1.本发明实施例涉及医学信息技术,尤其涉及一种基于人工智能模型的医学术语归一化方法、装置。
背景技术:
2.医学专业术语与真实电子病历中的临床术语存在较大的差异,将电子病历中医生书写不规范,口语化的描述等,经实体抽取、分类、归一化等,能够将不规范的临床术语转化为医学专业术语,以实现医学术语的归一化工作。
3.现有技术中,实现医学术语归一化采用的方案是从例如电子病历中抽取待归一化的医学原文,将抽取的医学原文与对应的标准术语库中的多个标准术语进行二分类处理,取正确分类中概率最大的标准术语,这种方案会存在准确率低并且工作量大的问题。
技术实现要素:
4.本发明实施例提供了一种基于人工智能模型的医学术语归一化方法、装置,以实现提高医学术语的归一化准确率和速率的技术效果。
5.第一方面,本发明实施例提供了一种基于人工智能模型的医学术语归一化方法,该方法包括:
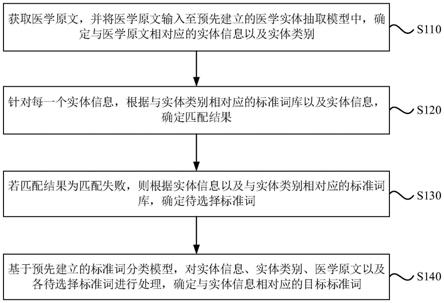
6.获取医学原文,并将所述医学原文输入至预先建立的医学实体抽取模型中,确定与所述医学原文相对应的实体信息以及实体类别;
7.针对每一个实体信息,根据与所述实体类别相对应的标准词库以及所述实体信息,确定匹配结果;
8.若所述匹配结果为匹配失败,则根据所述实体信息以及与所述实体类别相对应的标准词库,确定待选择标准词;
9.基于预先建立的标准词分类模型,通过所述实体信息、所述实体类别、所述医学原文以及各待选择标准词确定与所述实体信息相对应的目标标准词。
10.第二方面,本发明实施例还提供了一种基于人工智能模型的医学术语归一化装置,该装置包括:
11.实体抽取模块,用于获取医学原文,并将所述医学原文输入至预先建立的医学实体抽取模型中,确定与所述医学原文相对应的实体信息以及实体类别;
12.第一匹配模块,用于针对每一个实体信息,根据与所述实体类别相对应的标准词库以及所述实体信息,确定匹配结果;
13.待选择标准词确定模块,用于若所述匹配结果为匹配失败,则根据所述实体信息以及与所述实体类别相对应的标准词库,确定待选择标准词;
14.第一目标标准词确定模块,用于基于预先建立的标准词分类模型,对所述实体信息、所述实体类别、所述医学原文以及各待选择标准词进行处理,确定与所述实体信息相对应的目标标准词。
15.第三方面,本发明实施例还提供了一种电子设备,所述电子设备包括:
16.一个或多个处理器;
17.存储装置,用于存储一个或多个程序,
18.当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如本发明实施例任一所述的基于人工智能模型的医学术语归一化方法。
19.第四方面,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如本发明实施例任一所述的基于人工智能模型的医学术语归一化方法。
20.本发明实施例的技术方案,通过获取医学原文,并将医学原文输入至预先建立的医学实体抽取模型中,确定与医学原文相对应的实体信息以及实体类别,以对医学原文进行实体抽取,进而,针对每一个实体信息,根据与实体类别相对应的标准词库以及实体信息,确定匹配结果,以通过完全匹配的方式确定匹配结果,若匹配结果为匹配失败,则根据实体信息以及与实体类别相对应的标准词库,确定待选择标准词,并基于预先建立的标准词分类模型,对实体信息、实体类别、医学原文以及各待选择标准词进行处理,确定与实体信息相对应的目标标准词,解决了医学术语归一化时工作量大且准确率低的问题,实现了提高医学术语的归一化准确率和速率的技术效果。
附图说明
21.为了更加清楚地说明本发明示例性实施例的技术方案,下面对描述实施例中所需要用到的附图做一简单介绍。显然,所介绍的附图只是本发明所要描述的一部分实施例的附图,而不是全部的附图,对于本领域普通技术人员,在不付出创造性劳动的前提下,还可以根据这些附图得到其他的附图。
22.图1为本发明实施例一所提供的一种基于人工智能模型的医学术语归一化方法的流程示意图;
23.图2为本发明实施例二所提供的一种基于人工智能模型的医学术语归一化方法的流程示意图;
24.图3为本发明实施例三所提供的一种基于人工智能模型的医学术语归一化方法的流程示意图;
25.图4为本发明实施例三所提供的另一种基于人工智能模型的医学术语归一化方法的流程示意图;
26.图5为本发明实施例四所提供的一种基于人工智能模型的医学术语归一化装置的结构示意图;
27.图6为本发明实施例五所提供的一种电子设备的结构示意图。
具体实施方式
28.下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
29.实施例一
30.图1为本发明实施例一所提供的一种基于人工智能模型的医学术语归一化方法的流程示意图,本实施例可适用于在对电子病历中的医学原文进行标准化的情况,该方法可以由基于人工智能模型的医学术语归一化装置来执行,该装置可以通过软件和/或硬件的形式实现,该硬件可以是电子设备,可选的,电子设备可以是移动终端,pc端等。
31.如图1所述,本实施例的方法具体包括如下步骤:
32.s110、获取医学原文,并将医学原文输入至预先建立的医学实体抽取模型中,确定与医学原文相对应的实体信息以及实体类别。
33.其中,医学原文包含cdr(clinical data repository,临床数据中心)数据库中的所有病历文书信息,例如可以是电子病历中的原文信息,可以是一句话或一段话的形式,例如:医学原文可以是电子病历中的“髂动脉血栓复查”。医学实体抽取模型可以是用于将医学原文转化为医学实体的模型。实体信息可以是医学原文中涉及医学的实体,例如:髂动脉血栓等。实体类别可以是对实体信息划分的类别,该10大类实体类别包含但不限于疾病实体、症状实体、药品实体、体征实体、检验实体、手术实体、检查实体、用血实体以及部位实体等。
34.具体的,可以获取电子病历,并从电子病历中分解得到至少一条医学原文。针对每一条医学原文,可以将医学原文输入至预先建立的医学实体抽取模型中进行实体抽取处理,得到输出的实体信息,并确定每一个实体信息相对应的实体类别。
35.s120、针对每一个实体信息,根据与实体类别相对应的标准词库以及实体信息,确定匹配结果。
