1.本发明涉及虚拟现实技术领域,更具体地,涉及一种基于衣服块指引及空间自适应网络的虚拟试穿方法及系统。
背景技术:
2.随着互联网、城市物流系统的高速发展和全面普及,电子商务给消费者的生活带来极大的便利,其中,线上服装销售既能给消费者提供各式各样的购买选择,又能减少购物所需的时间成本。但线上服装销售也存在不足之处,即无法为消费者提供实际的试穿体验。虚拟试穿技术通过计算机等设备,采集人体和衣服的信息,进而虚拟地将人体与衣服进行融合,最后再将融合结果作为输出,这给用户提供一种虚拟的试穿体验,大大提升了消费者线上购物的体验。因此,无论是在学术界还是工业界,虚拟试穿一直是热门的研究方向。
3.早期的虚拟试穿技术主要依赖于计算机图形学,这类方法需要单独建模3d人体模型和3d衣服模型,再将3d衣服渲染到3d人体上。由于计算机图形学能够精准建模3d模型的几何图形,通常这类方法在各种场景下(不同人体体型、姿态,不同衣服类别)都可以渲染出比较合理的试穿结果。但这类方法也存在明显的不足,首先3d人体模型的建模一般需要借助一些昂贵的设备进行人体信息的采集、重建。其次,对于3d衣服模型,一般需要美工设计师精心设计才能得到,消费者也只能对那些已经提前设计好的3d衣服进行试穿。因此,基于计算机图形学的虚拟试穿方法不仅需要依赖于昂贵的硬件设备,而且无法泛化到不同的衣服,很难在实际生活中推广使用。
4.近年来,得益于生成模型,特别是基于数据驱动的生成对抗网络(generative adversarial network)的快速发展,越来越多的研究人员开始研究基于计算机视觉的虚拟试穿技术。此类方法通常是在二维图像层面对人体和衣服进行操作。具体来说,给定一张目标人体图像和一张衣服图像,此类方法先将衣服变形为能够和人体姿态、体型相适应的形状,再将变形衣服和人体进行融合以得到虚拟试穿结果。经过近几年的技术积累,基于计算机视觉的图像虚拟试穿技术在大多数场景下能够生成效果逼真的试穿结果,但仍存在一定的局限性。目前大多数方法的实现效果是将一张平铺衣服图像试穿到一张给定的人体图像上。此类方法不足的地方主要有两点。首先,此类方法的模型在训练过程中,需要使用配对的图像作为训练数据,即平铺衣服图像-人体图像,其中人体图像中人物的衣服和平铺衣服图像中的衣服相同。但这种配对数据的采集是比较困难的,需要以一种统一的标准拍摄平铺衣服图像,同时拍摄穿着对应衣服的模特图像。其次,此类方法在实际应用过程中,对输入的数据同样有着比较苛刻的要求,即需要同时给模型提供一张标准的平铺衣服图像和人体图像,无法直接根据两张人体图像实现人物衣服互换。虽然目前存在一些工作针对人体衣服互换这个任务提出了相应的解决方案,但这些方案也会存在影响大规模拓展的因素。比如,有一类方法在训练人体衣服互换模型时,使用了配对的人体图像对(同一个人穿同一件衣服,以不同姿态展示),同样,使用这样的配对数据也会面临采集困难的问题。还有一类方法,在训练过程中使用非配对的人体图像数据,但模型在测试阶段,需要针对某个测试样
例,在线优化模型参数,才能保证生成的试穿结果有清晰的纹理细节,这也会影响方法在实际使用过程中的效率。
技术实现要素:
5.本发明提供一种基于衣服块指引及空间自适应网络的虚拟试穿方法,该方法实现一种在训练阶段无需匹配数据、测试阶段无需在线优化、在保留衣服纹理等细节的基础上实现不同类别衣服互换的虚拟试穿方法。
6.本发明的又一目的在于提供一种应用该基于衣服块指引及空间自适应网络的虚拟试穿方法的系统。
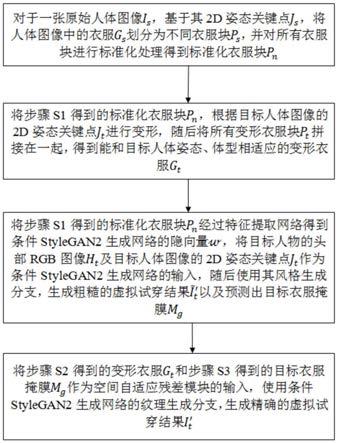
7.为了达到上述技术效果,本发明的技术方案如下:
8.一种基于衣服块指引及空间自适应网络的虚拟试穿方法,包括以下步骤:
9.s1:对于一张原始人体图像is,基于其2d姿态关键点js,将人体图像中的衣服gs划分为不同衣服块ps,并对所有衣服块进行标准化处理得到标准化衣服块pn;
