1.本公开属于变压器技术领域,尤其涉及一种基于参数优化的随机森林油中气体浓度预测方法及系统。
背景技术:
2.变压器作为电网运行中的关键设备,其油中溶解气体浓度预测一直是研究热点问题;随机森林算法作为一种泛化能力很强的集中机器学习算法,算法性能与算法参数选择有密切影响;目前存在较多的利用随机森林算法解决变压器油中溶解气体浓度预测方法。
3.本公开发明人发现,现有的随机森林变压器油中溶解气体浓度预测方法中,忽略了参数取值问题,影响了预测结果,现有方法的实用性和鲁棒性较差。
技术实现要素:
4.本公开为了解决上述问题,提出了基于参数优化的随机森林油中气体浓度预测方法及系统,本公开对随机森立算法的五个关键参数进行优化,将优化后的参数值带入随机森林算法中,并对变压器的油中溶解气体进行浓度预测,获得理想仿真结果,证明了改进的随机森林算法具有更好的适用性和可行性。
5.为了实现上述目的,本发明是通过如下的技术方案来实现:
6.第一方面,本公开提供了一种基于参数优化的随机森林油中气体浓度预测方法,包括:
7.获取变压器的油色谱数据;
8.依据油色谱数据和预设的油中气体浓度预测模型,得到油中气体浓度;
9.其中,所述油中气体浓度预测模型通过随机森林算法训练得到;进行油中气体浓度预测时,先将随机森林中决策树数目、决策树最大深度、节点可分最小样本数、叶子节点的最小样本数和最大叶子节点数进行参数优化,然后将优化后的参数值带入随机森林算法中,并对变压器的油中溶解气体进行浓度预测。
10.进一步的,参数优化过程为:
11.对所有需要优化的参数进行遗传编码,并生成初始种群;
12.将初始种群中每个个体的参数带入随机森林算法,进行回归分析,得到预测结果;
13.采用可决系数作为适应度:可决系数越接近1,表示模型准确度越高;
14.判断遗传算法的终止条件是否满足,如果满足则结束计算,否则,重新生成足量个体形成种群;
15.重复上述过程。
16.进一步的,所述可决系数r2为:
17.其中,yi为真实值,f(xi)为预测值,为真实值均值。
18.进一步的,评估每个个体的适应度,根据适应度进行选择、交叉、变异和克隆操作,
然后判断终止条件。
19.进一步的,随机森林算法中决策树的生成过程为:将输入空间递归地划分为二叉树,每个节点只向下分裂成两个区域,生成回归决策树。
20.进一步的,随机森林算法抽取数据采用无权重抽样,根据事先设定的决策树数量,对训练集数据进行多次有放回抽样,每次抽样产生相应的决策树。
21.进一步的,进行油中气体浓度预测模型训练时,将数据集分为训练集和测试集。
22.第二方面,本公开还提供了一种基于参数优化的随机森林油中气体浓度预测系统,包括数据采集模块和浓度预测模块;
23.所述数据采集模块,被配置为:获取变压器的油色谱数据;
24.所述浓度预测模块,被配置为:依据油色谱数据和预设的油中气体浓度预测模型,得到油中气体浓度;
25.其中,所述油中气体浓度预测模型通过随机森林算法训练得到;进行油中气体浓度预测时,先将随机森林中决策树数目、决策树最大深度、节点可分最小样本数、叶子节点的最小样本数和最大叶子节点数进行参数优化,然后将优化后的参数值带入随机森林算法中,并对变压器的油中溶解气体进行浓度预测。
26.第三方面,本公开还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现了第一方面所述的基于参数优化的随机森林油中气体浓度预测方法的步骤。
27.第四方面,本公开还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现了第一方面所述的基于参数优化的随机森林油中气体浓度预测方法的步骤。
28.与现有技术相比,本公开的有益效果为:
29.1.本公开对随机森立算法的五个关键参数进行优化,将优化后的参数值带入随机森林算法中,并对变压器的油中溶解气体进行浓度预测,获得理想仿真结果,证明了改进的随机森林算法具有更好的适用性和可行性;
30.2.本公开中,仿真结果表明改进随机森林算法预测包括乙炔在内的九种气体浓度时,无论是平均相对误差,还是最大相对误差,数值都低于传统随机森林算法相应的预测结果,证明了算法的实用性和鲁棒性。
附图说明
31.构成本实施例的一部分的说明书附图用来提供对本实施例的进一步理解,本实施例的示意性实施例及其说明用于解释本实施例,并不构成对本实施例的不当限定。
32.图1为本公开实施例1的随机森林算法原理图;
33.图2为本公开实施例1的带参数优化的随机森林算法原理图;
34.图3为本公开实施例1的遗传算法原理图;
35.图4为本公开实施例1的决策树数量对乙炔气体浓度预测;
36.图5为本公开实施例1的决策树最大深度对乙炔气体浓度预测的影响;
37.图6为本公开实施例1的叶子节点最小样本数对乙炔气体浓度预测的影响;
38.图7为本公开实施例1的节点最小可分样本数对乙炔气体浓度预测的影响;
