1.本发明涉及一种用于依据语音信号运行听力设备的方法,其中借助听力设备的声电输入转换器,从听力设备的周围环境接收包含语音信号的声音,并且将其转换为输入音频信号,其中借助信号处理,根据输入音频信号产生输出音频信号,输出音频信号通过电声输出转换器转换为输出声音,其中,依据语音信号设置用于根据输入音频信号产生输出音频信号的信号处理的至少一个参数。
背景技术:
2.在使用听力设备、例如助听器、头戴式耳机或通信设备时的重要的任务通常是尽可能精确地、即尤其在声学上尽可能可理解地向听力设备的用户输出语音信号。为此,通常在根据具有语音信号的声音产生的音频信号中抑制来自声音的干扰噪声,以便强调代表语音信号的信号分量,并且因此提高其可理解性。然而,通过用于噪声抑制的算法通常可能降低了所产生的输出信号的声音质量,其中,通过音频信号的信号处理尤其可能形成伪影(artefakt),和/或听觉感觉通常感觉为不太自然。
3.在大多数情况下,在此根据特征参量实施噪声抑制,特征参量首先涉及噪声或总信号、即例如信噪比(“signal-to-noise-ratio”,snr)、本底噪声水平(“noise floor”),或音频信号的电平。然而,用于控制噪声抑制的该方案最终可能导致,当虽然有明显的干扰噪声,但由于尽管存在干扰噪声却仍然很容易理解的语音分量,根本没有必要应用噪声抑制时,也应用噪声抑制。在该情况下,在没有真正必要的情况下,例如由于噪声抑制的伪影会承担声音质量恶化的风险。相反,在说话者的发音很弱的情况下(例如当说话者喃喃自语或发出类似声音时),仅与小的噪声叠加的并且就此而言使相关的音频信号具有良好的snr的语音信号也可以具有低的语音质量。
技术实现要素:
4.本发明所要解决的技术问题在于,提供一种方法,借助该方法可以依据语音信号的语音质量的尽可能客观的量度来运行听力设备。此外,本发明所要解决的技术问题是,提供一种听力设备,其被设计用于依据语音信号的语音质量运行。
5.根据本发明,第一个提到的技术问题通过用于依据语音信号运行听力设备的方法来解决,其中,借助听力设备的声电输入转换器接收来自听力设备的周围环境的包含语音信号的声音,并且将其转换为输入音频信号,其中,借助信号处理,根据输入音频信号产生输出音频信号,其中,通过借助信号处理对输入音频信号的分析定量地采集语音信号的至少一种发音和/或韵律特性,依据所述特性推导出语音信号的语音质量的定量的量度,并且其中,依据语音信号的语音质量的定量的量度设置用于根据输入音频信号产生输出音频信号的信号处理的至少一个参数。有利的和部分有创造性的设计方案是本发明和以下描述的主题。
6.根据本发明,第二个提到的技术问题通过听力设备来解决,该听力设备包括声电
输入转换器,其被设计用于接收来自听力设备的周围环境的声音并且将其转换为输入音频信号;信号处理装置,其被设计用于从输入音频信号产生输出音频信号,其中,听力设备被设计用于实施根据本发明的方法。
7.根据本发明的听力设备具有根据本发明的方法的优点,该方法尤其可以借助根据本发明的听力设备实施。针对方法和其扩展方案以下提到的优点在此根据意义可以转用至听力设备。
8.优选地,在根据本发明的方法中,输出音频信号通过电声输出转换器转换为输出声音。优选地,根据本发明的听力设备具有电声输出转换器,其被设计用于将输出音频信号转换为输出声音。
9.声电输入转换器在此尤其包括以下任何转换器,其被设计用于从周围环境的声音产生电音频信号,从而由声音引起的空气运动和气压波动在转换器的位置处通过产生的音频信号中的电气参量、尤其是电压的相应的振荡来再现。尤其地,声电输入转换器可以通过麦克风提供。相应地,电声输出转换器包括设计用于从电音频信号产生输出声音的任何转换器、即尤其是扬声器(例如平衡金属壳接收器,balanced metal case receiver),但也是骨传导耳机等。
10.尤其借助相应的信号处理装置进行信号处理,信号处理装置被设计用于借助至少一个信号处理器来实施设置用于信号处理的计算和/或算法。在此,信号处理装置尤其布置在听力设备上。然而,信号处理装置也可以布置在设计用于与听力设备连接用以交换数据的辅助设备、例如智能手机、智能手表等上。听力设备例如可以将输入音频信号传输到辅助设备,并且借助通过辅助设备提供的计算资源实施分析。最后,作为分析的结果,可以将语音质量的定量的量度传输回听力设备,并且在那里相应设置信号处理的至少一个参数。
11.分析在此可以直接在输入音频信号上实施,或根据由输入音频信号推导出的信号实施。这在此尤其可以由隔离的(isoliert)语音信号分量提供;但也可以由音频信号提供,如其例如可以在听力设备中通过反馈回路借助用于补偿声学反馈的补偿信号产生的等等;或者由根据另一输入转换器的另一输入音频信号产生的定向信号提供。
12.在此,语音信号的发音特性尤其包括共振峰、尤其是元音的精度,以及辅音、尤其是摩擦音和/或爆破音的支配度(dominanz)。在此可以说明,共振峰的精度越高或辅音的支配度和/或精度越高,那么将语音质量设置得越高。语音信号的韵律特性尤其包括语音信号的基本频率的时间稳定性和重音的相对声音强度。
