用于移动设备的具有嵌入式近-远立体声的masa
技术领域
1.本技术涉及用于移动设备的空间音频捕获和相关联渲染的装置和方法,但非排他地涉及用于沉浸式语音和音频服务(ivas)编解码器和用于移动设备的具有嵌入式近-远立体声的元数据辅助空间音频(masa)的装置和方法。
背景技术:
2.沉浸式音频编解码器正被实现,以支持范围从低比特率操作到透明的大量操作点。这种编解码器的示例是沉浸式语音和音频服务(ivas)编解码器,其被设计为适合于在诸如3gpp 4g/5g网络之类的通信网络上使用。这种沉浸式服务包括例如在诸如沉浸式通信、虚拟现实(vr)、增强现实(ar)和混合现实(mr)之类的应用的沉浸式语音和音频中使用。该音频编解码器被预期处理语音、音乐和通用音频的编码、解码和渲染。此外它还被预期支持基于通道的音频和基于场景的音频输入,包括关于声场和声源的空间信息。该编解码器还被预期以低延迟进行操作,以使能会话服务并在各种传输条件下支持高差错鲁棒性。
3.输入信号以所支持的多个格式之一(以及以一些所允许的格式组合)被呈现给ivas编码器。类似地,预期解码器可以以多个所支持的格式输出音频。
4.一些感兴趣的输入格式是元数据辅助空间音频(masa)、基于对象的音频,尤其是masa和至少一个对象的组合。元数据辅助空间音频(masa)是一种参数化空间音频格式和表示。它可以被认为是由“n个通道 空间元数据”组成的表示。它是一种基于场景的音频格式,特别适合于在诸如智能电话之类的实际设备上进行空间音频捕获。这个想法将依据时变和频变的声源方向来描述声音场景。如果没有检测到方向性声源,则音频被描述为扩散。空间元数据是相对于针对每个时频(tf)图块(tile)而指示的至少一个方向来描述的,并且例如可以包括针对每个方向的空间元数据和独立于方向数量的空间元数据。
技术实现要素:
5.根据第一方面,提供了一种装置,其包括被配置为执行以下操作的部件:接收至少一个通道语音音频信号和与至少一个通道语音音频信号相关联的元数据,该至少一个通道语音音频信号和元数据是从至少一个麦克风音频信号中生成的;接收至少一个通道环境音频信号和与至少一个通道环境音频信号相关联的元数据,其中,该至少一个通道环境音频信号和元数据是基于对至少一个麦克风音频信号的参数化分析而生成的,并且该至少一个通道环境音频信号与该至少一个通道语音音频信号相关联;以及基于该至少一个通道语音音频信号和元数据并进一步基于该至少一个通道环境音频信号和元数据,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于该至少一个通道环境音频信号地空间呈现该至少一个通道语音音频信号。
6.该部件可以进一步被配置为:接收至少一个其他音频对象音频信号,其中,被配置为生成编码多通道音频信号的部件被配置为:进一步基于该至少一个其他音频对象音频信号,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于至
少一个通道语音音频信号和至少一个通道环境音频信号地空间呈现该至少一个其他音频对象音频信号。
7.从其中生成至少一个通道语音音频信号和元数据的至少一个麦克风音频信号和从其中生成至少一个通道环境音频信号和元数据的至少一个麦克风音频信号可以包括:没有公共麦克风的单独的麦克风群组;或者具有至少一个公共麦克风的麦克风群组。
8.该部件可以进一步被配置为:接收输入,该输入被配置为控制编码多通道音频信号的生成。
9.该部件可以进一步被配置为:基于所确定的与至少一个通道语音音频信号相关联的元数据的位置参数与所分配的近通道渲染通道之间的失配,修改与该至少一个通道语音音频信号相关联的元数据的位置参数,或者改变与该至少一个通道语音音频信号相关联的近通道渲染通道分配。
10.被配置为基于至少一个通道语音音频信号和元数据并进一步基于至少一个通道环境音频信号和元数据来生成编码多通道音频信号的部件可以被配置为:获得编码器比特率;选择嵌入式编码级别,并向每个所选择的嵌入式编码级别分配比特率,其中,第一级别与该至少一个通道语音音频信号和元数据相关联,第二级别与该至少一个通道环境音频信号相关联,第三级别与该至少一个通道环境音频信号所关联的元数据相关联;基于所分配的比特率,对该至少一个通道语音音频信号和元数据、该至少一个通道环境音频信号和与该至少一个通道环境音频信号相关联的元数据进行编码。
11.该部件可以进一步被配置为:确定能力参数,该能力参数基于以下中的至少一个而被确定:传输通道能力;渲染装置能力,其中,被配置为生成编码多通道音频信号的部件可以被配置为:进一步基于该能力参数,生成编码多通道音频信号。
12.被配置为进一步基于能力参数来生成编码多通道音频信号的部件可以被配置为:基于传输通道能力和渲染装置能力中的至少一个,选择嵌入式编码级别,并向每个所选择的嵌入式编码级别分配比特率。
13.用于基于参数化分析来生成至少一个通道环境音频信号和元数据的至少一个麦克风音频信号可以包括至少两个麦克风音频信号。
14.该部件可以进一步被配置为:输出编码多通道音频信号。
15.根据第二方面,提供了一种装置,其包括被配置为执行以下操作的部件:接收嵌入式编码音频信号,该嵌入式编码音频信号包括以下级别的嵌入式音频信号中的至少一个:要被渲染为空间语音场景的至少一个通道语音音频信号和相关联的元数据;要被渲染为近-远立体声场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号;要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据;以及解码该嵌入式编码音频信号,并输出表示场景的多通道音频信号,以使得该编码多通道音频信号使得能够独立于至少一个通道环境音频信号地空间呈现至少一个通道语音音频信号。
16.上述级别的嵌入式音频信号可以进一步包括:要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据、以及至少一个其他音频对象音频信号和相关联的元数据,并且其中,被配置为解码嵌入式编码音频信号并输出表示场景的多通道音频信号的部件可以被配置为:解码并输出
多通道音频信号,以使得该至少一个其他音频对象音频信号的空间呈现在空间上独立于该至少一个通道语音音频信号和该至少一个通道环境音频信号。
17.该部件可以进一步被配置为:接收输入,该输入被配置为控制嵌入式编码音频信号的解码和多通道音频信号的输出。
18.该输入可以包括能力的切换,其中,被配置为解码嵌入式编码音频信号并输出多通道音频信号的部件可以被配置为:基于该能力的切换,更新该解码和输出。
19.该能力的切换可以包括以下中的至少一个:耳塞/耳机配置的确定;头戴式耳机配置的确定;以及扬声器输出配置的确定。
20.该输入可以包括嵌入式级别的改变的确定,其中,被配置为解码嵌入式编码音频信号并输出多通道音频信号的部件可以被配置为:基于该嵌入式级别的改变,更新该解码和输出。
21.该输入可以包括针对嵌入式级别的比特率的改变的确定,其中,被配置为解码嵌入式编码音频信号并输出多通道音频信号的部件可以被配置为:基于针对该嵌入式级别的比特率的改变,更新该解码和输出。
22.该部件可以被配置为:控制嵌入式编码音频信号的解码和多通道音频信号的输出,以基于所确定的至少一个语音音频信号检测位置和/或所分配的近通道渲染通道通道之间的失配,修改至少一个通道语音音频信号位置,或者改变与至少一个通道语音音频信号相关联的近通道渲染通道分配。
23.该输入可以包括至少一个通道语音音频信号与至少一个通道环境音频信号之间的相关性的确定,并且被配置为解码并输出多通道音频信号的部件被配置为:当该相关性小于所确定的阈值时:控制与该至少一个通道语音音频信号相关联的位置,以及通过以下操作来控制由该至少一个通道环境音频信号形成的环境空间场景:根据所获得的旋转参数,基于该至少一个通道环境音频信号来旋转该环境空间场景,或者通过对该环境空间场景应用对应的反向旋转来补偿另一设备的旋转;以及当该相关性大于或等于所确定的阈值时:控制与该至少一个通道语音音频信号相关联的位置,以及通过以下操作来控制由该至少一个通道环境音频信号形成的环境空间场景:通过对该环境空间场景应用对应的反向旋转来补偿另一设备的旋转,同时让该场景的其余部分旋转,或者根据所获得的旋转参数,基于该至少一个通道环境音频信号来旋转该环境空间场景。
24.根据第三方面,提供了一种方法,其包括:接收至少一个通道语音音频信号和与至少一个通道语音音频信号相关联的元数据,该至少一个通道语音音频信号和元数据是从至少一个麦克风音频信号中生成的;接收至少一个通道环境音频信号和与至少一个通道环境音频信号相关联的元数据,其中,该至少一个通道环境音频信号和元数据是基于对至少一个麦克风音频信号的参数化分析而生成的,并且该至少一个通道环境音频信号与该至少一个通道语音音频信号相关联;以及基于该至少一个通道语音音频信号和元数据并进一步基于该至少一个通道环境音频信号和元数据,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于该至少一个通道环境音频信号地空间呈现该至少一个通道语音音频信号。
25.该方法可以进一步包括:接收至少一个其他音频对象音频信号,其中,生成编码多通道音频信号包括:进一步基于该至少一个其他音频对象音频信号,生成编码多通道音频
信号,使得能够在空间上独立于至少一个通道语音音频信号和至少一个通道环境音频信号地空间呈现该至少一个其他音频对象音频信号。
26.从其中生成至少一个通道语音音频信号和元数据的至少一个麦克风音频信号和从其中生成至少一个通道环境音频信号和元数据的至少一个麦克风音频信号可以包括:没有公共麦克风的单独的麦克风群组;或者具有至少一个公共麦克风的麦克风群组。
27.该方法可以进一步包括:接收输入,该输入被配置为控制编码多通道音频信号的生成。
28.该方法可以进一步包括:基于所确定的与至少一个通道语音音频信号相关联的元数据的位置参数与所分配的近通道渲染通道之间的失配,修改与该至少一个通道语音音频信号相关联的元数据的位置参数,或者改变与该至少一个通道语音音频信号相关联的近通道渲染通道分配。
29.基于至少一个通道语音音频信号和元数据并进一步基于至少一个通道环境音频信号和元数据来生成编码多通道音频信号可以包括:获得编码器比特率;选择嵌入式编码级别,并向每个所选择的嵌入式编码级别分配比特率,其中,第一级别与该至少一个通道语音音频信号和元数据相关联,第二级别与该至少一个通道环境音频信号相关联,第三级别与该至少一个通道环境音频信号所关联的元数据相关联;基于所分配的比特率,对该至少一个通道语音音频信号和元数据、该至少一个通道环境音频信号和与该至少一个通道环境音频信号相关联的元数据进行编码。
30.该方法可以进一步包括:确定能力参数,该能力参数基于以下中的至少一个而被确定:传输通道能力;渲染装置能力,其中,生成编码多通道音频信号可以包括:进一步基于该能力参数,生成编码多通道音频信号。
