1.本发明涉及计算机多媒体技术领域,特别涉及一种基于音视频感知的人物性别识别技术。
背景技术:
2.性别识别是让计算机根据输入的人的语音特征、面部特征等信息判断性别的过程,它是当前计算机生物识别领域中热门的研究课题之一,在人工智能、系统监控、模式识别等方面有着重要的前景。性别识别在身份识别与验证中可以充当“过滤器”,利用监测出来的性别信息提高身份认证识别的速度与精度。现有技术通常是单独利用视频特征或者语音特征进行性别识别,只利用视频特征进行性别识别的局限性在于其高度依赖于合适的头部方向和完全正对的面部图像,当得到不同角度的图片时,识别性能大大降低,这种方法也很消耗计算资源和时间。只利用音频特征进行性别识别不像基于视频特征那么消耗计算资源和时间,但它的局限性在于语音样本通常来自嘈杂的环境,使得性别判定更加困难。
3.本发明提出基于音视频感知的人物性别识别技术,结合视频特征和语音特征,实现一个性能更好、功能更强大的性别识别系统。
技术实现要素:
4.本发明所要解决的技术问题在于针对现有技术的不足,提出了一种基于音视频感知的人物性别识别技术,通过结合人物的面部特征和语音特征,进行人物性别的识别。
5.为了解决上述技术问题,本发明采用的技术方案是:基于音视频感知的人物性别识别技术,包括以下步骤:
6.1)收集男性和女性的面部缩略图像,将图像放缩为20x20尺寸
7.2)将处理后的图像输入基于视频特征的分类器中对人物性别进行分类,得到基于视频特征的性别识别结果。
8.3)收集男性和女性的语音数据,计算倒谱(cepstrum)并保留前12个系数。
9.4)上述12个系数输入到基于音频特征的svm分类器中进行训练,得到基于音频特征的性别识别结果。
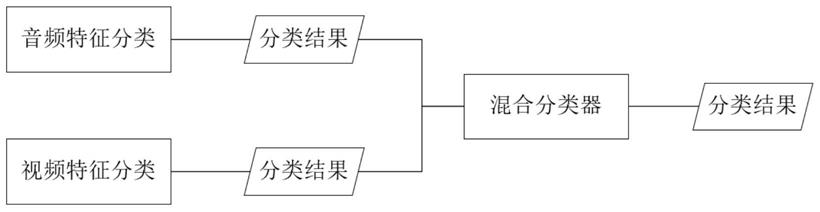
10.5)将基于音频特征的性别识别结果和基于视频特征的性别识别结果送入最终的多模态混合分类器中,得到最终的性别识别结果。
附图说明
11.图1为本发明操作流程的框图。
12.图2为本发明混合分类器的结构。
具体实施方式
13.下面结合实施例对本发明做进一步的详细说明,以令本领域技术人员参照说明书
文字能够据以实施。
14.本实施例的基于音视频感知的人物性别识别技术,包含以下步骤:
15.1)收集面部缩略图,将图片大小放缩为20x20尺寸,保存到400维向量中。
16.2)将处理后的面部图像数据输入到基于视频特征的支持向量机(support vector machine,svm)分类器中进行训练,基于视频特征的分类器根据性别来对原始视频数据进行分类,并输出分类结果。svm旨在找到一个超平面f
*
(x),其定义为:
17.f
*
(x)=《w,x》 b
ꢀꢀꢀ
(1)
18.寻找超平面可转化为约束优化问题,最优超平面表示为:
[0019][0020]
其中k(,)是一个核函数,f
*
(x)的符号决定了x的标签。
[0021]
3)将训练好的svm模型进行测试,对于测试集中误分类的面部缩略图,将其归入训练集继续进行训练,然后再用测试集剩余图像进行测试。
[0022]
4)手机男性和女性的语音数据,将输入语音波形分为时长为16ms的帧(frame),利用快速傅里叶变换(fast fourier transform,fft)将语音信号转换到频域,然后通过下式计算出倒谱(cepstrum):
[0023]
cepstrum(frame)=fft-1
(log|fft(frame)|)
ꢀꢀꢀ
(3)
[0024]
保留倒谱的前12个系数作为音频特征分类器的输入。
[0025]
5)将提取的音频特征输入到svm分类器中,得到基于音频特征的人物性别分类结果。
[0026]
6)将基于视频特征的性别分类结果和基于音频特征的性别分类结果进行语义上的融合,然后输入到最终的多模态混合分类器中进行性别分类,得到最终的性别识别结果,混合分类器详细如图2所示。每一个数据点到超平面的距离可表示为:
[0027][0028]
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节。
技术特征:
1.基于音视频感知的人物性别识别技术,其特征在于,包括以下步骤:1)第一个特征分类器,基于音频特征对人物性别进行初步判定,得到初步判定结果;2)第二个特征分类器,基于视频特征对人物性别进行初步判定,得到初步判定结果;3)一个混合分类器,基于第一个特征分类器和第二个特征分类器的初步判定结果,对两者进行整合并输出最终的人物性别的判定结果,判定为男性或者女性。2.根据权利要求1所述的基于音视频感知的人物性别识别技术,其特征在于,第一个特征分类器为基于音频特征的分类器,第二个分类器为基于视频特征的分类器。3.根据权利要求2所述的基于音视频感知的人物性别识别技术,其特征在于,基于音频特征的分类器包括支持向量机(svm)。4.根据权利要求2所述的基于音视频感知的人物性别识别技术,其特征在于,第一个基于音频特征的分类器、第二个基于视频特征的分类器、和最终的混合分类器,其中每一个都包括支持向量机(svm)。5.基于音视频感知的人物性别识别技术,包含以下步骤:1)生成一个数据库,里面包含多个待分类的男性和女性的面部图像;2)从上述1)中数据库提取缩略图像;3)训练支持向量机分类器以区分男性和女性的面部图像,包括确定合适的多项式核和拉格朗日乘子的上界;4)生成一个数据库,里面包含多个待分类的男性和女性的语音;5)从4)中数据库提取倒谱特征;6)训练支持向量机分类器以区分男性和女性的语音,包括确定合适的径向基函数和拉格朗日乘子的上界;7)使用语义融合的方式,结合基于音频特征和基于视频特征的分类结果,最终得到相比单独基于语音或者视频特征的更优的性别分类结果。
技术总结
本发明公开了一种基于音视频感知的人物性别识别技术,首先利用支持向量机(Support Vector Machine,SVM)分别在音频数据和视频数据上对人物进行性别识别,然后将初步的识别结果输入到最终的多模态混合分类器中,对最终的分类器进行训练,并给出最终的性别识别结果。依据本发明为一种基于音视频感知的人物性别识别技术,其识别准确率较高。其识别准确率较高。其识别准确率较高。
技术研发人员:李东晋 彭德中 王骞 刘杰 张利君 银大伟 蒋瑞 付俊英
受保护的技术使用者:四川大学
技术研发日:2020.09.04
技术公布日:2022/3/21
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。