13.声音产生通常包括声源的三个物理组成部分:机械振荡器、例如弦或膜,其使振荡器周围的空气处于振动中;振荡器的激励(例如通过拨动或抚摸);和共振体。通过激励使振荡器处于振荡中,从而使振荡器周围的空气通过振荡器的振动而处于压力振动中,压力振动作为声波传播。在此,在机械振荡器中大多不仅激励单一频率的振动,而且激励不同频率的振动,其中,传播的振动的频谱组成确定声波图。特定的振动的频率在此通常提供为基本频率的整数倍,并且被称为该基本频率的“谐波”或泛音(oberton)。然而,也可以构造更复杂的频谱模式,从而并非所有产生的频率都可以表示为相同的基本频率的谐波。在此,在共振空间中产生的频率的共振也与声波图有关,因为在共振空间中由振荡器产生的特定的频率通常相对于声音的主频率衰减。
14.在应用于人声时,这意味着机械振荡器通过声带及其在从肺部流过声带的空气中
的激励提供,其中,共振空间主要由咽腔和口腔形成。男性声音的基本频率通常在60hz到150hz的范围内,女性通常在150hz到300hz的范围内。由于各个人之间的、不仅关于其声带,而且尤其关于咽腔和口腔的解剖差异,首先形成不同的发声。通过由相应的下颌和嘴唇运动来改变口腔的体积和几何形状,共振空间在此可以如下地改变,即形成表征产生元音的频率、所谓的共振峰。对于各个元音,这些共振峰处于不可改变的频率范围(所谓的“共振峰范围”)中,其中,通常通过一系列的通常为四个的共振峰的前两个共振峰f1和f2以已经可清晰听到的方式将元音与其他的声音区分开(参见“元音三角形”和“元音梯形”)。在此,与基本频率、即基本振动的频率无关地形成共振峰。
15.在该意义中,共振峰的精度尤其理解为声能在彼此界定的共振峰范围上、尤其是分别在共振峰范围内的各个频率上的集中程度,和各个元音根据共振峰的由此产生的可确定性。
16.为了产生辅音,流过声带的气流在至少一个部位上被部分或完全阻塞,由此此外也形成气流的湍流,因此,仅可以使一些辅音与和元音类似清晰的共振峰结构相关联,而其他的辅音具有较宽带的频率结构。然而,也可以使辅音与特定的频带相关联,在这些频带中,声能被集中。由于辅音的冲击性的“噪声性质”,这些频带通常高于元音的共振峰范围,即主要在大约2到8khz的范围内,而元音的最重要的共振峰f1和f2的范围通常在大约1.5khz(f1)或4khz(f2)处结束。在此,辅音的精度尤其确定由声能在相应的频率范围上的集中程度和各个辅音的由此产生的可确定性来确定。
17.然而,语音信号的各个组成部分的可区分性和进而可能分辨这些组成部分的可能性不仅取决于发音方面。所述发音方面主要涉及语音、所谓的音素的最小的隔离的声音事件的声学精度,韵律方面也决定了语音质量,因为可以通过语调和重音,尤其在在几个片段、即几个音素或音素组上给一个说明赋予特别的意义,例如通过提高句子末尾的音高来澄清问题,或通过重读词语中的具体的音节来区分不同的含义(参见“umfahren”与“umfahren”)或重读一个词语来强调它。在这方面,通过例如确定声音的音调、即其基本频率的随时间的变化的量度,以及幅度最大值和/或电平最大值的对比的清晰度的量度,也可以根据韵律特性尤其如上面描述的那样定量地采集语音信号的语音质量。
18.因此,根据语音信号的一个或多个所提到的和/或另外的定量采集的发音和/或韵律特性可以推导出语音质量的定量的量度,并且可以根据该量度来控制信号处理。语音质量的定量的量度与说话者的语音生成有关,该说话者在感觉为“干净的”发言中可能具有缺陷(例如口齿不清或含糊不清),甚至语音错误,这相应降低了语音质量。
19.与语音在环境中的传播相关的参量、例如以频带方式对各个语音分量和噪声分量进行加权的语音清晰度指数(“speech intellegibility index”,sii),或借助模拟人类语音的调制的测试信号采集传输信道对调制深度的影响的语音传输指数(“speech transmission index”,sti)不同地,当前的量度在此尤其与传输信道的外部特性、例如可能有回响的空间或嘈杂的环境中的传播无关,而是优选仅与由说话者产生的语音的固有特性相关。
20.这尤其意味着,在安静的环境和/或仅具有低背景噪声的环境中,(基于参考值,该参考值优选确定用于感觉为“非常好的”语音质量)识别并且借助信号处理修正降低的语音质量。这尤其适用于以下情况,在所述情况中,实际上存在良好的snr,并且因此,不需要或
仅稍微需要通过信号处理对输入音频信号进行处理(必要时除了由测听引起的、为了补偿听力设备的用户的听力障碍相应单独调整的信号处理以外),从而通过信号处理可以有针对性地改进包含在输入音频信号中的语音信号的弱的语音质量。在此,以下控制参量中的一个或多个可以设置为至少一个参数:放大因子(宽带地或取决于频带地)、宽带或取决于频带的压缩的拐点或压缩比、自动增益控制的时间常数、噪声抑制的强度、定向信号的定向效果。
21.优选地,放大因子和/或压缩比和/或压缩的拐点和/或自动增益控制(“automatic gain control”,agc)的时间常数和/或噪声抑制的强度和/或定向信号的定向效果依据语音信号的语音质量的定量的量度设置为信号处理的至少一个参数。在此尤其地,参数也可以提供为与频率相关的参数、例如频带的放大因子、多频带压缩的与频率相关的压缩参量(压缩比、拐点、攻击或释放)、定向信号的频带式的定向参数。通过所提到的控制参量,可以尤其是在自身的低的噪声(或高snr)的情况下进一步改进不足的语音质量。
22.在此有利地,当定量的量度表明语音质量的恶化时,提高放大因子;或提高压缩比;或降低压缩的拐点;或缩短时间常数,;或减弱噪声抑制,;或提高定向效果。