31.进一步基于能力参数来生成编码多通道音频信号可以包括:基于传输通道能力和渲染装置能力中的至少一个,选择嵌入式编码级别,并向每个所选择的嵌入式编码级别分配比特率。
32.用于基于参数化分析来生成至少一个通道环境音频信号和元数据的至少一个麦克风音频信号可以包括至少两个麦克风音频信号。
33.该方法可以进一步包括:输出编码多通道音频信号。
34.根据第四方面,提供了一种方法,其包括:接收嵌入式编码音频信号,该嵌入式编码音频信号包括以下级别的嵌入式音频信号中的至少一个:要被渲染为空间语音场景的至少一个通道语音音频信号和相关联的元数据;要被渲染为近-远立体声场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号;要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据;以及解码该嵌入式编码音频信号,并输出表示场景的多通道音频信号,以使得该编码多通道音频信号使得能够独立于至少一个通道环境音频信号地空间呈现至少一个通道语音音频信号。
35.上述级别的嵌入式音频信号可以进一步包括:要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据、以及至少一个其他音频对象音频信号和相关联的元数据,并且其中,解码嵌入式编码音频信号并输出表示场景的多通道音频信号可以包括:解码并输出多通道音频信号,以
使得该至少一个其他音频对象音频信号的空间呈现在空间上独立于该至少一个通道语音音频信号和该至少一个通道环境音频信号。
36.该方法可以进一步包括:接收输入,该输入被配置为解码嵌入式编码音频信号的控制和多通道音频信号的输出。
37.该输入可以包括能力的切换,其中,解码嵌入式编码音频信号并输出多通道音频信号可以包括:基于该能力的切换,更新该解码和输出。
38.该能力的切换可以包括以下中的至少一个:耳塞/耳机配置的确定;头戴式耳机配置的确定;以及扬声器输出配置的确定。
39.该输入可以包括嵌入式级别的改变的确定,其中,解码嵌入式编码音频信号并输出多通道音频信号可以包括:基于该嵌入式级别的改变,更新该解码和输出。
40.该输入可以包括针对嵌入式级别的比特率的改变的确定,其中,解码嵌入式编码音频信号并输出多通道音频信号可以包括:基于针对该嵌入式级别的比特率的改变,更新该解码和输出。
41.该方法可以包括:控制嵌入式编码音频信号的解码和多通道音频信号的输出,以基于所确定的至少一个语音音频信号检测位置和/或所分配的近通道渲染通道通道之间的失配,修改至少一个通道语音音频信号位置,或者改变与至少一个通道语音音频信号相关联的近通道渲染通道分配。
42.该输入可以包括至少一个通道语音音频信号与至少一个通道环境音频信号之间的相关性的确定,并且解码并输出多通道音频信号可以包括:当该相关性小于所确定的阈值时:控制与该至少一个通道语音音频信号相关联的位置,以及通过以下操作来控制由该至少一个通道环境音频信号形成的环境空间场景:根据所获得的旋转参数,基于该至少一个通道环境音频信号来旋转该环境空间场景,或者通过对该环境空间场景应用对应的反向旋转来补偿另一设备的旋转;以及当该相关性大于或等于所确定的阈值时:控制与该至少一个通道语音音频信号相关联的位置,以及通过以下操作来控制由该至少一个通道环境音频信号形成的环境空间场景:通过对该环境空间场景应用对应的反向旋转来补偿另一设备的旋转,同时让该场景的其余部分旋转,或者根据所获得的旋转参数,基于该至少一个通道环境音频信号来旋转该环境空间场景。
43.根据第五方面,提供了一种装置,其包括至少一个处理器和包括计算机程序代码的至少一个存储器,该至少一个存储器和计算机程序代码被配置为与至少一个处理器一起使该装置至少:接收至少一个通道语音音频信号和与至少一个通道语音音频信号相关联的元数据,该至少一个通道语音音频信号和元数据是从至少一个麦克风音频信号中生成的;接收至少一个通道环境音频信号和与至少一个通道环境音频信号相关联的元数据,其中,该至少一个通道环境音频信号和元数据是基于对至少一个麦克风音频信号的参数化分析而生成的,并且该至少一个通道环境音频信号与该至少一个通道语音音频信号相关联;以及基于该至少一个通道语音音频信号和元数据并进一步基于该至少一个通道环境音频信号和元数据,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于该至少一个通道环境音频信号地空间呈现该至少一个通道语音音频信号。
44.该装置可以进一步被使得:接收至少一个其他音频对象音频信号,其中,被使得生成编码多通道音频信号的该装置被使得:进一步基于该至少一个其他音频对象音频信号,
生成编码多通道音频信号,使得能够在空间上独立于至少一个通道语音音频信号和至少一个通道环境音频信号地空间呈现该至少一个其他音频对象音频信号。
45.从其中生成至少一个通道语音音频信号和元数据的至少一个麦克风音频信号和从其中生成至少一个通道环境音频信号和元数据的至少一个麦克风音频信号可以包括:没有公共麦克风的单独的麦克风群组;或者具有至少一个公共麦克风的麦克风群组。
46.该装置可以进一步被使得:接收输入,该输入被配置为控制编码多通道音频信号的生成。
47.该装置可以进一步被使得:基于所确定的与至少一个通道语音音频信号相关联的元数据的位置参数与所分配的近通道渲染通道之间的失配,修改与该至少一个通道语音音频信号相关联的元数据的位置参数,或者改变与该至少一个通道语音音频信号相关联的近通道渲染通道分配。
48.被使得基于至少一个通道语音音频信号和元数据并进一步基于至少一个通道环境音频信号和元数据来生成编码多通道音频信号的该装置可以被使得:获得编码器比特率;选择嵌入式编码级别,并向每个所选择的嵌入式编码级别分配比特率,其中,第一级别与该至少一个通道语音音频信号和元数据相关联,第二级别与该至少一个通道环境音频信号相关联,第三级别与该至少一个通道环境音频信号所关联的元数据相关联;基于所分配的比特率,对该至少一个通道语音音频信号和元数据、该至少一个通道环境音频信号和与该至少一个通道环境音频信号相关联的元数据进行编码。
49.该装置可以进一步被使得:确定能力参数,该能力参数基于以下中的至少一个而被确定:传输通道能力;渲染装置能力,其中,被使得生成编码多通道音频信号的该装置可以被使得:进一步基于该能力参数,生成编码多通道音频信号。
50.被使得进一步基于能力参数来生成编码多通道音频信号的该装置可以被使得:基于传输通道能力和渲染装置能力中的至少一个,选择嵌入式编码级别,并向每个所选择的嵌入式编码级别分配比特率。
51.用于基于参数化分析来生成至少一个通道环境音频信号和元数据的至少一个麦克风音频信号可以包括至少两个麦克风音频信号。
52.该装置可以进一步被使得:输出编码多通道音频信号。
53.根据第六方面,提供了一种装置,其包括至少一个处理器和包括计算机程序代码的至少一个存储器,该至少一个存储器和计算机程序代码被配置为与至少一个处理器一起使该装置至少:接收嵌入式编码音频信号,该嵌入式编码音频信号包括以下级别的嵌入式音频信号中的至少一个:要被渲染为空间语音场景的至少一个通道语音音频信号和相关联的元数据;要被渲染为近-远立体声场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号;要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据;以及解码该嵌入式编码音频信号,并输出表示场景的多通道音频信号,以使得该编码多通道音频信号使得能够独立于至少一个通道环境音频信号地空间呈现至少一个通道语音音频信号。
54.上述级别的嵌入式音频信号可以进一步包括:要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据、以及至少一个其他音频对象音频信号和相关联的元数据,并且其中,被使得解码嵌
入式编码音频信号并输出表示场景的多通道音频信号的该装置可以被使得:解码并输出多通道音频信号,以使得该至少一个其他音频对象音频信号的空间呈现在空间上独立于该至少一个通道语音音频信号和该至少一个通道环境音频信号。
55.该装置可以进一步被使得:接收输入,该输入被配置为控制嵌入式编码音频信号的解码和多通道音频信号的输出。
56.该输入可以包括能力的切换,其中,被使得解码嵌入式编码音频信号并输出多通道音频信号的该装置可以被使得:基于该能力的切换,更新该解码和输出。
57.该能力的切换可以包括以下中的至少一个:耳塞/耳机配置的确定;头戴式耳机配置的确定;以及扬声器输出配置的确定。
58.该输入可以包括嵌入式级别的改变的确定,其中,被使得解码嵌入式编码音频信号并输出多通道音频信号的该装置可以被使得:基于该嵌入式级别的改变,更新该解码和输出。
59.该输入可以包括针对嵌入式级别的比特率的改变的确定,其中,被使得解码嵌入式编码音频信号并输出多通道音频信号的该装置可以被使得:基于针对该嵌入式级别的比特率的改变,更新该解码和输出。
60.该装置可以被使得:控制嵌入式编码音频信号的解码和多通道音频信号的输出,以基于所确定的至少一个语音音频信号检测位置和/或所分配的近通道渲染通道通道之间的失配,修改至少一个通道语音音频信号位置,或者改变与至少一个通道语音音频信号相关联的近通道渲染通道分配。
61.该输入可以包括至少一个通道语音音频信号与至少一个通道环境音频信号之间的相关性的确定,并且被使得解码并输出多通道音频信号的该装置可以被使得:当该相关性小于所确定的阈值时:控制与该至少一个通道语音音频信号相关联的位置,以及通过以下操作来控制由该至少一个通道环境音频信号形成的环境空间场景:根据所获得的旋转参数,基于该至少一个通道环境音频信号来旋转该环境空间场景,或者通过对该环境空间场景应用对应的反向旋转来补偿另一设备的旋转;以及当该相关性大于或等于所确定的阈值时:控制与该至少一个通道语音音频信号相关联的位置,以及通过以下操作来控制由该至少一个通道环境音频信号形成的环境空间场景:通过对该环境空间场景应用对应的反向旋转来补偿另一设备的旋转,同时让该场景的其余部分旋转,或者根据所获得的旋转参数,基于该至少一个通道环境音频信号来旋转该环境空间场景。
62.根据第七方面,提供了一种装置,其包括:接收电路,被配置为接收至少一个通道语音音频信号和与至少一个通道语音音频信号相关联的元数据,该至少一个通道语音音频信号和元数据是从至少一个麦克风音频信号中生成的;接收电路,被配置为接收至少一个通道环境音频信号和与至少一个通道环境音频信号相关联的元数据,其中,该至少一个通道环境音频信号和元数据是基于对至少一个麦克风音频信号的参数化分析而生成的,并且该至少一个通道环境音频信号与该至少一个通道语音音频信号相关联;以及编码电路,被配置为基于该至少一个通道语音音频信号和元数据并进一步基于该至少一个通道环境音频信号和元数据,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于该至少一个通道环境音频信号地空间呈现该至少一个通道语音音频信号。