39.图8为本公开实施例1的最大叶子节点数对乙炔气体浓度预测的影响;
40.图9为本公开实施例1的乙炔的预测结果;
41.图10为本公开实施例1的甲烷的预测结果;
42.图11为本公开实施例1的氧气的预测结果。
具体实施方式:
43.下面结合附图与实施例对本公开作进一步说明。
44.应该指出,以下详细说明都是例示性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
45.实施例1:
46.本实施例提供了一种基于参数优化的随机森林油中气体浓度预测方法,包括:
47.获取变压器的油色谱数据;
48.依据油色谱数据和预设的油中气体浓度预测模型,得到油中气体浓度;
49.其中,所述油中气体浓度预测模型通过随机森林算法训练得到;进行油中气体浓度预测时,先将随机森林中决策树数目、决策树最大深度、节点可分最小样本数、叶子节点的最小样本数和最大叶子节点数进行参数优化,然后将优化后的参数值带入随机森林算法中,并对变压器的油中溶解气体进行浓度预测。
50.在本实施例中,如图1所示,随机森林算法流程主要包括三个步骤:对训练数据集进行随机抽取获得训练子集、随机选取特征子集形成决策树和并行训练每个决策树获得对应结果。
51.设x是一个包含m个特征的输入向量,y是输出值,sn是一个包含n个观测值(xi,yi)的训练集,其中:
52.sn={(x1,y2),...,(xn,yn)},x∈rm,y∈r
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
53.决策树的生成采用分类和回归树cart(classification and regression tree)算法,该算法将输入空间x递归地划分为二叉树,根据最小损失函数,每个节点只向下分裂成两个区域,最终基于最小二乘偏差,生成回归决策树。
54.最小损失函数为:
55.f=min[∑(y
i-c1)2 ∑(y
i-c2)2]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0056]
其中c1和c2表示两个区域r1和r2的平均值。
[0057]
随机森林算法抽取数据采用的是有放回抽样中的无权重抽样,根据事先设定的决策树数量n,对训练集数据进行n次有放回抽样,每次抽样产生相应的决策树,由于是随机采样,每棵决策树的训练数据不同,决策树之间也就存在着差异,通过这种方式可以有效克服单棵决策树产生的过拟合问题。
[0058]
随机森林算法的参数取值将直接影响到算法的预测准确性;对随机森林算法的重要参数进行寻优,获得最优参数组合有利于提升模型的预测准确率。影响随机森林算法性能的参数有17个,本实施例中考虑了影响最大的5个参数;具体的为:
[0059]
决策树数目:就是决策树的棵数,取值对随机森林算法的性能影响较大,如果取值过小会导致模型欠拟合,模型预测效果差;随着其取值的增大算法的精度也会提升,但随之
而来的就是计算时间过久、效率过低的问题,取值过高甚至会导致模型过拟合;
[0060]
决策树最大深度,与数据量和数据特征关系密切,在数据量大、特征较多时,必须考虑决策树最大深度的取值;
[0061]
节点可分最小样本数,是决策树生成中的关键参数;
[0062]
叶子节点的最小样本数,当节点样本数少于节点可分最小样本数,那么决策树停止划分;
[0063]
最大叶子节点数,是决策树生成中的关键参数。
[0064]
本实施例中,带参数优化的随机森林算法流程如图2所示;具体流程为:
[0065]
(1)对上述5个参数进行遗传编码,并生成初始种群;
[0066]
(2)将种群中每个个体的参数带入随机森林算法,进行回归分析,得到预测结果;
[0067]
(3)采用可决系数r2作为适应度:
[0068][0069]
其中,yi为真实值,f(xi)为预测值,为真实值均值。可决系数越接近1,表示模型准确度越高。
[0070]
(4)判断遗传算法的终止条件是否满足,如果满足则结束计算,当前最好随机森林预测结果就是最后结果,否则就通过选择、交叉、变异和克隆重新生成足量个体形成种群。
[0071]
(5)重复(2)、(3)和(4)步骤。
[0072]
遗传算法是模拟达尔文自然选择进化和遗传学生物进化过程的最优搜索方法;和传统优化方法相比,遗传算法从问题解的串集开始搜索,搜索范围广,不易陷入局部最优。
[0073]
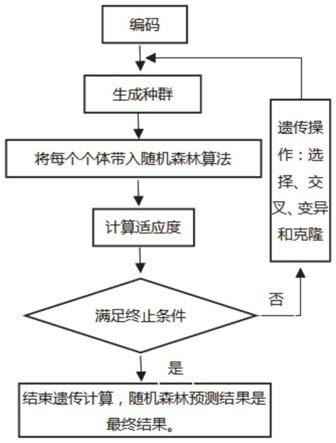
在本实施例中,如图3所示,遗传算法工作过程是设置m个个体形成初始种群,评估每个个体的适应度,根据适应度进行选择、交叉、变异和克隆操作,生成p 1代个体m个,然后判断终止条件,如果条件满足,最大适应度个体就是最优输出,否则继续遗传操作。
[0074]
为了验证本实施例的可行性,下面通过具体项目进行验证:
[0075]
