1.本发明属于语音分离领域,具体涉及一种基于复数门控循环单元的波束形成方法,主要是深度学习结合信号处理知识提升多通道说话人分离语音的信号失真比(sdr)、客观语音质量评估(pesq)、短时客观可懂度(stoi)等指标的技术,为语音识别等模块提供更干净的音频。
背景技术:
2.语音分离的目标是从混合音频中分离出每个说话人的音频,旨在使机器在复杂的声学环境下依然能够识别多个说话人声音内容的前端技术。在嘈杂的声学环境中,例如经典的鸡尾酒会场景,人们能够精准地关注并理解某些说话人的语音内容,而忽略场景噪音、混响和其他说话人的声音。对机器而言,语音分离便是实现复杂场景下与人自然交互的前提。早期的研究大多从听觉场景和信号处理的角度出发,例如波束形成、听觉场景分析等,涉及到复杂的信号处理算法和流程。近些年来,随着深度学习的发展,神经网络架构代替了一些传统的信号处理方法,语音分离技术得到了飞速发展。在多通道领域,使用深度学习结合信号处理的方法得到了广泛的研究
1.,尤其是波束形成在深度学习领域的应用,例如最小方差无失真响应(minimum variance distortionless response,mvdr),极大的提升了多通道多说话人语音分离的性能。
3.而在深度学习领域使用波束形成,仍然需要很多数学操作,例如在计算波束形成的加权系数的时候需要对功率谱密度矩阵求逆,这种求逆操作常常会导致数值不稳定
2.;除此之外,mvdr方法滤波后虽然会减少失真,但仍存在较高的干扰残留。一般来讲,mvdr常常在语句级别进行操作,这种粗糙的操作往往忽略了帧与帧之间的相关性信息,不是最佳选择。帧级别的波束形成,在每个帧上分别计算波束形成的加权系数,而非用一个系数完成整条语音的波束,能够实现逐帧分离,其性能优于传统的mvdr方法。最近,有学者在多模态领域,将音频和视频特征结合,使用基于门控循环单元的波束形成方法,提升了视频中目标说话人提取的性能
[3,4]
。本发明认为,基于门控循环单元的波束形成方法具有广泛的应用前景,可以应用到多通道多说话人语音分离场景。所不足的是,基于门控循环单元的波束形成的输入是实部和虚部拼接的特征,简单的拼接不利于特征的充分利用。
技术实现要素:
[0004]
本发明的目的是为了克服现有技术中的不足,针对多通道多说话人语音分离中数值不稳定、干扰残留严重以及复数特征利用不充分的问题,提供一种基于复数门控循环单元的波束形成方法,旨在通过改善波束形成加权系数的预测方式提升混响条件下多通道多说话人语音分离的整体性能,并力求发掘本身的特性促进语音分离领域的发展。
[0005]
本发明的目的是通过以下技术方案实现的:
[0006]
一种基于复数门控循环单元的波束形成方法,包括以下步骤:
[0007]
(1)进行复数掩蔽预测;混合音频经过短时傅里叶变换,转为复数混合音频特征,
利用复数混合音频特征的实部和虚部计算对数功率谱,复数混合音频特征和对数功率谱的最小单位为时频单元,也称为帧;将对数功率谱输入到双向长短时记忆网络预测复数掩蔽
[5]
,由于混合音频由若干名说话人的音频组成,为了提取每个说话人的音频,预测的复数掩蔽数量和说话人的个数对应;
[0008]
(2)将复数掩蔽和复数混合音频特征做元素乘积得到说话人复数音频特征,将所述说话人复数音频特征与自身的共轭转置做矩阵乘,标准化后沿着时间维度求和得到复数功率谱密度矩阵;元素乘积时,考虑深度滤波
[6]
:计算得到的说话人复数音频特征的当前帧,数值上等于复数混合音频特征当前帧以及前后若干帧与复数掩蔽乘积的求和,实现多以一映射;
[0009]
(3)复数功率谱密度矩阵有若干个,分别与每个说话人的音频对应;为了分离出其中一名说话人的音频,将其中一说话人的音频对应的复数功率谱密度矩阵视作目标,即为语音功率谱密度矩阵;其余所有说话人的音频对应的复数功率谱密度矩阵求和后视作干扰功率谱密度矩阵;将语音功率谱密度矩阵和干扰功率谱密度矩阵的实部与实部拼接,虚部与虚部拼接,得到复数矩阵特征;
