1.本发明属于生物识别技术领域,更具体的是涉及一种说话人分离方法、装置、电子设备及计算机可读介质。
背景技术:
2.随着音频处理技术的不断提高,从海量的数据中,如电话录音、新闻广播、会议录音等,获取感兴趣的特定人声已成为研究热点。说话人分离技术是指从多人对话中自动地将语音依据说话人进行划分,并加以标记的过程,即解决的是“什么时候由谁说”的问题。
3.目前,有一种基于变分贝叶斯方法的说话人分离方法,将传统说话人分离结果作为预分离输入,在此基础上通过隐马尔可夫模型对各帧特征进行建模,从而成功从非常短的语音片段中稳健地估计说话人模型。该方法可以有效缩短说话人建模单元大小,实现从非常短的语音片段中稳健地估计说话人模型,从而可以应用于如学习规划顾问(learning planning consultant,lpc)等简短对话问答系统中。但是由于原有的变分贝叶斯算法中输入帧特征为非静音帧的简单拼接,降采样过程可能将不在同一个语音分段的帧合并到1个状态,最终输出可能会出现说话人分离边界与切分边界不符的现象,影响分离效果。
技术实现要素:
4.(一)要解决的技术问题
5.本发明旨在解决原有的变分贝叶斯算法输入为非静音帧的简单拼接,影响分离效果的技术问题。
6.(二)技术方案
7.为解决上述技术问题,本发明的一方面提出一种说话人分离方法,所述方法包括如下步骤:
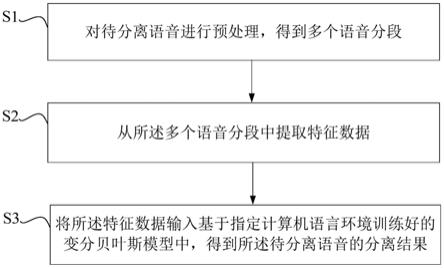
8.对待分离语音进行预处理,得到多个语音分段;
9.从所述多个语音分段中提取特征数据,所述特征数据包括:拼接特征矩阵,预分类结果,以及各个语音分段的结束帧数;
10.将所述特征数据输入基于指定计算机语言环境训练好的变分贝叶斯ivector模型中,所述变分贝叶斯模型根据拼接特征矩阵计算各个帧的统计量;根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系;将所述对应关系作用于各个帧的统计量和预分类结果中,得到各个状态的降采样结果;对各个状态的降采样结果进行前后迭代后,输出各个帧的语音标签,得到所述待分离语音的分离结果;其中,所述状态指预定个数个帧所在的时间片段中说话人的分布。
11.根据本发明一种优选的实施方式,所述根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系包括:
12.将第i帧分至状态i*segrange/seglen中,并根据各个帧与各个状态的对应关系生成关系矩阵;
13.其中:seglen为待分离语音包含的总帧数,segrange为各个语音分段包含的帧数除以预设每个状态包含的帧数取整。
14.根据本发明一种优选的实施方式,所述根据拼接特征矩阵计算各个帧的统计量包括:
15.计算各个帧各高斯分量的后验概率;
16.将各个帧各高斯分量的后验概率通过混合高斯模型向ivector空间投影矩阵进行投影,得到各个帧ivector分量的一阶统计量。
17.根据本发明一种优选的实施方式,所述根据拼接特征矩阵计算各个帧的统计量还包括:
18.将小于阈值的各个帧各高斯分量的后验概率置为0,得到稀疏化的各个帧各高斯分量的后验概率,并将稀疏化的各个帧各高斯分量的后验概率通过混合高斯模型向ivector空间投影矩阵进行投影,得到各个帧ivector分量的一阶统计量。
19.根据本发明一种优选的实施方式,所述对各个状态的降采样结果进行前后迭代后,输出各个帧的语音标签包括:
20.迭代更新各个状态的降采样结果并输出证据下界,直至证据下界收敛或达到最大迭代次数为止;
21.将各状态对应概率最大的说话人语音标签作为该状态中各个帧的语音标签,并返回各个帧的语音标签。
22.根据本发明一种优选的实施方式,所述对待分离语音进行预处理,得到多个语音分段包括:
23.对待分离语音进行预处理后,得到各语音分段内语音单元与起止时间的对应结果;
24.对应的,所述方法还包括:
25.查找语音单元对应起止时间内标记时间最长的语音标签,将该语音单元与所述语音标签对应作为说话人分离结果输出。
26.根据本发明一种优选的实施方式,所述将所述特征数据输入基于指定计算机语言环境训练好的变分贝叶斯ivector模型之前,所述方法还包括:
27.读取基于指定计算机语言环境训练好的ivector模型。
