1.本发明涉及降水预测技术领域,特别涉及一种基于稀疏样本的雨季降水年际变化预测方法。
背景技术:
2.降水作为最常见的天气现象之一与人们的生活息息相关。雨季是每年降水比较集中的湿润多雨季节。此季节经常出现大雨和暴雨。雨季中的强降水区域往往会造成严重的洪涝灾害,进而造成巨大的经济损失和人身安全威胁。在中国,雨季是每年的夏季(6月、7月和8月)。从降水的空间分布来看:在中国的西北地区,雨季极端天气事件发生较少,部分地区累计降水量在50mm以下;在中国的东南地区,雨季降水受夏季风和台风等因素影响,部分地区累计降水量高达 1000mm以上。因此,准确预测雨季降水的强降水区域对于精准预防洪涝灾害,保障财产和人身安全具有重要意义。
3.目前,对于短期气候预测问题,传统的数值天气预测方法仍然是气象中心常用的降水预测方法之一。该方法的预测依据是大气的实际情况,在一定初始值和边界条件的约束下,利用高性能计算机作数值计算,求解代表天气演变过程的流体力学和热力学方程组,从而实现预测一定时间段后的大气运动状态和天气现象。由于求解方程组需要的计算复杂度很高,所以,该方法完成年际降水预测往往需要以更优的硬件和更长的计算时间作为代价。近几年,也有不少深度学习的方法解决降水预测问题。它们中的一部分考虑图像信息中包含的时空关系,另一部分考虑气象数据与降水事件之间的联系。神经网络模型可以避免求解复杂的方程组,但是它们往往需要大量的历史数据用于学习潜在的预测关系和增强模型的泛化能力。对于雨季降水年际变化预测问题,数据往往是一个稀缺资源。markov模型也是一个解决离散时间序列预测的机器学习方法,它被广泛应用于降水预测问题上。markov模型既没有很高的计算复杂度,又不需要大量的历史数据。但是,它的预测结果往往依赖于历史降水量的大多数情况。也就是说,由于大多数年份同一观测站雨季降水量是相近的。所以,马尔科夫模型对于降水的极端情况和异常情况预测效果不好。因此,在保证预测精度的同时解决雨季降水预测的稀疏样本问题具有重要研究意义。
技术实现要素:
4.本发明的目的是提供一种解决上述技术难题的基于稀疏样本的雨季降水年际变化预测方法。
5.为此,本发明技术方案如下:
6.一种基于稀疏样本的雨季降水年际变化预测方法,具体步骤如下:
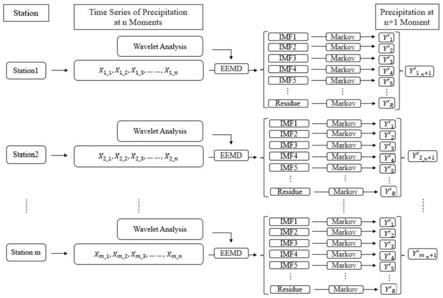
7.s1、对雨季降水的稀疏样本进行处理,以获取构建雨季降水预测模型的指导数据;其具体步骤为:
8.s101、基于预测区域内m个观测站点,获取各观测站点n年来每年的雨季月平均降水量形成雨季降水时间序列形成雨季降水时间序列利用小波分析
将雨季降水时间序列分解为六个高频分量:分解为六个高频分量:和以及一个低频分量
9.s102、采用可解释方差法对六个高频分量的分散程度进行分析,筛除高频分量中的无意义高频分量;
10.s103、最终得到用于步骤s2的剩余高频分量和一个低频分量;其中,剩余高频分量个数s为对应观测站雨季降水不同时间尺度的有效分解结果s;
11.s2、将各观测站雨季降水不同时间尺度的有效分解结果s作为构建雨季降水预测模型的指导数据,分别对各观测站的雨季降水预测模型进行构建,其具体构建步骤为:
12.s201、利用eemd法对雨季降水时间序列进行分解,并指定得到s个特征项和1个趋势项;其中,s个特征项为s个雨季降水时间分解序列:包括imf1, imf2,
…
,imfs,趋势项为第s阶残差rs(n);
13.s202、基于s个特征项和1个趋势项,利用markov模型,依次通过状态等级划分、转移次数矩阵统计、转移概率矩阵计算和加权求和计算,得到该站点对应地s个特征项和1个趋势项在第n 1年的预测数值;
14.s203、对步骤s202得到的s个特征项和1个趋势项在第n 1年的预测数值进行加和,所得结果即为该站点在第n 1年的雨季月平均降水量的预测值;
15.s204、重复步骤s201~s203,直至完成m个站点第n 1年雨季月平均降水量的全部预测。