63.根据第八方面,提供了一种装置,其包括:接收电路,被配置为接收嵌入式编码音
频信号,该嵌入式编码音频信号包括以下级别的嵌入式音频信号中的至少一个:要被渲染为空间语音场景的至少一个通道语音音频信号和相关联的元数据;要被渲染为近-远立体声场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号;要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据;以及解码电路,被配置为解码该嵌入式编码音频信号,并输出表示场景的多通道音频信号,以使得该编码多通道音频信号使得能够独立于至少一个通道环境音频信号地空间呈现至少一个通道语音音频信号。
64.根据第九方面,提供了一种包括指令的计算机程序(或包括程序指令的计算机可读介质),这些指令(或程序指令)用于使装置至少执行以下操作:接收至少一个通道语音音频信号和与至少一个通道语音音频信号相关联的元数据,该至少一个通道语音音频信号和元数据是从至少一个麦克风音频信号中生成的;接收至少一个通道环境音频信号和与至少一个通道环境音频信号相关联的元数据,其中,该至少一个通道环境音频信号和元数据是基于对至少一个麦克风音频信号的参数化分析而生成的,并且该至少一个通道环境音频信号与该至少一个通道语音音频信号相关联;以及基于该至少一个通道语音音频信号和元数据并进一步基于该至少一个通道环境音频信号和元数据,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于该至少一个通道环境音频信号地空间呈现该至少一个通道语音音频信号。
65.根据第十方面,提供了一种包括指令的计算机程序(或包括程序指令的计算机可读介质),这些指令(或程序指令)用于使装置至少执行以下操作:接收嵌入式编码音频信号,该嵌入式编码音频信号包括以下级别的嵌入式音频信号中的至少一个:要被渲染为空间语音场景的至少一个通道语音音频信号和相关联的元数据;要被渲染为近-远立体声场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号;要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据;以及解码该嵌入式编码音频信号,并输出表示场景的多通道音频信号,以使得该编码多通道音频信号使得能够独立于至少一个通道环境音频信号地空间呈现至少一个通道语音音频信号。
66.根据第十一方面,提供了一种包括程序指令的非暂时性计算机可读介质,这些程序指令用于使装置至少执行以下操作:接收至少一个通道语音音频信号和与至少一个通道语音音频信号相关联的元数据,该至少一个通道语音音频信号和元数据是从至少一个麦克风音频信号中生成的;接收至少一个通道环境音频信号和与至少一个通道环境音频信号相关联的元数据,其中,该至少一个通道环境音频信号和元数据是基于对至少一个麦克风音频信号的参数化分析而生成的,并且该至少一个通道环境音频信号与该至少一个通道语音音频信号相关联;以及基于该至少一个通道语音音频信号和元数据并进一步基于该至少一个通道环境音频信号和元数据,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于该至少一个通道环境音频信号地空间呈现该至少一个通道语音音频信号。
67.根据第十二方面,提供了一种包括程序指令的非暂时性计算机可读介质,这些程序指令用于使装置至少执行以下操作:接收嵌入式编码音频信号,该嵌入式编码音频信号包括以下级别的嵌入式音频信号中的至少一个:要被渲染为空间语音场景的至少一个通道
语音音频信号和相关联的元数据;要被渲染为近-远立体声场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号;要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据;以及解码该嵌入式编码音频信号,并输出表示场景的多通道音频信号,以使得该编码多通道音频信号使得能够独立于至少一个通道环境音频信号地空间呈现至少一个通道语音音频信号。
68.根据第十三方面,提供了一种装置,其包括:用于接收至少一个通道语音音频信号和与至少一个通道语音音频信号相关联的元数据的部件,其中,该至少一个通道语音音频信号和元数据是从至少一个麦克风音频信号中生成的;用于接收至少一个通道环境音频信号和与至少一个通道环境音频信号相关联的元数据的部件,其中,该至少一个通道环境音频信号和元数据是基于对至少一个麦克风音频信号的参数化分析而生成的,并且该至少一个通道环境音频信号与该至少一个通道语音音频信号相关联;以及用于基于该至少一个通道语音音频信号和元数据并进一步基于该至少一个通道环境音频信号和元数据,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于该至少一个通道环境音频信号地空间呈现该至少一个通道语音音频信号的部件。
69.根据第十四方面,提供了一种装置,其包括:用于接收嵌入式编码音频信号的部件,其中,该嵌入式编码音频信号包括以下级别的嵌入式音频信号中的至少一个:要被渲染为空间语音场景的至少一个通道语音音频信号和相关联的元数据;要被渲染为近-远立体声场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号;要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据;以及用于解码该嵌入式编码音频信号,并输出表示场景的多通道音频信号,以使得该编码多通道音频信号使得能够独立于至少一个通道环境音频信号地空间呈现至少一个通道语音音频信号的部件。
70.根据第十五方面,提供了一种包括程序指令的计算机可读介质,这些程序指令使装置至少执行以下操作:接收至少一个通道语音音频信号和与至少一个通道语音音频信号相关联的元数据,该至少一个通道语音音频信号和元数据是从至少一个麦克风音频信号中生成的;接收至少一个通道环境音频信号和与至少一个通道环境音频信号相关联的元数据,其中,该至少一个通道环境音频信号和元数据是基于对至少一个麦克风音频信号的参数化分析而生成的,并且该至少一个通道环境音频信号与该至少一个通道语音音频信号相关联;以及基于该至少一个通道语音音频信号和元数据并进一步基于该至少一个通道环境音频信号和元数据,生成编码多通道音频信号,以使得该编码多通道音频信号使得能够在空间上独立于该至少一个通道环境音频信号地空间呈现该至少一个通道语音音频信号。
71.根据第十六方面,提供了一种包括程序指令的计算机可读介质,这些程序指令使装置至少执行以下操作:接收嵌入式编码音频信号,该嵌入式编码音频信号包括以下级别的嵌入式音频信号中的至少一个:要被渲染为空间语音场景的至少一个通道语音音频信号和相关联的元数据;要被渲染为近-远立体声场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号;要被渲染为空间音频场景的至少一个通道语音音频信号和相关联的元数据以及至少一个通道环境音频信号和相关联的空间元数据;以及解码该嵌入式编码音频信号,并输出表示场景的多通道音频信号,以使得该编码多通道音
频信号使得能够独立于至少一个通道环境音频信号地空间呈现至少一个通道语音音频信号。
72.一种装置,包括用于执行如上所述的方法的动作的部件。
73.一种装置,被配置为执行如上所述的方法的动作。
74.一种计算机程序,包括用于使计算机执行如上所述的方法的程序指令。
75.一种被存储在介质上的计算机程序产品可以使装置执行本文所述的方法。
76.一种电子设备可以包括如本文所述的装置。
77.一种芯片组可以包括如本文所述的装置。
78.本技术的实施例旨在解决与现有技术相关联的问题。
附图说明
79.为了更好地理解本技术,现在将通过示例的方式参考附图,其中:
80.图1和图2示意性地示出当使用移动设备时可能遇到的典型音频捕获场景;
81.图3a示意性地示出示例编码器和解码器架构;
82.图3b和图3c示意性地示出适于在一些实施例中使用的示例输入设备;
83.图4示意性地示出适于接收图3c的输出的示例解码器/渲染器装置;
84.图5示意性地示出根据一些实施例的示例编码器和解码器架构;
85.图6示意性地示出根据一些实施例的示例输入格式;
86.图7示意性地示出根据一些实施例的具有三层的示例嵌入方案;
87.图8a和图8b示意性地示出适于实现一些实施例的示例输入生成器、编解码器生成器、编码器、解码器和输出设备架构;
88.图9示出根据一些实施例的嵌入式格式编码的流程图;
89.图10更详细地示出根据一些实施例的嵌入式格式编码和级别选择以及波形和元数据编码的流程图;
90.图11a至图11d示出根据一些实施例的示例渲染/呈现装置;
91.图12示出根据一些实施例的用于立体声头戴式耳机输出的语音对象和masa环境音频的示例沉浸式渲染;
92.图13示出根据一些实施例的在实现示例近-远表示的比特切换(其中,嵌入式级别下降)的情况下渲染的示例改变;
93.图14示出在单声道与立体声能力之间切换的示例;
94.图15示出根据一些实施例的包括呈现能力切换的渲染控制方法的流程图;
95.图16示出根据一些实施例的在针对立体声输出的从沉浸式模式到嵌入式格式模式的改变期间的渲染控制的示例;
96.图17示出根据一些实施例的在由能力改变引起的嵌入式格式模式发生改变期间的渲染控制的示例;
97.图18示出根据一些实施例的在由从单声道到立体声的能力改变引起的嵌入式格式模式发生改变期间的渲染控制的示例;
98.图19示出根据一些实施例的从单声道到沉浸式模式的嵌入式格式模式改变期间的渲染控制的示例;
99.图20示出根据一些实施例的在基于更高空间维度音频中的用户交互来适配较低空间维度音频期间的渲染控制的示例;
100.图21示出在一些实施例中使用的方法所允许的用户体验的示例;
101.图22示出当在实现一些实施例时接听电话时的近-远立体声通道偏好选择的示例;
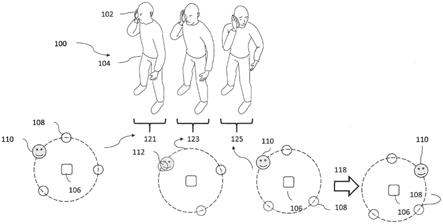
102.图23示出适于实现所示装置的示例设备。
具体实施方式
103.下面更详细地描述了用于空间语音和音频环境输入格式定义以及用于ivas的编码框架的合适装置和可能机制。在这种实施例中,可以提供用于立体声和单声道表示的向后兼容的传送和播放,其具有用于对应呈现的嵌入式结构和能力。在一些实施例中,呈现能力切换使得解码器/渲染器能够例如以不对应于发射机偏好的方式在最佳通道中分配语音,而无需在呈现设备中进行盲下混合。此外,输入格式定义和编码框架可以特别适于实际的移动设备空间音频捕获(例如,更好地允许ue贴耳沉浸式捕获(ue-on-ear immersive capture))。
