检测和/或登记热命令以由自动助理触发响应动作
背景技术:
1.人们可以利用本文称为“自动助理”(也称为“聊天机器人”、“交互式个人助理”、“智能个人助理”、“个人语音助理”、“会话代理”、“虚拟助理”等)的交互式软件应用参与人机对话。例如,人类(当他们与自动助理交互时,可以被称为“用户”)可以使用自由形式的自然语言输入来提供命令、查询和/或请求,所述自由形式的自然语言输入可以包括被转换成文本然后被处理的有声话语和/或键入的自由形式的自然语言输入。
2.在许多情况下,在自动助理可以解释并响应用户的请求之前,它必须首先例如使用通常被称为“热词”或“唤醒词”的预定义口头调用短语而被“调用”。因此,许多自动助理以在本文中被称为“有限收听状态”或“默认收听状态”的方式操作,在所述“有限收听状态”或“默认收听状态”的方式操作中,它们总是“收听”麦克风针对有限(或受限或“默认”)的热词集合采样的音频数据。音频数据中捕获的除了默认的热词集合以外的任何话语都将被忽略。一旦利用默认的热词集合中的一个或多个调用了自动助理,它就可以以本文被称为“完全收听状态”的方式操作,其中,对调用后的至少一些时间间隔,自动助理对由麦克风采样的音频数据执行话音到文本(“stt”)处理(也被称为“话音辨识处理”)以生成文本输入,继而对所述文本输入进行语义处理以确定用户的意图(并实现该意图)。
3.在默认收听状态下操作自动助理提供了各种益处。限制被“收听”的热词的数量允许节省功率和/或计算资源。例如,可以训练设备上机器学习模型以生成指示何时检测到一个或多个热词的输出。实现这样的模型可能仅需要最小的计算资源和/或功率,这对于通常资源受限的辅助设备是特别有益的。除了这些益处之外,在有限热词收听状态下操作自动助理也提出了各种挑战。为了避免无意调用自动助理,通常将热词选择为在日常会话中不经常说出的词或短语(例如,“长尾”词或短语)。但是,存在要求用户在调用自动助理以执行某些操作之前说出长尾热词可能会很麻烦的各种情况。
技术实现要素:
4.本文描述了用于检测和/或登记(或调试)新“热命令”的技术,所述“热命令”可用于使自动助理执行响应动作而不必首先被显式地调用。如本文所使用的,“热命令”是指一个或多个词或短语,其在被说出时,由自动助理进行响应,而不需要自动助理首先被显式地调用并转化为自动助理尝试响应任何捕获的话语的完全收听/响应状态。
5.在一些实施方式中,话音辨识可以完全或至少部分地在诸如独立的交互式扬声器的客户端设备上实现,该客户端设备可以包括或可以不包括诸如显示器、相机和/或其他传感器的其他组件。在一些这样的实施方式中,自动助理可以对除了紧跟自动助理被调用之后的时间捕获的口头话语执行话音辨识处理。这些其他时间可以包括例如每当在计算设备附近检测到用户时、每当检测到用户话音并确定用户话音不是源自另一机器(诸如电视或收音机)时等。
6.换句话说,在一些实施方式中,实现配置有本公开的所选方面的自动助理的计算设备可以比常规自动助理对更多检测到的话语执行话音辨识处理,如上所述,常规自动助
理可能仅对在显式调用之后检测到的话语执行话音辨识处理。可以使用本文描述的技术来分析由该话音辨识处理生成的文本片段,以确定它们是否应该触发自动助理的响应动作、应该被登记为热命令,或者应该被忽略或丢弃。在许多实施方式中,即使与利用常规自动助理相比,针对更大部分检测到的话语生成文本片段,本文描述的技术也可以在客户端设备上本地执行,从而避免将文本片段传送到基于云的系统。
7.在一些实施方式中,可以基于各种“热命令登记标准”,在热命令库中选择性地登记热命令。一个热命令登记标准可以是——在显式调用自动助理之后接收的——文本命令满足文本命令语料库中的频率阈值。语料库可以与特定用户(例如,说话者)或与用户群体相关联。例如,假设特定用户调用自动助理某一阈值次数以发出特定命令“turn off the lights(关灯)”。在满足阈值之前,该命令在没有首先显式调用的情况下可能不会触发自动助理的响应动作。然而,一旦满足阈值(例如,用户已经调用自动助理十次以关灯),就可以在热命令库中登记文本命令“turn off the lights”。随后,每当相同的命令由相同的用户发出而没有首先调用自动助理时,自动助理仍然将采取响应动作,例如,通过关闭同一房间中的灯。
8.在一些实施方式中,特别是仅在显式调用自动助理之后执行话音辨识处理的那些实施方式中,在热命令库中登记文本命令可以使得前述设备上机器学习模型被进一步训练以检测向前推进的文本命令。在自动助理对在其他时间捕获的其他话语执行(加载)话音辨识处理的其他实施方式中,可以将由每个话语生成的文本片段与存储在热命令库中的文本片段进行比较。可能发生匹配,其中,例如,给定文本片段与热命令库中的记录足够相似和/或语义一致。
9.可以找到足够的相似性,其中,例如,存在文本片段与所登记的热命令之间的精确匹配,或者文本片段与所登记的热命令之间的编辑距离满足某个阈值(例如,小于某个编辑距离),或者甚至当文本片段的嵌入在热命令的嵌入的某个欧几里德距离内时。在一些实施方式中,热命令库可以仅存储先前登记的文本命令的嵌入。语义一致性可以存在于两个命令之间,其中,例如,命令的对应槽可以接收语义相似的值。例如,“set a time for ten minutes(将时间设置为十分钟)”和“set a timer for one hour(将定时器设置为一小时)”是语义一致的,因为它们共享的槽是时间间隔。
10.在其他实施方式中,基于不同于(或除了)热命令库中的登记的因素,由口头话语生成的文本片段可以被认为是热命令。例如,在一些实施方式中,可以对多个话语执行话音辨识处理(例如,不需要显式调用自动助理)以生成多个文本片段。同时,一个或多个视觉传感器可以生成视觉数据,该视觉数据在被分析时,揭示说话者在每个话语期间的凝视。如果在说出产生特定文本片段的特定话语时,说话者正在看在其上至少部分地实现自动助理的计算设备,则该特定文本片段可以被认为是热命令。
11.可以考虑的另一信号(例如,用于在热命令库中登记或用于确定给定文本片段是否意味着作为自动助理的命令)是一个或多个智能电器是否紧跟在捕获话语之后立即由人操作。假设用户说“turn on the lights(打开灯)”,但是然后另一个用户操作开关以打开一些智能灯。这将表明命令“turn on the lights”不应当被登记或解释为热命令。然而,假设在相同的场景中,智能灯未被打开并且随后静默。这可能表明命令“turn on the lights”应该至少在这种情况下被解释为热命令,并且还可以增加命令应当被登记为向前
推进的热命令的可能性,特别是如果这种场景多次发生。
12.在一些实施方式中,提供了一种由一个或多个处理器执行的方法,该方法包括:使用所述处理器中的一个或多个来操作自动助理;响应于触发事件,将所述自动助理从有限收听状态转化为完全话音辨识状态;在处于所述完全话音辨识状态时,由所述自动助理接收来自用户的口头命令;对所述口头命令执行话音辨识处理以生成文本命令;确定所述文本命令满足文本命令语料库中的频率阈值;以及响应于所述确定,将指示所述文本命令的数据登记为热命令,其中,在所述登记之后,与所述文本命令语义一致的另一文本命令的话语触发由所述自动助理执行响应动作,而不需要显式调用所述自动助理。
13.在各种实施方式中,触发事件可以包括检测到由麦克风捕获的音频数据中的一个或多个默认热词。在各种实施方式中,文本命令的语料库可以包括由所述用户生成的文本命令语料库。在各种实施方式中,文本命令语料库可以包括由包括所述用户的用户群体生成的文本命令语料库。
14.在各种实施方式中,该方法还可以包括将所述文本命令应用为跨机器学习模型的输入以生成输出。所述输出可以指示所述文本命令指向所述自动助理的概率,其中,所述登记进一步响应于所述概率满足阈值。在各种实施方式中,该方法可以进一步包括基于由一个或多个相机捕获的视觉数据来检测所述用户的凝视指向其上至少部分地实现所述自动助理的计算设备,其中,所述登记进一步响应于所述检测。
15.在各种实施方式中,登记可以进一步响应于确定在所述口头命令之后的预定时间间隔期间,没有检测到另外的话语。在各种实施方式中,登记可以进一步响应于确定在所述口头命令之后的预定时间间隔期间,人没有采取响应动作。
