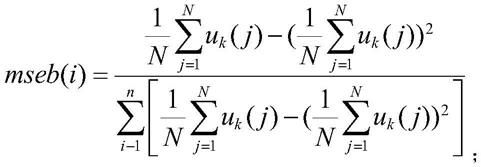
1.本发明属于图像处理技术领域,具体涉及基于三维卷积的非朗伯体表面光度立体模型及方法。
背景技术:
2.近年来随着3d相关技术的发展,非刚性体的三维数字化技术受到了业内的广泛关注。实现高效、高精度、廉价的重建方法一直是三维数字化领域的一个研究重点。
3.现有的方法都是单独使用空间信息或者帧间信息来进行法向量的恢复。因此提出了一种多维度信息融合的方法,同时使用空间信息和帧间信息来进行法向量的求解,在算法对于异常值区域(高光和阴影)具有较好的鲁棒性的同时,又能保留丰富的纹理信息。
技术实现要素:
4.本发明的第一个方面:旨在提供基于三维卷积获取非朗伯体表面三维图像的方法。
5.为实现上述技术目的,本发明采用的技术方案如下:
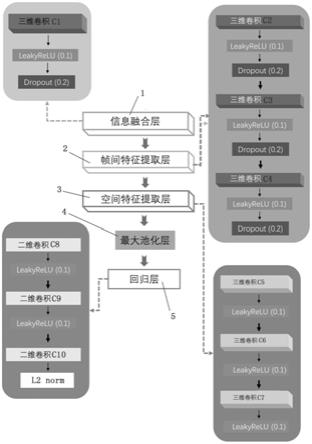
6.基于三维卷积的非朗伯体表面光度立体模型,包括信息融合层、帧间特征提取层、空间特征提取层、最大池化层和回归层;
7.所述信息融合层用于融合每一张图像与其对应的光源信息,保证在后续处理中图像与光源的一一对应;
8.所述帧间特征提取层用于提取帧间信息,获取输入图像帧之间的信息,用于我们法向图的估计;
9.所述空间特征提取层提取单张图像内部的结构信息用于法向图的恢复;
10.所述最大池化层用于用于降维、去除冗余信息、对特征进行压缩、简化网络复杂度、减少计算量、减少内存消耗。
11.作为本发明的一种优选方案,所述信息融合层包括一个三维卷积层c1,三维卷积层c1后跟有一个leakyrelu激活函数,其leakyrelu激活函数输出值dropout比率为0.2。
12.作为本发明的一种优选方案,所述帧间特征提取层包括三个三维卷积层,其分别为三维卷积层c2、三维卷积层c3和三维卷积层c4,每个三维卷积层后跟有一个leakyrelu激活函数,每个leakyrelu激活函数输出值dropout比率为0.2。
13.作为本发明的一种优选方案,所述空间特征提取层包括三个三维卷积层,其分别为三维卷积层c5、三维卷积层6和三维卷积层c7,每个三维卷积层后跟有一个leakyrelu激活函数。
14.作为本发明的一种优选方案,所述回归层包括三个二维卷积层,其分别为二维卷积层c8、二维卷积层c9和二维卷积层c10,二维卷积层c8和二维卷积层c9后跟有一个leakyrelu激活函数,二维卷积层c10后跟有一个l2 normalization修正函数。
15.本发明的第二方面,提供一种以多张从不同角度照明的图像来重建待测工件三维
表面信息的数据处理系统。
16.一种数据处理系统,包括数据处理器、图形处理器和数据存储器,数据处理器从数据存储器中读取图像并输入图形处理器中,图形处理器中预设图像识别网络,图像识别网络包括图像输入、获得输入图像的有效特征的特征提取器、最大池化层和法向求解单元;其特征在于:图像输入至初始融合模块,初始融合模块使当前图像及其光照信息一一对应,初始融合模块输出的融合了光照信息的图像输入到特征提起器中,特征提取器包括帧间信息提取器和空间信息提取器,帧间信息提取器和空间信息提取器均使用三维卷积核,其中帧间信息占一个维度,空间信息占两个维度;帧间信息提取器的输入是初始融合模块的输出,空间信息提取器的输入是帧间信息提取器的输出;空间信息提取器的输出作为最大池化层的输入。
17.进一步,法向求解单元对最大池化层的输出先做卷积操作,然后做l2正则化,正则化输出的结果为法向图。
18.进一步,法向求解单元的最后一个卷积操作使用3通道。
19.进一步,图像识别网络的其他卷积操作使用128通道。
20.进一步,融合待测物体图像的空间信息和帧间信息的步骤包括:
21.建立信息融合模块的公式:
22.其中,il
input
表示公式的输入,il
input
包括每次拍摄任务获得的各张图像和光源强度、以及光源方向,f0表示公式的输出,con6×1×1表示一个尺寸为6
×1×
1的卷积核,con6×1×1(il
input
)表示对il
input
做卷积操作,σ表示leaky relu激活函数,σ(con6×1×1(il
input
)表示对con6×1×1(il
input
)做激活操作。表示dropout操作,表示对σ(con6×1×1(il
input