28.本发明第二方面提供一种说话人分离装置,包括:
29.预处理模块,用于对待分离语音进行预处理,得到多个语音分段;
30.提取模块,用于从所述多个语音分段中提取特征数据,所述特征数据包括:拼接特征矩阵,预分类结果,以及各个语音分段的结束帧数;
31.模型处理模块,用于将所述特征数据输入基于指定计算机语言环境训练好的变分贝叶斯ivector模型中,得到所述待分离语音的分离结果;
32.其中,所述变分贝叶斯模型包括:统计量计算模块,用于根据拼接特征矩阵计算各个帧的统计量;
33.降采样模块,用于根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系;将所述对应关系作用于各个帧的统计量和预分类结果中;所述状态指特定时间片段说话人的分布;
34.结果输出模块,用于对各个状态的降采样结果进行前后迭代后,输出各个帧的语音标签。
35.本发明第三方面提出一种电子设备,包括处理器和存储器,所述存储器用于存储计算机可执行程序,当所述计算机程序被所述处理器执行时,所述处理器执行如上述任一项所述的说话人分离方法。
36.本发明第四方面还提出一种计算机可读介质,存储有计算机可执行程序,所述计算机可执行程序被执行时,实现如上述任一项所述的说话人分离方法。
37.(三)有益效果
38.本发明从多个语音分段中提取各个语音分段的结束帧数,训练好的ivector模型能够根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系;将所述对应关系作用于各个帧的统计量和预分类结果中;其中,所述状态指特定时间片段说话人的分布;从而保证将各个语音分段的分界处设为状态分界线;避免将不在同一个语音分段的帧合并到1个状态,杜绝输出结果中出现说话人分离边界与切分边界不符的现象,提高了说话人分离的效果。
39.本发明将变分贝叶斯模型基于指定计算机语言环境(比如c )进行训练,使其能够满足实际质检任务应用的需要。
附图说明
40.图1是本发明实施例一种说话人分离方法的流程示意图;
41.图2a是本发明实施例中对语音分段进行划分的示意图;
42.图2b是对图2a中的子语音分段进行预分类的示意图;
43.图3为本发明实施例变分贝叶斯模型的流程示意图;
44.图4是本发明实施例一种说话人分离装置的结构示意图;
45.图5是本发明的一个实施例的电子设备的结构示意图;
46.图6是本发明的一个实施例的计算机可读记录介质的示意图。
具体实施方式
47.在对于具体实施例的介绍过程中,对结构、性能、效果或者其他特征的细节描述是为了使本领域的技术人员对实施例能够充分理解。但是,并不排除本领域技术人员可以在特定情况下,以不含有上述结构、性能、效果或者其他特征的技术方案来实施本发明。
48.附图中的流程图仅是一种示例性的流程演示,不代表本发明的方案中必须包括流程图中的所有的内容、操作和步骤,也不代表必须按照图中所显示的顺序执行。例如,流程图中有的操作/步骤可以分解,有的操作/步骤可以合并或部分合并,等等,在不脱离本发明的发明主旨的情况下,流程图中显示的执行顺序可以根据实际情况改变。
49.附图中的框图一般表示的是功能实体,并不一定必然与物理上独立的实体相对应。即,可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理单元装置和/或微控制器装置中实现这些功能实体。
50.各附图中相同的附图标记表示相同或类似的元件、组件或部分,因而下文中可能
省略了对相同或类似的元件、组件或部分的重复描述。还应理解,虽然本文中可能使用第一、第二、第三等表示编号的定语来描述各种器件、元件、组件或部分,但是这些器件、元件、组件或部分不应受这些定语的限制。也就是说,这些定语仅是用来将一者与另一者区分。例如,第一器件亦可称为第二器件,但不偏离本发明实质的技术方案。此外,术语和/或”、及/或”是指包括所列出项目中的任一个或多个的所有组合。
51.为解决背景技术中的技术问题,本发明提出一种说话人分离方法,该方法从多个语音分段中提取各个语音分段的结束帧数,训练好的ivector模型能够根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系;将所述对应关系作用于各个帧的统计量和预分类结果中;其中,所述状态指特定时间片段说话人的分布;从而保证将各个语音分段的分界处设为状态分界线;避免将不在同一个语音分段的帧合并到1个状态,杜绝输出结果中出现说话人分离边界与切分边界不符的现象,提高了说话人分离的效果。
