1.本技术涉及中文信息处理技术领域,特别是涉及一种汉字的输入、输出方法。
背景技术:
2.在计算机及其网络中语言文字的表达模式非常重要,计算机处理的数据实际上都是二进制的数据,也就是计算机实际上只能识别0和1两种状态,因此在计算机发展的过程中,人们需要解决的一个很重要的问题就是文字的处理,也就是如何将文字符号转化为二进制数据、如何给信息或者数据赋予独一无二的二进制代码。
3.世界上第一台电子计算机是由美国人发明的,它是建立在西方文化的基础之上的,而英文本身只有26个字母,再加上美国人日常使用的所有符号,也不会超过100个。基于此美国人制定了一套规则:american standard code for information interchange,美国信息交换标准代码,也就是ascii编码。
4.目前国际上使用最广泛的数据传输代码就是美国制定的ascii码。标准的ascii码是按照7比特来给每一个字符编码的,一个字节有8比特,所以是一种单字节的编码。在ascii码中,每一个字符占用一个字节中的低7位,字节的最高位是空着的,通常设定为0。由于ascii码采用7比特来编码,所以总共可以表示出27(128)个字符,包括拉丁字符的大写字母和小写字母、阿拉伯数字、标点符号以及一些特殊字符。ascii码虽然是美国的国家标准,但是由于使用广泛,国际标准化组织iso直接采用ascii作为国际标准,叫做iso646。
5.目前计算机是以字节作为信息的最小可操作单元,ascii码是高位置为“0”的可运算单字节模式,在计算机通讯技术里,7-bit ascii也叫做“安全字符”(safe characters),即能保证正确传递每一个字节,其基本工作原理是:在每个字节的八个比特里,其中七个比特运载数据,一个比特用来做奇偶检验,如果奇偶检验发现错误,就说明收到的字节发生传递错误,从而能根据程序设计做重新接收,直到奇偶检验说明收到的字节是正确的。
6.目前西文在计算机中是以ascii码表达,汉字因为字数众多无法单字节表达,只能通过使用多字节、每个字节高位置设为“1”(用于区别ascii码)并捆绑在一起的方式表达,表示汉字的两、三、四字节不能拆分、错位,否则会产生一串乱码,就像高速公路上两三辆汽车捆绑在一起运动受到极大制约,信息安全性能更是无从谈起。并且全球重要领域的信息核心系统,为了信息安全可靠运行都将非ascii码排除在外,例如全球金融信息核心系统、全球空管系统、大型数据库核心系统、全球网络域名解析系统等等。这也是我们在计算机中文系统运行时常出现死机、乱码、汉字文本出现问号黑框等的原因。更为甚者假如全球网络控制中心将信息流中的字节高位统一置“0”,就会出现ascii码平台一切运行正常,而非ascii码平台瞬间崩溃的情况。
7.因此多字节捆绑一起的汉字计算机内码表达模式的存在众多的问题:非ascii码多字节汉字机内码只起到汉字的标识作用,没有数字化排序检索等运算功能。多字节的高位置“1”捆绑模式会带来巨大的安全隐患:在某些计算机的操作系统中,没有考虑到字符代码的最高位,还有一些操作系统采用的字符代码体系是扩充了的ascii字符,也就是8位的
ascii字符,在这些操作系统中,如果一个字符的最高位为1,既可能是一个扩充的ascii字符,也可能是一个最高位设定为1的汉字,在这种情况之下,如果计算机不能做出正确的区分,就可能会出现令人头痛的“乱码”。现有的这种汉字模式会为中文计算机处理带来诸如不停转码变换等操作,因为常用的汉字输入法都需要借助汉字输入码,例如拼音码、五笔字型码等,输入码被接受后需要由汉字操作系统的“输入码转换模块”转换为机内码,才能被存储和进行各种处理,这个过程必然会产生输入码与存储码的异化,由此加大了系统开销并必然会导致出错。
技术实现要素:
8.基于此,针对已有汉字计算机内码表达模式存在的问题,提供一种汉字数据化的输入、输出方法。
9.根据本发明实施例的一个方面,提供了一种汉字数据化的输入方法,所述方法包括:
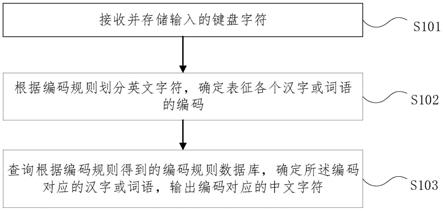
10.接收并存储输入的键盘字符;
11.根据编码规则划分英文字符,确定表征各个汉字或词语的编码;
12.查询根据编码规则得到的编码规则数据库,确定所述编码对应的汉字或词语,输出编码对应的中文字符;
13.所述编码规则为:
14.使用行、列、纵、序四位带有权位独立可计算的西文大写字母组合表示每个汉字,其中:
15.行为汉字拼音声母,使用23个西文大写字母表示,无声母将第一字符作为行表示,字母i、v、u作为特殊用途使用,行为i、v、u时表示中文标点符号或非汉字文字,西文大写字母与声母的对应关系如下:
[0016][0017]
列为汉字拼音韵母,使用26个西文大写字母表示,西文大写字母与韵母对应关系如下:
[0018][0019]
纵为汉字拼音声调,使用26个西文大写字母表示,西文大写字母与声调的对应关系如下:
[0020]
阴平声调用abc def顺序表示,阳平声调用ghi jkl顺序表示,上声声调用mno pqr
顺序表示,去声声调用tuv wxyz顺序表示,轻声声调用s表示,其中abc、ghi、mno和tuv为前部声调字母组,def、jkl、pqr和wxyz为后部声调字母,声母为ch、sh、zh或韵母为
ü
的拼音仅使用后部声调字母;对于同音同调字,按照预先确定的汉字使用频率顺序、笔画数和笔画顺序排序和分组,每26位分一组,排序位于前26位的汉字为第一组,使用对应声调字母的第一位字母作为纵,排序位于27-52位的汉字为第二组,使用对应声调字母的第二位字母作为纵,以此类推每一组内的汉字使用对应的声调字母作为各字的纵;
[0021]
序为声调顺序码,使用26个西文大写字母表示;同音同调字按照预先确定的汉字使用频率顺序、笔画数和笔画顺序排序和分组后,对于属于同一组的同音同调字,即纵相同的同音同调字根据排序结果用a-z大写字母顺序标识来作为各字的序,与纵结合表征和区分同音同调字。
[0022]
进一步地,同音同调字按照预先确定的汉字使用频率顺序、笔画数和笔画顺序排序和分组时,一个字对应繁体字位于对应简体字的后面一位,便于计算机对繁体字与简体字之间的运算转换。
[0023]
进一步地,所述编码规则还包括:
[0024]
中文词语各字之间用
“‑”
符连接,后缀字用“'”符连接,儿话音用“'e”表示,字词之间用空格分割;
[0025]
在中文文本中,通过在4位以内西文大写字母字符串前加
“‑”
符,来区分中文和西文大写字母。
[0026]
优选地,所述编码规则数据库中包含有现代普通话发音的未标识字发音。
[0027]
进一步地,所述四位带有权位独立可计算的西文大写字母是指每一位大写字母都是独立可运算单元,利用每一位大写字母对应的ascii码能够进行数学运算。
[0028]
优选地,所述编码规则还包括:
[0029]
将预先确定的常用字编码用一位、二位、三位简码表示,每个简码对应各自的四位全码供运算处理使用,所述一位简码是汉字的行一位表示,二位简码是汉字的行、列二位表示,三位简码是汉字的行、列、纵三位表示。
[0030]
进一步地,所述编码规则还包括:
[0031]
形式为“xx-xx”、“xx-xx-xx”、“xx-xx-xx-xx”的两字词、三字词、四字词为标准词,标准词内的每一个字都是二位简码表示,所述标准词是整体表示结构,不受每个二级简码字限制,计算机在对标准词进行解析时是将所述标准词看作整体一个词来处理的;非标准词使用任意简全码组合表示。
[0032]
进一步地,每个汉字的三位简码是发音码,按每个汉字对应字母组合的行、列、纵组合就能拼出所述汉字的发音;三位简码对应的xxxr,表示为对应汉字儿化音的发音码。
[0033]
根据本发明实施例的另一个方面,提供了一种汉语语音数据化的输出方法,所述方法包括:
[0034]
接收语音信息;
[0035]
识别所述语音信息的音节、声调以及句读;
[0036]
根据所述语音信息的音节、声调以及句读,通过计算和查询编码规则数据库确定对应的汉字及语句编码,然后输出所述编码和/或与编码对应的带有部分声调以及句读标记的中文文本;
[0037]
所述编码规则数据库采用上述的编码规则。
[0038]
根据本发明实施例的又一个方面,提供了一种汉字编码语音播报的输出方法,所述方法包括:
[0039]
接收带有部分声调以及句读标记的汉字编码;
[0040]
查询编码规则数据库确定对应的汉字及语句的发声特点,输出对应精确没有二义性的语音信息;
[0041]
所述编码规则数据库采用上述的编码规则。
[0042]
本发明至少具有以下有益效果:
[0043]
本发明提供的输入方法,通过接收并存储输入的键盘字符,根据编码规则划分英文字符,确定表征各个汉字或词语的编码,以及查询编码规则数据库确定所述编码对应的汉字或词语,然后输出编码对应的中文字符,可将目标文字或者语句在电子设备上输入;所述编码规则是使用行、列、纵、序四位带有权位的西文大写字母组合表示每个汉字;本发明实现了将每个汉字拆分并完全数字量化,表示汉字的每一位字母都可以独立参与计算机的运算,解决了传统的汉字机内码不可运算的难题,使得汉字在计算机中不再只是起到打字机的作用:输入、存储、排版、打印,而是可以参与计算机对信息的解析、排序、检索、计算、推理和控制;本发明在汉字与ascii码之间建立了一一对应的可识别映射关系,实现了汉