1.本发明涉及教育大数据和模型处理技术领域,尤其是一种基于联邦蒸馏的联邦学习模型的训练方法、系统和介质。
背景技术:
2.随着互联网及人工智能(ai)的快速发展,用户无时无刻不在使用无数移动设备来产生大量数据,久而久之,数据是爆炸且呈指数增长的,例如,容量巨大且类型冗余的教育大数据。众所周知,机器学习(machine leaming,简称ml)等人工智能技术在科学研究和商业决策中的成功应用正得益于大数据的驱动,具有高表征能力的数据可以帮助我们构建更复杂、更准确的ml模型。但是,日常生活中的数据往往以数据孤岛形式存在,数据难以聚合和存储。数据孤岛成为机器学习的一大挑战之一。最典型的就是目前海量碎片化存在于各地区学校、培训机构的教育资源数据。加上通用数据保护条例(gdpr)的发表及限制,数据隐私保护成为机器学习的又一大瓶颈。在这种情况下,学者们开始将注意力从数据聚合转向模型聚合。联邦学习(federated leaming,简称fl)作为一种新的分布式机器学习框架应运而生。相关技术中,在联邦学习中参与的用户数量可以达到几十、几百甚至更多,每个客户端本地数据的数据异质性致使联邦学习无法学习更好的全局模型。此外,客户端和中心服务器之间的通讯也存在高延迟和不稳定性。
技术实现要素:
3.本发明面向教育大数据旨在至少解决现有联邦学习技术中存在的技术问题之一。为此,本发明提出一种基于联邦蒸馏的联邦学习模型的训练方法、系统和介质,能够有效提升联邦学习模型的准确度,提高客户端和中心服务器之间通讯的稳定性及收敛速度。
4.一方面,本发明实施例提供了一种基于联邦蒸馏的联邦学习模型的训练方法,包括以下步骤:
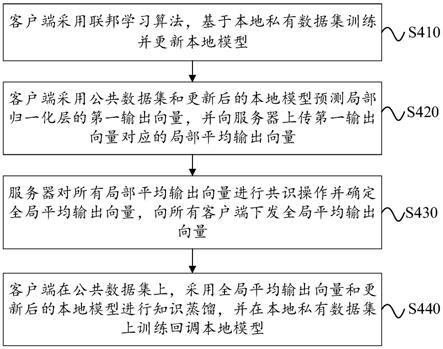
5.客户端采用联邦学习算法,基于本地私有数据集训练并更新本地模型;
6.所述客户端采用公共数据集和更新后的所述本地模型预测局部归一化层的第一输出向量,并向服务器上传所述第一输出向量对应的局部平均输出向量;
7.服务器对所有所述局部平均输出向量进行全局共识操作并确定全局平均输出向量,向所有所述客户端下发所述全局平均输出向量;
8.所述客户端在所述公共数据集上,采用所述全局平均输出向量和更新后的所述本地模型进行知识蒸馏,并在所述本地私有数据集上训练回调本地模型。
9.在一些实施例中,在执行所述客户端采用联邦学习算法,基于本地私有数据集训练并更新本地模型这一步骤之前,所述方法还包括以下步骤:
10.所述服务器向每个所述客户端发送初始化模型。
11.在一些实施例中,所述客户端与服务器之间传输模型平均输出向量。
12.在一些实施例中,所述客户端更新本地模型,包括:
13.获取部分所述本地私有数据集;
14.确定本地模型的目标函数对应的梯度信息;
15.根据所述梯度信息和所述本地私有数据集,采用迭代一阶方式获取近似值。
16.在一些实施例中,在所述客户端采用公共数据集和更新后的所述本地模型预测局部归一化层的第一输出向量之前,所述方法还包括以下步骤:
17.计算每个标签的第二输出向量。
18.在一些实施例中,所述客户端在所述公共数据集上,采用所述全局平均输出向量和更新后的所述本地模型进行知识蒸馏,包括:
19.所述客户端根据所述全局平均输出向量,控制更新后的所述本地模型,采用知识蒸馏学习所述公共数据集上的共识信息。
20.在一些实施例中,所述归一化层包括softmax层;所述第一输出向量包括softmax层输出的logit向量。
21.另一方面,本发明实施例提供了一种基于联邦蒸馏的联邦学习模型的训练系统,包括:
22.客户端,所述客户端采用联邦学习算法,基于本地私有数据集训练并更新本地模型;采用公共数据集和更新后的所述本地模型预测局部归一化层的第一输出向量,并向服务器上传所述第一输出向量对应的局部平均输出向量;以及在所述公共数据集上,采用服务器下发的全局平均输出向量和更新后的所述本地模型进行知识蒸馏,并在所述本地私有数据集上训练回调本地模型;
23.服务器,所述服务器对所有所述局部平均输出向量进行全局共识操作并确定全局平均输出向量,向所有所述客户端下发所述全局平均输出向量。
