一种面向电网调控业务的ai模型服务化共享方法及系统
技术领域
1.本发明涉及一种面向电网调控业务的ai模型服务化共享方法及系统,属于电网调控技术领域。
背景技术:
2.目前电网调控技术领域的人工智能技术应用取得了初步的成果,但各类业务应用多采用ai模型独立管理模式,存在底层资源重复建设、多种算法框架模型压缩与转换能力不足、模型来源与版本无法溯源、异构系统模型部署与服务化发布能力较弱等方面问题,且应用ai模型成果没有形成共建共享的生态环境。
3.根据目前电网调控业务的发展趋势,迫切需要提供一个人工智能模型全生命周期管理框架与系统,实现人工智能模型存储、版本控制、模型检索、云-边-端模型按需部署和模型推理能力服务化共享。
技术实现要素:
4.为了解决现有技术中ai模型管理薄弱、模型无法共享的问题,本发明提出了一种面向电网调控业务的ai模型服务化共享方法及系统,对ai模型进行统一存储和版本管理,并通过集群系统进行模型调用,降低业务应用ai模型管理成本,提高管理效率,实现应用ai模型成果在电网调控系统内部共建共享。
5.为解决上述技术问题,本发明采用了如下技术手段:
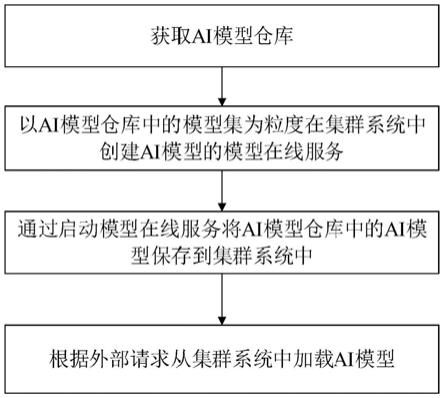
6.第一方面,本发明提出了一种面向电网调控业务的ai模型服务化共享方法,包括如下步骤:
7.获取ai模型仓库,所述ai模型仓库包括多个模型集,每个模型集中存储有多个相同类型的ai模型;
8.以ai模型仓库中的模型集为粒度在集群系统中创建ai模型的模型在线服务;
9.通过启动模型在线服务将ai模型仓库中的ai模型保存到集群系统中;
10.根据外部请求从集群系统中加载ai模型。
11.结合第一方面,进一步的,ai模型仓库中的每个模型集配置有唯一的模型集id,同一个模型集包括一个或多个模型集版本,每个模型版本配置有唯一的模型集版本id;ai模型仓库中的每个ai模型配置有唯一的模型uid。
12.结合第一方面,进一步的,ai模型仓库中设置有模型集信息表、模型集版本信息表和ai模型信息表,均为二维表形式;模型集信息表包括模型集id、模型集名称、模型类型、模型来源;模型集版本信息表包括模型集id、模型集版本id、更新时间;ai模型信息表包括模型uid、模型集id、模型集版本id、更新时间。
13.结合第一方面,进一步的,ai模型仓库的构建方法为:
14.通过电网调控业务训练获取多个ai模型,并将获取到的ai模型以内存块形式暂存;
15.利用校验算法计算内存块的特征值,记为第一特征值;
16.将内存块与第一特征值共同发送给服务器的文件管理服务;
17.文件管理服务利用校验算法再次计算内存块的特征值,记为第二特征值;
18.判断第一特征值与第二特征值是否相同,如果相同,从内存块中获取ai模型,并将ai模型存储到ai模型仓库对应的模型集中。
19.结合第一方面,进一步的,模型在线服务的创建方法包括:
20.获取服务名称、实例数、cpu、gpu和内存;
21.根据模型集id、模型集版本id和服务名称,设置模型在线服务的集群标签为“app=服务名称-集群id”;
22.调用kubernetes api创建deployment,deployment的标签label为集群标签;
23.通过deployment创建replicaset,并利用replicaset在系统后台创建与实例数相等个数的pod;
24.调用kubernetes api创建service,并将service的selector和deployment的label设置一致;
25.调用kubernetes api创建ingress,并将ingress与service关联起来。
26.结合第一方面,进一步的,通过启动模型在线服务将ai模型仓库中的ai模型保存到集群系统中的方法为:
27.根据模型集id、模型集版本id从ai模型仓库中获取对应的模型uid列表;
28.根据模型uid列表,通过文件管理服务从ai模型仓库中批量获取ai模型,并将获取到的ai模型以内存块形式暂存;
29.利用校验算法计算内存块的特征值,记为第一特征值;
30.通过文件管理服务将第一特征值与内存块一起发送至集群系统;
31.集群系统利用校验算法再次计算内存块的特征值,记为第二特征值;
32.判断第一特征值与第二特征值是否相同,如果相同,将该内存块保存至集群系统。
33.结合第一方面,进一步的,在集群系统中,通过修改ingress对象的backend配置信息进行模型在线服务的蓝绿集群部署升级。
34.结合第一方面,进一步的,在集群系统中,调用kubernetes api修改deployment的replicas参数,从而增减pod的数量;调用kubernetes api修改deployment的requests和limits参数,从而修改每个pod的cpu、gpu和内存。
35.结合第一方面,进一步的,根据外部请求从集群系统中加载ai模型的方法包括:
36.通过ingress获取集群外部url格式的http请求,并根据预先设置的规则列表对接收到的http请求进行规则匹配;
37.规则匹配成功后,ingress根据service名称和端口号将http请求转发给service;
38.service根据selector将http请求代理到对应的deployment的pod上;
39.模型在线服务解析http请求,根据解析出的模型uid使用各ai算法框架相应的模型加载方式加载集群系统中的ai模型。
40.第二方面,本发明提出了一种面向电网调控业务的ai模型服务化共享系统,包括:
41.ai模型仓库,用于以模型集的形式存储ai模型,每个模型集存储相同类型的ai模型;
42.模型管理模块,用于批量存取ai模型,更新ai模型,管理ai模型仓库中的模型集信息和模型集版本;
43.模型在线服务部署模块,用于以ai模型仓库中的模型集为粒度在集群系统中部署ai模型的模型在线服务;
44.服务启动模块,通过启动模型在线服务将ai模型仓库中的ai模型保存到集群系统中;
45.模型加载模块,根据外部请求从集群系统中加载ai模型。
46.采用以上技术手段后可以获得以下优势:
47.本发明提出了一种面向电网调控业务的ai模型服务化共享方法及系统,通过ai模型仓库汇聚调控应用ai模型成果,实现电网调控领域ai模型的共建;针对电网调控业务应用ai模型文件小但数量多的特点,本发明以模型集为粒度进行管理,支持批量持久化存储和获取ai模型,减少网络传输频率,有效提高了模型存取效率;本发明基于kubernetes提供ai模型服务一体化发布,可以快速平滑的进行模型升级和扩容,提高硬件资源利用率,实现跨调度机构与业务系统的ai模型能力共享;通过模型在线服务蓝绿部署升级,保证不间断的对外提供服务,只要老版本的服务不被删除,可以在任何时间切换至老版本对应的模型在线服务,有效降低ai模型升级风险。
48.本发明方法和系统可以显著降低业务应用对ai模型管理的沟通成本和人力成本,有效提高模型管理效率,实现应用ai模型成果在调控系统内部共建共享。
附图说明
49.图1为本发明一种面向电网调控业务的ai模型服务化共享方法的步骤流程图;
50.图2为本发明实施例中ai模型管理和服务化共享数据流程图;
51.图3为本发明实施例中创建模型在线服务的流程图。
具体实施方式
52.下面结合附图对本发明的技术方案作进一步说明:
53.为了在电网调度系统中实现ai模型的共建共享,本发明提供了一种面向电网调控领域的ai模型管理方法,以模型集为粒度对电网调控领域ai模型进行存储和管理,构建ai模型仓库,具体操作如下:
54.s1、用户按需创建多个模型集,每个模型集配置有唯一的模型集id,每个模型集仅存储相同类型的ai模型,常见人工智能算法框架和模型文件类型对应关系如表1所示。
55.表1
[0056][0057][0058]
s2、通过电网调控业务训练获取多个ai模型,每个ai模型配置有唯一的模型uid,并将获取到的ai模型以内存块形式暂存。
[0059]
s3、利用校验算法计算内存块的特征值,记为第一特征值,将内存块与第一特征值共同发送给服务器的文件管理服务。
[0060]
s4、文件管理服务利用校验算法再次计算内存块的特征值,记为第二特征值。
[0061]
s5、判断第一特征值与第二特征值是否相同,如果相同,从内存块中获取ai模型,并将ai模型存储到ai模型仓库对应的模型集中。
[0062]
在本发明实施例中,校验算法包括但不限于crc-32、crc-64、sha-1、sha-256、md5等。
[0063]
本发明可以对模型集进行版本控制,同一个模型集可以包括一个或多个模型集版本,每个模型版本配置有唯一的模型集版本id。当一个模型集中的任一ai模型更新时,就会生成一个新版本的模型集,ai模型可以自动更新或手动更新,即新的模型集版本可以自动创建或手动创建,ai模型手动更新过程一般为用户主动上传新的ai模型或修改现有ai模型的参数并重新训练,ai模型自动更新过程为:针对电网调控业务不同应用需要按日、周、月、季度、年等不同周期重新训练ai模型,并进行批量ai模型更新,通过内部自动更新模式代替人工维护,可以降低沟通成本和人力成本,有效提高管理效率。
[0064]
在ai模型仓库中,以二维表形式存储了模型集信息、模型集版本信息和ai模型信息,分别记为模型集信息表、模型集版本信息表和ai模型信息表。模型集信息包括模型集id、模型集名称、模型类型、模型来源等;其中,模型来源可以是平台自定义的或者是用户自定义的。模型集版本信息表包括模型集id、模型集版本id、版本更新时间等;ai模型信息包括模型uid、模型集id、模型集版本id、更新时间等。
[0065]
电网调控领域部分业务应用,需要针对不同电网设备构建成百上千个相同类型的ai模型,模型文件相对较小但数量相对较多,以模型集为粒度进行管理,可以有效降低沟通成本和人力成本,提高管理效率。此外,本发明采用批量持久化存储ai模型模式,减少了网络传输频率,有效提高了传输和存储效率
