1.本发明涉及中文文本分拣领域,特别地,涉及基于图张量卷积的中文文本分拣系统。
背景技术:
2.如何快速精准地从大量文本中获取有用信息一直是国内外学者研究的热点问题。文本作为最基础、最常见的电子数据形式,广泛存在于互联网中。合理地对文本文档实现分类,准确地在海量电子文本数据之中获取目标数据,是目前急需解决的问题与挑战。
3.为提高中文文本分析的质量和速度,高效率的文本自动识别分拣成为其先决条件,因此,快速而准确的文本自动识别与分拣分类技术,成为文本分析工作研究的核心内容。近年来,随着深度学习的迅速发展,卷积神经网络、循环神经网络等深度学习模型被大量运用在自然语言处理领域,用以处理结构化的文本数据。然而中文文本可能会出现非结构化的文本信息,图神经网络可以把实际问题看作图中节点之间的连接和消息传播问题,对节点之间的依赖关系进行建模,从而能够很好的处理图结构数据。故发明一种高准确率、高智能化、可以处理非结构化文本信息的中文文本分拣系统具有重要意义。
技术实现要素:
4.为了克服已有中文文本分拣方法只能处理结构化的文本数据,难以处理非结构化数据的不足,本发明提供一种高准确率、高智能化、可以处理非结构化文本信息的中文文本分拣系统。基于图张量卷积对中文文本进行自动分类,基于图张量卷积的中文文本分拣系统采用中文文本作为输入,利用文本预处理模块对其进行数据清洗,基于中文文本数据库建立一个图张量卷积模型用以对中文文本进行分类,利用建立的图张量卷积模型对新输入的中文文本进行分类,并输出分类结果。本发明可以实现非结构化的中文文本,具有高准确率、高智能化等优势。解决了目前中文文本分拣系统只能处理结构化中文文本、分拣准确率低等劣势。
5.本发明解决其技术问题所采用的技术方案是:
6.一种基于图张量卷积的中文文本分拣系统,包括中文文本获取模块、基于图张量卷积的中文文本分类系统、中文文本分类显示模块,各部位依次相连构成一个完整的系统。其中基于图张量卷积的中文文本分类系统包括中文文本数据库、文本预处理模块、中文文本建模模块、中文文本分类模块和分类结果输出模块。
7.进一步地,中文文本数据库用以存储现有的中文文本和文本对应的类别,中文文本建模模块基于中文文本数据库中的数据建模,并且能够实时更新该数据库,从而实时地更新中文文本分类模型。
8.进一步地,文本预处理模块用以清洗中文文本,再利用清洗后的中文文本构建三种异构图,三种异构图分别为基于语义的图、基于句法的图和基于序列的图,三种图的节点相同,但边不同,三种异构图构成图张量。通过构造三种图的方法能够有效提取中文文本中
的语义、句法和序列的特征,对后续的分类准确率具有较大的提高,采用如下过程完成:
9.对中文文本进行分词,删除中文文本中的标点符号,删除无具体内容的介词、连词。得到清洗后的中文文本:
10.s={w1,w2,...,wk,...,wn}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
11.其中s表示清洗后的中文文本,wk表示清洗后的中文文本中第k个词,n表示清洗后的中文文本中词的数量。
12.根据该分类任务训练长短期记忆网络,从训练得到的长短期记忆的输出中获得每个词wi的语义特征嵌入
[0013][0014]
其中f
id
表示第i个词的第d维的嵌入值,d表示每个词的嵌入维度。
[0015]
则三种异构图的节点由每个词的语义特征嵌入构成:
[0016][0017]
构建基于语义的图。中文文本中第i个词wi和第j个词wj语义相似度sim
i,j
为:
[0018][0019]
中文文本中第i个词wi对应图中第i个节点,第j个词wj对应图中第j个节点,即中文文本中第i个词wi的语义特征嵌入作为第i个节点的嵌入向量,第j个词wj的语义特征嵌入作为第j个节点的嵌入向量。
[0020]
设定一个阈值ρ
sim
,则第i个节点和第j个节点间语义图的边权重为:
[0021][0022]
为语义图的邻接矩阵添加自连接,则语义图的邻接矩阵a
semantic
表示为:
[0023][0024]
基于语义的图g
semantic
可表示为:
[0025]gsemantic
=(b,a
semantic
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0026]
构建基于句法的图,利用解析器提取每个中文文本中各词间的依赖关系,将这种依赖关系视为无向关系。统计所有中文文本中具有句法依赖关系的每对词的次数,中文文本中第i个词wi对应图中第i个节点,第j个词wj对应图中第j个节点,则第i个节点和第j个节点间句法图的边权重为:
[0027]
[0028]
其中表示第i个词wi和第j个词wi在所有中文文本数据库中具有句法依赖关系的次数,表示第i个词wi和第j个词wi在所有中文文本数据库中出现在同一条文本中的次数。
[0029]
为句法图的邻接矩阵添加自连接,则句法图的邻接矩阵a
synatic
表示为:
[0030][0031]
基于句法的图g
syntactic
可表示为:
[0032]gsyntactic
=(b,a
syntactic
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0033]
构建基于序列的图。统计两个词在同一个滑动窗口下的出现的概率,概率越大则两个词间的权重也就越大。中文文本中第i个词wi对应图中第i个节点,第j个词wj对应图中第j个节点,则第i个节点和第j个节点间的序列关系l
ij
为:
[0034][0035][0036][0037][0038]
其中i
λ
(i,j)表示在滑动窗口大小为λ下第i个词和第j个词同时出现的次数,i
λ
(i)表示在滑动窗口大小为λ下第i个词出现的次数,i
λ
(j)表示在滑动窗口大小为λ下第j个词出现的次数,i
λ
表示在滑动窗口大小为λ下遍历的次数,p
λ
(i,j)表示在滑动窗口大小为λ下第i个词和第j个词同时出现的概率,p
λ
(i)表示在滑动窗口大小为λ下第i个词出现的概率,p
λ
(j)表示在滑动窗口大小为λ下第j个词出现的概率。
[0039]
若l
ij
>0表示两词相关,值越大,则相关性越强,若l
ij
=0表示两词是独立统计的,若l
ij
<0表示两词互斥。只保留l
ij
>0的序列关系。则第i个节点和第j个节点间序列图的边权重为:
[0040][0041]
为序列图的邻接矩阵添加自连接,则序列图的邻接矩阵a
sequential
表示为:
[0042][0043]
基于序列的图g
sequential
可表示为:
[0044]gsequential
=(b,a
sequential
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0045]
将三种异构图g
semantic
、g
syntactic
、g
sequential
组成图张量其中节点特征张量邻接张量
[0046]
选取中文文本数据库中数据的60%作为训练集,剩余的40%作为验证集。训练集用于中文文本建模模块的模型训练,验证集用于验证模型的分类效果。
[0047]
进一步地,中文文本建模模块利用图张量卷积网络建立高准确率的图张量卷积文本分类模型,并且利用中文文本数据库中的训练集数据自动地学习如何有效地进行图张量卷积和分类。图张量完成一次卷积操作由一次图内卷积和一次图间卷积组成,取第m次图张量卷积后的节点特征进行分类,图张量卷积采用如下过程完成:
[0048]
图张量中每个节点的初始特征h0为每个词的语义特征嵌入,则:
[0049][0050]
分别对三种异构图进行图内卷积操作,则第l层图内卷积后的节点特征张量为:
[0051][0052]
其中表示图张量的邻接张量,h
l
表示第l层的节点特征张量,表示第l层图内卷积的权重矩阵,σ(
·
)表示激活函数,可以表示为:
[0053][0054]
其中α表示该激活函数中的超参数。
[0055]