[0010]
(4)构建复数门控循环单元网络,将拼接好的复数矩阵特征输入到复数门控循环单元网络中,充分利用复数网络的特点,预测波束形成的加权系数;波束形成的加权系数和复数混合音频特征做矩阵乘后,即可得到更精确的说话人复数音频特征,对说话人复数音频特征做逆傅里叶变换,得到分离的说话人的音频;基于复数门控循环单元的波束形成方法以尺度不变的信噪比作为损失函数。
[0011]
进一步的,步骤(2)中深度滤波的具体过程如下:复数混合音频特征的当前帧,在时间维度前后各取k个,频率维度前后各取l个,共计(2k 1)*(2l 1)帧,复数掩蔽同样的取用方式,(2k 1)*(2l 1)帧做完元素乘积后求和,即为说话人复数音频特征的当前帧。
[0012]
进一步的,复数门控循环单元网络的输入和输出皆是复数,拼接好的复数矩阵特征输入到复数门控循环单元网络后,充分交互复数矩阵特征的实部和虚部,输出的预测结果作为波束形成的加权系数。
[0013]
进一步的,一个加权系数实现一个说话人的音频分离,为了分离出每个说话人的音频,需要重复执行权力要求1中步骤(3)和步骤(4),预测波束形成的加权系数的数量等于说话人的个数。
[0014]
与现有技术相比,本发明的技术方案所带来的有益效果是:
[0015]
以往深度学习实现多通道多说话人语音分离的方法,大多是复数掩蔽结合语句级别最小方差无失真响应(mvdr)波束形成的方案,存在较多风险。本发明不仅使用深度滤波后的复数掩蔽,充分利用前后帧提升复数功率谱密度矩阵计算的精确度,而且利用门控循环单元,直接预测帧级别的波束形成加权系数,避免了复杂的数学计算,提升数值稳定性的同时,也抑制了mvdr方法产生的干扰残留;在构建网络时,使用了复数门控循环单元,相比单纯使用门控循环单元进行实数特征处理,交替预测复数波束形成加权系数的实部和虚部,性能又有了一些提升。
[0016]
此外本发明将深度学习和信号处理的知识运用在一起,为推动现有的多通道语音分离方案提供了一个新的思考角度。
附图说明
[0017]
图1是现有技术中基线方法的流程示意图;
[0018]
图2深度滤波的图表解释,图中l和k的取值都是1,表明在时间和频率维度上向前向后各取1帧;
[0019]
图3a是门控循环单元结构的示意图,图3b复数门控循环单元结构的示意图;
[0020]
图4是本发明的整体示意图,是实验的主要内容,这里省略了图1中的一些具体步骤,以整体模块展示;
[0021]
图5a和图5b分别是同一混合音频在通过传统基线方法和本发明方法解码得到的结果,二者选取的是较短的音频。
具体实施方式
[0022]
下面结合实验过程及实验结果对本发明做进一步描述和证明。本发明在目前多通道多说话人语音分离的通用方法的基础上,从分析掩蔽预测的提升空间和改进波束形成的精确度出发,将深度滤波技术运用到复数掩蔽中;使用复数门控循环神经单元代替最小方差无失真响应波束形成中的数学计算部分,使得整个方法的中间结果皆依赖于神经网络的非线性,避免大矩阵的求逆等复杂计算;同时复数门控循环神经单元使得特征处理时保持复数特性不变,直接预测帧级别波束形成的加权系数。具体技术方案要点分为以下三部分:
[0023]
(1)复数掩蔽预测网络
[0024]
在语音分离领域,最经典的方法之一是基于掩蔽的方法。无论是单通道还是多通道多说话人语音分离,亦或是时域和时频域解决方案,该方法都非常有效。本质上该方法是预测了一种滤波器,滤波器能从复数混合音频特征中过滤出目标音频特征。对单通道语音分离而言,得到掩蔽后直接进行对位元素的乘积即可得到分离后的音频:
[0025][0026]
其中t、f表示时间和频率,是分离后的说话人的音频,m(t,f)通常指掩蔽,
⊙
指对位元素乘法,x(t,f)是复数混合音频特征。对于复数掩蔽而言,掩蔽的数值类型是复数域。在多通道混合音频进行短时傅里叶变换后,进一步计算对数功率谱(lps),作为复数掩蔽预测网络的输入,对数功率谱的计算公式如下:
[0027]
lps=log(sqrt(real2 imag2))
ꢀꢀ
(2)
[0028]
其中real和imag便是短时傅里叶变换后复数混合音频特征的实部和虚部部分。该特征对单通道和多通道音频计算方法皆适用。多通道音频的特征多一个维度,其大小等于阵列麦克风的数量。为了符合网络输入形式,将通道维度和批维度叠加到一起,多通道对数功率谱特征维度便和单通道一致,网络可以直接预测复数掩蔽。
[0029]
整个复数掩蔽预测网络细节与图1展示的结构基本一致。使用双向长短时记忆网络(blstm)作为基本框架,依次串联三个blstm层和一个全连接层,以及relu激活函数层。全连接层将复数掩蔽的频率维度映射到257*2维,其中257为原始复数混合音频特征的频率维度大小,2便意味着掩蔽使用复数,将维度拆分并组合成复数张量,便得到了复数掩蔽。而基线方法中预测实数掩蔽,全连接层将实数掩蔽的频率维度映射到257维。复数掩蔽与输入的复数混合音频特征相乘以提取说话人的复数音频特征,以便进一步计算复数功率谱密度矩
阵。
[0030]
复数掩蔽实部和虚部是分别预测得到的。和复数域的音频相乘能直接得到说话人的复数音频特征,并且能各自反映两部分的数值特性。而实数域的掩蔽和复数的音频相乘时,本质上是做了数据广播,实数掩蔽分别和复数混合音频特征的实部和虚部相乘,容易导致失配等问题。因此复数掩蔽在近年来使用率极高,性能上也比实数掩蔽效果略好。
[0031]
进一步使用深度滤波进行多对一映射。映射方式如图2所示。利用复数掩蔽预测网络的全连接层,将复数掩蔽的频率维度映射为257*2*(2l 1)*(2k 1),并拆分为(257,2,2l 1,2k 1)。这么做可行的原因是,复数掩蔽没有物理含义,只有将其和对应的复数混合音频特征相乘,才有了滤波作用。因此要使深度滤波的方法奏效,仅需将复数混合音频特征扩展两个维度,大小分别为2l 1和2k 1,其中l和k分别是指当前帧的时间维度和频率维度分别向前和向后延申的长度。当l和k皆取1时,便是图2所示的映射方式。在计算完对位元素乘积后,沿着(2l 1)和(2k 1)的维度求和,得到说话人的复数音频特征的当前帧。
[0032]
(2)功率谱密度矩阵的计算
[0033]
在多通道语音分离领域,类似单通道的简单掩蔽滤波失真严重,为了提升音质,波束形成必不可少。功率谱密度矩阵的计算是为了波束形成加权系数的推导。在基线方法中,使用mvdr波束形成作为波束算法。下面简单介绍传统mvdr波束形成算法的流程。
[0034]
mvdr波束形成是基于最大信干噪比(sinr)准则的自适应波束形成算法。该算法可以自适应的使麦克风阵列输出在期望的方向上功率最小同时信干噪比最大,以抑制噪音和干扰。mvdr在军事领域有着比较广泛的应用,常被用于水声无线通信技术,可以实现水面舰艇和潜艇之间的通信等。mvdr算法采用了自适应波束形成中常用的采样矩阵求逆算法,该算法在信干噪比下具有较快的收敛速度。将多通道音频信号写成矩阵的形式为:
[0035]
x(n)=αs(n-τ) v(n)
ꢀꢀꢀꢀ
(3)
[0036]
其中x,α,s,τ和v分别表示阵列接收的音频、导向矢量、声源发出的音频、传播时延以及干扰,n为时间采样点。*表示卷积操作。对上式进行傅里叶变换,将时域信号转为时频域:
[0037]
x(t,f)=αs(t,f) v(t,f)
ꢀꢀ
(4)
[0038]
α为阵列的导向矢量,反应了麦克风阵列对方向的敏感程度,该矢量是有具体值的:
[0039][0040]
其中ω表示角频率,m表示麦克风个数,e为指数,j表示虚部。而其他元素的意义参考前述。将αs(t,f)使用一个参数表达。此时波束形成后的信号在时频域上可以表示为:
[0041][0042]
其中wi(f)为第i个麦克风在频率f下的加权系数,写成矩阵后即为w,h表示共轭转置,y(t,f)为增强后的单通道音频。而mvdr波束形成的关键则是计算信号的功率谱密度矩阵,输出信号的功率谱密度矩阵为:
[0043]
φ=e(yyh)=whe(xxh)w
ꢀꢀ
(7)
[0044]
其中y和x分别表示麦克风阵列的增强信号和原始输出信号。w表示加权系数,φ表示协方差矩阵,e通常指计算期望。
[0045]
对于频域的一个信号s(t,f),一般采用下式计算信号s(t,f)的功率谱密度矩阵,这里假设噪声和音频之间不相关:
[0046]
φ
ss
=e[s(t,f)s(t,f)]
ꢀꢀ
(8)
[0047]
故而对于接收音频、声源发出的音频和干扰,三者之间满足:
[0048]
φ
xx
=φ
ss
φ
vv
ꢀꢀ
(9)
[0049]
φ
xx
、φ
ss
和φ
vv
依次对应接收音频、声源发出的音频和干扰的功率谱密度矩阵。输入和输出音频的功率谱密度矩阵决定着信号的信干噪比。mvdr方法就是使得输出音频的功率最小,来获得最优加权系数的预测。而输出功率谱由上式决定,在最优化过程中要避免使得加权系数变为0,即保证信号在期望的方向上没有失真:
[0050]
whα=
ꢀꢀ
(10)
[0051]
在该约束条件下求解最优问题,即在上式的情况下,求式7中加权系数最小:
[0052]
minwwhφ
xx
w s.t.whα=1
ꢀꢀ
(11)
[0053]
这样,经过求解约束优化问题,可以得到mvdr波束形成的自适应加权系数为:
[0054][0055]
符号定义与前述一致。。从mvdr的加权系数表达式中可以看出,该系数可以根据干扰的功率谱密度矩阵的变化而变化,因而mvdr算法可以自适应的使麦克风阵列输出在期望方向上的sinr最大,达到最佳效果。当麦克风阵列中阵元数下降,或者高信噪比的环境下,期望信号和干扰往往存在明显的相干性,这在很大程度上影响了mvdr算法的性能。从公式12中可以看出,在进行波束形成时,需要对大矩阵求逆,这种方式本身非常不稳定,这也是本发明使用神经网络代替数学计算的原因。
[0056]
在深度学习联合mvdr的方法中,计算功率谱密度矩阵的公式与上述类似,以实数掩蔽为例,结合复数混合音频特征,语句级别的功率谱密度矩阵计算公式为:
[0057][0058]
其中分母部分是使用实数掩蔽作为标准化的方法,t为时间维度总长,其余符号定义与前述一致。而是指掩蔽和复数混合音频特征相乘后得到的说话人复数音频特征。使用语句级别的复数功率谱密度矩阵,计算得到的波束形成加权系数计算也是语句级别,直接使用比较粗造。另一方面,缺乏时间维度使得特征不适合输入到复数门控循环单元中,无法学习时序特征。因此在上式的基础上,计算帧级别的功率谱密度矩阵是有必要的。该计算公式相比式13,不需要在时间维度求和:
[0059][0060]
分别计算语音的功率谱密度矩阵和干扰的功率谱密度矩阵,最终输入到复数门控循环单元的特征是二者拼接得到的复数矩阵特征。
[0061]
(3)复数门控循环单元波束形成
[0062]
整个基线方法的训练流程如图1所示。图3b展示了复数门控循环单元的结构,主要由两个gru组成,分别为实部gru和虚部gru。单个gru结构如图3a所示,门控循环单元gru是长短时记忆网络lstm的一种变体,本身比lstm计算量小,效果也非常可观。可以解决循环神
经网络中的长依赖问题。不同于lstm中输入门,遗忘门和输出门三种门来控制输入,记忆和输出,gru只需要更新和重置两个门即可做到将重要的特征保留,且参数量要比lstm要少,训练速度快。
[0063]
对于复数网络,已经有实验证明,在增强领域,效果要略微优于实数网络结构。因此本发明构建复数门控循环单元网络。在整个复数网络中,使用两个门控循环单元,整个波束形成加权系数计算流程可以总结为下面几条公式:
[0064]rr
=grur(real)
[0065]
ir=grur(imag)
[0066]ri
=grui(real)
[0067]ii
=grui(imag)
[0068]
out
real
=r
t-ii[0069]
out
imag
=ir riꢀꢀꢀꢀ
