一种基于k-means聚类算法的学生发展方向预测方法及系统
技术领域
1.本发明涉及机器学习技术领域,尤其涉及一种基于k-means聚类算法的学生发展方向预测方法及系统。
背景技术:
2.职业教育越来越受到国家的重视,且正处于蓬勃发展的时期,随着职业教育重要性的日益突出,高等职业教育的入学率也在不断地提高。
3.随着高职院校的发展壮大,高职学生的数量也在快速增长,在高职院校中,存储着大量学生的学情分析数据,而这个重要的学情分析数据在众多高校中,并没有充分的利用起来,如何将这些有价值的学情分析数据充分利用起来有目的性的培养高职院校的学生,提升高校学生的专业能力尤为重要。
技术实现要素:
4.有鉴于此,本技术提出了一种基于k-means聚类算法的学生发展方向预测方法及系统,解决了现有技术中没有充分利用到学情分析数据对学生的未来发展方向进行预测的问题,为制定学生学习计划和职业发展规划提供可行性的建议。
5.本发明的技术方案是这样实现的:
6.本发明提出了一种基于k-means聚类算法的学生发展方向预测方法,所述方法包括:
7.s1,采集高职院校的学生学情分析数据,并将其作为训练数据;
8.s2,利用k-means聚类算法对训练数据进行处理,采用特征选择算法对 k-means聚类算法进行优化,找出影响高职学生发展方向的主要因素;
9.s3,构建rbf神经网络模型,将影响高职学生发展方向的主要因素输入到 rbf神经网络模型进行优化训练,得到训练好的学生发展方向预测模型;
10.s4,获取待预测学生学情数据并对待预测学生学情数据进行处理,利用训练好的学生发展方向预测模型对处理后的待预测学生学情数据进行分析,预测并输出学生未来发展方向的预测结果。
11.在以上技术方案的基础上,优选的,步骤s2中,采用特征选择算法对 k-means聚类算法进行优化具体包括:
12.s201,对训练数据进行抽样得到样本数据集s={s1,s2,
…
,sm},每个数据对象都包含q个特征属性,即si={s
i1
,s
i2
,
…
,s
iq
},将样本数据集划分为k个不同的类别集合c={c1,c2,
…
,ck},ci∈c;
13.s202,随机选择一个数据对象si作为质心,si∈s,计算各类别集合中的数据对象与si的欧式距离,从中选择与si距离最近的d个数据对象;
14.s203,d个数据对象与si构成新的集合t(c),其他数据对象根据其所属类别构成了新的集合g(c);
15.s204,依据集合t(c)和g(c)更新各特征属性的特征权重向量,按照权重值从大到小的顺序进行排序,筛选出权重值靠前的z个特征属性。
16.在以上技术方案的基础上,优选的,步骤s204具体包括:
17.依据集合t(c)和g(c)更新各特征属性的特征权重向量,得到权重向量集合 w={w1,w2,
…
,wq},其计算公式为:
[0018][0019]
其中,t表示第t个特征属性,t=1,2,
…
,q,i=1,2,
…
,m,q(c)表示集合t(c)中包含第t个特征属性的数据个数,q(s(si))表示样本数据集中包含第t个特征属性的数据个数,diff(t,si,x)表示数据对象在第t个特征属性上的差值函数,n表示抽取样本数据的次数。
[0020]
在以上技术方案的基础上,优选的,步骤s2中,采用特征选择算法对 k-means聚类算法进行优化之后还包括:
[0021]
根据筛选出的特征属性,针对每一个聚类重新选择聚类中心,不断地进行更新聚类,根据均衡判别函数判别聚类的程度,当均衡判别函数取最小值时,得到最优的聚类结果,即为影响高职学生发展方向的主要因素。
[0022]
在以上技术方案的基础上,优选的,根据均衡判别函数判别聚类的程度包括:
[0023]
计算样本数据集中数据对象xi与所属类别的聚类中心ci之间的聚类的平方,计算公式为:
[0024][0025]
计算两个类簇间的差异,其计算公式为
[0026]
b(c)=∑
1≤j≤i≤k
d(ci,ci)2[0027]
其中,ci和ci分别为第i个和第j个类簇的聚类中心;
[0028]
均衡判别函数的计算公式为:
[0029][0030]
其中,k为聚类个数,b(c)为类簇之间的差异,w(c)为类簇内部的差异。
[0031]
在以上技术方案的基础上,优选的,步骤s3中rbf神经网络模型具体包括:
[0032]