本实施例中,以某电网某220kv变压器从2020年4月18日到2021年6月8日油色谱数据为例,观测周期为24小时,共415组数据,去掉无效数据后剩余410组数据;将360组数据(2020.4.18-2021.4.18)作为训练集,其余50组数据(2021.4.19-2021.6.8)作为测试集。
[0076]
利用matlab软件,分别对乙炔、甲烷和氧气等多种气体进行预测分析。
[0077]
如图4、图5、图6、图7和图8所示,以随机森林中五个参数(决策树的数目、决策树最大深度、节点可分最小样本数、叶子节点的最小样本数和最大叶子节点数)为例,验证不同参数对乙炔气体浓度预测的影响。
[0078]
其中,决策树的数目默认值100、决策树最大深度默认值2、节点可分最小样本数默认值10、叶子节点的最小样本数默认值5和最大叶子节点数默认值5。
[0079]
由表1可知,五个关键参数不同取值对气体浓度影响明显,因此需要取值进行遗传算法优化。
[0080]
表1五个参数不同取值平均误差表
[0081][0082]
在本实施中,进行遗传编码时,待优化参数取值范围都为1-500,因此采用9位二进制对一个参数编码,因为有5个待优化参数,所以采用45位二进制码对五个参数进行编码。随机生成100个初始个体形成种群。终止条件是迭代次数小于105次。遗传操作中采用轮盘赌方式进行选择,交叉概率0.7,变异概率0.01,克隆概率0.02。
[0083]
为满足可决系数最大的条件,取决策树数目为200,最大树深3,节点可分最小样本数取20,叶子节点最小样本数取10,最大叶子节点数取10。
[0084]
在上述工作的基础上,利用遗传算法得到的最优化参数,以及选定的电网原始数据,进行随机森立算法仿真;随机森林算法采用bootstrap方式进行有放回采样形成200个决策树训练集;最后将200个决策树预测结果取均值作为最终结果。
[0085]
对乙炔预测情况如图9所示,未进行参数优化的随机森林算法平均误差是3.24%,进行了参数优化的随机森林算法平均误差2.66%;
[0086]
对甲烷预测情况如图10所示,未进行参数优化的随机森林算法平均误差是3.27%,进行了参数优化的随机森林算法平均误差2.92%;
[0087]
对氧气预测情况如图11所示,未进行参数优化的随机森林算法平均误差是3.61%,进行了参数优化的随机森林算法平均误差2.38%。
[0088]
在上述的基础上,采用相同的参数优化方法进行参数优化并分别采用随机森林算法进行浓度预测,其它气体预测结果如表2所示。
[0089]
由表2可知,本实施例中,采用带遗传算法参数优化的随机森林算法比传统随机森林算法具有更低的平均相对误差和最大相对误差,说明本实施例中的方法具有更好的预测稳定性和可靠性。
[0090]
表2其它油中溶解气体预测结果
[0091][0092]
本实施例中,在对随机森林算法参数分析的基础上,确定5个关键参数并利用遗传算法对参数进行优化。然后以某电网220kv变压器油中溶解气体数据为研究对象,利用随机森林算法进行360组数据的训练,最后对50组数据进行预测;仿真结果表明本实施例中提出的改进随机森林算法预测包括乙炔在内的九种气体浓度时,无论是平均相对误差,还是最大相对误差,数值都低于传统随机森林算法相应的预测结果,证明了算法的实用性和鲁棒性。
[0093]
实施例2:
[0094]
本实施例提供了一种基于参数优化的随机森林油中气体浓度预测系统,包括数据采集模块和浓度预测模块;
[0095]
所述数据采集模块,被配置为:获取变压器的油色谱数据;
[0096]
所述浓度预测模块,被配置为:依据油色谱数据和预设的油中气体浓度预测模型,得到油中气体浓度;
[0097]
其中,所述油中气体浓度预测模型通过随机森林算法训练得到;进行油中气体浓度预测时,先将随机森林中决策树数目、决策树最大深度、节点可分最小样本数、叶子节点的最小样本数和最大叶子节点数进行参数优化,然后将优化后的参数值带入随机森林算法中,并对变压器的油中溶解气体进行浓度预测。
[0098]
实施例3:
[0099]
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现了实施例1所述的基于参数优化的随机森林油中气体浓度预测方法的步骤。
[0100]
实施例4:
[0101]
本实施例提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现了实施例1所述的基于参数优化的随机森林油中气体浓度预测方法的步骤。
[0102]
以上所述仅为本实施例的优选实施例而已,并不用于限制本实施例,对于本领域的技术人员来说,本实施例可以有各种更改和变化。凡在本实施例的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本实施例的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。