1.本发明涉及总账(ledger)修剪(pruning)系统,具体地,涉及总账可验证修剪(verifiable pruning)系统。
背景技术:
2.现有的分布式总账例如区块链(blockchain)或者有向无环图(dag,directed acyclic graph)的总账大小随着时间的推移变大,因而存储(storage)不足成为一个大问题。
3.随着高速技术的发展,存储容量的不足成为一个更大的问题。
4.目前以太坊(ethereum)的处理速度为20笔交易(tx)/秒(sec),比特币(bitcoin)为7tx/sec。以以太坊为例,每年累积250gb的数据。
5.未来还可以具有更高的交易处理速度。例如,在相比区块链具有更高交易处理速度的有向无环图-账户智慧交易链(dag-awtc,directed acyclic graph-account-wise transaction chain)总账方式中,未来还可以设定4ktx/sec的目标。
6.在4ktx/sec的交易处理速度下,一天生成的分布式总账的大小为0.5kbyte/tx*4ktx/sec*60sec/min(分)*60min/hour(时)*24hours/day(天),即172.8gb/day。
7.若每天在所有节点累积172.8gb的数据,则随着时间的推移,存在需要确保无限量存储的问题。
8.具有高交易处理速度的总账结构中,由于总账大小的累积增加,存储的利用度问题势必会成为更大的问题。
9.即使在处理速度低的以太坊(ethereum)的情况下,进行对几年前时间点之前的数据进行删除的修剪(pruning),使每个节点中只拥有几年前时间点之后的数据。经过修剪的旧数据由财团单独管理,并以每当有请求时分发的方式利用。
10.因此,可以看出,仅通过简单地使用现有的修剪(pruning)来进行有效的总账管理是有限的。
技术实现要素:
11.技术问题
12.本发明的目的在于,提供一种总账可验证修剪系统。
13.解决问题的手段
14.根据第一实施例的总账可验证修剪系统可以包括偏斜梅克尔树生成模块,上述偏斜梅克尔树生成模块根据链表(linked list)方式将之前子树的根哈希(root hash)值r
n-1
包含在数据块(data block)tn中,对包含上述根哈希值r
n-1
的数据块tn进行散列来计算出h(tn),将计算出的h(tn)与之前子树的根哈希值r
n-1
求和后进行散列来计算出h(h(tn)|r
n-1
),将计算出的h(h(tn)|r
n-1
)依次添加到二进制梅克尔树(binary merkle tree)结构的各节点中,从而扩展并生成偏斜梅克尔树(skewed merkle tree)。
15.其中,还可包括节点真伪验证模块,上述节点真伪验证模块为了验证过去规定数据块tk是否包含在上述偏斜梅克尔树中,利用上述tk和上述偏斜梅克尔树的规定根哈希值h(ti)(其中,k《i《=n),依次执行哈希值运算来计算出上述偏斜梅克尔树的最新根哈希值,通过对比计算出的最新根哈希值是否与预先已知的最新根哈希值rn一致,来验证上述tk的真伪。
16.根据第二实施例的总账可验证修剪系统可以包括h-偏斜梅克尔树(hierarchical-skewed merkle tree)生成模块,上述h-偏斜梅克尔树生成模块根据链表(linked list)方式将之前子树的根哈希(root hash)值r
n-1
包含在数据块(data block)tn中,对包含上述根哈希值r
n-1
的数据块tn进行散列来计算出h(tn),将计算出的h(tn)、之前子树的根哈希值r
n-1
与跳转链接(jump link)r
n-(基数^偏移量)
求和后进行散列来计算出h(h(tn)|r
n-1
|r
n-(基数^偏移量)
),将计算出的h(h(tn)|r
n-1
|r
n-(基数^偏移量)
)依次添加到二进制梅克尔树(binary merkle tree)结构的各节点中,从而扩展并生成h-偏斜梅克尔树(hierarchical-skewed merkle tree)。