将图张量中三个异构图的对应节点连接,组成虚拟图,三个异构图的节点数量均为n,故能得到n个虚拟图。每个虚拟图包含3个节点且节点之间两两相连,虚拟图节点特征为经过上一次图内卷积操作后更新得到的节点特征,设置所有虚拟图的边的权重均为1,则第k个虚拟图的邻接矩阵为:
[0056][0057]
将所有虚拟图的邻接矩阵组合,构成虚拟图的邻接张量:
[0058][0059]
对图内卷积后的节点特征进行图间卷积操作,则第l层图间卷积后的节点特征张量,即第l 1层的节点特征张量h
l 1
为:
[0060][0061]
其中表示第l层图内卷积后的节点特征张量,表示第l层图间卷积的权重矩阵,σ(
·
)表示激活函数。
[0062]
第m次图张量卷积后的节点特征其中n表示节点的数量,c表示分类任务的类别数量。对3种异构图的同一个节点的特征进行平均池化,得到平均池化后的节点特征v:
[0063]
v=averagepooling(hm)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(24)
[0064]
其中对平均池化后的节点特征接一个全连接网络,则最终的输出o为:
[0065]
o=softmax(w
fc
v b
fc
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(25)
[0066]
其中w
fc
表示全连接网络的权重矩阵,b
fc
表示全连接网络的偏置矩阵,softmax(
·
)将输出值映射为(0,1)区间内的数,且所有数之和为1,最终选取数值最大的数对应的索引类别作为最终预测的中文文本所属的类别。
[0067]
进一步地,中文文本分类模块用以对文本预处理模块后新获取的中文文本直接输入权利要求4中训练得到的图张量卷积文本分类模型,得到该中文文本地类别。
[0068]
进一步地,分类结果输出模块将权利要求5中得到的新获取的中文文本类别结果进行输出。
[0069]
本发明的技术构思为:本发明针对现有中文文本分拣方法只能处理结构化的文本数据,难以处理非结构化数据的不足,提供了一种高准确率、高智能化、可以处理非结构化文本信息的中文文本分拣系统。基于图张量卷积对中文文本进行自动分类,基于图张量卷积的中文文本分拣系统采用中文文本作为输入,利用文本预处理模块对其进行数据清洗,基于中文文本数据库建立一个图张量卷积模型用以对中文文本进行分类,图张量卷积模型包括图内卷积和图间卷积,利用建立的图张量卷积模型对新输入的中文文本进行分类,并输出分类结果。本发明可以实现非结构化的中文文本,具有高准确率、高智能化等优点。解决了目前中文文本分拣系统只能处理结构化中文文本、分拣准确率低等缺点。
[0070]
本发明的有益效果主要体现在:1、通过文本预处理模块将非结构化的中文文本数据构建为图张量,实现对非结构化的中文文本进行分拣;2、通过构造三种图的方法能够有效提取中文文本中的语义、句法和序列的特征,对后续的分类准确率具有较大的提高;3、利用新输入的中文文本,可以对基于图张量卷积的中文文本分类模型进行实时地更新;4、图内卷积后又增加了一次图间卷积操作,能够有效融合三种异构图的信息,从而有效提高模型的分类准确率;5、基于图张量卷积的中文文本分类模型可以根据训练数据自动地学习,智能性强,受人为因素影响较小。
附图说明
[0071]
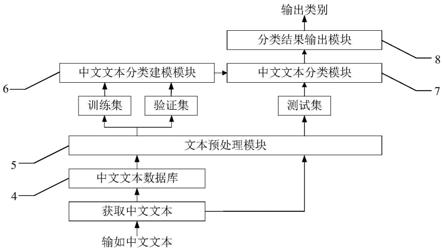
图1一种基于图张量卷积的中文文本分拣系统的硬件连接图;
[0072]
图2一种基于图张量卷积的中文文本分类系统的功能模块图。
具体实施方式
[0073]
下面结合附图对本发明作进一步描述。
[0074]
参考图1,一种基于图张量卷积的中文文本分拣系统,中文文本获取模块1、基于图张量卷积的中文文本分类系统2、中文文本分类显示模块3依次相连。参考图2,所述基于图张量卷积的中文文本分类系统2包括中文文本数据库4、文本预处理模块5、中文文本分类建模模块6、中文文本分类模块7和分类结果输出模块8。
[0075]