23.特别地,对于由定量的量度的相应的变化(在连续或离散的情况下,朝“更好的”的二进制值或朝“更好的”值范围)表明的语音质量的改进,可以采取相反的措施,即,减小放大因子;或减小压缩比;或提高压缩的拐点;或延长时间常数;或增大噪声抑制,;或降低定向效果。
24.刚好对于通过听力设备来再现语音,通常试图输出优选在55db至75db、特别优选60db至70db的范围内的语音信号,因为在该范围以下可能会损害语音的可理解性,并且在该范围以上,声级已经被许多人感觉为不舒服,并且此外,通过进一步的放大也无法实现进一步的改进。因此,在语音质量不足时,可以将放大适度提高到实际设置用于“可正常理解的”语音信号的值以上,并且在特别好的语音质量的情况下,可以稍微降低可能非常吵的语音信号。
25.音频信号的压缩首先导致,在压缩的所谓的拐点之上,随着信号电平的增大,拐点以所谓的压缩比越来越降低。更高的压缩比在此意味着在信号电平增大时的较小的放大。拐点以上的信号电平的放大的相对减小在此通常发生在调入时间或响应时间(“攻击”)内,其中,在具有没有超过拐点的信号电平的调出时间(“释放”)之后,压缩又被取消(zur
ü
cknehmen)。
26.然而,在拐点kp以上,可以依据输入电平pin如下确定输出信号的电平pout(所有电平值均以db为单位):
27.pout(db)=[pin(db)
–
kp(db)]/r kp,
[0028]
其中,r是压缩比。2:1的压缩比因此意味着,在拐点kp以上,在输入电平增大10db时,输出电平仅增大5db。
[0029]
这种压缩通常用于获取电平峰值,并且因此能够更大程度地放大总音频信号,而不会导致电平峰值过度放大,并且因此导致音频信号失真。如果在语音质量恶化时降低压缩的拐点,或提高压缩比,这意味着有更多的储备可用于放大的在压缩后的提高,从而可以更好地强调输入音频信号的更安静的信号分量。相反,在语音质量改进的情况下,可以提高拐点,或降低压缩比(即设置为更接近线性放大),从而仅在较高的电平中或在较小的范围
中进行输入音频信号的动态的压缩,由此可以更好地保持自然的听觉感觉。
[0030]
对于agc的时间常数通常适用的是,太短的调入时间可能导致不自然的声音感知,并且因此优选避免太短的调入时间。然而,在语音质量相对较差的情况下,通过语音清晰度的改进,agc的更快的响应速度的优点可以超过声音感知的潜在的缺点。这同样适用于定向信号的定向效果:通常,强烈定向的定向信号可能会损害空间听觉,从而通过听觉感觉可能不再正确定位声源。尤其是因为这例如在街道交通中也可能与听力设备的用户的安全相关,所以通常当并且以何种程度绝对需要使用时(例如用于强调对话伙伴)才试图并且在该量度中使用定向信号。但是,如果语音质量很差,那么还可以进一步提高定向效果。在确定语音质量很差的情况下,同样可以提高诸如频谱减法等的噪声抑制,即使这没有通过snr单独要求。用于噪声抑制的方法通常仅在必要时使用,因为例如可能形成可听到的伪影。
[0031]
相反,在改进语音质量的情况下,可以延长agc的时间常数,或可以减小定向效果,因为根据假设,自然环绕声是优选的,并且针对语音清晰度借助定向麦克风附加地强调语音信号是不需要的,或者只稍微需要。非定向的噪声抑制同样可以例如借助维纳滤波器在更大的程度上使用,因为必要时语音质量的适度损害在此仍然可能被视为是可接受的。
[0032]
证实为进一步有利的是,分别检查多个频带的语音信号的信号分量,并且依据语音信号的语音质量的定量的量度,仅在确定语音信号的足够高的信号分量的频带中设置信号处理的至少一个参数。这尤其意味着,对于在其中完全没有确定语音信号的信号分量的频带或在其中语音信号的确定的信号分量低于相关阈值的频带,与确定的语音质量无关地设置信号处理的参数,并且因此尤其根据通常的标准、例如snr等对其进行评估。由此可以确保,由于语音信号及其语音质量,在实际不参与的频带中没有“共调”。
[0033]
适宜地,对于语音质量的定量的量度,作为语音信号的发音特性采集与语音信号中的元音的预设的共振峰的精度相关的特征参量;和/或与语音信号中的辅音、尤其是摩擦音和/或爆破音的支配度相关的特征参量;和/或与浊音和清音的转变的精度相关的特征参量,和/或作为语音信号的韵律特性采集与语音信号的基本频率的时间稳定性相关的特征参量;和/或与语音信号的重音的声音强度相关的特征参量。
[0034]
为了采集与语音信号中的辅音的支配度相关的特征参量,在此例如可以计算包含在低的频率范围内的第一能量,可以计算包含在低的频率范围之上的更高的频率范围内的第二能量,并且可以根据第一能量和第二能量的比和/或在提到的频率范围的相应的带宽上加权的比来形成特征参量。
[0035]
为了采集与浊音和清音的转变的精度相关的特征参量,例如可以根据相关性测量和/或根据过零率来区分浊音时间序列和清音时间序列,确定从浊音时间序列到清音时间序列或从清音时间序列到浊音时间序列的转变,针对至少一个频率范围确定在转变之前包含在浊音或清音时间序列中的能量,并且针对至少一个频率范围确定在转变之后包含在清音或浊音时间序列中的能量。随后根据转变之前的能量并且根据转变之后的能量确定特征参量。
[0036]
为了采集与语音信号中的元音的预设的共振峰的精度相关的特征参量,例如可以确定在频率空间中的至少一个共振峰范围内的语音信号的信号分量,针对至少一个共振峰范围内的语音信号的信号分量确定与电平相关的信号参量,并且根据与电平相关的信号参量的最大值和/或根据其时间稳定性确定特征参量。