104.关于以下被配置为定义具有单独的语音和空间音频的输入格式和元数据信令的实施例来描述概念。在这种实施例中,完整的音频场景在(至少)两个所捕获的流中被提供给合适的编码器。第一流是基于至少一个麦克风捕获的单声道语音对象,第二流是基于对来自至少三个麦克风的信号的参数化分析的参数化空间环境信号。在一些实施例中,可选地,可以提供附加声源的音频对象。元数据信令可以至少包括用于语音对象流的语音优先级指示符(以及可选地,其空间位置)。第一流可以至少主要与靠近用户的嘴部(近通道)的用户语音和音频内容有关,而第二流可以至少主要与远离用户的嘴部(远通道)的音频内容有关。
105.在一些实施例中,生成输入格式以便促进相关和/或不相关信号的定向补偿。例如,对于不相关的第一和第二信号,可以独立地处理这些信号,而对于相关的第一和第二信号,可以根据语音对象位置来修改参数化空间音频(masa)元数据。
106.在一些实施例中,可以根据所定义的输入格式来提供空间语音和音频编码。该编码可以被配置为允许语音和空间环境的分离,其中,在波形和元数据编码之前,语音对象位置被修改(如果需要),或者其中,基于语音对象真实位置的活动部分与所分配的通道之间的失配来应用对近通道渲染通道分配的更新。
107.在一些实施例中,可基于改变(所发送的信号的)浸入级别和呈现设备能力来提供渲染控制和呈现。例如,在一些实施例中,根据传送给解码器/渲染器的所切换的能力来修改音频信号渲染特性。在一些实施例中,可以根据通过传输接收的嵌入式级别的改变来修改音频信号渲染特性和通道分配。此外,在一些实施例中,可以根据渲染特性和对一个或多个输出通道的通道分配来渲染音频信号。换句话说,近和远信号(其是不同于使用左右立体声通道的传统立体声表示的2-通道或立体声表示)根据一些预定的信息而被分配到左右通道立体声呈现。类似地,近和远信号可以具有指示应如何执行单声道呈现的通道分配或下混合信息。
108.此外,在一些实施例中,根据ue设置(例如,由用户经由ui选择的或由沉浸式语音
服务提供的)和/或空间分析,可以在空间ivas音频流中使用单声道语音信号(近信号)的空间位置。在这种实施例中,masa信号(空间环境,远信号)被配置为自动地包含在masa空间分析期间获得的空间信息。
109.因此,在一些实施例中,可以根据传输比特率和渲染能力来对音频信号进行解码和渲染,以向接收用户或收听者提供以下之一:
110.1.单声道语音对象。
111.2.根据近-远双通道配置的立体声语音(作为单声道) 环境(作为另一单声道)。
112.3.全空间音频。提供用于所发送的流的正确空间放置,其中,单声道语音对象在对象位置处被渲染,并且空间环境由方向性分量和扩散声场两者组成。
113.在一些实施例中,可以利用单声道语音/音频波形的evs编码来实现所发送的流的附加的向后互操作性。
114.移动手机或设备,在本文中也被称为ue(用户设备),代表沉浸式音频服务的最大细分市场,其年销售额超过10亿。在空间播放方面,这些设备可以被连接到立体声头戴式耳机(优选地,具有头部跟踪)。在空间捕获方面,ue本身可以被认为是优选设备。为了增加多麦克风空间音频捕获在市场上的普及并且为了向尽可能多的用户提供沉浸式音频体验,因此针对沉浸式通信优化捕获和编解码器性能是已被详细考虑的一个方面。
115.例如,图1示出了在移动设备上的典型的音频捕获场景100。在这个示例中,存在没有带头戴式耳机的第一用户104。因此,用户104将ue 102贴耳打电话。用户可以呼叫配备有立体声头戴式耳机并因此能够使用该头戴式耳机听到由第一用户捕获的空间音频的另一用户106。基于第一用户的空间音频捕获,可以为第二用户提供沉浸式体验。然而,考虑到例如常规masa捕获和编码,设备在捕获用户的耳朵上可能会出现问题。例如,用户语音可能会主导空间捕获,从而降低沉浸式级别。此外,用户的所有头部旋转以及设备相对于用户的头部的旋转都会导致针对接收用户的音频场景旋转。在一些情况下,这可能会使用户感到困惑。因此,例如,在时间121,所捕获的空间音频场景具有第一定向,如由来自另一用户106的体验的所渲染声音场景所示,其示出了第一用户110在相对于另一用户106的第一位置处以及(在该场景中的多于一个的音频源中的)一个音频源108在另一用户106正前方的位置处。进而,当用户在时间123转动他们的头部并在时间125进一步转动时,所捕获的空间场景进而旋转,这通过音频源108相对于另一用户106的位置和第一用户110的音频位置的旋转而被示出。这例如可能会导致音频源的重叠112。此外,如果使用用户设备的传感器信息来补偿旋转(如由关于时间125的箭头118所示),则第一用户的音频源(第一用户的语音)的位置反方向旋转,从而使体验更差。
116.图2示出了使用移动设备的另一音频捕获场景200。用户204可以例如从ue 202在ue贴耳捕获模式下操作开始(如在左侧221所示),进而改变为免提模式(其例如可以是如图2的中央223所示的手持式免提,或者如图2的右侧225所示的ue/设备202被放置在桌子上)。另一用户/收听者也可以佩戴耳塞或头戴式耳机来呈现所捕获的音频信号。在这种情况下,收听者/另一用户可以在手持免提模式下四处走动,或者例如在被放置在桌子上的设备周围移动(在免提捕获模式下)。在这个示例的用例中,设备相对于用户语音位置的旋转和整个沉浸式音频场景比图1的情况要复杂得多,尽管这对于实际会话应用来说同样是一个相当简单且典型的用例。
117.在一些实施例中,基于诸如陀螺仪、磁力计、加速度计、和/或定向传感器之类的任何合适的传感器,可以在捕获侧空间分析中至少部分地补偿各种设备旋转。可替代地,在一些实施例中,如果旋转补偿角度信息被发送为侧信息(side-information)(或元数据),则可以在播放侧补偿捕获装置旋转。如本文所描述的实施例示出了使能补偿捕获装置旋转以使得补偿或音频修改可以被单独地应用于语音和背景声音空间音频(换句话说,例如,只可以补偿“近”或“远”音频信号)的装置和方法。
118.ivas的一个关键用例是其中在两个参与者之间建立音频呼叫的音频场景(特别是对于实际的仅音频移动捕获)的自动稳定,具有沉浸式音频捕获能力的参与者例如以其ue贴耳开始呼叫,但是又切换到手持式免提并最终切换到设备在桌子上的免提,并且空间声音场景以不会导致收听者体验到“近”音频信号或“远”音频信号的不正确旋转的方式被发送并渲染给对方。
119.这样的示例可以是其中用户bob下班回家。他走过一个公园,突然想起他还需要讨论周末的计划。他向另一用户,他的朋友peter,发出沉浸式音频呼叫,还传送了在他周围的树上鸟儿歌唱的美好环境。bob没有带头戴式耳机,因此他将智能电话放在他的耳边以更好地听到peter的声音。在他回家的路上,他在十字路口停了下来,左右看了看,然后再一次向左看,以安全地穿过街道。bob一回到家,他就切换到手持免提操作,最后将智能电话放在桌子上以通过扬声器继续通话。空间捕获还向peter提供bob的布谷鸟自鸣钟系列的方向性声音。无论捕获设备的定向和操作模式如何改变,都能向peter提供稳定的沉浸式音频场景。
120.因此,这些实施例尝试针对实际的移动设备用例来优化捕获,以使得空间音频表示的语音主导地位被最小化并且方向性语音以及空间背景两者在捕获设备旋转期间保持稳定。
121.另外,这些实施例尝试使能与ivas是其扩展的3gpp evs的向后互操作性,并提供与evs的单声道兼容性。另外,这些实施例还允许立体声和空间兼容性。这在用于ue贴耳用例的空间音频中特别适用(例如,如图1中所示)。
122.此外,这些实施例尝试基于用户在其设备上可用的各种渲染能力来向收听者提供最佳音频渲染。具体而言,一些实施例尝试实现从空间音频呼叫到更低空间维度的低复杂度切换/下混合。在一些实施例中,这可以在来自具有各种渲染或呈现方法的ue的沉浸式音频语音呼叫中被实现。
123.图3a至图3c和图4示出了示例的捕获和呈现装置,其提供了可以描述这些实施例的合适的相关背景。
124.例如,图3a示出了多通道捕获和双耳音频呈现装置300。在这个示例中,空间多通道音频信号(2个或更多个通道)301被提供给降噪和信号分离处理器303,其被配置为执行降噪和信号分离。例如,这可以通过生成从原始单声道/立体声/多麦克风信号中提取的降噪主单声道信号306(主要包含近场语音)来执行。这使用了许多当前设备所使用的一般的单声道或多麦克风噪声抑制技术。该流作为向后兼容的流按原样被发送到接收器。另外,降噪和信号分离处理器303被配置为生成环境信号305。这些可以通过从所有麦克风信号中移除单声道信号(语音)而被获得,从而产生与存在若干麦克风时一样多的环境流。根据该方法,因此存在一个或多个空间信号可用于进一步编码。
125.进而,单声道306和环境305音频信号可以由空间声像归一化处理器307来处理,该
处理器执行合适的空间声像处理以便产生包括左耳310和右耳311输出的双耳兼容输出309。
126.图3b示出了示例的第一输入生成器(和编码器)320。输入生成器320被配置为接收空间麦克风321(多通道)音频信号,这些音频信号被提供给降噪和环境提取处理器323,其被配置为执行从多麦克风信号中提取单声道语音信号325(主要包含近场语音)并将其传递给传统语音编解码器327。另外,生成环境信号326(基于麦克风音频信号,其中语音信号被提取),这些环境信号可以被传递给合适的立体声/多通道音频编解码器328。
127.传统语音编解码器327对单声道语音音频信号325进行编码并输出合适的语音编解码器比特流329,并且立体声/多通道音频编解码器328对环境音频信号326进行编码以输出合适的立体声/多通道环境比特流330。
128.图3c示出了第二示例的输入生成器(和编码器)340。第二输入生成器(和编码器)340被配置为接收空间麦克风341(多通道)音频信号,这些音频信号被提供给降噪和环境提取处理器343,其被配置为执行从多麦克风信号中提取单声道语音信号345(主要包含近场语音)并将其传递给传统语音编解码器347。另外,生成环境信号346(基于麦克风音频信号,其中语音信号被提取),这些环境信号可以被传递给合适的参数化立体声/多通道音频处理器348。
129.传统语音编解码器347对单声道语音音频信号345进行编码并输出合适的语音编解码器比特流349。
130.参数化立体声/多通道音频处理器348被配置为生成单声道环境音频信号351(其可以被传递给合适的音频编解码器352)和空间参数比特流350。音频编解码器352接收单声道环境音频信号251,并对其进行编码以生成单声道环境比特流353。