)做dropout操作。卷积操作、激活操作和dropout操作属于深度学习的常规函数或常规操作。
23.每张图像具有r、g、b三个通道,每张图像拍摄时的光源信息图需要x、y、z三个坐标值来表征,每个坐标方向的值存储在一个通道里;将每张图像的3通道信息和对应的光源信息图的3通道信息、这6个通道的信息通过一个6
×1×
1的卷积核进行操作,由此融合该张图像与对应光源信息,防止之后的操作将一一对应的关系打乱。
24.可选的,使用irfe(帧间信息提取器)进行帧间信息提取,
25.irfe由一个尺寸为5
×1×
1的卷积核,一个leaky relu激活函数和一个dropout层组成:
·
表示帧间信息提取器的输入,表示对输入进行i次卷积,卷积核的尺寸为5
×1×
1;表示对进行激活操作,表示对进行dropout操作。
26.进一步,使用irfe提取帧间信息提取的步骤为:
27.将irfe的初始输入
·
设置为f0,
[0028][0029]
其中,f0表示信息融合模块公式的输出;表示第一个帧间信息提取器的输出,irfe1(f0)表示第一个帧间信息提取器以f0作为输入;k为irfe的个数,表示第k个帧间信息提取器的输出,表示第k个帧间信息提取器以第k-1个帧间信息提取器的输出作为输入;
[0030]
优选的,k=3。
[0031]
进一步,使用iafe(空间信息提取器)进行空间信息提取,iafe由一个尺寸为1
×3×
3的卷积核,一个leaky relu激活函数组成:relu激活函数组成:其中,
·
表示空间信息提取器的输入,表示对输入做i次卷积、卷积核的尺寸为1
×3×
3,表示对进行激活。
[0032]
进一步,将iafe的初始输入设置为
[0033][0034][0035]
其中,表示第一个空间信息提取器的输出,表示第一个空间信息提取器的输入,表示第l个空间信息提取器的输出,表示以第l-1个空间信息提取器的输出作为作为第l个空间信息提取器的输入。
[0036]
优选的,l=3。
[0037]
进一步,以作为最大池化的输入,
[0038]
,mp表示最大池化max-pooling操作,f
max
表示最大池化的输出。这一步的操作提取不同通道之间最显著的信息,同时也为后面的操作固定了输入通道。
[0039]
进一步,以f
max
作为输入进行法向量求解:
[0040][0041]
其中,con1×1表示尺寸为1
×
1的卷积,con1×1(f
max
)表示对f
max
进行卷积操作,卷积
核的尺寸为1
×
1,σ表示leaky relu激活函数,表示l2正则化;
[0042]
以n
ij
表示像素坐标为(i,j)的点的法向量,以整个图像的所有像素的法向量形成的法向图表征待测物体的表面三维信息。
[0043]
本发明的有益效果:
[0044]
本发明将三维卷积引入光度立体领域,提出了mt-cnn-ps模型;该模型充分利用了输入图像序列的帧间信息与空间信息,具有较好的法向量恢复准确率;空间信息对于高光点,以及阴影区域具有很好的信息补偿作用,加入空间信息可以提高算法对于异常区域的鲁棒性;
[0045]
本发明在训练时加入了光源图像掩膜,用于减小无用点对于结果的干扰;提高了模型对于图像阴影部分的鲁棒性;本发明的模型在保留高运算速度的同时,相比于现有的光度立体方法具有较高的法向恢复准确率,具有较好的工业运用前景。
附图说明
[0046]
本发明可以通过附图给出的非限定性实施例进一步说明。
[0047]
图1是本发明基于三维卷积的非朗伯体表面光度立体模型的网络结构示意图。
[0048]
图2是本发明基于三维卷积的非朗伯体表面光度立体方法的流程示意图。
[0049]
图3是本发明实施例1~5的网络结构示意图。
[0050]
图4是本发明实施例6的网络结构示意图。
[0051]
图5是本发明实施例7的网络结构示意图。
[0052]
图6是本发明实施例8的网络结构示意图。
[0053]
图7是基于merl数据集渲染图像结果对比结果。
具体实施方式
[0054]
为了使本领域的技术人员可以更好地理解本发明,下面结合附图和实施例对本发明技术方案进一步说明。
[0055]
如图1所示,本发明公开了基于三维卷积的非朗伯体表面光度立体模型,包括信息融合层1、帧间特征提取层2、空间特征提取层3、最大池化层4和回归层5;
[0056]
信息融合层1用于融合每一张图像与其对应的光源信息,保证在后续处理中图像与光源的一一对应;