中文文本数据库4用以存储现有的中文文本和文本对应的类别,中文文本建模模块6基于中文文本数据库中的数据建模,并且能够实时更新该数据库,从而实时地更新中文文本分类模型。
[0076]
进一步地,文本预处理模块5用以清洗中文文本,再利用清洗后的中文文本构建三种异构图,三种异构图分别为基于语义的图、基于句法的图和基于序列的图,三种图的节点相同,但边不同,三种异构图构成图张量。通过构造三种图的方法能够有效提取中文文本中的语义、句法和序列的特征,对后续的分类准确率具有较大的提高,采用如下过程完成:
[0077]
对中文文本进行分词,删除中文文本中的标点符号,删除无具体内容的介词、连词。得到清洗后的中文文本:
[0078]
s={w1,w2,...,wk,...,wn}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0079]
其中s表示清洗后的中文文本,wk表示清洗后的中文文本中第k个词,n表示清洗后的中文文本中词的数量。
[0080]
根据该分类任务训练长短期记忆网络,从训练得到的长短期记忆的输出中获得每个词wi的语义特征嵌入
[0081][0082]
其中f
id
表示第i个词的第d维的嵌入值,d表示每个词的嵌入维度。
[0083]
则三种异构图的节点由每个词的语义特征嵌入构成:
[0084][0085]
构建基于语义的图。中文文本中第i个词wi和第j个词wj语义相似度sim
i,j
为:
[0086][0087]
中文文本中第i个词wi对应图中第i个节点,第j个词wj对应图中第j个节点,即中文文本中第i个词wi的语义特征嵌入作为第i个节点的嵌入向量,第j个词wj的语义特征嵌入作为第j个节点的嵌入向量。
[0088]
设定一个阈值ρ
sim
,则第i个节点和第j个节点间语义图的边权重为:
[0089][0090]
为语义图的邻接矩阵添加自连接,则语义图的邻接矩阵a
semantic
表示为:
[0091][0092]
基于语义的图g
semantic
可表示为:
[0093]gsemantic
=(b,a
semantic
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0094]
构建基于句法的图。利用斯坦福corenlp解析器提取每个中文文本中各词间的依赖关系,将这种依赖关系视为无向关系。统计所有中文文本中具有句法依赖关系的每对词的次数,中文文本中第i个词wi对应图中第i个节点,第j个词wj对应图中第j个节点,则第i个节点和第j个节点间句法图的边权重为:
[0095][0096]
其中表示第i个词wi和第j个词wi在所有中文文本数据库中具有句法依赖关系的次数,表示第i个词wi和第j个词wi在所有中文文本数据库中出现在同一条文本中的次数。
[0097]
为句法图的邻接矩阵添加自连接,则句法图的邻接矩阵a
synatic
表示为:
[0098][0099]
基于句法的图g
syntactic
可表示为:
[0100]gsyntactic
=(b,a
syntactic
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0101]
构建基于序列的图。统计两个词在同一个滑动窗口下的出现的概率,概率越大则两个词间的权重也就越大。中文文本中第i个词wi对应图中第i个节点,第j个词wj对应图中第j个节点,则第i个节点和第j个节点间的序列关系l
ij
为:
[0102][0103][0104][0105][0106]
其中i
λ
(i,j)表示在滑动窗口大小为λ下第i个词和第j个词同时出现的次数,i
λ
(i)表示在滑动窗口大小为λ下第i个词出现的次数,i
λ
(j)表示在滑动窗口大小为λ下第j个词
出现的次数,i
λ
表示在滑动窗口大小为λ下遍历的次数,p
λ
(i,j)表示在滑动窗口大小为λ下第i个词和第j个词同时出现的概率,p
λ
(i)表示在滑动窗口大小为λ下第i个词出现的概率,p
λ
(j)表示在滑动窗口大小为λ下第j个词出现的概率。