131.图4示出了被配置为处理来自图3c的比特流的示例解码器/渲染器400。因此,解码器/渲染器400包括语音/环境音频解码器和空间音频渲染器401,其被配置为接收单声道环境比特流353、空间参数比特流350和语音编解码器比特流349,并生成合适的多通道音频输出403。
132.图5示出了适于实现如下文讨论的实施例的ivas编码器/解码器架构的高级概述。该系统可以包括一系列可能的输入类型,包括单声道音频信号输入类型501、立体声和双耳音频信号输入类型502、masa输入类型503、全景环绕声(ambisonics)输入类型504、基于通道的音频信号输入类型505、以及音频对象输入类型506。
133.此外,该系统包括ivas编码器511。ivas编码器511可以包括增强语音服务(evs)编码器513,其可以被配置为接收单声道输入格式501,并至少针对一些输入类型提供比特流521的至少一部分。
134.此外,ivas编码器511可以包括立体声和空间编码器515。立体声和空间编码器515可以被配置为接收来自任何输入来自立体声和双耳音频信号输入类型502、masa输入类型503、ambisonics输入类型504、基于通道的音频信号输入类型505和音频对象输入类型506的信号,并提供比特流521的至少一部分。在一些实施例中,evs编码器513可以被用于对从输入类型502、503、504、505、506获得的单声道音频信号进行编码。
135.另外,ivas编码器511可以包括元数据量化器517,其被配置为接收与诸如masa输入类型503、ambisonics输入类型504、基于通道的音频信号输入类型505和音频对象输入类
型506之类的输入类型相关联的侧信息/元数据,并对它们进行量化/编码以提供比特流521的至少一部分。
136.此外,该系统包括ivas解码器531。ivas解码器531可以包括增强语音服务(evs)解码器533,其可以被配置为接收比特流521,并生成合适的解码单声道信号以用于输出或进一步处理。
137.此外,ivas解码器531可以包括立体声和空间解码器535。立体声和空间解码器535可以被配置为接收比特流,并对它们进行解码以生成合适的输出信号。
138.另外,ivas解码器531可以包括元数据去量化器537,其被配置为接收比特流521,并重新生成可以被用于协助空间音频信号处理的元数据。例如,基于立体声和空间解码器535和元数据去量化器537的组合,可以在解码器中生成至少一些空间音频。
139.在以下示例中,感兴趣的主要输入类型是masa 503和对象506。如下文描述的实施例以编解码器输入为特征,该编解码器输入可以是masa 至少一个对象输入,其中,对象特别用于提供用户语音。在一些实施例中,masa输入可以与用户语音对象相关或不相关。在一些实施例中,与此相关状态有关的信令可以被提供为ivas输入(例如,输入元数据)。
140.在一些实施例中,masa 503输入被提供给ivas编码器,作为单声道或立体声音频信号和元数据。然而,在一些实施例中,输入可以代替地由3个(例如,平面一阶ambisonic-foa)或4个(例如,foa)通道组成。在一些实施例中,编码器被配置为将ambisonics输入编码为masa(例如,经由经修改的dirac编码),将基于通道的输入(例如,5.1或7.1 4)编码为masa,或者将一个或多个对象轨道编码为masa或编码为经修改的masa表示。在一些实施例中,基于对象的音频可以被定义为至少具有相关联的元数据的单声道音频信号。
141.如本文所描述的实施例在针对用户语音对象的准确音频对象输入定义方面可以是灵活的。在一些实施例中,特定的元数据标志将用户语音对象定义为用于通信的主信号(语音)。对于某些输入信号和编解码器配置,如用户生成的内容(ugc),这种信令可以被忽略或者区别于主会话模式而被处理。
142.在一些实施例中,ue被配置为实现不仅提供空间信号(例如,masa)而且还提供双分量信号的空间音频捕获,其中,用户语音被单独处理。在一些实施例中,用户语音由单声道对象表示。
143.因此,在一些实施例中,ue被配置为在ivas编码器511输入处提供诸如“masa 对象”之类的组合。这例如在图6中示出,其中,用户601和ue 603被配置为向合适的ivas编码器捕获/提供单声道语音对象605和masa环境607输入。换句话说,ue空间音频捕获不仅提供空间信号(例如,masa),而且还提供双分量信号,其中,用户语音被单独处理。
144.因此,在一些实施例中,输入是主要使用靠近用户的嘴部的至少一个麦克风捕获的单声道语音对象609。该至少一个麦克风可以是ue上的麦克风,或者,例如是头戴式麦克风或所谓的领夹式麦克风,音频流从麦克风被提供给ue。
145.在一些实施例中,单声道语音对象具有相关联的语音优先级信令标志/元数据621。单声道语音对象609可以包括单声道波形和至少包括声源(即,用户语音)的空间位置的元数据。该位置可以是真实位置,例如,相对于捕获设备(ue)位置的位置,或者是基于一些其他设置/输入的虚拟位置。在实践中,语音对象可以以其他方式利用与业内通常以基于对象的音频而已知的相同/相似的元数据。
146.下表总结了根据一些实施例的语音对象的最少特性。
147.特性描述(值)音频波形单个单声道薄型(旨在用于用户语音)元数据:语音优先级指示具有(最)高优先级的用户语音信号元数据:位置对象位置(例如,x-y-z或方位角/仰角/(距离))
148.下表提供了一些信令选项,这些选项可以附加地或可替代地用于根据一些实施例的语音对象的常规对象音频位置。
[0149][0150][0151]
在一些实施例中,可以针对语音对象渲染通道实现不同的信令(元数据),其中,存
在仅单声道或近-远立体声传输。
[0152]
对于音频对象,场景中的对象放置可以是任意的。当场景(至少由至少一个对象组成)被双耳化以用于渲染时,对象位置可以例如随时间改变。因此,还可以在语音对象元数据中提供时变位置信息(如上表中所示)。
[0153]
单声道语音对象输入可以被认为是“近”信号,该信号始终可以根据其在沉浸式渲染中所信令发送的位置来进行渲染,或者可替代地在缩减域渲染中被下混合到固定位置。通过“近”来标示相对于所捕获的语音源的信号捕获空间位置/距离。根据实施例,无论确切的呈现配置和比特率如何,此“近”信号总是被提供给用户并在渲染中始终可以被听到。为此目的,提供了语音优先级元数据或等效的信令(如上表中所示)。在一些实施例中,即使在缺少任何masa空间输入的情况下,该流也可以是来自沉浸式ivas ue的默认的单声道信号。
[0154]
因此,来自沉浸式ue(智能电话)的沉浸式通信的空间音频被表示为两个部分。第一部分可以被定义为单声道语音对象609的形式的语音信号。
[0155]
第二部分(环境部分623)可以被定义为空间masa信号(包括masa通道611和masa元数据613)。在一些实施例中,空间masa信号至少基本上不包括用户语音对象的轨道或者仅与用户语音对象微弱相关。例如,可以使用领夹式麦克风或用强波束成形来捕获单声道语音对象。
[0156]
在一些实施例中,可以信令发送用于语音对象和环境信号的附加的声学相关(或分离)信息。此元数据提供关于在语音对象与环境信号之间存在多少声学“泄漏”或串扰的信息。特别地,该信息可以被用于控制定向补偿处理,如下文中所解释的。
[0157]
在一些实施例中,实现了空间masa信号的处理。这可以是根据以下步骤:
[0158]
1.如果语音对象与masa环境波形之间没有相关性或有低相关性(相关性《阈值),则
[0159]
a.独立地控制语音对象的位置
[0160]
b.通过以下操作来控制masa空间场景:
[0161]
i.让masa空间场景根据实际旋转来进行旋转,或者
[0162]
ii.通过在每一tf图块(tf-tile-per-tf-tile)的基础上对masa空间场景方向应用对应的负旋转来补偿设备旋转。
[0163]
2.如果语音对象与masa环境波形之间存在相关性(相关性》=阈值),则
[0164]
a.控制语音对象的位置
[0165]
b.通过以下操作来控制masa空间场景:
[0166]
i.通过在tf-tile-per-tf-tile的基础上对masa空间场景应用在“a.”中使用的旋转(至少当对于语音对象vad=1时)来补偿与用户语音(tf图块和方向)对应的tf图块的设备旋转,同时让该场景的其余部分根据实际捕获设备旋转来进行旋转,或者
[0167]
ii.让masa空间场景根据实际旋转来进行旋转,同时至少使与用户语音(tf图块和方向)对应的tf图块扩散(至少当对于语音对象vad=1时),其中,方向到扩散的修改量(amount of directional-to-diffuse modification)可以取决于与对应于用户语音的masa tf图块相关的置信值(confidence value)。
[0168]
从上面可以理解,相关性计算可以基于长期平均来执行(即,不基于针对单个帧计算的相关值来执行决定),并且可以使用语音活动性检测(vad)来识别在语音对象通道/信
号内用户的语音的存在。在一些实施例中,相关性计算是基于至少两个信号的编码器处理。在一些实施例中,提供了元数据信令,例如,除了信号相关性计算之外,其可以至少部分地基于捕获设备特定信息。
[0169]
在一些实施例中,语音对象位置控制可以涉及(预先)确定的语音位置或语音对象在空间场景中的稳定性。换句话说,与不需要的旋转补偿相关。
[0170]
在一些实施例中,如上面所讨论的置信值的考虑可以是角距离(方向之间)和信号相关性的加权函数。
[0171]
在此观察到当语音与空间环境分离时,如果实现了合适的信令,则无论是在捕获还是在渲染中本地完成,旋转补偿(例如,在ue贴耳空间音频捕获用例中)都可以被简化。如本文所讨论的表示还可以使能单声道对象的任意放置(其无需依赖于场景旋转)。因此,在一些实施例中,可以使用单个音频波形和masa元数据来传送环境,其中,设备旋转可已经以在语音与环境之间(即使它们相关)不存在可感知或恼人的失配的方式被补偿。
[0172]
masa输入音频例如可以是基于单声道和基于立体声的音频信号。因此,除了masa空间元数据之外,还可以存在单声道波形或立体声波形。在一些实施例中,可以实现任一类型的输入和传送。然而,在一些实施例中,用于环境的基于单声道的masa输入连同用户语音对象可以是优选的格式。
[0173]
在一些实施例中,还可以可选地存在其他对象625,其被表示为对象615音频信号。这些对象通常与整个场景的一些其他音频分量有关,而不是与用户语音有关。例如,用户可以在所发送的场景中添加虚拟扬声器以播放音乐信号。这种音频元素通常将会作为音频对象被提供给编码器。
[0174]