24.另一方面,本发明实施例提供了一种基于联邦蒸馏的联邦学习模型的训练系统,包括:
25.至少一个存储器,用于存储程序;
26.至少一个处理器,用于加载所述程序以执行所述的基于联邦蒸馏的联邦学习模型的训练方法。
27.另一方面,本发明实施例提供了一种存储介质,其中存储有计算机可执行的程序,所述计算机可执行的程序被处理器执行时用于实现所述的基于联邦蒸馏的联邦学习模型的训练方法。
28.本发明实施例提供的一种基于联邦蒸馏的联邦学习模型的训练方法,具有如下有益效果:
29.本实施例的客户端先采用联邦学习算法,基于本地私有数据集训练并更新本地模型,并采用公共数据集和更新后的本地模型预测局部归一化层的第一输出向量,并向服务器上传第一输出向量对应的局部平均输出向量,接着服务器对所有局部平均输出向量进行全局共识操作并确定全局平均输出向量后,向所有客户端下发全局平均输出向量,然后客户端在公共数据集上,采用全局平均输出向量和更新后的本地模型进行知识蒸馏,并在本地私有数据集上训练回调本地模型。本实施例通过联邦蒸馏完成模型更新,使用个性化联邦学习完成局部个性化,同时联邦蒸馏使每个客户端能够在公共数据集上训练自己的本地模型,并使用模型的归一化层的输出向量上传服务器完成模型更新,使得通信成本只取决
于模型输出,不会随模型大小倍数增加,从而有效提高客户端和中心服务器之间通讯的稳定性和减少延迟。
30.本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
31.下面结合附图和实施例对本发明做进一步的说明,其中:
32.图1为一种现有的联邦学习的实施例示意图;
33.图2为本发明实施例的个性化联邦蒸馏示意图;
34.图3为本发明实施例的一种基于联邦蒸馏的联邦学习模型的训练方法的流程图;
35.图4为在mnist数据集内处于强凸设置下本本发明实施例与其他方法的准确率曲线示意图;
36.图5为在mnist数据集内处于强凸设置下本本发明实施例与其他方法的损失曲线示意图;
37.图6为在mnist数据集内处于非凸设置下本本发明实施例与其他方法的准确率曲线示意图;
38.图7为在mnist数据集内处于非凸设置下本本发明实施例与其他方法的损失曲线示意图;
39.图8为在synthetic数据集内处于强凸设置下本本发明实施例与其他方法的准确率曲线示意图;
40.图9为在synthetic数据集内处于强凸设置下本本发明实施例与其他方法的损失曲线示意图;
41.图10为在synthetic数据集内处于非凸设置下本本发明实施例与其他方法的准确率曲线示意图;
42.图11为在synthetic数据集内处于非凸设置下本本发明实施例与其他方法的损失曲线示意图;
43.图12为本发明实施例在mnist数据集内处于强凸设置下k值对准确率影响的示意图;
44.图13为本发明实施例在mnist数据集内处于强凸设置下k值对训练损失影响的示意图;
45.图14为本发明实施例在mnist数据集内处于非凸设置下k值对准确率影响的示意图;
46.图15为本发明实施例在mnist数据集内处于非凸设置下k值对训练损失影响的示意图;
47.图16为本发明实施例在synthetic数据集内处于强凸设置下k值对准确率影响的示意图;
48.图17为本发明实施例在synthetic数据集内处于强凸设置下k值对训练损失影响的示意图;
49.图18为本发明实施例在synthetic数据集内处于非凸设置下k值对准确率影响的
示意图;
50.图19为本发明实施例在synthetic数据集内处于非凸设置下k值对训练损失影响的示意图。
具体实施方式
51.下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
52.在本发明的描述中,若干的含义是一个以上,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
53.本发明的描述中,除非另有明确的限定,设置等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。
54.本发明的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