10.s2:将步骤s1得到的标准化衣服块pn,根据目标人体图像的2d姿态关键点j
t
进行变形,随后将所有变形衣服块p
t
拼接在一起,得到能和目标人体姿态、体型相适应的变形衣服g
t
;
11.s3:将步骤s1得到的标准化衣服块pn经过特征提取网络得到条件stylegan2生成网络的隐向量将目标人物的头部rgb图像h
t
及目标人体图像的2d姿态关键点j
t
作为条件stylegan2生成网络的输入,随后使用其风格生成分支,生成粗糙的虚拟试穿结果以及预测出目标衣服掩膜mg;
12.s4:将步骤s2得到的变形衣服g
t
和步骤s3得到的目标衣服掩膜mg作为空间自适应残差模块的输入,使用条件stylegan2生成网络的纹理生成分支,生成精确的虚拟试穿结果i
′
t
。
13.进一步地,所述步骤s1的具体过程是:
14.s11:使用人体姿态估计器,获得原始人体图像is的18个2d姿态关键点js;
15.s12:使用人体语义分割解析器,获得原始人体图像is的人体语义分割图,该分割图上不同区域对应人体的不同部位,并根据原始人体图像is及其语义分割图,获取衣服图像gs;
16.s13:根据步骤s11得到的原始人体2d姿态关键点js将步骤s12得到的衣服图像gs划分为与人体区域相关联的8个衣服块ps,相关联的人体区域依次为:左下手臂、左上手臂、右下手臂、右上手臂、上半身躯干,颈部、左臀部,右臀部;
17.s14:将步骤s13得到的所有大小不同、朝向不同的衣服块ps,通过透视变换统一标准化为具有相同大小、相同朝向的标准化衣服块pn。
18.进一步地,所述步骤s2的具体过程是:
19.s21:使用人体姿态估计器,获得目标人体图像i
t
的18个2d姿态关键点j
t
;
20.s22:根据步骤s21得到的目标2d姿态关键点j
t
,通过透视变换,将步骤s14得到的所有标准化衣服块pn,变换为目标形状下的衣服块p
t
;
21.s23:将步骤s22得到的所有变形衣服块p
t
拼接在一起的到能与目标人体姿态、体型相适应的变形衣服g
t
。
22.进一步地,所述步骤s3的具体过程是:
23.s31:将步骤s14得到的标准化衣服块pn按通道进行拼接,依次经过一个风格编码器网络和一个特征映射网络,得到编码了衣服颜色、形状信息的特征向量,该特征向量充当条件stylegan2生成网络的隐向量
24.s32:使用人体语义分割解析器,获得目标人体图像i
t
的人体语义分割图,该分割图上不同区域对应人体的不同部位,并根据目标人体图像i
t
及其语义分割图,目标人物的头部rgb图像h
t
;
25.s33:将步骤s21得到的目标2d姿态关键点j
t
转换为rgb人体骨骼形式,并与步骤s32得到的标人物的头部rgb图像h
t
按通道进行拼接,输进一个身份编码器,得到了编码目标人体姿态、身份信息的特征图f
id
;
26.s34:将步骤s33得到特征图f
id
作为条件stylegan2生成网络的输入,同时使用步骤s31得到的隐向量修改条件stylegan2每一个子生成模块的卷积核参数;
27.s35:在条件stylegan2生成网络中分辨率为128*128的子生成模块之后,使用风格生成分支,分别生成粗糙的虚拟试穿结果以及预测出目标衣服掩膜mg。
28.进一步地,所述步骤s4的具体过程是:
29.s41:去除变形衣服g
t
的外部不对齐区域,并提取变形衣服的特征,具体做法为,将步骤s35得到的目标衣服掩膜mg和步骤s23得到的变形衣服g
t
进行逐像素相乘,剔除掉g
t
中目标衣服掩膜mg之外的区域,并将得到的变形衣服输进一个衣服编码器,得到衣服变形衣服特征图f
′g;
30.s42:根据步骤s23的到的变形衣服g
t
,得到其对应的二进制掩膜m
t
,将m
t
与步骤s35得到的目标衣服掩膜mg进行与运算,得到对齐区域的掩膜m
align
,再根据mg和m
align
,得到不对齐区域掩膜m
misalign
;
31.s43:对步骤s41得到的变形衣服特征f
