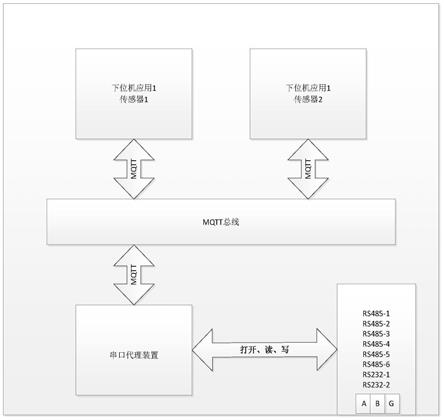
1.本发明属于网络安全技术领域,更进一步涉及一种加密流量识别方法,可用于改 善网络管理、监控应用安全及对加密流量数据进行异常检测。
背景技术:
2.移动设备和互联网的迅速普及极大地改变了各种网络服务的接入方式,导致了网络 流量的爆炸式增长。针对网络流量的网络攻击严重影响到网络的正常安全运行,甚至危 害到公民的信息安全。随着越来越多的移动服务采用加密技术,数据包中的许多信息将 变得不可见,加密方法的规则也层出不穷,加密流量识别技术成为研究学者关注的重点。 虽然经典方法可以解决基于端口和有效载荷方法不能解决的许多问题,但它仍然存在一 些局限性,如复杂的特征需要手工提取十分耗时耗力、特征更新频繁等。流量数据的不 平衡性会导致小样本识别率偏低的问题。在进行模型训练时,如何高效提取特征,减少 标记数据的需求,提高识别率是一个非常关键的研究课题。加密流量识别由于可以分析 用户操作习惯和使用的应用类别,所以有非常广泛的数据挖掘和商业应用价值。加密流 量识别可以应用于改善网络管理,网络管理者可以根据不同流量在带宽中的比例动态控 制接入,合理控制流量的变化趋势。加密流量识别可以应用于监控应用安全,安全监管 机构需要实时识别恶意流量,以避免严重的损失。加密流量识别可以应用于异常检测, 根据用户的操作习惯针对性的优化应用,以提供更好的用户体验。
3.北京工业大学在申请号为202110081372.1的专利申请文献公开了一种“基于卷积 神经网络的加密流量实时分类方法及装置”。其实施步骤是:首先,将采样得到的数据 包作为字节流,任意相连两个字节作为一个字节对;其次,确定所有字节对的频率特征; 然后,将所有字节对的频率特征,输入预训练的卷积神经网络模型,输出每一条加密流 量的数据流类型。该方法由于提取到的特征仅仅是可分离的,并不能体现出深层特征的 内部关系,故导致识别精度不够高。
4.北京理工大学在申请号为201911164936.7的专利申请文献公开了一种“一种基于 深度学习策略的异常加密流量检测与分类方法”。其实施步骤是:首先,利用相邻做差 法对原始数据进行特征加强;其次,利用加强后的数据集中带有协议标签的数据训练一 维卷积神经网络模型来对已知类型异常加密流量进行检测与分类;然后,利用k-均值 算法对加强后的数据集中没有协议标签的未知类型异常加密流量进行分类。该方法由于 一维卷积神经网络模型收敛速度很慢,缺乏鲁棒性,导致识别速度不快。
技术实现要素:
5.本发明的目的在于针对上述现有技术的不足,提出一种基于原型卷积网络的加密流 量识别方法,以提高识别精度,加快识别速度。
6.实现本发明目的的技术方案是:通过高效提取加密流量数据特征,实现对加密流量 数据进行智能识别,其实现方案包括如下:
7.1.一种基于原型卷积网络的加密流量识别方法,其特征在于:
8.a)从加密流量网络中采集网络数据包获取流量原始数据,再对其依次进行数据清 洗、数据变换、数据编码、数据增强的预处理,得到加密流量数据,并计算其对应的 类别;
9.b)构建由采集模块、嵌入模块、筛查模块、距离模块依次级联组成的原型生成模 型,并将加密流量数据输入到该模型中,得到流量原型数据及其对应的类别;
10.c)对流量原型数据进行聚类,并计算聚类的原型密度,得到流量原型数据中的特 征生成向量;
11.d)对特征生成向量分别按照70%,20%,10%进行抽取,组成训练样本集,测试 样本集,验证样本集;
12.e)构建依次由输入层,卷积层,池化层,全连接层和输出层级联组成的原型卷积 网络;
