1.本技术涉及智能语音助手安全技术领域,尤其涉及一种基于遗传算法的智能语音助手唤醒词识别模型加固方法和装置。
背景技术:
2.随着人工智能的飞速发展,现有的音箱等设备日趋智能化,可以通过语音助手与用户完成互动。用户便可以用语音指令实现各种功能,如播放音乐、搜索网页、拨打电话等,因此语音助手的安全性对于用户隐私与安全显得至关重要。
3.现有的语音助手通常都通过唤醒词激活,语音助手会检测周围的语音,只有在用户说出预设的唤醒词后,语音助手才会被激活以接收进一步的指令,因此语音助手的正确唤醒是保护用户隐私与安全的关键,一旦语音助手被节目广播或是谈话间误唤醒,就会开始录制周围的语音,对用户隐私造成侵害,甚至可能接受错误的指令,对用户的安全造成影响。
4.现有的语音助手唤醒模型通常由一个部署在本地的轻量模型和在云端的检测模型组成,共同用于识别环境中可能的唤醒词,但由于训练数据不充分等原因,语音助手的唤醒模型往往会被误唤醒,将非唤醒词的单词识别为唤醒词而被错误激活,由此带来许多安全问题。
技术实现要素:
5.本技术旨在至少在一定程度上解决相关技术中的技术问题之一。
6.为此,本技术的第一个目的在于提出一种基于遗传算法的智能语音助手唤醒词识别模型加固方法,解决了现有语音助手误唤醒词挖掘难度大、误唤醒现象频繁难以优化的问题,提供了一种高效低成本的语音助手模型加固方法,实现了对语音助手的误唤醒词挖掘,并进一步对语音助手的误唤醒词检测模型进行了加固。
7.本技术利用唤醒词的音素特征,定义不同单词间的不相似性度量,采用遗传算法,进行涵盖误唤醒率与不相似性的多目标优化问题求解,利用文字转语音系统(tts)进行快速的自动化搜索,以找到尽可能多位于帕累托前沿面的误唤醒词,将误唤醒词作为再训练的样本,用于加固原有的唤醒词识别模型,反复迭代以提升模型识别唤醒词的准确率。
8.本技术的第二个目的在于提出一种基于遗传算法的智能语音助手唤醒词识别模型加固方法装置。
9.本技术的第三个目的在于提出一种非临时性计算机可读存储介质。
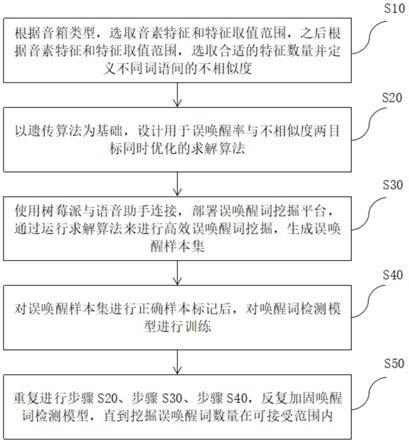
10.为达上述目的,本技术第一方面实施例提出了一种基于遗传算法的智能语音助手唤醒词识别模型加固方法,包括:步骤s10:根据音箱类型,选取音素特征和特征取值范围,之后根据音素特征和特征取值范围,选取合适的特征数量并定义不同词语间的不相似度;步骤s20:以遗传算法为基础,设计用于误唤醒率与不相似度两目标同时优化的求解算法;步骤s30:使用树莓派与语音助手连接,部署误唤醒词挖掘平台,通过运行求解算法来进行
高效误唤醒词挖掘,生成误唤醒样本集;步骤s40:对误唤醒样本集进行正确样本标记后,对唤醒词检测模型进行训练;步骤s50:重复进行步骤s20、步骤s30、步骤s40,反复加固唤醒词检测模型,直到挖掘误唤醒词数量在可接受范围内。
11.可选地,在本技术的一个实施例中,根据音箱类型,选取音素特征和特征取值范围,包括:
12.对于中文音箱,选取声母、韵母、音调作为音素特征,特征取值范围为汉语中使用的声母韵母以及四个声调;
13.对于英文音箱,选取字母作为音素特征,特征取值范围为阿拉伯字母与占位符“/”。
14.可选地,在本技术的一个实施例中,对于中文音箱,选取的特征数量为唤醒词汉字个数的3倍,分别对应每个汉字的声母、韵母、声调;
15.对于中文音箱,两个中文单词间的不相似度表示为:
[0016][0017]
其中,表示两个中文单词,ci表示对应位置的特征,表示预定义的两特征间的距离。
[0018]
可选地,在本技术的一个实施例中,对于英文音箱,选取的特征数量为单词字母个数的1.5倍,分别对应于该位置的字母或占位符;
[0019]
对于英文音箱,两个英文单词间的不相似度表示为:
[0020][0021]
其中,表示两个英文单词,ci表示单词对应的音素,表示预定义的两音素间的不相似度,d,i,e分别是将单词w1转变为单词w2所需的删除、插入、替换操作集合。
[0022]
可选地,在本技术的一个实施例中,以遗传算法为基础,设计用于误唤醒率与不相似度两目标同时优化的求解算法,包括以下步骤:
[0023]