[0037]
为了采集与语音信号的重音的声音强度相关的特征参量,对于语音信号例如可以以时间分辨的方式采集与音量相关的参量、例如电平等,在预设的时间段内形成与音量相关的参量的最大值与所述参量的在预设的时间段内确定的平均值的商,并且依据所述商确定特征参量,商由在预设的时间段内的与音量相关的参量的最大值和平均值形成。
[0038]
有利地,对于语音质量的定量的量度,作为语音信号的发音特性采集与辅音的发音相关的特征参量、例如与语音信号中的辅音、尤其是摩擦音和/或爆破音的支配度相关的特征参量,和/或与浊音和清音的转变的精度相关的特征参量,并且如果定量的量度表明辅音的发音不充分,那么作为至少一个参数增大至少一个表征形成辅音的频带的放大因子。这尤其意味着:在语音质量的定量的量度中,对辅音的发音进行评估。如果在此例如通过与相应的边界值比较而确定了辅音的发音相对较弱,那么可以以预设的绝对值或依据与边界值的偏差提高频率范围,在所述频率范围中集中辅音的声能(即例如2khz到10khz、优选3.5khz到8khz)。替代与边界值的比较地,定量的量度的单调函数在此也可以用于提高相关的频带。
[0039]
有利地,二进制量度被推导为定量的量度,二进制量度依据语音质量采用第一值或第二值,其中,第一值与语音信号的足够好的语音质量相关联,第二值与语音信号的不足的语音质量相关联,其中对于第一值,信号处理的至少一个参数被预先设置为对应于信号处理的常规模式的第一参数值,并且其中对于第二值,信号处理的至少一个参数被设置为与第一参数值不同的第二参数值。
[0040]
这尤其意味着:定量的量度允许将语音质量区分为两个值,其中,第一值(例如值1)对应于相对较好的语音质量,而第二值(例如值0)对应于较差的语音质量。在语音质量足够好(第一值)时,根据预先设置进行信号处理,其中,第一参数值优选与在没有依据定量采集的语音质量的信号处理中相同地使用。由此优选地,对于至少一个参数定义信号处理的常规模式、即尤其是在将不采集语音质量作为标准时会发生的信号处理。
[0041]
如果现在语音质量出现“恶化”,从而定量的量度从与更好的语音质量相关联的第一值出发采用“更差的”第二值,那么设置第二参数值,第二参数值优选被选择为,使得信号处理适用于改进语音质量。
[0042]
在此优选地,对于定量的量度从第一值到第二值的转变,至少一个参数从第一参数值连续渐变到第二参数值。由此避免了输出音频信号中的急剧的转变,急剧的转变会被感觉为是不舒服的。
[0043]
在有利的设计方案中,离散的量度被推导为语音质量的定量的量度,离散的量度依据语音质量从至少三个离散值的值范围采用一个值,定量的量度的各个值单调映射到至少一个参数的相应的离散的参数值。具有定量的量度的两个以上的值的离散值范围允许以更高的分辨率采集语音质量,并且就此可以在控制信号处理时更详细地考虑到语音质量。
[0044]
在进一步有利的、尤其替换的设计方案中,连续的量度被推导为定量的量度,该连续的量度依据语音质量从连续的值范围采用一个值,其中,定量的量度的各个值单调映射到至少一个参数的来自连续的参数区间的相应的参数值。尤其地,连续的量度包括基于连续的用于计算的算法的这种量度,其中,由于输入音频信号的数字采集和计算,应该忽略无穷小的离散化(并且尤其应该被认为是连续的)。
[0045]
对于一种量度(该量度的值是连续的),可以单调地并且尤其至少分段连续地依据
定量的量度设置至少一个参数。例如,如果语音质量的量度m采用从0(差)到1(好)的值,那么作为参数,例如放大因子g可以(与频率相关地或宽带地)依据m∈[0,1]在最大值gmax(对于m=0)和最小值gmin(对于m=1)之间连续单调变化,最大值和最小值形成参数区间[gmin,gmax]。在此尤其地,还可以为m设置边界值m
l
,在高于该边界值时,放大因子恒定地采用gmin,即例如对于m≥m
l
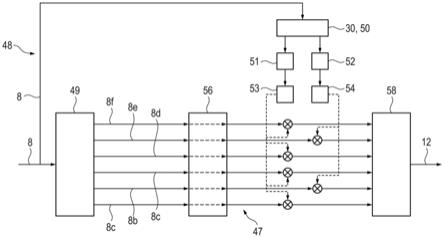
,g(m)=gmin。在这种情况下,语音质量的“恶化”被视为定量的量度m低于边界值m
l
。对于具有多于两个值的离散的值范围的定量的量度以及对于与至少一个要设置的参数不同的控制参量,类似的情况同样是适用的。
[0046]
优选探测语音活动,和/或在输入音频信号中确定snr,其中,依据语音信号的语音质量的定量的量度,附加地依据探测到的语音活动或确定的snr,设置用于根据输入音频信号产生输出音频信号的信号处理的至少一个参数。这尤其包括,如果在输入音频信号中没有探测到语音活动,和/或如果snr是太差的(即例如低于预设的边界值),那么已经可以中断对输入音频信号的关于语音信号的发音和/或韵律特性的分析,并且用于噪声抑制的相应的信号处理被视为是优先的。
[0047]
优选地,听力设备被设计为助听器。在此,助听器可以通过单耳装置或通过带有两个本地装置的双耳装置提供,本地装置由助听器的用户分别佩戴在其右耳或左耳上。除了所提到的输入转换器以外,助听器尤其还可以具有至少一个另外的声电输入转换器,其将周围环境的声音转换成相应的另外的输入音频信号,从而语音信号的至少一种发音和/或韵律特性的定量采集可以通过分析多个参与的输入音频信号来进行。在双耳装置的情况下,所使用的输入音频信号中的两个可以分别在助听器的不同的本地单元中(即分别在左耳和右耳上)产生。在此,信号处理装置尤其可以包括两个本地单元的信号处理器,其中优选地,根据所考虑的发音和/或韵律特性以适当的方式通过针对两个本地单元形成的平均值或者最大值或最小值,分别使语音质量的本地产生的量度标准化。特别地,对于双耳装置,信号处理的至少一个参数涉及双耳的运行,即例如控制定向信号的方向性。