16.在各种实施方式中,所述方法可以进一步包括:响应于所述登记,将指示所述文本命令的数据或所述文本命令本身缓存在至少部分地实现所述自动助理的计算设备的本地存储器中。在各种实施方式中,所述方法可以进一步包括在所述登记之后,基于所缓存的数据触发所述文本命令,而无需显式地调用所述文本命令,以便缓存响应于所述文本命令的信息,其中,在所述触发之后,响应于所述文本命令的后续调用,输出所缓存的信息,以代替触发所述文本命令。在各种实施方式中,在所述缓存之后,所述文本命令的调用可以使得指示所述文本命令的所述数据通过局域网(“lan”)和个域网(“pan”)中的一个或两个直接传送到智能电器。在各种实施方式中,接收指示所述文本命令的所述数据可以使得所述智能电器执行响应动作。
17.在各种实施方式中,指示所述文本命令的所述数据可以包括模板,所述模板包括用于接收一个或多个后续参数的一个或多个槽,所述一个或多个后续参数与从所述用户接收的所述口头命令中提供的一个或多个参数语义一致。
18.在另一相关方面,一种使用一个或多个处理器实现的方法可以包括:接收在一个或多个麦克风处捕获的音频数据,其中,所述音频数据包括第一口头话语和第二口头话语;对所述音频数据执行话音辨识处理,以生成与所述第一口头话语和所述第二口头话语相对应的第一文本片段和第二文本片段;响应于确定所述第一文本片段满足一个或多个热命令标准,基于所述第一文本片段执行响应动作;以及响应于确定所述第二文本片段未能满足所述一个或多个热命令标准,丢弃或忽略所述第二文本片段而不执行另一响应动作。
19.在各种实施方式中,一个或多个热命令标准可以包括在热命令库中登记所考虑的
文本片段。在各种实施方式中,所述热命令库可以包括文本片段,所述文本片段在被说出时,触发由所述自动助理执行响应动作,而不需要检测一个或多个默认热词或将所述自动助理转化为活动收听状态。
20.在各种实施方式中,该方法可以进一步包括基于由一个或多个相机捕获的视觉数据来检测在用户提供所述第一口头话语时所述用户的第一凝视以及所述用户提供所述第二口头话语时所述用户的第二凝视。在各种实施方式中,一个或多个热命令标准可以包括凝视指向在其上至少部分地实现所述自动助理的计算设备。
21.另外,一些实施方式包括一个或多个计算设备的一个或多个处理器,其中,一个或多个处理器可操作以执行存储在相关联的存储器中的指令,并且其中,指令被配置为使得执行前述方法中的任何一个。一些实施方式还包括一个或多个非暂时性计算机可读存储介质,其存储可由一个或多个处理器执行以实现前述方法中的任何一个的计算机指令。
22.应当意识到,本文更详细描述的前述概念和附加概念的所有组合被设想为是本文公开的主题的一部分。例如,出现在本公开的结尾处的所要求保护的主题的所有组合被设想为是本文公开的主题的一部分。
附图说明
23.图1是可以实现本文公开的实施方式的示例性环境的框图。
24.图2a和2b示意性地描绘了根据各种实施方式的可以如何处理话语以调用自动助理的两个不同示例。
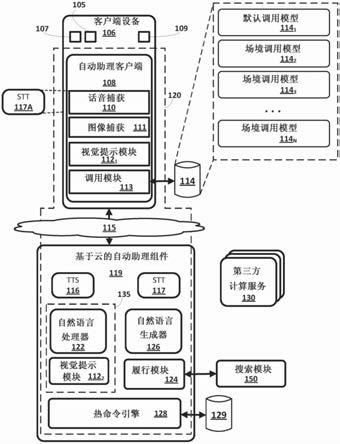
25.图3a、3b和3c示意性地描绘了根据各种实施方式的可以由配置有本公开的所选方面的自动助理和/或助理设备实施的示例性状态机的阶段。
26.图4a和4b描绘了用户与配置有本公开的所选方面的自动助理之间的示例性对话。
27.图5a和图5b描绘了用户与配置有本公开的所选方面的自动助理之间的更多示例性对话。
28.图6描绘了图示根据本文公开的实施方式的示例性方法的流程图。
29.图7描绘了示出根据本文公开的实施方式的示例性方法的流程图。
30.图8图示了计算设备的示例性架构。
具体实施方式
31.现在转到图1,图示了其中可以实现本文公开的技术的示例性环境。该示例性环境包括一个或多个客户端计算设备106。每个客户端设备106可以执行自动助理客户端108的相应实例,自动助理客户端108在本文中也可以被称为自动助理的“客户端部分”。可以在一个或多个计算系统(统称为“云”计算系统)上实现一个或多个基于云的自动助理组件119(在本文中也可以统称为自动助理的“服务器部分”),该一个或多个计算系统经由通常以115指示的一个或多个局域网和/或广域网(例如,因特网)通信地耦合到客户端设备106。
32.在各种实施方式中,自动助理客户端108的实例通过其与一个或多个基于云的自动助理组件119的交互的方式可以形成从用户的角度看似乎是自动助理120的逻辑实例的内容,用户可以参与与所述自动助理120的人机对话。这种自动助理120的一个实例在图1中以虚线示出。因此,应该理解到,与在客户端设备106上执行的自动助理客户端108接涉的每
个用户实际上可以与他或她自己的自动助理120的逻辑实例接涉。为了简洁和简单起见,本文中用作“服务”特定用户的术语“自动助理”将指在由用户操作的客户端设备106上执行的自动助理客户端108和一个或多个基于云的自动助理组件119(其可以在多个自动助理客户端108之间共享)的组合。还应该理解到,在一些实施方式中,自动助理120可以响应于来自任何用户的请求,而不管该自动助理120的特定实例是否实际上“服务”了该用户。
33.一个或多个客户端设备106可以包括例如以下中的一个或多个:台式计算设备、膝上型计算设备、平板计算设备、移动电话计算设备、用户车辆的计算设备(例如,车载通信系统、车载娱乐系统、车载导航系统)、独立的交互式扬声器(在某些情况下可能包括视觉传感器)、诸如智能电视的智能电器(或配备有具有自动助理能力的网络加密狗的标准电视)和/或包括计算设备的用户可穿戴装置(例如,具有计算设备的用户的手表、具有计算设备的用户的眼镜、虚拟或增强现实计算设备)。可以提供附加的和/或替代的客户端计算设备。一些客户端设备106(诸如独立的交互式扬声器(或“智能扬声器”))可以采取助理设备的形式,其主要被设计为促进用户和自动助理120之间的对话。一些这样的助理设备可以采取带附接显示器的独立交互式扬声器的形式,附接显示器可能是也可能不是触摸屏显示器。
34.在一些实施方式中,客户端设备106可以配备有具有一个或多个视场的一个或多个视觉传感器107,尽管这不是必需的。视觉传感器107可以采用各种形式,诸如数字相机、无源红外(“pir”)传感器、立体相机、rgbd相机等。一个或多个视觉传感器107可以例如通过图像捕获模块111使用来捕获其中部署了客户端设备106的环境的图像帧(静态图像或视频)。然后可以例如通过视觉提示模块1121来分析这些图像帧,以检测图像帧中包含的用户提供的视觉提示。这些视觉提示可以包括但不限于手势、对特定参考点的凝视、面部表情、用户的预定义运动等。这些检测到的视觉提示可以用于各种目的,诸如调用自动助理120和/或使得自动助理120采取各种动作。
35.附加地或可替代地,在一些实施方式中,客户端设备106可以包括一个或多个接近传感器105。接近传感器可以采取各种形式,诸如无源红外(“pir”)传感器、射频识别(“rfid”)、接收从另一附近电子组件发射的信号(例如,来自附近用户的客户端设备的蓝牙信号、从设备发射的高频或低频声音等)的组件等。附加地或可替代地,视觉传感器107和/或麦克风109也可以被用作接近传感器,例如,通过视觉和/或听觉地检测用户接近。
36.如本文中更详细描述的,自动助理120经由一个或多个客户端设备106的用户接口输入和输出设备参与与一个或多个用户的人机对话会话。在一些实施方式中,自动助理120可以响应于用户经由客户端设备106之一的一个或多个用户接口输入设备提供的用户接口输入而参与与用户的人机对话会话。在那些实施方式的一些中,用户接口输入明确地指向自动助理120。例如,用户可以口头提供(例如,键入、说出)预定的调用(“热”或“唤醒”)短语,诸如“ok,assistant(好,助理)”或“hey,assistant(嘿,助理)”,以使自动助理120主动开始收听或监视键入的文本。附加地或可替代地,在一些实施方式中,可以基于一个或多个检测到的视觉提示,单独地或与口头调用短语结合地调用自动助理120。
37.在一些实施方式中,即使当用户接口输入没有明确地指向自动助理120时,自动助理120也可以响应于用户接口输入而参与人机对话会话。例如,自动助理120可以检查用户接口输入的内容并响应于存在于用户接口输入中存在某些词项和/或基于其他提示而参与对话会话。在许多实施方式中,自动助理120可以利用话音辨识来将来自用户的话语转换为
文本,并例如通过提供搜索结果、一般信息和/或采取一种或多种响应动作(例如,播放媒体、启动游戏、点菜等)来对文本相应地做出响应。在一些实施方式中,自动助理120可以附加地或替代地对话语做出响应而无需将话语转换为文本。例如,自动助理120可以将语音输入转换为嵌入、转换为实体表示(指示语音输入中存在的实体/多个实体)和/或其他“非文本”表示,并对这样的非文本表示进行操作。因此,本文描述为基于从语音输入转换的文本进行操作的实施方式可以附加地和/或替代地直接对语音输入和/或语音输入的其他非文本表示进行操作。