字彻底的ascii码化,并可直接认读,系统在处理信息时不会像目前中文汉字机内码因为双字节或三、四字节不可拆分、不可错位、每个字节高位置为“1”等造成中文乱码甚至导致系统崩溃的严重后果,也不会被强行排除在重要信息处理系统之外,极大地提高了计算机处理中文时的精准和安全可靠程度;另外,本发明的输入法区别表示多音字、多调字和简繁体,使得每一个字母组合精确表示唯一一个汉字及其读音,同时输入码就是汉字机内码,汉字被输入时不再需要由汉字操作系统的“输入码转换模块”转换为机内码,可直接被存储和进行各种处理,避免产生输入码与存储码之间的异化,减少了系统开销以及增加系统稳定性,同时能够实现键盘汉字盲打输入和汉字的涂卡机读输入。
附图说明
[0044]
图1为本发明一个实施例提供的一种汉字数据化的输入方法示意图;
[0045]
图2为本发明一个实施例提供的一种汉语语音数据化的输出方法示意图;
[0046]
图3为本发明一个实施例提供的一种汉字编码语音播报的输出方法示意图。
具体实施方式
[0047]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
[0048]
实施例一:
[0049]
在本实施例中,如图1所示,提供了一种汉字数据化的输入方法,所述方法包括:
[0050]
步骤s101,接收并存储输入的键盘字符,所述键盘包括物理键盘或虚拟键盘,也就是该输入方法所编码的按键可以采用常用的实体键盘,也可以采用虚拟键盘,即软件程序
中提供的键盘,例如手机、平板中的键盘,存储的输入编码字符能够用于计算机进行运算和通讯。
[0051]
步骤s102,根据编码规则划分英文字符,确定表征各个汉字或词语的编码。
[0052]
步骤s103,查询根据编码规则得到的编码规则数据库,确定所述编码对应的汉字或词语,输出编码对应的中文字符。
[0053]
所述编码规则为:
[0054]
使用行、列、纵、序四位带有权位独立可计算的西文大写字母组合表示每个汉字,其中:
[0055]
行为汉字拼音声母,使用23个西文大写字母表示,无声母将第一字符作为行表示,字母i、v、u作为特殊用途使用,行为i、v、u时表示中文标点符号或非汉字文字,西文大写字母与声母的对应关系如下:
[0056][0057]
列为汉字拼音韵母,使用26个西文大写字母表示,西文大写字母与韵母对应关系如下:
[0058][0059][0060]
纵为汉字拼音声调,使用26个西文大写字母表示,西文大写字母与声调的对应关系如下:
[0061]
阴平声调用abc def顺序表示,阳平声调用ghi jkl顺序表示,上声声调用mno pqr顺序表示,去声声调用tuv wxyz顺序表示,轻声声调用s表示,其中abc、ghi、mno和tuv为前部声调字母组,def、jkl、pqr和wxyz为后部声调字母,声母为ch、sh、zh或部分韵母为
ü
的拼音仅使用后部声调字母;对于同音同调字,按照预先确定的汉字使用频率顺序、笔画数和笔画顺序排序和分组,每26位分一组,排序位于前26位的汉字为第一组,使用对应声调字母的第一位字母作为纵,排序位于27-52位的汉字为第二组,使用对应声调字母的第二位字母作为纵,以此类推每一组内的汉字使用对应的声调字母作为各字的纵;
[0062]
序为声调顺序码,使用26个西文大写字母表示;同音同调字按照预先确定的汉字使用频率顺序、笔画数和笔画顺序排序和分组后,对于属于同一组的同音同调字,即纵相同的同音同调字根据排序结果用a-z大写字母顺序标识来作为各字的序,与纵结合表征和区分同音同调字。
[0063]
具体地,例如,安的编码为abaa,其行为a,对应于无声母将第一字符作为行来表示。
[0064]
具体地,行为i、v、u的编码表示标点符号或非汉字文字,i、v、u作为行的字母组合保留为标点符号及非汉字文字的编码空间,所述非汉字文字包括日本、韩国等汉字圈国家的文字,这样就把全球象形文字全部纳入字符一维线性空间,对全球象形文字都可进行计算机排序检索等数学运算。
[0065]
具体地,韵母为ai时对应于列用z表示,将ai用西文字母最后一位来对应,可以保证韵母e、i、o、u的不错位,即西文字母e就表示韵母e、西文字母i就表示韵母i、西文字母o就可以表示韵母o、西文字母u就可以表示韵母u。
[0066]
具体地,例如,发[z
ī