由于用户语音是主要的通信信号,所以对于会话操作,可用比特率的很大一部分可以被分配给语音对象编码。例如,在48kbps时,可以考虑可分配大约20kbps来编码语音,而剩余的28kbps被分配给空间环境表示。在这种比特率下,尤其是在更低的比特率下,对空间masa波形的单声道表示进行编码以实现尽可能高的质量可以是有益的。由于这些原因,在一些示例中,基于单声道的masa输入可以是最实用的。
[0175]
另一个考虑是嵌入式编码。在图7中提供了合适的嵌入式编码方案提议,其中,基于单声道的masa(编码)是实用的。嵌入式编码的实施例可以使能三个级别的嵌入式编码。
[0176]
如由单声道:语音(mono:voice)列所示的最低级别是单声道操作,其包括单声道语音对象701。这也可以被指定为“近”信号。
[0177]
如由图7中的立体声:近-远(stereo:near-far)列所示的第二级别是特定类型的立体声操作。在这种实施例中,输入是单声道语音对象701和环境masa通道703两者。这可以被实现为“近-远”立体声配置。然而,不同之处在于这些实施例中的“近”信号是完整的单声道语音对象,其参数例如如上表中所示。
[0178]
在这些实施例中,先前定义的方法被扩展以处理沉浸式音频而不是仅处理立体声以及各种级别的渲染。“远”通道是基于单声道的masa表示的单声道部分。因此,它包括完整的空间环境,但没有在空间中正确地渲染它的实际方法。在立体声传送的情况下被渲染的内容还将取决于空间渲染设置和能力。下表提供了根据一些实施例的可以被用于渲染的“远”通道的一些附加特性。
[0179][0180][0181]
如由空间音频(spatial audio)列所示的嵌入式结构的第三和最高级别是空间masa环境表示,该空间masa环境表示包括单声道语音对象701和空间masa环境表示,该空间masa环境表示包括环境masa通道703和环境masa空间元数据705这两者。在这些实施例中,空间信息以可以向收听者正确地渲染空间中的环境的方式被提供。
[0182]
另外,如由图7中的空间音频 对象列所示的一些实施例中,在对编码器的组合输入的情况下,可以包括有附加的对象707。注意,这些附加的单独对象707不被假定是嵌入式编码的一部分,而是它们被单独地处理。
[0183]
在一些实施例中,在编解码器输入(例如,输入元数据)处可存在优先级信令,其指示例如特定对象707是比环境音频更重要还是更不重要。通常,这种信息是基于用户输入(例如,经由ui)或服务设置。
[0184]
例如,可存在导致更低嵌入模式的优先级信令,以在进入下一步嵌入式级别之前在该侧包括单独的对象以进行传输。
[0185]
换句话说,在一些情况(输入设置)和操作点下,可传送更低的嵌入模式和可选对象,例如,单声道语音对象 单独的音频对象,然后才考虑切换到近-远立体声传输模式。
[0186]
图8a呈现了用于实现一些实施例的示例装置。图8a例如示出了ue 801。ue 801包括用于捕获用户的语音803的至少一个麦克风,并且被配置为将单声道语音音频信号提供给单声道语音对象(近)输入811。换句话说,使用专用的麦克风设置来捕获单声道语音对象。例如,它可以是单个麦克风或多个麦克风,这些麦克风例如被用来执行合适的波束成形。
[0187]
在一些实施例中,ue 801包括用于环境的空间捕获麦克风阵列805,其被配置为捕获环境分量并将其传递给masa(远)输入813。
[0188]
在一些实施例中,单声道语音对象(近)811输入被配置为接收麦克风的语音音频信号,并将单声道音频信号作为单声道语音对象传递给ivas编码器821。在一些实施例中,单声道语音对象(近)811输入被配置为处理音频信号(例如,在将音频信号传递给ivas编码器821之前,优化单声道语音对象的音频信号)。
[0189]
masa输入813被配置为接收空间捕获麦克风阵列的环境音频信号,并将其传递给ivas编码器821。在一些实施例中,单独的空间捕获麦克风阵列被用于获得空间环境信号(masa),并根据任何合适的手段对其进行处理以提高所捕获的音频信号的质量。
[0190]
进而,ivas编码器821被配置为基于如由比特流831所示的两个输入格式音频信号对这些音频信号进行编码。
[0191]
此外,ivas解码器841被配置为对编码的音频信号进行解码,并将其传递给单声道语音输出851、近-远立体声输出853、以及空间音频输出855。
[0192]
图8b呈现了用于实现一些实施例的另一示例装置。图8b例如示出了ue 851,其包括组合的空间音频捕获多麦克风布置853,该空间音频捕获多麦克风布置853被配置为向单声道语音对象(近)输入861提供单声道语音音频信号,并且向masa输入863提供masa音频信号。换句话说,图8b示出了组合的空间音频捕获,其输出用于语音的单声道和用于环境的空间信号。组合的分析处理例如可以从空间捕获中抑制用户语音。这可以针对单独的通道或masa波形(“远”通道)而被完成。可以认为该音频捕获看起来非常类似于图8a,但是至少有一些共同的处理,例如,从空间捕获信号中移除波束成形的麦克风信号。
[0193]
在一些实施例中,单声道语音对象(近)861输入被配置为接收麦克风的语音音频信号,并将单声道音频信号作为单声道语音对象传递给ivas编码器871。在一些实施例中,单声道语音对象(近)861输入被配置为处理音频信号(例如,在将音频信号传递给ivas编码器871之前,优化单声道语音对象的音频信号)。
[0194]
masa输入863被配置为接收空间捕获麦克风阵列的环境音频信号,并将其传递给ivas编码器871。在一些实施例中,单独的空间捕获麦克风阵列被用于获得空间环境信号(masa),并根据任何合适的手段对其进行处理以提高所捕获的音频信号的质量。
[0195]
进而,ivas编码器871被配置为基于如由比特流881所示的两个输入格式音频信号对这些音频信号进行编码。
[0196]
此外,ivas解码器891被配置为对编码的音频信号进行解码,并将其传递给单声道语音输出893、近-远立体声输出895、以及空间音频输出897。
[0197]
在一些实施例中,除了可以使用从单独的通道或masa波形中抑制(移除)用户语音之外,可以应用其他空间音频处理以优化单声道语音对象 masa空间音频输入。例如,在活动语音期间,方向可以不被认为对应于主麦克风方向或全面增加扩散值。例如,当本地vad没有激活语音麦克风时,可以执行完整的空间分析。在一些实施例中,可以利用这种附加的处理,例如,仅当ue在耳朵上或在手持式免提操作中使用并且用于语音信号的麦克风靠近用户的嘴部时。
[0198]
对于多麦克风ivas ue,默认的捕获模式可以是利用单声道语音对象 masa空间音频输入格式的模式。
[0199]
在一些实施例中,ue基于其他(非音频)传感器信息来确定捕获模式。例如,可以有已知的方法来检测ue与用户的耳朵接触或基本上位于用户的耳朵附近。在这种情况下,空间音频捕获可以进入如上所描述的模式。在其他实施例中,该模式可以取决于一些其他模式选择(例如,用户可以使用合适的ui提供输入以选择设备是处于免提模式、手持免提模式、还是手持模式)。
[0200]
关于图9,更详细地描述了ivas编码器813、863的操作。
[0201]
例如,在一些实施例中,如图9中步骤901所示,ivas编码器813、863可以被配置为获得协商的设置(例如,如上所描述的模式),并对编码器进行初始化。
[0202]
下一操作可以是获得输入。例如,如图9中步骤903所示,获得单声道语音对象 masa空间音频。
[0203]
此外,在一些实施例中,如图9中步骤905所示,该编码器被配置为获得当前的编码器比特率。
[0204]
进而,如图9中步骤907所示,可以获得编解码器模式请求。这种请求与接收方请求有关,例如,对于发送设备要使用的特定编码模式。
[0205]
进而,如图9中步骤909所示,可以选择嵌入式编码级别,并分配比特率。
[0206]
进而,如图9中步骤911所示,波形和元数据可以被编码。
[0207]
此外,如图9中所示,编码器的输出被传递为比特流913,其进而由ivas解码器915进行解码,这例如可以是采用嵌入式输出形式的形式。例如,在一些实施例中,输出形式可以是单声道语音对象917。该单声道语音对象可以进一步是靠近通道919(还有另一环境远通道921)的单声道语音对象。此外,ivas解码器915的输出可以是单声道语音对象923、环境masa通道925和环境masa通道空间元数据927。
[0208]
此外,图10更详细地示出了选择嵌入式编码级别选择(图9步骤909)和对波形和元数据进行编码(图9步骤911)的操作。初始操作是如图10中步骤1001所示的获得单声道语音对象音频信号,如图10中步骤1003所示的获得masa空间环境音频信号,以及如图10中步骤1005所示的获得总比特率。
[0209]
如图10中步骤1007所示,在已获得单声道语音对象音频信号之后,该方法进而可以包括将语音对象位置与近通道渲染通道分配进行比较。
[0210]
此外,如图10中步骤1011所示,在已获得单声道语音对象音频信号和masa空间环境音频信号之后,该方法进而可以包括确定输入信号活动性级别,并预先分配比特预算。
[0211]
如图10中步骤1013所示,在已比较语音对象位置、确定输入信号活动性级别并获得总比特率之后,该方法进而可以包括估计对切换的需要,并确定语音对象位置修改。
[0212]
如图10中步骤1009所示,在已估计对切换的需要并确定语音对象位置修改之后,该方法可以包括在需要时修改语音对象位置或者更新近通道渲染通道分配。特别地,针对嵌入模式切换考虑修改单声道对象位置以平滑任何潜在的不连续性。可替代地,可以更新针对近通道的推荐l/r分配(如在编码器输入处接收的)。该更新还可以包括远通道l/r分配(或者,例如,混合平衡)的更新。对这种修改的潜在需求是基于近-远立体声渲染通道偏好和语音对象位置显著偏离的可能性。这种偏离是可能的,因为语音对象位置可以被理解为空间中连续的时变位置。另一方面,近-远立体声通道选择(进入l或r通道/耳朵呈现)通常是静态的,或者例如仅在某些暂停期间更新,以免创建不必要且恼人的不连续(即,内容在通道之间跳跃)。因此,这两个分量波形的信号活动性级别被跟踪。
[0213]
此外,如图10中步骤1015所示,该方法可以包括确定要使用的嵌入式级别。这可以是基于对总比特率(以及,例如,协商的比特率范围)的了解,估计对切换在使用的嵌入式级别(单声道、立体声、空间,诸如图7和图9中所示)的潜在需要。
[0214]
在此之后,如图10中步骤1017所示,进而可以分配用于语音和环境的比特率。
[0215]
如图10中步骤1019所示,在已分配比特率以及在需要时修改语音对象位置或者更新近通道渲染通道分配之后,该方法进而可以包括根据所分配的比特率来执行波形和元数据编码。
[0216]
进而,如图10中步骤1021所示,可以输出编码的比特流。
[0217]
