基于gpu集群的相对论性波尔兹曼方程计算方法、存储介质及设备
技术领域
1.本发明属于相对论性波尔兹曼方程求解处理方法,具体涉及一种基于大型gpu集群的相对论性波尔兹曼方程计算方法、计算机可读存储介质及设备。
背景技术:
2.相对论性玻尔兹曼方程作为动理学理论的基本方程,在描述非平衡态输运过程中有着十分广泛的应用,相对论性玻尔兹曼方程的基本表达形式如下:
[0003][0004]
其中,fa(x,p,t)为a类型粒子的分布函数,p为粒子的动量,e为粒子的能量,ca为碰撞项,碰撞项的表达式为:
[0005][0006]
上式中为散射矩阵元,可以由量子理论计算得出。
[0007]
由于较高的维度和复杂的碰撞项积分,长期以来,完整地求解非相对论性玻尔兹曼方程一直都是极具挑战的工作。即使目前,人们可以利用千兆级的计算集群,非相对论性玻尔兹曼方程的求解依然十分困难。
[0008]
在非相对论玻尔兹曼方程的实际应用中,通常需要非常密集的时空网格来描述与压力、温度、湍流等相关的复杂效应。相对论和非相对论玻尔兹曼方程之间的主要区别在于碰撞项和耦合方程。在相对论玻尔兹曼方程中,碰撞积分通常比非相对论情况下复杂得多。同时,对于相对论性碰撞方程,散射矩阵也更加复杂,而在非相对论的情况下,通常只涉及一种粒子,例如气体或液体。除了碰撞项带来的困难,相对论玻尔兹曼方程往往包含多个耦合方程,也增加了计算的复杂度。因此,完全求解相对论性玻尔兹曼方程在当前的科学技术水平下依然十分困难。
[0009]
目前,prd-be(physical review d-boltzmann equation)是首个运行在gpu上的全碰撞项波尔兹曼方程求解程序,相较于传统的粒子模拟方法,能够利用微观理论计算的相互作用散射矩阵元,而无需借助实验参数。在prd-be中,gpu显卡的并行主要通过将碰撞积分的采样点进行分割,并分配至多块gpu显卡上进行积分运算,能够正确并快速求解波尔兹曼方程。但是,当系统涉及到超大规模gpu显卡集群时,上述并行方案在计算效率上会有大幅度的降低。具体而言,假设碰撞积分需要400个采样点,prd-be中对碰撞项的400个蒙特卡洛采样点进行分割,交由不同的gpu卡进行计算,计算结束后再收回至主节点,这种方法需要在gpu卡之间进行大量的数据交换,因而制约了其并行效率。
技术实现要素:
[0010]
本发明为解决目前通过prd-be求解波尔兹曼方程,当系统涉及到超大规模gpu显卡集群时,计算效率会有大幅度降低的技术问题,提供一种基于大型gpu集群的相对论性波尔兹曼方程计算方法、计算机可读存储介质及设备。
[0011]
为达到上述目的,本发明采用以下技术方案予以实现:
[0012]
一种基于gpu集群的相对论性波尔兹曼方程计算方法,其特殊之处在于,包括以下步骤:
[0013]
s1,由gpu集群中主节点划定分布函数所在的相空间范围,并将分布函数所在的相空间在直角坐标系中划分为多个网格;
[0014]
s2,根据gpu集群中分节点的数量,对经步骤s1划分的多个网格拆分为多个坐标空间;其中,多个所述坐标空间之间有交叠部分;
[0015]
s3,将多个坐标空间分别分配至各分节点,在每个分节点上通过中心差分的形式对相对论性波尔兹曼方程的左侧进行更新,并对碰撞积分采用蒙卡方式进行计算;
[0016]
s4,将每个分节点中坐标空间与其他分节点中坐标空间交叠部分的分布函数回收至主节点,对各交叠部分中的错误数值进行替换,再将替换过错误数值后的交叠部分重新分配至原分节点中;
[0017]
s5,随时间更新分布函数的信息。
[0018]
进一步地,步骤s3中,所述将多个坐标空间分别分配至各分节点具体为,将多个坐标空间分别用python库ray分配至各分节点。
[0019]
进一步地,步骤s3中,所述通过中心差分的形式对相对论性波尔兹曼方程的左侧进行更新具体为,利用python库numba通过中心差分的形式对相对论性波尔兹曼方程的左侧进行更新,并将更新过程中的全部信息存储在相应节点显卡的全局内存中;
[0020]
所述对碰撞积分采用蒙卡方式进行计算具体为,对碰撞积分在cuda核上采用蒙卡方式进行计算,并将计算过程中的全部信息存储在相应节点显卡的局域显存中。
[0021]
进一步地,步骤s4中,所述沿时间更新分布函数的信息具体为,利用时间的一阶差分更新分布函数的信息。
[0022]
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,其特殊之处在于,所述计算机程序被处理器执行时实现如上所述方法的步骤。
[0023]
另外,本发明还提供了一种控制设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特殊之处在于,所述处理器执行所述计算机程序时实现上所述方法的步骤。
[0024]
与现有技术相比,本发明具有以下有益效果:
[0025]
1.基于大型gpu集群的相对论性波尔兹曼方程计算方法,在prd-be的基础上,给出了在大型gpu集群上求解相对论性全碰撞项玻尔兹曼方程的数值框架。本发明的计算方法通过将坐标空间进行分割,能够在多gpu设备上进行玻尔兹曼方程的求解,相较于现有的prd-be,能够更好地适配多gpu集群,具备跨节点的并行能力。