]的汉字有吱ziaa、咨ziab、姿ziac、兹ziad、资ziae、資ziaf、滋ziag、孜ziah、淄ziai、缁ziaj、緇ziak、辎zial、輜ziam、嗞zian、嵫ziao、孳ziap、趑ziaq、锱ziar、錙zias、龇ziat、齜ziau、髭ziav、鲻ziaw、鯔ziax、孖ziay、赀ziaz、貲ziba、鄑zibb、粢zibc、觜zibd、镃zibe、鎡zibf、鼒zibg共33个,其中前26位吱ziaa、咨ziab、姿ziac、兹ziad、资ziae、資ziaf、滋ziag、孜ziah、淄ziai、缁ziaj、緇ziak、辎zial、輜ziam、嗞zian、嵫ziao、孳ziap、趑ziaq、锱ziar、錙zias、龇ziat、齜ziau、髭ziav、鲻ziaw、鯔ziax、孖ziay、赀ziaz为第一组,因此这些字纵都是为a,组内用a-z大写字母顺序标识作为各字的序来进行区分;第27-33位貲ziba、鄑zibb、粢zibc、觜zibd、镃zibe、鎡zibf、鼒zibg为第二组,因此这些字纵都是为b,类似地,组内用a-g顺序标识作为各字的序来进行区分。
[0067]
具体地,例如,当吗作为语气助词时其发轻声,吗发轻声时的编码为masa,对应于轻声声调用s表示。
[0068]
具体地,因为行为c时对应声母c或ch、行为s时对应声母s或sh、行为z时对应声母z或zh、列为u对应u或
ü
,如果不加以区分其具体对应哪一个,会导致对编码的解读有多义性,为了避免这种情况,声母为ch、sh、zh的卷舌音或韵母为
ü
的拼音使用def、jkl、pqr和wxyz作为声调字母,其他拼音不会引起歧义,则可使用全部声调字母。例如:财的编码为czge,其使用g表示二声声调;柴的编码为czja,其使用j表示是卷舌音的二声声调;奴的编码为nuga,其使用g表示二声声调;女的编码为nupa,其使用p表示
ü
的三声声调。
[0069]
进一步地,所述按照预先确定的汉字使用频率顺序、笔画数和笔画顺序排序和分组,具体是根据国务院在2013年发布的《通用规范汉字表》来对同音同调字排序和分组。在《通用规范汉字表》中,将收入的汉字分为三级,一级字表为常用字集,收字3500个,二级为次常用字集,收字3000个,三级为不常用字集,收字1605个,同时在每个字集内,对汉字根据笔画数目进行排列,相同笔画数的按照横、竖、撇、点顺序排列,因此在每个字集内,对汉字都是在使用频率范围内由简单到复杂顺序排列的。并且因为对《通用规范汉字表》三级字库的收入和分类是大数据统计的结果,因此《通用规范汉字表》的内容是相对稳定的,根据《通用规范汉字表》作为同音同调字纵的分组和顺序码排序依据是非常科学和合理的,可以保证在此编码规则对应的编码规则数据库中,发音是按照拼音顺序排列,同音同调字是根据常用到不常用、字体由简单到复杂排列的,编码规则数据库的字库中部分汉字编码如下所示:
[0070][0071][0072]
其中@对的中文字符是在《通用规范汉字表》中收录有这个字,但是目前在计算机上无法显示,由上述摘选的部分汉字编码可以清楚看出编码时发音是按照拼音顺序排列,同音同调字是根据常用到不常用、字体由简单到复杂排列的,极具科学性。
[0073]
同时,在所述编码规则数据库的字库中,例如,好[h
ǎ
o]对应的编码为hdma,好[h
à
o]对应的编码为hdtc,表示同形多音字各自独立表示,同字的不同读音分别对应不同的编码,提高了中文表达的准确性和精确度,而目前的汉字机内码只是对该字型的一个编码,无法区分多音字。
[0074]
具体地,同音同调字按照预先确定的汉字使用频率顺序、笔画数和笔画顺序排序
和分组时,一个字对应繁体字位于对应简体字的后面一位,便于计算机对繁体字与简体字之间的运算转换。例如“马”的编码为mama,马的繁体字“馬”的编码mamb,计算机对于“马”的序进行 1,就可直接计算的到“馬”的编码。另外,当一个汉字具有多个繁体字时,多个繁体字分别对应各自的简体字,保证繁体字与简体字之间的运算转换不会出错。例如,“台”字念[t
á
i]时有三个繁体字,分别是“臺”、“颱”、“檯”,因此在对“台”进行编码时,首先对它作为独立字时编码,其作为独立字时的编码为tzga,然后依次对其三个繁体字对应的简体字及其该繁体字进行编码,在编码规则数据库中体现为:台tzgb、臺tzgc、台tzgd、颱tzge、台tzgf、檯tzgg,使得无论一个汉字具有多少个繁体字,仍然可根据规则直接进行繁体字与简体字之间的运算转换。再例如,里作为公里的里时,没有繁体字,而作为里面的里时,是具有繁体字的,因此对两个里要先分别作为独立字编码,同时里面的里后面一位是其对应的繁体字,因此在编码规则数据库中体现为:里limd、里lime、裏limf,里limd表示的是公里的里,里lime表示的是里面的里。
[0075]
进一步地,所述编码规则还包括:
[0076]
中文词语各字之间用
“‑”