所述rfb神经网络模型为单隐层多层神经网络结构,包括输入层、隐藏层和输出层,输入层的神经元个数为m,输出层神经元个数为n,隐藏层神经元个数为h,隐藏层激活函数为高斯径向基函数,输出层激活函数为线性函数。
[0033]
在以上技术方案的基础上,优选的,步骤s3中,将影响高职学生发展方向的主要因素输入到rbf神经网络模型进行优化训练具体包括:
[0034]
影响高职学生发展方向的主要因素有p个,表示为x={x1,x2,
…
,x
p
},y表示预测模型的输出结果,将影响高职学生发展方向的主要因素作为输入变量,将学生的发展方向作为最终的输出变量,则对应的函数关系表示为 y=f(x1,x2,
…
,x
p
)。
[0035]
在以上技术方案的基础上,优选的,隐藏层激活函数为高斯径向基函数具体包括:
[0036]
设定隐藏层采用径向基函数作为rbf神经网络的高斯函数,其计算公式为:
[0037][0038]
其中,x表示rbf神经网络模型的输入变量,σ表示隐藏层神经元的宽度参数;
[0039]
利用高斯径向函数可以得到隐藏层的输入与输出hi之间的非线性对应关系,其表达式为
[0040][0041]
其中,ci表示第i个隐藏层神经节点到输出层神经节点的偏置向量,σi为第i个隐藏层神经元的宽度参数,i=1,2,
…
,h。
[0042]
在以上技术方案的基础上,优选的,输出层激活函数为线性函数具体包括:
[0043]
输出层实现从隐藏层到输出层的线性输出,y表示输出层节点的输出,其计算公式为
[0044][0045]
其中,k表示隐藏层中的节点数,wi表示第i个隐藏层到输出层中节点的权重,hi为第i个隐藏层中节点的输出值,θ是相应输出层中节点的阈值;
[0046]
当输入的值xi为时,第j个隐藏层节点的输入公式为:
[0047][0048]
其中,i=1,2,
…
,p,j=1,2,
…
,h,cj表示第j个隐藏层神经节点到输出层神经节点的偏置向量;
[0049]
隐藏层的输出矩阵为:
[0050][0051]
本发明还提供了一种基于k-means聚类算法的学生发展方向预测系统,所述系统包括:
[0052]
数据采集模块,采集高职院校的学生学情分析数据,并将其作为训练数据;
[0053]
特征选择模块,利用k-means聚类算法对训练数据进行处理,采用特征选择算法对k-means聚类算法进行优化,找出影响高职学生发展方向的主要因素;
[0054]
模型构建模块,构建rbf神经网络模型,将影响高职学生发展方向的主要因素输入到rbf神经网络模型进行优化训练,得到训练好的学生发展方向预测模型;
[0055]
预测模块,获取待预测学生学情数据并对待预测学生学情数据进行处理,利用训练好的学生发展方向预测模型对处理后的待预测学生学情数据进行分析,预测并输出学生未来发展方向的预测结果。
[0056]
本发明的一种基于k-means聚类算法的学生发展方向预测方法及系统,相对于现有技术,具有以下有益效果:
[0057]
(1)根据高职院校学生发展预测问题的复杂性和特征属性的繁杂,选取了 k-means聚类算法作为核心算法,并给予了优化,找出影响高职学生发展方向的主要因素。
[0058]
(2)采用rbf神经网络建立了学生发展方向预测模型,将影响高职学生发展方向的主要因素输入到rbf神经网络模型进行优化训练,得到训练好的学生发展方向预测模型,根据学生自身的属性和特点定性的分析构建函数,充分利用了学情分析数据对学生的未来发展方向进行预测,为制定学生学习计划和职业发展规划提供可行性的建议。
[0059]
(3)通过计算特征属性的权重向量的值来判断一个特征属性对当前聚类的贡献程度,筛选和清洗了无效的特征属性,降低了聚类分析的复杂程度,提高了算法的性能和计算结果的准确性。
附图说明
[0060]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0061]
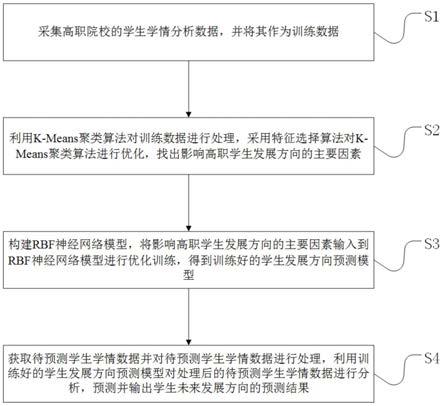
图1为本发明一种基于k-means聚类算法的学生发展预测方法的流程示意图;
[0062]
图2为本发明一种基于k-means聚类算法中优化k-means聚类算法的流程示意图。
具体实施方式
[0063]
下面将结合本发明实施方式,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
