1.本发明涉及交通技术领域,具体涉及一种分布式系统下道路车流量预测方法。
背景技术:
2.随着社会的不断发展,城市机动车保有量持续增加,城市道路堵塞问题严重,成为阻碍城市出行发展的重要问题。精确的短时交通流预测为管理者提供了数据支持,及时做出调整以缓解城市的交通压力。传统的单机预测方法在数据量大时,运行时间较长。
技术实现要素:
3.发明目的:为解决背景技术中存在的技术问题,本发明提出一种基于分布式系统的道路车流量预测方法,目的在于能够在历史数据庞大的条件下,借助分布式系统并行处理数据的方法建立预测模型来预测当天道路车流量。
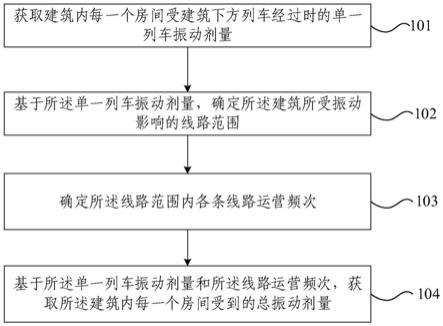
4.本发明包括以下步骤:
5.步骤1:搭建hadoop分布式环境,hadoop分布式环境包括hdfs分布式文件系统,搭建服务器的spark分布式环境;
6.步骤2:获取一条道路所有历史车辆数据以及预测当天的实时车辆数据;
7.步骤3:根据步骤2的历史车辆数据,按照小时划分,利用hadoop统计出一天中每个小时的车流量,以此作为一小时内的车流量;
8.步骤4:计算所有的历史车流量与预测当天的实时车流量的向量距离;
9.步骤5:对于步骤4中得到的数据,选取不同的k值,并且计算第一至第k个向量距离的偏差和方差,当偏差和方差最小时,得到最优的k值;
10.步骤6:根据最优的k值,选择其余天数的车流量数据,用于训练机器学习的回归模型
11.步骤7:根据最优的k值,选择k条历史车流量的数据,输入到各个回归模型,得到两组以上下一小时的预测值和相应的均方根误差值;
12.步骤8:根据步骤7得出的多组预测值和相应的均方根误差值,利用k近邻模式匹配预测当天下一小时的道路车流量。
13.步骤2中,所述历史车辆数据和预测当天的实时车辆数据,数据的结构包括记录时间和车辆识别号。
14.步骤2中,将历史车辆数据以及预测当天的实时车辆数据保存到hdfs分布式文件系统。
15.步骤3中,从hdfs分布式文件系统中读取数据,并对读取的车辆记录数据进行分布式并行处理,得到每日每小时的车流量,存入hdfs分布式文件系统,具体包括如下步骤:
16.步骤3-1:以《月-日-时,车辆编号》作为输入的键值对;
17.步骤3-2:统计所有数据中月-日-时的车辆数,输出的键值对为《月-日-时,车辆数》;
18.步骤3-3:根据每一天的时间段,将步骤3-2的键值对进行分类,统计出每天的情况,输出为《月-日,(时,车辆数)》;
19.步骤3-4:把同一天的数据整合在一起,输出为《月-日,{(时,车辆数),(时,车辆数)
…
}》。
20.步骤4中,利用了hadoop的mapreduce过程进行计算,mapreduce包括map阶段和reduce阶段,具体包括如下步骤:
21.步骤4-1,读取n天的数据sn={x
n1
,x
n2
,
…
,x
n24
}和预测当日的数据q={y1,y2,
…
,yk},其中x
ni
代表第n天i时的人数,yi代表当日i时的人数。
22.步骤4-2,分布式计算向量距离将键值对《i,si》作为map阶段的输入,将《li,i》作为map阶段的输出键值对;
23.步骤4-3,在reduce阶段,将《li,i》进行降序排序,并交换参数位置,以《i,li》输出键值对,将结果暂存到hdfs分布式文件系统。
24.步骤5中,k值为k近邻模式匹配中的系数,选取第一至第k个距离,即mi,=1,2,
…
,,分布式地计算它们的偏差和方差,具体计算步骤如下:
25.步骤5-1,读取步骤4-3的结果,分布式计算{mi|i=1,2,
…
,k}的偏差b和方差v,具体的,先生成键值对《i,(m1,m2,
…
mi)》,作为map阶段的输入,将《i,(b,v)》作为map阶段的输出
26.步骤5-2,当k值在1到n之间变化时,存在一个最优的k值,使得偏差和方差最低,选取此时的k值。
27.步骤6中,所述各个回归模型包括分布式系统上的线性回归模型、决策树回归模型、随机森林回归模型、梯度提升树回归模型,这些模型由spark上的machine learning library(mllib)提供,训练各个回归模型的步骤包括:
28.步骤6-1,将历史前k小时的数据作为特征值,第k 1小时的数据作为目标值;
29.步骤6-2,将历史前k小时的数据进行归一化操作;
30.步骤6-3,利用k折交叉验证法训练各个回归模型;
31.步骤6-4,计算每个回归模型的均方根误差值rmsei。
32.步骤7包括:将预测当日的数据输入各个回归模型,得到两组以上预测值χ
in
,i=1,2,3,4,n=1,2,
…
k,χ
in
表示第i个回归模型对应第n条数据的预测值,i取值为1、2、3、4时分别对应线性回归模型、决策树回归模型、随机森林回归模型、梯度提升树回归模型。
33.步骤8包括:
34.步骤8-1,利用公式计算回归模型根据均方根误差值加权而得出的历史k天中k 1时的车流量预测,hn表示第n条数据对应当天的k 1时车流量预测;
35.步骤8-2,考虑到历史车流量与实时数据的相关性,引入谷本tanimoto系数改进knn的向量距离公式,改进后的向量距离为λn=n*n,其中谷本tanimoto系数
36.步骤8-3,利用公式计算当天k 1时的车流量预测结果,y即当天k 1时的车流量预测结果。
37.本发明具有以下优点及有益效果:在分布式系统上并行处理庞大的数据,将数据分散到不同的节点上,使它们同时在不同节点上运行,从而加快计算速度。在k近邻匹配中融合了多种机器学习回归模型,有效地利用了所有历史数据来预测下一小时的道路车流量情况,并且模型准确率较高。
附图说明