步骤s21:将唤醒词、与唤醒词接近的词,以及初始化的词作为初始样本,其中,通过计算唤醒词的不相似度,选取不相似度小于预设值的特征重新组合得到与唤醒词接近的词;
[0024]
步骤s22:分别评估样本的误唤醒率和不相似度,其中,误唤醒率定义为播放样本;
[0025]
步骤s23:依照帕累托支配与拥挤度排序的方式对样本进行选择,得到保留样本;
[0026]
步骤s24:对保留样本集合进行变异操作,以得到下一代的样本集合,其中,变异操作包括:随机选择集合中的两个样本并随机交换一段特征,或将某个样本的某个特征随机更新为取值范围内的其他特征;
[0027]
步骤s25:重复步骤s22、步骤s23、步骤s24,直到达到算法最大迭代数,生成最终样本集合。
[0028]
可选地,在本技术的一个实施例中,依照帕累托支配与拥挤度排序的方式对样本进行选择,具体为:
[0029]
选择集合中的帕累托前沿作为被保留的样本,选择后在集合中删去被选择保留的样本,继续选择剩余样本的帕雷托前沿,若某次选择帕累托前沿的样本后,将使被选择的样本数超过了预设的保留样本数,则按照拥挤度对该次选择的样本进行降序排序,逐一保留样本直到选择的样本数达到预设的保留样本数。
[0030]
可选地,在本技术的一个实施例中,使用树莓派与语音助手连接,部署误唤醒词挖掘平台,通过运行求解算法来进行高效误唤醒词挖掘,生成误唤醒样本集,包括以下步骤:
[0031]
步骤s31:在电脑端运行求解算法,生成待测试的样本,通过扬声器向智能音箱播放生成的样本;
[0032]
步骤s32:通过光传感器与智能音箱连接,判断智能音箱的语音助手是否被激活,树莓派将激活结果返回电脑;
[0033]
步骤s33:在预设的算法迭代次数达到后,记录并保存测试过程中样本的不相似度与误唤醒率,保留具有一定误唤醒率的样本作为误唤醒样本集。
[0034]
可选地,在本技术的一个实施例中,对误唤醒样本集进行正确样本标记,具体为:
[0035]
将误唤醒样本标记为负类后,在初次训练数据集中随机选取正样本,使得新的数据集中的正负样本比例与原有数据集的正负样本比例一致,
[0036]
采用交叉熵损失函数为目标训练唤醒词检测模型,其中,交叉熵损失函数表示为:
[0037][0038]
其中,yi表示样本是否为正类,pi表示样本被预测为正类的概率。
[0039]
为达上述目的,本技术第二方面实施例提出了一种基于遗传算法的智能语音助手唤醒词识别模型加固装置,包括:特征预处理模块、算法设计模块、误唤醒词挖掘模块、训练模块、重复模块,其中,
[0040]
特征预处理模块,用于根据音箱类型,选取音素特征和特征取值范围,之后根据音素特征和特征取值范围,选取合适的特征数量并定义不同词语间的不相似度;
[0041]
算法设计模块,用于以遗传算法为基础,设计用于误唤醒率与不相似度两目标同时优化的求解算法;
[0042]
误唤醒词挖掘模块,用于使用树莓派与语音助手连接,部署误唤醒词挖掘平台,通过运行求解算法来进行高效误唤醒词挖掘,生成误唤醒样本集;
[0043]
训练模块,用于对误唤醒样本集进行正确样本标记后,对唤醒词检测模型进行训练;
[0044]
重复模块,用于重复调用算法设计模块、误唤醒词挖掘模块、训练模块,反复加固唤醒词检测模型,直到挖掘误唤醒词数量在可接受范围内。
[0045]
为了实现上述目的,本技术第三方面实施例提出了一种非临时性计算机可读存储介质,当存储介质中的指令由处理器被执行时,能够执行一种基于遗传算法的智能语音助手唤醒词识别模型加固方法。
[0046]
本技术实施例的基于遗传算法的智能语音助手唤醒词识别模型加固方法、基于遗传算法的智能语音助手唤醒词识别模型加固装置和非临时性计算机可读存储介质,解决了
现有语音助手误唤醒词挖掘难度大、误唤醒现象频繁难以优化的问题,提供了一种高效低成本的语音助手模型加固方法,实现了对语音助手的误唤醒词挖掘,并进一步对语音助手的误唤醒词检测模型进行了加固。
[0047]
本技术利用唤醒词的音素特征,定义不同单词间的不相似性度量,采用遗传算法,进行涵盖误唤醒率与不相似性的多目标优化问题求解,利用文字转语音系统(tts)进行快速的自动化搜索,以找到尽可能多位于帕累托前沿面的误唤醒词,将误唤醒词作为再训练的样本,用于加固原有的唤醒词识别模型,反复迭代以提升模型识别唤醒词的准确率。