′g中,内部不对齐区域,进行特征填充操作,具体做法为,使用步骤s42得到的对齐区域掩膜,提取f
′g中对齐区域的特征并计算平均值,随后使用平均特征填充f
′g的不对齐区域;
32.s44:在条件stylegan2生成网络中分辨率为128*128的子生成模块之后,引入空间自适应残差模块,将步骤s402得到的变形衣服特征fg,经过不同卷积层,分别计算出空间残差模块中反归一化层中缩放因子γ和平移因子β;
33.s45:在条件stylegan2生成网络纹理生成分支的空间自适应残差模块之后,加入一个分辨率为256*256的子生成模块,生成精确的虚拟试穿结果i
′
t
。
34.进一步地,所述步骤s41形式化表示为以下数学公式:
35.f
′g=εg(g
t
⊙
mg),
36.其中,εg表示衣服编码器;
37.所述步骤s42形式化表示为以下数学公式:
38.m
align
=mg∩m
t
,
39.m
misalign
=m
g-m
align
。
40.所述步骤s43形式化表示为以下数学公式:
41.42.其中,表示计算特征在空间维度上的平均值。
43.进一步地,所述步骤s44引入的空间自适应残差模块的具体操作可以形式化表示为以下数学公式:
[0044][0045]
其中,γ
z,y,x
(
·
)和β
z,y,x
(
·
)分别代表计算缩放因子γ和平移因子β的卷积操作,h
z,y,x
代表输进残差模块的特征图中某个位置的值,z代表特征图通道维度上某一位置,y代码特征图高度维度上的某一位置,x代表特征图宽度维度上的某一位置,μz代表特征图某一通道上特征的平均值,σz代表特征图中某一通道上特征的方差。
[0046]
进一步地,在训练阶段,通过计算生成的试穿结果(粗糙虚拟试穿结果和精确虚拟试穿结果i
′
t
)与真实图像is的重构损失和感知损失来约束系统模型的学习,具体公式为:
[0047][0048]
进一步地,在训练阶段,引入预测出目标衣服掩膜mg和真实目标衣服掩膜m
gt
的损失,来约束系统模型的学习,具体公式为:
[0049][0050]
在训练阶段,针对生成的试穿结果(粗糙虚拟试穿结果和精确虚拟试穿结果i
′
t
),还使用对抗损失来约束系统模型的学习,训练阶段的总损失函数形式化表示为以下数学公式:
[0051][0052]
其中,λ
rec
、λ
perc
、取值依次为40,40,100。
[0053]
一种应用基于衣服块指引及空间自适应网络的虚拟试穿方法的系统,包括以下模块:
[0054]
原始衣服分解、标准化模块:用于对于一张原始人体图像is,基于其2d姿态关键点js,将人体图像中的衣服gs划分为不同衣服块ps,并对所有衣服块进行标准化处理得到标准化衣服块pn;
[0055]
衣服变形模块:用于将步骤s1得到的标准化衣服块pn,根据目标人体图像的2d姿态关键点j
t
进行变形,随后将所有变形衣服块p
t
拼接在一起,得到能和目标人体姿态、体型相适应的变形衣服g
t
;
[0056]
粗糙试穿结果生成模块:用于将步骤s1得到的标准化衣服块pn经过特征提取网络得到条件stylegan2的隐向量将目标人物的头部rgb图像h
t
及目标人体图像的2d姿态关键点j
t
作为条件stylegan2生成网络的输入,随后使用其风格生成分支,生成粗糙的虚拟试穿结果以及预测出目标衣服掩膜mg;
[0057]
精细试穿结果生成模块:用于将步骤s2得到的变形衣服g
t
和步骤s3得到的目标衣服掩膜mg作为空间自适应残差模块的输入,使用条件stylegan2生成网络的纹理生成分支,生成精确的虚拟试穿结果i
′
t
。
[0058]
与现有技术相比,本发明技术方案的有益效果是:
[0059]