在一些实施例中,该编码器被配置是evs兼容的。在这种实施例中,ivas编解码器可以以evs兼容编码模式(例如,evs 16.4kbps)对用户语音对象进行编码。通过剥离任何ivas语音对象元数据和空间音频部分并仅解码evs兼容的单声道音频,这使得与传统的evs设备兼容变得非常简单。进而,尽管使用了ivas ue(具有沉浸式捕获)到evs ue,这也与从evs ue到evs ue的端到端体验相对应。
[0218]
图11a到图11d示出了针对使用ivas的沉浸式对话服务的一些典型的渲染/呈现用例,可以根据一些实施例来使用这些使用ivas的沉浸式对话服务。尽管在一些实施例中,该装置可以被配置为实现以下讨论中的会议应用,但是该装置和方法实现了(沉浸式)语音呼叫,换句话说,两个人之间的呼叫。因此,例如,用户可以被配置为如图11a中所示使用ue来进行音频渲染。在这是传统ue的一些实施例中,通常已经协商好了单声道evs编码(或者,例如,amr-wb)。然而,如果该ue是ivas ue,则它可以被配置为接收沉浸式比特流。在这种实施例中,通常实现了单声道音频信号播放,并因此用户可以仅播放单声道语音对象(并且实际上仅发送单声道语音对象)。在一些实施例中,可以为用户提供用于选择输出嵌入级别的选项。例如,ue可以被配置有使用户能够控制环境再现级别的用户接口(ui)。因此,在一些实施例中,还可以向用户提供并呈现近和远通道的单耳混合。在一些实施例中,基于如上所示的远通道特性表来接收默认的混合平衡值。在一些实施例中,例如,可以针对同样在上面示出的附加/替代的语音对象特性表来提供单声道语音默认距离增益。
[0219]
在一些实施例中,该渲染装置包括耳塞(诸如由图11b中的无线左通道耳塞1113和
1413、1411可以以自动检测它们是否被放置在用户的耳朵中为特征。在图14的左手侧,图示佩戴单个earpod 1411的用户。然而,用户可以添加第二earpod 1413,并且在图14的右手侧图示佩戴这两个earpod 1413、1411的用户。因此,用户可以例如在通话期间在双通道立体声(或沉浸式)播放与一通道单声道播放之间反复切换。在一些实施例中,沉浸式对话编解码器渲染器能够通过提供始终良好的用户体验来处理该用例。否则,用户将会因传入通信音频的不正确渲染而分心,并且可能例如完全丢失所发送的用户语音。
[0225]
关于图15,示出了用于根据解码器/渲染器中的呈现能力切换来控制渲染的合适方法的流程图。在一些实施例中,渲染控制可以被实现为(ivas)内部渲染器和外部渲染器中的至少一个的一部分。
[0226]
因此,在一些实施例中,如图15中步骤1501所示,该方法包括接收比特流输入。
[0227]
如图15中步骤1503所示,在已接收到比特流之后,该方法可以进一步包括获得解码的音频信号和元数据,以及确定所发送的嵌入式级别。
[0228]
此外,如图15中步骤1505所示,该方法可以进一步包括接收合适的用户接口输入。
[0229]
如图15中步骤1507所示,在已获得合适的用户接口输入、已获得解码的音频信号和元数据并已确定所发送的嵌入式级别之后,该方法进而可以包括获得呈现能力信息。
[0230]
如图15中步骤1509所示,系下一操作是确定是否存在能力的切换。
[0231]
如图15中步骤1511所示,如果能力的切换被确定,则该方法可以包括根据所切换的能力来更新音频信号渲染特性。
[0232]
如图15中步骤1513所示,如果没有切换或者遵循更新,则该方法可以包括确定是否存在嵌入式级别改变。
[0233]
如图15中步骤1515所示,如果存在嵌入式级别改变,则该方法可以包括根据嵌入式级别的改变来更新音频信号渲染特性和通道分配。
[0234]
如图15中步骤1517所示,如果没有嵌入式级别改变或者遵循音频信号渲染特性和通道分配的更新,则该方法可以包括根据渲染特性(包括所发送的元数据)和对一个或多个输出通道的通道分配来渲染音频信号。
[0235]
因此,该渲染可以导致如由图15中步骤1523所示的单声道信号的呈现、如由图15中步骤1521所示的立体声信号的呈现、以及如由图15中步骤1519所示的沉浸式信号的呈现。
[0236]
因此,可以应用针对语音对象的修改,并且可以实现在呈现能力切换和嵌式入级别改变下的环境信号渲染。
[0237]
因此,例如关于图16,示出了在默认嵌入式级别从沉浸嵌入式级别改变为立体声嵌入式级别或直接改变为单声道嵌入式级别期间的渲染控制。例如,网络拥塞导致比特率降低,并且编码器相应地改变嵌入式级别。在左手侧的示例中,“语音对象 masa环境”音频的沉浸式渲染用于立体声头戴式耳机/耳塞/earpod呈现(在此被可视化为佩戴左通道1113和右通道1111earpod的用户)。所呈现的场景被示出为包括渲染器1601、位于前方与左方之间的单声道对象1603、以及环境声源,源1 1607位于渲染器装置1601的前方、源2 1609位于渲染器装置1601的右方、源3 1605位于渲染器装置1601的左后方之间。
[0238]
如箭头1611所示,嵌入式级别从沉浸式被降低到立体声,这导致通过左通道来渲染单声道语音对象1621并且环境声源位于渲染器装置1625的右方。
[0239]
如箭头1613所示,嵌入式级别还从沉浸式被降低到单声道,这导致通过左通道来渲染单声道语音对象1631。换句话说,当用户在收听立体声呈现时,立体声和单声道信号不会被双耳化。相反,考虑信令并选择说话者语音的呈现侧(根据编码器信令的语音对象优选通道)。
[0240]
在其中“智能”呈现设备能够向(ivas内部/外部)渲染器信令传送其当前能力/使用的一些实施例中,渲染器可以能够用于单声道或立体声呈现的能力以及可以在那个通道(或哪个耳朵)上进行单声道呈现。如果这是未知的或无法确定的,则由用户来确保他们的earpod/头戴式耳机/耳机等被正确放置,否则用户可能(在空间呈现的情况下)接收到不正确旋转的沉浸式场景或者(取决于渲染器)被提供大部分扩散的环境呈现。
[0241]
这可以例如关于图17被示出,图17示出了在从双通道呈现到单通道呈现的能力切换期间的渲染控制。因此,在此可以理解解码器/渲染器被配置为接收能力改变的指示。这例如可以是图15的流程图中所示的输入步骤1505。
[0242]
例如,图17示出与图16中所示类似的场景,但是其中用户移除或关闭1715左通道earpod,从而导致仅佩戴右通道earpod 1111。由此,如在左手侧所示,示出了所呈现的场景,其包括渲染器1601、位于前方与左方之间的单声道对象1603、以及环境声源,源1 1607位于渲染器装置1601的前方、源2 1609位于渲染器装置1601的右方、源3 1605位于渲染器装置1601的左后方之间。
[0243]
如箭头1711所示,嵌入式级别从沉浸式被降低到立体声,这导致通过右通道来渲染单声道语音对象1725并且环境声源1721也位于渲染器装置1725的右方。
[0244]
如箭头1713所示,嵌入式级别还被示出为从沉浸式降低到单声道,这导致通过右通道来渲染单声道语音对象1733。
[0245]
在这种实施例中,可以接收沉浸式信号(或者存在基本上同时的到立体声或单声道的嵌入式级别改变,这可以例如由基于接收器呈现设备能力改变而对编码器的编解码器模式请求(cmr)引起)。因此,音频被路由到渲染器中的可用通道。注意,这是渲染器控制,它不仅仅是在呈现设备中对这两个通道进行下混合,如果只有呈现能力切换而嵌入层级别没有改变,则这将会是在图17的左手侧可见的沉浸式信号的直接下混合。因此,用户体验得以改进,声音更清晰。
[0246]
关于图18,示出了从单声道到立体声的嵌入式级别改变的示例。左手侧示出了相对于渲染器,单声道语音对象1803的位置是在渲染器1801的右方。当单声道到近-远立体声能力被改变(基于编码器信令或者在解码器处的相关联用户偏好)时,语音被从右侧平移到左侧,如由轮廓1833(右轮廓)到1831(左轮廓)所示,这导致对象渲染器将语音对象(近)1823向左方输出并将环境(远)1825向右方输出。
[0247]
关于图19,示出了从单声道到沉浸式的嵌入式级别改变的示例。左手侧示出了相对于渲染器,单声道语音对象1803的位置是在渲染器1801的右方。当单声道到沉浸式能力被改变(例如,被分配更高的比特率)时,单声道语音对象被平滑地转移1928到它在空间场景中的正确位置1924。这是可以的,因为它是被单独地传送的。因此,修改位置元数据(在解码器/渲染器中)以实现这种转变。如果在单声道渲染中最初没有外部化/双耳化,则语音对象首先如图所示地被从1913外部化到1923。另外,环境音频源1922、1925、1927在其正确位置被呈现。
[0248]
关于图20,示出了基于接收用户(在更高空间维度)的先前用户交互对较低空间维度音频的示例呈现适配。它图示了空间场景的捕获及其在近-远立体声模式下的默认呈现。
[0249]
因此,图20示出了“语音对象2031 masa环境(masa通道2033和masa元数据2035)”音频的捕获和沉浸式渲染。捕获场景被示出具有若干定向,前方2013、左方2003和右方2015,并且该场景包括捕获装置2001、位于前方与左方之间的单声道对象2009、以及环境声源。在图20所示的示例中,源1 2013位于捕获装置2001的前方,源2 2015位于捕获装置2001的右方,源3 2011位于捕获装置1201的左后方之间。渲染器2041(收听者)能够通过使用如本文所描述的实施例生成并呈现捕获场景的摹本。例如,渲染器2041被配置为生成并呈现位于前方与左方之间的单声道对象2049,以及位于渲染装置2041的前方的环境声源1 2043、位于渲染装置2041的右方的声源2 2045、以及位于渲染装置1211的左后方之间的源3 3042。
[0250]
此外,接收用户可以自由地操纵该场景的至少一些方面(根据任何可以限制用户这样做的自由度的信令)。例如,如箭头2050所示,用户可以将语音对象移动到他们偏好的位置。这可以在应用中触发针对语音通道的本地偏好的重新映射。因此,渲染器2051(收听者)能够通过使用如本文所所描述的实施例生成并呈现捕获场景的经修改的摹本。例如,渲染器2051被配置为生成并呈现位于前方与左方之间的单声道对象2059,同时将环境声源2042、2043、2045保持在其原始定向。
[0251]
此外,当例如由网络拥塞/降低的比特率2060等引起的嵌入式层级别改变时,单声道语音对象2063由渲染装置2061保持在其先前主要被用户听到的通道上,而单声道环境音频对象2069被保持在另一侧。(注意,在双耳化呈现中,用户会听到来自这两个通道的声音。hrtf的应用和语音对象的到达方向给出它在虚拟场景中的位置。在立体声信号的非双耳化呈现的情况下,语音可以可替代地只从单个通道出现)。这与基于捕获和传送的默认情形不同,该默认情形如在右上方所示,其中,单声道语音对象2019被渲染装置2021定位在原始捕获侧,而单声道环境音频对象2023被定位在相对侧。