[0057]
帧间特征提取层2用于提取帧间信息,获取输入图像帧之间的信息,用于我们法向图的估计;
[0058]
空间特征提取层3提取单张图像内部的结构信息用于法向图的恢复;
[0059]
最大池化层4用于用于降维、去除冗余信息、对特征进行压缩、简化网络复杂度、减少计算量、减少内存消耗。
[0060]
信息融合层1包括一个三维卷积层c1,三维卷积层c1后跟有一个leakyrelu激活函数,其leakyrelu激活函数输出值dropout比率为0.2。
[0061]
帧间特征提取层2包括三个三维卷积层,其分别为三维卷积层c2、三维卷积层c3和三维卷积层c4,每个三维卷积层后跟有一个leakyrelu激活函数,每个leakyrelu激活函数输出值dropout比率为0.2。
[0062]
空间特征提取层3包括三个三维卷积层,其分别为三维卷积层c5、三维卷积层6和三维卷积层c7,每个三维卷积层后跟有一个leakyrelu激活函数。
[0063]
回归层5包括三个二维卷积层,其分别为二维卷积层c8、二维卷积层c9和二维卷积层c10,二维卷积层c8和二维卷积层c9后跟有一个leakyrelu激活函数,二维卷积层c10后跟有一个l2 normalization修正函数。
[0064]
在一些实施例中,一种数据处理系统,包括数据处理器、图形处理器和数据存储器,数据处理器从数据存储器中读取图像并输入图形处理器中,图形处理器中预设图像识别网络,图像识别网络为基于三维卷积的非朗伯体表面光度立体模型,如图1、2所示,图像识别网络包括图像输入、获得输入图像的有效特征的特征提取器、最大池化层和法向求解单元;图像输入至初始融合模块,初始融合模块使当前图像及其光照信息一一对应,初始融合模块输出的融合了光照信息的图像输入到特征提起器中,特征提取器包括帧间信息提取器和空间信息提取器,帧间信息提取器和空间信息提取器均使用三维卷积核,其中帧间信息占一个维度,空间信息占两个维度;帧间信息提取器的输入是初始融合模块的输出,空间信息提取器的输入是帧间信息提取器的输出;空间信息提取器的输出作为最大池化层的输入。
[0065]
在一些实施例中,法向求解单元对最大池化层的输出先做卷积操作,然后做l2正则化,正则化输出的结果为法向图。在一些实施例中,法向求解单元的最后一个卷积操作使用3通道。在一些实施例中,图像识别网络的其他卷积操作使用128通道。上述回归层作为法向量求解单元。
[0066]
如图1、2所示,在一些实施例中,提取待测物体图像中的空间信息和帧间信息,空间信息和帧间信息均以三维卷积分别表示,其中,三维卷积包括二维空间维度和一维帧间维度,空间信息的三维卷积中的一维帧间维度的值为设定值、二维空间维度为图像的空间信息值,帧间信息的三维卷积中的二维空间维度的值为设定值,一维帧间维度为帧间信息值;进行图像信息融合时,先处理帧间信息,再处理空间信息,再融合帧间信息和空间信息获得待测物体表面纹理的三维图像。
[0067]
在一些实施例中,融合待测物体图像的空间信息和帧间信息的步骤包括:
[0068]
建立信息融合模块的公式:
[0069]
其中,il
input
表示公式的输入,il
input
包括每次拍摄任务获得的各张图像和光源强度、以及光源方向,f0表示公式的输出,con6×1×1表示一个尺寸为6
×1×
1的卷积核,con6×1×1(il
input
)表示对il
input
做卷积操作,σ表示leaky relu激活函数,σ(con6×1×1(il
input
)表示对con6×1×1(il
input
)做激活操作。表示dropout操作,表示对σ(con6×1×1(il
input
)做dropout操作。卷积操作、激活操作和dropout操作属于深度学习的常规函数或常规操作。
[0070]
每张图像具有r、g、b三个通道,每张图像拍摄时的光源信息图需要x、y、z三个坐标值来表征,每个坐标方向的值存储在一个通道里;将每张图像的3通道信息和对应的光源信息图的3通道信息、这6个通道的信息通过一个6
×1×
1的卷积核进行操作,由此融合该张图像与对应光源信息,防止之后的操作将一一对应的关系打乱。
[0071]
在一些实施例中,使用irfe(帧间信息提取器)进行帧间信息提取,irfe由一个尺
寸为5
×1×
1的卷积核,一个leaky relu激活函数和一个dropout层组成:
·
表示帧间信息提取器的输入,表示对输入进行i次卷积,卷积核的尺寸为5
×1×
1;表示对进行激活操作,表示对进行dropout操作。
[0072]
在一些实施例中,使用irfe提取帧间信息提取的步骤为:
[0073]
将irfe的初始输入
·
设置为f0,
[0074][0075]
其中,f0表示信息融合模块公式的输出;表示第一个帧间信息提取器的输出,irfe1(f0)表示第一个帧间信息提取器以f0作为输入;k为irfe的个数,表示第k个帧间信息提取器的输出,表示第k个帧间信息提取器以第k-1个帧间信息提取器的输出作为输入。本实施例中,k=3。
[0076]
在一些实施例中,使用iafe(空间信息提取器)进行空间信息提取,iafe由一个尺寸为1
×3×
3的卷积核,一个leaky relu激活函数组成:其中,
·
表示空间信息提取器的输入,表示对输入做i次卷积、卷积核的尺寸为1
×3×
3,表示对进行激活。
[0077]
进一步,将iafe的初始输入设置为
[0078][0079]
其中,表示第一个空间信息提取器的输出,表示第一个空间信息提取器的输入,表示第l个空间信息提取器的输出,表示以第l-1个空间信息提取器的输出作为作为第l个空间信息提取器的输入。本实施例中,l=3。
[0080]
在一些实施例中,以作为最大池化的输入,
[0081]
,mp表示最大池化max-pooling操作,f
max
表示最大池化的输出。这一步的操作提取
不同通道之间最显著的信息,同时也为后面的操作固定了输入通道。
[0082]
进一步,以f
max
作为输入进行法向量求解:
[0083][0084]
其中,con1×1表示尺寸为1
×
1的卷积,con1×1(f
max
)表示对f
max
进行卷积操作,卷积核的尺寸为1
×
1,σ表示leaky relu激活函数,表示l2正则化;以n
ij
表示像素坐标为(i,j)的点的法向量,以整个图像的所有像素的法向量形成的法向图表征待测物体的表面三维信息。
[0085]
具体的实施例1~5,
[0086]
如图3所示,基于三维卷积的非朗伯体表面光度立体模型,包括信息融合层、帧间特征提取层、空间特征提取层、最大池化层和回归层;
[0087]
帧间特征提取层包括三个三维卷积层,其分别为三维卷积层c2、三维卷积层c3和三维卷积层c4,每个三维卷积层后跟有一个leakyrelu激活函数,每个leakyrelu激活函数输出值dropout比率为0.2,三维卷积层c2、三维卷积层c3和三维卷积层c4包括if个1*1的特征图;
[0088]
空间特征提取层包括三个三维卷积层,其分别为三维卷积层c5、三维卷积层6和三维卷积层c7,每个三维卷积层后跟有一个leakyrelu激活函数;三维卷积层c5、三维卷积层6和三维卷积层c7包括1个s*s的特征图;
[0089]
在图像处理过程中,先进行帧间特征提取层处理,再进行帧间特征提取层处理;
[0090]
其中,实施例1取:s=3,if=5;
[0091]
实施例2取:s=1,if=5;
[0092]
实施例3取:s=5,if=5;
[0093]
实施例4取:s=3,if=1;
[0094]
实施例5取:s=3,if=3;
[0095]
实施例6
[0096]
如图4所示,基于三维卷积的非朗伯体表面光度立体模型,包括信息融合层、帧间特征提取层、空间特征提取层、最大池化层和回归层;
[0097]
帧间特征提取层包括三个三维卷积层,其分别为三维卷积层c2、三维卷积层c3和三维卷积层c4,每个三维卷积层后跟有一个leakyrelu激活函数,每个leakyrelu激活函数输出值dropout比率为0.2,三维卷积层c2、三维卷积层c3和三维卷积层c4包括1个3*3的特征图;
[0098]
空间特征提取层包括三个三维卷积层,其分别为三维卷积层c5、三维卷积层6和三维卷积层c7,每个三维卷积层后跟有一个leakyrelu激活函数;三维卷积层c5、三维卷积层6和三维卷积层c7包括5个1*1的特征图;
[0099]
在图像处理过程中,先进行帧间特征提取层处理,再进行帧间特征提取层处理;
[0100]
实施例7
[0101]
如图5所示,基于三维卷积的非朗伯体表面光度立体模型,包括信息融合层、帧间特征提取层、空间特征提取层、最大池化层和回归层;
[0102]