16.进一步地,在步骤s101中,第i年的雨季月平均降水量
[0017][0018]
式中,a
n-6
为该观测站第i年6月降水量总和;a
n-7
为该观测站第i年7月降水量总和;a
n-8
为该观测站第8月降水量总和;i为年序数,其取值范围为1~n中任一整数。
[0019]
进一步地,在步骤s101中,小波分析具体采用小波基函数db16。
[0020]
进一步地,步骤s102的具体筛选方法为:
[0021]
将六个高频分量和一个低频分量分别代入可解释方差计算公式:
[0022][0023]
式中,式中,m1为的平均数;当时,时,时,式中,m2为的平均数;当或时,以此类推;
[0024]
当evar>0.1对应地高频分量为能够代表雨季降水的分量,即小波分析的代表性
分量;当evar≤0.1且对应地高频分量周期波动小,则判定为无意义高频分量。
[0025]
进一步地,步骤s201的具体步骤为:
[0026]
s2011、对雨季降水时间序列添加一定信噪比的随机白噪声,得到加噪雨季降水时间序列x(n));
[0027]
s2012、取x(n)的极大值点并拟合出上包络线x
max
(n),取x(n)的极小值点并拟合出下包络线x
min
(n);
[0028]
s2013、求上包络线x
max
(n)和下包络线x
min
(n)的上下包络线均值m1(n):
[0029][0030]
s2014、对加噪雨季降水时间序列x(n)与上下包络线均值m1(n)作差,得到余下信号d1(n);将该余下信号d1(n)替换x(n),成为新的加噪雨季降水时间序列;
[0031]
s2015、重复步骤s2012至s2014,直到满足设定的迭代次数m1要求,得到 d1(n)';
[0032]
s2016、重复步骤s2011至s2015,直到满足设定的迭代次数m2要求,得到 m2个d1(n)',对m2个d1(n)'取平均值得到第一个特征项imf1;
[0033]
d1(n)'=imf1={imf
1-1
,imf
1-2
,imf
1-3
,
…
,imf
1-j
,
…
,imf
1-n
};
[0034]
s2017、基于步骤s1所得的指导结果,对于本实施例来说,该步骤s201需要分解出5个imf和1个趋势项;因此,采用将时间序列与imf1作差的方法,计算得到第1阶残差r1(n);将r1(n)作为新雨季降水时间序列,重复步骤s2011 至s2016,直到对应得到如上所述的s个雨季降水时间分解序列:imf1,imf2,
…
, imf5,而第5阶残差rs(n)即为如上所述的趋势项。进一步地,在步骤s201中,信噪比为0.02;m1=10;m2=2000。
[0035]
进一步地,步骤s202的具体实施步骤为:
[0036]
s2021、将各雨季降水时间分解序列按照均值偏离标准差的程度划分为五个状态等级,以将各时间分解序列转换为相应的状态序列;
[0037]
s2022、分别对各状态序列进行统计,每个状态序列对应得到5个状态转移次数矩阵f1~f5;然后基于每个状态转移矩阵计算时间跨度分别为1年、2年、3 年、4年和5年的5个转移概率矩阵;
[0038]
s2023、根据公式:计算时间跨度分别为1年至5年的自相关系数;式中,t为雨季降水时间分解序列的年序数,其取值范围为1~n;a为时间跨度,其取值为1~5的整数;j的其取值为1~5的整数;为该时间序列分量下各元素的平均值;再将1~5年的自相关系数归一化得到预测的权重;
[0039]
s2024、对第n 1年的雨季降水时间分解序列进行预测:
[0040]
1)利用加权求和公式为:对同一状态的概率加权求和,并取得概率最大的状态p
i_max
对应地状态数值;式中,i为步骤s2021对应的五个状态等级;b为时间
跨度;pb为转移概率;
[0041]
2)对于s个特征项,利用级别特征值的概念得到最终的预测数值;对于1 个残差项,取预测状态区间中位数作为预测数值;