本发明基于原始人体姿态,将衣服进行分块、标准化得到标准化表示下的衣服块,再根据目标人体姿态得到变形衣服,通过条件stylegan2生成网络的风格生成分支预测出目标衣服掩膜,并使用该掩膜对粗糙的变形衣服进行修正,最后通过条件stylegan2生成网络的纹理生成分支生成准确的虚拟试穿结果,实现一种在训练阶段无需匹配数据、测试阶段无需在线优化、在保留衣服纹理等细节的基础上实现不同类别衣服互换的虚拟试穿方法。
附图说明
[0060]
图1为本发明一种基于衣服块指引及空间自适应网络的虚拟试穿方法的步骤流程图;
[0061]
图2为本发明一种基于衣服块指引及空间自适应网络的虚拟试穿系统的系统架构图;
[0062]
图3为本发明具体实施例之虚拟试穿系统的结构示意图;
[0063]
图4为本发明所采集的数据集示例图及其数据分布图;
[0064]
图5为本发明在所采集的数据集上不同场景下虚拟试穿效果示例图;
[0065]
图6为本发明和其他对比方法在upt数据集上的试穿效果对比图;
[0066]
图7为本发明和其他对比方法在deepfashion数据集上的试穿效果对比图;
[0067]
图8为本发明和其他对比方法在mpv数据集上的试穿效果对比图;
[0068]
图9为本发明消融实验中的效果对比图;
[0069]
图10为本发明和其他方法在upt数据集和deepfashion数据集上定量指标对比图;
[0070]
图11为本发明和其他方法在mpv数据集上定量指标对比图;
[0071]
图12为本发明消融实验中定量指标对比。
具体实施方式
[0072]
附图仅用于示例性说明,不能理解为对本专利的限制;
[0073]
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
[0074]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0075]
下面结合附图和实施例对本发明的技术方案做进一步的说明。
[0076]
如图1所示,一种基于衣服块指引及空间自适应网络的虚拟试穿方法,包括如下步骤:
[0077]
步骤s1,对于一张原始人体图像is,基于其2d姿态关键点js,将人体图像中的衣服gs划分为不同衣服块ps,并对所有衣服块进行标准化处理得到标准化衣服块pn。
[0078]
具体地,步骤s1进一步包括:
[0079]
步骤s100,使用人体姿态估计器,获得原始人体图像is的18个2d姿态关键点js。
[0080]
步骤s101,使用人体语义分割解析器,获得原始人体图像is的人体语义分割图,该分割图上不同区域对应人体的不同部位,并根据原始人体图像is及其语义分割图,获取衣
服图像gs。
[0081]
具体地,步骤s101进一步包括:
[0082]
步骤s101a,给定一张原始人体图像is,使用人体语义分割解析器,获得一张类别数为20的人体语义分割图,分割图上不同标签对应人体的不同部位。
[0083]
步骤s101b,将原始人体语义分割图中属于上衣的区域的值置1,其余区域置0,得到一张衣服掩膜。
[0084]
步骤s101c,结合原始人体图像is和衣服掩膜,获取衣服图像gs。
[0085]
步骤s102,根据步骤s100得到的原始人体2d姿态关键点js将步骤s101得到的衣服图像gs划分为与人体区域相关联的8个衣服块ps,相关联的人体区域依次为:左下手臂、左上手臂、右下手臂、右上手臂、上半身躯干,颈部、左臀部,右臀部。
[0086]
步骤s103,将步骤s102得到的所有大小不同、朝向不同的衣服块ps,通过透视变换统一标准化为具有相同大小、相同朝向的标准化衣服块pn。
[0087]
具体地,步骤s103进一步包括:
[0088]
步骤s103a,定义一个分辨率为64*64的标准衣服块模版针对由步骤s102得到的每一个衣服块根据的四边形顶点和的四边形顶点,使用opencv自带api,计算出将变换为所需的透视变换矩阵。
[0089]
步骤s103b,使用步骤s103a得到的透视变换矩阵,将变换到标准衣服块
[0090]
步骤s2,将步骤s1得到的标准化衣服块pn,根据目标人体图像的2d姿态关键点j
t