[0066]
根据上述构建的ai模型仓库,本发明提出了一种面向电网调控业务的ai模型服务化共享方法,如图1、2所示,具体包括如下步骤:
[0067]
步骤a、获取ai模型仓库。
[0068]
步骤b、以ai模型仓库中的模型集为粒度在集群系统中创建ai模型的模型在线服务;模型在线服务可以是自动创建的也可以手动创建的,模型在线服务可以对外提供模型预测、手动或自动更新等功能,如图3所示,具体包括如下步骤:
[0069]
步骤b01、获取服务名称、实例数、cpu、gpu和内存等所需机器资源,这些所需的机器资源一般是人为设置的。
[0070]
对于ai模型仓库中的任一模型集,仅存在一个且名称唯一的模型在线服务,服务名称与模型集id对应,服务名称以二维表形式存储。一个模型集版本有且仅有一个集群,由于一个模型集可能包括多个版本,因此对于任一模型在线服务,支持存在多个集群(即模型集版本),但仅集群外部通过url可访问模型在线服务中的一个集群,该集群为绿集群,其它集群为蓝集群。集群id属于uid,其与模型集id、模型集版本id、实例数、cpu、gpu、内存、集群状态等,以二维表形式存储,保证映射关系的完整性。
[0071]
在本发明实施例中,假定模型集为g1,模型集版本为v1,设置模型在线服务名称test、集群id为d1、实例数为2、cpu核数为2、gpu核数为0和内存大小为2g。
[0072]
步骤b02、根据模型集id、模型集版本id和服务名称,设置模型在线服务的集群标签为“app=服务名称-集群id”。
[0073]
步骤b03、创建deployment.yaml文件,调用kubernetes api创建deployment,deployment的标签label为步骤b02中的集群标签。
[0074]
kubernetes会使用deployment创建replicaset,replicaset在后台创建与所设置的实例数相等个数的pod。每个pod对应一个基于基础镜像创建的容器,该容器可以启动模型在线服务,对外提供模型预测、手动或自动更新等功能,每次接收到http请求时调用相应函数。
[0075]
基础镜像内预装包括但不限于spark、tensorflow、keras、scikit-learn等模型在线服务所需的java/python模块。
[0076]
在本发明实施例中,调用kubernetes api创建的deployment对象名称为“test-d1”,标签label为“app=test-d1”,假定模型发布服务对外暴露端口号为12345,deployment.yaml文件的示例如下:
[0077][0078]
步骤b04、创建service.yaml文件,调用kubernetes api创建service,并将service的selector和deployment的label设置一致,使步骤b03创建的这一组pod能够被该service访问到。
[0079]
在本实施例中,调用kubernetes api创建service名称为“test-d1”,该service的selector为“app=test-d1”,它会将请求代理到步骤b03创建的pod上,service.yaml文件的示例如下:
[0080][0081]
步骤b05、创建ingress.yaml文件,调用kubernetes api创建ingress,并将ingress与service关联起来。
[0082]
service和pod仅可在kubernetes集群内部网络中通过ip地址访问,无法被集群外部访问,因此本发明通过ingress实现集群外部通过url向指定pod发送http请求的功能。ingress中设置了入站请求的规则列表,可在接到http请求后进行规则匹配,并将流量转发
到service名称和端口号。
[0083]
在本发明实施例中,创建一个名称为“test”的ingress对象,它会匹配http规则/modelservice/test并将流量转发至步骤b04中创建的名称为“test-d1”的service对象的12345端口。ingress.yaml文件的示例如下:
[0084][0085]
步骤c、通过启动模型在线服务将ai模型仓库中的ai模型保存到集群系统中,具体操作如下:
[0086]
步骤c01、启动模型在线服务,根据该模型在线服务对应的模型集id、模型集版本id从ai模型仓库中获取对应的模型uid列表。
[0087]
根据模型集id和模型集版本id检索ai模型仓库中的模型集信息表、模型集版本信息表和ai模型信息表,可以得到所有符合要求的ai模型uid,形成模型uid列表。
[0088]
步骤c02、根据模型uid列表,通过文件管理服务从ai模型仓库中批量获取ai模型,并将获取到的ai模型以内存块形式暂存。
[0089]
步骤c03、利用校验算法计算内存块的特征值,记为第一特征值;通过文件管理服务将第一特征值与内存块一起发送至集群系统。