[0042]
级别特征值h根据公式:计算得到;
[0043]
式中,pi为预测结果为状态i时的概率,ε是最大概率的作用指数,在本实施例中,ε=2;
[0044]
当级别特征值h》i时,预测的数值l按下式计算:
[0045][0046]
当级别特征值h《i时,预测的数值l按下式计算:
[0047][0048]
式中,ti为预测状态i的数值区间的上限,bi为预测状态i的数值区间的下限;
[0049]
s2025、重复上述步骤s2021至s2025,直至得到剩余s个特征项以及残差项的全部预测结果:imf
2-(n 1)
,imf
3-(n 1)
,imf
4-(n 1)
,imf
5-(n 1)
和r
n 1
。
[0050]
进一步地,步骤s2021中,状态等级划分方法为:当,则状态等级划分为1;当,则状态等级划分为2;当则状态等级划分为3;则状态等级划分为4;当则状态等级划分为5;其中,x为第j年的imf值,即imf
1-j
;为n年雨季降水时间分解量的平均值,即:即:s为n年雨季降水时间分解量(imf
1-1
,imf
1-2
,imf
1-3
,
…
, imf
1-j
,
…
,imf
1-n
)的标准差;α为距离雨季降水时间分解量平均值的第一偏移量,β为距离雨季降水时间分解量平均值的第二偏移量,且α>β,二者均为人为设定值。
[0051]
进一步地,在步骤s203中,对步骤s202得到的全部第n 1年的雨季降水时间分解序列结果进行加和重构,得到该站点在第n 1年雨季月平均降水量加和重构计算公式为:
[0052][0053]
与现有的降水预报方法相比,该基于稀疏样本的雨季降水年际变化预测方法的有益效果:
[0054]
1)与传统的数值预测方法相比,该方法避免了大量方程组的求解计算,计算复杂度更低;与此同时,该方法在普通笔记本电脑上就可以实现,避免了数值预测方法对硬件的超高要求,经济成本更低;
[0055]
2)对于雨季降水的年际变化问题,可以利用的历史数据比较少;该方法引入markov模型来解决稀疏样本问题;markov模型可以通过稀疏样本数据的状态转移关系推测1年后的雨季降水情况,避免了对大量历史数据样本的依赖;
[0056]
3)由于雨季降水时间序列往往可以看作不同时间尺度序列的叠加结果,所以该方法先利用小波分析获得雨季降水中具有物理意义的各个分量,从而确定 eemd分析的分解等级;将eemd分析结果利用markov模型预测,克服了在稀疏样本下仅用markov模型预测时依赖于雨季降水多数情况的问题;提高了 markov模型预测异常降水和极端降水的能力。
附图说明
[0057]
图1为本发明的基于稀疏样本的雨季降水年际变化预测方法的流程图;
[0058]
图2(a)为本发明的一级异常n1预测正确的站点数目与markov模型的对比结果;
[0059]
图2(b)为本发明的二级异常n2预测正确的站点数目与markov模型的对比结果;
[0060]
图2(c)为本发明的漏报站m预测正确的站点数目与markov模型的对比结果;
[0061]
图3(a)为本发明的ts评分的预测结果与markov模型的对比结果;
[0062]
图3(b)为本发明的acc评分的预测结果与markov模型的对比结果。
具体实施方式
[0063]
下面结合附图及具体实施例对本发明做进一步的说明,但下述实施例绝非对本发明有任何限制。
[0064]
如图1所示为基于现有的1951年至2016年稀疏的雨季降水样本,采用本技术的基于稀疏样本的雨季降水年际变化预测方法对2017年、2018年和2019年的雨季降水量进行预测,其具体实施步骤如下:
[0065]
s1、对雨季降水的稀疏样本进行处理,以获取构建雨季降水预测模型的指导数据;
[0066]
具体地,雨季降水的稀疏样本的具体处理步骤如下:
[0067]