17.其中,上述跳转链接r
n-(基数^偏移量)
可以为上述h-偏斜梅克尔树中过去规定时间点的节点上的根哈希值,上述基数(base)可以是为了向每个规定间隔分配跳转链接而预设的跳转链接的最短距离,上述偏移量(offset)可以为当前节点的位置n%基数。
18.并且,上述跳转链接的距离(dist)可以通过基数
偏移量
(base
offset
)值计算。
19.一方面,上述h-偏斜梅克尔树生成模块可以被配置为向偏移量 (基数
偏移量
)*k的每个节点分配上述跳转链接。
20.在此情况下,上述k可以由正整数组成。
21.另一方面,还可包括节点真伪验证模块,上述节点真伪验证模块为了验证过去规定数据块tk是否包含在上述h-偏斜梅克尔树中,利用上述tk和上述h-偏斜梅克尔树的规定根哈希值h(ti)(其中,k《i《=n)依次执行哈希值运算来计算出上述h-偏斜梅克尔树的最新根哈希值,通过对比计算出的最新根哈希值是否与预先已知的最新根哈希值rn一致,来验证上述tk的真伪。
22.其中,上述节点真伪验证模块被配置为根据下述的步骤验证上述h-偏斜梅克尔树中是否存在哈希值ry或数据块ty:步骤1):从最新的根哈希值r
head
到过去时间点方向的规定距离内链接(节点)为基准,检索与ry的时间点相同或在未来的链接(节点)中存在于过去最早时间点的跳转链接或者链接(节点);步骤2):从上述检索到的存在于过去最早时间点的跳转链接或者链接的哈希值到过去时间点方向的规定距离内的链接(节点)为基准,检索与ry的时间点相同或在未来的链接(节点)中存在于过去最早时间点的跳转链接或者链接(节点);步骤3):重复步骤2)的过程至达到上述ry;步骤4):利用上述ty,对上述步骤2)以及步骤3)中重复检索到的跳转链接或者链接(节点)的集合,依次计算朝未来方向的根哈希;以及步骤5):对比最终计算出的根哈希值是否与上述r
head
相同,若对比结果相同,则可以验证上述哈希值ry或者数据块ty存在于h-偏斜梅克尔树中。
23.其中,上述规定距离可以为基数。
24.发明的效果
25.根据上述总账可验证修剪系统,总账结构被配置为偏斜梅克尔树,只存储及管理最新的数据,验证另一节点提交的交易的真伪,从而具有最小化总账大小的增加并维持的
效果。
26.尤其,被配置为从偏斜梅克尔树转换为升级的h-偏斜梅克尔树来管理总账,具有大大减少随时间增加的验证用数据(proof)大小的效果。并且在缩减验证用数据大小的同时,可以通过更少次数的运算步骤验证数年前的旧数据的真伪,从而具有可以进一步提高验证速度的效果。
27.而且,h-偏斜梅克尔树被配置为通过对比由两个以上的运算路径计算出的哈希值来确认是否相同,从而具有可以确认新添加的跳转链接是否为伪造的效果。
附图说明
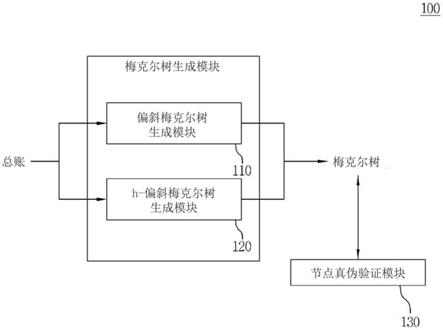
28.图1为根据本发明实施例的总账可验证修剪系统的框图。
29.图2为传统梅克尔树的结构图。
30.图3及图4为根据本发明实施例的偏斜梅克尔树生成算法的概念图。
31.图5至图10为根据本发明实施例的h-偏斜梅克尔树生成算法的概念图。
具体实施方式
32.本发明可实施多种变更,可具有多种实施例,将在附图中例示特定实施例并进行详细说明。但是,这并非表示所要将本发明限定于特定实施方式,而应当理解为包括本发明的思想及技术范围内的所有变更、等同技术方案及代替技术方案。在说明每个附图时,对于类似的结构要素使用了类似的附图标记。
33.第一、第二、a、b等术语可用于描述各种结构要素,但上述结构要素不应限于上述多个术语。上述多个术语仅用来将一个结构要素与其他结构要素区分。例如,在不脱离本发明权利范围的情况下,第一结构要素可以命名为第二结构要素,类似地第二结构要素也可以命名为第一结构要素。术语“和/或”包括多个相关记载项的组合或者多个相关记载项中的任一项。