[0090]
步骤c04、集群系统利用校验算法再次计算内存块的特征值,记为第二特征值,并判断第一特征值与第二特征值是否相同,如果相同,将该内存块保存至集群系统中。ai模型是暂存在集群系统中,停止模型在线服务集群时删除并释放机器资源。
[0091]
模型在线服务启动后,对外发布模型在线服务,外部可以请求模型在线服务。
[0092]
通过重复步骤c01~c04,实现用户需求通过外部url请求、内部自动更新ai模型,支持全模型集更新至指定版本和更新任一版本的任一ai模型。一站式ai模型升级,同时满足业务应用在不同场景下ai模型手动更新、自动定期更新需求。
[0093]
对于同一个模型在线服务,如果有新的模型集版本出现或者需要更换服务对应的模型集版本,可通过修改ingress对象的backend配置信息进行模型在线服务的蓝绿集群部署升级。蓝绿部署在升级过程中,模型在线服务始终在线,可以保证不间断的对外提供服务。同时,新版本上线的过程中,并没有修改老版本的任何内容,在部署期间,老版本的状态不受影响,只要老版本的服务不被删除,可以在任何时间切换至老版本对应的模型在线服务,降低ai模型升级风险。
[0094]
在本发明实施例中,假定新的模型集版本为v2(与上文的v1对应),实例数为1、cpu核数为2、gpu核数为0和内存大小为2g,蓝绿集群部署升级的具体操作如下:
[0095]
(1)根据模型集、模型集版本、服务名称、实例数、cpu、gpu和内存等配置信息,设置新的集群标签“app=test-d2”,调用kubernetes api创建的deployment对象名称为“test-d2”,标签label为“app=test-d2”,并利用kubernetes与实例数相等个数的pod,此时,该组
pod为蓝集群,步骤b03中创建的一组pod为绿集群。
[0096]
(2)创建service.yaml文件,调用kubernetes api创建service名称为“test-d2”,并将service的selector为“app=test-d2”,它会将请求代理到步骤(1)创建的pod上。
[0097]
(3)调用kubernetes api修改步骤b05创建的ingress对象的配置信息,实现服务流量切换。
[0098]
修改“test”的ingress对象的backend配置信息,将流量转发至步骤(2)中创建的名称为“test-d2”的service对象的12345端口。切换后,步骤(1)中创建的一组pod变为绿集群,步骤b03中创建的一组pod变为蓝集群。
[0099]
在集群系统中,当模型服务的负载能力有较高要求时,可调用kubernetes api修改deployment的replicas参数以增加pod的数量,也可根据集群资源使用情况,修改requests和limits参数以修改每个pod的cpu、gpu和内存等资源。
[0100]
步骤d、根据外部请求从集群系统中加载ai模型,完成模型调用,对外提供模型预测等功能。
[0101]
步骤d01、通过ingress获取集群外部url格式的http请求,并根据预先设置的规则列表对接收到的http请求进行规则匹配。
[0102]
步骤d02、规则匹配成功后,ingress根据service名称和端口号将http请求转发给service。
[0103]
步骤d03、service根据selector将http请求代理到对应的deployment的pod上,pod上的容器内的模型在线服务可以接收到http请求。
[0104]
步骤d04、模型在线服务解析http请求,根据解析出的模型uid使用各ai算法框架相应的模型加载方式加载集群系统中的ai模型,返回模型预测结果,完成ai模型调用。
[0105]
外部可通过url访问一个版本的模型集,可以同时调用该版本模型集中的多个ai模型。
[0106]
本发明方法还包括如下步骤:
[0107]
步骤e:根据集群id停止不使用的模型在线服务集群,具体操作如下:
[0108]
步骤e01:调用kubernetes api删除名称为“服务名称-集群id”的deployment。在本实施例中,调用kubernetes api删除名称为“test-d1”的deployment。
[0109]
步骤e02:调用kubernetes api删除标签为“app=服务名称-集群id”replicaset。在本实施例中,调用kubernetes api删除标签为“app=test-d1”的replicaset。
[0110]
步骤e03:调用kubernetes api删除标签为“app=服务名称-集群id”的pod。在本实施例中,调用kubernetes api删除标签为“app=test-d1”的pod。
[0111]
步骤e04:调用kubernetes api删除名称为“服务名称-集群id”service。在本实施例中,调用kubernetes api删除名称为“test-d1”的service。