36.其中,标准词库可以是针对不同实体类别分别建立的标准词库,标准词库中包含在相对应的实体类别下的专业医学术语,记为候选标准词。例如:与部位实体相对应的标准词库可以是基于人体解剖学知识构建的。匹配结果可以是实体信息与标准词库中的各候选标准词的匹配结果,匹配结果可以是匹配成功或者匹配失败。
37.具体的,针对每一个实体信息,确定与该实体信息的实体类别相对应的标准词库。进而,将实体信息与确定出的标准词库中的各候选标准词通过硬规则进行匹配,并确定匹配结果。
38.需要说明的是,硬规则可以理解为当实体信息与标准词完全相同,则匹配结果为匹配成功,反之,则匹配结果为匹配失败。
39.s130、若匹配结果为匹配失败,则根据实体信息以及与实体类别相对应的标准词库,确定待选择标准词。
40.其中,待选择标准词可以是标准词库中与实体信息的匹配程度满足预设条件的候选标准词,即为初步筛选得到的标准词。
41.具体的,若匹配结果为匹配失败,则可以认为标准词库中的候选标准词没有与实体信息完全一致的,因此,可以进行相似度匹配。进而,可以将相似度达到预设条件的候选标准词作为待选择标准词,如:预设条件为相似度超过80%等,或者,相似度从高至低排序,将排名位于前20的候选标准词作为待选择标准词。
42.需要说明的是,预设条件中相对应的具体数值可以根据实际需求进行设定,在本实施例中不作具体限定。
43.s140、基于预先建立的标准词分类模型,对实体信息、实体类别、医学原文以及各
待选择标准词进行处理,确定与实体信息相对应的目标标准词。
44.其中,标准词分类模型可以是二分类模型,用于判断实体信息与待选择标准词是否匹配。目标标准词可以是与医学原文中的实体信息相对应的候选标准词,即标准化后的专业医学术语。
45.具体的,待选择标准词的数量可以是多个,因此,针对每一个待选择标准词,可以将实体信息、实体类别、医学原文以及待选择标准词输入至预先建立的标准词分类模型中,得到二分类结果。进而,根据与各待选择标准词相对应的二分类结果,并根据二分类结果确定目标标准词。
46.示例性的,标准词分类模型中,可以将匹配成功的输出设定为“1”,匹配失败的输出设定为“0”。可以是若匹配概率达到50%,则输出1,匹配概率未达到50%,则输出0。并且,可以确定二分类结果为1和0的概率。例如:与第一个待选择标准词通过标准词分类模型得到的结果是,当分类结果为0的概率为0.4,为1的概率为0.6,则可以确定二分类结果为1,对应的概率为0.6;与第二个待选择标准词通过标准词分类模型得到的结果是,当分类结果为0的概率为0.7,为1的概率为0.3,则可以确定二分类结果为0;与第三个待选择标准词通过标准词分类模型得到的结果是,当分类结果为0的概率为0.3,为1的概率为0.7,则可以确定二分类结果为1,对应的概率为0.7;由此可以知道,二分类结果为1的待选择标准词为第一个待选择标准词和第三个待选择标准词,进而,确定二分类结果为1的概率中最大值为0.7,确定相对应的待选择标准词是该最大值0.7对应的第三个待选择标准词,进而,可以将第三个待选择标准词作为与实体信息相对应的目标标准词。
47.需要说明的是,通过预先建立的标准词分类模型进行分类的次数与待选择标准词的数量一致,远小于与实体类别相对应的标准词库中的候选标准词的数量,因此,可以提升归一化速率。
48.可选的,若匹配结果为匹配成功,则将匹配成功的候选标准词确定为与实体信息相对应的目标标准词。
49.具体的,若匹配结果为匹配成功,则表明标准词库中的存在与实体信息完全一致的候选标准词,此时,可以将完全一致的候选标准词作为与实体信息相对应的目标标准词。
50.可选的,为了更好的进行医学术语归一化、标准化,还可以预先构建标准词库,具体可以是:构建与各实体类别相对应的数据库建立标准词库。
51.其中,实体类别包含但不限于疾病实体、症状实体、药品实体、体征实体、检验实体、手术实体、检查实体、用血实体以及部位实体等。
52.具体的,可以是获取与各实体类别相对应的数据库,例如:针对疾病实体所对应的国际疾病分类(international classification of diseases,icd)数据库icd-10,针对症状实体所对应的基于医学知识构建的症状数据库,针对药品实体所对应的国家药品监督局的药品库。在获取各数据库后,可以对各数据库中的数据信息进行结构化处理,还可以进行其他处理,以使数据信息能够用于后续医学术语的标准化。并将处理后的数据库作为与各实体类别相对应的标准词库。
53.需要说明的是,上述数据库只是示例性的说明,并非限定,可以是任一医学术语相关的数据库。
54.本发明实施例的技术方案中涉及的多路召回方案可以理解为:首先通过硬规则直
接匹配实体信息,进行第一次匹配结果返回,若匹配失败,则确定待选择标准词,并基于标准词分类模型针对各待选择标准词进行匹配召回,得到第二次匹配结果,即得到与实体信息相对应的目标标准词。
55.本发明实施例的技术方案,通过获取医学原文,并将医学原文输入至预先建立的医学实体抽取模型中,确定与医学原文相对应的实体信息以及实体类别,以对医学原文进行实体抽取,进而,针对每一个实体信息,根据与实体类别相对应的标准词库以及实体信息,确定匹配结果,以通过完全匹配的方式确定匹配结果,若匹配结果为匹配失败,则根据实体信息以及与实体类别相对应的标准词库,确定待选择标准词,并基于预先建立的标准词分类模型,对实体信息、实体类别、医学原文以及各待选择标准词进行处理,确定与实体信息相对应的目标标准词,解决了医学术语归一化时工作量大且准确率低的问题,实现了提高医学术语的归一化准确率和速率的技术效果。
56.实施例二
57.图2为本发明实施例二所提供的一种基于人工智能模型的医学术语归一化方法的流程示意图,本实施例在上述各实施例的基础上,针对待选择标准词的确定方式进行详细说明,还增加了通过诊断原词对实体信息进行匹配得到目标标准词的方式,具体可参见本实施例的技术方案。其中,与上述各实施例相同或相应的术语的解释在此不再赘述。
58.如图2所述,本实施例的方法具体包括如下步骤:
59.s210、获取医学原文,并将医学原文输入至预先建立的医学实体抽取模型中,确定与医学原文相对应的实体信息以及实体类别。
60.可选的,为了实现实体信息的抽取以及实体类别的确定,可以预先建立医学实体抽取模型,具体步骤可以包括:
61.步骤一、根据医学样本原文以及预先标注的与医学样本原文相对应的实体信息和实体类别,对初始医疗预训练模型进行训练,得到待测试医疗预训练模型。
62.其中,初始医疗预训练模型基于双向长短期记忆人工神经网络以及条件随机场构建的bert(bidirectional encoder representation from transformers,预训练的语言表征)医疗预训练模型构建。医学样本原文可以是已经标注了实体类别并确定了实体信息的原文。初始预训练模型可以是基于默认参数构建的模型,后续可以进行参数迭代更新等。待测试医疗预训练模型可以是对初始预训练模型训练得到的,还未进行测试的模型。
63.具体的,可以获取电子病历,并根据电子病历确定医学样本原文,通过数据标注平台等,进行处理对医学样本原文标注出相对应的实体信息和实体类别。基于双向长短期记忆人工神经网络(bi-directional long short-term memory,bilstm)以及条件随机场(conditional random fields,crf)构建初始医疗预训练模型。根据医学样本原文以及与医学样本原文相对应的实体信息和实体类别对初始医疗预训练模型进行训练,将训练得到的模型作为待测试医疗预训练模型。
64.步骤二、基于医学训练原文以及预先标注的与医学训练原文相对应的实体信息和实体类别对待测试医疗预训练模型进行测试,当测试结果满足预设条件时,将待测试医疗预训练模型作为医学实体抽取模型。
65.其中,预设条件可以是测试结果满足一定准确率、迭代次数达到预设次数、测试结果收敛等条件。
66.具体的,可以根据步骤一中获取医学样本原文以及相对应的实体信息和实体类别的方法,获取测试使用的医学训练原文以及与医学训练原文相对应的实体信息和实体类别,以对待测试医疗训练模型进行测试。若测试结果满足预设条件,则将待测试医疗预训练模型作为医学实体抽取模型。若测试结果不满足预设条件,则可以通过扩大训练样本的方式等,对待测试医疗预训练模型进行再训练,以得到满足预设条件的医学实体抽取模型。
67.示例性的,可以令医学样本原文与医学训练原文的比例为预设比例,即设置训练集和测试集的比例为预设比例,如:预设比例为7:3,并根据测试结果来调整待测试医疗预训练模型的网络结构或训练参数等。
68.s220、针对每一个实体信息,根据与实体类别相对应的标准词库以及实体信息,确定匹配结果。
69.s230、若匹配结果为匹配失败,则根据预先确定的诊断原词以及实体信息,确定是否存在与实体信息相对应的诊断原词,若存在,则执行s240;若不存在,则执行s250。
70.其中,诊断原词具有相匹配的候选标准词,诊断原词可以是在训练得到医学实体抽取模型时,医生进行标注过的词语。
71.具体的,获取在训练医学实体抽取模型阶段进行标注的医学样本原文和/或医学训练原文作为诊断原词。进一步的,将实体信息和诊断原词进行相似度匹配,若相似度达到预设的相似度阈值,则可以确定存在与实体信息相对应的诊断原词,否则,不存在与实体信息相对应的诊断原词。
72.示例性的,将实体信息与诊断原词进行tf-idf(term frequency
–
inverse document frequency,词频-逆文本频率)方法和相似度方法处理,若相似度大于95%,则判定为存在与实体信息相对应的诊断原词,否则,判定为不存在。
73.需要说明的是,相似度匹配可以包括欧几里得距离、皮尔逊相关系数、余弦相似度等算法,采用一个或多个予以组合来进行相似度计算,在本实施例中不做具体限定。
74.s240、根据诊断原词以及确定与诊断原词相对应的候选标准词,将候选标准词确定为与实体信息相对应的目标标准词。
75.其中,候选标准词可以是标准词库中的各标准词。
76.具体的,在确定与实体信息相对应的诊断原词后,获取与诊断原词相对应的候选标准词,将该候选标准词作为与实体信息相对应的目标标准词。
77.s250、通过词频-逆文本频率方法,根据实体信息以及与实体类别相对应的标准词库,确定与实体信息相匹配的第一数量的第一候选标准词,通过词向量相似度方法,根据实体信息以及与实体类别相对应的标准词库,确定与实体信息相匹配的第二数量的第二候选标准词,并执行s260。
78.其中,第一数量和第二数量可以是预先设定的数值,若想要提高计算速度,则可以适当减小第一数量和第二数量,若想要提高匹配准确性,则可以适当增大第一数量和第二数量。第一候选标准词可以是通过词频-逆文本频率方法匹配出的候选标准词,第二候选标准词可以是通过词向量相似度方法匹配出的候选标准词。
79.具体的,通过tf-idf算法可以将实体信息和与实体类别相对应的标准词库中的各候选标准词进行匹配,并将匹配程度从高至低排序,将位于前第一数量的候选标准词作为第一候选标准词。通过词向量(word to vector,word2vec)相似度方法可以将实体信息和
与实体类别相对应的标准词库中的各候选标准词进行匹配,并将匹配程度从高至低排序,将位于前第二数量的候选标准词作为第二候选标准词。
80.需要说明的是,第一数量和第二数量可以相同,也可以不同,可以根据实际需求进行设定,例如:20或50等,在本实施例中不做具体限定。
81.s260、根据第一候选标准词以及第二候选标准词确定待选择标准词。
82.具体的,可以对第一候选标准词和第二候选标准词进行处理,得到待选择标准词,处理方式可以是确定重叠部分的词语为待选择标准词,也可以是确定综合匹配程度,确定综合匹配程度靠前的一定数量的词语为待选择标准词。
83.可选的,列举下列两种待选择标准词的确定方式:
84.方式一、若第一候选标准词与第二候选标准词相同,则将第一候选标准词确定为待选择标准词。
85.具体的,将第一候选标准词和第二候选标准词的重叠部分作为待选择标准词。
86.示例性的,在20个第一候选标准词和20个第二候选标准词中,存在8个相同的候选标准词,则可以将相同的候选标准词作为待选择标准词。
87.方式二、若第一候选标准词与第二候选标准词相同,则将第一候选标准词确定为初始待选择标准词;将除初始待选择标准词之外且相似度达到第一相似度阈值的第一候选标准词确定为第一待选择标准词;将除初始待选择标准词之外且相似度达到第二相似度阈值的第二候选标准词确定为第二待选择标准词;根据初始待选择标准词、第一待选择标准词以及第二待选择标准词确定待选择标准词。
