多个工作单位和职位,按照位置的临近关系,对工作单位和职位进行配对;如果某个职位在位置上没有临近的工作单位,则将识别出的徽标作为该职位对应的工作单位。
12.一种面向人物名片的任职关系抽取系统,包括图片训练测试集单元,用于存储包含汉字的多种字体的不同噪音的人物名片图片,以及对人物名片图片自动进行角度调整生成多个测试样例的人物名片图片;文本知识库单元,用于存储中文汉字拼音库、笔顺库,以及职位和单位名称的词典;文字提取单元,用于实现对人物名片图片中的文字的提取,得到文字提取结果输出至实体识别单元,文字提取结果包括文字区域;
实体识别单元,用于实现对文字提取结果中的人名、工作单位和职位三种实体的识别;其中还包括对于当同一个文字区域中包含两个或以上实体时,利用中文词法工具将其划分为单个的实体;实体修正单元,用于实现对识别的人名、工作单位和职位的置信度低于预设值的部分进行修正;任职关系生成单元,用于生成若干个《人名,工作单位,职位》的三元组,并存储在数据库中;其中,实体修正单元包括人名修正子单元,工作单位修正子单元和职位修正子单元:人名修正子单元,用于对于识别出的人名,在人物名片图片中存在对应人名拼音的情况下,利用中文汉字拼音库中获得具有相同拼音且字形最接近的汉字进行修正;在不存在拼音的情况下,利用字形相似度度量选择字型最接近汉字进行修正;工作单位修正子单元,对于识别出的工作单位,根据其位置和字体判断是否为徽标,如果是徽标则调用徽标识别算法进行识别和修正;如果不是徽标但其中包含工作单位的英文、拼音或地址信息,则使用英文、拼音或地址信息作为输入,调用搜索引擎的接口搜索获得工作单位的正确名称进行修正;如果不包含以上信息,则首先利用语言模型得到字,然后在字中利用字形相似度度量选择字型最接近汉字进行修正;职位修正子单元,用于对于识别出的职位,根据职位词典库选择编辑距离最小的职位名称进行修正;如果词典中的职位名称的距离都大于预设阈值,则将修正过的工作单位名称和待修正的职位一同输入到语言模型中,得到最有可能的字,然后在该字中利用字形相似度度量选择字型最接近汉字进行修正。
13.本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明的方法和系统能自动实现如下功能:(1)从文字提取的结果中识别出人名,工作单位,职位三种实体;(2)对识别错误的文字,根据实体的特点进行修正;(3)对于多个工作单位和职位,进行匹配,生成若干个正确的《人名,工作单位,职位》三元组;从而提高对任职关系的抽取的准确率,实现对人物名片中的任职关系自动录入与存储,提高电子名片的查看率和传播。基于抽取的任职关系,可以对人脉关系进行管理和扩展。
附图说明
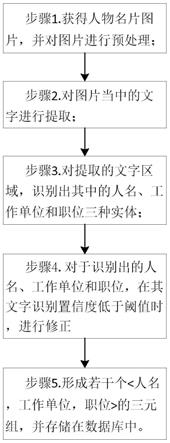
14.图1是一种面向人物名片的任职关系抽取方法流程图;图2是一种面向人物名片的任职关系抽取系统结构图;图3是文字提取单元的结构图;图4是实体修正单元的结构图。
具体实施方式
15.下面结合附图对本发明的技术方案做进一步的详细说明:
如图1所示,一种面向人物名片的任职关系抽取方法,包括如下步骤:步骤1.获得人物名片图片,并对图片进行预处理;步骤2.对图片当中的文字进行提取;步骤3.对提取的文字区域,识别出其中的人名、工作单位和职位三种实体;步骤4.对于步骤3中识别出的人名、工作单位和职位,在其文字识别置信度低于阈值时,进行修正;步骤5.形成若干个《人名,工作单位,职位》的三元组,并存储在数据库中。
16.其中步骤1的名片图片可以经拍摄获得,使用爬虫从网络获得,或者由用户提供。对图片的预处理步骤包括:(1)如果图片中包含多个名片,首先分割为单个的人物名片;(2)对图片进行二值化、平滑噪声、倾斜角检测和纠正等处理。
17.其中步骤2中对图片当中的文字进行提取包括文字检测和文字识别两个步骤。其中文字检测可以采用db等基于图像分割的检测模型,判别每一个像素点是否属于一个文本目标和它与周围像素的连接情况,再将相邻像素结果整合为一个文本框;文字识别算法可以使用crnn识别模型,包括卷积层cnn,循环层rnn和转录层ctc。
18.在步骤2之前,还包括自动生成图片训练测试集对文字提取方法进行训练的步骤。自动生成训练测试集的方法包括生成3000个汉字常用字的常用字体包括宋体、楷体、隶书和黑体等的不同噪音的图片,以及对人物名片图片自动进行角度调整生成的多个测试样例。
19.其中步骤3中,基于命名实体识别的方法识别出其中的人名、工作单位和职位三种实体,其中还包括对于当同一个区域中包含两个或以上实体时,例如“福建摩柯咨询有限公司ceo”中包括了“工作单位”和“职位”两个实体,利用中文词法工具将其划分为单个的实体,词法工具可以采用百度lac中文词法分析工具。其中命名实体识别的方法可以使用包括嵌入层,bilstm层,以及解码crf层组成的三层模型。