符连接,后缀字用“'”符连接,儿话音用“'e”表示,字词之间用空格分割;中文文本中,通过在4位以内西文大写字母字符串前加
“‑”
符,来区分中文和西文大写字母。
“‑”
、“'”对应的就是ascii通用符。例如,“他是我们的好榜样”,这一句话对应t's w-m'd h bc-yc。再例如,“树根儿”对应的编码为su-gg'e,“抠门儿”对应的编码为kt-mg'e,使得儿化音可以独立表示,区别于“儿”作为词语时的编码,例如“女儿”对应的编码为nu-e。另外,如果在一篇中文文章中需要输入4位以内的西文大写字母,为了和汉字编码作为区分,需要在输入时在所述西文大写字母前加
“‑”
符号,并且由于字词本身已用空格进行分割,这里使用的
“‑”
符号也不会和连接词语时使用的
“‑”
符号混淆。例如,“我在ibm公司上班”,这一句话对应编码是w'zz-ibm gr-si sc-bb,这样系统在处理输入的字符串时,就不会将ibm识别为某个汉字编码。
[0077]
基于此,在步骤s102中能准确区分后缀字和词,同时正确划分英文字符,确定表征各个汉字或词语的编码以及中文语句所包含的句读信息,便于计算机进行语意处理。
[0078]
进一步地,所述编码规则数据库中包含有现代普通话发音的未标识字发音。例如“一”只有读音[y
ī
],但是其有多种会产生变调的情况:“一”字独用、作为词或句子的最后一个字使用时,读本调第一声,如统一、一九等;“一”字用在第四声的前面时,“一”变调读第二声,如一个、一次、一样等;“一”字用在第一声、第二声、第三声时,“一”变调读第四声,如一回、一种、一张等,另外在口语中,人们也经常习惯于将“一”读作[y
ā
o]。因此在本编码规则数据库中加入了这些汉字经过变调后的发音以及口语化的发音,“一”字对应于一声、二声、四声音调以及[y
ā
o]的读音,其对应的编码分别为yiaa、yiga、yita和ydaa,类似的情况还包括七、八和不。
[0079]
进一步地,所述四位带有权位独立可计算的西文大写字母是指每一位大写字母都是独立可运算单元,利用每一位大写字母对应的ascii码能够进行数学运算,也就是将汉字在ascii码之间建立了一一对应的映射关系,实现了汉字彻底的ascii码化,计算机在处理汉字信息时不会再出现乱码问题,极大地提高了计算机处理中文时的精准和安全可靠程度。
[0080]
例如,“我”对应的编码是woma,字符w对应的ascii码是87,字符o对应的ascii码是
79,字符m对应的ascii码是77,字符a对应的ascii码是65,对字符w进行-9变为n、字符o进行-6变为i、字符m进行 0还是m、字符a进行 2变为c,由此可将“我”的编码进行运算后变换为“你”nimc。
[0081]
类似地,因为所述四位带有权位独立可计算的西文大写字母是指每一位大写字母都是独立可运算单元,通过这种编码方法能够进行诗歌押韵的判定,所谓押韵就是需要诗歌每一句最后一个字的韵母和声调都要相同,也就是通过判定诗歌每一句最后一个字对应编码的列是否一致、纵是否属于同类,就可判定诗句是否押韵。例如在诗歌“床前明月光,疑是地上霜;举头望明月,低头思故乡”中,光对应的编码为glaa、霜对应的编码为sldc、乡对应的编码为xlaa,三字的列都为l,且纵都属于一声对应的音调字母,因此可以判定此三句诗词是满足押韵的。
[0082]
进一步地,所述编码规则还包括:
[0083]
在所述编码规则数据库的字库中,将常用字用一位、二位、三位简码表示,每个简码对应各自的四位全码供运算处理使用,所述一位简码是汉字的行一位表示,二位简码是汉字的行、列二位表示,三位简码是汉字的行、列、纵三位表示。例如可用t来表示他(taaa),可用tc来表示堂(tcgb),可用tcm来表示躺(tcmc)。
[0084]
具体地,在所述编码规则数据库的字库中,所述一位简码与汉字的对应关系为:
[0085][0086]
具体地,在所述编码规则数据库的字库中,所述二位简码与汉字的对应关系为:
[0087]
[0088][0089]
特殊地,其中由于十、时、亿比较常用,用两位简码表示会非常实用,因此用未被使用的ea、eb、ec二位简码来分别表示十、时、亿,同样,这几位简码分别对应十、时、亿的原四位可计算全码。
[0090]
进一步地,形式为“xx-xx”、“xx-xx-xx”、“xx-xx-xx-xx”的两字词、三字词、四字词为标准词,标准词内的每一个字都是二位简码表示,所述标准词是整体表示结构,不受每个二级简码字限制;非标准词可以使用任意简全码组合表示。例如,“新华社”这一词可以表示为xp-hj-se,表示整体独立不受对应二位简码字限制的标准词,计算机在对标准词进行解析时是将所述标准词看作整体一个词来处理的,以此提高计算机处理汉字信息的效率;“我们”这一词可以表示为w-m,“担架”可以表示为dbab-jjte,“人才”可以表示为r-czg,对应与非标准词可以使用任意简全码组合表示,对于非标准词,计算机都是按字独立解析的。因此本发明将常用词以标准词的形式收录入编码规则数据库的标准词库,所述编码规则数据库的标准词库中部分标准词编码如下:
[0091][0092]
基于此,在步骤s103中查询根据编码规则得到的编码规则数据库,确定所述编码对应的汉字或词语时,对于标准词会通过检索编码规则数据库中的标准词库,来确定标准词编码对应的中文字符并输出,而对于单独的汉字和非标准词,是通过检索编码规则数据库中的字库来确定每个编码对应的中文字符并输出的。
[0093]
进一步地,所述编码规则还包括:
[0094]
每个汉字的三位简码是发音码,也就是计算机在对键盘输入的字母组合进行中文同声翻译来语音播报时,按每个汉字对应字母组合的行、列、纵组合就能拼出所述汉字的发音;三位简码对应的xxxr,表示为对应汉字儿化音的发音码。从编码规则数据库的字库中抽取全部三位简码作为发音码和全部儿话音音码xxxr,组成新的音码库,能够为汉字与对应发音建立没有二义性的映射关系。
[0095]
本发明提供的输入法成功实现了“文同音”,符合现代社会语音信息统一、标准交流发展的需要。由于汉字本身不具有发音属性导致全国识字不同音的现象,而本发明提供的方法则直观、完备的将对应汉字的发音(包括四声)可直观表达并锁定。“文同音”功能极大改善中文的学习、使用、扩展能力,同时也极大扩展了计算机处理中文的能力。
[0096]
进一步地,所述编码规则数据库中的字库,理论上能够容纳264个字符,足以包含汉字发展至今,包括罕用字、异体字在内的所有汉字字符。
[0097]
在本实施例提供的输入方法中,通过接收并存储输入的键盘字符,根据编码规则划分英文字符,确定表征各个汉字或词语的编码,以及查询编码规则数据库确定所述编码对应的汉字或词语,然后输出编码对应的中文字符,可将目标文字或者语句在电子设备上输入。所述编码规则是使用行、列、纵、序四位带有权位的西文大写字母组合表示每个汉字,同时输入时中文词语各字之间用
“‑”
符连接,后缀字用“'”符连接,儿话音用“'e”表示,字词之间用空格分割。这种输入方法实现了将每个汉字拆分并完全数字量化,表示汉字的每一位字母都可以独立参与计算机的运算,解决了传统的汉字机内码不可运算的难题,使得汉字在计算机中不再只是起到打字机的作用:输入、存储、排版、打印,而是可以参与计算机对信息的解析、排序、检索、计算、推理和控制。
[0098]
本发明实施例在汉字与ascii码之间建立了一一对应可直接识别的映射关系,实现了汉字彻底的ascii码化,系统在处理信息时不会像目前中文汉字机内码因为双字节或三、四字节不可拆分、不可错位、每个字节高位置为“1”等造成中文乱码甚至导致系统崩溃的严重后果,也不会被强行排除在重要信息处理系统之外,极大地提高了计算机处理中文时的精准和安全可靠程度,同时使得可以方便地在计算机及各类数字化设备和网络间进行汉字信息的输入、存储、传输和控制。
[0099]
另外,本发明的编码规则区别表示多音字、多调字和简繁体,使得每一个字母组合精确表示唯一一个汉字及其读音,并且能在输入时合理断字断词,让计算机精确理解语句的语意,使得输入的语句没有二义性,使得汉字输入可以实现真正意义上的盲打。同时输入码就是汉字机内码,汉字被输入时不再需要由汉字操作系统的“输入码转换模块”转换为机内码,才能被存储和进行各种处理,减少了系统开销以及增加系统稳定性,并且能够实现汉字的盲打输入。同时计算机可按每个汉字对应字母组合的行、列、纵组合拼出所述汉字的发音,计算机在对键盘输入的字母组合序列进行同声翻译时,能够准确翻译和播报输入者要表达的含义。
[0100]
同时,对于本发明实施例提供的输入方法,学生学习汉语拼音时只需一堂课即可掌握汉字拼音与行、列、纵、序各自的对应关系,即可迅速进入盲打状态,简单、易学。并且本发明还可使得目前考试、填表等汉字计算机输入,实现用26个字母涂卡机读来处理,极大地提高了信息处理的速度,节省了大量的劳动力。
[0101]
实施例二:
[0102]
在本实施例中,如图2所示,提供一种汉语语音数据化的输出方法,所述方法包括:
[0103]
s201,接收语音信息。
[0104]
s202,识别所述语音信息的音节、声调以及句读。
[0105]
s203,根据所述语音信息的音节、声调以及句读,通过计算和查询编码规则数据库确定对应的汉字及语句编码,然后输出所述编码和/或与编码对应的带有部分声调以及句
读标记的中文文本。
[0106]