88.其中,第一相似度阈值和第二相似度阈值可以是确定待选择标准词时使用的相似度阈值,第一相似度阈值和第二相似度阈值可以相同,也可以不同,具体数值可以根据实际需求进行设定。初始待选择标准词可以是第一候选标准词与第二候选标准词重叠的部分。
89.具体的,将第一候选标准词和第二候选标准词的重叠部分作为初始待选择标准词。将第一候选标准词中除初始待选择标准词的部分进行再次筛选,选择其中相似度达到第一相似度阈值的第一候选标准词作为第一待选择标准词。进而,可以对第二候选标准词中除初始待选择标准词的部分进行类似的处理,即选择其中相似度达到第二相似度阈值的第二候选标准词作为第二待选择标准词。在确定初始待选择标准词,第一待选择标准词和第二待选择标准词后,将上述词语进行组合得到待选择标准词。
90.示例性的,在20个第一候选标准词和20个第二候选标准词中,存在8个相同的候选标准词,则可以将相同的候选标准词作为初始待选择标准词。第一候选标准词中除去8个初始待选择标准词剩余的12个第一候选标准词中,相似度大于80%(第一相似度阈值)的第一候选标准词有3个,则将这3个第一候选标准词作为第一待选择标准词。第二候选标准词中除去8个初始待选择标准词剩余的12个第二候选标准词中,相似度大于85%(第二相似度阈值)的第二候选标准词有2个,则将这2个第二候选标准词作为第二待选择标准词。进而,根据8个初始待选择标准词,3个第一待选择标准词和2个第二待选择标准词,可以确定出13个待选择标准词。
91.需要说明的是,方式一可以确定第一候选标准词和第二候选标准词中的重叠部分进行后续匹配,能够排除无需进行后续匹配的部分候选标准词。方式二在方式一的基础上添加了阈值匹配的候选标准词,避免了方式一由于确定出的待选择标准词较少,后续匹配
过程中可能无法找到最优匹配结果的问题。然而,相较于方式二,方式一确定出的待选择标准词数量更少,后续匹配速度更快。具体在使用本实施例技术方案时,选用何种方式可以根据实际需求确定,在本实施例中不做具体限定。
92.还需要说明的是,上述两种方式只是示例性的确定待选择标准词的方式,并非限定。
93.s270、基于预先建立的标准词分类模型,对实体信息、实体类别、医学原文以及各待选择标准词进行处理,确定与实体信息相对应的目标标准词。
94.具体的,针对每一个待选择标准词,可以将实体信息、实体类别、医学原文以及待选择标准词输入至预先建立的标准词分类模型中,得到二分类结果,并根据二分类结果确定目标标准词。
95.在上述各实施例的基础上,可选的,还需要建立标准词分类模型。具体建立标准词分类模型包括如下步骤:
96.步骤一、获取医学术语训练集。
97.其中,医学术语训练集包括训练医学原文、与训练医学原文相对应的训练实体信息、与训练医学原文相对应的训练实体标签、与训练医学原文相对应的训练标准词。医学术语训练集可以分为训练样本数据和校验样本数据,具体划分方式可以根据需求设定。
98.具体的,可以通过电子病历进行处理和标注,确定训练医学原文、与训练医学原文相对应的训练实体信息、与训练医学原文相对应的训练实体标签、与训练医学原文相对应的训练标准词,并构成医学术语训练集。
99.需要说明的是,通过上述方式构建的医学术语训练集中,全部匹配结果均为匹配,那么,针对每一个训练医学原文,可以将与对应的训练标准词不同的其他标准词的匹配结果设置为不匹配,以完成对医学术语训练集的样本扩充。
100.步骤二、基于医学术语训练集中的训练样本数据对初始分类模型进行训练得到待校验分类模型。
101.其中,初始分类模型可以是将加权方法和embedding(嵌入)向量化,引入bert模型中构建的二分类模型。待校验分类模型可以是初步训练得到的二分类模型。
102.具体的,基于医学术语训练集中的训练样本数据对初始分类模型进行训练,对初始分类模型中的参数和模型结构进行迭代调整,将训练结果满足训练需求的模型作为待校验分类模型。
103.步骤三、基于医学术语训练集中的校验样本数据对待校验分类模型进行校验,当校验结果满足校验条件时,将待校验分类模型作为标准词分类模型。
104.其中,校验结果可以是准确率结果,或模型收敛结果等,校验条件可以是与校验结果相对应的预先设定的模型条件。
105.具体的,基于医学术语训练集中的校验样本数据对待校验分类模型进行校验,得到校验结果,将校验结果与校验条件进行比对,若比对通过,则将待校验分类模型作为标准词分类模型;若比对不通过,则需要对待校验分类模型进行再次训练调整。
106.本发明实施例的技术方案中涉及的多路召回方案可以理解为:首先通过硬规则直接匹配实体信息,进行第一次匹配结果返回,若匹配失败,则基于诊断原词和实体信息进行第二次匹配结果返回,若仍是匹配失败,则确定待选择标准词,并基于标准词分类模型针对
各待选择标准词进行匹配召回,得到第三次匹配结果,即确定与实体信息相对应的目标标准词。
107.本发明实施例的技术方案,通过获取医学原文,并将医学原文输入至预先建立的医学实体抽取模型中,确定与医学原文相对应的实体信息以及实体类别,针对每一个实体信息,根据与实体类别相对应的标准词库以及实体信息,确定匹配结果,若匹配结果为匹配失败,则根据预先确定的诊断原词以及实体信息,确定是否存在与实体信息相对应的诊断原词,以进行第二次匹配,若存在,则根据诊断原词以及确定与诊断原词相对应的候选标准词,将候选标准词确定为与实体信息相对应的目标标准词;若不存在,则通过词频-逆文本频率方法,根据实体信息以及与实体类别相对应的标准词库,确定与实体信息相匹配的第一数量的第一候选标准词,通过词向量相似度方法,根据实体信息以及与实体类别相对应的标准词库,确定与实体信息相匹配的第二数量的第二候选标准词,并根据第一候选标准词以及第二候选标准词确定待选择标准词,进而,基于预先建立的标准词分类模型,对实体信息、实体类别、医学原文以及各待选择标准词进行处理,确定与实体信息相对应的目标标准词,解决了医学术语归一化时工作量大且准确率低的问题,实现了通过多路召回的方式提高医学术语的归一化准确率和速率的技术效果。
108.实施例三
109.作为上述各实施例的可选实施方案,图3为本发明实施例三所提供的一种基于人工智能模型的医学术语归一化方法的流程示意图。其中,与上述各实施例相同或相应的术语的解释在此不再赘述。