55.联邦学习是一种分布式机器学习框架。联邦学习可以使多个称为客户端的用户共同协作训练共享的全局模型,而训练期间无需暴露来自其本地设备的隐私数据。如图1所示,传统联邦学习是在客户端110和服务器120之间进行交互,其交互过程的数据处理过程包含客户端进行本地更新、客户端将更新后的模型上传服务器、服务器进行聚合平均及广播分发到各个客户端这四个步骤。由整个训练过程可知,联邦学习通过学习各个本地用户的数据特征,运用模型聚合代替数据聚合,更好的利用散列各处的小数据打破现存的数据孤岛窘态。于此同时,用户数据永远不会直接与第三方共享。数据隐私保护的联邦学习也因此备受关注且衍生出许多应用。
56.但是,在联邦学习中参与的用户数量可以达到几十、几百甚至更多,每个客户端本地数据的数据异质性致使联邦学习无法学习更好的全局模型。此外,客户端和中心服务器之间的通讯存在高延迟和不稳定性。这些因素使得联邦学习在实际应用需求时面临诸多挑战。因此,本实施例通过采用联邦蒸馏算法设计一种个性化的联邦学习来克服上述问题,并实现以下目标:第一、确保数据异质性下的每个客户端获得更高准确率的个性化模型;第二、在少量的通信迭代轮次中促进模型的快速收敛。
57.具体地,在传统联邦学习中,由一组客户端和一个中央参数服务器组成,旨在最小化优化公式(1)的目标函数而共同协作训练。在公式(1)中,m代表参与客户端总量(k=1
…
m),w为全局模型权重,fk:rd→
r,fk(w)为客户端k的本地目标函数,如公式(2)所示。在公式2中,dk代表了客户端k的本地私有数据集,ξk是从私有数据集中随机选择出来的数据集合(x,y),是客户端k在ξk数据分布和w下的损失函数,加权平均得到fk(w)。但是由于客户端之间的数据在数量、质量、环境及应用等各方面的差异,ξk和ξ
k 1
中存在严重的
数据差异,呈现非独立同分布(non-i.i.d)的数据特征。此外,客户端的用户数据呈现出各式各样的non-i.i.d数据分布,如偏态特征分布、偏态标签分布、概念转移等。
[0058][0059][0060]
表示表示目标损失函数fk(w)的最小化,m表示表示客户的总数,e表示表示客户端k在本地私有数据集上的目标损失函数的期望,即加权值。
[0061]
然而,在联邦学习的实际应用环境中保证边缘参与设备的隐私数据分布为i.i.d是不切实际的。本实施例假设f
*
(w)和分别表示f(w)和fk(w)的最小值,令的差值表示数据异质性程度,pk代表第k个客户端的权重。因此,当数据是i.i.d时,随着样本数量的增加,差值会越来越接近于零。而如果数据是non-i.i.d,则差值不为零,其大小表示数据分布的异质性程度。反观现实中普遍存在的non-i.i.d数据分布,则使客户端每个局部目标函数的优化方向发生偏离,局部目标函数的加权最小值不等于全局目标函数的最小值。这无疑损害了全局训练模型的性能。因此,需要重点设计模型算法,以实现面对non-i.i.d数据时表现出良好的鲁棒性,使其在数据异质性的情况下训练出通讯高效且个性化的联邦学习模型是很有必要的。
[0062]
如上所述,联邦学习性能受数据异质性的影响。数据异质性越高,联邦学习性能越差。为了解决数据异质性问题,现有的研究过程旨在减少数据异质性引起的模型偏差。通过在客户端设备、数据和模型层面谈论并给出了各种个性化处理方法,以减少全局模型和局部模型的目标损失函数之间的差异。类似的个性化联邦学习方法是pfedme。pfedme将目标函数优化更改为如公式(3)所示:
[0063][0064]
其中g是多个外部客户端数据聚合得到的全局模型,θk是通过优化客户端k的数据分布得到的个性化模型,fk(θk)为客户端k的本地个性化模型目标函数,的定义是莫罗包络函数。pfedme优化了本地客户端数据分布,并保持本地模型与全局模型之间存在有限距离,以减少数据异质性导致的模型偏移。但是,由于内部优化器的黑盒化,pfedme需要通过多步更新的迭代方法获得个性化模型,这无疑增加了模型通讯成本。再者,pfedme采用的模型更新通讯方式仍然是传统联邦学习的参数交换方式,该方式的参数交换会使通讯成本随着模型大小进行扩展,从而产生高额通信开销,尤其是在边缘无线设备的分布式联邦学习中。