[0107]
若l
ij
>0表示两词相关,值越大,则相关性越强,若l
ij
=0表示两词是独立统计的,若l
ij
<0表示两词互斥。只保留l
ij
>0的序列关系。则第i个节点和第j个节点间序列图的边权重为:
[0108][0109]
为序列图的邻接矩阵添加自连接,则序列图的邻接矩阵a
sequential
表示为:
[0110][0111]
基于序列的图g
sequential
可表示为:
[0112]gsequential
=(b,a
sequential
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)
[0113]
将三种异构图g
semantic
、g
syntactic
、g
sequential
组成图张量其中节点特征张量邻接张量
[0114]
选取中文文本数据库中数据的60%作为训练集,剩余的40%作为验证集。训练集用于中文文本建模模块的模型训练,验证集用于验证模型的分类效果。
[0115]
进一步地,中文文本建模模块6利用图张量卷积网络建立高准确率的图张量卷积文本分类模型,并且利用中文文本数据库4中的训练集数据自动地学习如何有效地进行图张量卷积和分类。图张量完成一次卷积操作由一次图内卷积和一次图间卷积组成,取第m次图张量卷积后的节点特征进行分类,图张量卷积采用如下过程完成:
[0116]
图张量中每个节点的初始特征h0为每个词的语义特征嵌入,则:
[0117][0118]
分别对三种异构图进行图内卷积操作,则第l层图内卷积后的节点特征张量为:
[0119][0120]
其中表示图张量的邻接张量,h
l
表示第l层的节点特征张量,表示第l层图内卷积的权重矩阵,σ(
·
)表示激活函数,可以表示为:
[0121][0122]
其中α表示该激活函数中的超参数。
[0123]
将图张量中三个异构图的对应节点连接,组成虚拟图,三个异构图的节点数量均为n,故能得到n个虚拟图。每个虚拟图包含3个节点且节点之间两两相连,虚拟图节点特征
为经过上一次图内卷积操作后更新得到的节点特征,设置所有虚拟图的边的权重均为1,则第k个虚拟图的邻接矩阵为:
[0124][0125]
将所有虚拟图的邻接矩阵组合,构成虚拟图的邻接张量:
[0126][0127]
对图内卷积后的节点特征进行图间卷积操作,则第l层图间卷积后的节点特征张量,即第l 1层的节点特征张量h
l 1
为:
[0128][0129]
其中表示第l层图内卷积后的节点特征张量,表示第l层图间卷积的权重矩阵,σ(
·
)表示激活函数。
[0130]
第m次图张量卷积后的节点特征其中n表示节点的数量,c表示分类任务的类别数量。对3种异构图的同一个节点的特征进行平均池化,得到平均池化后的节点特征v:
[0131]
v=averagepooling(hm)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(24)
[0132]
其中对平均池化后的节点特征接一个全连接网络,则最终的输出o为:
[0133]
o=softmax(w
fc
v b
fc
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(25)
[0134]
其中w
fc
表示全连接网络的权重矩阵,b
fc
表示全连接网络的偏置矩阵,softmax(
·
)将输出值映射为(0,1)区间内的数,且所有数之和为1,最终选取数值最大的数对应的索引类别作为最终预测的中文文本所属的类别。
[0135]
进一步地,中文文本分类模块7用以对文本预处理模块5后新获取的中文文本直接输入权利要求4中训练得到的图张量卷积文本分类模型,得到该中文文本地类别。
[0136]
进一步地,分类结果输出模块8将权利要求5中得到的新获取的中文文本类别结果进行输出。
[0137]
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。