38.客户端计算设备106和操作基于云的自动助理组件119的计算设备中的每一个可以包括用于存储数据和软件应用的一个或多个存储器、用于访问数据并执行应用的一个或多个处理器以及有助于通过网络进行通信的其他组件。由客户端计算设备106和/或自动助理120执行的操作可以分布在多个计算机系统上。自动助理120可以被实现为例如在通过网络彼此耦合的一个或多个位置中的一个或多个计算机上运行的计算机程序。
39.如上所述,在各种实施方式中,客户端计算设备106可以操作自动助理客户端108或自动助理120的“客户端部分”。在各种实施方式中,自动助理客户端108可以包括话音捕获模块110、上述图像捕获模块111、视觉提示模块1121和/或调用模块113。在其他实施方式中,话音捕获模块110、图像捕获模块111、视觉提示模块112和/或调用模块113的一个或多个方面可以例如通过一个或多个基于云的自动助理组件119与自动助理客户端108分开地实现。例如,在图1中,还存在可以检测图像数据中的视觉提示的基于云的视觉提示模块1122。
40.在各种实施方式中,可以使用硬件和软件的任何组合来实现的话音捕获模块110可以与诸如麦克风109或其他压力传感器的硬件对接以捕获用户话语的音频记录。在一些实施方式中,话语可以至少临时地被存储为缓冲器(诸如环形缓冲器)中的音频数据。出于各种目的,可以对该音频记录执行各种类型的处理。在一些实施方式中,可以使用硬件或软件的任何组合来实现的图像捕获模块111可以被配置为与视觉传感器107对接以捕获与视觉传感器107的视场相对应的一个或多个图像帧(例如,数字照片)。
41.在各种实施方式中,视觉提示模块1121(和/或基于云的视觉提示模块1122)可以使用硬件或软件的任何组合来实现,并且可以被配置为分析由图像捕获模块111提供的一个或多个图像帧,以检测在一个或多个图像帧中和/或跨一个或多个图像帧捕获的一个或多个视觉提示。视觉提示模块1121可以采用多种技术来检测视觉提示。例如,视觉提示模块1122可以使用被训练以生成指示图像帧中检测到的用户提供的视觉提示的输出的一个或多个人工智能(或机器学习)模型。
42.如前所述,话音捕获模块110可以被配置为例如经由麦克风109捕获用户的话音。附加地或可替代地,在一些实施方式中,话音捕获模块110可以进一步被配置为例如使用话音到文本(“stt”)处理技术(在本文中也被称为“话音辨识处理”),将所捕获的音频转换为文本和/或其他表示或嵌入。如图1所示,在一些实施方式中,话音捕获模块110可以包括除了或代替下文描述的基于云的stt模块117使用的板载stt模块117a。附加地或替代地,在一些实施方式中,话音捕获模块110可以被配置为执行文本到话音(“tts”)处理以例如使用一个或多个语音合成器,将文本转换为计算机合成的话音。
43.然而,在一些情况下,因为客户端设备106在计算资源(例如,处理器周期、存储器、
电池等)方面可能相对受限,所以客户端设备106本地的话音捕获模块110可以被配置为将有限数量的不同口头短语——特别是调用自动助理120的短语——转换为文本(或转换为其他形式,诸如较低维度的嵌入)。其他话音输入可以被发送到基于云的自动助理组件119,其可以包括基于云的tts模块116和/或基于云的stt模块117。
44.在各种实施方式中,调用模块113可以被配置为确定是否调用自动助理120,例如,基于由话音捕获模块110和/或视觉提示模块1121(在一些实施方式中,其可以在单个模块中与图像捕获模块111组合)提供的输出。例如,调用模块113可以确定用户的话语是否有资格作为应当发起与自动助理120的人机对话会话的调用短语。
45.在一些实施方式中,调用模块113可以单独地或结合由视觉提示模块1121检测到的一个或多个视觉提示来分析指示用户话语的数据,诸如音频记录或从音频记录提取的特征向量(例如,嵌入)。在一些实施方式中,当还检测到特定视觉提示时,可以降低由调用模块113采用以确定是否响应于口头话语而调用自动助理120的阈值。因此,即使当用户提供与正确的调用短语“ok assistant”不同但在发音上有些相似的有声话语时,该话语仍然可以在结合视觉提示(例如,说话者挥手、说话者直接凝视视觉传感器107等)检测到时被接受为正确的调用。
46.在一些实施方式中,调用模块113可以使用例如存储在设备上模型数据库114中的一个或多个设备上调用模型来确定话语和/或视觉提示是否有资格作为调用。可以训练这样的设备上调用模型以检测调用短语/手势的变化。例如,在一些实施方式中,可以使用训练示例来训练设备上调用模型(例如,一个或多个神经网络),每个训练示例包括来自用户的话语的音频记录(或提取的特征向量),以及指示与话语同时捕获的一个或多个图像帧和/或检测到的视觉提示的数据。在一些这样的实施方式中,设备上调用模型114可以以捕获的话语构成意图唤醒自动助理120的调用短语的概率p的形式生成输出。
47.在图1中,设备上模型数据库114可以存储一个或多个设备上调用模型114
1-114n。在一些实施方式中,可以训练默认设备上调用模型1141以在音频记录或指示其的其他数据中检测一个或多个默认调用短语或热词,诸如先前提到的那些短语或热词(例如,“ok assistant”,“hey,assistant”等)。在一些这样的实施方式中,这些模型可以总是可获得并且可用于将自动助理120转化为完全收听状态,其中,可以如下所述(例如,在客户端设备106上或通过一个或多个基于云的自动助理组件119)使用自动助理120的其他组件处理由话音捕获模块110(至少在调用之后的一段时间内)捕获的任何音频记录。
48.另外,在一些实施方式中,设备上模型数据库114可以至少临时地存储一个或多个附加“场境调用模型”114
2-114n。这些场境调用模型114
2-114n可以在特定场境中由调用模块113使用和/或可供它们获得。场境调用模型114
2-114n可以被训练以例如在音频记录或指示其的其他数据中检测一个或多个特定于场境的热词。在一些实施方式中,场境调用模型114
2-114n可以根据需要从例如形成基于云的自动助理组件119的一部分但也可以全部或部分在客户端设备106上实现的热词命令引擎128中有选择地下载,这将在下面更详细地描述。
49.在各种实施方式中,当调用模块113使用场境调用模型114
2-114n检测到各种动态热词时,它可以将自动助理120转化为前面所述的完全收听状态。附加地或可替代地,调用模块113可以将自动助理120转化为在其中执行一个或多个特定于场境的响应动作的特定
于场境的状态,而需要或无需将自动助理120转化为一般收听状态。在许多情况下,触发将自动助理120转化为特定于场境的状态的音频数据可能不会被传送到云。相反,可以完全在客户端设备106上执行一个或多个特定于场境的响应动作,这可以减少响应时间和传送到云的信息量,这从隐私的角度来看可能是有益的。
50.在一些实施方式中,自动助理120,并且更具体地,话音捕获模块110,可以对在除了与自动助理120的调用同时发生的情况下检测到的话语执行stt处理。例如,在一些实施方式中,话音捕获模块110可以对所有捕获的话语、对在特定场境中捕获的话语等执行stt处理。然后,可以由本文描述的各种组件分析由该stt处理生成的文本,以例如调用自动助理120、执行各种响应动作等。
51.基于云的tts模块116可以被配置为利用云的实际上无限的资源来将文本数据(例如,由自动助理120制定的自然语言响应)转换为计算机生成的话音输出。在一些实施方式中,tts模块116可以将计算机生成的话音输出提供给客户端设备106以例如使用一个或多个扬声器直接输出。在其他实施方式中,可以将由自动助理120生成的文本数据(例如,自然语言响应)提供给话音捕获模块110,然后,话音捕获模块110可以将文本数据转换为本地输出的计算机生成的话音。
52.基于云的stt模块117可以被配置为利用云的实际上无限的资源来将话音捕获模块110捕获的音频数据转换为文本,然后可将其提供给意图匹配器135。在一些实施方式中,基于云的stt模块117可以将化音的音频记录转换为一个或多个音素,然后将一个或多个音素转换为文本。附加地或可替代地,在一些实施方式中,stt模块117可以采用状态解码图。在一些实施方式中,stt模块117可以生成用户话语的多个候选文本解释。在一些实施方式中,stt模块117可以取决于是否存在同时检测到的视觉提示来使特定候选文本解释加权或偏置得比其他候选文本解释更高。