52.在一种示例中,将第i帧分至状态i*segrange/seglen中,并根据各个帧与各个状态的对应关系生成关系矩阵;其中:seglen为待分离语音包含的总帧数,segrange为各个语音分段包含的帧数除以预设每个状态包含的帧数取整。
53.本发明将变分贝叶斯模型基于指定计算机语言环境(比如c )进行训练,使其能够满足实际质检任务应用的需要。对变分贝叶斯模型训练后,可以读取基于指定计算机语言环境训练好的变分贝叶斯ivector模型、对各高斯分量计算各特征向量空间到ivector子空间投影的三维矩阵、对角通用背景模型的均值、对角通用背景模型的方差、对角通用背景模型高斯分量权重。
54.在一种示例中,变分贝叶斯模型的ivector维数ivectordim=400,高斯分量数numgauss=1024,mel频率倒谱系数mfcc的特征维数featdim=23;所述三维矩阵的维数为(numgauss*(featdim*ivectordim));对角通用背景模型高斯分量权重的维数为numgauss,对角通用背景模型的均值和对角通用背景模型的方差的维数为numgauss*featdim。
55.为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
56.图1是本发明一种说话人分离方法的流程示意图,如图1所示,所述方法包括如下步骤:
57.s1、对待分离语音进行预处理,得到多个语音分段;
58.示例性的,对输入的单通道语音,可以通过语音活动检测(voice activity detection,vad)压缩掉静音后,再通过自动语音识别技术(automatic speech recognition,asr)将压缩掉静音的语音转码为文字,并输出文字的对齐结果。同时,根据文字的对齐结果进一步压缩掉转码对齐结果中静音时长大于预设时间(目前设定为0.3s)的语音,得到多个语音分段、各语音分段对应的语音文字、及各语音分段内语音单元与起止时间的对应结果,也称为语音分段的对齐结果。
59.进一步的,可以采用xvector说话人分离技术,对各个语音分段(记为s1,s2
…
)采用滑窗方法进一步划分为子语音分段;图2a为采用窗长1.5s,窗移0.75s将语音分段(也称分句)划分为多个子语音分段(也称子分句)的示意图,已备后续使用。
60.s2、从所述多个语音分段中提取特征数据;
61.其中,所述特征数据用于变分贝叶斯模型识别待分离语音的语音标签。示例性的,所述特征数据包括:拼接特征矩阵,预分类结果,以及各个语音分段的结束帧数;其中:
62.拼接特征矩阵:以固定帧长(比如10ms为帧长)提取各个语音分段s1,s2
……
中各帧的mfcc特征,各帧的mfcc特征的维数为m,则生成n*m的矩阵,其中,n为帧数,各个语音分段包含的帧数依次记为n1、n2
……
;各帧的mfcc特征记为x1,x2
……
,将各帧的mfcc特征的各列进行拼接,行数不变,得到拼接特征矩阵x;
63.各个语音分段的结束帧数q_segment为数组[0,n1,n1 n2
……
],首项为0,末项为各语音分段包含的帧数之和。
[0064]
预分类结果:基于预分类生成策略对每个语音分段sk中的子语音分段sk1,sk2
……
skn进行预分类。示例性的,可以配置预分类生成策略为:sk1前二分之一窗长内的帧分类至对应标记lk1;ski与sk(i 1)之间的前二分之一窗长重叠部分内的帧分至对应标记lki,ski与sk(i 1)之间的后二分之一窗长重叠部分内的帧分至对应标记lk(i 1),skn最后的非重叠部分对应标记lk(n 1)。
[0065]
由于图2a中采用窗长1.5s,窗移0.75s将语音分段划分为多个子语音分段,则通过上述预分类生成策略得到图2b的帧标记。
[0066]
s3、将所述特征数据输入基于指定计算机语言环境训练好的ivector模型中,得到所述待分离语音的分离结果;
[0067]