(15)
[0070]
其中real和imag是复数矩阵特征的实部和虚部部分,grur为实部gru,grui为虚部gru,而rr、ir、ri和ii皆为网络中间产物,四者相互组合,最终得到预测的实部out
real
和虚部out
imag
,组成波束形成加权系数。激活函数选择prelu,这是一种改进的relu函数,对梯度的负数处理更加灵活。使用波束形成加权系数和复数混合音频特征进行矩阵乘法,得到精度更高的分离后的单通道音频特征,进行逆傅里叶变换后完成一次波束过程。波束形成时选择第一个通道为参考通道,因此计算尺度不变的信噪比(sisnr)时也选择标签的第一个通道。整个网络使用串行管道结构,复数掩蔽预测网络和复数门控循环单元波束形成同时训练,最终本发明的方法框架图如图4所示。
[0071]
本发明中使用的数据共28000条音频,其中训练集∶验证集∶测试集=20∶5∶3,混合音频使用代码模拟生成。模拟时提供单通道的干净音频,声源来自华尔街日报数据集wsj0。首先生成单通道的混合音频wsj0-2mix。该步骤不需要空间和阵列信息的参与,其模拟过程相对简单。之后采用基于图像法的房间脉冲响应发生器(rir)对wsj0-2mix数据集进行空间化,该方法在虚拟房间中设置麦克风阵列的坐标,两个说话人的坐标,以及图像法产生的混响的位置坐标等等。最后的数据集包含一个干净多通道数据集和一个带混响的多通道数据集,两者都是八通道两个说话人的混合音频,采样率为8khz。为了突出实验环境的复杂,本发明主要使用混响版本的数据。在混响条件下实现多通道两说话人语音分离。混响的存在会影响分离的性能,研究表明,无混响的场景要比有混响的场景性能好大约20%。干净的多通道音频数据主要用来做预实验,用于观察混响对多通道语音分离的影响程度。值得一提的是,在本次实验中不引入去混响方法如加权预测误差(weighted prediction errors,wpe)。除此之外,使用一些数据清洗工作,保证音频的长度皆在1秒以上。
[0072]
实验中由于验证集和训练集具有相同的说话人,因此验证集也被称作封闭集(closed condition,cc),表示说话人在解码时方法已知。测试集的说话人不同于训练集,又被称为开放集(open condition,oc),这意味着测试时说话人是未知的。测试封闭集和开放集下本发明的表现,开放集的解码结果作为主要观察对象。
[0073]
基线方法训练参数设置如表1。使用2块nvidia3090型号的gpu,完成方法的训练以及解码工作,每个gpu的显存为24gb。基线方法基于espnet,一个开源的语音工具,集成了语音领域的前沿技术方法,其中包括多通道语音分离的方案,即掩蔽和mvdr波束形成结合的
框架。本发明的最终方法也集成于espnet,通过对该工具最底层的代码改进,完成新方法的设计。
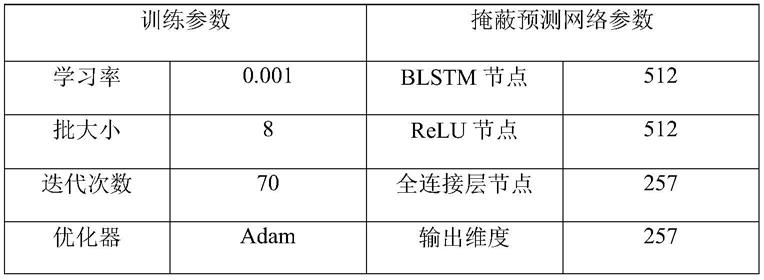
[0074]
表1基线方法的结构及训练参数
[0075][0076]
基线改进后即为本发明,由于网络更加复杂,因此需要的显存也急剧上升。本发明的参数如表2所示。训练参数上保持和基线方法的训练参数一致,而复数掩蔽预测网络中全连接层的维度相比基线方法有较大的变化,主要完成复数和映射操作。复数门控循环单元网络由实部gru单元和虚部gru单元组成,每个gru节点都设置为300。由于复数门控循环单元是时间敏感的,需要将复数矩阵特征做维度变换,将批维度和频率维度叠加,时间维度保持不变,剩余所有维度进行叠加后才可输入到复数门控循环单元中,对上述剩余所有维度叠加的新维度进行非线性操作。
[0077]
表2本发明方法的网络参数及训练参数
[0078][0079][0080]
首先是验证性实验,在图1基线方法下分别测试干净数据集和混响数据集分离后的性能,针对不同的数据集进行训练并解码打分,经过实验初步验证,在方法和参数一致的情况下,带混响的混合音频分离难度要远高于干净音频。如表3所示,在一些关键指标如pesq,stoi和sdr中,带混响的数据表现都远低于干净数据。结合实际生活场景,混响数据更具有研究价值和提升空间,真正干净的语音在真实环境下几乎不存在。