34.应当理解,当提及某个结构要素与其他结构要素“连接”或“联接”时,可以是与其他结构要素直接连接或联接,也可以是中间存在其他结构要素。相反,当提及某个结构要素与其他结构要素“直接连接”或“直接联接”时,应当理解为中间不存在其他结构要素。
35.本技术中使用的术语仅仅用于描述特定实施例,而非旨在限定本发明。除非在文脉上含义有明显的不同,否则单数的表达包括复数的表达。本技术中,“包括”或“具有”等术语应理解为要指定说明书上所记载的特征、数字、步骤、操作、结构要素、部件或这些组合的存在,而非预先排除一个或多个其他特征、数字、步骤、操作、结构要素、部件或这些组合的存在或者附加可能性。
36.除非另有其他定义,否则其中所使用的全部术语(包括技术或科学术语)具有与本发明所属技术领域普通技术人员通常所理解的含义相同的含义。例如通用词典中定义的术语应解释为具有与相关技术的文脉上所具有的含义一致的含义,除非本技术中有明确定义,否则不应解释为理想化或过度形式化的含义。
37.以下,参照附图,对本发明的优选实施例进行详细说明。
38.图1为根据本发明实施例的总账可验证修剪系统的框图,图2为传统梅克尔树的结构图,图3及图4为根据本发明实施例的偏斜梅克尔树生成算法的概念图,图5至图10为根据
本发明实施例的h-偏斜梅克尔树生成算法的概念图。
39.首先,参照图1,根据本发明实施例的总账可验证修剪系统可以被配置为包括偏斜梅克尔树(skewed merkle tree)生成模块110或者h-偏斜梅克尔树(hierarchical-skewed merkle tree)生成模块120以及节点真伪验证模块130。
40.通常,梅克尔树(merkle tree)也称为哈希树(hash tree),具有由密码学哈希值组成的树形数据结构。
41.如图2所示,梅克尔树用于验证某些数据(例如,h1、h2、h3、h4、h5)的哈希值(例如,h6、h7、h8、root)被包含在梅克尔树中。即,只需沿着直到根节点(root node)的路径计算并验证哈希值即可。若最终计算值与根哈希值一致,则完成验证。例如,当需要验证h1时,若利用h2和h8沿着路径计算并验证哈希值的结果与根哈希值一致,则完成验证。
42.然而,在利用这种梅克尔树验证方式时,哈希值(h6、h7、h8、root)的数据大小偏小,但原始数据(h1、h2、h3、h4、h5)的数据大小相对而言必然很大。
43.总账可验证修剪系统并不是利用这种现有的普通梅克尔树结构,而是利用由此升级的偏斜梅克尔树结构以及从偏斜梅克尔树结构进一步升级的h-偏斜梅克尔树结构进行删除旧数据的修剪(pruning),同时可以只通过这种升级的梅克尔树结构来完美验证旧数据的真伪。
44.偏斜梅克尔树结构中每个节点可以通过只拥有近期的数据,例如,一天左右的数据来验证所有数据的真伪。
45.假设分布式总账系统具有一天4ktx/sec的交易处理速度,则只将一天累计的数据172.8gb数据存储在节点中,将所有剩余的先前数据进行修剪,并利用存储的数据,即偏斜梅克尔树的根哈希值来完美验证经过修剪的数据的真伪。
46.进而,h-偏斜梅克尔树结构具有比偏斜梅克尔树结构更短的验证用数据(proof)长度的数年前的旧数据。这种验证用数据(proof)的大小会随时间变大,但是本发明中通过缩小验证用数据的大小本身,可以减少验证所需的运算负担以及验证所需的时间。
47.再次参照图1及图3,偏斜梅克尔树生成模块110可以被配置为利用多个数据块(data block)生成二进制梅克尔树(binary merkle tr ee)结构的偏斜梅克尔树。
48.偏斜梅克尔树生成模块110可以被配置为生成偏斜梅克尔树,上述偏斜梅克尔树具有数据块(data block)tn和之前子树的根哈希值r
n-1
成对的二进制梅克尔树(binary merkle tree)结构的形态。
49.偏斜梅克尔树的每个节点中存储初始数据块t1和根哈希值r
n-1
。
50.偏斜梅克尔树生成模块110可以被配置为由h(h(tn)|r