[0026]
2.物理引擎是仿真计算竞争的核心领域,本发明的计算方法作为连接宏观与微观的非平衡态输运算法,通过大规模并行,能够为未来物理引擎发展提供技术支撑。
[0027]
3.本发明的计算机可读存储介质,可将上述计算方法作为程序进行存储,计算机
程序被处理器执行时能够实现上述计算方法,最终达到对玻尔兹曼方程进行求解的目的。
[0028]
4.本发明的控制设备,可将上述计算方法作为程序进行存储,处理器可执行该程序实现对玻尔兹曼方程的求解。
附图说明
[0029]
图1为现有的prd-be的算法流程示意图;
[0030]
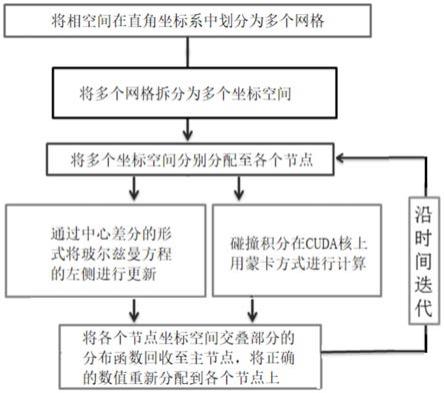
图2为本发明基于大型gpu集群的相对论性波尔兹曼方程计算方法流程示意图。
具体实施方式
[0031]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
[0032]
本专利所涉及计算方法基于《towards a full solution of the relativistic boltzmann equationfor quark-gluon matter on gpus》中提出的方法,以下简称prd-be。prd-be是首个运行在gpu上的全碰撞项玻尔兹曼方程求解程序。prd-be能够从第一性原理的角度直接利用由量子理论计算的散射矩阵元,给出非平衡态物质的演化。相较于传统的粒子模拟方法,直接求解玻尔兹曼方程,能够利用微观理论计算的相互作用散射矩阵元,而无需借助实验参数。在prd-be中,gpu显卡的并行主要通过将碰撞积分的采样点进行分割,并分配至多块gpu显卡上进行积分运算,具体算法如图1所示,生成六维相空间直角坐标系网格,再用ray(控制节点间通讯)将碰撞积分的采样点进行分割,并分发至多块显卡中,在每个节点中,用numba在cuda核之间(全局显存)进行中心差分(玻尔兹曼方程左侧和麦克斯韦方程),同时,在每个cuda核之内用numba(局域显存)进行蒙卡积分(碰撞项),然后,回收不同显卡上的积分采样点,沿时间迭代,重复用ray(控制节点间通讯)将碰撞积分的采样点进行分割,并执行后续处理步骤。
[0033]
针对prd-be的并行效率问题,本发明计算方法提出了基于坐标空间的并行方案,通过该方案,减少了显卡之间数据交换的数量。
[0034]
本发明给出了rbg框架数值求解玻尔兹曼方程的技术路线,基于prd-be的思路,进行了扩展和优化。gpu有很高的时钟频率(clock frequency)和每周期指令数目(instruction per cycle),与此同时,同一节点的显卡内核之间也有很高的通讯速度,因此,gpu在求解包含碰撞项(积分形式)的六维相空间玻尔兹曼-麦克斯韦耦合方程方面有着cpu集群不可比拟的优势。
[0035]
如图2所示,为本发明基于大型gpu集群的相对论性波尔兹曼方程计算方法具体步骤,主要包含五个过程:(1)首先由gpu集群中主节点划定分布函数所在的相空间范围,并将相空间在直角坐标系中划分为多个网格。(2)根据具体的节点数目,将坐标空间的网格进行拆分(网格有交叠部分),拆分为多个坐标空间。(3)用python库ray将多个坐标空间分别分配至各个分节点,在每个分节点上,利用python库numba通过中心差分的形式将玻尔兹曼方程的左侧进行更新(更新过程中的所有信息存储在显卡的全局内存中),碰撞积分则直接在cuda核上用蒙卡方式进行计算(计算过程中的所有信息存储在显卡的局域显存中)。(4)将
各个分节点坐标空间交叠部分的分布函数回收至主节点,并根据交叠区域的具体形式将正确的数值重新分配到各个分节点上。(5)重复执行(3)和(4),利用时间的一阶差分更新分布函数的信息。
[0036]
由于坐标空间的跨节点网格是彼此交叠的,可以保证边界处的分布函数始终能够获得正确的更新。目前,一块nvidia a100卡有大约7000个核,如果相空间网格的尺度选为306,那么在一块显卡上完成一个步长的计算大约需要1-3秒(根据prd-be的经验)。通常情况下,非平衡系统的演化大约需要10000步,因此,一块a100卡上进行完整的演化需要约8小时。因此,通过在多块卡上进行并行,实际的计算时间会更短。
[0037]
本发明的计算方法可在计算机可读存储介质中应用,计算机可读存储介质存储有计算机程序,上述计算方法可作为计算机程序存储于计算机可读存储介质中,计算机程序被处理器执行时实现上述计算方法的各步骤。
[0038]
另外,本发明的计算方法还可以应用于终端设备,终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,处理器执行所述计算机程序时实现本发明计算方法的步骤。此处的终端设备可以是计算机、笔记本、掌上电脑,及各种云端服务器等计算设备,处理器可以是通用处理器、数字信号处理器、专用集成电路或其他可编程逻辑器件等。
[0039]
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。
