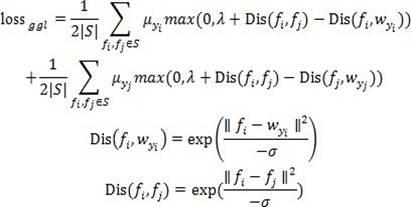
1.本文发明设计图像识别领域,具体地说,本发明设计一种基于特征缩放和边界样本的不平衡图像分类系统。
背景技术:
2.随着深度学习的不断发展,图像分类取得了巨大的进步。然而,在现实世界中,不平衡问题非常普遍,例如癌症诊断和异常检测。现有的不平衡问题大致可以分为两类:长尾不平衡和阶跃不平衡。一般来说,正确预测少数样本的好处远高于错误分类多数样本的好处。然而,现有的算法大多适用于均衡数据,当应用于非均衡数据时,算法会偏向于多数类。
3.人们提出了各种方法来解决不平衡问题。重采样和代价敏感学习是解决不平衡问题的常用方法,这些方法也可以与深度学习相结合来处理不平衡图像。重采样,它通过过采样或下采样来重新平衡每个类的数量。过采样是通过在少数类中重复一些样本来扩展少数类,而下采样是删减大多数类的一部分样本。另一种称为代价敏感学习的方法也用于处理不平衡问题。这种策略为错误分类的少数样本分配了更高的惩罚,这使得模型更加关注少数样本。
4.在过去的几十年中,不平衡学习方法得到了广泛的发展。一种常见的方法是重采样,它通过过采样或下采样来重新平衡每个类的数量。过采样是通过在少数类中重复一些样本来扩展少数类,而下采样是删减一部分多数类的样本。然而,由于重复数据的存在,过采样容易导致过拟合,而下采样会删减一些有价值的信息,从而导致欠拟合。另一种称为代价敏感学习的方法也用于处理不平衡问题。这种策略为错误分类的少数样本分配了更高的惩罚,这使得模型更加关注少数样本。但代价矩阵需要根据经验来确定。在算法改进方面,集成学习是一种典型的方法,它结合了几个简单的分类器来提高整体性能。虽然集成学习在各个领域已经被证明是有效的,但是很多集成学习在多类分类和图像识别方面都有局限性。
5.本发明从模型结构出发,利用样本之间的几何信息来解决不平衡图像分类问题。虽然深度学习在大多数情况下都能对图像进行高性能分类,但它们没有考虑数据的不平衡性,大部分网络模型都是针对平衡数据集,因此此类模型在不平衡图像数据集上表现不佳。为了解决这个问题,我们引入了特征缩放模块和基于gabriel图的边界样本挖掘模块。特征缩放模块基于不同类别的超球半径的比值,对特征进行缩放,从而促进模型对少数类的训练。同时,基于gabriel图的边界样本挖掘模块,在构建的gabriel图的基础上,约束类内类间距离,从而提升模型的表征能力。
技术实现要素:
6.本发明所要解决的技术问题是提供一种更加有效的图像识别系统,通过该图像识别系统,可以进一步提高对不平衡图像数据的识别准确率。本发明提供一种能够解决不平衡图像分类问题的深度学习算法,通过在传统的深度神经网络中引入特征缩放和边界样本
挖掘来增强模型对不平衡图像数据的识别。
7.具体而言,一种基于特征缩放和边界样本的不平衡图像分类系统,包括以下步骤:
8.1)将原始样本数据划分为训练集和测试集两部分,并将训练集构造为不平衡数据;
9.2)特征缩放模块,根据每个类的特征所构成的超球半径对特征进行按比例缩放,从而增强模型对少数类样本的训练与学习;
10.3)基于gabriel图的边界样本挖掘模块,根据gabriel图的定义在样本特征的基础上构建gabriel图,并且发掘边界样本特征,在所发掘的特征的基础上对类内类间距离进行约束;
11.4)通过损失调度器,控制上述两个模块的训练过程,使训练前期关注表征你能力的训练,后期关注类别的判别。
12.5)测试步骤中,将原始测试图片输入到训练好的卷积神经网络中,通过网络提取特征,然后通过全连接层对图片进行判断。
13.步骤1)所述的构造不平衡数据,在训练数据上构造不同类型的不平衡数据集,而在测试数据和验证数据上依旧保持平衡性,并在此基础上验证模型的有效性和泛化性。一方面,长尾不平衡数据集通过指数函数在训练样本中对每个类的样本进行随机采样,其中i为类下标,ni是第i类的样本数,i的值从0到c-1,c是类别数,最后ρ是不平衡比。另一方面,而跃阶不平衡是通过减少一半类别中的样本数量来创建的,即一半类别的样本数不变,剩下的类别的样本数减少为原来的
14.步骤2)中的特征缩放模块,根据一个批次中的每个类中所包含的样本特征计算每个类的中心,在求得每个类在当前批次的中心后通过指数移动平均计算类中心,该过程可以被定义为,center=ηcenter
pre
(1-η)mean其中center为中心,η为中心更新的系数,center
pre
为之前批次计算得到的中心,mean为当前批次每个类的中心。