s101、将雨季降水时间序列利用小波分析分解为六个高频分量和一个低频分量;具体分解步骤如下:
[0068]
s1011、基于在中国,雨季是指每年的6月至8月,获取来自全国m个(m=160) 观测站的雨季降水资料,具体为1951年~2016年共计66年来每年6月至8月的降水量;
[0069]
s1012、对各观测站66年来每年6月至8月的降水量按照如下公式求平均值,得到单一观测站第i年的雨季月平均降水量
[0070][0071]
式中,a
n-6
为该观测站第i年6月降水量总和;a
n-7
为该观测站第i年7月降水量总和;a
n-8
为该观测站第8月降水量总和;i为年序数,其取值范围为1~66 中任一整数;
[0072]
通过对观测站66年来每年的雨季降水量进行计算,进而得到该观测站的雨季降水时间序列
[0073]
以此类推,最终计算得到160个观测站的各站点的雨季降水时间序列
[0074]
s1013、采用小波基函数db16,对步骤s1012得到的各观测站的雨季降水时间序列
依次进行分解,得到与观测站的雨季降水时间序列对应的六个雨季降水时间序列高频分量:和以及一个雨季降水时间序列低频分量
[0075]
s102、将由步骤s101得到的各观测站的雨季降水时间序列及其通过分解得到的六个雨季降水时间序列高频分量:和以及一个雨季降水时间序列低频分量分别代入可解释方差计算公式:
[0076][0077]
式中,evar为可解释方差,var(z)为原始时间序列z的分散程度,具体地,原始时间序列z即为观测站的雨季降水时间序列;var(z-z')为小波分析后分量 z'与原始时间序列z之间的差的分散程度,具体地,小波分析后分量z'即为观测站的雨季降水时间序列对应地六个雨季降水时间序列高频分量:应地六个雨季降水时间序列高频分量:和;其中,
[0078]
var(z)的计算公式为:var(z)的计算公式为:式中,m1为的平均数;
[0079]
var(z-z')的计算公式为(以z'取为例):为例):式中, m2为的平均数;
[0080]
由于可解释方差衡量是分散程度的对比,evar越大即表示小波分析结果与雨季降水的分布程度越相近;因此,在上述可解释方差计算结果中,evar>0.1对应地高频分量为能够代表雨季降水的分量,即小波分析的代表性分量;而evar≤0.1 并且对应地高频分量周期波动小(即没有显著的周期性变换趋势),则判定为无意义高频分量;
[0081]
s103、根据步骤s102的计算结果,舍去经过步骤s101得到六个雨季降水时间序列高频分量中的无意义高频分量,得到该观测站雨季降水不同时间尺度的分解结果,即有意义高频分量的个数s;
[0082]
经过步骤s101~s103得到的s个分解结果即为雨季降水中不同物理意义的分量,可作为指导雨季降水预测模型构建的基础,即构建雨季降水预测模型的指导数据;
[0083]
在本实施例中,以位于上海的站点56为例,经过上述步骤s101~s102的计算,可得到下表1:
[0084][0085]
根据上表的计算结果,对于该站站点分解出得六个高频分量来说,高频分量为由于没有显著的周期性变换趋势,因此判定为无意义高频分量;基于此,该位于上海的站点56的雨季降水不同时间尺度的分解结果s=5;
[0086]
s2、将经过步骤s1得到的各观测站雨季降水不同时间尺度的分解结果s作为构建雨季降水预测模型的指导数据,对分别构建各观测站分别进行雨季降水预测模型;
[0087]
具体地,该步骤s2中,针对每个观测站的雨季降水模型的构建步骤如下:
[0088]
s201、利用eemd法(即集合经验模态分解法)对各站点的雨季降水时间序列进行分解,并指定得到s个特征项和1个趋势项;
[0089]
在该分解过程中,每个站点的雨季降水时间序列可以看作一个n维向量, eemd法对该n维向量依次进行白噪声处理、作差处理、迭代处理,使其分解为 s个特征项和1个趋势项;同理,利用eemd分解出的每个特征项和趋势项均为新的n维向量,因此,经过eemd法分解所得结果为(s 1)