[0064]
本发明实施例提供一种基于k-means聚类算法的学生发展方向预测方法,具体步骤如图1所示,包括但不限于以下步骤:
[0065]
s1,采集高职院校的学生学情分析数据,并将其作为训练数据。
[0066]
具体的,高职院校的学生学情分析数据从院校的教务处获取,将这些学情分析数据作为训练数据,对学生进行数据挖掘和数据分析。
[0067]
s2,利用k-means聚类算法对训练数据进行处理,采用特征选择算法对 k-means聚类算法进行优化,找出影响高职学生发展方向的主要因素。
[0068]
k-means算法是一种无监督的、重复迭代型的聚类算法,由于算法性能优良,计算简单快速而得到了广泛的应用,k-means聚类算法是一种相关测度是基于欧氏距离的分区聚类算法,这种算法需要得到相应的最优聚类中心向量,并求出准则函数的最小值,在k-means聚类算法中,两个数据点之间的距离越小,两个数据点之间的相关联性越大,在不同程度上,相互靠近的数据点对象可以形成类簇。
[0069]
具体的,步骤s2的具体过程如图2所示,包括但不限于以下步骤:
[0070]
s201,对训练数据进行抽样得到样本数据集s={s1,s2,
…
,sm},每个数据对象都包含q个特征属性,即si={s
i1
,s
i2
,
…
,s
iq
},将样本数据集划分为k个不同的类别集合c={c1,c2,
…
,ck},ci∈c。
[0071]
s202,随机选择一个数据对象si作为质心,si∈s,计算各类别集合中的数据对象与si的欧式距离,从中选择与si距离最近的d个数据对象。
[0072]
s203,d个数据对象与si构成新的集合t(c),其他数据对象根据其所属类别构成了新的集合g(c)。
[0073]
s204,依据集合t(c)和g(c)更新各特征属性的特征权重向量,按照权重值从大到小的顺序进行排序,筛选出权重值靠前的z个特征属性。
[0074]
具体的,依据集合t(c)和g(c)更新各特征属性的特征权重向量,得到权重向量集合w={w1,w2,
…
,wq},其计算公式为:
[0075][0076]
其中,t表示第t个特征属性,t=1,2,
…
,q,i=1,2,
…
,m,q(c)表示集合t(c)中包含第t个特征属性的数据个数,q(s(si))表示样本数据集中包含第t个特征属性的数据个数,diff(t,si,x)表示数据对象在第t个特征属性上的差值函数,n表示抽取样本数据的次数。
[0077]
采用特征选择算法对k-means聚类算法进行优化之后还包括:
[0078]
根据筛选出的特征属性,针对每一个聚类重新选择聚类中心,不断地进行更新聚类,根据均衡判别函数判别聚类的程度,当均衡判别函数取最小值时,得到最优的聚类结果,即为影响高职学生发展方向的主要因素。
[0079]
进一步,根据均衡判别函数判别聚类的程度包括:
[0080]
计算样本数据集中数据对象xi与所属类别的聚类中心ci之间的聚类的平方,计算公式为:
[0081][0082]
计算两个类簇间的差异,其计算公式为
[0083]
b(c)=∑
1≤j≤i≤k
d(ci,ci)2[0084]
其中,ci和ci分别为第i个和第j个类簇的聚类中心;
[0085]
均衡判别函数的计算公式为:
[0086][0087]
其中,k为聚类个数,b(c)为类簇之间的差异,w(c)为类簇内部的差异。
[0088]
为了适应和解决高职院校学生发展预测问题,采用特征选择算法对k-means 算法进行了优化,该算法首先对高职院校的学生设置对应的特征属性,然后对无关的特征属性进行筛选和清洗,规范化相应的特征属性选择,再对聚类中心进行赋初值,不断更新,最后用均衡判别函数对选取的聚类中心进行优化,使之越来越匹配对应的聚类数目,从而找出影响高职学生发展的影响因素。
[0089]
当采集的学情分析数据拥有太多的特征属性时,会掺杂入一部分无效的或者重复的特征属性,会增加聚类分析的复杂程度,降低算法的性能,甚至影响计算结果的准确性。为了解决这个问题,筛选和清洗无效的特征属性是必要的,这里通过计算特征属性的权重
向量的值来判断一个特征属性对当前聚类的贡献程度。同时,通过对特征属性在同一个类别的数据对象与不同类别的数据对象之间的不同进行查看和验证来度量该特征的对聚类的贡献程度。如果特征属性在不同类别的对象之间互相区别比较明显,但是在同一个数据类别的对象之间又互相区别不明显,即特征属性的权重较大,那么该特征属性对聚类的贡献程度高,具有较强的特征区分能力。