15.计算得到每个类的中心后,需要计算每个类的半径,将类的中心向量和所有同类样本的特征向量求欧式距离,取最大值作为当前类的半径。
16.最后,利用每一类的半径和拥有最多样本数的类的半径求比值,根据半径的比值,对不同类别的特征进行缩放,缩放系数可以定义为,其中γ为温度系数,控制半径比值对原始特征的影响。rj为第j类的半径,r
xmax
为包含最多样本数的类的半径。
17.得到缩放系数之后,对卷积神经网络提取的特征进行缩放,最后经过 softmax函数归一化得到预测结果。
18.步骤3)中的基于gabriel图的边界样本挖掘模块,gabriel图的定义如下,||f
i-fj||2≤(||f
i-fk||2 ||f
j-fk||2)
若满足上式则特征fi和特征fj之间可以构成边,其中‖
·
‖表示欧式距离,fk表示出了fi和fj之外的所有其他特征向量。
19.在卷积神经网络提取特征之后,利用gabriel图的定义在特征上构建 gabriel图,并且保留端点是异类的边,而这些样本我们将其定义为每个类别的边界样本。在这些边界样本的基础上,我们利用损失函数使得边界样本本身更加靠近类中心,而异类边界样本之间更加远离,从而使得类内更加紧凑,而类间更加分散,达到增强模型表征能力的目的,具体损失函数定义如下,体损失函数定义如下,体损失函数定义如下,其中s为gabriel图边的集合,σ为系数,对应的全连接层的权重,λ为阈值用于控制类内类间距离的差值,为用于平衡不平衡性的权重,由于类别的样本数存在不平衡性,因此在挖掘得到的边界样本中,多数类的样本较多,从而导致在计算类内类间距离值时多数类的距离值更多,使得少数类的结果几乎被忽略。通过加权增强少数类距离在损失函数中的作用,其中n
xmax
表示包含最多样本数的类别的样本数,表示每一类的样本数。
20.步骤4)中的损失调度器,用于控制两个模块的训练过程,使训练前期关注表征能力的训练,即更加关注loss
ggl
的变化,后期更加关注判别能力的训练,即更加关注交叉熵损失函数loss
ce
的变化,通过损失调度器控制步骤2)中的温度系数γ。系数γ和β控制训练过程,定义如下,β=max(1-γ,ε)其中τ和ε为超参数,为[0,1]之间的小数,其中τ用于控制不同轮次时系数的影响力,ε用于控制当训练到后期是仍然保持之前训练得到的表征能力,防止后续的训练破坏之前训练轮次模型学习到的表征能力,epoch为训练轮次,epochs为总轮次。
[0021]
因此总的损失函数可以被定义如下,loss=loss
ce
βloss
ggl
其中loss
ce
表示交叉熵损失函数。
[0022]
所述模型在新的测试集中进行预测时,将数据输入卷积神经网络中进行预测,最后的样本可以被预测为:
其中pi表示第i类预测的概率。
[0023]
本发明的有益效果是:本发明的一种基于特征缩放和边界样本的不平衡图像分类系统。特征缩放模块利用每个类的特征的超球半径的比值对其特征进行缩放,从而使得模型更加关注少数类的训练。边界样本挖掘模块利用gabriel图挖掘边界样本,并且最小化类内距离,最大化类间距离,从而增强神经网络的表征能力。两者结合使神经网络能更好的适应不平衡数据,增强了图像识别系统在不平衡数据上的鲁棒性,提升了分类性能。
附图说明
[0024]
图1是本发明整体框架图。
[0025]
图2是本发明的训练流程图。
具体实施方式
[0026]
下面结合附图和具体实施例对本发明进行详细描述,但并不因此将本发明限制在所述的实施例范围之中。
[0027]
实施例
[0028]
本实施例提供一种图像识别方法用于在不平衡图像数据集中有效识别图像,参见图1和图2,本发明主要包括以下步骤:
[0029]
训练阶段
[0030]
1)对图像数据进行预处理,将原始图像数据进行水平翻转,随机裁剪以及标准化后得到新的图像数据,将新的图像数据输入到模型当中;
[0031]
2)对步骤1)中得到的新图像数据,使用卷积神经网络对图像数据的特征进行提取,得到原始图像的高阶抽象特征;
[0032]
3)对步骤2)提取得到的抽象特征,采用特征缩放模块,计算每一类的超球半径,此处的超球半径的计算方式如下:center=ηcenter
pre
(1-η)mean其中center为中心,η为中心更新的系数,center
pre
为之前批次计算得到的中心, mean为当前批次每个类的中心;
[0033]
4)利用步骤3)中得到的每个类的半径,为每一个类计算缩放系数进行特征缩放从而得到新特,征缩放系数可以定义为:其中γ为温度系数,控制半径比值对原始特征的影响,rj为第j类的半径,r