×
n维向量;其中,特征项的数量s的取值为步骤s1得到的雨季降水不同时间尺度的分解结果s的取值;在采用eemd法对雨季降水时间序列进行分解前人为设定目标输出结果。
[0090]
具体地,该步骤s201的具体实施步骤为:
[0091]
s2011、对n维的雨季降水时间序列添加一定信噪比的随机白噪声,加噪雨季降水时间序列x(n);具体地,信噪比优选为0.02;
[0092]
s2012、取x(n)的极大值点并拟合出上包络线x
max
(n),取x(n)的极小值点并拟合出下包络线x
min
(n);
[0093]
s2013、求上包络线x
max
(n)和下包络线x
min
(n)的上下包络线均值m1(n):
[0094][0095]
s2014、对加噪雨季降水时间序列x(n)与上下包络线均值m1(n)作差,得到余下信号d1(n);将该余下信号d1(n)替换x(n),成为新的加噪雨季降水时间序列;
[0096]
s2015、重复步骤s2012至s2014,直到满足设定的迭代次数m1(本实施例中,m1=10)要求,得到d1(n)';
[0097]
s2016、重复步骤s2011至s2015,直到满足设定的迭代次数m2(本实施例中,m2=2000)要求,得到m2个d1(n)',对m2个d1(n)'取平均值得到第一个特征项imf1;其中,d1(n)'=imf1={imf
1-1
,imf
1-2
,imf
1-3
,
…
,imf
1-j
,
…
,imf
1-n
}, n=66;
[0098]
s2017、基于步骤s1所得的指导结果,对于本实施例来说,该步骤s201需要分解出5
个imf和1个趋势项;因此,采用将时间序列与imf1作差的方法,计算得到第1阶残差r1(n);将r1(n)作为新雨季降水时间序列,重复步骤s2011 至s2016,直到对应得到如上所述的s个雨季降水时间分解序列:imf1,imf2,
…
, imf5,而第5阶残差rs(n)即为如上所述的趋势项;
[0099]
s202、基于单一站点的s个特征项和1个趋势项,利用markov模型对该站点在第n 1年的雨季月平均降水量进行预测;
[0100]
在该步骤s202中,采用markov模型一方面能够考虑历史降水数据从某一个状态向下一个状态转移的概率,另一方面能够考虑时间序列本身的自相关性;进而,通过综合考虑预测对象和预测出的其他状态的概率,得出预测的数值结果;
[0101]
具体地,以s 1中的1个雨季降水时间分解序列imf1为例,对其第n 1年的雨季降水时间分解序列进行预测的实施步骤为:
[0102]
s2021、状态等级划分:
[0103]
将雨季降水时间分解序列imf1={imf
1-1
,imf
1-2
,imf
1-3
,
…
,imf
1-j
,
…
,imf
1-n
},按照均值偏离标准差的程度,划分为如下表2所示的五个状态等级,以将时间分解序列imf1转换为状态序列a1,a1={a
1-1
,a
1-2
,a
1-3
,
…
,a
1-j
,
…
,a
1-n
};
[0104]
表2:
[0105][0106]
其中,x为第j年的imf值,即imf
1-j
;为n年雨季降水时间分解量的平均值,即:s为n年雨季降水时间分解量(imf
1-1
,imf
1-2
,imf
1-3
,
…
,imf
1-j
,
…
,imf
1-n
)的标准差;α为距离雨季降水时间分解量平均值的第一偏移量,β为距离雨季降水时间分解量平均值的第二偏移量,且α>β,二者均为人为设定值;
[0107]
在本实施例中,该上海站点56的雨季降水时间分解序列imf1的状态等级划分的具体情况如下表3所示。其中,α=0.8,β=0.4。
[0108]
表3:
[0109]
[0110]
[0111][0112]
s2022、转移概率矩阵计算:
[0113]