53.自动助理120(特别是基于云的自动助理组件119)可以包括意图匹配器135、前述tts模块116、前述stt模块117以及下面更详细描述的其他组件。在一些实施方式中,可以在与自动助理120分离的组件中省略、组合和/或实现模块和/或自动助理120的模块中的一个或多个。在一些实施方式中,为了保护隐私,可以至少部分地在客户端设备106上(例如,排除在云之外)实现自动助理120的一个或多个组件,诸如自然语言处理器122、tts模块116、stt模块117等。
54.在一些实施方式中,自动助理120响应于在与自动助理120的人机对话会话期间,由客户端设备106之一的用户生成的各种输入来生成响应内容。自动助理120可以(例如,当与用户的客户端设备分开时通过一个或多个网络)提供响应内容,以作为对话会话的一部分呈现给用户。例如,自动助理120可以响应于经由客户端设备106提供的自由形式的自然语言输入而生成响应内容。如本文所使用的,自由形式的输入是由用户制定的并且不限于呈现给用户以选择的选项组的输入。
55.如本文中所使用的,“对话会话”可以包括在用户与自动助理120(在一些情况下,其他人类参与者)之间的一个或多个消息的逻辑上自包含的交换。自动助理120可以基于各种信号来区分与用户的多个对话会话,该各种信号诸如是会话之间的时间流逝、会话之间的用户场境(例如,位置、预定会议之前/之中/之后等)的改变、检测到除了用户和自动助理之间的对话之外的用户与客户端设备之间的一个或多个中间交互(例如,用户切换应用一
段时间,用户走开、然后稍后返回到独立的语音激活产品)、会话之间的客户端设备的锁定/休眠、用于与自动助理120的一个或多个实例对接的客户端设备的改变等。
56.意图匹配器135可以被配置为基于用户提供的输入(例如,有声话语、视觉提示等)和/或基于其他信号(诸如传感器信号和在线信号(例如,从web服务获得的数据)等)来确定用户的意图。在一些实施方式中,意图匹配器135可以包括自然语言处理器122和上述基于云的视觉提示模块1122。在各种实施方式中,除了基于云的视觉提示模块1122可以拥有更多资源自行支配之外,基于云的视觉提示模块1122可以类似于视觉提示模块1121来操作。特别地,基于云的视觉提示模块1122可以检测可以由意图匹配器135单独或与其他信号结合使用的视觉提示以确定用户的意图。
57.自然语言处理器122可以被配置为处理由用户经由客户端设备106生成的自然语言输入,并且可以生成注释输出(例如,以文本形式)以供自动助理120的一个或多个其他组件使用。例如,自然语言处理器122可以处理由用户经由客户端设备106的一个或多个用户接口输入设备生成的自然语言自由格式输入。所生成的注释输出包括自然语言输入的一种或多种注释和/或自然语言输入的一个或多个(例如,全部)词项。
58.在一些实施方式中,自然语言处理器122被配置为识别和注释自然语言输入中的各种类型的语法信息。例如,自然语言处理器122可以包括形态学模块,该形态学模块可以将各个词分成词素和/或例如以词素的类别来注释这些词素。自然语言处理器122还可以包括词性标记器,该词性标记器被配置为利用其语法角色来注释词项。例如,词性标记器可以利用其词性(诸如“名词”、“动词”、“形容词”、“代词”等)来标记每个词项。此外,例如,在一些实施方式中,自然语言处理器122可以附加地和/或可替代地包括被配置为确定自然语言输入中的词项之间的句法关系的依赖性解析器(未描绘)。例如,依赖性解析器可以确定哪些词项修改了句子的其他词项、主语和动词等等(例如,解析树)——并且可以对这种依赖性进行注释。
59.在一些实施方式中,自然语言处理器122可以附加地和/或可替代地包括实体标记器(未描绘),该实体标记器被配置为注释一个或多个段中的实体指涉,诸如对人(包括例如文学人物、名人、公众人物等)、组织和位置(真实的和虚构的)等的指涉。在一些实施方式中,关于实体的数据可以被存储在一个或多个数据库中,诸如知识图(未描绘)中。在一些实施方式中,知识图可以包括代表已知实体(在一些情况下,实体属性)的节点以及连接节点并代表实体之间关系的边。例如,“banana(香蕉)”节点可以(例如,作为孩子)连接到“fruit(水果)”节点,该“fruit”节点继而可以(例如,作为孩子)连接到“produce(产品)”和/或“food(食物)”节点。作为另一示例,被称为“hypothetical caf
é
(假想咖啡馆)”的餐厅可以由还包括诸如其地址、所供应食物的类型、时间、联系人信息等的属性的节点表示。在一些实施方式中,可以将“hypothetical caf
é”
节点通过(例如,表示孩子到父亲的关系的)边连接到一个或多个其他节点(诸如“restaurant(餐厅)”节点、“business(企业)”节点、标识餐厅所在城市和/或州的节点等)。
60.自然语言处理器122的实体标记器可以以较高的粒度级别(例如,以使得能够识别对诸如人的实体类别的所有指涉)和/或较低的粒度级别(例如,以使得能够识别对特定实体(诸如特定人员)的所有指涉)来注释对实体的指涉。实体标记器可以依赖于自然语言输入的内容来消解特定实体和/或可以可选地与知识图或其他实体数据库进行通信来消解特
more movies like this(给我找更多这样的电影)”之类的东西。
66.在一些实施方式中,自动助理120可以充当用户与一个或多个第三方计算服务130(或“第三方代理”或“代理”)之间的中介。这些第三方计算服务130可以是接收输入并提供响应输出的独立软件过程。一些第三方计算服务可以采取第三方应用的形式,该第三方应用可以或可以不在与例如操作基于云的自动助理组件119的那些计算系统分开的计算系统上操作。意图匹配器135可以识别的一种用户意图是与第三方计算服务130接涉。例如,自动助理120可以向服务提供对应用编程接口(“api”)的访问以用于控制智能设备。用户可以调用自动助理120并提供诸如
““
i’d like to turn the heating on(我想打开供暖)”的命令。意向匹配器135可以将该命令映射到语法,该语法触发自动助理120以与第三方服务接涉,从而使得用户的供暖打开。第三方服务130可以为自动助理120提供需要被填充的最小槽列表,以实现(或“消解”)打开供暖的命令。在该示例中,槽可以包括供暖将被设定到的温度以及供暖将被打开的持续时间。自动助理120可以生成自然语言输出并(经由客户端设备106)将其提供给用户,该自然语言输出索求槽的参数。
67.履行模块124可以被配置为接收由意图匹配器135输出的预测/估计的意图以及相关联的槽值(无论是由用户前摄地提供还是从用户那里索求的)并履行(或“消解”)意图。在各种实施方式中,用户意图的履行(或“消解”)可以例如通过履行模块124来生成/获得各种履行信息(也被称为“响应”信息或“消解信息”)。如下面所描述的,在一些实施方式中,可以将履行信息提供给自然语言生成器(在一些附图中为“nlg”)126,其可以基于履行信息来生成自然语言输出。
68.履行(或“消解”)信息可以采取各种形式,因为可以以多种方式履行(或“消解”)意图。假设用户请求纯粹的信息,诸如“where were the outdoor shots of
‘
the shining’filmed?(“the shining”的户外镜头在哪里拍摄的?)”可以例如通过意图匹配器135将用户的意图确定为搜索查询。可以将搜索查询的意图和内容提供给履行模块124,如图1所示,该模块可以针对响应信息与被配置为搜索文档和/或其他数据源(例如知识图等)的语料库的一个或多个搜索模块150通信。履行模块124可以向搜索模块150提供指示搜索查询的数据(例如,查询的文本、降维嵌入等)。搜索模块150可以提供响应信息,诸如gps坐标或其他更明确的信息,诸如“timberline lodge,mt.hood,oregon(山林小屋,胡德,俄勒冈州)。”该响应信息可以形成由履行模块124生成的履行信息的一部分。
69.附加地或可替代地,履行模块124可以被配置为例如从意图匹配器135接收用户的意图以及由用户提供或使用其他方式(例如,用户的gps坐标、用户偏好等)确定的任何槽值并触发响应操作。响应动作可以包括例如订购商品/服务、启动定时器、设置提醒、发起电话呼叫、播放媒体、操作智能电器、发送消息等。在一些这样的实施方式中,履行信息可以包括与履行、确认响应(在一些情况下,可以从预定响应中选择)等相关联的槽值。
70.自然语言生成器126可以被配置为基于从各种来源获得的数据来生成和/或选择自然语言输出(例如,被设计为模仿人类话音的词/短语)。在一些实施方式中,自然语言生成器126可以被配置为将与意图的履行相关联的履行信息接收为输入,并且基于履行信息生成自然语言输出。附加地或可替代地,自然语言生成器126可以从诸如第三方应用之类的其他源接收信息(例如,所需的槽),其可以用来为用户编写自然语言输出。