[0065]
因此,本实施例提出引入联邦蒸馏的思想来解决pfedme算法的通信开销瓶颈。联邦蒸馏使用整体蒸馏技术,允许在中央服务器和参与客户端之间交换模型输出,即在任何迭代次数的信息交换中,客户端传输的是平均输出向量而不是模型梯度等参数信息。与传统的联邦学习相比,联邦蒸馏产生的通信开销仅取决于模型输出维度,与蒸馏数据的大小成正比,不会根据模型的大小进行扩展。
[0066]
具体地,如图2所示,本发明在服务器220与参与客户端210之间的信息交换期间,客户端先进行本地模型更新310,并预测本地模型归一化层的输出向量320,接着传递本地模型归一化层的输出向量330,服务器对接收的本地模型的输出向量进行聚合平均340,然后将聚合平均后的全局平均向量和公共数据集光波分发到各个客户端350,客户端在根据全局向量和公共数据集进行蒸馏学习360。由此可知,本实施例可以大大减少联邦学习训练过程中的通信成本,同时采取知识蒸馏学习公共数据集知识以趋近共识,之后在本地训练回调调整模型参数,缩进本地与全局模型之间的偏差,提高模型性能。
[0067]
下面以流程图的形式,阐述本实施例的具体实施过程。
[0068]
参照图3,本实施例提供了本发明实施例提供了一种基于联邦蒸馏的联邦学习模型的训练方法,包括以下步骤:
[0069]
s410、客户端采用联邦学习算法,基于本地私有数据集训练并更新本地模型。本地私有数据包括表1中的mnist数据集。
[0070]
s420、客户端采用公共数据集和更新后的本地模型预测局部归一化层的第一输出向量,并向服务器上传第一输出向量对应的局部平均输出向量。其中,归一化层包括softmax层。第一输出向量包括logit向量。具体地,将softmax层的输出向量放在logit中,以表示softmax层的输出向量。
[0071]
s430、服务器对所有局部平均输出向量进行全局共识操作并确定全局平均输出向量,向所有客户端下发全局平均输出向量。
[0072]
s440、客户端在公共数据集上,采用全局平均输出向量和更新后的本地模型进行知识蒸馏,并在本地私有数据集上训练回调本地模型。例如,每个客户端本地进行知识蒸馏,下载全局平均输出向量在公共数据集上训练本地模型已接近共识。最后,每个客户端训练在本地私有数据集上本地模型以进行回调。具体地,在蒸馏阶段,此时的客户端已经获得了公共平均输出向量。客户端使用知识蒸馏,根据公共数据集学习共识信息。最后,每个客户端继续对私有数据集进行一些批量训练以进行回调。
[0073]
在一些实施例中,在每次开始训练之前,服务器为所有客户端发送初始化模型。
[0074]
在完成一次步骤s410至步骤s440后,即完成一次迭代过程。随着客户端不断学习全局模型的知识,局部目标函数与全局目标函数的偏差会逐渐减小,最终可以在数据异质性环境中用较低的通讯成本取得具有较高精度个性化本地模型。
[0075]
具体地,本实施例包括客户端和远程服务器的训练过程两部分。客户端训练阶段主要包括更新、预测、蒸馏等步骤。其中,在更新阶段,本实施例使用pfedme算法在本地私有数据集上进行模型的本地训练和更新。首先,要得到个性化模型,需要计算梯度信息。本实施例通过对部分本地私有数据dk进行采样,使用公式(4)计算的无偏估计。在公式(4)中,客户端k在本地私有数据集dk上的本地个性化目标函数的梯度近似于其在数据分布ξk下本地个性化目标函数梯度的平均。其中,θk是通过优化客户端k的数据分布得到的个性化模型,为客户端k在数据分布ξk下的本地个性化模型目标函数,则表示的梯度。之后使用迭代一阶方法获得如公式(5)所示的近似值其中,表示在全局回合数t和本地回合数r下客户端k的局部模型,λ表示
控制个性化模型强度的正则化参数。梯度信息在预测阶段,客户端使用公共数据集和本地模型来预测本地softmax层的输出向量。每个客户端k在softmax层输出之前计算的每个标签如公式(6)所示的输出向量作为第二输出向量。在公式6中,表示每个标签的模型输出向量,其中c是协变量向量,l是对应标签的编码向量,是每个客户端运行神经网络后生成的对数向量。在蒸馏阶段,此时的客户端已经获得了公共平均输出向量。客户端使用知识蒸馏,根据公共数据集学习共识信息。最后,每个客户端继续对私有数据集进行一些批量训练以进行回调。