13.f)设置最大迭代轮次数为100,将训练样本集和测试样本集输入到原型卷积网络 中,利用原型学习方法进行原型卷积网络的训练,直到原型卷积网络达到最大迭代轮 次数,得到训练好的原型卷积网络;
14.g)将验证样本集中的特征向量输入到已经训练好的原型卷积网络中,得到加密流 量识别结果。
15.本发明与现有技术相比,具有以下优点:
16.第一,本发明由于将加密流量数据输入到原型生成模型中,得到流量原型数据及 其对应的类别,能够提升对流量数据的嵌入粒度,且对其特征能进行更精确的表示, 增大了识别不同类流量所需的聚类间的离散性,提升了识别精度;
17.第二,本发明由于对流量原型数据进行聚类,并计算聚类的原型密度,得到流量 原型数据中的特征生成向量,因而能够提取结构化的深层特征,更加贴近流量数据的 分布特点,增加识别不同类流量所需的聚类内之间的聚合,进一步提升了识别精度;
18.第三,本发明将原型学习和神经网络相结合,构建了原型卷积网络,并在基于期 望最大化的框架中执行迭代,避免了有监督学习所带来无法对庞大的加密流量类别进 行完全快速分类的问题,加快了识别速度。
附图说明
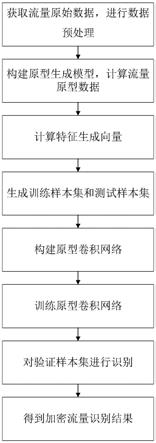
19.图1为本发明的实现流程图;
20.图2为用本发明和现有5种方法分别在2个数据集上的得到加密流量识别精度仿 真图。
具体实施方式
21.下面结合附图对本发明的实施例和效果做进一步详细的描述。
22.参照图1,本实例的实现包括如下步骤:
23.步骤1,获取流量原始数据,并对其进行预处理。
24.1.1)从加密流量网络中采集网络数据包获取流量原始数据;
25.本实例采取但不限于通过wireshark工具对经由openvpn传输的网络数据包进 行依次采集源ip地址、目的ip地址、源端口、目的端口、网络协议、用户数据信息, 组成流量原
始数据;
26.1.2)将获取的流量原始数据中的无效值和缺失值设置为0,完成数据清洗;
27.本实例采取但不限于一致性检查来发现无效值,即根据每个变量的合理取值范围 和相互关系检查数据是否合乎要求,并将不符合要求的数据标记为无效值;
28.1.3)将数据清洗后的流量数据利用变换函数将其变换为正态分布完成数据变换;
29.本实例采取但不限于平方根函数作为变换函数,即将变换前数据分布偏前的数据 利用平方根公式变换为正态分布;
30.1.4)将数据变换后的流量数据表示为二进制向量完成数据编码;
31.本实例采取但不限于独热编码进行数据编码,即采用位状态寄存器来对数据进行 编码;
32.1.5)将数据编码后的流量数据根据数据增强因子将其进行倍数变换,完成数据增 强,得到加密流量数据;
33.1.6)计算加密流量数据对应的类别:
[0034][0035]
其中,q表示加密流量数据对应的类别编码值,即为选择加密流量数据对应的所 有类别中第q个类别,q取值为[1,2,
…
,n],n为加密流量数据类别总数,本实例采取 但不限于12,f表示流量类别函数,δ表示流量类别参数,表示流量类别原型参数, z是加密流量数据。
[0036]
步骤2,构建原型生成模型。
[0037]
2.1)建立采集模块:用以从步骤1中所述加密流量数据中依次选取w个加密流量 数据样本作为支持集,选取u个加密流量数据样本作为查询集;
[0038]
2.2)建立嵌入模块:用以从支持集中获得加密流量数据样本ζ,从查询集中获得 加密流量数据样本ξ,并根据该查询集中加密流量数据样本ξ计算查询集特征向量: sk=α(ξ,θ),其中,α表示嵌入函数,θ表示嵌入参数,k表示类别原型数,k取值为 [1,2,