71.热命令引擎128可以被配置为基于各种信号,将文本命令选择性地登记为例如数
据库129中的热命令。尽管在图1中被描绘为基于云的自动助理组件119的一部分,但是在各种实施方式中,热命令引擎128和/或数据库129可以附加地或可替代地全部或部分地在一个或多个客户端设备106中实现。同样地,在一些实施方式中,数据库129可以全部或部分地维护在客户端设备106上,其包括为特定用户(例如,控制客户端设备106的用户)登记的热命令。
72.在各种实施方式中,热命令引擎128可以被配置为确定例如由stt 117a/117生成的文本命令满足文本命令语料库(例如,在调用自动助理120之后接收的文本命令语料库)中的频率阈值。例如,文本命令可以在过去的文本命令的语料库中出现超过某个最小次数,或者可以以匹配或超过某个最小阈值的某个频率或百分比出现。响应于该确定,热命令引擎128可以将指示文本命令的数据登记在数据库129(和/或客户端设备106的本地数据库)中。指示文本命令的这些数据可以包括或可以不包括逐字的文本命令本身、由热命令生成的嵌入、由热命令生成的模板或语法(下面描述)等。在由热命令引擎128登记之后,与文本命令匹配或语义一致的另一文本命令的话语可以触发由自动助理120执行响应动作,而不需要显式调用自动助理120。
73.在一些实施方式中,由热命令引擎128使用本文描述的技术登记的热命令可以被存储为包括一个或多个槽的语法或“模板”。在一些情况下,这些槽可以由通配符或其他类似机制表示,使得槽可以接收与导致热命令被登记的口头命令中提供的参数语义一致的后续参数。当两个不同的值在槽中可互换使用时,它们是“语义一致的”。
74.例如,假设随着时间的推移,用户在调用自动助理120之后发出以下命令:“set a timer for five minutes(将定时器设置为五分钟)”、“set a timer for twenty minutes(将定时器设置为二十分钟)”和“set a timer for one hour(将定时器设置为一小时)”。值“five minutes(五分钟)”、“twenty minutes(二十分钟)”和“one hour(一小时)”是语义一致的——它们都指时间间隔。因此,可以生成和登记热命令模板,诸如“set a timer for《time》(将定时器设置为《时间》”等),使得用户在发出语义一致的向前推进的命令之前,不需要调用自动助理120。
75.除了时间间隔之外的其他值也可以彼此语义一致。例如,在控制智能电器的场境中,不同的智能灯识别(例如,“kitchen light 1(厨房灯1)”、“living room light 4(客厅灯4)”、“den lights(卫生间灯)”、“back porch lights(后廊灯)”)可能是语义一致的。同样地,可使用类似命令控制的电器可以在语义上是一致的。例如,模板“turn the《appliance》up(打开《电器》)”可以是指音频系统的音量、恒温器温度、烤箱温度、空调、智能灯的光强度等。不同的人也可以在热命令的上下文中在语义上是一致的——例如,“send a message to《person’s name》(向《人名》发送消息)”可以被用来根据谁的姓名被插入到槽中而向不同的人发送消息。
76.取决于在客户端设备106处和/或在话音捕获模块110处可用的功能,可以以各种方式调用自动助理120。图2a-b示意性地描绘了用于调用自动助理120以使自动助理120执行响应动作的两个示例性流水线。本公开的所选方面可全部或部分地在任一流水线上或在与图2a-b中所描绘的流水线共享各种特性的其他流水线上实现。
77.图2a描绘了自动助理120主要依赖于基于云的stt模块117来执行话音辨识处理的流水线。从左开始,话语由话音捕获模块110捕获,例如作为录制的音频数据。话音捕获模块
110从所录制的音频数据中提取各种音频特征,诸如音素、语调、音高、节奏等。调用模块113将这些特征应用为跨调用模型114的输入,以生成所捕获的话语是意指调用自动助理120的概率p。
78.如果在240处,p未能满足t,则可以在242处忽略/丢弃话语。然而,在240处,如果p满足某个阈值t(例如,p》0.75、p》0.65、p》0.9等),则处理可以返回到话音捕获模块110,其可以捕获/缓冲包含在先前处理的话语之后、之前发出或与先前处理的话语混合的口头命令的音频数据。话音捕获模块110可以将该命令数据(例如,原始音频数据、嵌入等)传递到stt模块117(基于云的或板载客户端设备106)以进行话音辨识处理。
79.stt模块117可以生成文本命令,该文本命令然后被提供给意图匹配器135,意图匹配器135可以如上所述处理命令(例如,经由自然语言处理器122)。可以将由意图匹配器135确定的意图提供给履行模块124。履行模块124可以例如通过执行一个或多个响应动作来履行如前所述的意图。如图2a底部的间隔所示,直到自动助理120被成功调用并且话音捕获模块110捕获/缓冲口头命令为止,自动助理120可以处于“受限收听状态”,其中,它主要或专门响应于默认热词或其他调用触发(例如,按下热键)。在调用之后,自动助理120处于“完全收听状态”,其中,它将对由话音捕获模块110捕获的任何话语执行stt处理并尝试履行由话音捕获模块110捕获的任何话语。
80.图2b描绘了stt处理主要或专门在客户端设备106上实现的可替代流水线。在设备上执行stt处理可以呈现各种技术优点,诸如通过向云发送较少数据并且特别通过减少与口头命令的解释相关联的时延来保护隐私。在许多情况下,使用图2b的流水线处理的口头命令可以比使用图2a的流水线发布的口头命令快得多地被处理。这在登记的热命令和/或指示登记的热命令的数据被本地缓存在例如客户端设备106的存储器中的实施方式中尤其如此,如下面将描述的。
81.在图2b中,话语由话音捕获模块110捕获。话音捕获模块110生成音频数据并将其提供给stt模块117a(板载客户端设备106)。stt模块117a执行话音辨识处理以生成文本数据(图2b中的“txt.”),该文本数据被提供给下游组件,诸如调用模块113和/或热命令引擎128。
82.无论哪个下游组件从stt模块117a接收文本数据,该组件都可以在244处分析文本以做出决定。如果分析揭示话语是意图调用自动助理120的默认热词或短语,则处理可以返回到话音捕获模块110,其可以从缓冲器接收和/或提供包含口头命令(其可以在初始话语之后、之前或与初始话语混合)的附加音频数据。然后,处理可以通过如前所述的组件117、135和124进行。
83.然而,在244处,可以替代地确定文本数据包含热命令。如果是这种情况,则可能不需要额外的stt处理。相反,并且如图2b所示,可以将热命令直接提供给意图匹配器135,意图匹配器135可以生成意图以供履行模块124处理。基于各种因素,文本片段可以被认为是热命令。在一些实施方式中,如果文本命令与登记的热命令类似,例如在语义上一致,则文本命令可以被认为是热命令。
84.附加地或可替代地,在一些实施方式中,文本命令可以被应用为跨经训练的机器学习模型的输入以生成输出。输出可以指示文本命令指向自动助理120的概率。在一些实施方式中,可以使用在用户显式地调用自动助理120之后由用户发出的自由形式命令/查询来
训练机器学习模型。
85.附加地或可替代地,如图2b中的虚线箭头所描绘的,在一些实施方式中,不是将登记的热命令发送到意图匹配器135,而是作为登记过程的一部分,例如在客户端设备106上本地缓存所登记的热命令。在一些这样的实施方式中,当随后在口头话语中检测到所登记的热命令时,可以基于缓存的登记的热命令来触发响应动作,而无需基于云的自动助理组件119处理登记的热命令。
86.在一些实施方式中,可以缓存响应于文本命令的信息,诸如搜索结果。可以响应于热命令的后续调用而输出缓存的信息,以代替文本命令被触发。例如,假设用户经常询问自动助理120“what’s the weather today?”该查询可以被登记为热命令。在一些这样的实施方式中,可以例如周期性地、随机地、每天早晨等将查询自动提交给适当的搜索引擎。当用户稍后询问“what’s the weather today?”(例如,不必首先调用自动助理120)时,响应数据可能已经被缓存,使得自动助理120可以以很少或没有可辨别的时延来输出天气。