[0076][0077][0078][0079]
在远程服务器训练阶段,主要进行模型输出聚合和广播。在任何迭代次数t的信息交换中,设备传输的是平均输出向量而不是参数信息。如公式(7)所示,所有客户端上传的输出向量在参数服务器中进行平均,得到全局平均输出向量之后,服务器将聚合平均后的全局平均输出向量广播给每个客户端。
[0080][0081]
综上所述,本实施例使用联邦蒸馏完成模型更新,使用个性化联邦学习完成局部个性化。联邦蒸馏使每个客户端能够在公共数据集上训练自己的本地模型,并使用模型的softmax层的输出向量上传服务器完成模型更新。这样,通信成本只取决于模型输出,不会随着模型大小增加一倍。本文提出的联邦蒸馏算法有望实现具有通信效率的个性化联邦学习方案。
[0082]
本实施例在真实数据集(mnist)和合成数据集(synthetic)上执行分类任务。考虑数据大小和类别的异构设置,将mnist分成n=20份。它们各自分配了不同的数据量,数据量范围为[1165,3834],对于类别,只允许每个客户拥有10个标签中的2个;在生成和分发synthetic数据集时,使用α控制本地模型的差异,β控制本地数据与其他客户端数据的差异。因此,本实施例生成了一个具有α=β=0.5异构特征的synthetic数据集,同样分成n=20份,数据量范围为[250,25810]。上述数据集的异质性设置确保了用于联邦学习的训练和测试数据集是non-iid的。考虑到联邦蒸馏的数据集设置,无论是mnist还是synthetic数据集,提取其中的一份数据集作为公共数据集。最后,为mnist数据集和synthetic数据集均定义了s=5个客户端进行联邦学习训练。
[0083]
在实验中,将具有softmax激活和交叉熵损失函数的l2-正则化多项逻辑回归模型(mlr)作为μ-强凸模型设置进行训练。同时,还使用了一个两层神经网络(dnn)作为非凸案例。其中,一个隐藏层是relu激活函数,最后一层是softmax层。在mnist上使用大小为100的隐藏层,在synthetic数据集上使用大小为20的隐藏层。为了突出pfd的算法性能,将pfd与
fedavg、per-fedavg和pfedme进行了比较。由于联邦蒸馏设置,将比较上述算法的局部模型性能。为了与per-fedavg进行比较,使用其局部个性化模型,该模型可以在sgd步骤之后从全局模型中获得。对于pfedme,使用由个性化参数θ评估的本地个性化模型作为对比实验。所有的实验都使用pytorch1.4.0版本,gpu是可选的。
[0084]
实验结果对比如附表1、图4至图11所示。其中,图4至图11在测试过程中,学习率设置为0.005,客户端数为5、计算复杂度为5。由图4、图5、图6和图7可知,在mnist数据集上,无论是强凸设置还是非凸设置,pfd得到的局部个性化模型在测试准确率和训练损失方面都优于对比方案。对于基准解决方案pfedme,pfd使本地客户端能够更好地学习公共数据集的知识,其中,pfd表示本实施例的方法。同时pfd转换模型输出替代参数更新,有效减少模型训练回合,模型收敛更快。在dnn设置中,pfd的性能与其他算法基本相同。由图4、图5、图6、图7、图8、图9、图10和图11可知,与mnist相比,各个对比模型在synthetic数据集上的测试准确率和训练损失都表现出明显的波动。pfd和pfedme的个性化联邦学习算法在合成数据环境中取得了更好的测试准确率。在强凸设置下,pfd的模型性能仍然领先于其他解决方案。与pfedme相比,它具有更快的收敛速度和更小的训练损失。在非凸设置下,pfd和pfedme的测试准确率相当,并且领先于fedavg和per-fedavg。总的来讲,pfd的收敛速度明显快于其他比较方案。这是因为通过联邦蒸馏,可以避免通过多次梯度更新近似优化个性化模型,使得pfd个性化模型在收敛速度和计算复杂度方面比其他基准模型更具优势。测试准确率结果表明,异质性数据时,pfd算法仍然表现良好。同时,局部模型训练的准确率也提升到了前所未有的水平。这表明pfd可以有效地为客户个性化全局模型。