所述编码规则数据库可采用实施例一中所述的编码规则。
[0107]
所述的计算指的是根据所述语音信息的音节、声调以及句读信息,精确区分后缀字与词语的读音差别,以及对断句有精确的判断。
[0108]
例如,对于“这样的人才是我们需要的”这句语音信息,这句话是有两种含义的:
[0109]
①
这样的人/才是我们需要的;
[0110]
②
这样的人才/是我们需要的。
[0111]
当语音信息分别按两种含义来叙述时,计算机能识别音节、声调以及句读信息,对中文词语各字之间用
“‑”
符连接、后缀字用“'”符连接,词语之间用空格分隔,来输出所述语音信息对应的编码:
[0112]
①
这样的人/才是我们需要的ze-yc'd r czg-s w-m xu-yd'd;
[0113]
②
这样的人才/是我们需要的ze-yc'd r-czg's w-m xu-yd'd。
[0114]
因此,通过此方法,能在输出编码信息实现对中文语音的断字断词判断,使得输出的编码信息没有二义性。
[0115]
类似地,对于“武汉市长江大桥”这句话,因为“长”本身是多音字以及断句的不同,这句话是有歧义存在,可以指代长江大桥,也可以指代市长。当语音信息分别按两种含义来叙述时,计算机能识别音节、声调以及句读信息,对中文词语各字之间用
“‑”
符连接、后缀字用“'”符连接,词语之间用空格分隔,同时因为所述编码规则中中文多音字是分别独立表示的,输出所述语音信息对应的编码和中文字符时能对两种含义作出区分:
[0116]
①
武汉市/长江大桥
[0117]
wu-hb-si cc-jla da-qm,指代的是桥;
[0118]
②
武汉市长/江大桥
[0119]
wu-hb si-zc jla-da-qm,指代的是人。
[0120]
类似地,对于“北大图书馆一楼的同学”这句话,“一”有多个音调,这句话也是有歧义存在的,“一”读一声时,指代图书馆里第一层的同学,“一”读四声时,指代图书馆其中一栋楼里的同学。同样地,当语音信息分别按两种含义来叙述时,计算机能识别音节、声调以及句读信息,对中文词语各字之间用
“‑”
符连接、后缀字用“'”符连接,词语之间用空格分隔,同时因为所述编码规则中汉字声调是分别独立表示的,输出所述语音信息对应的编码能对两种含义作出区分:
[0121]
①
北大图书馆一楼的同学
[0122]
bf-da tu-su-gv yi-lt'd tr-xw,指代图书馆里第一层的同学;
[0123]
②
北大图书馆一楼的同学
[0124]
bf-da tu-su-gv yita-lt'd tr-xw,指代图书馆其中一栋楼里的同学。
[0125]
同样,对于“还欠人民币200万元”这句话,“还”字读音是“hu
á
n”还是“h
á
i”表达了两种截然相反的意思,对于语意的区分是十分重要的,同样地,当语音信息分别按两种含义来叙述时,计算机能识别音节、声调以及句读信息,对中文词语各字之间用
“‑”
符连接、后缀字用“'”符连接,词语之间用空格分隔,同时因为所述编码规则中汉字声调是分别独立表示的,输出所述语音信息对应的编码时能对两种含义作出区分:
[0126]
①
还(hu
á
n)欠人民币200万元
[0127]
hvg qkt rg-mp-bi 200wb-yv,表示已经还(hu
á
n)了欠款200万元;
[0128]
②
还(h
á
i)欠人民币200万元
[0129]
hz qkt rg-mp-bi 200wb-yv,表示仍然还(h
á
i)欠200万元。
[0130]
类似地,对于“多少”这个词,可以将多和少看作是整体的词,也可将少看作是后缀字,两种理解会导致对语句不同的理解,当语音信息分别按两种含义来叙述时,计算机能识别音节、声调以及句读信息,对中文词语各字之间用
“‑”
符连接、后缀字用“'”符连接,词语之间用空格分隔,输出所述语音信息对应的编码时能对两种含义作出区分:
[0131]
①
冬天衣服能穿多少穿多少
[0132]
dr-tk yi-fu nh cvdb dy-sd cvdb dy-sd,这里的多和少是一个组合在一起整体的词,此处表达的是要尽可能多穿;
[0133]
②
夏天衣服能穿多少穿多少
[0134]
xj-tk yi-fu nh cvdb dy'sd cvdb dy'sd,这里的少是后缀字,此处表达的是要尽可能少穿。
[0135]
本实施例的技术效果与实施例一相同,在此不作赘述。
[0136]
实施例三:
[0137]
在本实施例中,如图3所示,提供了一种汉字编码语音播报的输出方法,所述方法包括:
[0138]
步骤s301,接收带有部分声调以及句读标记的汉字编码。
[0139]