…
,e],e为类别原型总数;
[0039]
2.3)建立筛查模块:用以根据查询集特征向量计算类别原型:其中,|sk|表示查询集的特征向量数量,β为原型函数;
[0040]
2.4)建立距离模块:用以计算流量原型数据μ和流量原型数据μ对应的流量原型 数据类别w,其实现如下:
[0041]
根据支持集中加密流量数据样本ζ计算支持集特征向量:rk=α(ζ,θ),其中,α 表示嵌入函数,θ表示嵌入参数;
[0042]
根据支持集的特征向量rk计算原型距离:并计算原型标签 值:其中,|rk|表示支持集的特征向量数量,ck表示类别原 型;
进行最大池化运算,得到池化向量ψ;
[0061]
本实例采取但不限于序位池化法进行最大池化运算,即在池化域内按照激活值序 位进行最大池化运算;
[0062]
6.4)建立隐藏层:其采用从上至下的256个隐藏子层级联组成,用以对池化向量 ψ,进行映射计算,得到隐藏向量χ,设置隐藏子层之间的激活函数为softmax函数;
[0063]
6.5)建立输出层:其采用从上至下的2个输出子层级联组成,这两个输出子层之 间的激活函数为双曲正切激活函数,在每个输出子层先计算其期望编码为:v=g(χ), 再根据该期望编码v计算期望标签值h:
[0064][0065]
其中,g为期望函数,σ表示输出函数,v
′
表示期望动态编码,ck表示类别原型, c
′k表示类别原型动态编码,l表示聚类原型采集次数,w表示动态密流量数据类别, w
′
表示动态密流量数据类别,τ是期望系数;
[0066]
6.6)将输入层,卷积层,池化层,隐藏层及输出层依次级联组成的原型卷积网络。
[0067]
步骤7,训练原型卷积网络。
[0068]
7.1)设置最大迭代轮次数为100;
[0069]
7.2)将训练样本集和测试样本集输入到上述设计的原型卷积网络中,得到训练样 本集和测试样本集的期望标签值h;
[0070]
7.3)根据期望标签值h和原型标签值y计算训练误差:ε=-∑hlogy;
[0071]
7.4)根据当前批次的训练误差ε计算当前轮次梯度值:其中,t 表示轮次序数,π
t-1
表示上一轮次的梯度值,初始轮次的梯度值为0,η表示学习率;
[0072]
7.5)根据当前轮次梯度值更新当前轮次梯度卷积核参数,完成当前轮次训练;
[0073]
本实例采用但不限于梯度下降法更新卷积核参数,即指沿着梯度方向对卷积核参 数进行更新,以求解原型卷积网络收敛的最优解;
[0074]
7.6)判断当前训练轮次数是否达到设置的最大训练轮次数:
[0075]
若是,则停止训练,得到训练好的原型卷积网络;
[0076]
否则,将训练轮次数t增加1,返回7.1)。
[0077]
步骤8,获得加密流量数据识别结果。
[0078]
将验证样本集中的特征生成向量输入到已经训练好的原型卷积网络中,得到验证 样本集的期望标签值h;
[0079]
将验证样本集的期望标签值h与验证样本集中的真实标签值u进行比较,得到加密 流量数据识别结果:
[0080]
若h=u,则认为加密流量被正确识别;
[0081]
若h≠u,则认为加密流量未被正确识别。
[0082]
下面结合仿真实验,对本发明的效果做进一步的说明。
[0083]
1.仿真实验条件:
[0084]
本发明的仿真实验的运行环境是:处理器为intel(r)core(tm)i3-9100 cpu@ 3.60ghz,内存为8.00gb,硬盘为929g,操作系统为windows 10,编程环境为python3.8,编程软件为pycharm community edition 2020.2.3x64。