附图说明
[0048]
随后根据附图详细阐述本发明的实施例。在此分别示意性地:
[0049]
图1以电路图示出了助听器,该助听器采集具有语音信号的声音;
[0050]
图2以框图示出了用于确定根据图1的语音信号的语音质量的定量的量度的方法;
[0051]
图3以框图示出了用于依据确定的语音质量设置根据图1的助听器的信号处理的方法;并且
[0052]
图4以线图示出了根据图3的信号处理的控制参量依赖于根据图2的语音质量的定量的量度的函数。
[0053]
彼此相应的部件和参量在所有附图中分别具有相同的附图标记。
具体实施方式
[0054]
图1以电路图示意性示出了一种听力设备1,该听力设备当前被设计为助听器2。助听器2具有声电输入转换器4,该声电输入转换器被设计用于将助听器2的周围环境的声音6转换为输入音频信号8。具有另外的输入转换器(未示出)的助听器2的设计方案在此同样是可想到的,该另外的输入转换器从周围环境的声音6产生相应的另外的输入音频信号。助听
器2当前被构造为单独的单耳装置。同样可想到的是,助听器2被设计为具有两个本地装置(未示出)的双耳助听器,本地装置由助听器2的用户分别佩戴在其右侧的和左侧的耳朵上。
[0055]
将输入音频信号8输送至助听器2的信号处理装置10,在信号处理装置中,输入音频信号8尤其根据助听器2的用户的听力要求相应被处理,并且在此例如以频带方式被放大和/或压缩。为此尤其借助相应的信号处理器(在图1中未详细示出)和可通过信号处理器寻址的主存储器来设计信号处理装置10。输入音频信号8的可能的预处理、例如产生的输入音频信号8的a/d转换和/或预放大在此应该被视为输入转换器4的一部分。
[0056]
信号处理装置10在此通过处理输入音频信号8产生输出音频信号12,输出音频信号借助电声输出转换器14转换为助听器2的输出声音信号16。在此优选通过麦克风提供输入转换器4,例如通过扬声器(例如平衡金属壳接收器)提供输出转换器14,但也可以由骨传导耳机等提供输出转换器14。
[0057]
助听器2的周围环境的由输入转换器4采集的声音6此外包含未详细示出的扬声器的语音信号18和另外的声音分量20,另外的声音分量尤其可以包括指向的和/或扩散的干扰噪声(干扰声音或背景噪声),但也可以包含根据情况可以被视为有用信号的声音、例如音乐和与周围环境相关的声学的警告信号或指示信号。
[0058]
输入音频信号8的在用于产生输出音频信号12的信号处理装置10中实现的信号处理尤其可以包括对信号分量的抑制,该信号分量抑制包含在声音6中的干扰噪声,和代表语音信号18的信号分量相对于代表另外的声音分量20的信号分量的相对提升。在此尤其也可以使用与频率相关的或宽带的动态压缩和/或放大以及噪声抑制算法。
[0059]
为了可以在输出音频信号12中尽可能好地听到输入音频信号8中的代表语音信号18的信号分量,并且在输出声音16中仍然能够向助听器2的用户传达尽可能自然的听觉感觉,在信号处理装置10中应该确定语音信号18的语音质量的定量的量度,用以控制应用于输入音频信号8的算法。根据图2描述这一点。
[0060]
图2以框图示出了对根据图2的助听器2的输入音频信号8的处理。首先,针对输入音频信号8实施语音活动vad的识别。如果不存在值得注意的语音活动(路径“n”),那么根据第一算法25进行输入音频信号8的信号处理,用以产生输出音频信号12。第一算法25在此以提前预设的方式以宽带和/或尤其频带方式评估输入音频信号8的信号参数、例如电平、背景噪声、瞬态等,并且由此确定可应用于输入音频信号8的各个参数、例如频带方式的放大因子和/或压缩特征数据(即主要是拐点、比率、攻击、释放)。
[0061]
第一算法25尤其也可以设置听力情况的在声音6中实现的归类,并且依据归类设置各个参数,必要时作为相应针对具体的听力情况设置的听力程序。此外,对于第一算法25也可以考虑助听器2的用户的个体的听力要求,以便能够通过将第一算法25应用于输入音频信号8来尽可能好地补偿用户的听力障碍。
[0062]
然而,如果在识别语音活动vad时确定值得注意的语音活动(路径“y”),那么接下来确定snr,并且将其与预设的边界值th
snr
进行比较。如果snr不高于边界值、即snr≤th
snr
,那么第一算法25再次应用于输入音频信号8以产生输出音频信号12。然而,如果snr高于预设的边界值th
snr
、即snr》th
snr
,那么以如下描述的方式确定包含在输入音频信号8中的语音分量18的语音质量的定量的量度m,以用于输入音频信号8的进一步处理。为此,语音信号18的发音和/或韵律特性被定量地采集。包含在输入音频信号8中的语音信号分量26的术语在
此理解为输入音频信号8的代表声音6的语音分量18的信号分量,从声音借助输入转换器4产生输入音频信号8。
[0063]
为了确定所提到的定量的量度m,将输入音频信号8划分到各个信号路径中。
[0064]
对于输入音频信号8的第一信号路径32,首先确定中心波长λc并将其与中心波长的预定边界值th
λ
进行比较。如果根据中心波长的上述的边界值th
λ