[0085]
表1
[0086][0087]
除开上述的对比实验之外,本实施例还分析计算复杂度k对pfd的影响。在消融实验中,使用k=1,3,5,7来评估pfd的性能。实验仍然在强凸、非凸设置以及两个数据集上进行。实验结果如图12到图19所示,其中,图12为在mnist数据集内处于强凸设置下k值对准确率影响的示意图、图13为在mnist数据集内处于强凸设置下k值对训练损失影响的示意图、图14为在mnist数据集内处于非凸设置下k值对准确率影响的示意图、图15为在mnist数据集内处于非凸设置下k值对训练损失影响的示意图、图16为在synthetic数据集内处于强凸设置下k值对准确率影响的示意图、图17为在synthetic数据集内处于强凸设置下k值对训
练损失影响的示意图、图18为在synthetic数据集内处于非凸设置下k值对准确率影响的示意图、图19为在synthetic数据集内处于非凸设置下k值对训练损失影响的示意图。从图12到图15可知,在mnist数据集上,k值的变化对非凸设置下的模型性能影响不大。对于强凸设置,当k=5和k=7时,pfd可以达到更高的测试准确率。当k=3时,pfd的损失最小。从图16到图19可知,在synthetic数据集上,k值的波动明显强于上组。从图12到图19中可以看出,当k=3时,pfd在强凸设置和非凸设置下都能达到更高的测试准确率和更少的损失。这也进一步验证了本实施例提出的pfd方案可以保证异构数据环境下联邦学习中每个客户端的本地个性化模型的准确性。
[0088]
本发明实施例提供了一种基于联邦蒸馏的联邦学习模型的训练系统,包括:
[0089]
客户端,所述客户端采用联邦学习算法,基于本地私有数据集训练并更新本地模型;采用公共数据集和更新后的所述本地模型预测局部归一化层的第一输出向量,并向服务器上传所述第一输出向量对应的局部平均输出向量;以及在所述公共数据集上,采用服务器下发的全局平均输出向量和更新后的所述本地模型进行知识蒸馏,并在所述本地私有数据集上训练回调本地模型;
[0090]
服务器,所述服务器对所有所述局部平均输出向量进行全局共识操作并确定全局平均输出向量,向所有所述客户端下发所述全局平均输出向量。
[0091]
本发明方法实施例的内容均适用于本系统实施例,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同。
[0092]
本发明实施例提供了一种基于联邦蒸馏的联邦学习模型的训练系统,包括:
[0093]
至少一个存储器,用于存储程序;
[0094]
至少一个处理器,用于加载所述程序以执行图3所示的的基于联邦蒸馏的联邦学习模型的训练方法。
[0095]
本发明方法实施例的内容均适用于本系统实施例,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法达到的有益效果也相同。
[0096]
本发明实施例提供了一种存储介质,其中存储有计算机可执行的程序,所述计算机可执行的程序被处理器执行时用于实现图3所示的基于联邦蒸馏的联邦学习模型的训练方法。
[0097]
本发明实施例还提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存介质中。计算机设备的处理器可以从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行图3所示的基于联邦蒸馏的联邦学习模型的训练方法。
[0098]
上面结合附图对本发明实施例作了详细说明,但是本发明不限于上述实施例,在所属技术领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。此外,在不冲突的情况下,本发明的实施例及实施例中的特征可以相互组合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。