[0085]
仿真所使用的数据集为joy数据集和ssl数据集,其中:
[0086]
joy数据集是cisco开源的加密流量分析系统的数据集,用于从实时网络流量中提 取数据特征,使用netflow的面向流的模型,然后用json表示这些数据特征,数据集 包括数据包长度和时间序列,表示一个特定字节值出现在流中数据包的有效负载中的 概率的字节分布,tls特有的特征和初始数据包。
[0087]
ssl数据集使用tls证书的内容识别合法证书和恶意证书。ssl数据集的网络钓鱼 证书来自vaderetro,恶意软件证书来自mach.ch项目和censys.io,合法证书来自 alexa top。
[0088]
仿真使用的现有对比方法为以下5种:
[0089]
1、根据合适的参数分布的概率密度和概率分布模型,计算后验分布以求取类别期 望值的贝叶斯模型方法。
[0090]
2、根据在高维数据中寻找正样本和负样本之间的最大化分隔平面来划分数据求取 类别期望值的支持向量机模型方法。
[0091]
3、根据用与待判别数据距离最近的数据的类别求取类别期望值的最近邻模型方 法。
[0092]
4、根据通过历史数据的表现对未来结果发生的概率求取期望值的逻辑回归模型 方法。
[0093]
5、根据已知各种情况发生概率,通过构成决策树来求取类别期望值的决策树模型 方法。
[0094]
仿真实验1:比较本发明与现有5种方法的加密流量识别精度。
[0095]
仿真过程如下:
[0096]
首先,分别从joy数据集和ssl数据集中获取流量原始数据,并对其进行数据预 处理得到加密流量数据,使用本发明和上述现有5种加密流量识别方法,得到加密流 量数据识别结果;
[0097]
其次,根据加密流量数据识别结果统计被正确识别出的目标加密流量数目tp,被 正确识别出的其它加密流量数目tn,被错误识别出的目标加密流量数目fp,被遗漏识 别的目标加密流量数目fn,再分别计算准确率和召回率根据准确 率和召回率的计算结果,计算f1得分f1得分的高低可表示加密流量识别 精度的高低;
[0098]
最后,比较各方法的f1得分,结果如图2所示,其中横轴表示不同方法,纵轴表 示f1得分。
[0099]
由图2可以看出,本发明标示的柱状图对应的f1得分位于现有5种方法标示的柱 状图对应的f1得分的上方,即本发明的f1得分是6种方法中最高的,表明本发明的 加密流量识别精度高于现有的5种方法。
[0100]
仿真实验2:比较本发明与上述现有5种方法进行加密流量识别速度。
[0101]
用本发明和上述5种现有方法对joy数据集的加密流量进行识别,分别计算仿真 实验1中本发明的方法与上述5种现有方法的收敛参数,并将这6种方法收敛参数进 行比较,收敛参数的大小可以表示加密流量识别速度的快慢,结果如表1。
[0102]
表1各方法的收敛参数
[0103]
方法名称收敛参数收敛参数由小至大排序贝叶斯模型方法0.866支持向量机模型方法0.584最近邻模型方法0.825逻辑回归模型方法0.543决策树模型方法0.412本发明方法0.301
[0104]
由表1可以看出,现有5种方法进行识别的收敛参数均较大,本发明进行识别的收 敛参数较小,表明本发明的收敛参数小于现有的5种方法的收敛参数,本发明的识别 速度快于现有的5种方法的加密流量识别速度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。