帧间特征提取层包括三个三维卷积层,其分别为三维卷积层c2、三维卷积层c3和三维卷积层c4,每个三维卷积层后跟有一个leakyrelu激活函数,三维卷积层c2、三维卷积层c3和三维卷积层c4包括if个1*1的特征图;
[0103]
空间特征提取层包括三个三维卷积层,其分别为三维卷积层c5、三维卷积层6和三维卷积层c7,每个三维卷积层后跟有一个leakyrelu激活函数;三维卷积层c5、三维卷积层6和三维卷积层c7包括1个s*s的特征图;
[0104]
在图像处理过程中,先进行帧间特征提取层处理,再进行帧间特征提取层处理;
[0105]
其中,s=3,if=5;
[0106]
实施例8
[0107]
如图6所示,基于三维卷积的非朗伯体表面光度立体模型,包括信息融合层、特征提取层、最大池化层和回归层;
[0108]
特征提取层包括三个三维卷积层,其分别为三维卷积层c2、三维卷积层c3和三维卷积层c4,每个三维卷积层后跟有一个leakyrelu激活函数,每个leakyrelu激活函数输出值dropout比率为0.2,三维卷积层c2、三维卷积层c3和三维卷积层c4包括5个3*3的特征图;
[0109]
将实施例1~8卷积数据分析结果,针对不同形状的图像进行测试,其mae值如表1所示,
[0110][0111]
表1
[0112]
由表1可知,参考各个实施例的mae值,其实施例1的对于每一种图形下的效果相对较好;且相对稳定;
[0113]
按照实施例1的卷积层数据,建立mt-cnn-ps模型,将此模型与其它模型进行对比,针对不同形状的图像进行测试,其mae值如表2所示;
[0114][0115]
表2
[0116]
由表2可知,通过mt-cnn-ps模型处理的图像,对于不同形状下的效果每一明显的劣势,且在公开数据集diligent中熊、佛样本上上有明显的优势,因此其处理后的图像有较高的准确率。
[0117]
按照实施例1的卷积层数据,建立mt-cnn-ps模型,将此模型的光度立体方法与其它光度立体方法在输入图片数量较少时的平均误差对比(diligent十个物体平均误差),其mae值如表3所示,
[0118] 96161086本模型7.568.829.8410.7512.30ju-198.439.6610.0210.3912.16ch-188.399.3710.3311.1312.56si-187.2010.4914.3419.5030.28ik-1214.0815.4716.3716.8418.45baseline15.3916.6517.3117.4718.60
[0119]
表3
[0120]
·
表第一行代表输入的图像,第一列代表方法名称,中间数值代表平均角度误差。
[0121]
·
该表是本模型与目前先进的稀疏输入光度立体方法的横向对比,其中
[0122]
ju-19,ch-18,si-18都是基于深度学习的方法且ju-19,ch-18有特定的结构来针对稀疏输入的问题,甚于方法都是传统方法。可以看出我们的模型没有复杂的针对稀疏输入的结构,只是用了帧间空间提取器来提高信息利用率就能在16张和10张图片输入的时候有较好的效果。
[0123]
按照实施例1的卷积层数据,建立mt-cnn-ps模型,将此模型的光度立体方法与其它光度立体方法在输入图片数量较少时的平均误差对比(diligent十个物体具体误差),其mae值如表3所示,
[0124][0125]
表4
[0126]
由表3和表4可知,相对于其他的光度立体方法,mt-cnn-ps模型具有相对较好图像处理的稳定性。
[0127]
将实施例1的卷积层数据,建立mt-cnn-ps模型,将此模型光度立体方法处理后的图像,和ps-fcn模型立体方法处理后的图像,基于merl数据集渲染图像结果对比结果如图7所示,
[0128]
由图7可知,相对于ps-fcn来说,mt-cnn-ps模型具有相对较好图像处理的稳定性,并且其精确度更好。
[0129]
综上所述,本发明具有较好的法向量恢复准确率;空间信息对于高光点,以及阴影区域具有很好的信息补偿作用,加入空间信息可以提高算法对于异常区域的鲁棒性;本发明的模型在保留高运算速度的同时,相比于现有的光度立体方法具有较高的法向恢复准确率,具有较好的工业运用前景。
[0130]
上述实施例仅示例性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。