对状态序列a1进行统计,得到5个状态转移次数矩阵f1~f5;进而计算得到分别代表时间跨度为1年的转移概率矩阵p1、时间跨度为2年的转移概率矩阵 p2、时间跨度为3年的转移概率矩阵p3、时间跨度为4年的转移概率矩阵p4、以及时间跨度为5年的转移概率矩阵p5;每个转移概率矩阵的维数为5
×
5,代表上述5种状态之间的转换;
[0114]
该计算过程的具体实施步骤如下:
[0115]
1)统计时间跨度为1年的情况下,表示不同状态之间转移次数的转移次数矩阵f1:
[0116][0117]
其中,在转移次数矩阵f1中,f
ij
为由状态i转移到状态j的次数,i的取值为 1~5中任一整数,j的取值为1~5中任一整数;
[0118]
在本实施例中,以转移次数矩阵f1中f
11
为例,其含义为时间跨度为1年且发生由状态i转移到状态j的次数,参照表3可以统计得到,该情况发生次数为1 次,即自2012年至2013年,其转移情况为由状态1转移为状态1;同理,状态 1转移到状态5的次数为8次,即f
15
=8;
[0119]
2)基于转移次数矩阵f1,利用公式:计算转移次数矩阵f1对应的各个元素f
ij
在时间跨度为一年情况下由状态i转移到状态j的概率p
ij
,得到时间跨度为1年对应的转移概率矩阵p1:
[0120][0121]
在本实施例中,以转移次数矩阵f1中f
11
为例,在时间跨度为一年情况下由状态1转移到状态1的概率p
ij
的计算公式为:p
ij
=f
11
/(f
11
f
12
f
13
f
14
f
15
);
[0122]
3)依次更改状态转移时间跨度为2年、3年、4年和5年,并重复上述步骤 1)和2),分别计算得到2~5年时间跨度下的转移概率矩阵p2、p3、p4和p5。
[0123]
在本实施例中,根据表3统计的数据,得到当时间跨度为1年,imf1的状态转移次数矩阵f1至f5结果如下:
[0124][0125]
进一步,根据转移次数矩阵f1~f5,计算得到转移概率矩阵p1至p5;对于转移次数矩阵中f1,在时间跨度为1年的情况下,由状态1转移到状态2的概率p
12
的计算方式为:
[0126]
以此类推,转移概率矩阵p1至p5的计算结果如下:
[0127][0128]
s2023、权重系数计算:
[0129]
1)基于时间序列的自相关性的考虑,根据公式:
[0130][0131]
计算时间跨度分别为1年至5年的自相关系数;式中,t为雨季降水时间分解序列的年序数,其取值范围为1~n(在本实施例中,n=66);a为时间跨度,其取值为1,2,3,4或5;为(imf
1-1
imf
1-2
imf
1-3
…
imf
1-j
…
imf
1-n
)/n;
[0132]
2)将对应5年的自相关系数归一化得到预测的权重;
[0133]
其中,自相关系数归一化得到权重系数的公式为:
[0134]
在本实施例中,针对雨季降水时间分解序列imf1的权重结果如下表4所示。
[0135]
表4:
[0136]
权重12345la0.627330.086260.011290.078880.19624
[0137]
s2024、对第n 1年的雨季降水时间分解序列进行预测:
[0138]
1)对同一状态的概率加权求和,得到概率最大的状态p
i_max
;
[0139]
具体地,加权求和公式为:
[0140]
式中,i为步骤s2021对应的五个状态等级,因此i的取值范围为1~5;b为时间跨度,在本实施例中,基于2012年~2016年这5个年份代入计算,因此b 的取值为1~5;pb为转移概率;
[0141]
在本实施例中,2017年雨季降水的状态概率预测结果如下表5所示。
[0142]
表5:
[0143][0144]
在表5中,其具体计算方法以2016年为例,2016年在表2中划分的状态等级为1,2016年与2017年之间的时间跨度为1,该时间跨度对应地权重la=0.62733,因此,2017年状态等级转变为状态1的概率取转移概率矩阵p1中的p