xmax
为包含最多样本数的类的半径;
[0034]
5)对步骤2)提取的高阶抽象特征,系统在该批次的所有数据上构建 gabriel图,并保留端点是异类的边,将这些特征定义为边界样本特征,对于挖掘得到的边界样本特征,高斯度量损失函数,约束类内类间相似性,此处损失函数具体定义为:
其中s为gabriel图边的集合,σ为系数,对应的全连接层的权重,λ为阈值用于控制类内类间距离的差值,为用于平衡不平衡性的权重,通过加权增强少数类距离在损失函数中的作用,其中n
xmax
表示包含最多样本数的类别的样本数,表示每一类的样本数;
[0035]
6)对步骤4)中缩放后得到的新特征构造交叉熵损失函数,来计算模型识别的类型和真实标签之间的差距;
[0036]
7)对步骤5)和步骤6)中构建的损失函数,以及步骤4)中的特征缩放系数通过损失调度器进行动态调度训练,通过系数γ和β控制训练过程,其中γ控制缩放系数的变化,而β控制损失函数的变化,定义如下:β=max(1-γ,ε)其中τ和ε为超参数,为[0,1]之间的小数,其中τ用于控制不同轮次时系数的影响力,ε用于控制当训练到后期是仍然保持之前训练得到的表征能力,防止后续的训练破坏之前训练轮次模型学习到的表征能力,epoch为训练轮次,epochs为总轮次;
[0037]
8)总的损失函数可以被定义如下,loss=loss
ce
βloss
ggl
其中loss
ce
表示交叉熵损失函数。
[0038]
测试阶段
[0039]
1)将一张或多张待识别的图像输入模型;
[0040]
2)将步骤1)中输入的图像利用卷积神经网络进行特征提取得到抽象特征;
[0041]
3)将步骤2)中得到的抽象特征经过全连接层后,计算图像属于每一类的概率,将概率最大的类作为该图像所属的类别,具体如下:其中pi表示第i类预测的概率。
[0042]
实验设计
[0043]
实验数据集:
[0044]
实验数据来自国际通用图像数据cifar-10和cifar-100;cifar-10数据集共60000
张像素为32*32的图片,包括10类图像,分别为:飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船,货车。cifar-100数据集共60000张像素32*32 的图片,包括100类。
[0045]
对比算法:
[0046]
本文所提方法主要针对不平衡图像数据,因此对比算法我们采用同样适用于不平衡图像数据的方法focal loss,mixup,cb focal,ldam-drw,bbn。
[0047]
性能度量方法:
[0048]
由于测试数据是平衡的数据集,因此我们采用准确率(acc)来度量不同方法的性能,其中p为预测准确的样本数,n为总样本数。
[0049]
实验结果
[0050]
表1 对比方法在不平衡cifar-10上实验结果
[0051][0052]
由表1的对比结果可知,所提方法在不同不平衡度的数据集上均达到了最高的准确率,超过了所有的对比方法,这证明了所提方法的有效性与优越性。
[0053]
表2 对比方法在cifar-100上的实验结果
[0054][0055]
在相同不平衡度下,cifar-100相对于cifar-10具有更多的类别数,并且每一类所包含的样本数更少,因此对分类系统的性能要求更高。表2结果显示,所提分类系统相对于其他方法具有更高的鲁棒性。
[0056]
针对所提系统的不同模块,我们实施了消融实验特征缩放模块(fsm),边界样本挖掘模块(bsmm)。结果如下表所示,实验结果表明,特征缩放模块和边界样本挖掘模块对不平
衡数据分类都有效果,并且二者结合能进一步提升分类性能。
[0057]
表3 所提系统的不同模块的消融实验
[0058]
综上所述,本发明的基于特征缩放和边界样本挖掘的不平衡图像数据分类系统,特征缩放通过超球半径促进少数类的训练,而同时边界样本挖掘约束类内类间距离,二者结合提升了不平衡图像数据识别效果。此外,本发明也为领域内其他相关问题提供了参考,可以以此为依据进行拓展延伸,具有十分广阔的应用前景。
[0059]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的技术人员应当理解,这些只是举例说明,本发明的保护范围是由所附权利要求书限定的。在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。