38.下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
39.图1所示为本发明的方法实施步骤图。
40.图2所示为本发明的分布式系统结构图。
41.图3所示为本发明的具体实施流程图。
具体实施方式
42.实施例
43.如图1、图2、图3所示,本实施例提供了一种基于分布式系统的道路车流量预测方法,hadoop及其常用组件集群安装,具体包括:
44.一、用vmware虚拟3台服务器,搭建hadoop分布式环境环境。
45.二、在hadoop分布式环境环境的基础上,搭建3台服务器的spark分布式环境环境。
46.获取一条道路的一年内的历史车辆数据以及预测当天的实时车辆数据,格式为(月-日-时,车辆编号)。10月9日历史车辆数据如表1所示:
47.表1
48.时间车辆编号10-9-11c5h4431g10-9-11b38k96s8
…………
10-9-12df3154f310-9-12l63m1f9t
…………
49.10月21日截至12时的实时车辆数据例如表2所示:
50.表2
51.时间车辆编号10-21-11p88o9r6t10-21-11t1r6ddf3
…………
10-21-128a9jr6x210-21-125j6sw9er
52.利用hadoop fs-put命令上传历史车辆数据以及预测当天的实时车辆数据,保存到hdfs分布式文件系统。
53.搭建linux下eclipse开发环境,配置好hadoop插件,导入org.apache.hadoop.fs包,以支持打开文件、读写文件、删除文件等。
54.利用filesystem.open(path f)从hdfs分布式文件系统中打开文件读取数据,并对读取的海量车辆数据进行分布式并行处理,得到历史数据中每一天每小时的车流量,并且计算所有的历史车流量与预测当天的实时车流量的向量距离,具体处理如下:
55.一、以《月-日-时,车辆编号》作为输入的键值对。
56.二、在reduce函数中,统计所有数据中“月-日-时”的车辆数,输出的键值对为《月-日-时,车辆数》。
57.三、在map函数中,根据每一天的时间段,将上一步的键值对进行分类,统计出每天的情况,输出为《月-日,(时,车辆数)》。
58.四、在reduce函数中,将上一步的键值对进行处理,把同一天的数据整合在一起,输出为《月-日,{(时,车辆数),(时,车辆数)
…
}》。例如10月9日的数据如表3所示:
59.表3
60.小时车辆数53626305744886279536
…………
61.五、将上一步的键值对作为map阶段的输入,计算其与当日的键值对数据的向量距离将《月-日,向量距离》作为map阶段的输出。
62.六、在reduce阶段,对以上结果进行降序排序,将结果暂存到hdfs分布式文件系统。例如下表4,与10月21日截至12时的实时车辆数据向量距离最近的是5月26日,为53;其次是5月12日,向量距离为55,以及7月13日,向量距离58。
63.表4
64.日期向量距离5-26535-12557-1358
…………
65.在spark-shell命令行环境中,利用sc.textfile函数读取《月-日,向量距离》文件。
66.当k值在1到n之间变化时,计算前k个数据的偏差和方差,找到最优的k值,使得偏差和方差最低,这里取k为3。
67.使用spark上的machine learning library(mllib)构建线性回归、决策树回归、
随机森林回归、梯度提升树回归模型。训练以及预测步骤如下:
68.步骤1:用spark.createdataframe读取历史数据中每一天每小时的刷卡数量文件,将每日的前k小时的数据作为特征值,第k小时的数据作为目标值。
69.步骤2:用mllib中的normalizer将数据进行归一化操作。
70.步骤3:用mllib中的crossvalidator进行k折交叉验证法,以训练每个模型。
71.步骤4:用mllib中的regressionevaluator计算每个模型的均方根误差值rmsei。
72.将k条历史数据输入各个模型,即使用mllib中的model.transform函数,得到多组预测值χ
in
,i=1,2,3,4,n=1,2,
…
k,i表示各种模型,n表示对应k条数据。以第一条历史数据,即5月26日的数据为例,其13时的预测结果如下表5所示:
73.表5
74.模型预测值rmse线性回归1324.288.9决策树回归1485.6312.7随机森林回归1347.715.6梯度提升树1262.296.3
75.利用公式计算多个机器学习回归模型根据均方根误差值加权而得出的历史k天中k 1时的车流量预测,hn表示第n条数据对应当天的k 1时车流量预测。以第一条历史数据,即5月26日的数据为例,h1=1337.62。
76.考虑到历史车流量与实时数据的相关性,引入谷本(tanimoto)系数改进knn的向量距离公式,改进后的向量距离为λn=tn*mn,其中tanimoto系数,其中tanimoto系数
77.利用公式计算当天k 1时的车流量预测结果,y即当天k 1时的车流量预测结果,例如由下表6数据可得y=1410,即方法预测10月21日13时的车流量为1410。
78.表6
79.日期向量距离mntanimoto系数修正后的向量距离λn车流量预测值hn5-26530.9449.821337.265-12550.8948.951467.617-13580.8348.141426.90
80.本发明提供了一种分布式系统下道路车流量预测方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。