11
,即0.0714 (保留四位有效小数以便计算),因此,考虑权重因素影响,当b=1时,lapb=0.62733
ꢀ×
0.0714=0.0448;以此类推,对于2017年状态等级为1的情况,相应地,pi的计算结果即为状态1所在列的概率值分别与相应权重乘积的加和。
[0145]
根据表5的计算结果对比可知,在本实施例中,状态5为预测结果中的最大概率值对应的状态,即i=5。
[0146]
2)对于s个特征项,利用级别特征值的概念得到最终的预测数值;对于1 个残差项,取预测状态区间中位数作为预测数值;
[0147]
具体地,级别特征值h根据公式:计算得到;
[0148]
式中,pi为预测结果为状态i时的概率,ε是最大概率的作用指数,在本实施例中,ε=2;
[0149]
当级别特征值h》i时,预测的数值l按下式计算:
[0150][0151]
当级别特征值h《i时,预测的数值l按下式计算:
[0152][0153]
式中,ti为预测状态i的数值区间的上限,bi为预测状态i的数值区间的下限;
[0154]
在本实施例中,级别特征值的计算结果为:h=4.4684;由于结果值小于最大概率值对应的状态数值,即5;因此,最终的预测数值l根据公式计算得到为: l=34.5903,即该上海站点56的imf
1-(n 1)
=34.5903;
[0155]
s2025、重复上述步骤s2021至s2025,直至完成剩余s个特征项(imf2、 imf3、imf4、imf5)以及残差项的全部预测;
[0156]
s203、集成预测结果实现雨季降水在第n 1年的预测:
[0157]
对步骤s202得到的全部第n 1年的雨季降水时间分解序列结果进行加和重构,得到该站点在第n 1年雨季月平均降水量
[0158]
具体地,加和重构计算公式为:
[0159][0160]
在本实施例中,由步骤s202预测出的上海站点56的各个特征项和趋势项结果为:imf
1-n 1
=34.5903,imf
2-n 1
=13.0855,imf
3-n 1
=11.9694,imf
4-n 1
=-4.9133, imf
5-n 1
=4.4105,r
n 1
=173.35,于是得到该上海站点56在第n 1年雨季降水量预测值为232.4925;
[0161]
s204、重复步骤s201~s203,直至完成全国160个站点第n 1年的雨季降水预测。需要说明的是,在本实施例中,预计降水量的单位均为mm。
[0162]
由于本技术构建的模型中,基于过去雨季降水序列分解出的每年的雨季降水状态在过去和将来都是相互独立的,没有直接的关联性,因此可以采用马尔科夫模型前期检验对本实施例所得的结果进行验证,看是否符合规律,能够通过马氏检验;具体地,模型的马氏性是指在已知“现在”的条件下,“将来”与“过去”是独立的;在应用马尔科夫链时,通过进行马氏性检验,以确定其预测结构是否具有可行性。在本实施例中,将5个转移概率矩阵按卡方分布计算,其卡方结果均大于0.05显著水平的χ2(m-1)2(查表:χ
0.052
(m-1)2=26.296),通过马氏检验。
[0163]
进一步,为了证明本技术的基于稀疏样本的雨季降水年际变化预测方法,进一步采用评分的方法与气象局常用的第二代气候模式预测系统bcc_csm1.1(m) 作比较。另与仅
用markov模型的预测结果比较,证明了本方法提升预测精度的有效性。其具体评价步骤如下:
[0164]
为了更直观的看出各个模型的预测效果,我们利用评分的方法验证它们的有效性。
[0165]
首先,需要将预测出的雨季降水量数值按照公式1转换为雨季降水的距平百分率,距平百分率代表该降水量较历史同期值的涨幅或降幅。其中,ps评分、 acc评分和ts评分的计算公式都是对雨季降水距平百分率的处理。
[0166]