确定输入音频信号8中的信号分量是足够高频的,那么在第一信号路径32中,必要时在可适当选择的随时间的平滑化(未示出)之后,针对低的频率范围nf和位于低的频率范围nf之上的更高的频率范围hf选择信号分量。一个可能的划分例如可以是,低的频率范围nf包括所有以下频率:fn≤2500hz,尤其fn≤2000hz,并且更高的频率范围hf包括以下频率fh:2500hz《fh≤10000hz,尤其4000hz≤fh≤8000hz或2500hz《fh≤5000hz。
[0065]
选择可以直接在输入音频信号8中实施,或也如下地实现,即输入音频信号8借助滤波器组(未示出)被划分为各个频带,其中,各个频带依据相应的带边界与低的或更高的频率范围nf或hf相关联。
[0066]
随后,对于包含在低的频率范围nf中的信号确定第一能量e1,并且对于包含在更高的频率范围hf中的信号确定第二能量e2。现在由作为分子的第二能量和作为分母的第一能量e1形成商qe。在适当选择的更低和更高的频率范围lf、hf的情况下,商qe现在可以考虑作为特征参量33,该特征参量与语音信号18中的辅音的支配度相关。因此,特征参量33能够实现关于输入音频信号8中的语音信号分量26的发音特性的说明。例如,对于商的值qe》》1(即qe》th
qe
,其中预设的未详细示出的边界值th
qe
》》1)可以推导出辅音的高的支配度,而对于值qe《1,可以推导出低的支配度。
[0067]
在第二信号路径34中,在输入音频信号8中,根据相关性测量和/或根据输入音频信号8的过零率,实施浊音时间序列v和清音时间序列uv的区分36。根据浊音和清音时间序列v或uv,确定从浊音时间序列v到清音时间序列uv的转变ts。浊音或清音时间序列的长度例如可以在10至80ms之间、尤其是在20至50ms之间。
[0068]
现在对于至少一个频率范围(例如对特别有效的频带的适当确定的选择,例如bark尺度的频带16至23,或bark尺度的频带1至15),分别确定转变ts之前的浊音时间序列v的能量ev和转变ts之后的清音时间序列uv的能量en。在此尤其地,对于一个以上的频率范围,也可以分别分开地确定转变ts之前和之后的相应的能量。现在例如通过相对变化δe
ts
或通过转变ts之前和之后的能量ev、en的商(未示出)来确定能量在转变ts时如何变化。
[0069]
能量变化的量度,即当前的相对变化现在与针对转变时的能量分配的、预先针对良好的发音确定的边界值the比较。尤其地,特征参量35可以根据相对变化δe
ts
与所述边界值the的比或者根据相对变化δe
ts
与该边界值the的相对偏差来形成。所述特征参量35与语音信号18中的浊音和清音的转变的发音相关,并且因此能够实现关于输入音频信号8中的语音信号分量26的另外的发音特性的说明。在此通常适用的是以下说明,即在与浊音和清音相关的频率范围内,能量分配的变化越快地、即越在时间上可界定地发生,那么浊音和清音时间序列之间的转变就更精确地发音。
[0070]
然而,对于特征参量35也可以例如通过相应的能量的商或可比较的特征值考虑将能量分配到两个频率范围内(例如根据bark尺度的上述的频率范围,或在更低的和更高的频率范围nf、hf中),并且特征参量考虑在转变时商或特征值的变化。因此,例如可以确定商
或特征参量的变化率,并且将其与变化率的提前适当确定的参考值比较。
[0071]
为了形成特征参量35,也可以以类似的方式观察从清音时间序列的转变。通常可以根据关于相应的频带或频带组的相应的有效性的经验结果实现具体的设计方案、尤其关于要使用的频率范围和边界值或参考值的具体的设计方案。
[0072]
在第三信号路径38中,在输入音频信号8中以时间分辨的方式采集语音信号分量26的基本频率fg,并且根据基本频率fg的方差为所述基本频率fg确定时间稳定性40。时间稳定性40可以用作特征参量41,其能够实现关于输入音频信号8中的语音信号分量26的韵律特性的说明。在此,基本频率fg的较大的方差可以考虑作为更好的语音清晰度的指标,而单调的基本频率fg具有更小的语音清晰度。
[0073]
在第四信号路径42中,针对输入音频信号8和/或针对包含在其中的语音信号分量26以时间分辨的方式采集电平lvl,并且在尤其根据相应的经验知识预设的时间段44中形成时间平均值mn
lvl
。此外,在时间段44内确定电平lvl的最大值mx
lvl
。现在,将电平lvl的最大值mx
lvl
除以电平lvl的时间平均值mn
lvl
,并且因此确定与语音信号18的音量相关的特征参量45,该特征参量能够实现关于输入音频信号8中的语音信号分量26的韵律特性的进一步的说明。替代电平lvl地,在此也可以使用与语音信号分量26的音量和/或能量含量相关的另一参量。
[0074]
在第一至第四信号路径32、34、38、42中如所描述的那样分别确定的特征参量33、35、41或45现在可以分别单独考虑作为包含在输入音频信号8中的语音分量18的质量的定量的量度m,依据该量度,现在将第二算法46应用于输入音频信号8以进行信号处理。在此,可以通过信号处理的一个或多个参数的、依据相关的定量的量度m实现的相应的变化,从第一算法25产生第二算法46,或者第二算法设置完全独立的听力程序。
[0075]
尤其地,也可以根据如所描述的那样确定的特征参量33、35、41或45,例如通过特征参量33、35、41、45的乘积或加权平均值(在图2中通过合并特征参量33、35、41、45示意性示出)确定单独的值作为语音质量的定量的量度m。各个特征参量的加权在此尤其可以根据预先根据经验确定的加权因子进行,加权因子可以根据语音质量的由相应的特征参量采集的发音或韵律特性的有效性来确定。