110.如图3所述,本实施例的方法包括通过硬规则的直接匹配召回与医学实体相对应的标准词的第一路召回方式,还包括通过诊断原词与医学实体相似度匹配的第二路召回方式,还包括通过二分类模型对医学实体进行匹配的第三路召回方式,具体包括如下步骤:
111.1、输入cdr数据库中的病历文书信息。
112.2、通过实体抽取模型(医学实体抽取模型)抽取医学实体,确定与医学实体的实体类型相对应的标准库。
113.其中,医疗文本(不限于来源于电子病历)中的医学实体的实体类型包含疾病、症状和药品等,那么,不同实体类型所对应的医学实体所对应的标准库包含疾病类型标准库、症状类型标准库和药品类型标准库等。
114.示例性的,以疾病为例,电子病历中的病历主诉中的其中一段原文:“髂动脉血栓复查”。那么,所抽取的医学实体为“髂动脉血栓”,对应于该医学实体的标签(实体类型)为疾病,相对应的医学原文为“髂动脉血栓复查”。通过本实施例的技术方案,在疾病标准库中的确定出的标准词为髂动脉栓塞(i74.500x011)。
115.示例性的,以症状为例,电子病历中的病历主诉中的其中一段原文:“右腕皮肤擦伤”。对应于该医学实体的标签(实体类型)为症状,通过本实施例的技术方案,在症状标准库中确定出的标准词为腕部擦伤(s60.800x012)。
116.标准库可以是由国家开放的医学标准术语形成的标准词疾病库、症状库、药品库等。本发明的范围所涵盖的标准库包括但不限于国际系统医学术语临床术语(the systematized nomenclature of human and veterinary medicine clinical terms,snomed ct),icd-10等。
117.以手术专业词语为例,在国家医保标准库对于当中对于同一临床表达,涉及如下编号和手术标准名称:00.5500x008经皮降主动脉药物洗脱支架置入术;00.5500x009经皮周围动脉药物洗脱支架置入术;00.5500x010经皮周围静脉药物洗脱支架置入术;00.5500x011经皮尺动脉药物洗脱支架置入术;00.5500x012经皮腓动脉药物洗脱支架置入术;00.5500x013经皮肱动脉药物洗脱支架置入术;00.5500x014经皮桡动脉药物洗脱支架置入术;00.5500x015经皮上肢静脉药物洗脱支架置入术;00.5500x016经皮头臂静脉药物洗脱支架置入术;00.5500x017经皮外周动脉可降解支架置入术。
118.以药品名称词语为例,在国家药品监督管理局的药品库中对某一临床表达的药品,涉及如下编号和药品标准名称:龟龙中风丸(国药准字z20020147);龟龄集(国药准字z14020687);龟黄补酒(国药准字z20026072);龟鹿补肾胶囊(国药准字z20123109);龟鹿补肾片(国药准字z20080217);龟鹿补肾口服液(国药准字z44023432);龟鹿益肾胶囊(国药准字b20020196);龟鹿滋肾丸(国药准字z61020333);龟鹿宁神丸(国药准字z44021133);龟鹿二胶丸(国药准字z51021617);龟鹿二仙膏(国药准字z41022262);龟鹿二仙口服液(国药准字z20050229)。
119.需要说明的是,建立实体抽取模型可以包括:第一步:取电子病历中医学原文,确定实体类型(疾病、症状、药品等),使用数据标注平台将语料数据处理成标注数据(包括医学实体和实体类型),得到已标注的数据集;第二步:使用bert医疗预训练模型,将已标注的数据集的70%作为训练集,进行bilstm、crf神经网络的训练,在训练收敛后,用剩下的30%进行测试,并根据测试结果来调整网络结构或训练参数,得到实体抽取模型。其中,70%和30%只是举例说明,可以根据实际情况进行调整。
120.3、通过硬规则的直接匹配召回与医学实体相对应的标准词,若成功,则结束,若失败,则执行步骤4。
121.示例性的,硬规则指的是硬匹配查询,将医学实体“髂动脉血栓”,直接通过完全匹配的方式,与各个标准词进行匹配;若完全匹配,则返回1,否则,返回0。
122.当通过硬规则的直接匹配无法召回精确度较高的结果时,可以执行后续匹配步骤。
123.4、通过历史查询,获取医学实体对应的诊断原词,通过tf-idf和相似度计算,确定与医学实体相对应的标准词,若成功,则结束,若失败,则执行步骤5。
124.其中,诊断原词可以是医生等医学专业人士已人工确认好相对应标准词的医学原文。
125.具体的,将医学实体与各个诊断原词进行tf-idf和相似度计算,将相似度大于95%的诊断原词取出,确定诊断原词对应的标准词中相似度值最大的一个标准词为与医学实体相对应的标准词。若无法得到相似度大于95%的诊断原词时,可以执行后续匹配操作。
126.由于步骤3中的匹配方式是硬规则,返回结果单一,但是可能存在不全的问题,通过步骤4的方式可以进行弥补。通过设置相似度阈值(如上述示例中的95%)的方式,返回全部的近似结果。
127.示例性的,医学原文为“右腕皮肤擦伤就诊”,确定出的医学实体为“右腕皮肤擦伤”,实体类型(标签)为疾病。通过与诊断原词进行tf-idf相似度计算,取出相似度大于95%的诊断原词对应的标准词,如表1所示。
128.表1
129.序号编号标准词相似度值取最高值1s60.800x011腕和手擦伤95.1 2s60.800x012腕部擦伤98.0√3s60.800x021腕和手水泡97.0 4s60.800x023腕部水泡96.0 5s60.800x031腕和手虫咬伤95.5 6s60.800x032腕部虫咬伤95.3 7s60.800x041腕和手浅表异物95.2 8s60.800x042腕部浅表异物97.7 9s60.900x002腕部浅表损伤96.0 130.根据上表可知,返回9个相似度值大于95%的标准词,其中序号2所对应的标准词的相似度值最大为98%,可以将序号2所对应的标准词“腕部擦伤”确定为与医学实体“右腕皮肤擦伤”相对应的标准词。
131.5、将医学实体,通过标准词库进行tf-idf和word2vec相似度计算,根据预设阈值,分别取出第一数量和第二数量的标准词(候选标准词),然后取出tf-idf和word2vec相似度计算结果中两者重叠部分标准词(待选择标准词),并执行步骤6。