进行变形,随后将所有变形衣服块p
t
拼接在一起,得到能和目标人体姿态、体型相适应的变形衣服g
t
;
[0091]
具体地,步骤s2进一步包括:
[0092]
步骤s200,使用人体姿态估计器,获得目标人体图像i
t
的18个2d姿态关键点j
t
;
[0093]
步骤s201,根据步骤s200得到的目标2d姿态关键点j
t
,通过透视变换,将步骤s103得到的所有标准化衣服块pn,变换为目标形状下的衣服块p
t
;
[0094]
具体地,步骤s201进一步包括:
[0095]
步骤s201a,根据目标2d姿态关键点j
t
,得到每一个目标衣服块p
ti
在目标图像中的具体位置。
[0096]
步骤s201b,根据标准衣服块的四边形顶点和目标衣服块的四边形顶,使用opencv自带api,计算出将变换为所需的透视变换矩阵。
[0097]
步骤s201c,使用步骤s201b得到的透视变换矩阵,将变换到标准衣服块
[0098]
步骤s202,将步骤s201得到的所有变形衣服块p
t
拼接在一起的到能与目标人体姿态、体型相适应的变形衣服g
t
。
[0099]
在本发明具体实施例中,步骤s1和步骤s2中,所述人体姿态估计器使用文章“realtime multiperson 2d pose estimation using part affinity fields”所提出的方法,所述人体语义分割解析器则可以使用文章“graphonomy:universal human parsing via graph transfer learning”所提出的方法,所使用的opencv api为cv2.getperspectivetransform()和cv2.warpperspective(),在此不予赘述。
adversarial networks with limited data”所提的结构和方法,在此不予赘述。
[0115]
步骤s4,将步骤s2得到的变形衣服g
t
和步骤s3得到的目标衣服掩膜mg作为空间自适应残差模块的输入,使用条件stylegan2生成网络的纹理生成分支,生成精确的虚拟试穿结果i
′
t
。
[0116]
具体地,步骤s4进一步包括:
[0117]
步骤s400,去除变形衣服g
t
的外部不对齐区域,并提取变形衣服的特征,具体做法为,将步骤s304得到的目标衣服掩膜mg和步骤s202得到的变形衣服g
t
进行逐像素相乘,剔除掉g
t
中目标衣服掩膜mg之外的区域,并将得到的变形衣服输进一个衣服编码器,得到衣服变形衣服特征图f
′g。
[0118]
具体地,步骤s400可以形式化表示为以下数学公式:
[0119]f′g=εg(g
t
⊙
mg),
[0120]
其中,εg表示衣服编码器。
[0121]
在本发明具体实施例中,衣服编码器εg由1个卷积层和2个残差层构成。其中,卷积层由1个卷积核大小为7*7、卷积核个数为64的卷积函数和relu激活函数构成。第1个残差层由1个残差块以及relu激活函数构成,在残差块中,卷积函数的卷积核大小为4*4、步长为1、卷积核个数为64。第2个残差层由1个残差块以及relu激活函数构成,在残差块中,卷积函数的卷积核大小为4*4、步长为2、卷积核个数为128。
[0122]
步骤s401,根据步骤s202的到的变形衣服g
t
,得到其对应的二进制掩膜m
t
,将m
t
与步骤s304得到的目标衣服掩膜mg进行与运算,得到对齐区域的掩膜m
align
,再根据mg和m
align
,得到不对齐区域掩膜m
misalign
,
[0123]
具体地,步骤s401可以形式化表示为以下数学公式:
[0124]malign
=mg∩m
t
,
[0125]mmisalign
=m
g-m
align
;
[0126]
步骤s402,对步骤s400得到的变形衣服特征f
′g中,内部不对齐区域,进行特征填充操作,具体做法为,使用步骤s401得到的对齐区域掩膜,提取f