[0076]
如果定量的量度m还应该采集语音信号18中的元音的预设的共振峰的精度,那么可以确定在频率空间中的至少一个共振峰范围内的语音信号18的信号分量,并且可以为相关的共振峰范围内的语音信号18的信号分量确定电平或与电平相关的信号参量(未示出)。随后,根据最大值和/或根据电平的时间稳定性或与电平相关的信号参量确定与共振峰的精度相关的相应的特征参量。在此尤其地,作为至少一个共振峰范围可以选择第一共振峰f1(优选250hz至1khz、特别优选300hz至750hz)或第二共振峰f2(优选500hz至3.5khz、特别优选600hz至2.5khz)的频率范围,或选择第一和第二共振峰的两个共振峰范围。尤其地,也可以选择与不同的元音相关联的多个第一和/或第二共振峰范围(即与相应的元音的第一或第二共振峰相关联的频率范围)。现在针对一个或多个选择的共振峰范围确定信号分量,并且确定相应的信号分量的与电平相关的信号参量。在此,可以由电平本身或也通过必要时适当平滑化的最大的信号幅度提供信号参量。根据信号参量的时间稳定性(其又通过信号参量在适当的时间窗内的方差确定)和/或根据在适当的时间窗内信号参量与其最大值的偏差,现在可以做出关于共振峰的精度的说明,即小的方差和与发音的声音的最大电平
的小的偏差(尤其可以依据发音的声音的长度选择时间窗的长度)代表高的精度。
[0077]
图3以框图示出了依据语音质量设置根据图1的输入音频信号8的信号处理,语音质量例如在根据图2所示的方法中被定量地采集。在此一方面,将输入音频信号8划分到主信号路径47和副信号路径48。在主信号路径47中,以在下面还要描述的方式发生输入音频信号8的信号分量的实际的处理,使得稍后由这些被处理的信号分量形成输出音频信号12。在副信号路径中,以在下面还要描述的方式获得用于主信号路径47中的信号分量的所述处理的控制参量。如根据图2描述的那样,在此,在副信号路径48中确定语音信号的包含在输入音频信号8中的信号分量的语音质量的定量的量度m。
[0078]
输入音频信号8此外在滤波器组49处被划分成各个频带8a-8f(该细分在此可以包括比仅示意性示出的六个频带8a-8f明显更大的数量)。滤波器组49在此表示为单独的开关元件,但也可以使用在副信号路径48中确定定量的量度m的范围内使用的相同的滤波器组结构,或者可以一次性地划分信号用以确定定量的量度m,从而在产生的频带中的各个信号分量一方面在副信号路径48中被考虑用于确定语音质量的定量的量度m,并且另一方面在主信号路径47中相应被进一步处理,用以产生输出音频信号12。
[0079]
确定的定量的量度m在此一方面例如可以表示单个参量,其仅评估根据图1的语音信号18的具体的发音特性、例如辅音的支配度或浊音和清音时间序列之间的转变的精度或共振峰的精度,或评估具体的韵律特性、例如语音信号18的基本频率fg的时间稳定性,或语音信号18通过最大电平相对于电平的时间平均值的相应的变化的增强。另一方面,定量的量度m也可以形成为来自多个特征参量的加权平均值、例如来自根据图2的特征参量33、35、41、45的加权平均值,特征参量分别评估所提到的特性中的一个。
[0080]
定量的量度m当前应该被设计为二进制量度50,使得其采用第一值51或第二值52。第一值51在此表明足够好的语音质量,而第二值52表明语音质量不足。这尤其可以通过以下方式实现,即特征参量、例如根据图2被确定用于确定语音质量的定量的量度m的特征参量31、33、41或45的本身连续的值范围或多个这种特征参量的相应的加权平均值被划分为两个范围,并且给第一值51分配一个范围,而给第二值52分配另一范围。在此,为了对第一值或第二值51、52进行分配,优选可以如下地选择特征参量的值范围的各个范围或特征参量的平均值,使得对第一值51的分配实际上对应于足够高的语音质量,从而不再需要对输入音频信号8的进一步处理,以便确保从输出音频信号12产生的输出声音16中的相应的语音信号分量的足够的可理解性。
[0081]
定量的量度的第一值51在此与用于信号处理的第一参数值53相关联,第一参数值尤其可以通过相应在根据图2的第一算法25中实现的值提供。这意味着:第一参数值53尤其通过信号处理的至少一个参数的具体的值提供,例如(当前相应对于相关的频带)通过放大因子、压缩拐点、压缩比、agc的时间常数、或定向信号的定向参数提供。尤其地,第一参数值可以通过提到的信号控制参量中的多个的值的向量提供。第一参数值53的具体的数值在此对应于该参数在第一算法25中采用的值。
[0082]
第二值52与用于信号处理的第二参数值54相关联,第二参数值尤其可以通过放大因子、压缩拐点、压缩比、agc的时间常数或定向参数的相应在根据图2的第二算法46中实现的值提供。
[0083]
现在对各个频带8a-8f中的信号分量进行分析56,以确定语音信号的信号分量是
否存在于相应的频带8a-8f中。如果不是这种情况(在本示例中针对频带8a、8c、8d、8f),那么将第一参数值53应用于输入音频信号8以进行信号处理(例如作为用于相关的频带8a、8c、8d、8f的放大因子的向量)。这些频带8a、8c、8d、8f经受不需要附加地改进语音质量的信号处理,例如因为没有语音信号分量存在,或者因为语音质量已经是足够好的。