132.示例性的,可以分别从tf-idf和word2vec相似度计算结果中,根据预设阈值取出前20个或前50个标准词,将二者重叠部分确定为待选择标准词。
133.步骤5中可以确定出tf-idf和word2vec相似度计算的标准词重叠部分用于后续匹配,相较于全部进行后续匹配,减少了匹配的词语数量,提高了匹配速率。
134.可选的,在将二者重叠部分确定为待选择标准词的基础上,可以将通过tf-idf计算得到的标准词中相似度高于第一相似度阈值(如:80%)且没有在重叠部分的标准词,以及,通过word2vec相似度计算得到的标准词中相似度高于第二相似度阈值(如:80%)且没有在重叠部分的标准词,添加至待选择标准词中。例如:重叠部分的待选择标准词10个,通过tf-idf计算得到的标准词中相似度高于第一相似度阈值且没有在重叠部分的标准词2个,通过word2vec相似度计算得到的标准词中相似度高于第二相似度阈值且没有在重叠部分的标准词3个,最终得到的待选择标准词为10 2 3=15个。
135.在可选方案中,增加了第一相似度阈值和第二相似度阈值对重叠部分的标准词进行补充,能够避免只针对重叠部分进行后续匹配得不到最优匹配结果的情况,适当提高了匹配准确率,但是,会增加待选择标准词的数量,导致匹配速率降低。在实际应用中,可以根据实际需求选择确定待选择标准词的方式。
136.需要说明的是,采用两者重叠部分专业术语的优势如下,利用tf-idf相似度计算:如果某个词或短语在一篇文章中出现的频率(tf)高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,可以使用sklearn机器学习库中的countvectorizer文本特征提取函数,tfidfvectorizer文本特征提取函数,直接将此次或者短语转换为词向量。另外,利用word2vec相似度计算:利用gensim工具包下的word2vec模块,使用cbow(continuous bag-of-words model,连续词袋)方法,训练预设维度(如:512维)的字向量,加权平均生成字向量。取两种相似度计算的结果重叠部分,使用多个算法融
合的目的是减少误差,互相弥补不足,能够避免错过最优标准词。
137.示例性的,医学实体为“髂动脉血栓”,将“髂动脉血栓”和疾病标准库的标准词之间进行tf-idf相似度计算,假设返回相似结果top20;将医学实体“髂动脉血栓”和疾病标准库的标准词之间进行word2vec相似度计算,假设返回相似结果top20。根据该tf-idf的相似结果top20的20个标准词和word2vec的相似结果top20的20个标准词之间重叠部分得到为8个重叠的标准词,如表2所示。
138.表2
139.序号编号标准术语1i74.500x002髂动脉闭塞2i74.500x007髂总动脉闭塞3i74.500x008髂动脉血栓形成4i74.500x009髂内动脉血栓形成5i74.500x010髂外动脉血栓形成6i74.500x011髂动脉栓塞7i74.500x012髂内动脉栓塞8i74.500x013髂外动脉栓塞
140.6、将医学实体、病历中的医学原文、医学实体的实体类别以及得到的重叠部分标准词,输入预训练好的二分类模型(标准词分类模型),得到概率最大的标准词(目标标准词)。
141.需要说明的是,建立二分类模型可以包括:第一步:准备训练集,其中包括:医学实体、标签(实体类别)、医学原文,标准词组成训练集。还可以将相对应的标准词的对应结果设为1,其他结果设为0,以扩充正样本数量,解决样本不平衡问题。训练集中的数据都是正确的,是经过医生确认准备好的。第二步:将医学实体、标签、医学原文,标准词,进行加权、embedding向量化,引入bert模型,训练0/1二分类模型,并进行迭代,以对模型参数进行更新,训练产生一个可二分类的模型作为预训练好的二分类模型。
142.示例性的,在上述示例的基础上,可以确定出医学原文为“髂动脉血栓复查”,医学实体为“髂动脉血栓”,标签(实体类型)为疾病。预训练好的二分类模型的输入条件和输出结果的公式如下:
143.医学原文 医学实体 实体类型(标签) 待选择标准词
→
1/0
144.其中,1表示匹配度达到预设阈值,若未达到,则输出0。预设阈值可以是根据经验设定的阈值,例如可以是50%、60%或75%等。
145.例如:髂动脉血栓复查 髂动脉血栓 疾病 髂动脉栓塞
→
1。
146.还需要说明的是,在通过预训练好的二分类模型得到各待选择标准词所对应的输出结果后,返回输出结果为1所对应的待选择标准词,并根据这些待选择标准词中概率最大值,确定目标标准词。
147.示例性的,在上述示例的基础上,经过预训练好的二分类模型,可以得到如下表3所示的结果。
148.表3
[0149][0150]
通过上表可知,输出结果为1的是序号1、5和6的待选择标准词。其中,序号1的髂动脉闭塞输出结果为1的概率为0.6,序号5的髂外动脉血栓形成输出结果为1的概率为0.6,序号6的髂动脉栓塞输出结果为1的概率为0.7。其中,概率值最大的为0.7,因此,可以确定序号6对应的待选择标准词髂动脉栓塞为目标标准词。
[0151]
在本实施例的上述方案中,可知,本发明通过训练产生一个可二分类的模型作为预训练好的二分类模型来先输出结果1或0,再通过为1的结果中概率最大的作为目标标准词。对本发明而言,该二分类模型的先二分类再选最大的处理过程是非限制性的,本发明还包括这样的简化方案:分类结果为o直接删除,选择分类结果为1的标准词,再按照概率排序,选择概率最大的作为目标标准词。
[0152]
可选的,图4为本发明实施例三所提供的另一种基于人工智能模型的医学术语归一化方法的流程示意图。
[0153]
如图4所述,本实施例的方法包括通过硬规则的直接匹配召回与医学实体相对应的标准词的一路召回方式,还包括通过二分类模型对医学实体进行匹配的另一路召回方式,具体包括如下步骤:
[0154]
1、输入cdr数据库中的病历文书信息。
[0155]
2、通过实体抽取模型(医学实体抽取模型)抽取医学实体,确定与医学实体的实体类型相对应的标准库。
[0156]
3、通过硬规则的直接匹配召回与医学实体相对应的标准词,若成功,则结束,若失败,则执行步骤4。
[0157]