87.缓存的热命令不限于搜索查询。在一些实施方式中,用于控制智能电器的热命令可以在板载客户端设备106上被缓存(例如,作为登记过程的一部分),例如,以避免与基于云的自动助理组件119通信和/或减少时延。此类热命令的后续调用可以使得指示热命令的数据直接传送到智能电器。如本文所使用的,“直接”向智能电器传送数据可以指通过局域网(“lan”)和/或个域网(“pan”)中的一个或两个向智能电器传送数据,而无需通过一个或多个广域网(“wan”)与远程组件(例如,119)交换数据。
88.例如,诸如智能灯或智能锁的一些智能电器可以使用诸如蓝牙、网状网络等技术,与桥接组件进行无线通信。桥接组件继而可以经由一个或多个其他类型的无线网络(诸如wi-fi)到达。换句话说,桥接组件充当智能电器驻留在其上的第一无线通信网络(例如,蓝牙、网格)与用户通常在其上操作客户端设备106的第二无线通信网络(例如,wi-fi)之间的“桥接”。
89.缓存的热命令(或指示其的数据)可以直接从客户端设备106传送到桥接组件——或者如果不存在桥接组件,则传送到智能电器本身——而无需与基于云的自动助理组件119交换任何数据。接收到指示缓存的热命令的数据可以使得智能电器执行响应动作。例如,假设命令“turn on the lights”被登记为热命令。在一些实施方式中,该登记可以包括实际传达到灯(或控制灯的桥接组件)的命令数据被缓存。因此,当稍后检测到热命令时,该缓存的数据可以立即通过lan/pan传送到灯/桥接组件,具有很少或没有可辨别的时延。
90.利用图2b的流水线,自动助理120与利用图2a的流水线相比更频繁地执行stt处理。因此,不是具有如图2a中的“有限收听状态”,而是在图2b中,自动助理120具有在本文中被称为“选择性响应状态”的状态,其中,自动助理选择性地响应于文本命令/查询,如先前参考244的做出决定所描述的。如果自动助理120例如利用默认热词被显式地调用,则自动助理120可以转化到“完全响应状态”。
91.在选择性响应状态下,自动助理120基于各种因素选择性地响应文本命令。一个这样的因素是文本命令(或类似的文本命令,或匹配的语法/模板)先前是否被登记为热命令。另一个因素是说话者的凝视是否指向计算设备,该计算设备至少从用户的角度来看似乎实现了自动助理120的至少一部分。本文考虑了其他因素。在图2b的实施方式的完全响应状态下,自动助理120可以将指示其检测到的任何话语的数据(例如,stt文本输出)传送到基于
云的自动助理组件119以进行附加处理。
92.图3a-c示意性地描绘了根据各种实施方式的可以由配置有本公开的所选方面的自动助理(例如,120)和/或助理设备(例如,106)实现的示例性状态机的阶段。从图3a的左侧开始,自动助理120可以开始或默认为第一状态,其可以是图2a的有限收听状态或图2b的选择性响应状态。在检测到一个或多个默认热词(图3a-c中的“diw”)时,自动助理120可以转化到第二状态,其可以对应于图2a的完全收听状态或图2b的完全响应状态。
93.在第二状态下,自动助理120可以等待任何自由形式的输入,诸如口头话语。在检测到自由形式输入时,自动助理120可以至少临时转化到“命令登记分析”状态。在命令登记分析状态中,自动助理120例如通过热命令引擎128,可以基于各种因素来确定自由形式输入是否应当被登记为将来可用的热命令,而不需要自动助理120从第一状态转化到第二状态。虽然与“一般处理”串行地示出,但是在一些实施方式中,可以并行执行命令登记分析和一般处理,或者可以在一般过程之后执行命令登记分析,例如,以确保命令有效并且自动助理120能够响应。
94.在命令登记分析期间考虑的因素中的主要因素是接收命令或语义上一致的命令的频率。例如,可以将接收到命令或语义一致命令的次数的计数与阈值进行比较。如果满足阈值,则可以将文本命令或从命令及其槽聚合的模板/语法登记为可用于向前推进的热命令,而不需要显式地调用自动助理120。同时,无论自由形式输入是否被登记为热命令,它都可以经受一般处理(例如,通过意图匹配器135和/或履行模块124)以执行响应动作。
95.图3b描绘了在作为命令登记分析的结果已经登记了第一登记热命令(“ehc
1”)之后的图3a的状态机。现在,当自动助理120处于第一状态时,它可以如之前那样被调用到第二状态。然而,自动助理120还可以响应于第一登记热命令ehc1来执行第一响应动作(“响应动作1”)。如虚线箭头所示,在一些实施方式中,一旦执行第一响应动作,自动助理120就可以转化到第二状态,例如,使得用户可以利用用户希望的任何查询来跟进所登记的热命令。该登记过程可以在将来重复。例如,图3c描绘了在已经登记另一登记热命令(“ehc
2”)之后的自动助理120的状态机。
96.图4a和4b展示了根据本文描述的实施方式,用户101和自动助理的实例(图4a-b中未描绘)之间的人机对话会话可以如何经由客户端计算设备406的麦克风和扬声器(被描绘为独立的交互式扬声器,但这并不意味着限制)发生的一个示例。自动助理120的一个或多个方面可以在计算设备406上和/或在与计算设备406网络通信的一个或多个计算设备上实现。
97.在图4a中,用户101使用默认热短语“hey assistant”调用自动助理120。这可以使得自动助理120从图3a-c中的第一状态转化到第二状态。然后,用户101说出“set a timer for five minutes”。可以根据图3a-c的命令登记分析和一般处理来处理该短语。对于该示例,假设用户101(和/或其他用户,取决于实施方式)已经发出该命令或语义上一致的命令(例如,“set a timer for ten minutes”)达某一数目,该某一数目满足某一最小热命令登记阈值。
98.自动助理120可以首先通过设置定时器并说出“ok.timer starting
…
now(好的,定时器现在开始...)”来响应。然而,因为命令(和/或语义一致的命令)满足热命令登记标准(例如,先前提及的最小热命令登记阈值),所以自动助理120将命令(或更一般地,由该命
令及其槽生成的模板或语法)登记为登记的热命令。在这样做时,自动助理通知用户101“i see that you issue this command often,so i have changed my settings so that you no longer need to wake me up before issuing that command
…
you can just say set a timer for x minutes(我看到你经常发出该命令,所以我已经改变了我的设置,使得你在发出该命令之前不再需要唤醒我
…
你可以仅说将定时器设置为x分钟)”因此,并且如图4b所示,用户101稍后可以简单地说出命令“set a timer for six minutes”,并且自动助理120将首先启动定时器而无需被显式调用。
99.除了使用频率之外或代替使用频率,在一些实施方式中,可以使用其它因素和/或信号来确定命令是否应当被解释为热命令,和/或是否将命令登记为向前推进的热命令。附加地或可替代地,在一些实施方式中,命令的一个接一个的重复话语可以使命令被解释和/或登记为热命令。直观地,如果用户说出类似“turn the lights red(将灯变为红色)”的内容,然后重复相同的内容一次或多次,这表明用户正在等待自动助理120将灯变为红色。
100.图5a-b描绘了用户101的凝视被用来确定用户的话语是否意在用于自动助理120的示例。用户101再次与至少部分地在客户端设备506c上操作的自动助理120接涉。客户端设备506c包括视觉传感器507c,该视觉传感器507c生成视觉数据,该视觉数据可以被分析以确定用户凝视的方向。还存在两个其它客户端设备——膝上型计算机506a和智能电视506b——并包括相应的视觉传感器507a和507b。
101.在图5a中,用户101在不首先调用自动助理120的情况下说“turn on the lights”。可以例如使用凝视检测算法来分析由视觉传感器507a-c中的一个或多个生成的视觉数据,以确定用户凝视的方向。如果用户101正在看客户端设备506a-c中的任何一个的方向(如图5a中的虚线箭头所示),则这可以是单独或与其他信号组合使用以确定命令是否应当由自动助理120响应的信号。在图5a的情况下,自动助理120以“ok.turning on three lights(好的。打开三个灯)”作为响应。