[0084]
然而,如果不是这样的情况,并且定量的量度m采用第二值52,那么将第二参数值54应用于在其中确定了语音分量的那些频带8b和8e,以进行信号处理(这对应于按照根据图2的第二算法46的信号处理)。在此特别地,在根据能够说明辅音的发音的特征参量(例如根据图2的特征参量31和35,其取决于辅音的支配度或浊音和清音时间序列之间的转变的精度)确定定量的量度m的情况下,如果在频带8e中,针对辅音的发音存在特别集中的声能,那么用于更高的频带8e的第二参数值54尤其可以提供放大的附加的提升。
[0085]
最后,在如所描述的那样利用第一参数值53(对于频带8a、8c、8d、8f)或第二参数值54(对于频带8b、8e)对相应的信号分量进行信号处理之后,将各个频带8a-8f的信号分量在合成滤波器组58中组合,其中产生输出音频信号12。
[0086]
图4以线图示出了用于控制信号处理的参数g依赖于语音信号的语音质量的定量的量度m的函数f。参数g并不局限于放大,而是在此可以由上述的控制参量中的一个提供,或者在向量值的参数的情况下与向量的条目(eintrag)相关。对于根据图4的示例,定量的量度m具有0和1之间的连续的值范围,其中,值1表明最好的语音质量,而值0表明最差的语音质量。在此尤其地,用于确定定量的量度m的特征参量可以适当归一化,以便将定量的量度的值范围限制在区间[0,1]内。
[0087]
在此产生函数f(实线,左刻度),以便随后能够借助函数f在最大参数值gmax和最小参数值gmin之间连续内插参数g(虚线,右刻度)。现在函数值f(1)=1与定量的量度m的值1相关联,函数值f(0)=0与值0相关联。参数g在此使得对于良好的语音质量(即m=1)来说,参数值gmin用于信号处理,对于差的信号质量(即m=0)来说,参数值gmax用于信号处理。对于m的值高于边界值m
l
,总是还将语音质量视为“足够好”,从而参数g与相应的最小参数值gmin的无偏差对于“良好的语音质量”来说被视为是必需的;对于m≥m
l
,函数f(m)因此是f(m)=1,并且相应地g=gmin。在低于边界值m
l
的情况下,语音质量的定量的量度m(当前利用几乎指数的曲线)连续单调升高地映射到f(m),从而对于值m=0或m=m
l
,函数如所需的那样采用值f(0)=0或f(m
l
)=1。对于相关的参数g来说,这意味着对于m》0,g从gmax急剧减小到gmin(在m=m
l
处)。函数f与参数g的关系例如可以表示为
[0088]
g(m)=gmax
–
f(m)
·
(gmin
–
gmax)。
[0089]
虽然本发明在细节上通过优选的实施例详细说明和描述,但本发明并不局限于公开的示例,并且可以由本领域技术人员从中推导出其他的变型方案,而不会脱离本发明的保护范围。
[0090]
附图标记列表
[0091]
1 听力设备
[0092]
2 助听器
[0093]
4 输入转换器
[0094]
6 周围环境的声音
[0095]
8 输入音频信号
[0096]
8a-f 频带
[0097]
10 信号处理装置
[0098]
12 输出音频信号
[0099]
14 输出转换器
[0100]
16 输出声音
[0101]
18 语音信号
[0102]
20 声音分量
[0103]
25 第一算法
[0104]
26 语音信号分量
[0105]
32 第一信号路径
[0106]
33 特征参量
[0107]
34 第二信号路径
[0108]
35 特征参量
[0109]
36 区分
[0110]
38 第三信号路径
[0111]
40 时间稳定性
[0112]
41 特征参量
[0113]
42 第四信号路径
[0114]
44 时间段
[0115]
45 特征参量
[0116]
46 第二算法
[0117]
47 主信号路径
[0118]
49 滤波器组
[0119]
50 二进制量度
[0120]
51(二进制量度的)第一值
[0121]
52(二进制量度的)第二值
[0122]
53 第一参数值
[0123]
54 第二参数值
[0124]
56(对语音分量的)分析
[0125]
58 合成滤波器组
[0126]
δe
ts
(转变时的能量的)相对变化
[0127]
λ
c 中心波长
[0128]
e1 第一能量
[0129]
e2 第二能量
[0130]
ev(转变之前的)能量
[0131]
en(转变之后的)能量
[0132]fg
基本频率
[0133]
g 参数
[0134]
gmin 最小的参数值
[0135]
gmax 最大的参数值
[0136]
hf 更高的频率范围
[0137]
lvl 电平
[0138]
m 语音质量的定量的量度
[0139]ml
边界值
[0140]
mn
lvl
(电平的)时间平均值
[0141]
mx
lvl
电平的最大值
[0142]
nf 低的频率范围
[0143]
qe 商
[0144]
snr 信噪比(snr)
[0145]
th
λ
(中心波长的)边界值
[0146]
the(能量的相对变化的)边界值
[0147]
th
snr
(snr的)边界值
[0148]
ts 转变
[0149]
v 浊音时间序列
[0150]
vad 语音活动的识别
[0151]
uv 清音时间序列
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。