[0048]
本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
附图说明
[0049]
本技术上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
[0050]
图1为本技术实施例一所提供的一种基于遗传算法的智能语音助手唤醒词识别模型加固方法的流程图;
[0051]
图2为本技术实施例的基于遗传算法的智能语音助手唤醒词识别模型加固方法的另一个流程图;
[0052]
图3为本技术实施例的基于遗传算法的智能语音助手唤醒词识别模型加固方法的误唤醒词挖掘平台图;
[0053]
图4为本技术实施例的采用开源数据集训练模型加固前后误唤醒词挖掘效率图;
[0054]
图5为本技术实施例二所提供的一种基于遗传算法的智能语音助手唤醒词识别模型加固装置的结构示意图。
具体实施方式
[0055]
下面详细描述本技术的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本技术,而不能理解为对本技术的限制。
[0056]
下面参考附图描述本技术实施例的基于遗传算法的智能语音助手唤醒词识别模型加固方法和装置。
[0057]
图1为本技术实施例一所提供的一种基于遗传算法的智能语音助手唤醒词识别模型加固方法的流程图。
[0058]
如图1所示,该基于遗传算法的智能语音助手唤醒词识别模型加固方法包括以下步骤:
[0059]
步骤s10:根据音箱类型,选取音素特征和特征取值范围,之后根据音素特征和特征取值范围,选取合适的特征数量并定义不同词语间的不相似度;
[0060]
步骤s20:以遗传算法为基础,设计用于误唤醒率与不相似度两目标同时优化的求解算法;
[0061]
步骤s30:使用树莓派与语音助手连接,部署误唤醒词挖掘平台,通过运行求解算法来进行高效误唤醒词挖掘,生成误唤醒样本集;
[0062]
步骤s40:对误唤醒样本集进行正确样本标记后,对唤醒词检测模型进行训练;
[0063]
步骤s50:重复进行步骤s20、步骤s30、步骤s40,反复加固唤醒词检测模型,直到挖掘误唤醒词数量在可接受范围内。
[0064]
本技术实施例的基于遗传算法的智能语音助手唤醒词识别模型加固方法,通过步骤s10:根据音箱类型,选取音素特征和特征取值范围,之后根据音素特征和特征取值范围,选取合适的特征数量并定义不同词语间的不相似度;步骤s20:以遗传算法为基础,设计用于误唤醒率与不相似度两目标同时优化的求解算法;步骤s30:使用树莓派与语音助手连接,部署误唤醒词挖掘平台,通过运行求解算法来进行高效误唤醒词挖掘,生成误唤醒样本集;步骤s40:对误唤醒样本集进行正确样本标记后,对唤醒词检测模型进行训练;步骤s50:重复进行步骤s20、步骤s30、步骤s40,反复加固唤醒词检测模型,直到挖掘误唤醒词数量在可接受范围内。由此,能够解决现有语音助手误唤醒词挖掘难度大、误唤醒现象频繁难以优化的问题,提供了一种高效低成本的语音助手模型加固方法,实现了对语音助手的误唤醒词挖掘,并进一步对语音助手的误唤醒词检测模型进行了加固。
[0065]
本技术利用唤醒词的音素特征,定义不同单词间的不相似性度量,采用遗传算法,进行涵盖误唤醒率与不相似性的多目标优化问题求解,利用文字转语音系统(tts)进行快速的自动化搜索,以找到尽可能多位于帕累托前沿面的误唤醒词,将误唤醒词作为再训练的样本,用于加固原有的唤醒词识别模型,反复迭代以提升模型识别唤醒词的准确率。
[0066]
进一步地,在本技术实施例中,根据音箱类型,选取音素特征和特征取值范围,包括:
[0067]
对于中文音箱,选取声母、韵母、音调作为音素特征,特征取值范围为汉语中使用的声母韵母以及四个声调;
[0068]
对于英文音箱,选取字母作为音素特征,特征取值范围为阿拉伯字母与占位符“/”。
[0069]
进一步地,在本技术实施例中,对于中文音箱,选取的特征数量为唤醒词汉字个数的3倍,分别对应每个汉字的声母、韵母、声调;
[0070]
对于中文音箱,归一化后的中文单词间的不相似度表示为:
[0071][0072]
其中,表示两个中文单词,ci表示对应位置的特征,表示预定义的两特征间的距离,选取α=100以获得更均匀的不相似度分布。
[0073]
进一步地,在本技术实施例中,对于英文音箱,选取的特征数量为单词字母个数的1.5倍,分别对应于该位置的字母或占位符;
[0074]
对于英文音箱,归一化后的英文单词间的不相似度表示为:
[0075][0076]
其中,表示两个英文单词,ci表示单词对
应的音素,表示预定义的两音素间的不相似度,d,i,e分别是将单词w1转变为单词w2所需的删除、插入、替换操作集合。
[0077]
对于英文音箱,英文唤醒词的特征数量选取为略大于单词字母个数,具体地,选取为单词字母个数的1.5倍(向下取整)。
[0078]
进一步地,在本技术实施例中,以遗传算法为基础,设计用于误唤醒率与不相似度两目标同时优化的求解算法,包括以下步骤:
[0079]
步骤s21:将唤醒词与由与唤醒词特征接近(不相似度小于∈)的特征重新组合得到的词其中f可以表示声母、韵母、音调(c)或音素(p),以及一部分初始化的词作为初始种群,其中,通过计算唤醒词的不相似度,选取不相似度小于预设值的特征重新组合得到与唤醒词接近的词;
[0080]
步骤s22:分别评估样本的误唤醒率和不相似度,其中,误唤醒率s(wi)定义为播放样本10次过程中,语音助手被误唤醒的比例,不相似度d(wi):=dis(wi,w0)计算方式如下所示:
[0081][0082][0083]
步骤s23:依照帕累托支配与拥挤度排序的方式选择一部分样本保留。一个样本wi被样本wj支配当且仅当s(wj)≥s(wi)且d(wj)≥d(wi),集合中所有未被支配的样本集合称为帕累托前沿。一个样本的拥挤度c(wi)可以由其周围样本的指标计算得到:
[0084]
c(wi)=2(s
a-sb d
a-db)
[0085]
其中,
[0086][0087][0088]
类似地,将上述指标换为不相似度,即可得到da,db;
[0089]
步骤s24:对保留样本集合进行变异操作,以得到下一代的样本集合,其中,变异操作包括:随机选择集合中的两个样本并随机交换一段特征,或将某个样本的某个特征随机更新为取值范围内的其他特征;
[0090]
步骤s25:重复步骤s22、步骤s23、步骤s24,直到达到算法最大迭代数,生成最终样本集合。
[0091]
进一步地,在本技术实施例中,依照帕累托支配与拥挤度排序的方式对样本进行选择,具体为:
[0092]
选择集合中的帕累托前沿作为被保留的样本,选择后在集合中删去被选择保留的样本,继续选择剩余样本的帕雷托前沿,若某次选择帕累托前沿的样本后,将使被选择的样本数超过了预设的保留样本数,则按照拥挤度对该次选择的样本进行降序排序,逐一保留样本直到选择的样本数达到预设的保留样本数。
[0093]
进一步地,在本技术实施例中,使用树莓派与语音助手连接,部署误唤醒词挖掘平台,通过运行求解算法来进行高效误唤醒词挖掘,生成误唤醒样本集,包括以下步骤:
[0094]
步骤s31:在电脑端运行求解算法,生成待测试的样本,通过扬声器向智能音箱播放生成的样本;
[0095]
步骤s32:通过光传感器与智能音箱连接,判断智能音箱的语音助手是否被激活,树莓派将激活结果返回电脑;
[0096]
步骤s33:在预设的算法迭代次数达到后,记录并保存测试过程中样本的不相似度与误唤醒率,保留具有一定误唤醒率的样本作为误唤醒样本集:
[0097][0098]
进一步地,在本技术实施例中,对误唤醒样本集进行正确样本标记后,对现有网络模型进行再训练,具体为:
[0099]
将误唤醒样本标记为负类后,在初次训练数据集中随机选取正样本,使得新的数据集中的正负样本比例与原有数据集的正负样本比例一致,
[0100]
采用交叉熵损失函数为目标训练唤醒词检测模型,其中,交叉熵损失函数表示为:
[0101][0102]
其中,yi表示样本是否为正类,pi表示样本被预测为正类的概率。
[0103]
本技术是为已训练的模型提供一个加固方法,这里的数据集为初次训练采用的数据集,通常为训练者已经收集了的,而非在本技术中生成得到。
[0104]