′g中对齐区域的特征并计算平均值,随后使用平均特征填充f
gμ
的不对齐区域。
[0127]
具体地,步骤s402可以形式化表示为以下数学公式:
[0128][0129]
其中,表示计算特征在空间维度上的平均值;
[0130]
步骤s403,在条件stylegan2生成网络中分辨率为128*128的子生成模块之后,引入空间自适应残差模块,将步骤s402得到的变形衣服特征fg,经过不同卷积层,分别计算出空间残差模块中反归一化层中缩放因子γ和平移因子β。
[0131]
具体地,步骤s403引入的空间自适应残差模块的具体操作可以形式化表示为以下数学公式:
[0132][0133]
其中,γ
z,y,x
(
·
)和β
z,y,x
(
·
)分别代表计算缩放因子γ和平移因子β的卷积操作,h
z,y,x
代表输进残差模块的特征图中某个位置的值(z代表特征图通道维度上某一位置,y代
码特征图高度维度上的某一位置,x代表特征图宽度维度上的某一位置),μz代表特征图某一通道上特征的平均值,σz代表特征图中某一通道上特征的方差。
[0134]
在本发明具体实施例中,空间自适应残差模块包括3个残差子模块。每个残差子模块接收两个输入(前一个条件stylegan2生成网络子生成模块或前一个残差子模块的输出h、变形衣服特征fg),残差子模块的结构使用文章“semantic image synthesis with spatially-adaptive normalization”所提结构,在此不予赘述。
[0135]
步骤s404,在条件stylegan2生成网络纹理生成分支的空间自适应残差模块之后,加入一个分辨率为256*256的子生成模块,生成精确的虚拟试穿结果i
′
t
。
[0136]
在本发明具体实施例中,条件stylegan2生成网络的网络结构的子生成模块使用文章“training generative adversarial networks with limited data”所提的结构,在此不予赘述。
[0137]
在本发明系统模型的训练阶段,通过计算生成的试穿结果(粗糙虚拟试穿结果和精确虚拟试穿结果i
′
t
)与真实图像is的重构损失和感知损失来约束系统模型的学习。具体公式为:
[0138][0139][0140]
其中φk(i)表示图像i经过vgg19网络第k层得到的特征图。具体来说k依次代表了vgg19的’conv1_2’,’conv2_2’,’conv3_2’,’conv4_2’和’conv5_2’。
[0141]
在本发明系统模型的训练阶段,引入预测出目标衣服掩膜mg和真实目标衣服掩膜m
gt
的损失,来约束系统模型的学习。具体公式为:
[0142][0143]
在本发明系统模型的训练阶段,针对生成的试穿结果(粗糙虚拟试穿结果和精确虚拟试穿结果i
′
t
),还使用对抗损失来约束系统模型的学习。训练阶段的总损失函数形式化表示为以下数学公式:
[0144][0145]
其中λ
rec
、λ
perc
、取值依次为40,40,100。
[0146]
在本发明具体实施例中,使用文章“training generative adversarial networks with limited data”所提的对抗损失函数,在此不予赘述。
[0147]
如图2-3所示,本发明还提供一种基于衣服块指引及空间自适应网络的虚拟试穿方法,包括如下不同模块:
[0148]
原始衣服分解、标准化模块,对于一张原始人体图像is,基于其2d姿态关键点js,将人体图像中的衣服gs划分为不同衣服块ps,并对所有衣服块进行标准化处理得到标准化衣服块pn;
[0149]
衣服变形模块,将步骤s1得到的标准化衣服块pn,根据目标人体图像的2d姿态关键点j
t
进行变形,随后将所有变形衣服块p
t
拼接在一起,得到能和目标人体姿态、体型相适应的变形衣服g
t
;
[0150]