其中,指定计算机语言环境可以根据实际说话人分离结果的应用平台采用的计算机语言来定。比如:对于采用c 的语言质检平台,指定计算机语言环境为c 。
[0068]
示例性的,在本步骤之前,可以读取基于指定计算机语言环境训练好的ivector模型、用于对各高斯分量计算各特征向量空间到ivector子空间投影的三维矩阵v、对角通用背景模型的均值m、对角通用背景模型的方差ie、对角通用背景模型高斯分量权重w。
[0069]
在一种优选的模型参数中,变分贝叶斯模型的ivector维数ivectordim=400,高斯分量数numgauss=1024,mel频率倒谱系数mfcc的特征维数featdim=23;所述三维矩阵v的维数为(numgauss*(featdim*ivectordim));对角通用背景模型高斯分量权重w的维数为numgauss,对角通用背景模型的均值m和对角通用背景模型的方差ie的维数为numgauss*featdim。
[0070]
进一步,还可以设置模型的溢出概率、降采样率等等。
[0071]
本发明实施例中,所述变分贝叶斯模型根据拼接特征矩阵计算各个帧的统计量;根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系;将所述对应关系作用于各个帧的统计量和预分类结果中,得到各个状态的降采样结果;对各个状态的降采样结果进行前后迭代后,输出各个帧的语音标签,得到所述待分离语音的分离结果;其中,所述状态指预定个数个帧所在的时间片段中说话人的分布。
[0072]
示例性的,所述变分贝叶斯模型包括:
[0073]
统计量计算模块,用于根据拼接特征矩阵计算各个帧的统计量;
[0074]
降采样模块,用于根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系;将所述对应关系作用于各个帧的统计量和预分类结果中;所述状态指特定时间片段说话人的分布;
[0075]
结果输出模块,用于对各个状态的降采样结果进行前后迭代后,输出各个帧的语
音标签。
[0076]
在一种示例中,所述统计量计算模块包括:
[0077]
后验统计量计算模块,用于计算各个帧各高斯分量的后验概率ll;如图3,由于各帧拼接特征已经建模为对角通用背景模型的均值m、对角通用背景模型的方差ie-1的高斯分布分量之和,根据高斯分布公式,可计算各帧各混合高斯分量的后验概率,记为矩阵ll(numframes*numgauss);针对ll各帧行向量,求出其logsumexp值,各帧logsumexp值构成列向量g。
[0078]
稀疏化模块,用于将小于阈值的各个帧各高斯分量的后验概率置为0,得到稀疏化的各个帧各高斯分量的后验概率,并将稀疏化的各个帧各高斯分量的后验概率输入一阶统计量计算模块。如图3,经过实践检验,平均每帧1024个高斯分量中,只有约9-11个分量的后验概率超过0.001,可以认为ll是稀疏的,因此为简化计算,使计算效率和空间占用能够满足实际应用需要,配置阈值为0.001,将ll中小于0.001的分量置0,完成ll的稀疏化,从而提升计算效率,减小空间占用率。
[0079]
一阶统计量计算模块,用于将各个帧各高斯分量的后验概率通过混合高斯模型向ivector空间投影矩阵进行投影,得到各个帧ivector分量的一阶统计量。如图3,将稀疏化的各帧各高斯分量后验概率ll通过由合高斯模型向ivector空间投影矩阵v进行投影,得到各帧ivector分量的一阶统计量vtief。
[0080]
对数十分钟的长电话语音进行说话人分离时,录音可能长达数万至数十万帧,直接逐帧计算效率过低,需要降采样模块进行降采样优化。
[0081]
降采样的基础假设认为,有意义说话人音节长度至少为0.3s,因此可将20-25帧(对应0.2~0.25s)设为隐马尔可夫模型的状态,以状态为单元进行说话人状态建模。因此,可通过降采样的方法连接帧到状态的关系:生成降采样矩阵downsampler,分别作用于之前获得的统计量矩阵ll、vtief,以减小说话人分离时的计算量。
[0082]
在一种示例中,降采样模块设定每状态包含固定帧数downsample,降采样矩阵将[0,downsample-1],[downsample,2*downsample-1]
……