本技术唤醒模型加固的流程包括特征预处理、多目标优化算法设计、误唤醒词挖掘、误唤醒词再训练等步骤,其中,通过多目标遗传算法进行误唤醒词挖掘,对中英文音箱选取不同的特征、定义不同的不相似性度量,并且本技术模型加固方法是基于自动化的误唤醒词挖掘平台,通过反复迭代搜索误唤醒词进而重训练唤醒词检测模型以提升安全性。
[0105]
图2为本技术实施例的基于遗传算法的智能语音助手唤醒词识别模型加固方法的另一个流程图。
[0106]
如图2所示,该基于遗传算法的智能语音助手唤醒词识别模型加固方法,首先根据音箱类型,选定音素特征和特征取值范围;对于中文音箱,选取声母、韵母、音调作为音素特征,特征取值范围为汉语中使用的声母韵母以及四个声调;对于英文音箱,选取字母作为音素特征,特征取值范围为阿拉伯字母与占位符“/”;选取合适的特征数量并定义不同词语间的不相似度;将唤醒词、与唤醒词接近的词,以及随机生成的词作为初始种群;通过使用树莓派与语音助手连接,部署误唤醒词挖掘平台,分别评估样本的误唤醒率和不相似度,然后依照帕累托支配与拥挤度排序的方式对样本进行选择,得到保留样本,对保留样本集合进行变异操作,以得到下一代的样本集合,判断是否达到算法最大迭代数,若否,则重新对样本进行评估、选择和变异操作;若是,则生成误唤醒样本集;将误唤醒样本正确样本标记后,对现有网络模型进行再训练;判断模型误唤醒率是否足够低,若否,则重新进行运行遗传算法,反复加固唤醒词检测模型,直到挖掘误唤醒词数量在可接受范围内;若是,则结束。
[0107]
图3为本技术实施例的基于遗传算法的智能语音助手唤醒词识别模型加固方法的误唤醒词挖掘平台图。
[0108]
如图3所示,该基于遗传算法的智能语音助手唤醒词识别模型加固方法,利用树莓派与语音助手连接,部署误唤醒词挖掘平台,进行高效误唤醒词挖掘,具体为:电脑端运行误唤醒词挖掘算法,生成待测试的样本;通过扬声器向智能音箱播放待测试的样本;通过光传感器与智能音箱连接,判断智能音箱的语音助手是否被激活;树莓派将激活结果返回电脑。
[0109]
图4为本技术实施例的采用开源数据集训练模型加固前后误唤醒词挖掘效率图。
[0110]
如图4所示,横轴表示不同开源数据集中的唤醒词,纵轴表示运行误唤醒词挖掘算法后得到的误唤醒词比例,即误唤醒词占总测试样本的比例,在加固后均有显著的下降。
[0111]
图5为本技术实施例二所提供的一种基于遗传算法的智能语音助手唤醒词识别模型加固装置的结构示意图。
[0112]
如图5所示,该基于遗传算法的智能语音助手唤醒词识别模型加固装置,包括:特征预处理模块、算法设计模块、误唤醒词挖掘模块、训练模块、重复模块,其中,
[0113]
特征预处理模块10,用于根据音箱类型,选取音素特征和特征取值范围,之后根据音素特征和特征取值范围,选取合适的特征数量并定义不同词语间的不相似度;
[0114]
算法设计模块20,用于以遗传算法为基础,设计用于误唤醒率与不相似度两目标同时优化的求解算法;
[0115]
误唤醒词挖掘模块30,用于使用树莓派与语音助手连接,部署误唤醒词挖掘平台,通过运行求解算法来进行高效误唤醒词挖掘,生成误唤醒样本集;
[0116]
训练模块40,用于对误唤醒样本集进行正确样本标记后,对唤醒词检测模型进行训练;
[0117]
重复模块50,用于重复调用算法设计模块、误唤醒词挖掘模块、训练模块,反复加固唤醒词检测模型,直到挖掘误唤醒词数量在可接受范围内。
[0118]
本技术实施例的基于遗传算法的智能语音助手唤醒词识别模型加固装置,包括:特征预处理模块、算法设计模块、误唤醒词挖掘模块、训练模块、重复模块,其中,特征预处理模块,用于根据音箱类型,选取音素特征和特征取值范围,之后根据音素特征和特征取值范围,选取合适的特征数量并定义不同词语间的不相似度;算法设计模块,用于以遗传算法为基础,设计用于误唤醒率与不相似度两目标同时优化的求解算法;误唤醒词挖掘模块,用于使用树莓派与语音助手连接,部署误唤醒词挖掘平台,通过运行求解算法来进行高效误唤醒词挖掘,生成误唤醒样本集;训练模块,用于对误唤醒样本集进行正确样本标记后,对唤醒词检测模型进行训练;重复模块,用于重复调用算法设计模块、误唤醒词挖掘模块、训练模块,反复加固唤醒词检测模型,直到挖掘误唤醒词数量在可接受范围内。由此,能够解决现有语音助手误唤醒词挖掘难度大、误唤醒现象频繁难以优化的问题,提供了一种高效低成本的语音助手模型加固方法,实现了对语音助手的误唤醒词挖掘,并进一步对语音助手的误唤醒词检测模型进行了加固。