步骤s302,查询编码规则数据库确定对应的汉字及语句的发声特点,输出对应精确没有二义性的语音信息。
[0140]
所述编码规则数据库可采用实施例一中所述的编码规则。
[0141]
例如,对于“这样的人才是我们需要的”这句话,输入时断字断句的不同导致这句话是有两种含义的,相应的对编码进行翻译和语音播报时音节、声调以及句读是不同的,当按照两种不同含义来输入汉字编码时,计算机能根据所述编码规则对所述编码进行解析,确定对应的汉字及语句的发声特点,从而输出不同的语音信息:
[0142]
①
ze-yc'd r czg-s w-m xu-yd'd
[0143]
这样的人/才是我们需要的;
[0144]
②
ze-yc'd r-czg's w-m xu-yd'd
[0145]
这样的人才/是我们需要的。
[0146]
类似地,对于“武汉市长江大桥”这句话,由于“长”本身是多音字以及断句的不同,这句话是有歧义存在,可以指代长江大桥,也可以指代市长。相应地,对编码进行翻译和语音播报时音节、声调以及句读是不同的,当按照两种不同含义来输入汉字编码时,计算机能根据所述编码规则对所述编码进行解析,确定对应的汉字及语句的发声特点,从而输出不同的语音信息:
[0147]
①
wu-hb-si cc-jla da-qm
[0148]
武汉市/长江大桥,指代的是桥;
[0149]
②
wu-hb si-zc jla-da-qm
[0150]
武汉市长/江大桥,指代的是人。
[0151]
类似地,对于“北大图书馆一楼的同学”这句话,“一”有多个音调,这句话也是有歧
义存在的,“一”读一声时,指代图书馆里第一层的同学,“一”读四声时,指代图书馆其中一栋楼里的同学。同样地,当按照两种不同含义来输入汉字编码时,计算机能根据所示编码规则对所述编码进行解析,确定对应的汉字及语句的发声特点,从而输出不同的语音信息:
[0152]
①
bf-da tu-su-gv yi-lt'd tr-xw
[0153]
北大图书馆一楼的同学,对一输出一声的读音,指代图书馆里第一层的同学;
[0154]
②
bf-da tu-su-gv yita-lt'd tr-xw
[0155]
北大图书馆一楼的同学,对一输出四声的读音,指代图书馆其中一栋楼里的同学。
[0156]
同样地,对于“还欠人民币200万元”这句话,“还”字读音是“hu
á
n”还是“h
á
i”表达了两种截然相反的意思,对于语意的区分是十分重要的,同样地,当按照两种不同含义来输入汉字编码时,计算机能根据所述编码规则对所述编码进行解析,确定对应的汉字及语句的发声特点,从而输出不同的语音信息:
[0157]
①
hvg qkt rg-mp-bi 200wb-yv
[0158]
还(hu
á
n)欠人民币200万元,对还输出hu
á
n的读音,表示已经还了欠款200万元;
[0159]
②
hz qkt rg-mp-bi 200wb-yv
[0160]
还(h
á
i)欠人民币200万元,对还输出h
á
i的读音,表示仍然还欠200万元。
[0161]
类似地,对于“多少”这个词,可以将多和少看作是整体的词,也可将少看作是后缀字,两种理解会导致对语句不同的理解,当按照两种不同含义来输入汉字编码时,计算机能根据所述编码规则对所述编码进行解析,确定对应的汉字及语句的发声特点,从而输出不同的语音信息:
[0162]
①
dr-tk yi-fu nh cvdb dy-sd cvdb dy-sd
[0163]
冬天衣服能穿多少穿多少,这里的多和少是一个组合在一起整体的词,指代数量,发音时多和少作为整体来读,此处表达的是要尽可能多穿;
[0164]
②
xj-tk yi-fu nh cvdb dy'sd cvdb dy'sd,
[0165]
夏天衣服能穿多少穿多少,这里的少是多的后缀字,发音时对少会作强调,此处表达的是要尽可能少穿。
[0166]
进一步地,计算机在对键盘输入的字母组合序列进行翻译和语音播报时,根据接收的输入信息中的
“‑”
和“'”符号能够识别词语、后缀字和儿话音,对所述字母组合序列按语法、语意排列成句,语音播报翻译结果时能够合理断字断词,不会出现有歧义的语句,例如可以理解武汉市长江大桥说的是“人”还是“桥”、可以理解“还欠人民币200万元”说的是已经还了欠款200万元还是仍然还欠200万元,使得输入的中文数据是有价值的。
[0167]
本实施例的技术效果与实施例一相同,在此不作赘述。
[0168]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0169]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。