粗糙试穿结果生成模块,将步骤s1得到的标准化衣服块pn经过特征提取网络得到条件stylegan2的隐向量将目标人物的头部rgb图像h
t
及目标人体图像的2d姿态关键点j
t
作为条件stylegan2生成网络的输入,随后使用其风格生成分支,生成粗糙的虚拟试穿结果以及预测出目标衣服掩膜mg;
[0151]
精细试穿结果生成模块,将步骤s2得到的变形衣服g
t
和步骤s3得到的目标衣服掩膜mg作为空间自适应残差模块的输入,使用条件stylegan2生成网络的纹理生成分支,生成精确的虚拟试穿结果i
′
t
。
[0152]
具体实验过程:
[0153]
在本发明实施例中,我们从互联网上采集了一批针对非配对数据下虚拟试穿任务的模特图像,命名为upt数据集。upt数据集包含33254张半身正面/全身正面的模特图像,其中模特的服装涵盖各式各样的类别,包括长/短t恤、衬衫、背心、长裤、短裤、裙子等。upt数据集被进一步划分为训练集和测试集,分别包含27139、6615张模特图像。在本发明方法训练阶段,由于没有配对数据可以使用,原始人体图像和目标人体图像为同一图像;在测试阶段,为达到换装目的,原始人体图像和目标人体图像为不同图像。此外,我们从现有的虚拟试穿数据集中,即deepfashion数据集和mpv数据集,挑选正面模特图像作为upt数据集的补集,以说明本发明所提出方法在不同数据集上的表现。图4展示了upt数据集的部分样例,可以观察到,upt数据集中模特图像涵盖了不同模特性别、模特姿态、衣服类别。同时,图4也展示了upt数据集、deepfashion数据集以及mpv数据集半身和全身数据的分布差异。图5展示了本发明方法在upt数据集上的测试效果,第一行展示的是上半身虚拟试穿的效果,第二行展示的是下半身虚拟试穿的效果,第三行展示的是全身虚拟试穿的效果。观察图5可知,本发明方法在不同场景(上半身、下半身、全身)、不同衣服类别的试穿效果都能达到非常逼真的效果。
[0154]
为了说明本发明的有效性,我们选择现有3种平铺图换装虚拟试穿方法(将平铺衣服换到特定人身上)即cp-vton、acgpn、pfafn,和2种衣服互换虚拟试穿方法(实现两个人衣服互换)即adgan、liquid warping gan作为对比方法。其中针对3个平铺图换装的虚拟试穿方法,在upt数据集和deepfashion数据集上,由于这两个数据集没有对应的平铺衣服图像,在测试阶段,衣服直接根据语义分割图从目标人体图像中获取;在mpv数据集上,由于该数据集拥有平铺衣服-模特的配对数据,在测试阶段,衣服图像直接由平铺衣服提供。在一下图表中,我们将本发明所提方法简称为pasta-gan。
[0155]
下面将结合附图来说明本发明的虚拟试穿效果:
[0156]
以下将定量和定性分析本发明的虚拟试穿效果。针对定量指标,本发明使用fr
′
echet inception distance(fid)来衡量生成图片和真实图片的分布的相似程度,当fid分数越低,表示生成图像的分布与真实图像的分布越接近。此外,我们还采用问卷调查的方式,让参与的志愿者对不同方法的虚拟试穿效果进行公平评价。问卷的具体实现方式是,针对每一个数据集(upt、deepfahion、mpv)的测试集,我们都随机挑选40个测试样本,再使用不同方法进行在这40个随机测试样本上进行测试,然后邀请30位志愿者参与问卷调查,让
志愿者从生成结果中挑选出更加真实逼真、保留更多细节的试穿结果。
[0157]
图10展示了不同方法在upt数据集以及deepfashion数据集上的定量对比结果。在这两个数据集上,相比较于3种平铺图换装虚拟试穿方法(cp-vton、acgpn、pfafn)以及2种衣服互换虚拟试穿方法(adgan、liquid warping gan),本发明所提方法pasta-gan均能得到最低的fid分数,同时,根据问卷调查的统计结果,我们可以发现,大多数志愿者认为由本发明方法生成的虚拟试穿结果效果更逼真。