[0252]
关于图21,示出了根据实施例的三种用户体验的比较。这些用户体验都由编码器或解码器/渲染器侧信令来控制。呈现出同一场景(例如,先前关于图12所描述的场景)的三个状态,其中,这些状态被转变,并且其中,在渲染控制中实现了差异。在顶部的图21a中,示出了根据编码器侧信令的呈现。因此,渲染器2101最初被配置有在左方的单声道语音源2103和在右方的单声道环境音频源2102。立体声到沉浸式转变2104导致渲染器2105具有在正确位置的单声道语音源2109和环境音频源2106、2107、2108。进一步的沉浸式到单声道转变导致渲染器2131具有在左方的单声道语音源2133。
[0253]
在中部的图21b中,示出了根据编码器侧和解码器/渲染器侧信令的组合的呈现。在此,用户具有使语音对象在r通道(例如,右耳)中的偏好。图21a示出了根据编码器侧信令的呈现。因此,渲染器2111最初被配置有在右方的单声道语音源2113和在左方的单声道环境音频源2112。立体声到沉浸式转变2104导致渲染器2115具有在其正确位置的单声道语音源2119和环境音频源2116、2117、2118。进一步的沉浸式到单声道转变导致渲染器2141具有在右方的单声道语音源2143。
[0254]
最后,底部的图21c示出了用户偏好如何被应用于同样的沉浸式场景。这可以是如下情况:例如,在此有从近-远立体声传输(及其根据用户偏好的呈现)到沉浸式场景传输的
第一转变。语音对象位置被适配以维持用户偏好。因此,渲染器2121最初被配置有在右方的单声道语音源2123和在左方的单声道环境音频源2122。立体声到沉浸式转变2104导致渲染器2125具有移动到新位置的单声道语音源2129和在正确位置的环境音频源2126、2127、2108。进一步的沉浸式到单声道转变导致渲染器2151具有在左方的单声道语音源2153。
[0255]
关于图22,示出了基于接收用户的earpod激活的通道偏好选择(被提供为解码器/渲染器输入)。这是一个示例,其可以确定在一些先前示例中可见的用户偏好状态/输入中的至少一些。例如,用户可以没有这样的偏好。然而,可确定接收用户的伪偏好以便基于用户在接收呼叫时的通道选择来维持稳定的场景渲染。
[0256]
因此,例如,顶部示出了用户2201有传入呼叫2203(其中,该传输使用例如近-远立体声配置),用户添加右通道earpod 2205,如箭头2207所示,该呼叫被应答并且语音在右通道上被呈现。此外,如参考标号2210所示,用户进而可以添加左通道earpod 2209,这进而使渲染器在左通道上添加环境。
[0257]
底部示出了用户2221有传入呼叫2223(其中,该传输使用例如近-远立体声配置),用户添加左通道earpod 2225,如箭头2227所示,该呼叫被应答并且语音在左通道上被呈现。此外,如参考标号2230所示,用户进而可以添加右通道earpod 2229,这进而使渲染器在右通道上添加环境。
[0258]
可以理解在许多会话沉浸式音频用例中,接收用户不知道什么是正确的场景。因此,提供高质量且一致的体验很重要,其中,始终向用户至少传送最重要的信号。一般来说,对于会话用例,最重要的信号是说话者的语音。在本文中,在能力切换期间维持语音信号呈现。如果需要,语音信号因此从一个通道切换到另一通道或者从一个方向切换到其余的通道。基于呈现能力和信令,环境被自动地添加或移除。
[0259]
因此,根据本文的实施例,以嵌入式空间立体声配置发送两个可能完全独立的音频流,其中,第一立体声通道是单声道语音,第二立体声通道是空间音频环境场景的基础。因此,对于渲染,重要的是至少在l-r通道放置方面理解这两个通道的预期或期望的空间意义/定位。换句话说,通常需要知道哪个近-远通道是l,哪个近-远通道是r。可替代地,如在实施例中所解释的,可以提供关于将它们混合在一起以渲染至少一个通道的期望方式的信息。对于任何向后兼容的播放,无论如何通道都可以始终回放为l和r(尽管该选择可以是任意的,例如,通过将第一通道指定为l并将第二通道指定为r)。
[0260]
因此,在一些实施例中,可以基于单声道/立体声能力信令来决定如何在实际渲染系统中呈现任何以下所接收的信号。这些可以包括:
[0261]-仅单声道语音对象(或者剥离了元数据的仅单声道信号)
[0262]-具有单声道对象(或者剥离了元数据的单声道语音)和单声道环境波形的近-远立体声
[0263]-其中单独地传送单声道语音对象的空间音频场景
[0264]
在仅单声道播放的情况下,默认的呈现可以很简单:
[0265]-单声道对象在可用通道中被渲染
[0266]-近分量(单声道语音对象)在可用通道中被渲染
[0267]-被单独地传送的单声道语音对象在可用通道中被渲染
[0268]
在立体声播放的情况下,默认的呈现被建议如下:
[0269]-在优选通道中渲染单声道语音对象,或者根据所信令传送的方向对单声道对象进行双耳化
[0270]-在优选通道中渲染近分量(单声道语音对象),并在第二通道中渲染远分量(单声道环境波形),或者根据所信令传送的方向对近分量(单声道语音对象)进行双耳化,并根据默认或用户偏好的方式对远分量(单声道环境波形)进行双耳化
[0271]
ο环境信号的双耳化可以默认是完全扩散的,或者它可以取决于近通道方向或某些先前状态
[0272]-根据所信令传送的方向对被单独地传送的单声道语音对象进行双耳化,并根据masa空间元数据描述对空间环境进行双耳化
[0273]
关于图23,示出了可以被用作分析或合成设备的示例电子设备。该设备可以是任何合适的电子设备或装置。例如,在一些实施例中,设备2400是移动设备、用户设备、平板计算机、计算机、音频播放装置等。
[0274]
在一些实施例中,设备2400包括至少一个处理器或中央处理单元2407。处理器2407可以被配置为执行各种程序代码,诸如本文所描述的方法。
[0275]
在一些实施例中,设备2400包括存储器2411。在一些实施例中,至少一个处理器2407被耦合到存储器2411。存储器2411可以是任何合适的存储部件。在一些实施例中,存储器2411包括用于存储可在处理器2407上实现的程序代码的程序代码部分。此外,在一些实施例中,存储器2411还可以包括用于存储数据(例如根据本文所描述的实施例已被处理或将要被处理的数据)的存储数据部分。在需要时,被存储在程序代码部分内的所实现的程序代码和被存储在存储数据部分内的数据可以经由存储器-处理器耦合而被处理器2407取得。
[0276]
在一些实施例中,接口设备2400包括用户接口2405。在一些实施例中,用户接口2405可以被耦合到处理器2407。在一些实施例中,处理器2407可以控制用户接口2405的操作并从用户接口2405接收输入。在一些实施例中,用户接口2405可以使得用户能够例如经由小键盘向设备2400输入命令。在一些实施例中,用户接口2405可以使得用户能够从设备1700获得信息。例如,用户接口2405可以包括被配置为向用户显示来自设备2400的信息的显示器。在一些实施例中,用户接口2405可以包括触摸屏或触摸接口,其既能够使信息被输入到设备2400中,又能够向设备2400的用户显示信息。在一些实施例中,用户接口2405可以是如本文所述的用户接口。
[0277]
在一些实施例中,设备2400包括输入/输出端口2409。在一些实施例中,输入/输出端口2409包括收发机。在这种实施例中,收发机可以被耦合到处理器2407,并且被配置为例如经由无线通信网络实现与其他装置或电子设备的通信。在一些实施例中,收发机或任何合适的收发机或发射机和/或接收机部件可以被配置为经由有线或有线耦合来与其他电子设备或装置通信。
[0278]
收发机可以通过任何合适的已知通信协议来与其他装置通信。例如,在一些实施例中,收发机可以使用合适的通用移动电信系统(umts)协议、诸如ieee 802.x之类的无线局域网(wlan)协议、诸如蓝牙之类的合适的短距离射频通信协议、或红外数据通信路径(irda)。
[0279]
输入/输出端口2409可以被耦合到任何合适的音频输出,例如被耦合到多通道扬
声器系统和/或耳机(其可以是头部跟踪或非跟踪的头戴式耳机)等。
[0280]
通常,本发明的各种实施例可以采用硬件或专用电路、软件、逻辑或其任何组合来实现。例如,一些方面可以采用硬件来实现,而其他方面可以采用可由控制器、微处理器或其他计算设备执行的固件或软件来实现,但是本发明不限于此。尽管本发明的各个方面可以被图示和描述为框图、流程图或使用一些其他图形表示,但是众所周知地,本文所描述的这些框、装置、系统、技术或方法可以作为非限制示例采用硬件、软件、固件、专用电路或逻辑、通用硬件或控制器或其他计算设备或其某种组合来实现。
[0281]
本发明的实施例可以通过可由移动设备的数据处理器(诸如在处理器实体中)执行的计算机软件来实现,或者由硬件、或者由软件和硬件的组合来执行。此外,就此而言,应当注意,如附图中的逻辑流程的任何块可以表示程序步骤、或者互连的逻辑电路、块和功能、或者程序步骤和逻辑电路、块和功能的组合。该软件可以被存储在诸如存储器芯片或在处理器内实现的存储器块之类的物理介质上,诸如硬盘或软盘之类的磁性介质上、以及诸如dvd及其数据变体cd之类的光学介质上。
[0282]
存储器可以是适合于本地技术环境的任何类型,并且可以使用任何适当的数据存储技术来实现,诸如基于半导体的存储器设备、磁存储器设备和系统、光学存储器设备和系统、固定存储器和可移除存储器。数据处理器可以是适合于本地技术环境的任何类型,并且作为非限制性示例,可以包括通用计算机、专用计算机、微处理器、数字信号处理器(dsp)、专用集成电路(asic)、基于多核处理器架构的门级电路和处理器中的一个或多个。
[0283]
可以在诸如集成电路模块之类的各种组件中实践本发明的实施例。集成电路的设计总体上是高度自动化的过程。复杂而功能强大的软件工具可用于将逻辑级设计转换为准备在半导体衬底上蚀刻和形成的半导体电路设计。
[0284]
程序,诸如由加利福尼亚州山景城的synopsys公司和加利福尼亚州圣何塞的cadence design所提供的程序,使用完善的设计规则以及预先存储的设计模块库来自动对导体进行布线并将组件定位在半导体芯片上。一旦完成了半导体电路的设计,就可以将标准化电子格式(例如,opus、gdsii等)的所得设计传送到半导体制造设施或“fab”进行制造。
[0285]
前面的描述已经通过示例性和非限制性示例提供了本发明的示例性实施例的完整和有益的描述。然而,当结合附图和所附权利要求书阅读时,鉴于以上描述,各种修改和改编对于相关领域的技术人员而言将变得显而易见。然而,本发明的教导的所有这些和类似的修改仍将落入所附权利要求书所限定的本发明的范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。