[0090]
s3,构建rbf神经网络模型,将影响高职学生发展方向的主要因素输入到 rbf神经网络模型进行优化训练,得到训练好的学生发展方向预测模型;
[0091]
需要理解的是,所述rfb神经网络模型为单隐层多层神经网络结构,包括输入层、隐藏层和输出层,输入层的神经元个数为m,输出层神经元个数为n,隐藏层神经元个数为h,隐藏层激活函数为高斯径向基函数,输出层激活函数为线性函数。
[0092]
具体的,将影响高职学生发展方向的主要因素输入到rbf神经网络模型进行优化训练具体包括:
[0093]
影响高职学生发展方向的主要因素有p个,表示为x={x1,x2,
…
,x
p
},y表示预测模型的输出结果,将影响高职学生发展方向的主要因素作为输入变量,将学生的发展方向作为最终的输出变量,则对应的函数关系表示为 y=f(x1,x2,
…
,x
p
)。
[0094]
进一步的,隐藏层激活函数为高斯径向基函数具体包括:
[0095]
设定隐藏层采用径向基函数作为rbf神经网络的高斯函数,其计算公式为:
[0096][0097]
其中,x表示rbf神经网络模型的输入变量,σ表示隐藏层神经元的宽度参数;
[0098]
利用高斯径向函数可以得到隐藏层的输入与输出hi之间的非线性对应关系,其表达式为
[0099][0100]
其中,ci表示第i个隐藏层神经节点到输出层神经节点的偏置向量,σi为第 i个隐藏层神经元的宽度参数,i=1,2,
…
,h。
[0101]
进一步的,输出层激活函数为线性函数具体包括:
[0102]
输出层实现从隐藏层到输出层的线性输出,y表示输出层节点的输出,其计算公式为
[0103][0104]
其中,k表示隐藏层中的节点数,wi表示第i个隐藏层到输出层中节点的权重,hi为第i个隐藏层中节点的输出值,θ是相应输出层中节点的阈值;
[0105]
当输入的值xi为时,第j个隐藏层节点的输入公式为:
[0106][0107]
其中,i=1,2,
…
,p,j=1,2,
…
,h,cj表示第j个隐藏层神经节点到输出层神经节点的偏置向量;
[0108]
隐藏层的输出矩阵为:
[0109][0110]
本实施例中,为了帮助学生明确自己的发展方向,明确自己的学习计划,提高高职院校人才培养的质量,根据对实际数据的分析,选取了六个影响高职学生发展方向的主要因素作为学生发展预测模型的输入变量,用学生的发展方向或者从业选择作为最终的输出变量,则对应的函数关系可以表示为:y=f(x1,x2,x3,x4,x5,x6),其中对应的自变量为:x1是学生的家庭背景因素,x2是学生的性别因素,x3是学生兴趣和专业的匹配因素,x4是影响学生自我学习能力的因素,x5是影响学生交际能力的因素,x6为学生的所学专业的相关能力因素,y 为预测模型的输出结果。
[0111]
s4,获取待预测学生学情数据并对待预测学生学情数据进行处理,利用训练好的学生发展方向预测模型对处理后的待预测学生学情数据进行分析,预测并输出学生未来发展方向的预测结果。
[0112]
本实施例实际上是通过对学生所涉及的影响因素信息进行处理后作为学生发展方向预测模型的输入,充分利用了学情分析数据对学生的未来发展方向进行预测,为制定学生学习计划和职业发展规划提供可行性的建议。
[0113]
本实施例还提供了一种基于k-means聚类算法的学生发展方向预测系统,所述系统包括:
[0114]
数据采集模块,采集高职院校的学生学情分析数据,并将其作为训练数据;
[0115]
特征选择模块,利用k-means聚类算法对训练数据进行处理,采用特征选择算法对k-means聚类算法进行优化,找出影响高职学生发展方向的主要因素;
[0116]
模型构建模块,构建rbf神经网络模型,将影响高职学生发展方向的主要因素输入到rbf神经网络模型进行优化训练,得到训练好的学生发展方向预测模型;
[0117]
预测模块,获取待预测学生学情数据并对待预测学生学情数据进行处理,利用训练好的学生发展方向预测模型对处理后的待预测学生学情数据进行分析,预测并输出学生未来发展方向的预测结果。
[0118]
以上所述仅为本发明的较佳实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。