在公式(1)中,y'代表预测(实况)的某年某站点降水的距平百分率,y代表某年某站点的预测(实况)降水量,代表该站点雨季降水的实况历史均值。计算预测和实况的雨季降水距平百分率时利用相同的
[0167][0168]
空间距平相关系数(anomalous correlation coefficient,以下简称:acc)可针对任意空间范围计算并可得到评分的时间演变,在业务评分中广泛采用。acc 计算公式如公式(2)所示,其中x代表实况的距平百分率,f代表预测的距平百分率,i代表评价区域内的站点数;对于中国雨季降水预测问题,m=160,m=160,分别代表实况距平百分率和预测距平百分率的空间区域平均值。
[0169][0170]
趋势异常综合检验评分方法(operational prediction scores,以下简称:ps评分)主要分别考虑预测的趋势项、异常项和漏报项。
[0171]
对于全国160个气象观测站:1)逐站判定预测的趋势是否正确,趋势是以预测和实况的距平符号是否一致为判断依据,统计趋势预测正确的总站数为n0。
[0172]
2)逐站判定一级异常预测是否正确,一级异常的判定标准为雨季降水增长或减少20%到50%,统计出一级异常预测正确的总站数n1。
[0173]
降水的一级异常预报评分标准如下表6所示。
[0174]
表6:
[0175][0176]
3)逐站判定二级异常预测是否正确,二级异常的判定标准为雨季降水增长或减少50%以上,统计出二级异常预测正确的总站数n2。
[0177]
降水的二级异常预报评分标准如下表7所示。
[0178]
表7:
[0179][0180]
4)没有预测出二级异常而实况出现降水距平百分率≥100%或等于-100%的情况称为漏报站,记为m。
[0181]
5)统计实际参加评估的站数n(n=160);利用公式(3)计算得到的ps评分,式中,的a=2,b=2,c=4;
[0182][0183]
异常气候评分(threat score,以下简称ts评分)用来评估模型预测异常级(达到一级异常和二级异常的站点)的能力,ts计算公式如式4所示。其中,nf,n0分别代表预测和实况达到一级异常以上(包括二级异常)的站数,nc为预测正确的一级异常和二级异常站数。ts评分表示预测正确的站点数在预测和实况总站数中的百分比,该评分考虑了报错的影响。区别于ps评分,ts评分不包括对于趋势的评价,仅针对异常降水的情况做评估。
[0184][0185]
该结果是先利用克里金插值的方法,将160个观测站的站点数据转换成格点 数据,然后绘制成等值线图得到的。
[0186]
如表8所示为与bcc_csm1.1(m)的评分比较结果,可以看出本方法在2017 年的ps评分低于bcc_csm1.1(m),而2018年和2019年的ps评分均高于 bcc_csm1.1(m)。2017年的ps评分结果虽然没有模式预测系统好,但本方法得到了一个与之相当的预测结果。所以,综合3年的ps评分均值,可以看出,本方法有更好的预测结果。
[0187]
表8:
[0188][0189]
如图2(a)~图2(c)所示为本方法与仅用markov模型的逐站预测结果比较,如图3(a)和图3(b)所示为本方法与仅用markov模型的评分预测结果比较。可以看出,从异常降水预测正确的观测站数目来看,本方法的预测结果均优于仅用markov模型。从ts评分来看,本方法对于2017年至2019年异常降水的预测能力明显优于仅用markov模型。从acc评分来看,除了2017年本方法的预测结果不及仅用markov模型外,另外两年本方法的预测结果明显优于仅用仅用markov模型。2017年至2019年仅用markov模型的acc评分平均水平仅仅达到
0.059,但是本方法的3年平均水平可以达到0.091。实验结果进一步验证了本方法可以有效的提升模型预测异常降水的能力。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。