4、将医学实体,通过标准词库进行tf-idf和word2vec相似度计算,根据预设阈值,分别取出第一数量和第二数量的标准词(候选标准词),然后取出tf-idf和word2vec相似度
计算结果中两者重叠部分标准词(待选择标准词),并执行步骤5。
[0158]
5、将医学实体、病历中的医学原文、医学实体的实体类别以及步骤5中得到的标准词,输入预训练好的二分类模型(标准词分类模型),得到概率最大的标准词(目标标准词)。
[0159]
本发明实施例的技术方案,通过从病历中抽取医学实体,并根据人工标注准确的医学实体和标准词预训练的二分类模型,得到目标标准词,在面对大量标准词时,采用多路召回中的4种方式中一种或多种予以组合判断处理,得到最为匹配的目标标准词,解决了医学术语归一化时工作量大且准确率低的问题,实现了提高医学术语的归一化准确率和速率的技术效果。
[0160]
实施例四
[0161]
图5为本发明实施例四所提供的一种基于人工智能模型的医学术语归一化装置的结构示意图,该装置包括:实体抽取模块310、第一匹配模块320、待选择标准词确定模块330和第一目标标准词确定模块340。
[0162]
其中,实体抽取模块310,用于获取医学原文,并将所述医学原文输入至预先建立的医学实体抽取模型中,确定与所述医学原文相对应的实体信息以及实体类别;第一匹配模块320,用于针对每一个实体信息,根据与所述实体类别相对应的标准词库以及所述实体信息,确定匹配结果;待选择标准词确定模块330,用于若所述匹配结果为匹配失败,则根据所述实体信息以及与所述实体类别相对应的标准词库,确定待选择标准词;第一目标标准词确定模块340,用于基于预先建立的标准词分类模型,对所述实体信息、所述实体类别、所述医学原文以及各待选择标准词进行处理,确定与所述实体信息相对应的目标标准词。
[0163]
可选的,待选择标准词确定模块330,还用于通过词频-逆文本频率方法,根据所述实体信息以及与所述实体类别相对应的标准词库,确定与所述实体信息相匹配的第一数量的第一候选标准词;通过词向量相似度方法,根据所述实体信息以及与所述实体类别相对应的标准词库,确定与所述实体信息相匹配的第二数量的第二候选标准词;根据所述第一候选标准词以及所述第二候选标准词确定待选择标准词。
[0164]
可选的,待选择标准词确定模块330,还用于若所述第一候选标准词与所述第二候选标准词相同,则将所述第一候选标准词确定为待选择标准词。
[0165]
可选的,待选择标准词确定模块330,还用于若所述第一候选标准词与所述第二候选标准词相同,则将所述第一候选标准词确定为初始待选择标准词;将除所述初始待选择标准词之外且相似度达到第一相似度阈值的第一候选标准词确定为第一待选择标准词;将除所述初始待选择标准词之外且相似度达到第二相似度阈值的第二候选标准词确定为第二待选择标准词;根据所述初始待选择标准词、所述第一待选择标准词以及所述第二待选择标准词确定待选择标准词。
[0166]
可选的,所述装置还包括:第二匹配模块,用于根据预先确定的诊断原词以及所述实体信息,确定是否存在与所述实体信息相对应的诊断原词;其中,所述诊断原词具有相匹配的候选标准词;若存在,则根据所述诊断原词以及确定与所述诊断原词相对应的候选标准词,将所述候选标准词确定为与所述实体信息相对应的目标标准词;若不存在,则返回执行根据所述实体信息以及与所述实体类别相对应的标准词库,确定待选择标准词的操作。
[0167]
可选的,所述装置还包括:医学实体抽取模型建立模块,用于所述建立医学实体抽取模型;所述医学实体抽取模型建立模块,具体用于根据医学样本原文以及预先标注的与
所述医学样本原文相对应的实体信息和实体类别,对初始医疗预训练模型进行训练,得到待测试医疗预训练模型;其中,所述初始医疗预训练模型由双向长短期记忆人工神经网络以及条件随机场构建;基于医学训练原文以及预先标注的与所述医学训练原文相对应的实体信息和实体类别对所述待测试医疗预训练模型进行测试,当测试结果满足预设条件时,将所述待测试医疗预训练模型作为医学实体抽取模型。
[0168]
可选的,所述装置还包括:标准词分类模型建立模块,用于建立标准词分类模型;所述标准词分类模型建立模块,具体用于获取医学术语训练集;其中,所述医学术语训练集包括训练医学原文、与所述训练医学原文相对应的训练实体信息、与所述训练医学原文相对应的训练实体标签、与所述训练医学原文相对应的训练标准词;基于所述医学术语训练集中的训练样本数据对初始分类模型进行训练得到待校验分类模型;基于所述医学术语训练集中的校验样本数据对所述待校验分类模型进行校验,当校验结果满足校验条件时,将所述待校验分类模型作为标准词分类模型。
[0169]
可选的,所述装置还包括:第二目标标准词确定模块,用于若所述匹配结果为匹配成功,则将匹配成功的候选标准词确定为与所述实体信息相对应的目标标准词。
[0170]
可选的,所述装置还包括:标准词库建立模块,用于构建与各实体类别相对应的数据库建立标准词库;其中,所述实体类别包括疾病实体、症状实体、药品实体、体征实体、检验实体、手术实体、检查实体、用血实体以及部位实体中的至少一种。
[0171]
本发明实施例的技术方案,通过获取医学原文,并将医学原文输入至预先建立的医学实体抽取模型中,确定与医学原文相对应的实体信息以及实体类别,以对医学原文进行实体抽取,进而,针对每一个实体信息,根据与实体类别相对应的标准词库以及实体信息,确定匹配结果,以通过完全匹配的方式确定匹配结果,若匹配结果为匹配失败,则根据实体信息以及与实体类别相对应的标准词库,确定待选择标准词,并基于预先建立的标准词分类模型,对实体信息、实体类别、医学原文以及各待选择标准词进行处理,确定与实体信息相对应的目标标准词,解决了医学术语归一化时工作量大且准确率低的问题,实现了提高医学术语的归一化准确率和速率的技术效果。
[0172]
本发明实施例所提供的基于人工智能模型的医学术语归一化装置可执行本发明任意实施例所提供的基于人工智能模型的医学术语归一化方法,具备执行方法相应的功能模块和有益效果。
[0173]
值得注意的是,上述装置所包括的各个单元和模块只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明实施例的保护范围。
[0174]
实施例五