102.与图5b形成对比,其中,第一用户101a向另一用户101b说出“turn on the lights”。如虚线箭头所示,第一用户101a的凝视指向第二用户101b。这可以使用由它们相应的视觉传感器507a-c中的一个或多个捕获的视觉数据,基于由客户端设备506a-c中的一个或多个收集的视觉数据来再次检测。因此,在假设第二用户101b被指令打开灯的情况下,自动助理120不采取动作。
103.在一些实施方式中,例如,由于说话者所处的位置(例如,在任何视觉传感器507的视野之外),说话者的凝视方向可能不可用或不可确定。或者,可能没有足够的硬件资源(诸如视觉传感器)来确定说话者的凝视方向。然而,可以分析来自其他传感器(诸如麦克风或接近传感器)的信号,以确定多个人是否共存于该区域中。如果存在多个人,如图5b中所示,则这可能不利于将那些人中的某个人潜在地向那些人中的另一个人所说的内容解释为指向自动助理120的命令。
104.在一些实施方式中,可以将由用户101的话语生成的文本数据应用为跨上述机器学习模型的输入,以生成命令指向自动助理120的概率。该概率可能不是独自决定性的——毕竟,“turn on the lights”是房间中的另一个人可以遵循的命令——但是结合用户101针对自动助理120可以至少被感知为正在其上执行的客户端设备的凝视,组合信号可能足以触发自动助理120的响应。附加地或可替代地,在一些实施方式中,不是检测用户的凝视
方向,而是可以确定用户101是否是单独的。如果答案为是,则即使没有检测到他或她的凝视方向,也可以推断用户101正在针对自动助理120提议。
105.图6是图示根据本文公开的实施方式的示例性方法600的流程图。为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括各种计算机系统的各种组件,诸如自动助理120的一个或多个组件。此外,虽然方法600的操作以特定顺序示出,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
106.在框602处,系统可以至少部分地在一个或多个客户端设备(诸如106、406或506a-c)上操作自动助理120。在框604处,系统可以监视一个或多个触发事件。例如,系统可以针对意图调用自动助理120的一个或多个默认热词来监视在一个或多个麦克风处捕获的音频数据。如上所述,在一些实施方式中,这可能涉及提取音频数据的特征并将其应用为跨一个或多个调用模型114的输入。在其他实施方式中,系统可以对捕获话语的音频数据执行话音辨识处理(在本文中也称为stt处理)。可以分析最终生成的文本片段以确定其是否包含热词。在一些实施方式中,除了检测到默认热词之外的事件可以调用自动助理120,诸如按下一个或多个硬键或软键、在视觉传感器前面做出手势、在握住可访问自动助理120的移动电话的同时做出特定手势或运动等。
107.如果在框606处未检测到一个或多个触发事件,则方法600可以返回到框604。然而,如果框606处的答案为是,则在框608处,系统可以将自动助理120从诸如有限收听状态(图2a)或选择性响应状态(图2b)的第一状态转化到诸如完全话音辨识状态(图2a)或完全响应状态(图2b)的第二状态。
108.当处于第二状态时,在框610处,系统例如通过话音捕获模块110可以从用户接收口头命令,该口头命令可以被捕获为音频数据。在框612处,系统例如通过基于云的stt模块117或本地stt模块117a,可以对由在框610处接收的口头命令生成的音频数据执行话音辨识处理,以生成文本命令。
109.在框614处,系统例如通过热命令引擎128可以确定文本命令是否满足文本命令语料库中的频率阈值(图3a-c的命令登记分析)。在各种实施方式中,文本命令语料库可以是由说话用户生成的文本命令语料库,或者是由包括用户的用户群体生成的文本命令语料库。在一些实施方式中,在框616处,可以将与文本命令相关联的计数与频率阈值进行比较。该计数可以以各种方式确定,如下面所述。
110.在框616处,如果满足阈值,则在框618处,系统可以将指示文本命令的数据登记为热命令。在框618处的登记之后,与文本命令匹配或在语义上一致(例如,与模板/语法匹配)的另一文本命令的话语可以触发由自动助理120执行响应动作,而不需要显式调用自动助理120。
111.在一些实施方式中,只有引起热命令的登记的同一用户然后可以使用热命令来触发自动助理120的动作而无需调用。可以使用例如说话者辨识处理、面部辨识处理(例如,当存在一个或多个相机时)等,跨多个对话会话来识别该用户。在其他实施方式中,一旦热命令被登记,则它可以被超过使其被登记的用户(诸如其他注册用户(例如,家庭成员)或全体用户)使用。
112.在一些实施方式中,在可选框620处,系统可以将指示文本命令的数据(诸如文本命令本身)缓存在至少部分地实现自动助理120的一个或多个客户端设备106的本地存储器
中。这可以提供与自动助理120在将来响应类似命令时的时延有关的各种益处。例如,在一些实施方式中,可以自动地(例如,周期性地)触发文本命令,而无需人显式地调用文本命令,以便缓存响应于文本命令的信息。这在文本命令使得自动助理120输出对诸如“what’s the weather outside?(外面的天气怎么样?)”或“what’s on my calendar today?(今天我的日历上有什么?)”之类的查询的信息响应特别有用。周期性地重新缓存的信息可以由自动助理120直接响应于对文本命令的后续调用而输出,代替文本命令例如在基于云的自动助理组件119处被远程处理以消解说话者的请求。
113.在一些实施方式中,可以缓存控制智能电器的登记的热命令(或指示其的数据),以在将来指令自动助理120控制这些智能电器时改善时延。调用这种缓存的文本命令可以使文本命令或指示文本命令的数据(诸如被配置为控制专用智能电器的专用指令)通过lan和pan中的一个或两个直接传送到智能电器。如前所述,接收到文本命令或指示其的数据可以使智能电器执行响应动作。所有这些都可以发生,而无需例如在基于云的自动助理组件119处远程处理文本命令。
114.在框618(或可选框620)之后,方法600然后可以进行到框622,此时自动助理120可以执行响应动作。如果框616处的回答为否,则方法600可以直接进行到框622,跳过框618-620。在一些实施方式中,此时,可以递增与命令相关联的计数。在一些实施方式中,每当任何人或作为预定义群组的成员的任何人(例如,注册为家庭的一部分的用户)发出命令时,可以递增特定文本命令的计数。在一些实施方式中,可以跨客户端设备(例如,家庭中包含的智能扬声器、智能电话、平板电脑、助理设备)的协调生态系统累加特定文本命令的计数。例如,一个或多个用户可以具有与自动助理120相关联的账户,并且用户可以在这样的生态系统的任何客户端设备上访问这些账户。当这些累加的计数满足框616的频率阈值时,这些特定文本命令可以被选择性地登记为生态系统的热命令。这可以有效地使热命令在部署生态系统的客户端设备的环境中(诸如在家庭中、在由家庭成员驾驶的车辆中、在由家庭成员携带的移动电话上等)广泛可用。
115.类似地,在一些实施方式中,当文本命令(或由其生成的模板/语法)被登记为热命令时,它们可以在单个用户的基础上、在多用户的基础上(例如,可用于家庭成员和/或向客户端设备的特定生态系统注册的用户)被登记,或者甚至被登记以供在群体中广泛使用。在基于单个用户登记热命令的一些实施方式中,当用户发出登记的热命令时,自动助理120可以首先尝试确定说话者的身份和/或将说话者与注册的用户简档匹配。例如,自动助理120可以执行说话者辨识处理(或语音匹配)、面部辨识处理(如果视觉传感器可用)以确定说话者的身份,或者至少将说话者与所登记的语音简档匹配。如果说话者未被辨识,则在一些实施方式中,自动助理120可以忽略登记的热命令。另一方面,如果说话者被辨识,则可以使用本文描述的技术来分析所说的话语,以确定自动助理120是否应该采取响应动作。
116.如上所述,在一些实施方式中,针对多个用户——例如,家庭成员或向客户端设备(例如,家庭中的客户端设备和联网电器)的定义的生态系统注册的用户——登记热命令。在一些这样的实施方式中,那些注册用户中的任何一个可能能够向生态系统的客户端设备发出所登记的热命令。只要说话者能够例如使用语音匹配或面部辨识与所注册的用户简档(或更一般地,被注册为允许向自动助理120发出命令的某人,即使没有预定义的简档)匹配,自动助理120就可以采取响应动作而不首先被调用。
117.在图6中,基于是否满足框614的频率阈值,文本命令被选择性地登记为热命令。然而,这并不意味着限制。在其他实施方式中,可以使用附加的或替代的信号和/或技术来确定文本命令是否应该被登记为热命令和/或文本命令是否确实是对自动助理120而说。