[0119]
本技术利用唤醒词的音素特征,定义不同单词间的不相似性度量,采用遗传算法,进行涵盖误唤醒率与不相似性的多目标优化问题求解,利用文字转语音系统(tts)进行快速的自动化搜索,以找到尽可能多位于帕累托前沿面的误唤醒词,将误唤醒词作为再训练的样本,用于加固原有的唤醒词识别模型,反复迭代以提升模型识别唤醒词的准确率。
[0120]
为了实现上述实施例,本技术还提出了一种非临时性计算机可读存储介质,其上
存储有计算机程序,计算机程序被处理器执行时实现上述实施例的基于遗传算法的智能语音助手唤醒词识别模型加固方法。
[0121]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本技术的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0122]
此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本技术的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
[0123]
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现定制逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本技术的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本技术的实施例所属技术领域的技术人员所理解。
[0124]
在流程图中表示或在此以其他方式描述的逻辑和/或步骤,例如,可以被认为是用于实现逻辑功能的可执行指令的定序列表,可以具体实现在任何计算机可读介质中,以供指令执行系统、装置或设备(如基于计算机的系统、包括处理器的系统或其他可以从指令执行系统、装置或设备取指令并执行指令的系统)使用,或结合这些指令执行系统、装置或设备而使用。就本说明书而言,"计算机可读介质"可以是任何可以包含、存储、通信、传播或传输程序以供指令执行系统、装置或设备或结合这些指令执行系统、装置或设备而使用的装置。计算机可读介质的更具体的示例(非穷尽性列表)包括以下:具有一个或多个布线的电连接部(电子装置),便携式计算机盘盒(磁装置),随机存取存储器(ram),只读存储器(rom),可擦除可编辑只读存储器(eprom或闪速存储器),光纤装置,以及便携式光盘只读存储器(cdrom)。另外,计算机可读介质甚至可以是可在其上打印所述程序的纸或其他合适的介质,因为可以例如通过对纸或其他介质进行光学扫描,接着进行编辑、解译或必要时以其他合适方式进行处理来以电子方式获得所述程序,然后将其存储在计算机存储器中。
[0125]
应当理解,本技术的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。如,如果用硬件来实现和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
[0126]
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
[0127]
此外,在本技术各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
[0128]
上述提到的存储介质可以是只读存储器,磁盘或光盘等。尽管上面已经示出和描述了本技术的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本技术的限制,本领域的普通技术人员在本技术的范围内可以对上述实施例进行变化、修改、替换和变型。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