[0158]
图11展示了不同方法在mpv数据集上的定量对比结果。值得注意的是,在这个数据集上的测试结果,对比的平铺图换装虚拟试穿方法(cp-vton、acgpn、pfafn)采用其原来的设置进行测试,即将平铺衣服换到指定人身上,而本发明所提方法pasta-gan的设置则是实现两人衣服互换。由图11数据可发现,在这种对平铺图换装虚拟试穿方法来说更公平的设置下,本发明所提方法pasta-gan均能得到最低的fid分数及最好的问卷调查分数。
[0159]
图6、图7和图8分别展示了不同方法在upt数据集、deepfashion数据集以及mpv数据集上虚拟试穿效果对比。观察对比图可以发现,在不同的测试置下,本发明所提方法在保证试穿结果完整性、保证衣服外行正确性以及衣服纹理的保留上都有更好的效果。
[0160]
为了验证本发明所设计的试穿模块的有效性,本发明设计了4组消融实验。即pasta-gan
★
、pasta-gan*、其中,pasta-gan
★
、pasta-gan*均不使用条件stylegan2生成网络的纹理生成分支,pasta-gan
★
直接将完整衣服作为风格编码器的输入,而pasta-gan*将标准化衣服块作为作为风格编码器的输入。都使用了条件stylegan2生成网络的纹理生成分支,其中使用条件stylegan2生成网络的风格生成分支,即不使用预测的衣服掩膜对变形衣服进行修正,而使用普通的残差模块替换掉空间自适应残差模块。
[0161]
图12展示了本发明所提方法和不同消融方法间fid分数对比。由图12可发现,相比较于消融方法,本发明方法生成的试穿结果的fid分数最低。由此说明,对衣服分块及标准化处理、使用预测的衣服掩膜对变形衣服进行修正以及引入空间自适应残差模块都对最终虚拟试穿效果的真实性有帮助。
[0162]
图9展示了本发明所提方法和不同消融方法虚拟试穿效果对比。观察对比图可以发现,不使用条件stylegan2生成网络的纹理生成分支条件下,没有对衣服进行分块处理的pasta-gan
★
方法生成的试穿结果无法保证衣服外行的准确性;而对衣服进行分块处理的pasta-gan*方法则能保证衣服外行的准确性,但由于其没有使用纹理生成分支,其生成的试穿结果衣服纹理无法保留。在使用条件stylegan2生成网络的纹理生成分支条件下,由于没有使用风格生成分支,无法对变形衣服外部不对齐区域进行修正,因此,其试穿结果在衣服轮廓周围会存在瑕疵;而由于没有使用空间自适应残差模块,对变形衣服内部不对齐区域的生成存在瑕疵。
[0163]
综上所述,本发明实现了一种方法模型训练不依赖配对数据、能完成任意两个互换衣服且保留衣服外行、纹理等重要信息等虚拟试穿方法。
[0164]
1)在传统基于图像的虚拟试穿方法中(cp-vton、acgpn、pfafn),方法模型的训练需要使用配对数据(平铺衣服图像-模特图像),这加大了数据采集的难度,使方法无法高效利用互联网海量的数据作为训练数据。同时,在测试阶段,无法实现任意两个模特衣服的互
换,这也限制了方法的使用场景。本发明所提方法在训练阶段,无需使用配对数据,因此,互联网上任意的模特图像都可以作为本发明方法的模型训练数据。同时,在测试阶段,本发明也能够实现任意两个模特衣服互换,更加灵活。
[0165]
2)在现有实现衣服互换的虚拟试穿方法中(o-viton、vogue),虽然方法模型训练无需使用配对数据,但在测试阶段,往往需要在线优化,才能保证虚拟试穿结果纹理的真实性。本发明所提方法,在测试阶段,无需额外的优化,即可保证结果的纹理真实性。
[0166]
3)本方法能够实现任意两人衣服互换,也能适应到不同类别的服装,其试穿能尽可能保留衣服形状、颜色、纹理等细节,效果更逼真。
[0167]
相同或相似的标号对应相同或相似的部件;
[0168]
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。