n-1
)计算出每个节点的根哈希值并将其依次存储在每个节点中,从而扩展并生成偏斜梅克尔树。
51.偏斜梅克尔树生成模块110可以被配置为首先根据链表(linked list)方式将其之前子树的根哈希(root hash)值r
n-1
包含在新生成的数据块tn中。
52.并且可以被配置为通过散列tn来计算出h(tn),将计算出的h(tn)与之前子树的根哈希值r
n-1
求和后再次进行散列来计算出h(h(tn)|r
n-1
)。偏斜梅克尔树中依次存储h(h(tn)|r
n-1
)。
53.即,偏斜梅克尔树可以认为是链表和二进制梅克尔树的组合。
54.图3中哈希值r1为将第一数据块t1和根哈希初始值r0求和并散列的值。并且哈希值
r2为将第二数据块t2和最近的根哈希值r1散列的值。由于t2中以链表方式包含最近的根哈希值r1,因此可以通过散列t2和r1来计算出r2。以这种方式,在t3数据块中添加r2并重复上述过程,从而扩展并生成偏斜梅克尔树。
55.另一方面,图1的节点真伪验证模块130可以被配置为对偏斜梅克尔树中过去的特定节点进行验证其真伪。
56.为了验证图4中的t2是否包含在偏斜梅克尔树中,从偏斜梅克尔树的最新数据块t4获取其包含的r4。并且从用于验证的t2获取其包含的r1。并且可通过散列t2来计算出h(t2),并对r1和h(t2)求和并散列来计算出r2。
57.其中,如果预先已知t3的哈希值h(t3),则可以通过相同的方式计算r3,如果还预先已知h(t4),则可以利用r3计算r4。若以这种方式计算的r4与上面获得的r4相同,则可以验证,验证对象t2为包含在偏斜梅克尔树的节点。
58.即,只要知道偏斜梅克尔树中的h(t3)和h(t4),就可以对t2进行验证。
59.如果将其推广应用,则可以被视为节点真伪验证模块130为了在偏斜梅克尔树中验证特定节点的数据块tk,只要知道最新的根哈希值rn和中间步骤的数据块的哈希值h(ti)(其中,k《i《=n),就可以验证tk的真伪。
60.在此情况下,无需预先已知中间步骤的其他数据块,无需知道tk之前的一些数据块或者哈希值。
61.在偏斜梅克尔树结构中,即使每个节点不直接拥有所有数据块,也可以只通过几个小的哈希值来验证数据的真伪。这对减少网络负荷也有很大贡献。
62.但是,偏斜梅克尔树也具有缺点。由于偏斜梅克尔树的每个节点根据链表方式只拥有前一个子树的哈希值,因此如图4所示,在验证流程中需要逐个计算并运算所有节点。偏斜梅克尔树有益于验证近期的数据,但是对于数年单位的数千亿交易,具有由于运算步骤的增多而增加计算负荷的缺点。为了弥补该缺点,可以利用h-偏斜梅克尔树。
63.如图5所示,图1的h-偏斜梅克尔树生成模块120被配置为使每个节点除了拥有前一个根哈希值的同时进一步拥有与更早之前的节点的根哈希值有关的信息。更早之前的节点的根哈希值作为参照过去树的链接,被定义为跳转链接(jump link)。即,跳转链接为过去的根哈希值。
64.如图5所示,跳转链接具有指数函数性节点之间的距离,从而可以省略验证所需的长运算步骤而直接验证过去跳转链接的数据块。即,明显减少了验证用数据的大小以及运算步骤的次数,可以快速验证数年前的节点。
65.进一步拥有图5的跳转链接的h-偏斜梅克尔树的每个节点值rn可以被整理为h(h(tn)|r
n-1
|r
n-(基数^偏移量)
)。
66.其中,r
n-(基数^偏移量)
为过去某个时间点上节点的哈希值的跳转链接。
67.跳转链接中基数(base)是为了向每个规定间隔分配跳转链接而预设的跳转链接的最短距离。如果基数为3,则以3个节点间隔分配跳转链接。
68.并且,偏移量(offset)为当前节点的位置n除以基数的值的余数,即n%基数。
69.并且,从当前节点的位置n到跳转链接的距离(dist)可以通过基数
偏移量
(base
offset
)值计算。
70.图5例示基数为3且偏移量为1的跳转链接。
71.参照图5,跳转链接的距离为基数
偏移量