[0081]
表3基线方法下混响数据和干净数据的对比
[0082][0083]
在基线方法的基础上改进,使用混响数据训练本发明。实验结果如表4所示。实验结果表明,本发明使得带混响的混合音频的分离性能有较好的提升。三种评价指标相比基线均有提升,且无论是封闭集还是开放集。以开放集为例,pesq、stoi和sdr分别相对提升了32.08%、12.20%和31.54%,提升效果非常明显。为了进一步观察分离后的音频质量,挑选了同一混合音频在基线和本发明方法下分离的音频语谱图。原始混合音频由一个长音频和一个短音频组成,混合后的音频会出现末尾只有一人发声的情况,挑选了分离后的短音频进行观察。理论上,分离后的短音频在后半段应该全是静音段,事实上标签也是如此。观察图5a和图5b发现,基线方法得到的解码音频在后半段出现了不该出现的语谱信息,意味着分离不干净,出现了干扰残留,播放该音频也确实得到该结论。而在本发明解码的音频中,后半段声音抑制的非常好,几乎过滤掉所有长音频的声音,从听感上数据恢复的也更加清晰,这是符合预期的。
[0084]
表4基线方法和本发明在混响数据下的表现
[0085][0086]
参考文献:
[0087]
[1]r.gu,s.-x.zhang,and et al.,multi-modal multi-channel target speech separation,ieee journal of selected topics in signal processing,vol.14,no.3,pp.530
–
541,2020.
[0088]
[2]x.mestre and m.a.lagunas,on diagonal loading for minimum variance beamformers,in proceedings of the 3rd ieee international symposium on signal processing and information technology,2003,pp.459
–
462.
[0089]
[3]zhuohuang zhang,yong xu,meng yu,shi-xiong zhang,lianwu chen,dong yu,adl-mvdr:all deep learning mvdr beamformer for target speech separation,icassp,2020
[0090]
[4]yong xu,zhuohuang zhang,meng yu,shi-xiong zhang,lianwu chen,dong yu,g eneralized rnn beamformer for target speech separation,arxiv:2101.01280,2021
[0091]
[5]d.s.williamson,y.wang,and d.wang,complex ratio masking for monaural speech separation,ieee taslp,vol.24,no.3,pp.483
–
492,2015.
[0092]
[6]w.mack and e.a.habets,deep filtering:signal extraction and reconstruction using complex time-frequency filters,ieee signal processing letters,vol.27,pp.61
–
65,2019.
[0093]
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。