[0112]
步骤e05:根据集群id,删除模型在线服务集群配置信息。在本实施例中,删除集群id为d1的模型在线服务集群配置信息。
[0113]
步骤f:根据服务名称删除模型在线服务,具体操作如下:
[0114]
步骤f01:根据服务名称,查询所有集群列表。
[0115]
步骤f02:重复步骤e01-e05,依次删除所有集群。在本实施例中,调用kubernetes api删除名称为“test-d2”的deployment、标签为“app=test-d2”的replicaset、标签为“app=test-d2”的pod和名称为“test-d2”的service,删除集群id为d2的模型在线服务集群配置信息。
[0116]
步骤f03:调用kubernetes api删除名称为“服务名称”ingress。在本实施例中,调用kubernetes api删除名称为“test”的ingress。
[0117]
步骤f04:根据服务名称,删除模型在线服务信息。在本实施例中,删除服务名称为test的模型在线服务信息。
[0118]
本发明基于kubernetes提供ai模型服务一体化发布,实现快速平滑升级和扩容,提高硬件资源利用率,实现跨调度机构与业务系统的ai模型能力共享,可显著降低业务应用对ai模型管理的沟通成本和人力成本,有效提高管理效率,实现应用ai模型成果在调控系统内部共建共享。
[0119]
本发明还提出了一种面向电网调控业务的ai模型服务化共享系统,主要包括ai模型仓库、模型管理模块、模型在线服务部署模块、服务启动模块和模型加载模块。
[0120]
ai模型仓库主要用于以模型集的形式存储ai模型,每个模型集存储相同类型的ai模型。
[0121]
模型管理模块主要用于批量存取ai模型,更新ai模型,管理ai模型仓库中的模型集信息和模型集版本。
[0122]
模型管理模块包括如下子模块:
[0123]
模块m101:模型集管理子模块,提供模型集信息的增加、删除、修改和模型集版本控制功能。
[0124]
模块m102:ai模型批量存取子模块,批量持久化存储和获取ai模型,并根据校验算法生成特征值。
[0125]
模块m103:ai模型更新子模块,支持http请求和自动定期更新全模型集至指定版本和更新任一版本的任一ai模型。
[0126]
模型在线服务部署模块主要用于以ai模型仓库中的模型集为粒度在集群系统中部署ai模型的模型在线服务,模型在线服务部署模块的具体操作与本发明方法的步骤b一致。
[0127]
模型在线服务部署模块包括如下子模块:
[0128]
模块m201:deployment创建子模块,根据指定模型集、模型集版本,并设置服务名称、实例数、cpu、gpu和内存等所需机器资源,创建deployment.yaml文件,调用kubernetes api创建deployment。
[0129]
模块m202:service创建子模块,创建service.yaml文件,调用kubernetes api创建service。
[0130]
模块m203:ingress创建子模块,创建ingress.yaml文件,调用kubernetes api创建ingress。
[0131]
模块m204:流量切换子模块,根据需要切换蓝绿集群id,调用kubernetes api修改ingress配置信息。
[0132]
模块m205:集群状态查询子模块,根据集群id,查询该集群中所有pod的状态,常见pod状态如表2所示:
[0133]
表2
[0134]
服务状态名称服务状态描述创建中containercreating运行running停止terminating等待pending失败fail
[0135]
服务启动模块主要用于通过启动模型在线服务将ai模型仓库中的ai模型保存到集群系统中,具体操作与本发明方法的步骤c一致。
[0136]
模型加载模块主要用于根据外部请求从集群系统中加载ai模型,具体操作与本发明方法的步骤d一致。
[0137]
本发明方法和系统可以显著降低业务应用对ai模型管理的沟通成本和人力成本,有效提高模型管理效率,实现应用ai模型成果在调控系统内部共建共享。
[0138]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0139]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0140]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0141]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0142]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。