118.例如,在一些实施方式中,文本命令可以例如由调用模块113应用为跨机器学习模型的输入以生成输出。该输出可以指示文本命令针对自动助理的概率。在一些这样的实施方式中,框616的登记进一步响应于由机器学习模型传达的输出满足阈值的概率。附加地或可替代地,在一些实施方式中,框616的有条件登记可以进一步以基于由一个或多个相机捕获的视觉数据检测到用户的凝视指向其上至少部分地实现自动助理的计算设备为条件,如图5a所示。
119.在其他实施方式中,框616的有条件登记可以进一步以确定在口头命令之后的预定时间间隔期间没有检测到附加的话语为条件。假设说话者发出命令,随后是例如五到十秒的静默。这可能表明说话者是单独的——另一个人类对话参与者可能已经在那时做出响应——因此应当是针对自动助理120而说。或者,临时静默可能表明房间中存在的其他人意识到说话者是针对自动助理120而说,因此他们保持静默。
120.附加地或可替代地,在一些实施方式中,框616的有条件登记进一步以确定在口头命令之后的预定时间间隔期间,人没有采取响应动作为条件。假设说话者说出“turn on the lights”,但是然后另一个人快速操作物理开关以打开灯。这表明说话者正在针对另一个人而说,而不是自动助理120,因此,短语“turn on the lights”可能不适合于登记为热命令,至少在此时不适合。另一方面,如果说话者发出该命令并且在某个预定时间间隔(例如,5秒、10秒)内没有其他事情发生,则表明说话者实际上正在针对自动助理120而说,并且因此,文本命令“turn on the lights”应当被登记为热命令。
121.图7描绘了根据各种实施方式的用于实施本公开的所选方面的示例性方法700,包括诸如图2b中描绘的实施方式,其中,对在完全收听状态(图2a)或完全响应状态(图2b)之外捕获的话语执行stt/话音辨识处理。为了方便起见,参考执行操作的系统来描述流程图的操作。该系统可以包括各种计算机系统的各种组件。此外,虽然方法700的操作以特定顺序示出,但这并不意味着限制。可以重新排序、省略或添加一个或多个操作。
122.在框702处,系统可以接收在一个或多个麦克风处捕获的音频数据。音频数据可以包括随时间捕获的多个口头话语,诸如第一和第二口头话语。在框704处,系统可以对音频数据执行话音辨识处理(即,stt处理),以生成与第一和第二口头话语相对应的第一和第二文本片段。
123.在框706,系统可以确定第一文本片段满足一个或多个热命令标准。这些“热命令标准”可以类似于本文描述的“热命令登记标准”。例如,热命令标准可以包括但不限于说话者的凝视在说话时是否指向助理设备、其他人是否与说话者共存、说话者在说话时是否凝视另一个人而不是计算设备、在话语之后是否伴随某个预定时间间隔的静默和/或人的无动作、在自动助理120处于完全收听(图2a)或完全响应(图2b)状态时文本片段是否已经被说出了某个阈值次数等。
124.在框708,系统可以确定第二文本片段不满足一个或多个热命令标准。在框710处,响应于框706的确定,系统可以基于第一文本片段执行响应动作。在框712处,响应于框708的确定,系统可以丢弃或忽略第二文本片段而不执行另一响应动作。
125.在本文讨论的某些实施方式可能收集或使用关于用户的个人信息(例如,从其他电子通信提取的用户数据、关于用户的社交网络的信息、用户的位置、用户的时间、用户的生物特征信息、以及用户的活动和人口统计信息、用户之间的关系等)的情况下,向用户提供一个或多个机会来控制是否收集信息、是否存储个人信息、是否使用个人信息,以及如何收集、存储和使用关于用户的信息。也就是说,本文讨论的系统和方法仅在从相关用户接收到这样做的明确授权时才收集、存储和/或使用用户个人信息。
126.例如,向用户提供对程序或功能部件是否收集关于该特定用户或与该程序或功能部件相关的其他用户的用户信息的控制。向要对其收集个人信息的每个用户呈现一个或多个选项,以允许控制与该用户相关的信息收集、以提供关于是否收集信息以及关于要收集信息的哪些部分的许可或授权。例如,可以通过通信网络向用户提供一个或多个这样的控制选项。另外,某些数据可以在其被存储或使用之前以一种或多种方式被处理,使得个人可识别信息被移除。作为一个示例,可以处理用户的身份,使得不能确定个人可识别信息。作为另一示例,可以将用户的地理位置概括到更大的区域,使得不能确定用户的具体位置。
127.图8是示例性计算设备810的框图,该示例性计算设备可以可选地用于执行本文所述的技术的一个或多个方面。在一些实施方式中,客户端计算设备、用户控制的资源引擎134和/或其他组件中的一个或多个可以包括示例性计算设备810的一个或多个组件。
128.计算设备810通常包括至少一个处理器814,该处理器814经由总线子系统812与多个外围设备进行通信。这些外围设备可以包括:存储子系统824,该存储子系统824例如包括存储器子系统825和文件存储子系统826;用户接口输出设备820;用户接口输入设备822;以及网络接口子系统816。输入和输出设备允许用户与计算设备810进行交互。网络接口子系统816提供到外部网络的接口并耦合到其他计算设备中的相应的接口设备。
129.用户接口输入设备822可以包括:键盘;诸如鼠标、轨迹球、触摸板或图形输入板之类的指向设备;扫描仪;集成在显示器中的触摸屏;诸如话音辨识系统、麦克风之类的音频输入设备;和/或其他类型的输入设备。通常,使用术语“输入设备”旨在包括将信息输入到计算设备810或通信网络上的所有可能类型的设备和方式。
130.用户接口输出设备820可以包括显示子系统、打印机、传真机或诸如音频输出设备的非可视显示器。显示子系统可以包括:阴极射线管(crt);诸如液晶显示器(lcd)的平板设备;投影设备;或用于创建可见图像的一些其他机制。显示子系统还可以诸如经由音频输出设备来提供非视觉显示。通常,使用术语“输出设备”旨在包括用于将信息从计算设备810输出到用户或另一机器或计算设备的所有可能类型的设备以及方式。
131.存储子系统824存储提供本文所述的一些或所有模块的功能的编程和数据构造。例如,存储子系统824可以包括执行图6-7的方法的所选方面以及实现图1中描绘的各种组件的逻辑。
132.这些软件模块通常由处理器814单独或与其他处理器结合地执行。存储子系统824中使用的存储器825可以包括多个存储器,其包括用于在程序执行期间存储指令和数据的主随机存取存储器(ram)830以及其中存储固定指令的只读存储器(rom)832。文件存储子系统826可以为程序和数据文件提供持久存储,并且可以包括硬盘驱动器、软盘驱动器以及相关联的可移动介质、cd-rom驱动器、光盘驱动器或可移动介质盒。实现某些实施方式的功能的模块可以由文件存储子系统826存储在存储子系统824中,或者存储在处理器814可访问
的其他机器中。
133.总线子系统812提供了一种机制,该机制使得计算设备810的各个组件和子系统按预期彼此通信。尽管总线子系统812被示意性地示出为单条总线,但是总线子系统的可替代实施方式可以使用多条总线。
134.计算设备810可以是各种类型,包括工作站、服务器、计算集群、刀片服务器、服务器场或任何其他数据处理系统或计算设备。由于计算机和网络的不断变化的性质,出于图示一些实施方式的目的,图8中描绘的对计算设备810的描述仅旨在作为特定示例。计算设备810的许多其他配置可能具有比图8描绘的计算设备更多或更少的组件。
135.尽管本文已经描述和图示了几种实施方式,但是可以利用用于执行功能和/或获得结果和/或本文描述的一个或多个优点的多种其他手段和/或结构,并且每个这样的变型和/或改进被认为在本文描述的实施方式的范围内。更一般地,本文描述的所有参数、尺寸、材料和构造均意味着是示例性的,并且实际参数、尺寸、材料和/或构造将取决于教导所用于的具体应用或多个应用。仅使用常规实验,本领域技术人员将认识到或能够确定本文所述的具体实施方式的许多等同形式。因此,应当理解到,前述实施方式仅以示例的方式给出,并且在所附权利要求及其等同物的范围内,可以以不同于具体描述和要求保护的方式来实施实现。本公开的实施方式针对本文所述的每个单独的特征、系统、制品、材料、套件和/或方法。另外,如果这样的特征、系统、制品、材料、套件和/或方法不是相互矛盾的,则本公开的范围包括两个或多个这样的特征、系统、制品、材料、套件和/或方法的任何组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