[0175]
图6为本发明实施例五所提供的一种电子设备的结构示意图。图6示出了适于用来实现本发明实施例实施方式的示例性电子设备40的框图。图6显示的电子设备40仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
[0176]
如图6所示,电子设备40以通用计算设备的形式表现。电子设备40的组件可以包括但不限于:一个或者多个处理器或者处理单元401,系统存储器402,连接不同系统组件(包括系统存储器402和处理单元401)的总线403。
[0177]
总线403表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器,
外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(isa)总线,微通道体系结构(mac)总线,增强型isa总线、视频电子标准协会(vesa)局域总线以及外围组件互连(pci)总线。
[0178]
电子设备40典型地包括多种计算机系统可读介质。这些介质可以是任何能够被电子设备40访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
[0179]
系统存储器402可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(ram)404和/或高速缓存存储器405。电子设备40可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统406可以用于读写不可移动的、非易失性磁介质(图6未显示,通常称为“硬盘驱动器”)。尽管图6中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如cd-rom,dvd-rom或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线403相连。系统存储器402可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本发明各实施例的功能。
[0180]
具有一组(至少一个)程序模块407的程序/实用工具408,可以存储在例如系统存储器402中,这样的程序模块407包括但不限于操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块407通常执行本发明所描述的实施例中的功能和/或方法。
[0181]
电子设备40也可以与一个或多个外部设备409(例如键盘、指向设备、显示器410等)通信,还可与一个或者多个使得用户能与该电子设备40交互的设备通信,和/或与使得该电子设备40能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口411进行。并且,电子设备40还可以通过网络适配器412与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图所示,网络适配器412通过总线403与电子设备40的其它模块通信。应当明白,尽管图6中未示出,可以结合电子设备40使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、raid系统、磁带驱动器以及数据备份存储系统等。
[0182]
处理单元401通过运行存储在系统存储器402中的程序,从而执行各种功能应用以及数据处理,例如实现本发明实施例所提供的基于人工智能模型的医学术语归一化方法。
[0183]
实施例六
[0184]
本发明实施例六还提供一种包含计算机可执行指令的存储介质,所述计算机可执行指令在由计算机处理器执行时用于执行一种基于人工智能模型的医学术语归一化方法,该方法包括:
[0185]
获取医学原文,并将所述医学原文输入至预先建立的医学实体抽取模型中,确定与所述医学原文相对应的实体信息以及实体类别;
[0186]
针对每一个实体信息,根据与所述实体类别相对应的标准词库以及所述实体信息,确定匹配结果;
[0187]
若所述匹配结果为匹配失败,则根据所述实体信息以及与所述实体类别相对应的标准词库,确定待选择标准词;
[0188]
基于预先建立的标准词分类模型,对所述实体信息、所述实体类别、所述医学原文以及各待选择标准词进行处理,确定与所述实体信息相对应的目标标准词。
[0189]
本发明实施例的计算机存储介质,可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是——但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本文件中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
[0190]
计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
[0191]
计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括——但不限于无线、电线、光缆、rf等等,或者上述的任意合适的组合。
[0192]
可以以一种或多种程序设计语言或其组合来编写用于执行本发明实施例操作的计算机程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、smalltalk、c ,还包括常规的过程式程序设计语言——诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算机上执行、部分地在用户计算机上执行、作为一个独立的软件包执行、部分在用户计算机上部分在远程计算机上执行、或者完全在远程计算机或服务器上执行。在涉及远程计算机的情形中,远程计算机可以通过任意种类的网络——包括局域网(lan)或广域网(wan)—连接到用户计算机,或者,可以连接到外部计算机(例如利用因特网服务提供商来通过因特网连接)。
[0193]
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