[downsample,m*downsample-1]简单求和或取平均,合并为状态0,状态1
……
状态m,其中,m为预设的状态个数。但由于输入帧特征x为拼接矩阵,不考虑x的拼接特性的话,降采样过程可能将不在同一个语音分段的帧合并到1个状态,这显然是不合理的,也会影响最终的分离效果。
[0083]
在另一种示例种,降采样模块指示出各个语音分段的分界处,将各个语音分段的分界处设为状态分界线,根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系;将所述对应关系作用于各个帧的统计量和预分类结果中;所述状态指特定时间片段说话人的分布;示例性的,在各个语音分段内部,所述降采样模块将第i帧分至状态i*segrange/seglen中,并根据各个帧与各个状态的对应关系生成关系矩阵;
[0084]
其中:seglen为待分离语音包含的总帧数,segrange为各个语音分段包含的帧数除以预设每个状态包含的帧数取整。
[0085]
进一步,可以将帧和状态的对应关系记为矩阵downsampler,分别作用于ll、vtief、g、预分类结果q等矩阵,得到各个状态的降采样结果。
[0086]
所述结果输出模块包括:
[0087]
迭代模块,用于迭代更新各个状态的降采样结果并输出证据下界,直至证据下界收敛或达到最大迭代次数为止;示例性的,可以根据各个帧各高斯分量的后验概率和各个帧ivector分量的一阶统计量对各个状态统计量进行前向、后向的更新,当各个状态统计量满足收敛条件时,迭代停止更新,将最终的各个状态统计量转化为各状态对应说话人的概率。
[0088]
如图3,若给定最大迭代次数maxiters,迭代更新各状态的降采样结果并输出证据下界elbo界,直至elbo界收敛或达到最大次数为止。在每次迭代中,出于马尔可夫推理的需要,应给出帧与帧之间的先验转移概率,且为保证算法能正确运行,先验跳转概率应大于0.,优选的,可以设定状态转移的先验概率为0.9保持原状态,0.1进行随机等概率的状态跳转。具体的,通过上一步计算得到的ll、vtief、g等统计量,获取各状态对说话人的初始统计量lls;随后进行forward-backward算法,根据各帧说话人的初始统计量进行推理,根据先验状态概率进行前向、后向的状态更新;最后将各状态获得的说话人统计量转化为各状态说话人概率,同时输出elbo统计量,当统计量达到收敛(比如统计量差小于0.01)时,迭代停止。
[0089]
子返回模块,用于将各状态对应概率最大的说话人语音标签作为该状态中各个帧的语音标签,并返回各个帧的语音标签。示例性的,如图3,获取各状态说话人概率最大值所在的index作为该状态说话人的语音标签;将标签向量通过downsampler的转置矩阵,恢复为各帧说话人的语音标签,返回为说话人分离结果。其中,index为矩阵中该行向量最大元素所在的索引值。
[0090]
进一步的,所述方法还包括:
[0091]
查找语音单元对应起止时间内标记时间最长的语音标签,将该语音单元与所述语音标签对应作为说话人分离结果输出。其中,语音单元是说话的最小单元,比如可以是词语。比如:0~3s内时间最长的语音标签为说话人a,0~1s内对应语音单元“你好”,1~3s内对应语音单元“我是xxx”,则说话人分离结果为:说话人a说:你好,我是xxx。
[0092]
图4是本发明提供的一种说话人分离装置,如图4所示,所述装置包括:
[0093]
预处理模块41,用于对待分离语音进行预处理,得到多个语音分段;
[0094]
提取模块42,用于从所述多个语音分段中提取特征数据,所述特征数据包括:拼接特征矩阵,预分类结果,以及各个语音分段的结束帧数;
[0095]
模型处理模块43,用于将所述特征数据输入基于指定计算机语言环境训练好的ivector模型中,得到所述待分离语音的分离结果;
[0096]
其中,所述变分贝叶斯模型包括:统计量计算模块,用于根据拼接特征矩阵计算各个帧的统计量;
[0097]
降采样模块,用于根据各个语音分段的结束帧数将各个帧分至对应的状态,得到各个帧与各个状态的对应关系;将所述对应关系作用于各个帧的统计量和预分类结果中;所述状态指特定时间片段说话人的分布;
[0098]
结果输出模块,用于对各个状态的降采样结果进行前后迭代后,输出各个帧的语音标签。
[0099]