20.其中步骤4中,修正方法如下:(1)对于识别出的人名,在名片中存在对应人名拼音的情况下,利用中文汉字拼音库中获得具有相同拼音且字形最接近的汉字进行修正;在不存在拼音的情况下,利用字形相似度度量选择字型最接近汉字进行修正。其中字形相似度度可以基于ids(ideographic description sequence)的编辑距离计算。
21.(2)对于识别出的工作单位,根据其位置和字体等信息判断是否为徽标(logo)。如果是徽标(logo)则调用徽标(logo)识别算法进行识别和修正;如果不是常用的徽标(logo),但其中包含工作单位的英文、拼音或地址信息,则使用英文、拼音或地址信息作为输入,调用搜索引擎的接口搜索获得工作单位的正确名称进行修正;如果不包含以上信息,则首先利用语言模型得到最有可能的字,然后在最有可能的字中利用字形相似度度量选择字型最接近汉字进行修正。其中语言模型可以使用bert模型,字形相似度度可以基于ids计算。
22.(3)对于识别出的职位,根据职位词典库选择编辑距离最小的职位名称进行修正;如果词典中的职位名称的距离都大于阈值,则将修正过的工作单位名称和待修正的职位一同输入到语言模型中,得到最有可能的字,然后在最有可能的字中利用字形相似度度量选
择字型最接近汉字进行修正。其中语言模型可以使用bert模型,字形相似度度可以基于ids计算。
23.其中步骤5中,可能存在多个工作单位和职位,按照位置的临近关系,对工作单位和职位进行配对。如果某个职位在位置上没有临近的工作单位,则将识别出的徽标(logo)作为该职位对应的工作单位。
24.如图2所示,一种面向人物名片的任职关系抽取系统,包括如下部分:图片训练测试集单元:包括3000个汉字常用字的常用字体包括宋体、楷体、隶书和黑体等的不同噪音的图片,以及对人物名片图片自动进行角度调整生成多个测试样例等图片数据;文本知识库单元:包括中文汉字拼音库、笔顺库,以及职位和单位名称等词典;文字提取单元:实现对名片的图片中的文字的提取;实体识别单元:实现对文字提取结果中的人名、工作单位和职位三种实体的识别;其中还包括对于当同一个区域中包含两个或以上实体时,利用中文词法工具将其划分为单个的实体,词法工具可以采用百度lac中文词法分析工具。其命名实体识别方法,可以使用包括嵌入层,bilstm层,以及解码crf层组成的三层模型。
25.实体修正单元:实现对识别的人名、工作单位和职位置信度低的部分进行修正。
26.任职关系生成单元:生成若干个《人名,工作单位,职位》的三元组,并存储在数据库中。
27.如图3所示,其中文字提取单元包含检测子单元和识别子单元,分别实现文字检测和文字识别;其中文字检测可以采用db等基于图像分割的检测模型,判别每一个像素点是否属于一个文本目标和它与周围像素的连接情况,再将相邻像素结果整合为一个文本框;文字识别算法可以使用crnn识别模型,包括卷积层cnn,循环层rnn和转录层ctc。
28.如图4所示,其中实体修正单元,包括人名修正子单元,工作单位修正子单元和职位修正子单元:(1)人名修正子单元对于识别出的人名,在名片中存在对应人名拼音的情况下,利用中文汉字拼音库中获得具有相同拼音且字形最接近的汉字进行修正;在不存在拼音的情况下,利用字形相似度度量选择字型最接近汉字进行修正;其中字形相似度度可以基于ids(ideographic description sequence)的编辑距离计算。
29.(2)工作单位修正子单元对于识别出的工作单位,根据其位置和字体等信息判断是否为徽标(logo),如果是徽标(logo)则调用徽标(logo)识别算法进行识别和修正;如果不是常用的徽标(logo),但其中包含工作单位的英文、拼音或地址信息,则使用英文、拼音或地址信息作为输入,调用搜索引擎的接口搜索获得工作单位的正确名称进行修正;如果不包含以上信息,则首先利用语言模型得到最有可能的字,然后在最有可能的字中利用字形相似度度量选择字型最接近汉字进行修正。其中语言模型可以使用bert模型,字形相似度度可以基于ids计算。
30.(3)职位修正子单元对于识别出的职位,根据职位词典库选择编辑距离最小的职位名称进行修正。如果词典中的职位名称的距离都大于阈值,则将修正过的工作单位名称和待修正的职位一同输入到语言模型中,得到最有可能的字,然后在最有可能的字中利用字形相似度度量选择字型最接近汉字进行修正。其中语言模型可以使用bert模型,字形相
似度度可以基于ids计算。
31.以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