,即31等于3。
72.观察节点r4可以看出,r4的值可通过将t4的哈希值、前一个哈希值r3以及跳转链接r1求和后进行散列来得到。
73.图6例示了基数为3且偏移量为2的跳转链接。
74.图6中可以看出跳转链接的距离为32等于9。
75.但是,无需向偏移量为2的所有节点分配跳转链接。如图7所示,在节点位置n中可以只向偏移量 (基数
偏移量
)*k的节点进行分配。其中,k为正整数。除以上节点外的节点可以不分配跳转链接。
76.如图7所示,若基数为1且偏移量为1,则为1 31*k,因而r
19
、r
13
、r
10
、r7、r4、r1分配到跳转链接。并且若基数为3且偏移量为2,则为2 32*k,因而r
20
、r
11
、r2分配到跳转链接。如果基数为3且偏移量为3,则r
57
、r
30
、r3将分配到跳转链接。
77.图8示出完成图7的跳转链接分配的状态。表示反复执行跳转链接的分配直到每个偏移量达到基数。
78.另一方面,块的验证可以通过如下方式执行。
79.在h-偏斜梅克尔树中具有根哈希值r
x
,并且可以访问某个中间哈希值的情况下,为了验证数据块ty或者其父节点ry是否包含在h-偏斜梅克尔树,需进行以下步骤。
80.步骤1):从最新的根哈希值到过去时间点方向的适当距离(例如,基数)的链接(节点)为基准,检索与ry相同或在未来的过去最早的跳转链接或者普通链接。
81.步骤2):从检索到的过去的跳转链接或者普通链接的哈希值重新到过去时间点方向的适当距离(例如,基数)的链接(节点)为基准,检索与ry相同或在未来的过去最早的跳转链接或者普通链接。重复此过程至达到ry。
82.步骤3):利用ty,对以上检索到的链接的集合依次计算朝未来方向的根哈希。若最终计算结果与r
head
相同,则验证完成,从而验证存在于h-偏斜梅克尔树中。
83.图9例示从r
59
开始检索r8以验证t8。
84.参照图9,r
head
为r
59
,参照r
59
中适当的距离,即相当于基数3的距离的链接(节点)r
58
、r
57
值,检索并查询从r
57
到偏移量3的距离,即33的跳转链接中相比r8在未来的过去最早的链接r
30
。
85.其中,重新查询适当的距离,即相当于基数3的距离的链接(节点)r
29
。重新检查并查询从r
29
到偏移量2的距离,即32的跳转链接r
20
以及跳转链接r
20
的跳转链接r
11
。在以r
29
为基准的偏移量2的跳转链接中,跳转链接r
11
成为相比r8在未来的过去最早的链接。
86.并且,在r
11
中重新分别检索适当距离内的链接r
10
、r9、r8,最终达到r8。
87.并且,利用以上验证对象t8,重新朝未来方向依次计算出根哈希值。若最终计算出的根哈希值与h-偏斜梅克尔树上的r
59
一致,则验证t8存在于h-偏斜梅克尔树中。
88.在此过程中,从r8到r9、r
10
、r
11
、r
20
、r
29
、r
30
、r
57
、r
58
、r
59
总共需要9次运算步骤。然而,在不利用跳转链接的情况下,需要运算从r8到r
59
的所有节点,因此总共需要51次运算步骤。可以看出运算步骤明显减少,随着总账的大小增加,可以减少大量的运算量以及运算时间。
89.图10作为实际实现示例,示出基数为10的h-偏斜梅克尔树。跳转链接为10
偏移量
,因此跳转链接的距离以10、102、103增加,当距离为1999时,可以只通过28次步骤到达。
90.如上所述,总账可验证修剪系统可以只通过哈希值就可以完美验证数据,而无需直接拥有所有数据块,因此可以大幅减少数据的存储量。随着时间的推移,总账的大小也会急剧增加,因此迫切需要利用跳转链接的检索以及运算。
91.在上文中参照实施例进行了说明,但本领域普通技术人员可以理解,可在不脱离下述发明要求范围中所记载的本发明的精神及领域的范围内,对本发明实施各种修改及更改。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。