本领域技术人员可以理解,上述装置实施例中的各模块可以按照描述分布于装置中,也可以进行相应变化,分布于不同于上述实施例的一个或多个装置中。上述实施例的模
块可以合并为一个模块,也可以进一步拆分成多个子模块。
[0100]
图5是本发明的一个实施例的电子设备的结构示意图,该电子设备包括处理器和存储器,所述存储器用于存储计算机可执行程序,当所述计算机程序被所述处理器执行时,所述处理器执行说话人分离方法。
[0101]
如图5所示,电子设备以通用计算设备的形式表现。其中处理器可以是一个,也可以是多个并且协同工作。本发明也不排除进行分布式处理,即处理器可以分散在不同的实体设备中。本发明的电子设备并不限于单一实体,也可以是多个实体设备的总和。
[0102]
所述存储器存储有计算机可执行程序,通常是机器可读的代码。所述计算机可读程序可以被所述处理器执行,以使得电子设备能够执行本发明的方法,或者方法中的至少部分步骤。
[0103]
所述存储器包括易失性存储器,例如随机存取存储单元(ram)和/或高速缓存存储单元,还可以是非易失性存储器,如只读存储单元(rom)。
[0104]
可选的,该实施例中,电子设备还包括有i/o接口,其用于电子设备与外部的设备进行数据交换。i/o接口可以为表示几类总线结构中的一种或多种,包括存储单元总线或者存储单元控制器、外围总线、图形加速端口、处理单元或者使用多种总线结构中的任意总线结构的局域总线。
[0105]
应当理解,图5显示的电子设备仅仅是本发明的一个示例,本发明的电子设备中还可以包括上述示例中未示出的元件或组件。例如,有些电子设备中还包括有显示屏等显示单元,有些电子设备还包括人机交互元件,例如按扭、键盘等。只要该电子设备能够执行存储器中的计算机可读程序以实现本发明方法或方法的至少部分步骤,均可认为是本发明所涵盖的电子设备。
[0106]
图6是本发明的一个实施例的计算机可读记录介质的示意图。如图6所示,计算机可读记录介质中存储有计算机可执行程序,所述计算机可执行程序被执行时,实现本发明上述的说话人分离方法。所述计算机可读存储介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读存储介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。可读存储介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、rf等等,或者上述的任意合适的组合。
[0107]
可以以一种或多种程序设计语言的任意组合来编写用于执行本发明操作的程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如java、c 等,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(lan)或广域网(wan),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
[0108]
通过以上对实施方式的描述,本领域的技术人员易于理解,本发明可以由能够执行特定计算机程序的硬件来实现,例如本发明的系统,以及系统中包含的电子处理单元、服
务器、客户端、手机、控制单元、处理器等,本发明也可以由包含上述系统或部件的至少一部分的车辆来实现。本发明也可以由执行本发明的方法的计算机软件来实现,例如由直播设备的微处理器、电子控制单元,客户端、服务器端等执行的控制软件来实现。但需要说明的是,执行本发明的方法的计算机软件并不限于由一个或特定个的硬件实体中执行,其也可以是由不特定具体硬件的以分布式的方式来实现,对于计算机软件,软件产品可以存储在一个计算机可读的存储介质(可以是cd-rom,u盘,移动硬盘等)中,也可以分布式存储于网络上,只要其能使得电子设备执行根据本发明的方法。
[0109]
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,应理解的是,本发明不与任何特定计算机、虚拟装置或者电子设备固有相关,各种通用装置也可以实现本发明。以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。